
Modeling of Compressive Strength of Self-Compacting Rubberized Concrete Using Machine Learning





Abstract
:1. Introduction
2. Methods
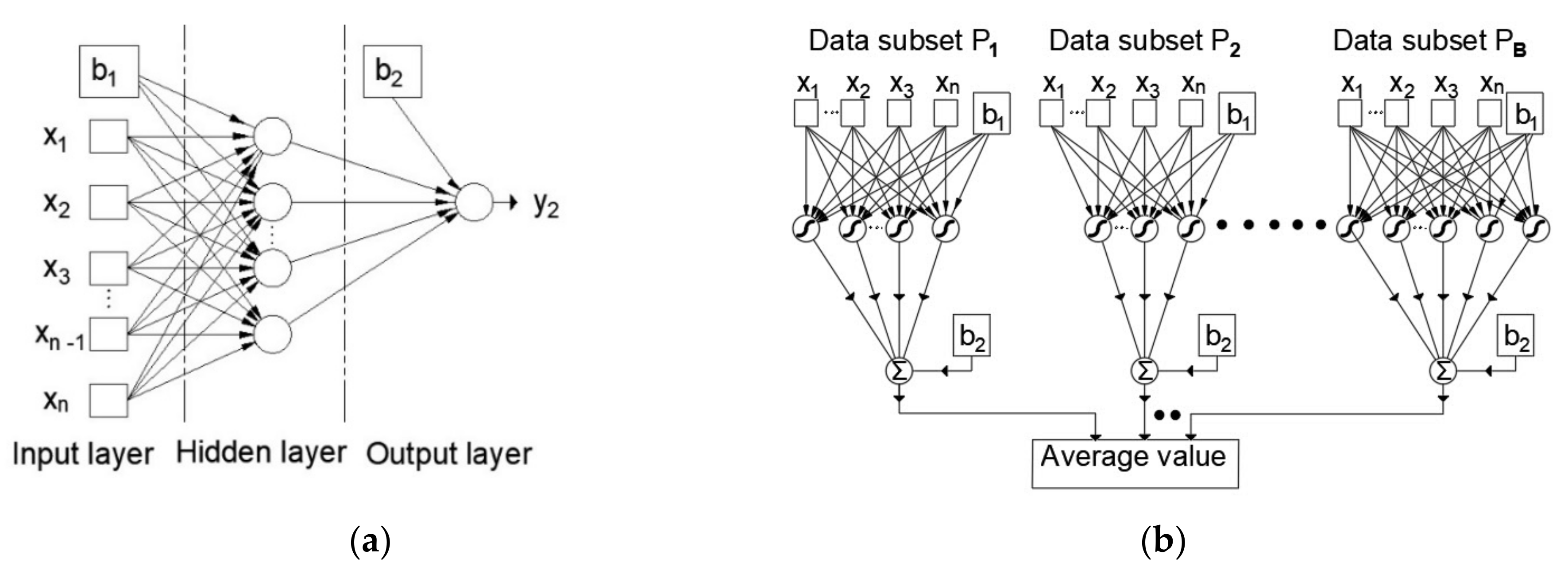
2.1. Multilayered Perceptron Artificial Neural Network (MLP-ANN)
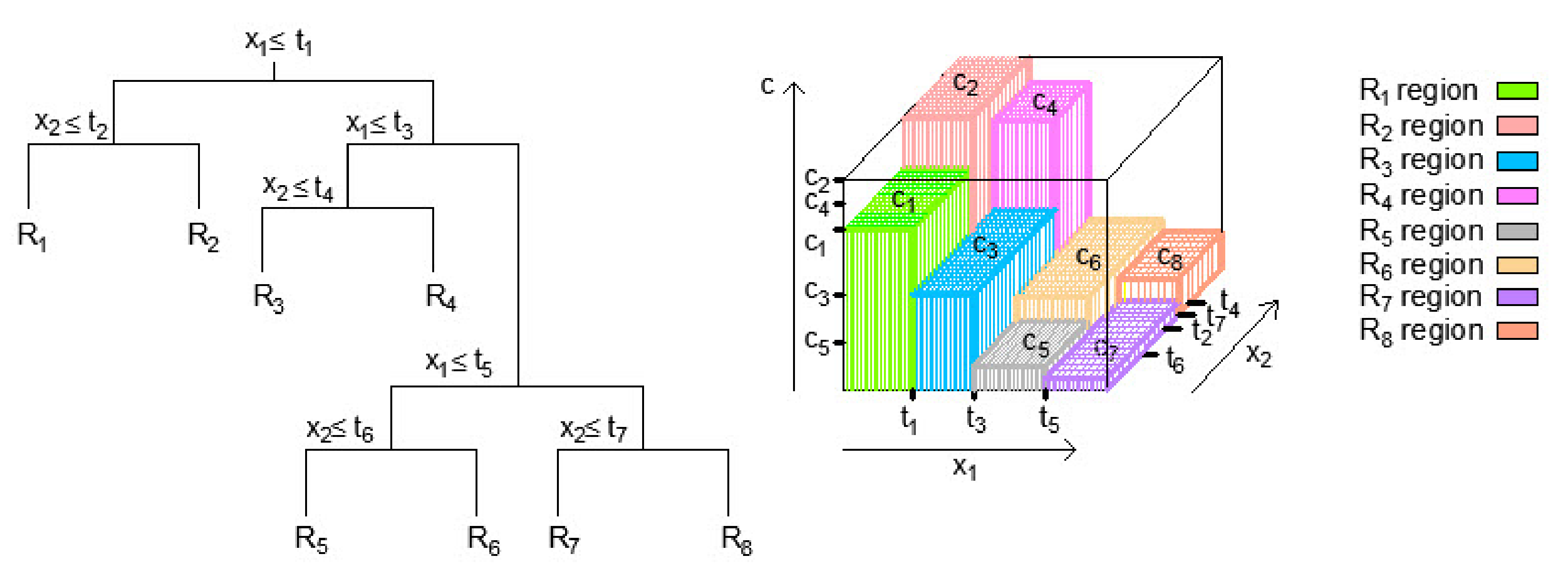
2.2. Regression Tree Ensembles
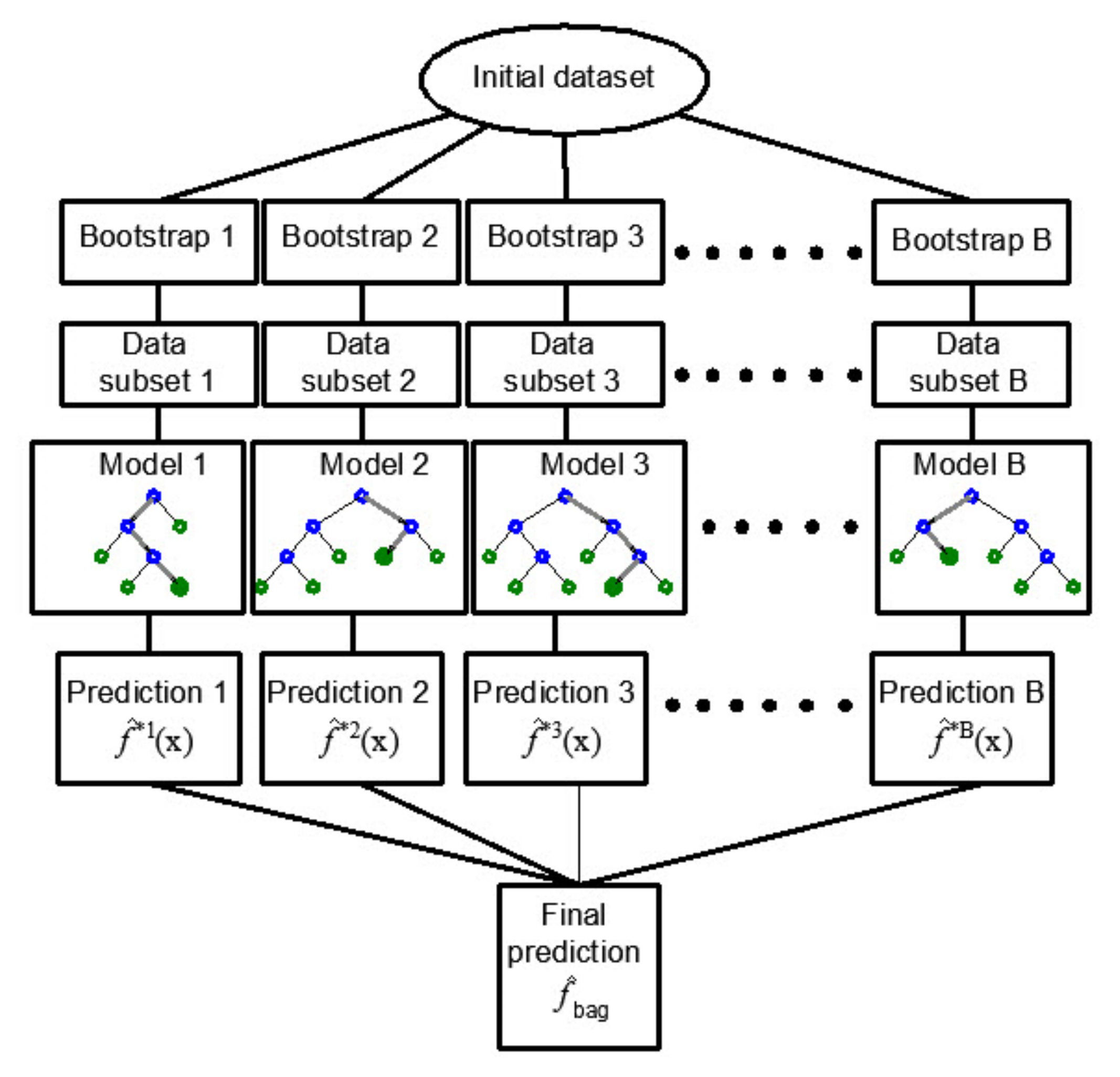
2.2.1. Bagging
2.2.2. Random Forests
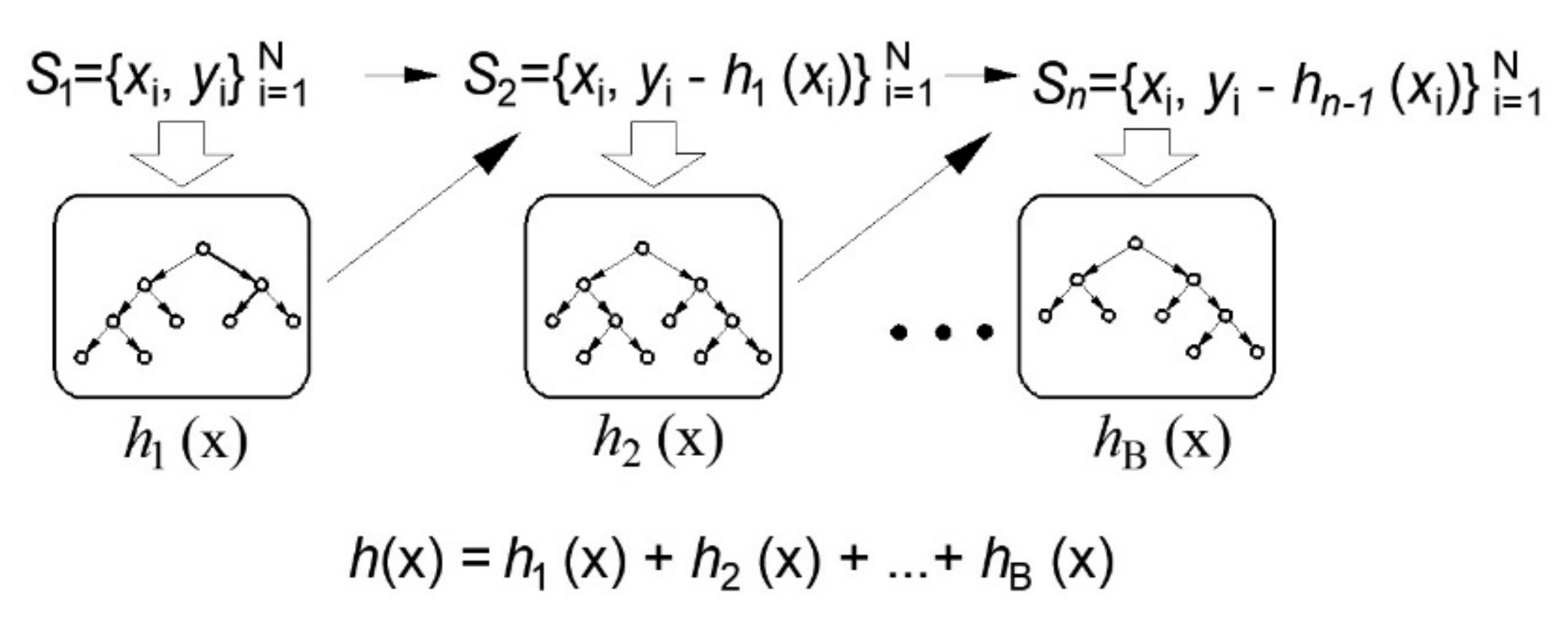
2.2.3. Boosting Trees
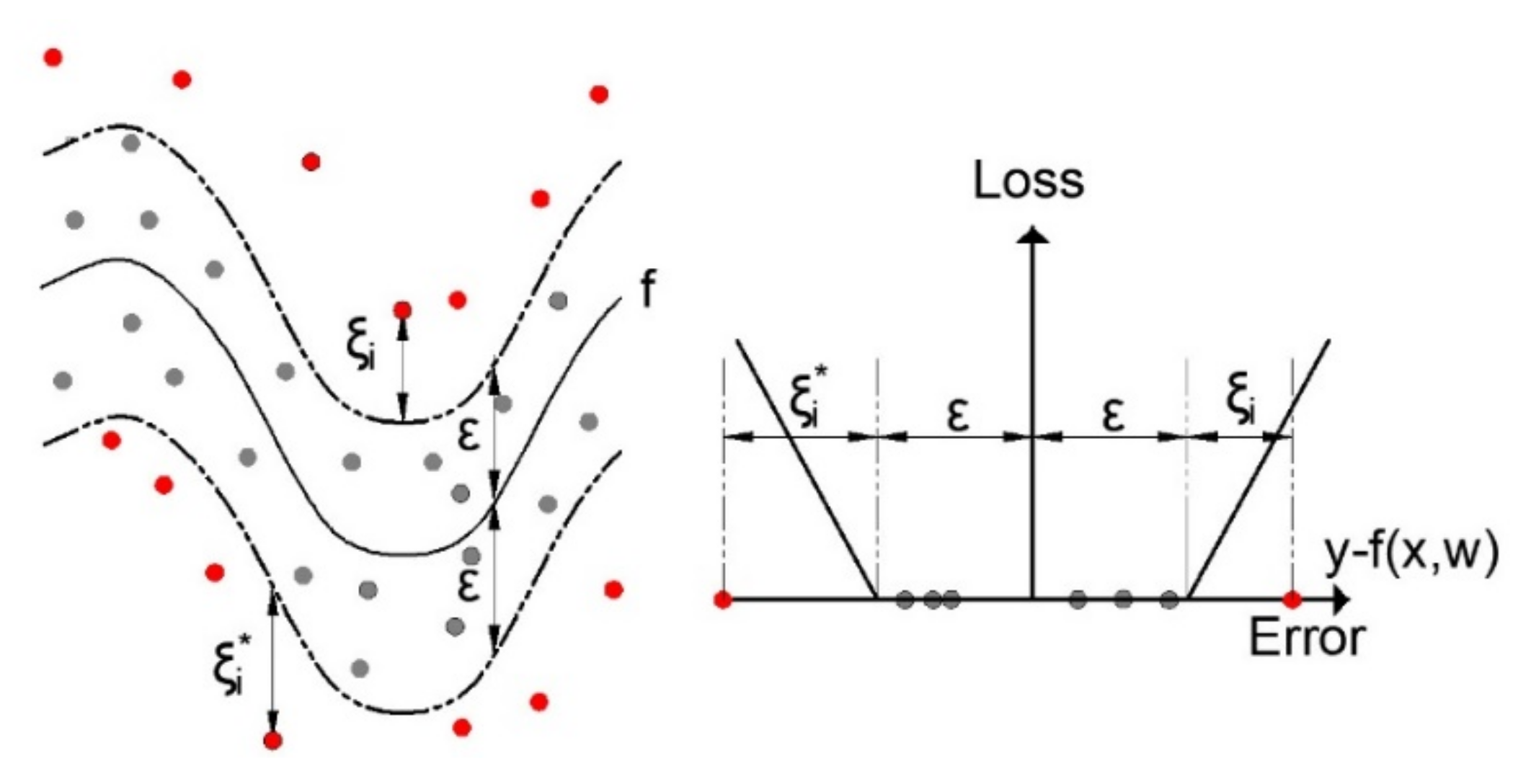
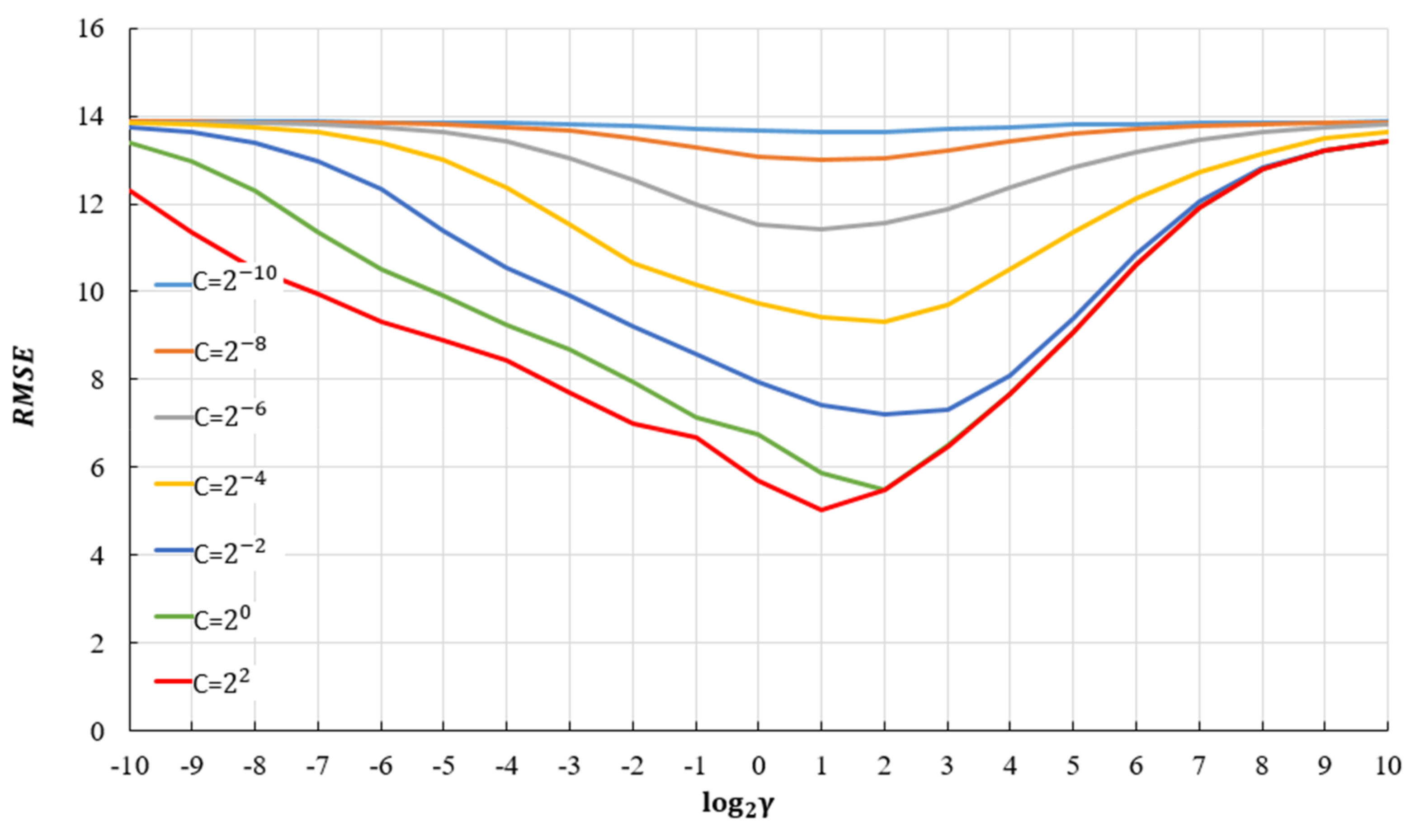
2.3. Support Vector Regression (SVR)
2.4. Gaussian Proces Regression
3. Evaluation and Performance Measures
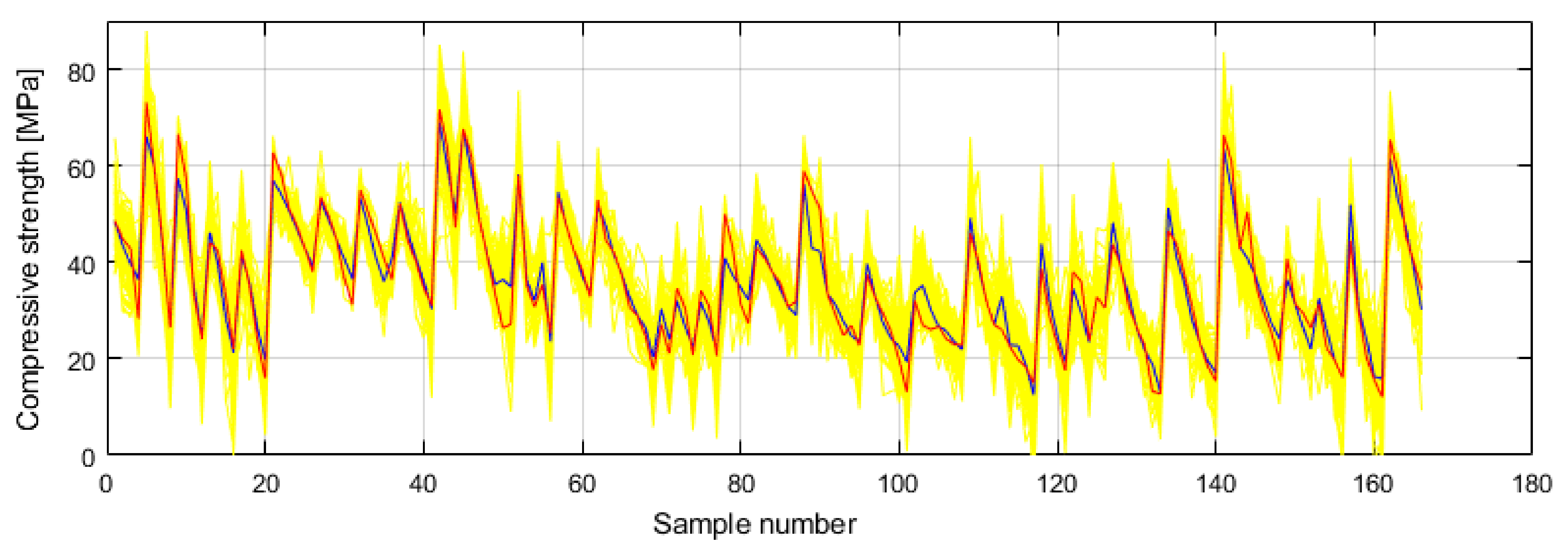
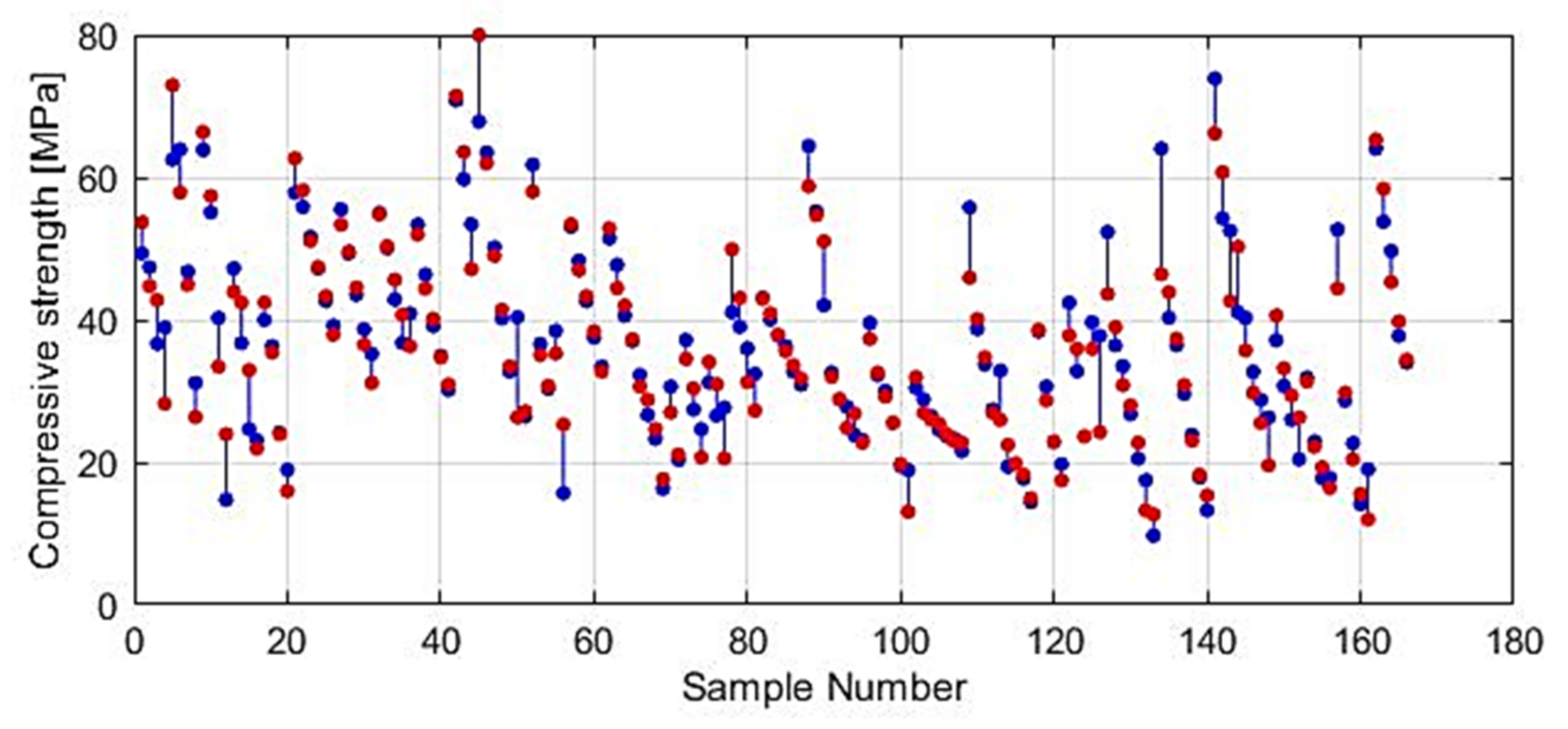
4. Dataset
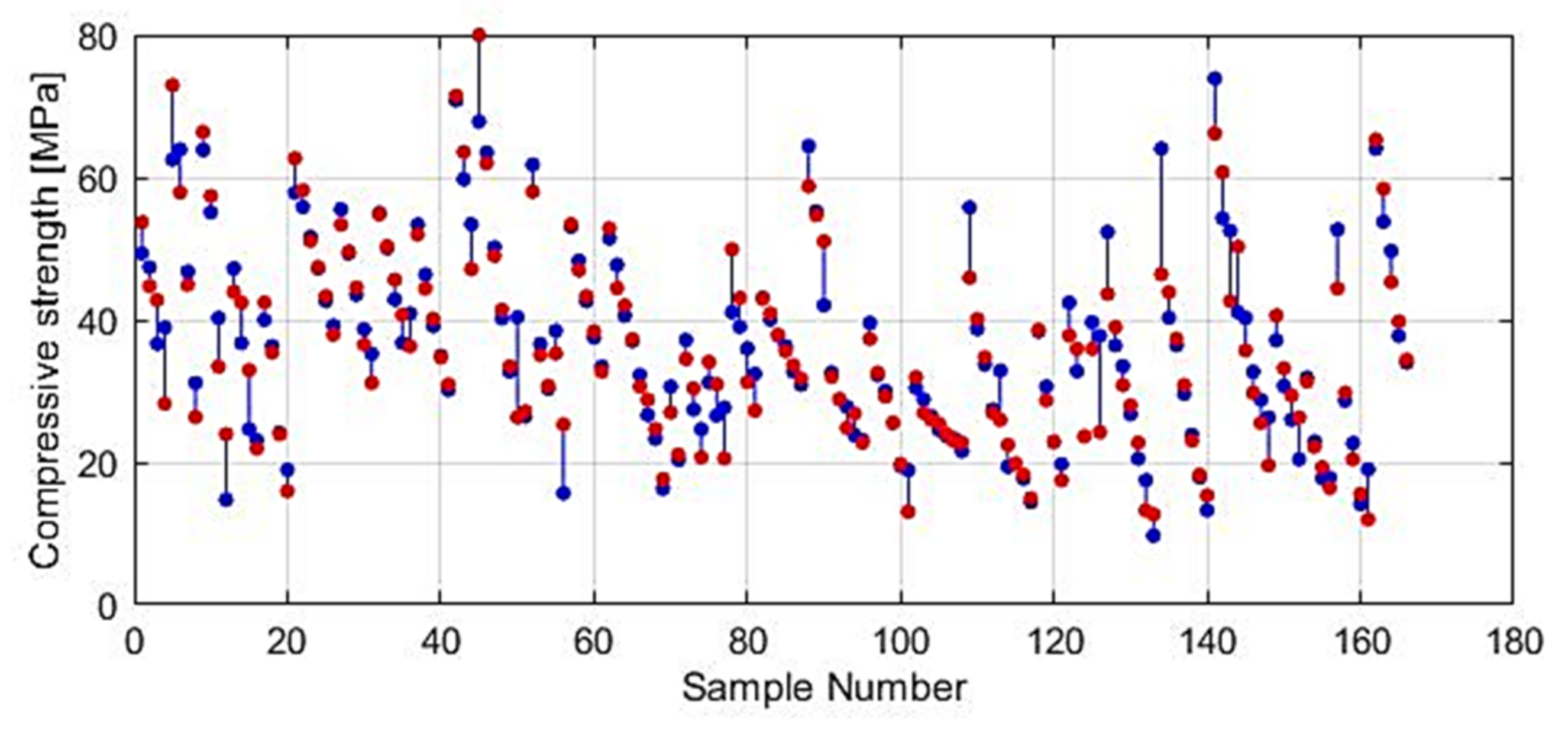
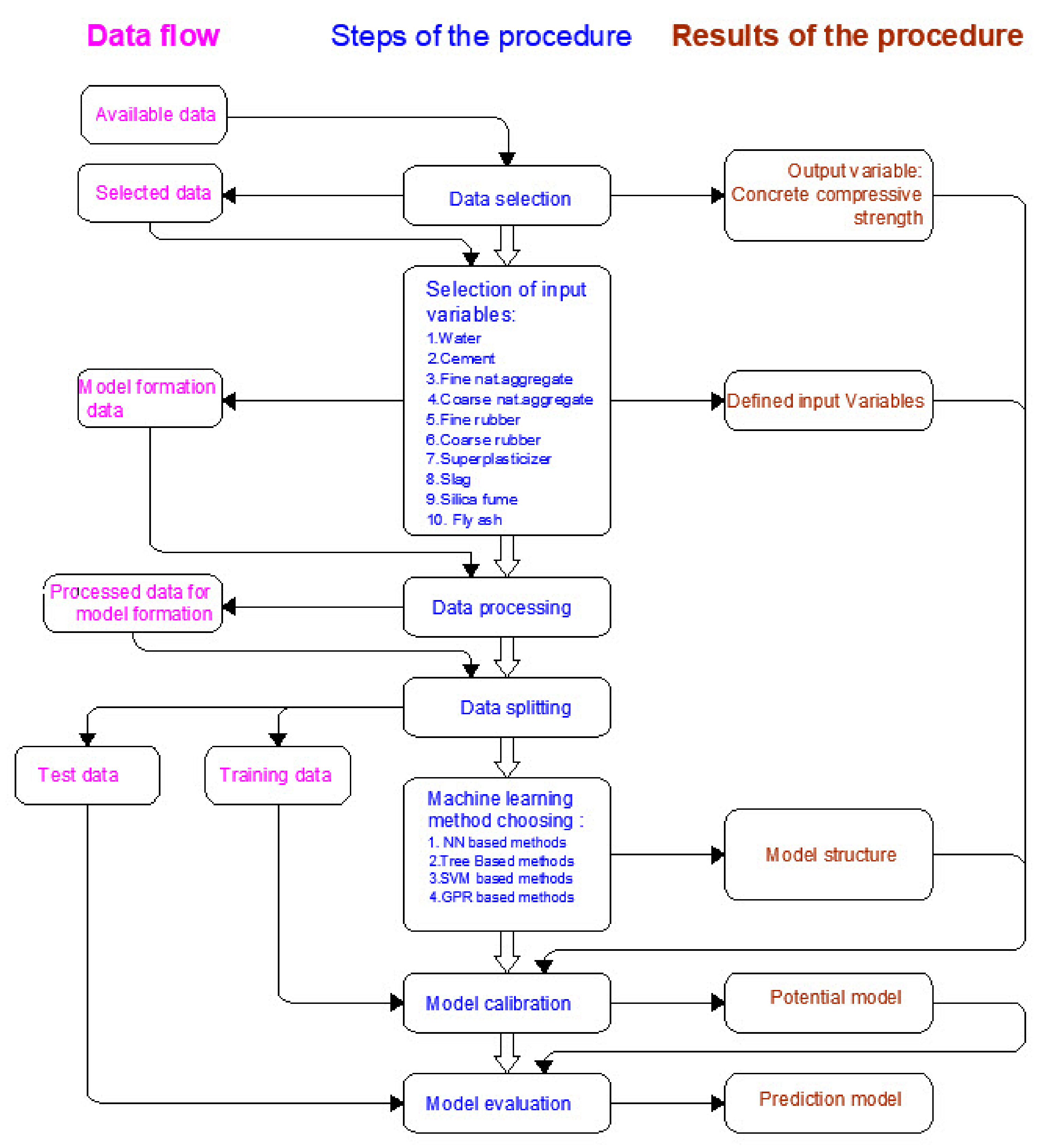
5. Results and Discussion
- Bagging method (TreeBagger),
- RF method,
- Boosted Trees method.
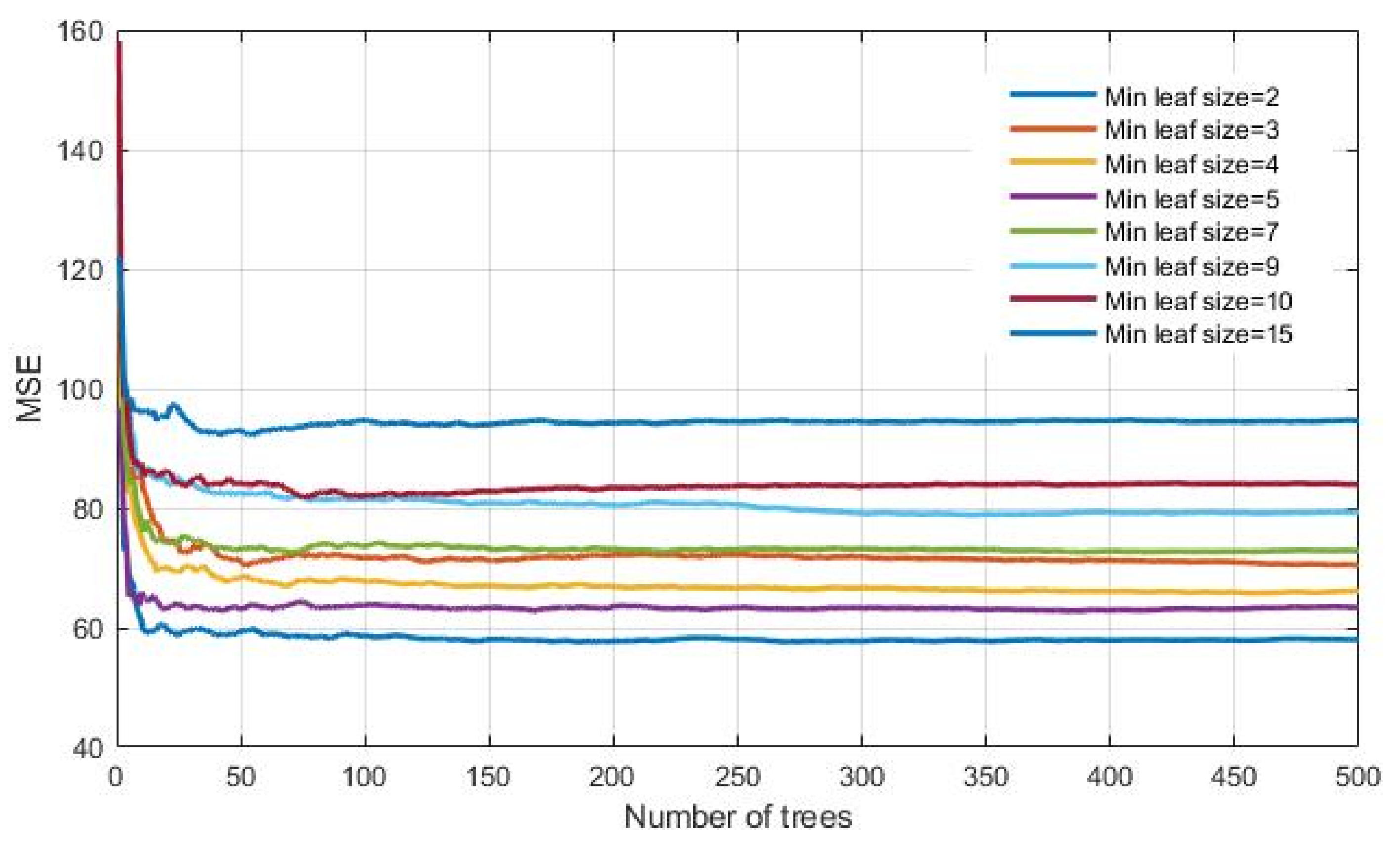
- Number of generated trees B. Within this analysis, the maximum number of generated trees was limited to 500.
- The minimum number of data or samples assigned to the leaf (min leaf size) within the tree. Values from 2 to 15 samples with a step size of 1 per tree leaf were considered.
- Number of generated trees B. Within this analysis, the maximum number of generated trees was limited to 500.
- The minimum number of data or samples assigned to a leaf (min leaf size) within a tree. Values from 2 to 10 samples per tree leaf were considered.
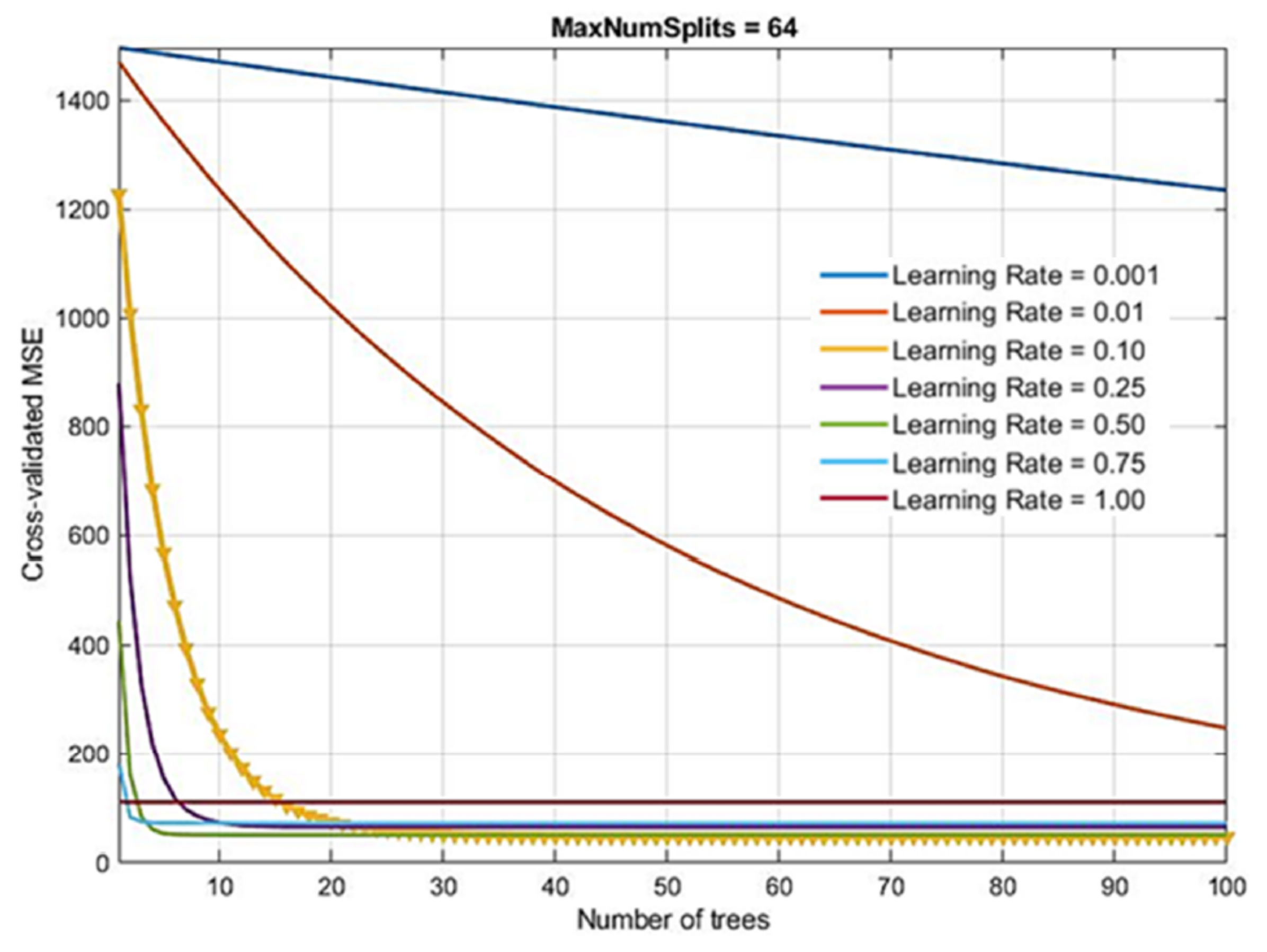
- Number of generated trees B. With the Gradient Boosting method, there is a possibility of overtraining the model when forming too many trees. Due to the large number of analyzed models in the research, the number of base models within the ensemble was limited to a maximum of 100.
- Learning rate λ. This parameter determines the training speed of the model. The paper investigates a number of values, as follows: 0.001; 0.01; 0.1; 0.25; 0.5; 0.75 and 1.0.
- Number of splits in the tree d. Models of trees with a maximum number of splits of 20 = 1, 21, 22, 23, 24, 25, 26, 27 = 128 were generated.
- Model where variable 8 is excluded as less relevant (slag),
- A model that includes all variables.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yildirim, S.T.; Duygun, N.P. Mechanical and physical performance of concrete including waste electrical cable rubber. IOP Conf. Ser. Mater. Sci. Eng. 2017, 245, 022054. [Google Scholar] [CrossRef]
- Hadzima-Nyarko, M.; Nyarko, E.K.; Djikanovic, D.; Brankovic, G. Microstructural and mechanical characteristics of self-compacting concrete with waste rubber. Struct. Eng. Mech. 2021, 78, 175–186. [Google Scholar] [CrossRef]
- Alaloul, W.S.; Musarat, M.A.; Haruna, S.; Law, K.; Tayeh, B.A.; Rafiq, W.; Ayub, S. Mechanical properties of silica fume modified high-volume fly ash rubberized self-compacting concrete. Sustainability 2021, 13, 5571. [Google Scholar] [CrossRef]
- Eurocode 2: Design of Concrete Structures—Part 1-1: General Rules and Rules for Buildings; EN 1992-1-1:2004 1 AC:2010; British Standards Institution: London, UK, 1992.
- ACI COMMITTEE 209. Creep Shrinkage Temperature in Concrete Structures; American Concrete Institute: Detroit, MI, USA, 2008; pp. 258–269. [Google Scholar]
- Harirchian, E.; Kumari, V.; Jadhav, K.; Raj Das, R.; Rasulzade, S.; Lahmer, T. A machine learning framework for assessing seismic hazard safety of reinforced concrete buildings. Appl. Sci. 2020, 10, 7153. [Google Scholar] [CrossRef]
- Martínez-Álvarez, F.; Schmutz, A.; Asencio-Cortés, G.; Jacques, J. A novel hybrid algorithm to forecast functional time series based on pattern sequence similarity with application to electricity demand. Energies 2019, 12, 94. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, M.; Hu, J.-L.; Hadzima-Nyarko, M.; Ahmad, F.; Tang, X.-W.; Rahman, Z.U.; Nawaz, A.; Abrar, M. Rockburst hazard prediction in underground projects using two intelligent classification techniques: A comparative study. Symmetry 2021, 13, 632. [Google Scholar] [CrossRef]
- Zhu, S.; Lu, H.; Ptak, M.; Dai, J.; Ji, Q. Lake water-level fluctuation forecasting using machine learning models: A systematic review. Environ. Sci. Pollut. Res. 2020, 27, 44807–44819. [Google Scholar] [CrossRef] [PubMed]
- Naderpour, H.; Mirrashid, M. Proposed soft computing models for moment capacity prediction of reinforced concrete columns. Soft Comput. 2020, 24, 11715–11729. [Google Scholar] [CrossRef]
- Lin, C.-J.; Wu, N.-J. An ANN model for predicting the compressive strength of concrete. Appl. Sci. 2021, 11, 3798. [Google Scholar] [CrossRef]
- Ahmad, M.; Hu, J.-L.; Ahmad, F.; Tang, X.-W.; Amjad, M.; Iqbal, M.J.; Asim, M.; Farooq, A. Supervised learning methods for modeling concrete compressive strength prediction at high temperature. Materials 2021, 14, 1983. [Google Scholar] [CrossRef]
- Aalimahmoody, N.; Bedon, C.; Hasanzadeh-Inanlou, N.; Hasanzade-Inallu, A.; Nikoo, M. BAT algorithm-based ANN to predict the compressive strength of concrete—A comparative study. Infrastructures 2021, 6, 80. [Google Scholar] [CrossRef]
- Sadowski, L.; Piechowka-Mielnik, M.; Widziszowski, T.; Gardynik, A.; Mackiewicz, S. Hybrid ultrasonic-neural prediction of the compressive strength of environmentally friendly concrete screeds with high volume of waste quartz mineral dust. J. Clean. Prod. 2019, 212, 727–740. [Google Scholar] [CrossRef]
- Nikoo, M.; Moghadam, F.T.; Sadowski, L. Prediction of concrete compressive strength by evolutionary artificial neural networks. Adv. Mater. Sci. Eng. 2015, 2015, 849126. [Google Scholar] [CrossRef]
- Hadzima-Nyarko, M.; Nyarko, E.K.; Ademović, N.; Miličević, I.; Kalman Šipoš, T. Modelling the influence of waste rubber on compressive strength of concrete by artificial neural networks. Materials 2019, 12, 561. [Google Scholar] [CrossRef] [Green Version]
- Diaconescu, R.-M.; Barbuta, M.; Harja, M. Prediction of properties of polymer concrete composite with tire rubber using neural networks. Mater. Sci. Eng. B 2013, 178, 1259–1267. [Google Scholar] [CrossRef]
- Abdollahzadeh, A.; Masoudnia, R.; Aghababaei, S. Predict strength of rubberized concrete using artificial neural network. WSEAS Trans. Comput. 2011, 2, 31–40. [Google Scholar]
- Topcu, I.B.; Sarıdemir, M. Prediction of rubberized concrete properties using artificial neural network and fuzzy logic. Constr. Build. Mater. 2008, 22, 532–540. [Google Scholar] [CrossRef] [Green Version]
- Gesoglu, M.; Guneyisi, E.; Ozturan, T.; Ozbay, E. Modeling the mechanical properties of rubberized concretes by neural network and genetic programming. Mater. Struct. 2010, 43, 31–45. [Google Scholar] [CrossRef]
- El-Khoja, A.M.N.; Ashour, A.F.; Abdalhmid, J.; Dai, X.; Khan, A. Prediction of rubberised concrete strength by using artificial neural networks (version 10009743). Int. J. Struct. Constr. Eng. 2018, 12. [Google Scholar] [CrossRef]
- Hadzima-Nyarko, M.; Nyarko, E.K.; Lu, H.; Zhu, S. Machine learning approaches for estimation of compressive strength of concrete. Eur. Phys. J. Plus 2020, 135, 682. [Google Scholar] [CrossRef]
- Gregori, A.; Castoro, C.; Venkiteela, G. Predicting the compressive strength of rubberized concrete using artificial intelligence methods. Sustainability 2021, 13, 7729. [Google Scholar] [CrossRef]
- Dat, L.T.M.; Dmitrieva, T.L.; Duong, V.N.; Canh, D.T.N. An artificial intelligence approach for predicting compressive strength of eco-friendly concrete containing waste tire rubber. IOP Conf. Ser. Earth Environ. Sci. 2020, 612, 012029. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, J.; Sresakoolchai, J.; Kaewunruen, S. Machine learning aided design and prediction of environmentally friendly rubberised concrete. Sustainability 2021, 13, 1691. [Google Scholar] [CrossRef]
- Sun, Y.; Li, G.; Zhang, J.; Qian, D. Prediction of the strength of rubberized concrete by an evolved random forest model. Adv. Civ. Eng. 2019, 2019, 5198583. [Google Scholar] [CrossRef] [Green Version]
- Bachir, R.; Mohammed, A.M.S.; Habibm, T. Using artificial neural networks approach to estimate compressive strength for rubberized concrete. Period. Polytech. Civ. Eng. 2018, 62, 858–865. [Google Scholar] [CrossRef] [Green Version]
- Cheng, M.-Y.; Hoang, N.-D. A self-adaptive fuzzy inference model based on least squares svm for estimating compressive strength of rubberized concrete. Int. J. Inf. Technol. Decis. Mak. 2016, 15, 603–619. [Google Scholar] [CrossRef]
- Zhang, J.; Ma, G.; Huang, Y.; Sun, J.; Aslani, F.; Nener, B. Modelling uniaxial compressive strength of lightweight self-compacting concrete using random forest regression. Constr. Build. Mater. 2019, 210, 713–719. [Google Scholar] [CrossRef]
- Ahmadi-Nedushan, B. An optimized instance based learning algorithm for estimation of compressive strength of concrete. Eng. Appl. Artif. Intell. 2012, 25, 1073–1081. [Google Scholar] [CrossRef]
- Chopra, R.; Sharma, K.; Kumar, M.; Chopra, T. Comparison of machine learning techniques for the prediction of compressive strength of concrete. Adv. Civ. Eng. 2018, 2018, 5481705. [Google Scholar] [CrossRef] [Green Version]
- Beale, M.H.; Hagan, M.T.; Demuth, H.B. Neural Network Toolbox; The Mathworks, Inc.: Natick, MA, USA, 2010. [Google Scholar]
- Kovačević, M.; Ivanišević, N.; Dašić, T.; Marković, L. Application of artificial neural networks for hydrological modelling in Karst. Gradjevinar 2018, 70, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Kovačević, M.; Ivanišević, N.; Petronijević, P.; Despotović, V. Construction cost estimation of reinforced and prestressed concrete bridges using machine learning. Građevinar 2021, 73, 727. [Google Scholar] [CrossRef]
- Hastie, T.; Tibsirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Breiman, L.; Friedman, H.; Olsen, R.; Stone, C.J. Classification and Regression Trees; Chapman and Hall/CRC: Wadsworth, OH, USA, 1984. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Friedman, J.H.; Meulman, J.J. Multiple additive regression trees with application in epidemiology. Stat. Med. 2003, 22, 1365–1381. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Kecman, V. Learning and Soft Computing: Support. In Vector Machines, Neural Networks, and Fuzzy Logic Models; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Smola, A.J.; Sholkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2. [Google Scholar] [CrossRef]
- LIBSVM—A Library for Support Vector Machines. Available online: https://www.csie.ntu.edu.tw/~cjlin/libsvm/ (accessed on 21 February 2021.).
- Rasmussen, C.E.; Williams, C.K. Gaussian Processes for Machine Learning; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Matić, P. Kratkoročno Predviđanje Hidrološkog Dotoka Pomoću Umjetne Neuronske Mreže. Ph.D. Thesis, University of Split, Split, Croatia, 2014. [Google Scholar]
- Emiroğlu, M.; Yildiz, S.; Keleştemur, O.; Keleştemur, M.H. Bond performance of rubber particles in the self-compacting concrete. In Proceedings of the 4th International Symposium Bond in Concrete 2012—Bond, Anchorage, Detailing, Brescia, Italy, 17–20 June 2012; pp. 779–785. [Google Scholar]
- Yung, W.H.; Yung, L.C.; Hua, L.H. A study of the durability properties of waste tire rubber applied to self-compacting concrete. Constr. Build. Mater. 2013, 41, 665–672. [Google Scholar] [CrossRef]
- Li, N.; Long, G.; Zhang, S. Properties of self- compacting concrete incorporating rubber and expanded clay aggregates. Key Eng. Mater. 2014, 629, 417–424. [Google Scholar] [CrossRef]
- Khalil, E.; Abd-Elmohsen, M.; Anwar, A.M. Impact resistance of rubberized self-compacting concrete. Water Sci. 2015, 29, 45–53. [Google Scholar] [CrossRef] [Green Version]
- Yu, J. Research on the mechanical properties of self-compacting waste rubberised aggregate concrete. In Proceedings of the 2016 International Conference on Civil, Transportation and Environment (ICCTE 2016), Guangzhou, China, 30–31 January 2016. [Google Scholar]
- Zaoiai, S.; Makani, A.; Tafraoui, A.; Benmerioul, F. Optimization and mechanical characterization of self-compacting concrete incorporating rubber aggregates. Asia. J. Civ. Eng. (BHRC) 2016, 17, 817–829. [Google Scholar]
- Ismail, M.K.; Hassan, A.A.A. Impact resistance and mechanical properties of self-consolidating rubberized concrete reinforced with steel fibers. J. Mater. Civ. Eng. 2017, 29, 04016193. [Google Scholar] [CrossRef]
- Turatsinze, A.; Garros, M. On the modulus of elasticity and strain capacity of Self-Compacting Concrete incorporating rubber aggregates. Resour. Conserv. Recycl. 2008, 52, 1209–1215. [Google Scholar] [CrossRef]
- Guneyisi, E. Fresh properties of self-compacting rubberized concrete incorporated with fly ash. Mater. Struct. 2010, 43, 1037–1048. [Google Scholar] [CrossRef]
- Long, G.; Ma, K.; Li, Z.; Xie, Y. Self-compacting concrete reinforced by waste tyre rubber particle and emulsified asphalt. In Proceedings of the Second International Conference on Sustainable Construction Materials, Design, Performance, and Application, Wuhan, China, 18–22 October 2012. [Google Scholar]
- Ganesan, N.; Bharati Raj, J.; Shashikala, A.P. Flexural fatigue behavior of self-compacting rubberized concrete. Constr. Build. Mater. 2013, 44, 7–14. [Google Scholar] [CrossRef]
- Ismail, M.K.; De Grazia, M.T.; Hassan, A.A.A. Mechanical properties of self-consolidating rubberized concrete with different supplementary cementing materials. In Proceedings of the International Conference on Transportation and Civil Engineering (ICTCE’15), London, UK, 21–22 March 2015. [Google Scholar] [CrossRef] [Green Version]
- Mishra, M.; Panda, K.C. An experimental study on fresh and hardened properties of self compacting rubberized concrete. Indian J. Sci. Technol. 2015, 8, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Guneyisi, E.; Gesoglu, M.; Naji, N.; Ipek, S. Evaluation of the rheological behaviour of fresh self-compacting rubberized concrete by using the Herschel-Bulkley and modified Bingham models. Arch. Civ. Mech. Eng. 2016, 16, 9–19. [Google Scholar] [CrossRef]
- Padhi, S.; Panda, K.C. Fresh and hardened properties of rubberized concrete using fine rubber and silpozz. Adv. Concr. Constr. 2016, 4, 49–69. [Google Scholar] [CrossRef]
- Bideci, A.; Öztürk, H.; Bideci, O.S.; Emiroglu, M. Fracture energy and mechanical characteristics of self-compacting concretes including waste bladder tyre. Constr. Build. Mater. 2017, 149, 669–678. [Google Scholar] [CrossRef]
- AbdelAleem, B.H.; Hassan, A.A.A. Development of self-consolidating rubberized concrete incorporating silica fume. Constr. Build. Mater. 2018, 161, 389–397. [Google Scholar] [CrossRef]
- Aslani, F.; Ma, G.; Wan, D.L.Y.; Le, V.X.T. Experimental investigation into rubber granules and their effects on the fresh and hardened properties of self-compacting concrete. J. Clean. Prod. 2018, 172, 1835–1847. [Google Scholar] [CrossRef]
- Hamza, B.; Belkacem, M.; Said, K.; Walid, Y. Performance of self-compacting rubberized concrete. MATEC Web Conf. 2018, 149, 01070. [Google Scholar] [CrossRef]
- Yang, G.; Chen, X.; Guo, S.; Xuan, W. Dynamic mechanical performance of self-compacting concrete containing crumb rubber under high strain rates. KSCE J. Civ. Eng. 2019, 23, 3669–3681. [Google Scholar] [CrossRef]
- Bušić, R.; Benšić, M.; Miličević, I.; Strukar, K. Prediction models for the mechanical properties of self-compacting concrete with recycled rubber and silica fume. Materials 2020, 13, 1821. [Google Scholar] [CrossRef] [Green Version]
- Hagan, M.T.; Demuth, H.B.; Beale, M.H.; Jesus, O.D. Neural Network Design. Martin, T.H., Ed.; Oklahoma State University: Stillwater, OK, USA, 2014. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Concrete | Algorithm | Data Points | Authors | Reference |
|---|---|---|---|---|
| Rubberized concrete | ANN, fuzzy logic (FL) | 36 | Topçu et al. | [19] |
| Rubberized concrete | ANN, gene-expression programming (GEP) | 70 | Gesoglu et al. | [20] |
| Rubberized concrete | ANN | 287 | El-Khoja et al. | [21] |
| Rubberized concrete | ANN, k-nearest neighbor (KNN), regression trees (RT) and random forests (RF) | 457 | Hadzima-Nyarko et al. | [22] |
| Rubberized concrete | GPR, SVM | 89 | Gregori et al. | [23] |
| Rubberized concrete | ANN | 129 | Dat et al. | [24] |
| Rubberized concrete | ANN | 353 | Huang et al. | [25] |
| Rubberized concrete | RF | 138 | Sun et al. | [26] |
| Rubberized concrete | ANN | 122 | Bachir et al. | [27] |
| Rubberized concrete | Self-adaptive fuzzy least squares support vector machines inference model (SFLSIM) | 70 | Cheng and Hoang | [28] |
| SCRC | Gaussian process regression (GPR) | 144 | Hadzima-Nyarko et al. | [2] |
| SCRC | Beetle antennae search (BAS)-algorithm-based random forest (RF) | 131 | Zhang et al. | [29] |
| Variable | Average Value | Minimum Value | Maximum Value |
|---|---|---|---|
| Water (kg/m3) | 197.15 | 170.00 | 246.00 |
| Cement (kg/m3) | 402.39 | 180.00 | 550.00 |
| Fine nat. aggregate (kg/m3) | 764.32 | 375.20 | 1192.00 |
| Coarse nat. aggregate (kg/m3) | 744.45 | 364.00 | 898.00 |
| Fine rubber (kg/m3) | 41.33 | 0 | 198.73 |
| Coarse rubber (kg/m3) | 18.20 | 0 | 355.80 |
| Superplasticizer (kg/m3) | 4.71 | 1.06 | 22.00 |
| Slag (kg/m3) | 23.08 | 0 | 175.00 |
| Silica fume (kg/m3) | 9.97 | 0 | 60.00 |
| Fly ash (kg/m3) | 74.26 | 0 | 330.00 |
| SCRC compr. Strength (MPa) | 74.26 | 0 | 330.00 |
| Year | Author(s) | Ref. | Type of Aggregate Replaced by Rubber | No. of Specimens | SCM 1 | No. of SCM |
|---|---|---|---|---|---|---|
| 2008 | Turatsinze and Garros | [57] | Coarse | 5 | - | - |
| 2010 | Guneyisi | [58] | Coarse | 16 | FA 2 | 12 |
| 2012 | Emiroglu et al. | [50] | Coarse | 3 | S 3 | 3 |
| 2012 | Long et al. | [59] | Fine | 6 | SF 4 + FA | 6 |
| 2013 | Ganesan et al. | [60] | Fine | 3 | FA | 3 |
| 2013 | Yung et al. | [51] | Fine | 5 | S + FA | 5 |
| 2014 | Li et al. | [52] | Fine | 7 | SF + FA | 7 |
| 2015 | Ismail et al. | [61] | Fine | 5 | - | - |
| 2015 | Khalil et al. | [53] | Fine | 5 | - | - |
| 2015 | Mishra and Panda | [62] | Coarse | 5 | - | - |
| 2016 | Guneyisi et al. | [63] | Fine and Coarse | 21 | FA | 21 |
| 2017 | Ismail and Hassan | [56] | Fine | 16 | FA | 3 |
| S | 3 | |||||
| 2016 | Padhi and Panda | [64] | Fine | 4 | - | - |
| 2016 | Yu | [54] | Fine | 6 | FA | 6 |
| 2016 | Zaoiai et al. | [55] | Fine and Coarse | 5 | - | - |
| 2017 | Bideci et al. | [65] | Coarse | 4 | S | 4 |
| 2018 | AbdelAleem and Hassan | [66] | Fine | 12 | S | 1 |
| FA | 1 | |||||
| SF | 10 | |||||
| 2018 | Aslani et al. | [67] | Fine and Coarse | 13 | S + FA + SF | 13 |
| 2018 | Hamza et al. | [68] | Fine | 4 | - | - |
| 2019 | Yang et al. | [69] | Fine | 4 | SF + FA | 4 |
| 2020 | Bušić et al. | [70] | Fine | 17 | SF | 10 |
| - | - | - | Total | 166 | - | - |
| Model | RMSE | MAPE/100 | ||
|---|---|---|---|---|
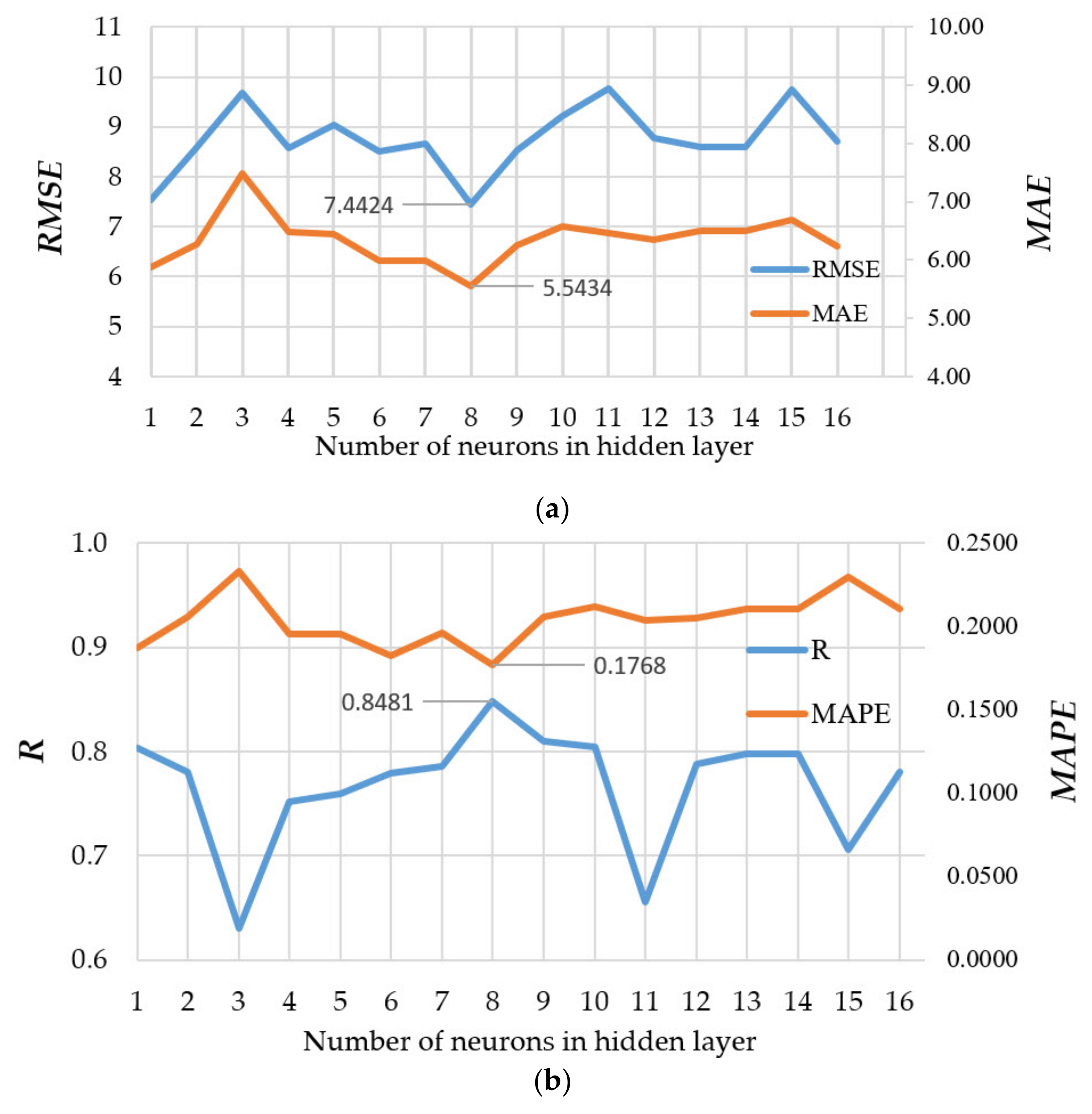
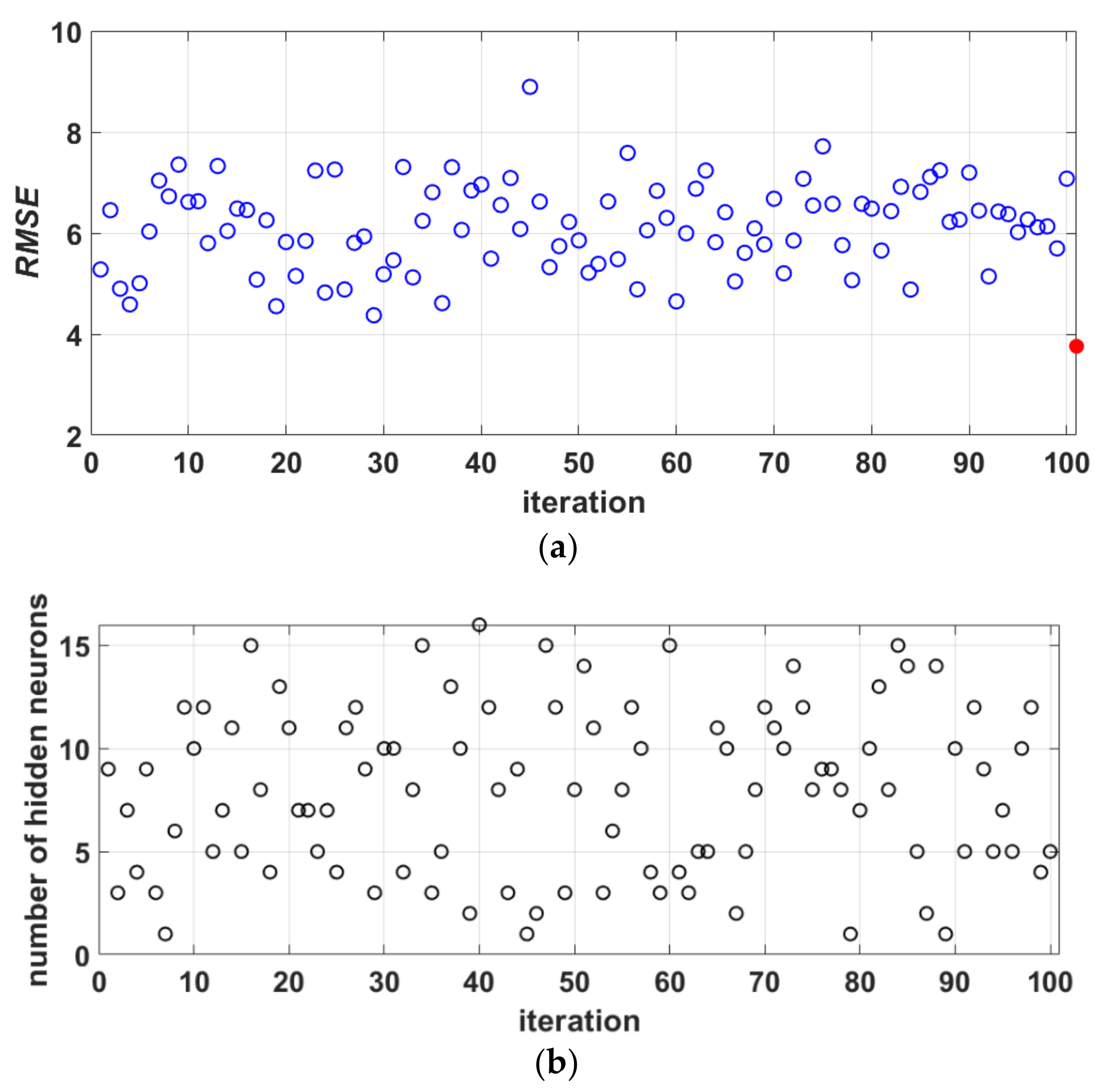
| NN-10-8-1 * | 7.4424 | 5.5434 | 0.1768 | 0.8481 |
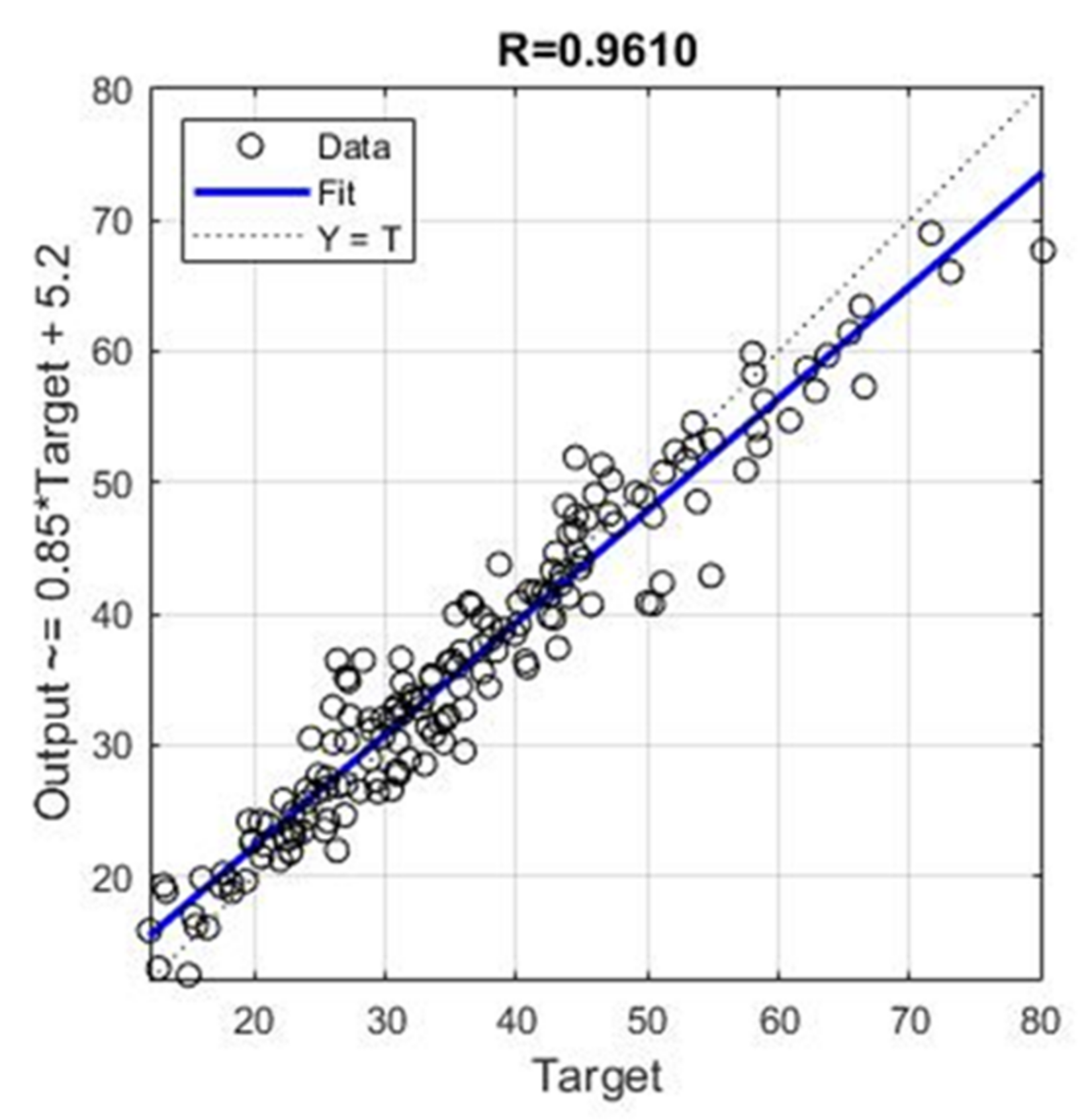
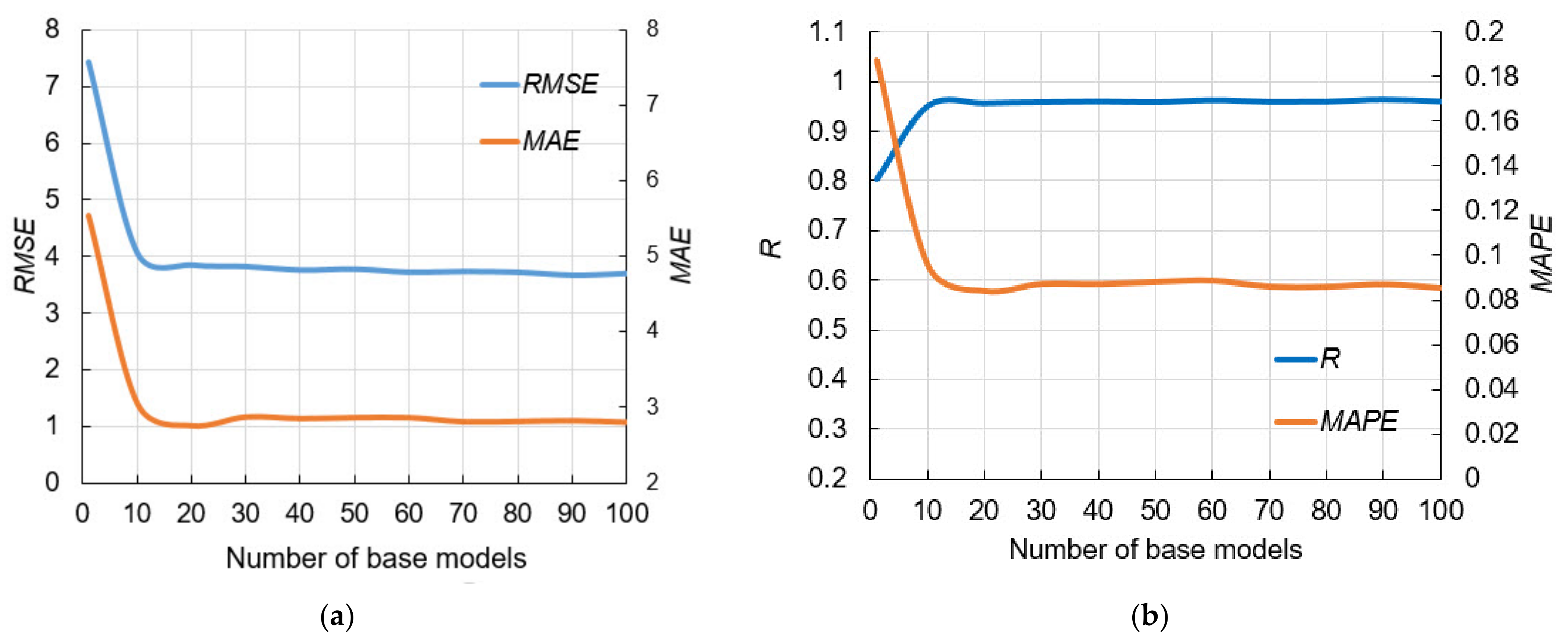
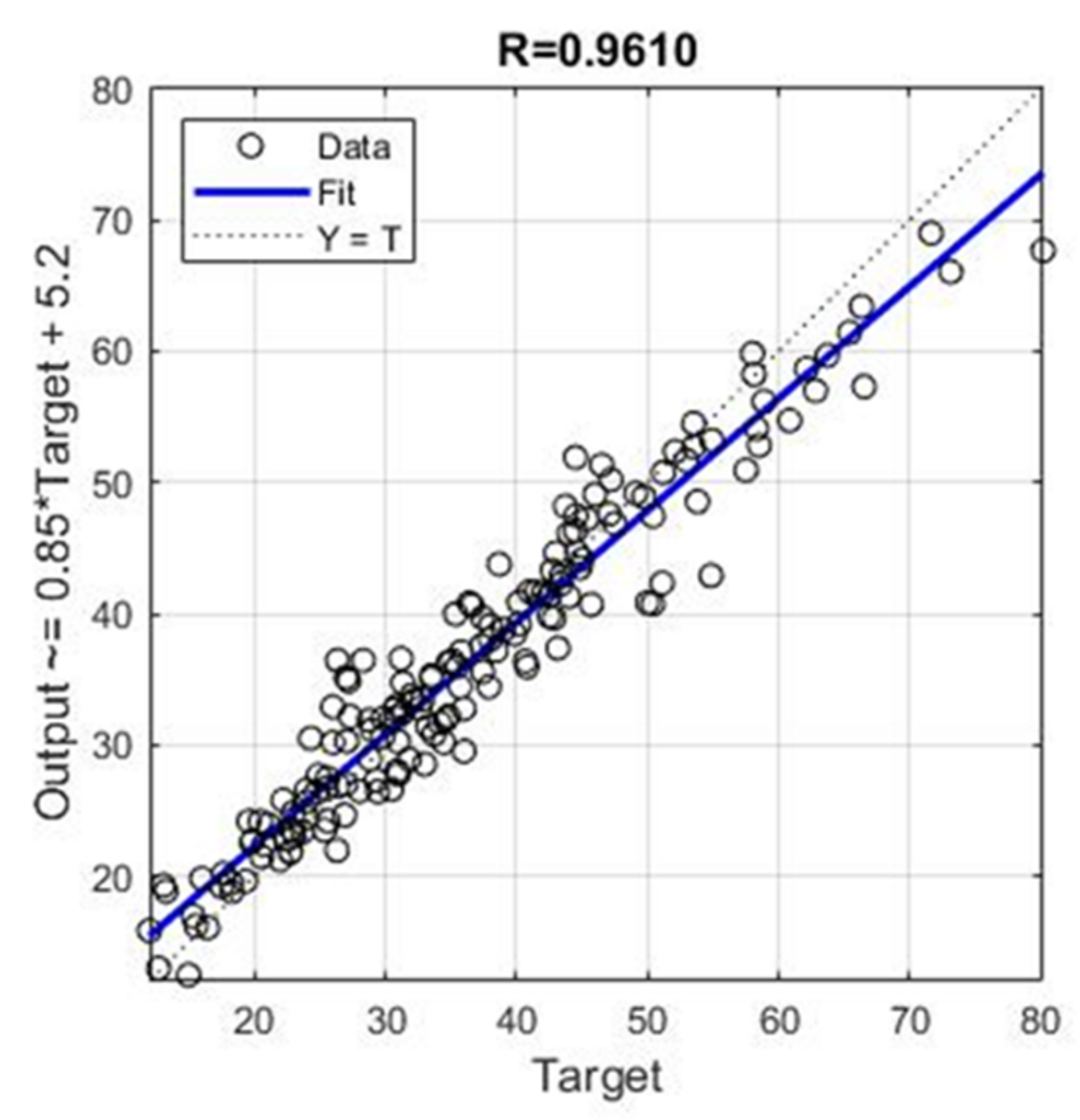
| Ensemble | 3.6888 | 2.8099 | 0.0854 | 0.9610 |
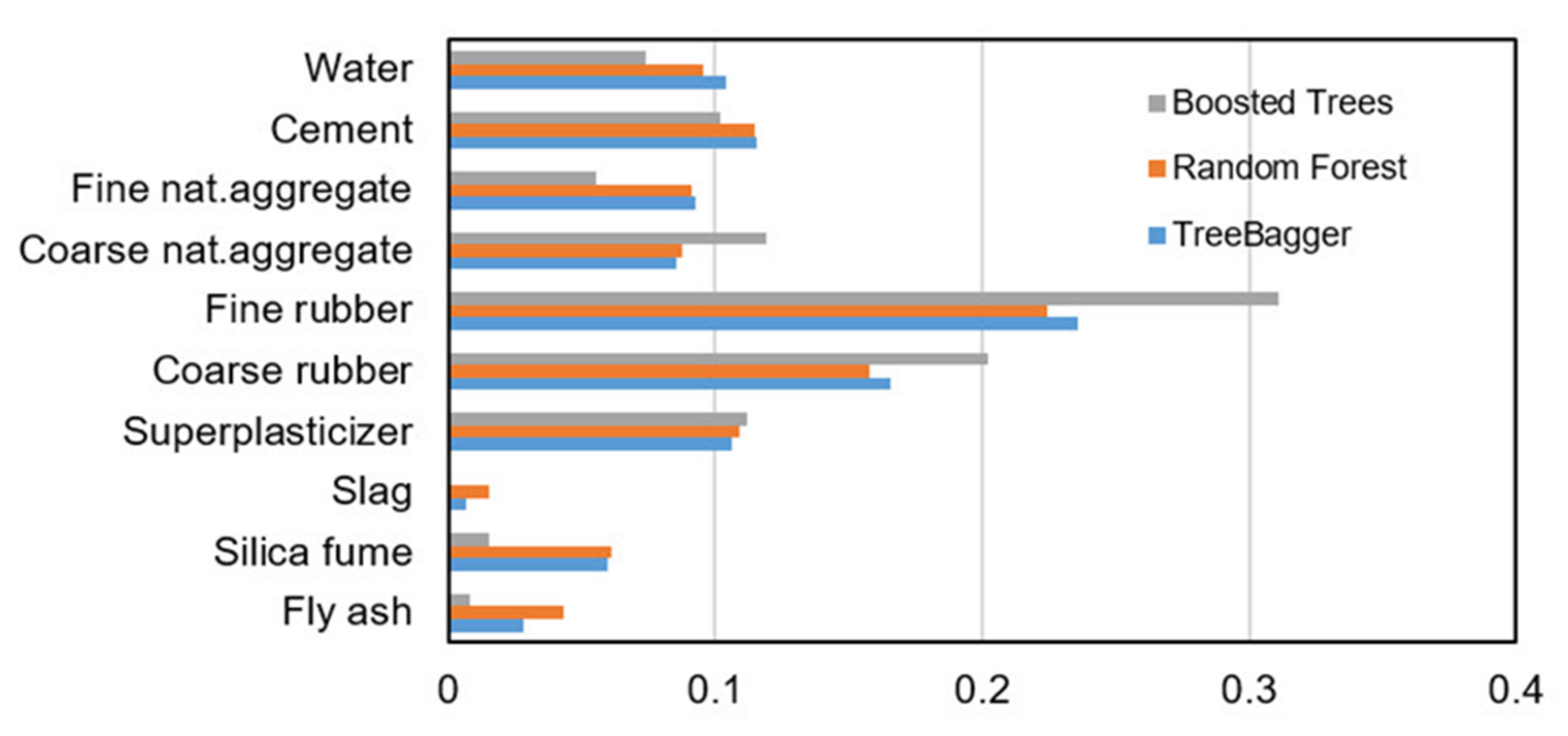
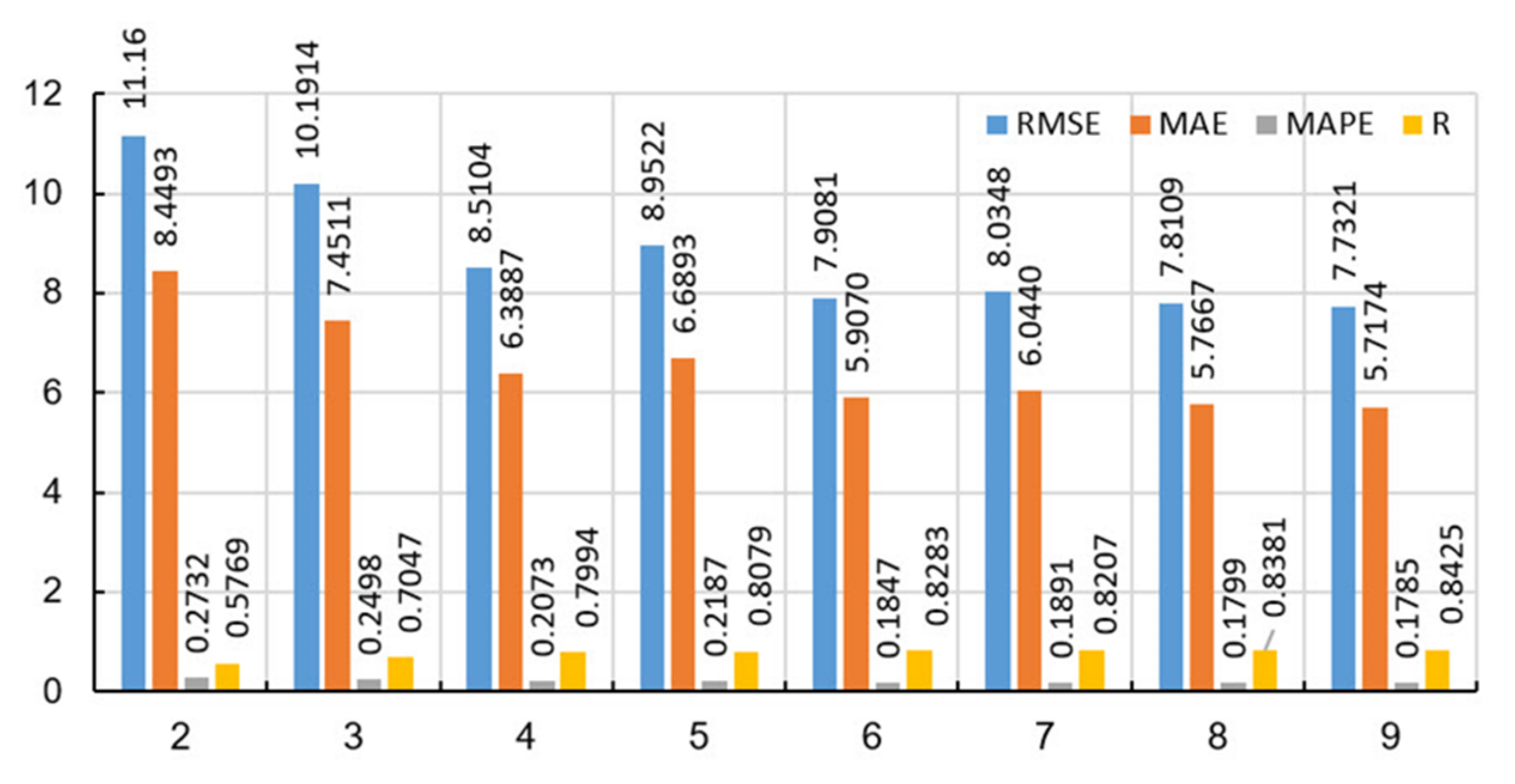
| Method | RMSE | MAE | MAPE/100 | R |
|---|---|---|---|---|
| TreeBager | 8.1890 | 6.0546 | 0.1881 | 0.8214 |
| RF | 7.7321 | 5.7174 | 0.1785 | 0.8425 |
| Boosted Trees | 7.4821 | 5.4248 | 0.1573 | 0.8432 |
| Model | RMSE | MAE | MAPE/100 | R |
|---|---|---|---|---|
| Lin. kernel | 8.7154 | 6.6468 | 0.2105 | 0.7751 |
| RBF kernel | 4.9646 | 3.5352 | 0.1171 | 0.9332 |
| Sig. kernel | 8.7104 | 6.6094 | 0.2073 | 0.7718 |
| GP Model Covariance Function | Covariance Function Parameters | |||
|---|---|---|---|---|
| Exponential | ||||
| 51.7642 | 44.6486 | |||
| Squared Exponential | ||||
| 1.9621 | 21.4682 | |||
| Matern 3/2 | ||||
| 4.4183 | ||||
| Matern 5/2 | ||||
| 2.8760 | ||||
| Rational Quadratic | ||||
| 2.8568 | 28.5379 | |||
| Covariance Function Parameters | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| ARD Exponential: ;=61.7884; | |||||||||
| 136.5920 | 34.7143 | 149.6719 | 87.1631 | 160.3637 | 137.0799 | 174.2748 | 380.2212 | 84.5739 | 42.4424 |
| ARD Squared exponential: =24.1382 | |||||||||
| 2.7611 | 0.8842 | 4.3944 | 3.1684 | 2.3792 | 2.6952 | 1.8852 | 4125.1386 | 5.6892 | 0.7528 |
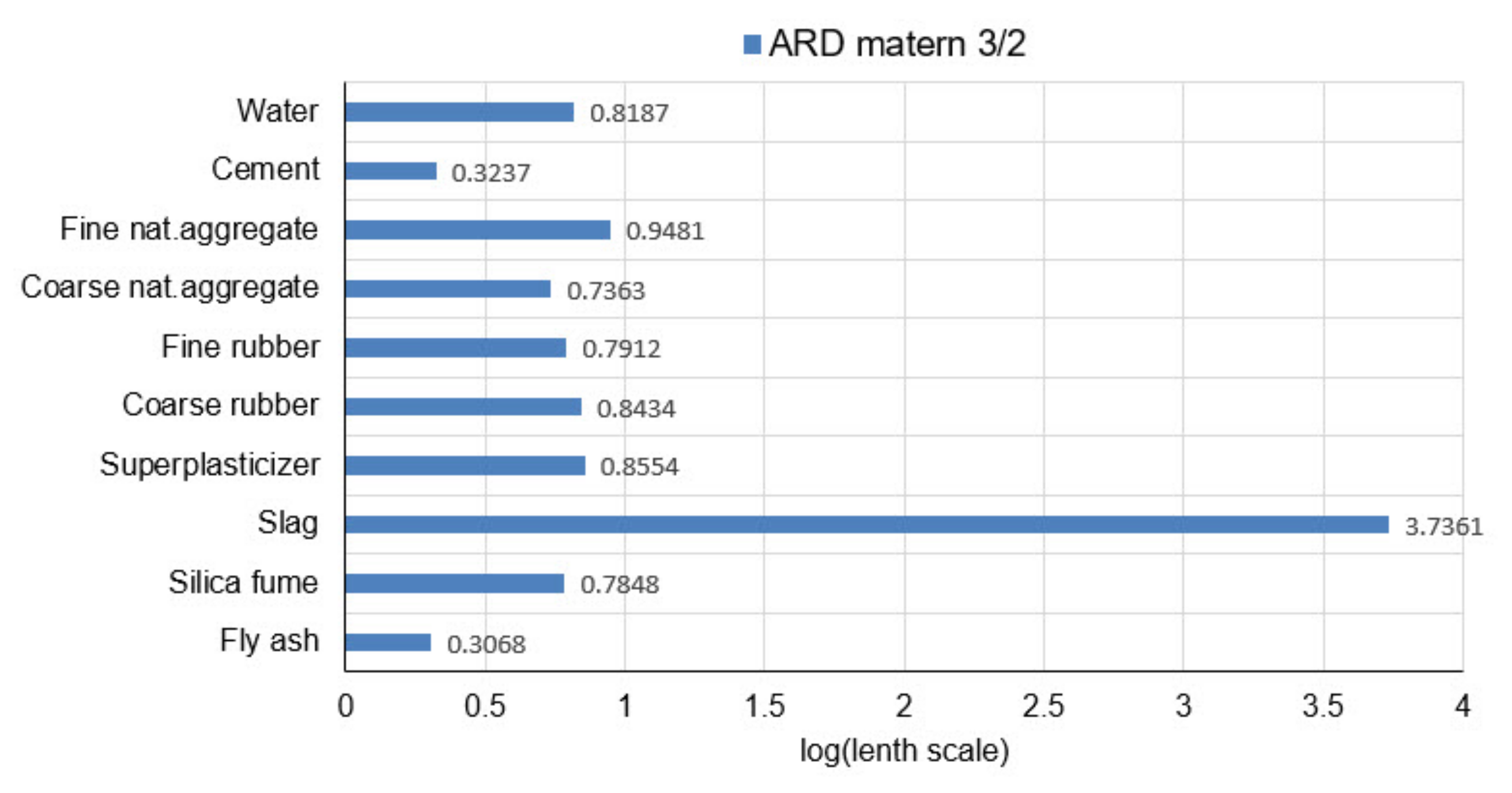
| ARD Matern 3/2: =32.6244 | |||||||||
| 6.5869 | 2.1073 | 8.8734 | 5.4483 | 6.1835 | 6.9731 | 7.1678 | 5445.6855 | 6.0925 | 2.0265 |
| ARD Matern 5/2: =26.5499 | |||||||||
| 3.8496 | 1.2738 | 6.9524 | 4.5500 | 3.5908 | 3.9290 | 2.6596 | 2276.2435 | 5.8061 | 1.3211 |
| ARD Rational quadratic: =0.3332; =61.7884 | |||||||||
| 3.6879 | 1.3166 | 7.3725 | 4.6652 | 3.7047 | 3.9596 | 2.6138 | 4383.7159 | 5.4661 | 1.4843 |
| GP Model Covariance Function | RMSE | MAE | MAPE/100 | R |
|---|---|---|---|---|
| Exponential | 5.0574 | 3.5064 | 0.1038 | 0.9316 |
| ARD-Exponential | 4.6120 | 3.1634 | 0.0947 | 0.9427 |
| Squared Exponential | 5.0447 | 3.4686 | 0.1133 | 0.9300 |
| ARD-Squared Exponential | 4.9670 | 3.4076 | 0.1101 | 0.9334 |
| Matern 3/2 | 4.7244 | 3.2487 | 0.1021 | 0.9386 |
| ARD-Matern 3/2 | 4.4341 | 3.1022 | 0.0958 | 0.9474 |
| Matern 5/2 | 4.8275 | 3.3133 | 0.1061 | 0.9360 |
| ARD-Matern 5/2 | 4.6527 | 3.2691 | 0.1037 | 0.9424 |
| Rational Quadratic | 4.6467 | 3.2022 | 0.0997 | 09407 |
| ARD Rational quadratic | 4.5937 | 3.1894 | 0.1006 | 0.9435 |
| Model | RMSE | MAE | MAPE/100 | R | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
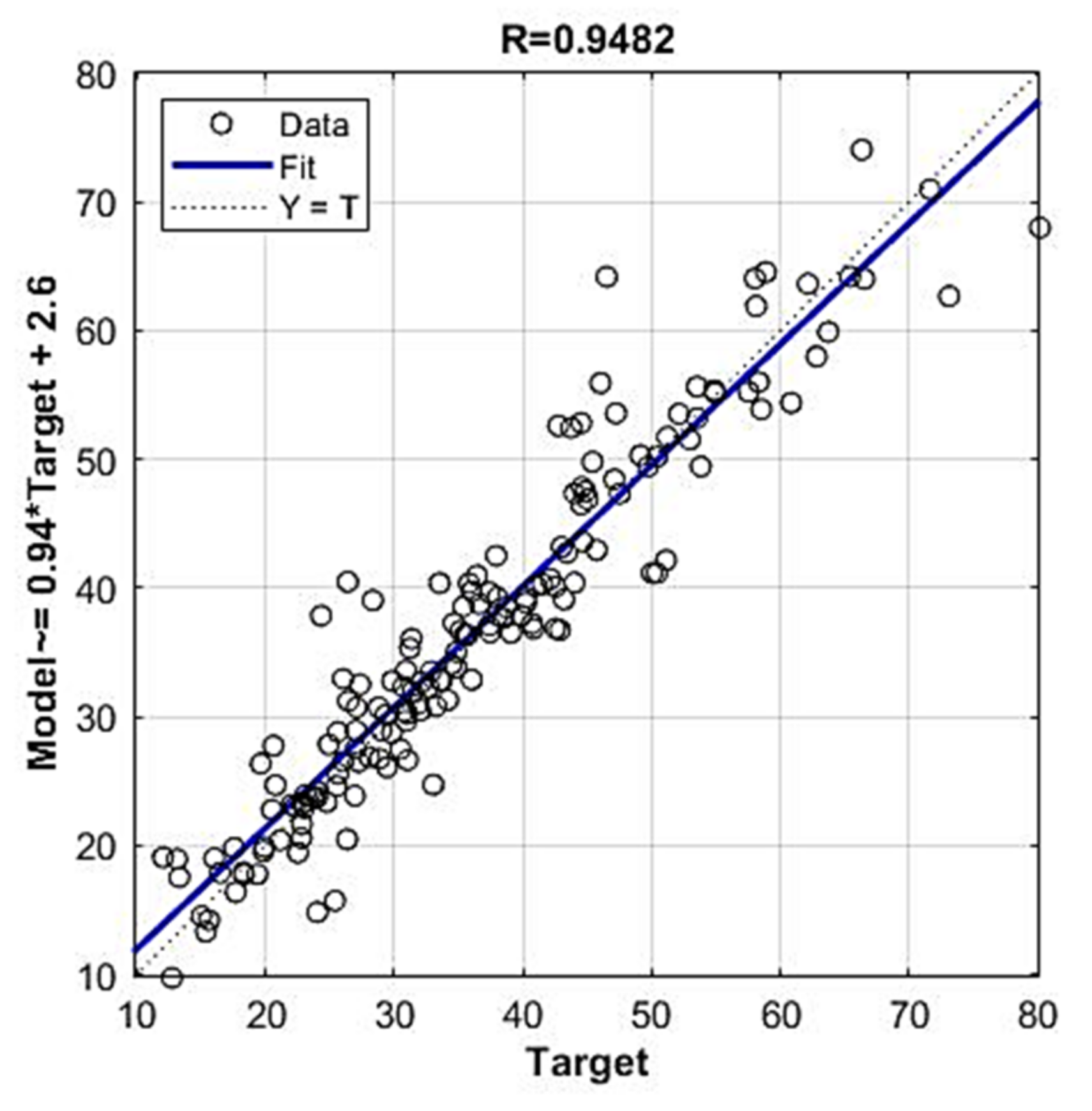
| 1. | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 4.3934 | 3.0583 | 0.0942 | 0.9482 |
| 2. | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 4.4341 | 3.1022 | 0.0958 | 0.9474 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kovačević, M.; Lozančić, S.; Nyarko, E.K.; Hadzima-Nyarko, M. Modeling of Compressive Strength of Self-Compacting Rubberized Concrete Using Machine Learning. Materials 2021, 14, 4346. https://doi.org/10.3390/ma14154346
Kovačević M, Lozančić S, Nyarko EK, Hadzima-Nyarko M. Modeling of Compressive Strength of Self-Compacting Rubberized Concrete Using Machine Learning. Materials. 2021; 14(15):4346. https://doi.org/10.3390/ma14154346
Chicago/Turabian StyleKovačević, Miljan, Silva Lozančić, Emmanuel Karlo Nyarko, and Marijana Hadzima-Nyarko. 2021. "Modeling of Compressive Strength of Self-Compacting Rubberized Concrete Using Machine Learning" Materials 14, no. 15: 4346. https://doi.org/10.3390/ma14154346
APA StyleKovačević, M., Lozančić, S., Nyarko, E. K., & Hadzima-Nyarko, M. (2021). Modeling of Compressive Strength of Self-Compacting Rubberized Concrete Using Machine Learning. Materials, 14(15), 4346. https://doi.org/10.3390/ma14154346