
InvMOE: MOEs Based Invariant Representation Learning for Fault Detection in Converter Stations

Abstract
:1. Introduction
- We propose InvMOE, a novel fault detection algorithm that combines invariant representation learning and a mixture of experts framework to address the challenges of limited generalization and sparse supervision.
- We introduce a causal-inspired approach for disentangling task-relevant features from environmental noise, enabling robust and reliable fault detection across diverse and unpredictable converter station environments.
- We develop a multi-task training strategy with MOE, which improves model efficiency and effectiveness, particularly in handling tasks with limited data, and demonstrate its superiority through extensive experiments on real-world datasets.
2. Related Works
2.1. Converter Station Fault Detection
2.2. Out-of-Distribution Generalization
2.3. Multi-Task Learning
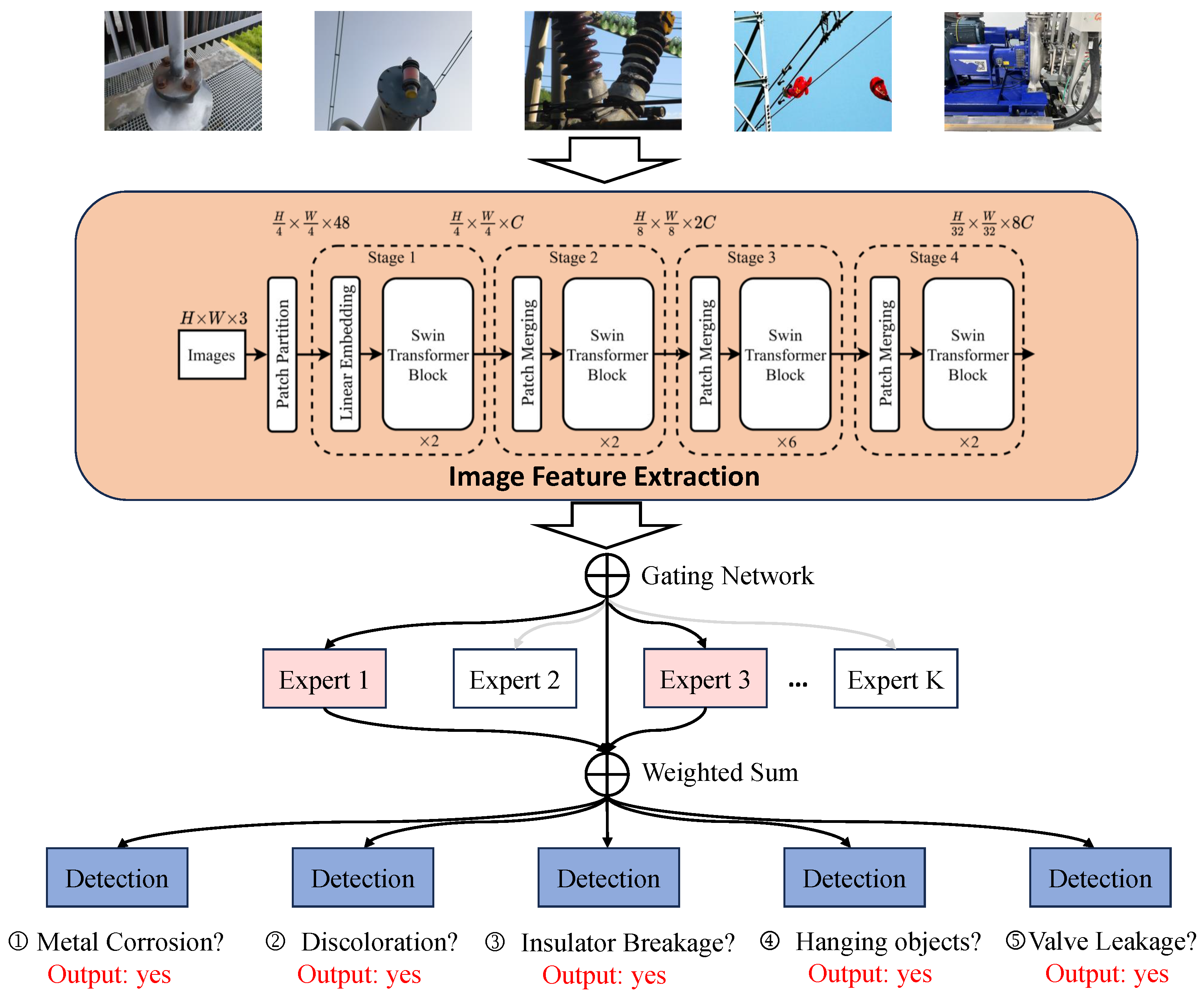
3. The Proposed InvMOE Framework
3.1. Image Feature Extraction
- Patch Tokenization: The input image x is divided into nonoverlapping patches of size . Each patch is flattened into a vector, and a linear embedding layer maps these vectors into a d-dimensional feature space. This produces an initial set of tokens .
- Hierarchical Feature Extraction: The tokenized patches are passed through multiple Transformer layers. Each layer consists of shifted window-based self-attention modules and feedforward networks, enabling efficient computation and the capture of long-range dependencies within the image [26].
- Feature Aggregation: As the processing progresses through hierarchical stages, features are aggregated and downsampled to reduce spatial dimensions while increasing semantic richness. This results in a compact feature vector , encapsulating the key visual information of the input image.
3.2. MOE-Based Multi-Task Learning
3.2.1. Adaptive Expert Routing
- Gating Network: The gating network is responsible for deciding which “expert” should process the input for each task. It operates by taking the input data and assigning them to one or more experts based on the relevance of each expert for a given task. This routing is adaptive, meaning the gating decisions change dynamically based on the input data and task requirements. A detailed working of the gating network is presented as follows: (a) The gating network takes the feature vector of the input data and computes a routing decision using a softmax function, producing a probability distribution over the experts. (b) The network assigns each input to one or more experts depending on the routing probabilities. The experts are chosen dynamically depending on the type of task and the input data.
- Experts: The experts in the framework are specialized subnetworks that are trained to focus on particular tasks. Each “expert” is associated with one or more fault types or specific task requirements. For example, in the case of fault detection, some experts may specialize in detecting electrical faults, while others may specialize in detecting mechanical or thermal faults. A detailed explanation of the experts is presented as follows: (a) Each expert is a neural network that has been fine-tuned to handle specific data patterns or tasks. These experts are trained on task-specific datasets, which could include different fault types or other specialized information relevant to each task. (b) Regarding the relationship between experts, the experts are not isolated. The gating mechanism dynamically routes inputs to the appropriate experts based on their capabilities and relevance to the current task. This allows the model to specialize in different aspects of the task while also facilitating knowledge sharing across the experts.
3.2.2. Multi-Task Learning
3.3. Invariant-Learning-Based Optimization
3.3.1. Causal Framework for Invariance
3.3.2. IRM-Based Regularization
| Algorithm 1 InvMOE framework for fault detection |
|
4. Experimental Results
4.1. Dataset Preprocessing
4.1.1. Data Collection
4.1.2. Data Augmentation
- Random cropping: Randomly cropping regions of the image to simulate variations in object size and position.
- Color jittering: Random adjustments to the image’s brightness, contrast, and saturation to simulate varying lighting conditions.
- Rotation and flipping: Random rotations and horizontal flips to simulate different camera angles.
- Noise injection: Adding random noise to images to simulate real-world disturbances and background complexities.
4.1.3. Normalization and Standardization
4.2. Experimental Settings
4.2.1. Training Setup
- The model was trained using mini-batch gradient descent, with a batch size of 32.
- Early stopping was employed to prevent overfitting, with a patience of 10 epochs. Training stopped if the validation loss did not improve for 10 consecutive epochs.
- The learning rate was initialized at 0.001 and decreased by a factor of 0.1 after every 20 epochs.
- The Adam optimizer was used for model optimization, which adapts the learning rate based on first and second moments of the gradients.
4.2.2. Evaluation Baselines
- KNN: KNN [27] is a simple, yet effective, machine learning algorithm used for classification and regression tasks. It works by identifying the K nearest data points to a given input and assigning a label (in classification) or predicting a value (in regression) based on the majority vote or average of the neighbors. KNN is nonparametric, meaning it makes no assumptions about the underlying data distribution. However, it can be computationally expensive for large datasets, since it requires calculating the distance between the query point and all training samples.
- ResNet: ResNet (Residual Network) [8] is a deep convolutional neural network architecture known for its use of residual connections, which help mitigate the vanishing gradient problem by allowing gradients to flow through the network more effectively. It is particularly effective in image classification tasks and has been widely used in various computer vision applications. ResNet is commonly employed as a baseline model for comparison in tasks requiring deep learning architectures.
- Swin Transformer: The Swin Transformer [26] is a state-of-the-art vision Transformer architecture that uses shifted windows for efficient self-attention and hierarchical feature representation. It overcomes the limitations of traditional Vision Transformers (ViTs) by processing images in smaller, nonoverlapping patches and dynamically adjusting attention regions, making it highly effective for capturing both local and global features. It has shown superior performance in various vision tasks compared to CNN-based architectures.
- IRM (Invariant Risk Minimization): IRM [10] focuses on learning representations that generalize across multiple environments by enforcing invariance in the learned features. In the context of fault detection, this method would remove the multi-task learning component, resulting in a model variant that learns invariant representations across different environmental conditions without task-specific adaptation. This approach helps in addressing environmental variability, but without the benefit of multi-task learning shared across tasks.
- EIIL: The EIIL [20] paradigm is proposed to address the challenges of learning invariant representations across diverse environments. By leveraging environment inference techniques, EIIL aims to improve model robustness and generalization by identifying and utilizing the invariant factors that are critical for learning in real-world, multi-environment settings.
4.2.3. Evaluation Metrics
- Accuracy (ACC): The accuracy of a model is the proportion of correct predictions out of the total number of predictions. It is computed aswhere TP, TN, FP, and FN are the true positive, true negative, false positive, and false negative values, respectively. Accuracy provides a general measure of how well the model is performing across all classes.
- F1-Score: The F1-score is the harmonic mean of precision and recall, providing a balance between the two metrics. It is defined aswhereThe F1-score is especially useful when the dataset is imbalanced, as it accounts for both false positives and false negatives.
4.3. Performance Comparisons with Baselines
- Accuracy Performance: InvMOE consistently outperformed all baseline models across all tasks, achieving the highest accuracy in each task. Notably, InvMOE achieved an accuracy of 97.5% in Task 1 (metal corrosion detection), which was higher than the next best model, IRM (97.0%), and significantly higher than ResNet (94.0%) and Swin Transformer (96.5%). In Task 5 (valve cooling water leakage), InvMOE maintained an impressive accuracy of 88.0%, surpassing all baseline models, with IRM coming in second at 85.5%.
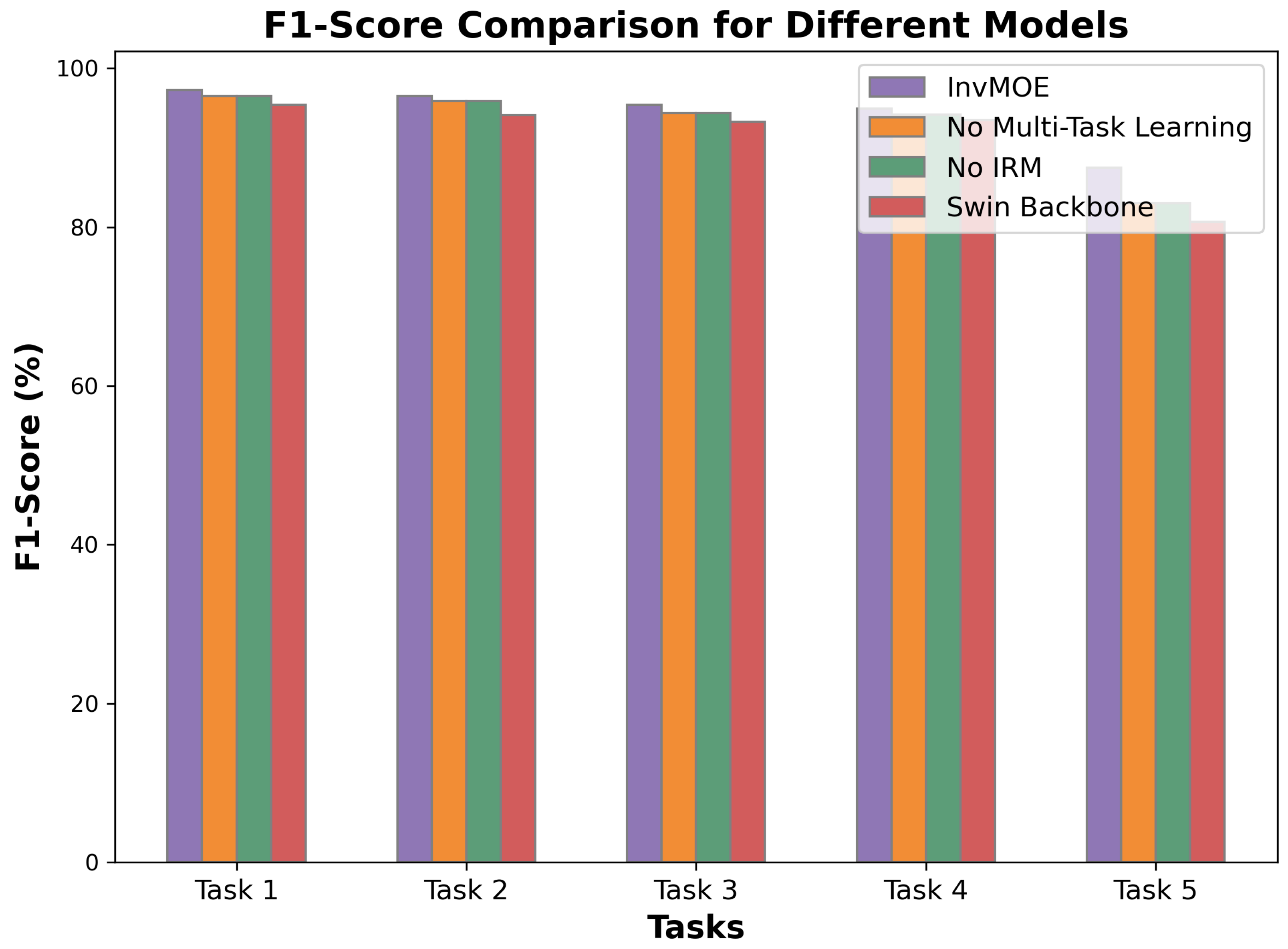
- F1-Score Performance: The trend observed in the accuracy results is reflected in the F1-scores. InvMOE again led with the highest F1-scores across all tasks. For example, in Task 1, InvMOE achieved an F1-score of 97.3%, outperforming IRM (97.1%), Swin Transformer (96.2%), and ResNet (93.5%). In Task 5, InvMOE maintained its superior performance with an F1-score of 87.5%, which was considerably higher than IRM (82.5%) and Swin Transformer (80.1%).
- Comparison to Baselines: As a classic machine learning method, KNN demonstrated strong classification performance on the first four tasks. However, it did not perform satisfactorily on the last task. This was primarily due to the lack of sufficient training samples, which hindered the model’s ability to generalize effectively in more complex scenarios. In addition, ResNet, while a strong baseline, generally fell behind both Swin Transformer and IRM in terms of both accuracy and F1-score. This is expected given that ResNet is a convolutional neural network, which may not capture the fine-grained relationships and long-range dependencies in the data as effectively as Transformer-based models. Swin Transformer and IRM performed similarly on most tasks, with IRM slightly outperforming Swin Transformer. This indicates that enforcing invariance across different environments (as done by IRM) offered some benefits over the self-attention mechanism used in Swin Transformer, particularly in tasks with varied environmental conditions. EIIL further inferred the environment labels considering the reality that there are potential unknown test scenarios, and it showed slight improvements over IRM in most cases. Overall, InvMOE demonstrated the most robust performance, suggesting that the integration of multi-task learning and the model’s ability to handle diverse fault detection scenarios contribute to its superior results. The accuracy and F1-score results for the different variants of the InvMOE model are summarized in Figure 3 and Figure 4.
5. Ablation Study
5.1. Description of Each Component of InvMOE
- InvMOE (full model): The complete model, which integrates multi-task learning, IRM, and the Swin Transformer backbone, as originally designed.
- No Multi-Task Learning: In this variant, the multi-task learning component was removed, and the model was instead trained in a traditional single-task learning setup. This isolated the contribution of task sharing and mutual information extraction.
- No IRM: This variant removed the IRM mechanism, allowing the model to train without the additional regularization imposed by Invariant Risk Minimization. This tested the hypothesis that mitigating environment variability is essential for consistent performance.
- Swin Transformer Backbone: In this variant, we maintained the multi-task learning and IRM components but replaced the Swin Transformer backbone with a simpler, more conventional architecture. This helped evaluate the importance of the Swin Transformer’s advanced self-attention and hierarchical feature extraction capabilities.
5.2. Ablation Analysis of InvMOE
- Impact of Invariant Risk Minimization (IRM): The removal of the IRM mechanism resulted in a noticeable drop in performance—again, about 1–2% in the accuracy and F1-score. This decline indicates the significance of the IRM component, which helps to neutralize environmental variations and ensures that the model learns stable representations that generalize across different environments. Without IRM, the model became more sensitive to environmental noise, leading to fluctuations in its performance. This reinforces the notion that invariant learning is key to achieving consistency and reliability in real-world applications, where environmental conditions can vary dramatically.
- Impact of Swin Transformer Backbone: The most striking performance drop occurred when the Swin Transformer backbone was replaced by a simpler architecture. The accuracy and F1-score both showed substantial reductions, particularly in tasks that required capturing long-range dependencies or complex contextual relationships. This highlights the power of the Swin Transformer’s self-attention mechanism, which allows the model to capture intricate dependencies between distant features. The hierarchical structure of the Swin Transformer further enhances its ability to extract meaningful features at multiple scales, which is particularly beneficial for tasks involving high-dimensional or sequential data. The performance drop in this variant reinforces the idea that state-of-the-art backbones, like the Swin Transformer, offer significant advantages over simpler models in terms of capturing fine-grained patterns and improving overall model performance.
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, S.; Wang, X.; Ren, X.; Wang, Y.; Xu, S.; Ge, Y.; He, J. Fault Diagnosis Method for Converter Stations Based on Fault Area Identification and Evidence Information Fusion. Sensors 2024, 24, 7321. [Google Scholar] [CrossRef] [PubMed]
- Jovcic, D.; Ahmed, K. High Voltage Direct Current (HVDC) Transmission Systems; Wiley: Hoboken, NJ, USA, 2015. [Google Scholar]
- Adamson, C.; Hingorani, N.G. High-Voltage Direct-Current Power Transmission; Garraway: London, UK, 1960. [Google Scholar]
- Li, R.; Xu, L.; Yao, L. DC fault detection and location in meshed multiterminal HVDC systems based on DC reactor voltage change rate. IEEE Trans. Power Deliv. 2016, 32, 1516–1526. [Google Scholar] [CrossRef]
- Bu, S.; Liu, Z.; Shi, Y.; Sun, Y. Feature-based fault detection in converter stations. IEEE Trans. Ind. Electron. 2017, 64, 7800–7808. [Google Scholar]
- Sun, C.; Zhang, X.; Li, H.; Chen, W. Hybrid methods for converter station monitoring. Energy Rep. 2018, 4, 202–209. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the NeurIPS, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Gulrajani, I.; Lopez-Paz, D. In search of lost domain generalization. In Proceedings of the International Conference on Learning Representations ICLR, Virtual Event, 3–7 May 2021. [Google Scholar]
- Arjovsky, M.; Bottou, L.; Gulrajani, I. Invariant Risk Minimization. arXiv 2019, arXiv:1907.02893. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the NeurIPS, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. Image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations ICLR, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Rojas-Carulla, M.; Schölkopf, B.; Turner, R.; Peters, J. Invariant models for causal transfer learning. J. Mach. Learn. Res. 2018, 19, 1–34. [Google Scholar]
- Li, Z.; Wang, Y.; Zhang, Q.; Chen, L. Deep learning-based fault diagnosis in HVDC systems. IEEE Trans. Power Electron. 2019, 34, 10245–10256. [Google Scholar]
- Mu, D.; Lin, S.; Zhang, H.; Zheng, T. A novel fault identification method for HVDC converter station Section based on energy relative entropy. IEEE Trans. Instrum. Meas. 2022, 71, 3507910. [Google Scholar] [CrossRef]
- Liu, W.; Chen, X.; Li, J.; Yang, H. Image-based fault detection in converter stations using deep learning. IEEE Access 2020, 8, 123456–123467. [Google Scholar]
- Li, Y.; Zhang, M.; Zhou, P.; Wu, F. Advanced deep learning models for converter station fault detection. IEEE Trans. Ind. Inform. 2021, 17, 4567–4578. [Google Scholar]
- Peng, C.; Zhang, Y.; Li, X.; Wang, J. Out-of-Distribution Generalization: A Survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar]
- Pearl, J.; Glymour, M.; Jewell, N.P. Causal Inference in Statistics: A Primer; Wiley: Hoboken, NJ, USA, 2016. [Google Scholar]
- Creager, E.; Jacobsen, J.H.; Zemel, R. Environment inference for invariant learning. In Proceedings of the 38th International Conference on Machine Learning, ICML, PMLR, Virtual, 18–24 July 2021; pp. 2189–2200. [Google Scholar]
- Krueger, D.; Caballero, E.; Jacobsen, J.H.; Zhang, A.; Binas, J.; Zhang, D.; Le Priol, R.; Courville, A. Out-of-distribution generalization via risk extrapolation (rex). In Proceedings of the 38th International Conference on Machine Learning, ICML, PMLR, Virtual, 18–24 July 2021; pp. 5815–5826. [Google Scholar]
- Li, H.; Zhang, Z.; Wang, X.; Zhu, W. Learning invariant graph representations for out-of-distribution generalization. NeurIPS 2022, 35, 11828–11841. [Google Scholar]
- Ajra, Y.; Hoblos, G.; Al Sheikh, H.; Moubayed, N. A Literature Review of Fault Detection and Diagnostic Methods in Three-Phase Voltage-Source Inverters. Machines 2024, 12, 631. [Google Scholar] [CrossRef]
- Wu, F.; Chen, K.; Qiu, G.; Zhou, W. Robust Open Circuit Fault Diagnosis Method for Converter Using Automatic Feature Extraction and Random Forests Considering Nonstationary Influence. IEEE Trans. Ind. Electron. 2024, 71, 13263–13273. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. A survey on multi-task learning. IEEE Trans. Knowl. Data Eng. 2021, 34, 5586–5609. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Cover, T.; Hart, P.E. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Number of Images |
|---|---|
| Task 1: Metal Corrosion | 500 |
| Task 2: Silica Gel Discoloration | 500 |
| Task 3: Insulator Breakage | 500 |
| Task 4: Overhead Suspension | 500 |
| Task 5: Valve Cooling Water Leak | 100 |
| Model | Task 1 | Task 2 | Task 3 | Task 4 | Task 5 |
|---|---|---|---|---|---|
| KNN | 92.5 | 90.9 | 88.8 | 89.6 | 60.7 |
| ResNet | 94.0 | 93.2 | 91.5 | 92.0 | 80.0 |
| Swin Transformer | 96.5 | 95.3 | 94.1 | 94.5 | 84.2 |
| IRM | 97.0 | 96.5 | 95.0 | 94.8 | 85.5 |
| EIIL | 96.8 | 97.1 | 95.2 | 94.9 | 86.7 |
| InvMOE | 97.5 | 96.8 | 95.6 | 95.1 | 88.0 |
| Model | Task 1 | Task 2 | Task 3 | Task 4 | Task 5 |
|---|---|---|---|---|---|
| KNN | 91.7 | 89.6 | 89.5 | 87.8 | 58.3 |
| ResNet | 93.5 | 92.0 | 90.3 | 90.8 | 75.2 |
| Swin Transformer | 96.2 | 94.4 | 93.0 | 93.2 | 80.1 |
| IRM | 97.1 | 96.4 | 94.9 | 94.7 | 82.5 |
| EIIL | 97.0 | 96.9 | 95.1 | 94.7 | 86.9 |
| InvMOE | 97.3 | 96.5 | 95.4 | 94.9 | 87.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, H.; Li, S.; Li, H.; Huang, J.; Qiao, Z.; Wang, J.; Tian, X. InvMOE: MOEs Based Invariant Representation Learning for Fault Detection in Converter Stations. Energies 2025, 18, 1783. https://doi.org/10.3390/en18071783
Sun H, Li S, Li H, Huang J, Qiao Z, Wang J, Tian X. InvMOE: MOEs Based Invariant Representation Learning for Fault Detection in Converter Stations. Energies. 2025; 18(7):1783. https://doi.org/10.3390/en18071783
Chicago/Turabian StyleSun, Hao, Shaosen Li, Hao Li, Jianxiang Huang, Zhuqiao Qiao, Jialei Wang, and Xincui Tian. 2025. "InvMOE: MOEs Based Invariant Representation Learning for Fault Detection in Converter Stations" Energies 18, no. 7: 1783. https://doi.org/10.3390/en18071783
APA StyleSun, H., Li, S., Li, H., Huang, J., Qiao, Z., Wang, J., & Tian, X. (2025). InvMOE: MOEs Based Invariant Representation Learning for Fault Detection in Converter Stations. Energies, 18(7), 1783. https://doi.org/10.3390/en18071783