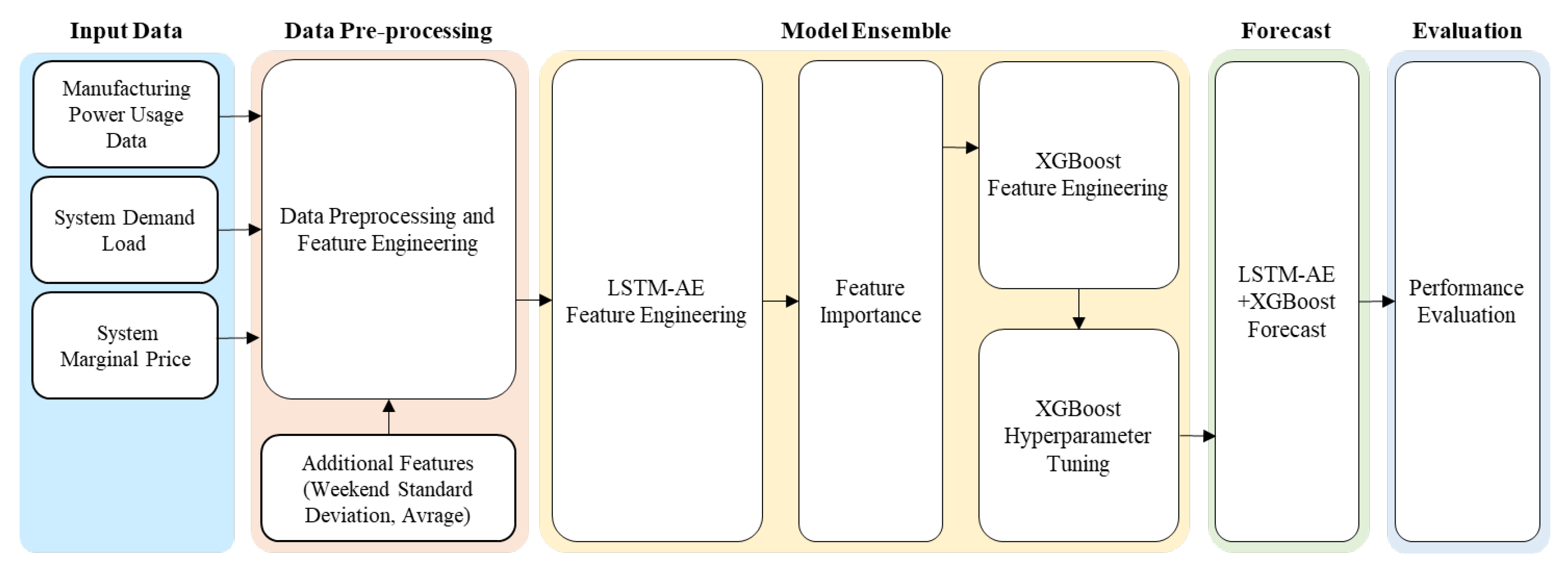
4.2. Dataset
The dataset used in this experiment comprises electricity consumption data collected every minute for seven months, from 1 March 2019 to 30 September 2019, from some manufacturing plants participating in the domestic DR market. Each plant exhibits approximate periodicity according to its manufacturing process. Plants implementing automated processes consistently recorded electricity consumption even during holidays. The power consumption of the plants varied according to their scale. Despite the limitation of the seven-month acquisition period, the weekly usage characteristics were strongly identified [
44].
In this experiment, the power consumption datasets of the forging process from two plants were used. To predict the power consumption of the forging process, the power consumption data measured simultaneously from the two forging plants were extracted and merged into a single dataset. First, the data variables were merged into a single file according to the time, with the system demand collected in 5 min intervals and the forging power consumption in 1 min intervals, resampling the gaps between variables. Additionally, holiday and weekly average and standard deviation values were added as variables to create a data frame. To analyze data preprocessing, the distribution of columns in the Forge1 and Forge2 data was visualized, confirming that the power consumption patterns of the two processes were similar, as shown in
Figure 3.
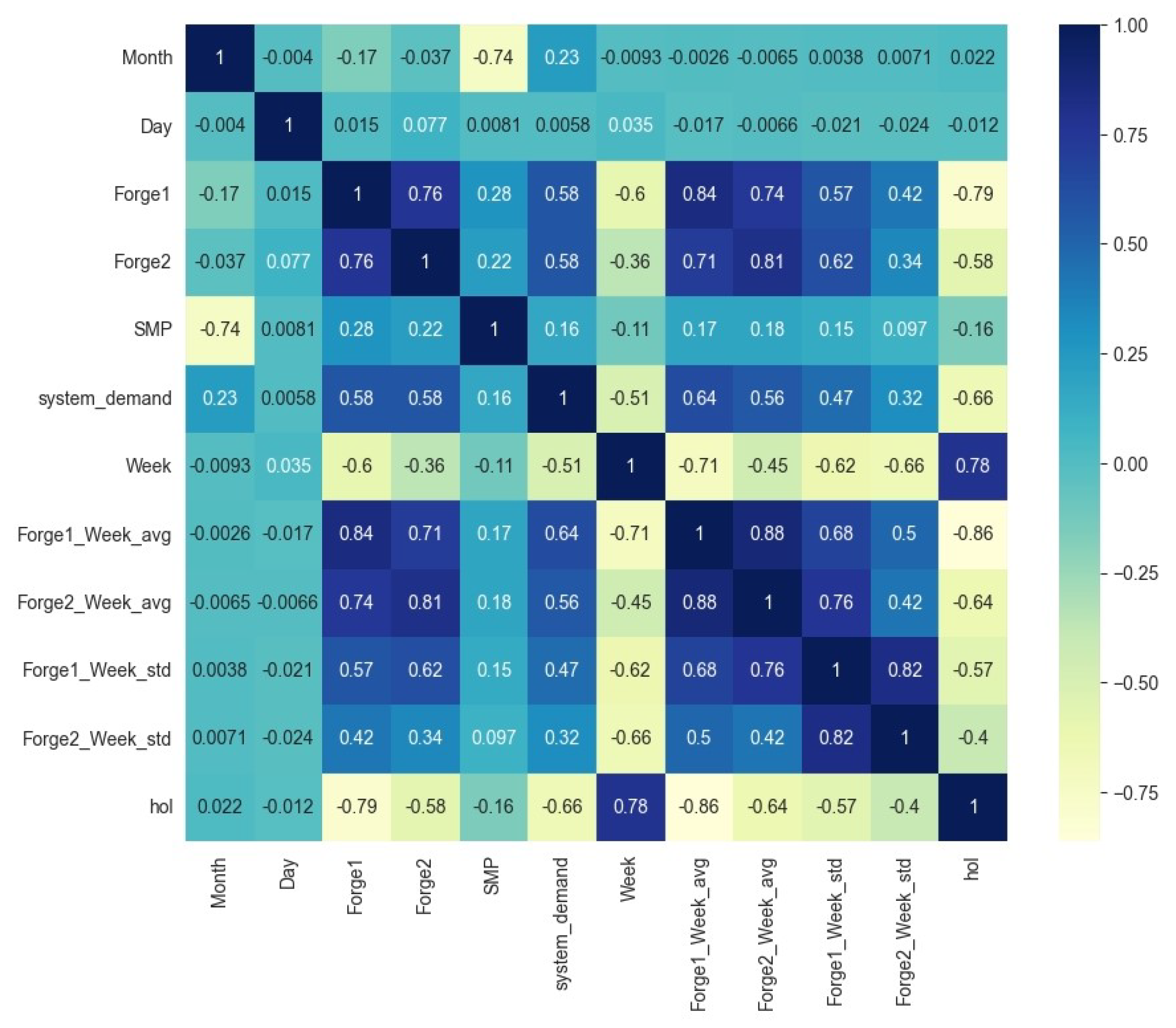
To select meaningful variables, the correlations between variables were examined through a correlation map, as shown in
Figure 4. Forge1 and Forge2 (0.76) showed a high positive correlation, indicating that when the power consumption of Forge1 is high, the power consumption of Forge2 tends to be high as well. SMP and system demand (0.16) showed a slight positive correlation, suggesting that when power demand is high, the market price of power may increase, although the impact is not significant. System demand and Forge1 Weekly Standard Deviation (
) and Forge2 Weekly Standard Deviation (
) showed a strong negative correlation between system power demand and the weekly power consumption standard deviation of each Forge, indicating that the higher the power demand, the lower the variability in weekly power consumption. Forge1 Weekly Average and Forge2 Weekly Average (0.88) showed a very high positive correlation between the weekly average power consumption of the two Forges, indicating that when the weekly average consumption of one Forge is high, the other Forge shows a similar trend. Lastly, the holiday variable holiday and Forge2 Weekly Standard Deviation (
) and Forge2 Weekly Average (0.86) showed strong negative and positive correlations, respectively, between holidays and the weekly standard deviation and average of Forge2, suggesting that the variability in power consumption of Forge2 is lower and the average consumption is higher during holidays.
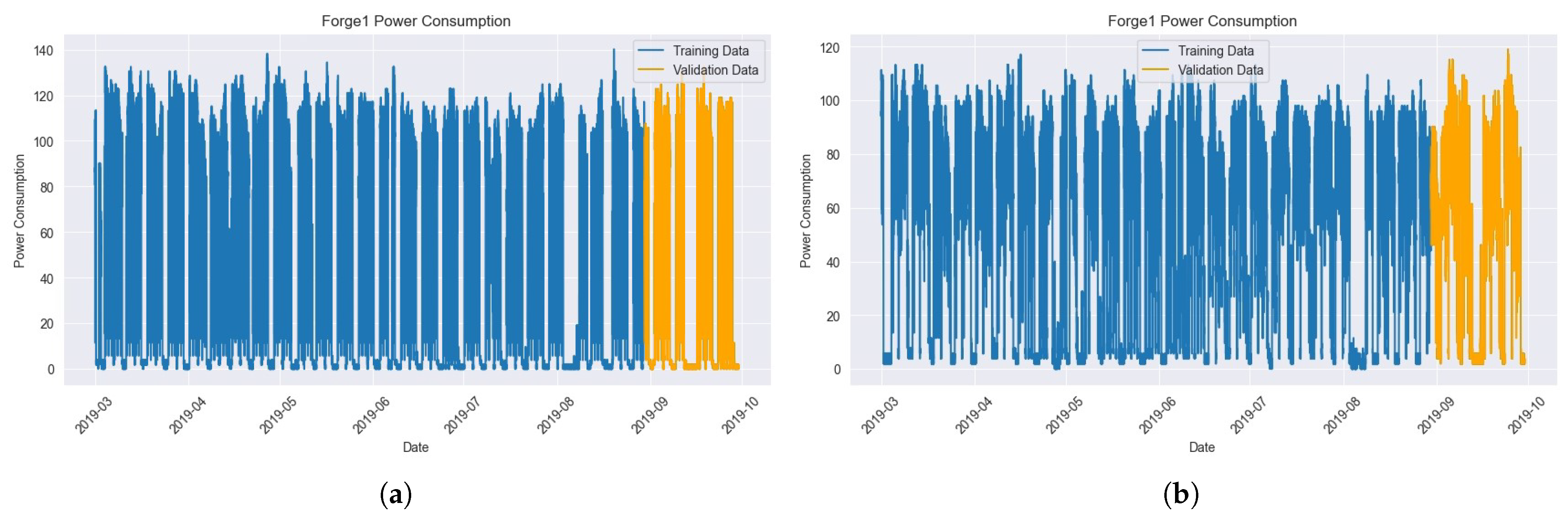
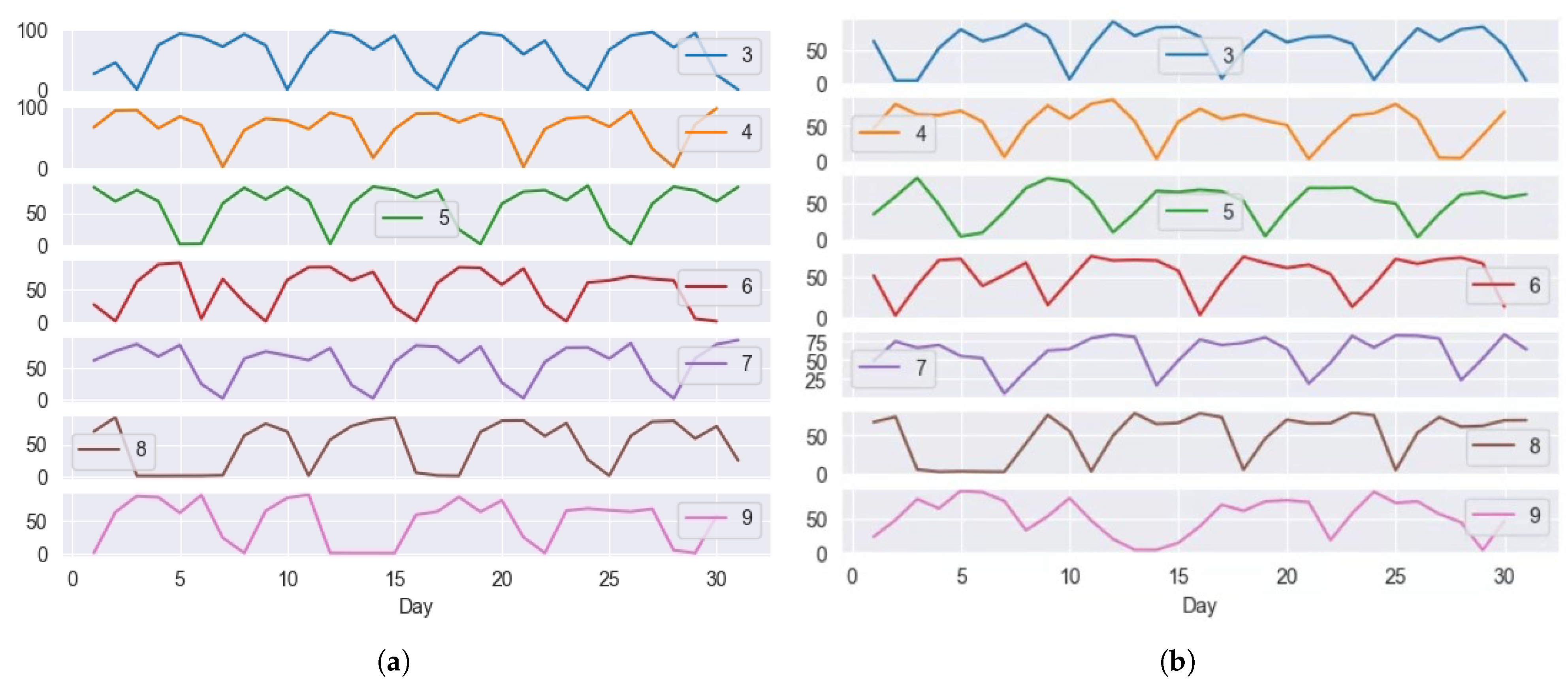
Based on
Figure 5, the selected variables were used to create a new data frame, and the dataset was split into training data and validation data as shown in
Figure 5a,b. The Validation Dataset was set to the power consumption from 1 September 2019 to 30 September 2019.
4.3. Performance Metrics
This study aims to enhance the accuracy of power consumption forecasting compared to existing models, reduce the error rate in anomaly detection in power consumption, and accurately quantify the environmental impact of energy consumption. The following performance metrics are used to evaluate the accuracy of the model. The performance metrics include MAE, Mean Squared Error (MSE), Coefficient of Determination (R2), and SMAPE to evaluate the accuracy of the predictive model.
MAE represents the mean of the absolute differences between actual and predicted values, with lower values indicating better accuracy.
MSE is the mean of the squared differences between predicted and actual values, indicating the size of the prediction error. Lower MSE values indicate higher predictive accuracy.
R2 indicates how well the model explains the actual values, ranging from 0 to 1, with values closer to 1 indicating better explanatory power. where
is the mean of the actual values.
SMAPE represents the mean of the absolute percentage differences between the predicted and actual values. It ranges from 0% to 200%, with lower values indicating higher predictive accuracy. Here,
is the actual value and
is the predicted value.
4.4. Experimental Results
The experimental process is as follows. First, the data variables were merged into a single file according to the time, with the system demand collected in 5 min intervals and the forging power consumption in 1 min intervals, resampling the gaps between variables.
To examine the monthly distribution, the monthly power consumption of Forge1 and Forge2 was checked.
Figure 6a,b show the trend of monthly power consumption for data preprocessing. Additionally, the generated data frame’s missing values and outliers were checked. Quantitative methods were not used to check for missing values, but qualitative methods such as graphs were used for confirmation.
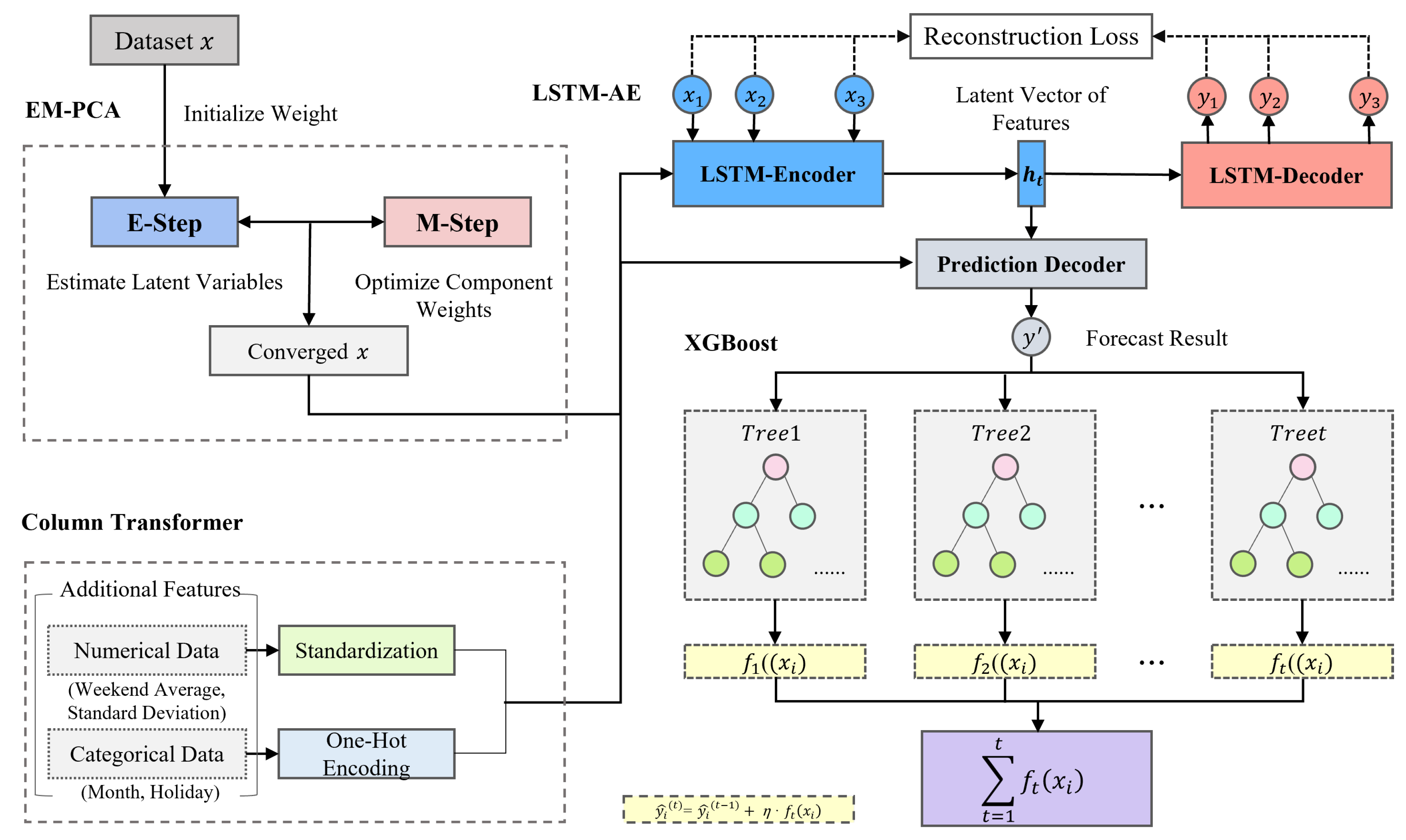
Figure 7 shows a qualitative visualization of missing data using Missingno Library: Forge1 had missing values on 9, 10, and 27 July, while Forge2 had a missing value on 27 April. Additionally, in this experiment, a DR event occurred temporarily from 18:00 to 19:00 on 13 June 2019, and this time was considered an outlier and preprocessed using the EM-PCA technique. The preprocessing results are shown in
Figure 8.
Figure 9 and
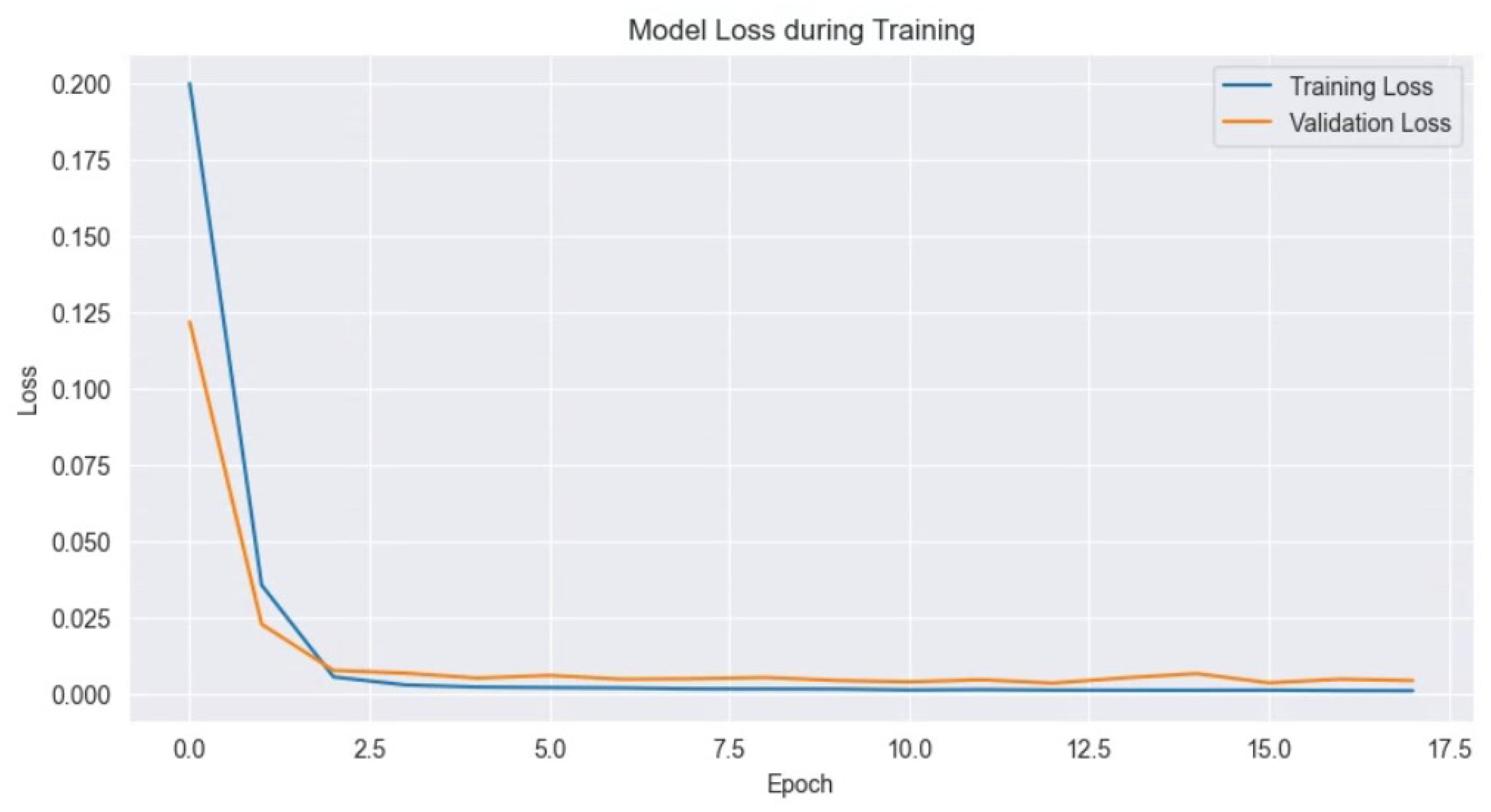
Figure 10 show the results of applying the extracted features from LSTM-AE and additional variables to XGBoost training.
Figure 9 visualizes the training and validation loss during feature extraction using the LSTM-AE model. The
x-axis represents the number of epochs, and the
y-axis represents the magnitude of loss. The training loss represents the loss on the training data, which decreases rapidly as epochs progress and stabilizes after a few epochs, indicating that the model adapts well to the training data. The validation loss represents the loss on the validation data, showing a similar trend to the training loss, stabilizing as epochs progress, indicating that the model maintains generalization performance without overfitting.
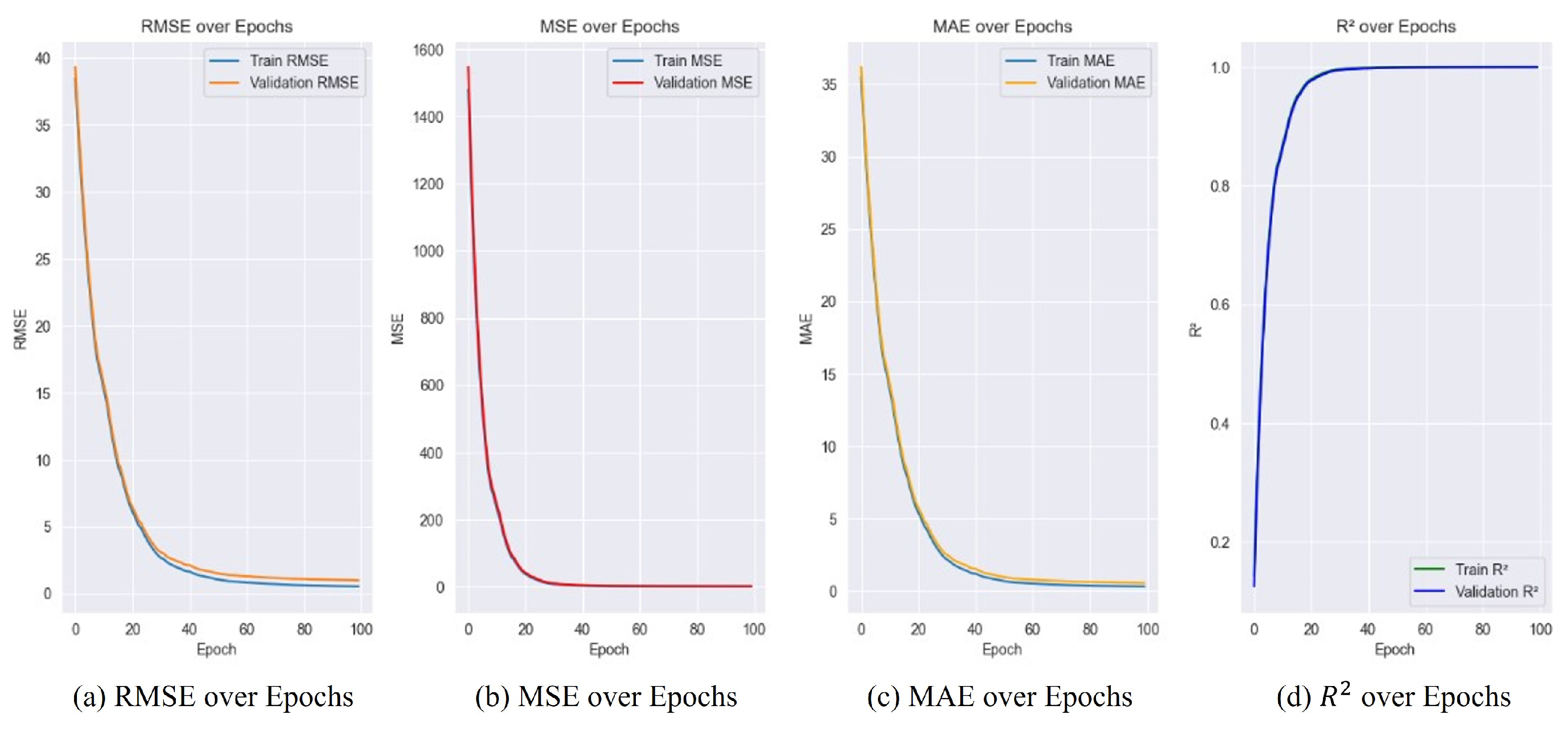
The graph in
Figure 10 shows that the metrics for both the training and validation data are very similar, indicating no signs of overfitting. Specifically, the values for (a) RMSE, (b) MSE, (c) MAE, and (d)
R2 consistently decrease or increase for both training and validation data. These results suggest that the model generalizes well to both training and validation data. In both graphs, blue represents the training data, orange represents the actual values of the validation data, and green represents the predicted values of the validation data.
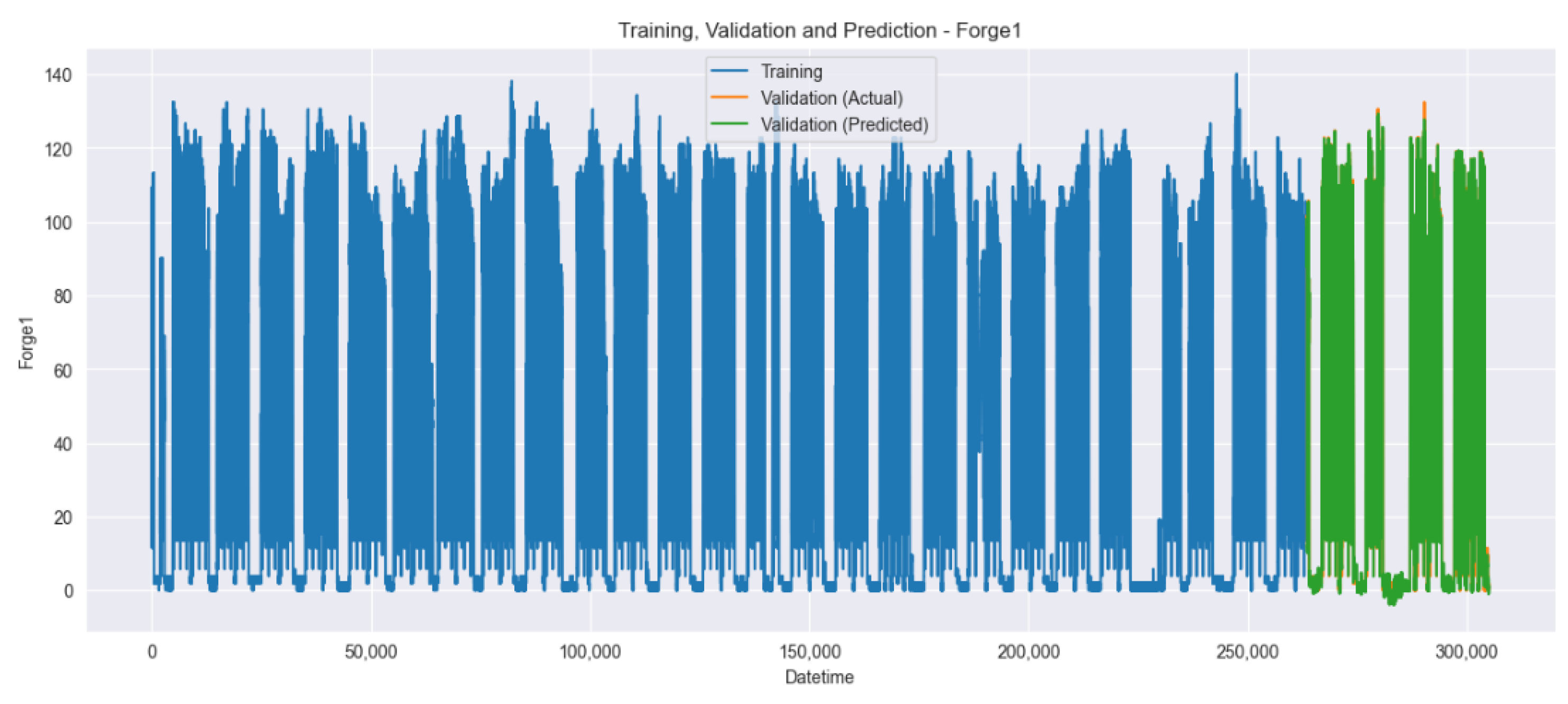
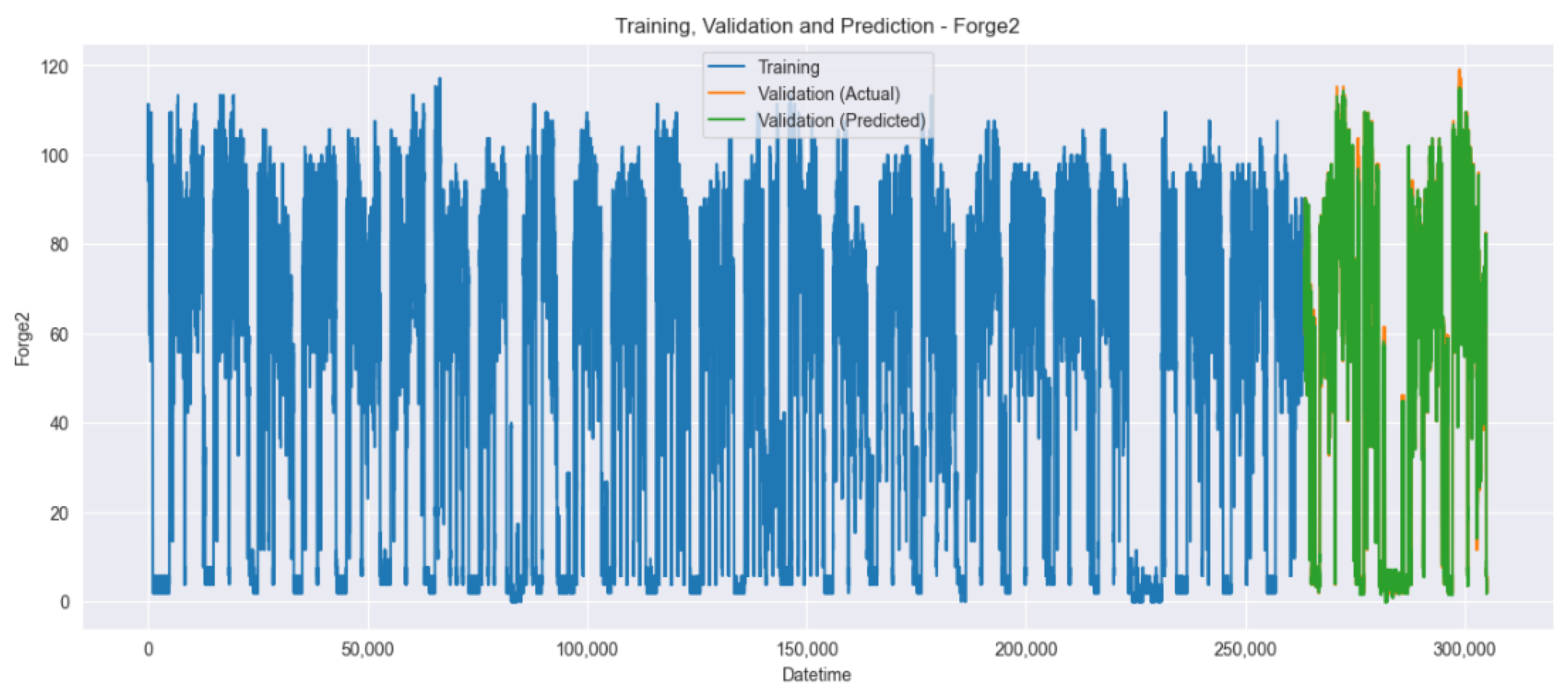
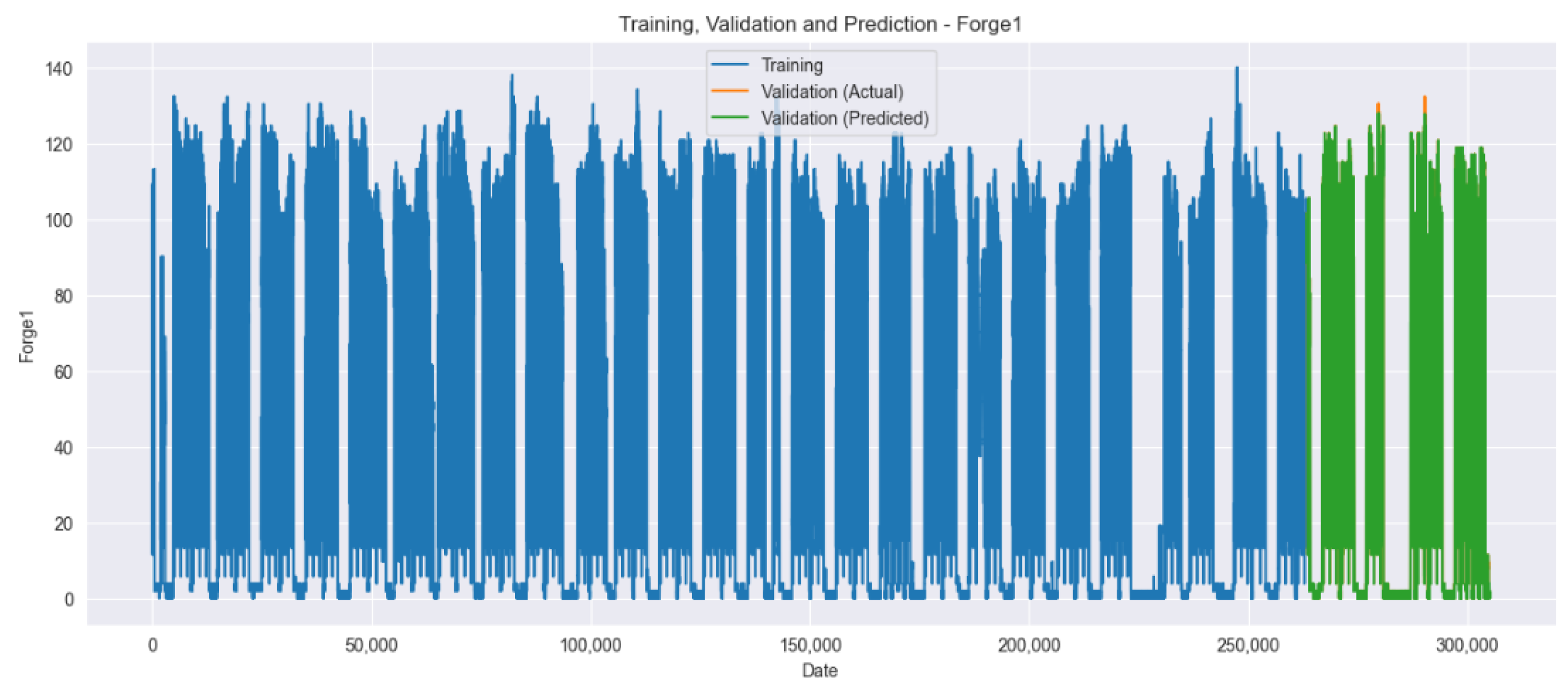
Figure 11 and
Figure 12 visualize the training, validation, and prediction results for the Forge1 and Forge2 datasets before hyperparameter tuning. In both graphs, blue represents the training data, orange represents the actual values of the validation data, and green represents the predicted values of the validation data.
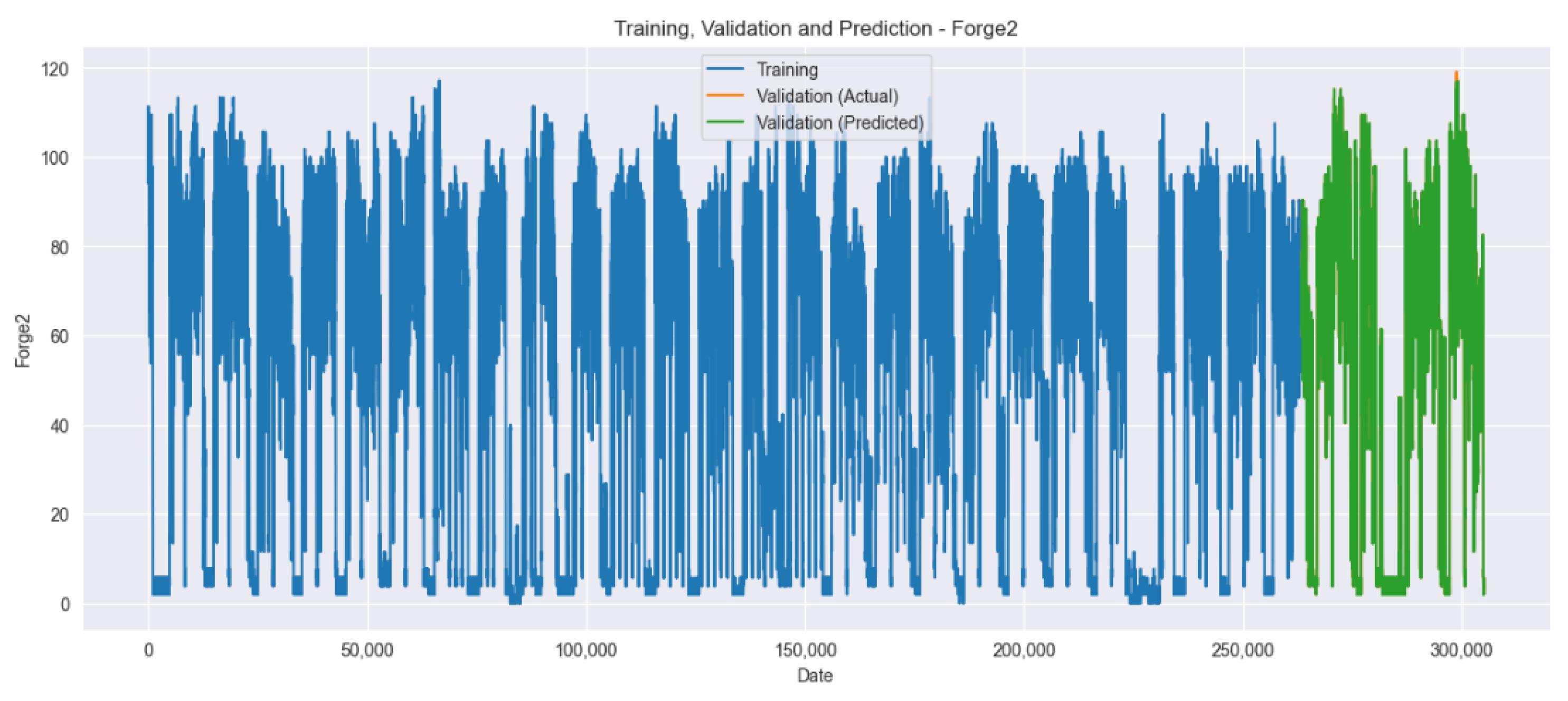
Figure 13 and
Figure 14 visualize the training, validation, and prediction results for the Forge1 and Forge2 datasets after hyperparameter tuning. It is visually confirmed that the prediction accuracy improves when comparing
Figure 11,
Figure 12,
Figure 13 and
Figure 14.
This study used various models to compare and evaluate the predictive performance on the Forge1 and Forge2 datasets. The evaluation metrics used include MAE, MSE,
R2, and SMAPE. The models used in the experiment are LSTM-AE, XGBoost, LightGBM, Prophet, GGNet, and the proposed method (Our method).
Table 5 summarizes the evaluation results for each model.
Our method showed superior performance in the evaluation metrics of MAE, MSE,
R2, and SMAPE compared to other models in
Table 5. Specifically, it recorded very low values for MAE and MSE, indicating that the predicted values are very close to the actual values. Additionally, the
R2 value was high at 0.99, indicating that the model explains the data variability well. On the other hand, the SMAPE metric, which evaluates the relative difference between predicted and actual values, showed relatively lower values compared to other models. This indicates that our method produced relatively small prediction errors for some data points. Overall, the SMAPE value was significantly lower than that of other models, indicating that the relative prediction error was also small. The LightGBM model showed better performance than the Prophet and GGNet model in terms of MAE and MSE, but all three models showed low
R2 values and high SMAPE values, indicating that they did not sufficiently explain the variability of the data and had large relative errors. This suggests that both models did not adequately reflect the characteristics of the Forge1 and Forge2 datasets. Furthermore, we added the training time metric to
Table 5 to highlight the computational efficiency of each model. Our method exhibited a notably shorter training time of 13 s, which is significantly less compared to the 17 min for LSTM-AE, 4 min for XGBoost, 5 min for Prophet, and 19 min for GGNet. This efficiency in training time, combined with superior predictive performance, underscores the practical applicability and robustness of our proposed method in real-world scenarios where timely and accurate predictions are crucial.
We believe that the high accuracy of our model is largely due to the preprocessing steps specifically tailored for LSTM-AE and the extensive hyperparameter tuning that was performed. The preprocessing involves EM-PCA, which efficiently handles missing data and extracts important features, optimizing the input for LSTM-AE. This tailored preprocessing might not be as effective for other models, which could explain their relatively lower performance. Moreover, the hyperparameters for LSTM-AE and our method were fine-tuned through rigorous cross-validation to achieve the best performance. The absence of similar fine-tuning for the other models could be a reason for their lower performance. We acknowledge this as a limitation of our study and propose to include a more balanced preprocessing and hyperparameter tuning strategy for all models in future work to ensure a fair comparison.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}