1. Introduction
Engineered geopolymer composites (EGC) are a new class of ultrahigh ductile fiber–reinforced concrete composites with 100% eco-friendly binding materials [
1]. Geopolymer concrete uses industrial by-products such as fly ash (FA), ground granulated blast furnace slag (GGBS), and metakaolin (MK) as binding materials that are activated by alkali activators [
2]. Combinations of hydroxides and silicates of sodium, potassium, or calcium, in various proportions, are generally used to activate aluminosilicate-based binders. These geopolymeric binders are reinforced with special synthetic fibers, such as polyvinyl alcohol (PVA) fibers or polyethylene (PE) fibers, that constitute EGC. The EGC exhibit peculiar strain-hardening characteristics, thus making the concrete ductile rather than brittle. The ductility of EGC is nearly 600 times that of normal concrete [
3]. These material ingredients of the composites are tailored in such a way as to obtain multiple micro-cracks upon loading, making the concrete flexible in nature. EGC is popularly known as bendable concrete, flexible concrete, or strain-hardening geopolymer composite (SHGC). Several studies are being carried out in the field of EGC all over the world, and these include advanced experiments. The state-of-the-art research on EGC includes studies on the effects of different kinds of binders; on the blending proportions, i.e., the binary binders in EGC [
4]; on the effects of nano materials on the interfacial properties of EGC [
5]; and a few durability studies on the effects of nano materials [
6]. Such advanced experiments require substantial costs and time.
Designing concrete composites to achieve the desired compressive strength is always tedious. The mix-design procedure of conventional concrete has been standardized such that the concrete can be designed to achieve the target compressive strength [
7]. Research into concrete technology has been extensively developed, resulting in the development of several special concrete-like high-performance concretes [
8,
9], fiber-reinforced concrete [
10,
11,
12], self-healing concrete [
13], lightweight concrete [
14,
15], etc. During the development stages of such special types of concrete, it is always required for the researchers to perform several trial mixes in a feasibility study and to achieve the desired strength, which may consume a huge amount of materials and time. Since EGC is in the developmental stage, the scenario for trial mixes of the material still exists.
The artificial neural network (ANN) is one of the artificial intelligence tools widely applied in almost all kinds of research worldwide [
16,
17,
18]. The ANN is based on the principle of millions of interconnected human biological neurons that respond based on signals from the brain. This technique is applied in ANN to predict responses based on several inputs by establishing a non-linear relationship. In civil engineering research, ANN has been successfully applied to anticipate the strength criteria of hardened concrete [
19] and the workability properties of fresh concrete [
20]. In addition to these studies, several important and advanced parametric studies, such as those estimating the bond strength of structural concrete [
21,
22], the spalling [
23] damage assessment of concrete [
24,
25], analyzing sections of deep beams [
26], estimating the fracture parameters of geopolymer composites [
27], and accessing the properties of FRP columns [
28] have been successfully conducted. Additionally, durability studies on various factors such as corrosion inhibition [
29], chloride penetration [
30,
31] and other aspects have also been successfully undertaken. One of the rare phenomena in applying ANN to concrete technology is the optimization of the mix-design process of special types of concrete [
32,
33,
34]. A few researchers have successfully applied the ANN technique to predict and optimize the mix design of conventional and special concrete; however, standardizing the procedure and conformity of the prediction abilities of those ANN models is still tedious.
2. Research Significance
In the early stages of the developmental phase of advanced research on special concrete and in order to study the material’s behavior in relation to various properties such as high strength and durability, it is essential to preliminarily understand the material’s basic behavior. The paramount concern in designing any kind of concrete composite is the compressive strength. For the conventional type of concrete, standard mix-design procedures are available by which, with the available material properties such as specific gravity and gradation, among others, the concrete composite can be designed to achieve the desired compressive strength [
7]. For special concrete composites, the mix design can be tedious to standardize. For instance, to design self-compacting concrete, the dosage and the type of super-plasticizer primarily depend on the binder, where several supplementary cementitious materials may also be used along with the cement. In such cases, it is impossible to standardize all the types of binding materials. Thus, trial mixes are the only true methods of possibly developing the composites. The problems associated with the trial mixes are the massive consumption of materials and time for the design, which are not economical and may delay the progress of advanced research.
To overcome this, several advanced techniques are being adopted in concrete technology to standardize the procedure of design [
35]. Among them, artificial intelligence is the most prominent. Since the early 2000s, soft computing techniques (SCT) have been applied in civil engineering, particularly in predicting the strength parameters of concrete composites [
17,
36]. Various mix-design factors are identified, numbered, and specified as inputs to anticipate the compressive strength of the composites. Specifying those inputs and outputs should determine those mix-design factors, technically known as the “design mix of concrete”. The application of SCTs in concrete mix design is a rare phenomenon and the accuracy of these predictions has not been addressed [
34].
EGC is one of the types of special concrete for which standards have not been prescribed, and since it is in the initial phases of development, several advanced studies are being carried out worldwide [
37,
38]. The available literature on the development of EGC is quite limited such that performing future studies on EGC requires more trials since assumptions cannot be made for any aspects. Using synthetic fibers in EGC makes it quite uneconomical [
39]. Thus, with the help of advanced computing techniques, a mix-design procedure is a prerequisite to minimizing the materials and time consumption in the trial mixes of EGC material development. This paper attempts to develop a mix-design procedure using the ANN technique. In this research work, Levenberg Marquardt (LM)–based ANN is employed to predict the mix-design factors. The GDX (gradient descent adaptive LR)–based ANN is adopted to analyze or cross-validate the mix-influencing factors. With the various types of ANN models, such a type of cross-validation enhances the accuracy of prediction and validation. Thus, it helps to minimize the number of trial experiments to achieve the desired strength of special concrete composites. The cost and time required for the experiments can also be reduced.
3. Methodology
Figure 1 shows the detailed methodology that was performed in this research study. This paper adopts the ANN to predict the mix-design influencing parameters in developing SHGC for the desired compressive strength and tensile strength. In other words, this is a detailed study on the mix-design process of developing SHGC using an ANN when a standard mix-design procedure is not available. The methodology comprises three stages: prediction, cross-validation and tack-together’ output for a preliminary database collection.
As a preliminary stage, a database required for training, testing, and cross-validating the ANN models was prepared, which was collected from the EGC papers, with a few ‘literature filtering’ criteria. It is obvious that the presence of surplus mix-design factors or materials or the involvement of the addition or replacement of mix-design ingredients (apart from those seven selected mix factors) may certainly influence the compressive strength and tensile strength. Thus, it was required to select the literature in such a way that no other influencing factors were involved, for which the filtering criteria were adopted. For instance, the fine aggregate selected here was silica sand, but some researchers might have used river sand in EGC, along with GGBS/fly ash, so such studies were filtered in the data collection process as the performance of silica sand and river sand may vary upon compressive strength. In the first stage, as per the computing techniques, parameters obtained once the concrete has been prepared in the fresh or hardened state can be given as inputs to predict the mix factors [
34]. Thus, parameters such as slump values, strength values, or Young’s modulus can be given as inputs. As per the literature available and the database collected, two strength parameters, compressive strength and tensile strength, were given as inputs, whereas the seven mix-design influencing factors—fly ash content, GGBS content, sand content, activator/binder ratio, PVA V
f (%), curing temperature x hours, and ambient curing days—were given as outputs. Several ANN models were created and analyzed to predict the seven mix-design factors, with only compressive strength and tensile strength values as inputs. Predicting seven outputs with only two inputs is a tedious task as per ANN [
40]. Thus, the trial-and-error method was adopted to train and test the various ANN models with variations in a number of hidden layers and hidden neurons in it, of which the five best ANN models were chosen (named ANN-I models). The predicting ability of those ANN-I models was ensured through regression analysis with coefficient of determination (R
2) as performed in the previous literature [
41,
42].
In the second stage, to test and validate the created ANN-I models, another type of ANN model was developed, the ANN-II model, which predicts the compressive and tensile strength with those seven mix-design influencing factors as inputs. Now, to validate the ANN-I models, the mix-design outputs obtained were adjusted and given as inputs to the trained ANN-II model to predict the compressive strength rearwards, denoted as “cross-validation” as mentioned by Jena et al. 2020 [
43]. The term ‘adjustments’ indicates the corrections that can be made in the predicted mix-design values obtained from the ANN-I models. Certain outputs may go beyond the allowable range during the prediction of mix-design values from ANN-I models. For example, it is redundant if the output activator/binder ratio is beyond 1.3. These values were then adjusted to the nominal value of 0.65. It is to be noted that such adjustments were made only to the activator/binder ratio and PVA fiber (%) (Taken as 2, if >2) and the remaining outputs were fed unchanged. This predicted compressive and tensile strength would be analyzed with the experimental database obtained from literature to test the predictive ability of the ANN-I models.
The third stage involves a method known as “tack-together output”. Despite considering all the seven outputs (mix-design influencing factors) from the same ANN-I models, each output with the maximum R2 value was isolated and tacked together. For example, the fly ash content’s first output may show the maximum accuracy from any one of the five ANN-I models, which is isolated. Similarly, other outputs were also isolated and these isolated outputs were tacked together to form a combined mix design. These combined mix-design outputs were again validated in the second stage of cross-validation with the ANN-II model and the results were analyzed.
4. Database
The literature based on the material studies of engineered geopolymer composites (EGC) was collected. In total, 14 studies [
38,
39,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54,
55] were selected as per the criteria mentioned in
Table 1 and the database was framed. A total of 72 datasets were collected from the carefully selected 14 studies with the aforesaid mix-influencing factors. The research on material EGC started initially as a feasibility study by Onho et al. in 2014 [
1]. Researchers worldwide performed various material and behavioral studies on EGC on the aspect of developing strain-hardening concrete composites and the importance of sustainability. Hence, the data available concerning such novel material are comparatively limited. Since only a limited number of inputs are chosen as mix-design factors, studies involving only those selected mix factors can be considered, which further limits the datasets. It is also to be noted that, the studies involving surplus mix design factors were not considered for data collection, i.e., for instance, if a study uses metakaolin or silica fume as one of the binders (which are other than the selected binders of fly ash and ggbs), then the study was not considered for data collection. This was certainly to improve the accuracy of prediction. Furthermore, studies like A Yaman et al. 2017 [
34] proved that adequate mix-design accuracy can be obtained for developing ANN models. The researcher used 69 datasets for both training and validation in predicting the mix-design and showed an accuracy level of 80%. The mix-design influencing factors such as binder contents, fiber dosage, curing conditions, etc., were initially selected for which the prediction needs to be made and is described in
Table 1.
The mix-design influencing factors selected were based on the efficiency of those materials and the availability of experimental data. Several kinds of study on EGC have preferred metakaolin (MK) as binding material; however, the availability of experimental data was comparatively lower, though the efficiency of using MK is similar to FA and GGBS. Similarly, strain-hardening criteria can be achieved by polyethylene and polyolefin fibers, but PVA fibers are most efficient as per the literature. Several variations on geopolymer activators, such as the molarity of sodium hydroxide and the ratio of sodium hydroxide to silicate, could be identified in the literature. Only the efficient combinations were selected, as specified in
Table 1. The curing conditions chosen were high-temperature curing followed by ambient curing until the test.
In stage 1, to predict the mix-design for SHGC, the inputs were compressive strength (CS) and tensile strength (TS) and the outputs were seven mix-design factors. The specifications of the collected dataset, i.e., its minimum–maximum range, and standard deviation for both training and testing is presented in
Table 2. This could help to identify the quality of data collection. For the second stage of cross-validation, the inputs and outputs become reversed. Among the 72 datasets, 62 datasets were used for training the models and a subset of 10 datasets was used for testing the predictive models.
5. Development of ANN Models
5.1. Architecture of ANN Models
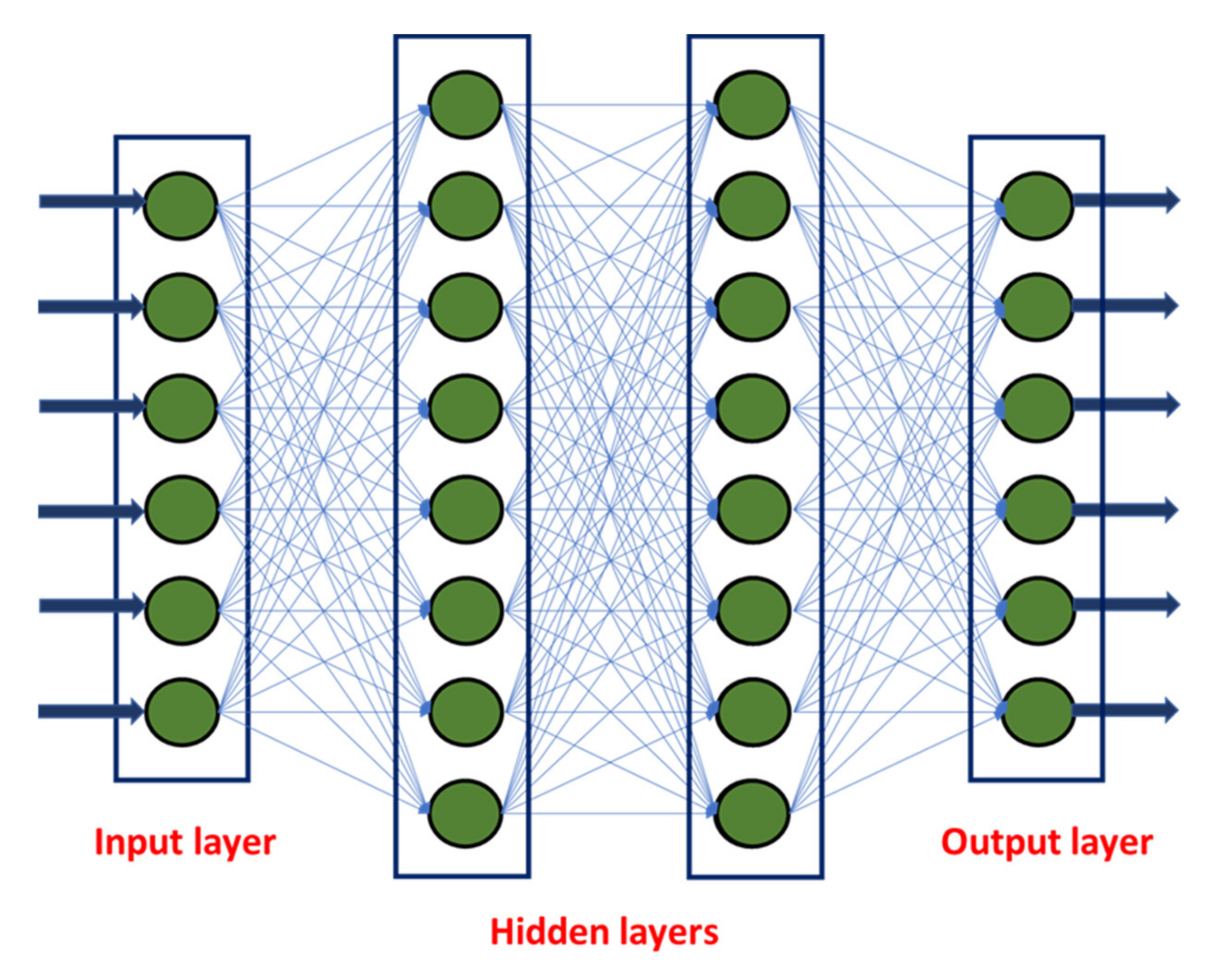
As described earlier, ANN works on the principle of human/animal biological neurons, i.e., several million neurons are interconnected between the brain and other parts of the body, and based on the signal transmission, the brain recognizes and instructs. Similarly, ANN consists of three layers: an input layer, hidden layer(s), and an output layer. The data for input and output layers were collected as described in
Section 4. Now, the development of best models lies in formulating the number of hidden layers and number of hidden neurons in each layer; selecting the right type and function of ANN; and developing criteria such as epochs and max-fail and others, which were mentioned in
Section 5.2.
Figure 2 shows the basic architecture of ANN models. Based on the number of inputs, outputs, and hidden layers, an empirical relation between inputs and outputs is established based on the weights associated with the links, which is represented in Equation (1)
Here, O represents output; W represents weights; I represents inputs; H represents hidden neurons.
Now, to calculate an output, which is related to hidden neurons and inputs, the weights associated with the empirical relation has to be assigned with several trials until good accuracy in the equation is obtained, which is called training. MATLAB software was used in this study to establish best equations (i.e., best ANN models) with several trials and iterations. With those established equations, outputs can be further predicted.
5.2. Stage 1: Prediction of Mix-Design Influencing Factors
After the development of the database, it was essential to select the type of ANN network and its required criteria for training the models. Undoubtedly, the feed-forward backpropagation type of ANN network was chosen based on the literature’s acknowledgments [
17,
36]. Based on the trial-and-error method, several functions of neural networks were tried and it was found that LM-based ANN worked best in predicting the mix design. As the LM-ANN worked well in predicting the outputs when the number of inputs was comparatively smaller [
56]. To obtain the best ANN models in predicting the mix-design, variations in the number of hidden layers and the number of hidden neurons were considered and trained accordingly.
During the training stages, 70% of the dataset was used for training, 15% for self-validation, and 15% for self-testing as per the “nntool” algorithm. It is to be noted that the training criteria, such as the number of epochs, max_fail, and other factors, vary for different ANN models. The learning and transfer functions used were “LEARNGDM” and “LOGSIG”, respectively. Starting with a single hidden layer, hidden neuron ranges from 0 to 20 were tried. ANN [2:16:7] (indicated as 2 inputs; 1 hidden layer with 16 neurons and 7 outputs) resulted in nominal values of material conditions and curing regimes. It was identified that the higher the number of hidden neurons, the higher its prediction accuracy. However, numbers greater than 16 (>16) was not considered since the training process failed upon regression.
In the next phase, two layers of hidden neurons were used. Under different combinations of hidden neurons, it was found that the first hidden layer with 16 neurons was more efficient than the other combinations. Keeping 16 neurons as constant for the first hidden layer, various numbers of hidden neurons upon hidden layers were tried and self-tested and it was found that the ANN [2:16:16:7] and ANN [2:16:25:7] models provided nominal results. Furthermore, various hidden neurons with three hidden layers were tried and found the best possible outcomes as ANN [2:16:16:8:7], ANN [2:16:16:25:7] and ANN [2:16:32:16:7] models.
Table 3 summarizes the correlation coefficient (R) obtained during the training stages with the best possible ANN models. Among those ANN models, the best ANN model developed was identified to be the ANN [2:16:16:7] model with the best analysis upon a correlation coefficient during the training stage.
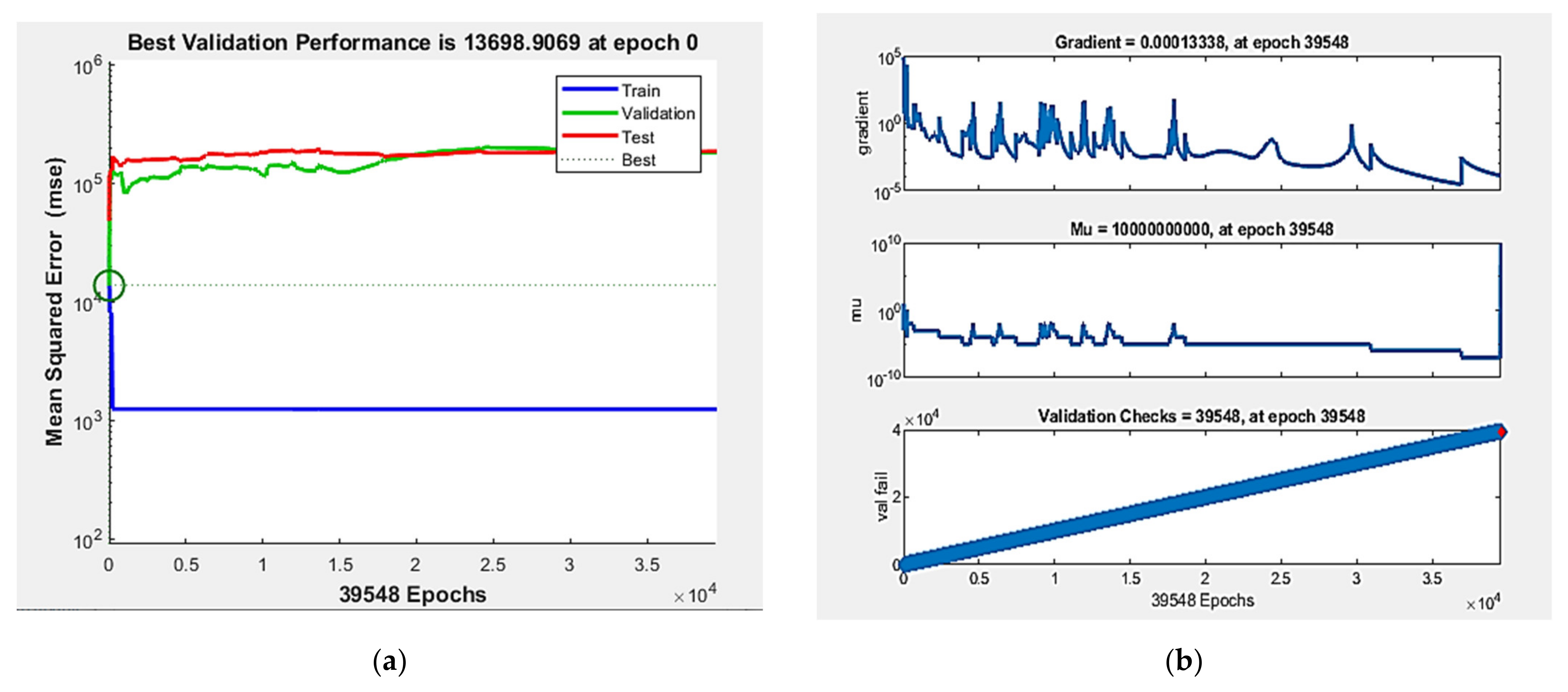
Figure 3 depicts the best validation performance, training state, and regression obtained for the ANN [2:16:16:7] model.
5.3. Stage 2: Prediction of Compressive and Tensile Strength for the Cross-Validation of ANN-I Models
In this stage, the same 72 datasets were employed in the development of the ANN-II model to predict the compressive and tensile strengths. During the prediction of compressive strength with several mix-design factors, i.e., few outputs with several inputs, GDX based ANN performed best, as per the literature [
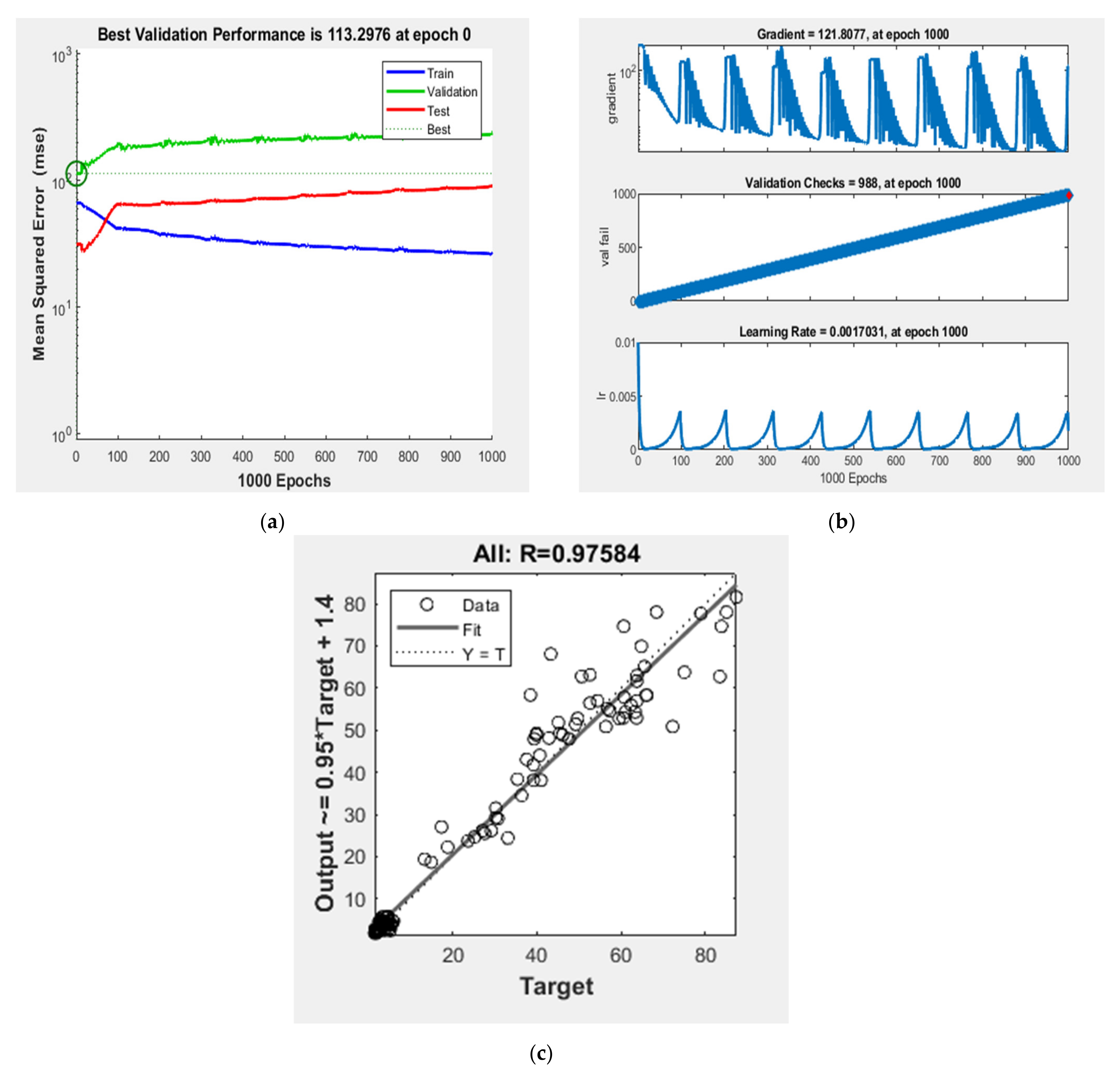
57]. Hence, initially, one hidden layer with several hidden neurons was trained and tested for its predictive ability based on the trial-and-error method. It is to be noted that the databases used for training and testing, respectively, for ANN-I models were used in ANN-II also. It was found that ANN [7:14:2] performed best with predictive ability, up to 94%. Performances during the training process of the ANN [7:14:2] model are shown in
Figure 4. For cross-validating, the mix designs obtained from the ANN-I models were adjusted and fed as inputs to the ANN-II model and the compressive strength and tensile strength were predicted. Thus, the predicted compressive and tensile strength from the ANN-II model was analyzed with the experimental literature database for validation. It thus helped to verify the predicting ability of the ANN-I models.
6. Results and Discussion
ANN-I models were developed to predict the numerical mix-design factors that help develop the material SHGC for its desired compressive and tensile strength. The five best models were selected from several trained models. The analysis on the predicting ability of ANN models to mix-design factors does not primarily lie in regression analysis, unlike compressive strength. For instance, when predicting sensitive parameters such as compressive strength, variance beyond ±5% is not acceptable [
7], whereas predicting outputs such as binder content can be accepted within the range of ±20% [
34]. Thus, the regression analyses were done with the perfect line analysis of range ± 20% variance. The combined analysis is the most important thing to consider in analyzing the predictive ability of ANN models on mix-design. Mix design is the combination of several factors/parameters towards a target. Change in one of the parameters correspondingly when there is a change in other parameters(s) may result in the same target. In other words, for a single target, there may be several combinations of inputs feasible. The ratio between the binders and aggregates may be constant, but the content/value varies. Due to this fact, regression analysis of the ANN models alone is inadequate to examine the ability of prediction, for which the cross-validation was performed. However, the regression analyses were performed initially, followed by cross-validation, for preliminary logical checks.
6.1. Regression Analyses of Mix-Design Prediction of ANN-I Models
The regression analysis with the coefficient of determination (R
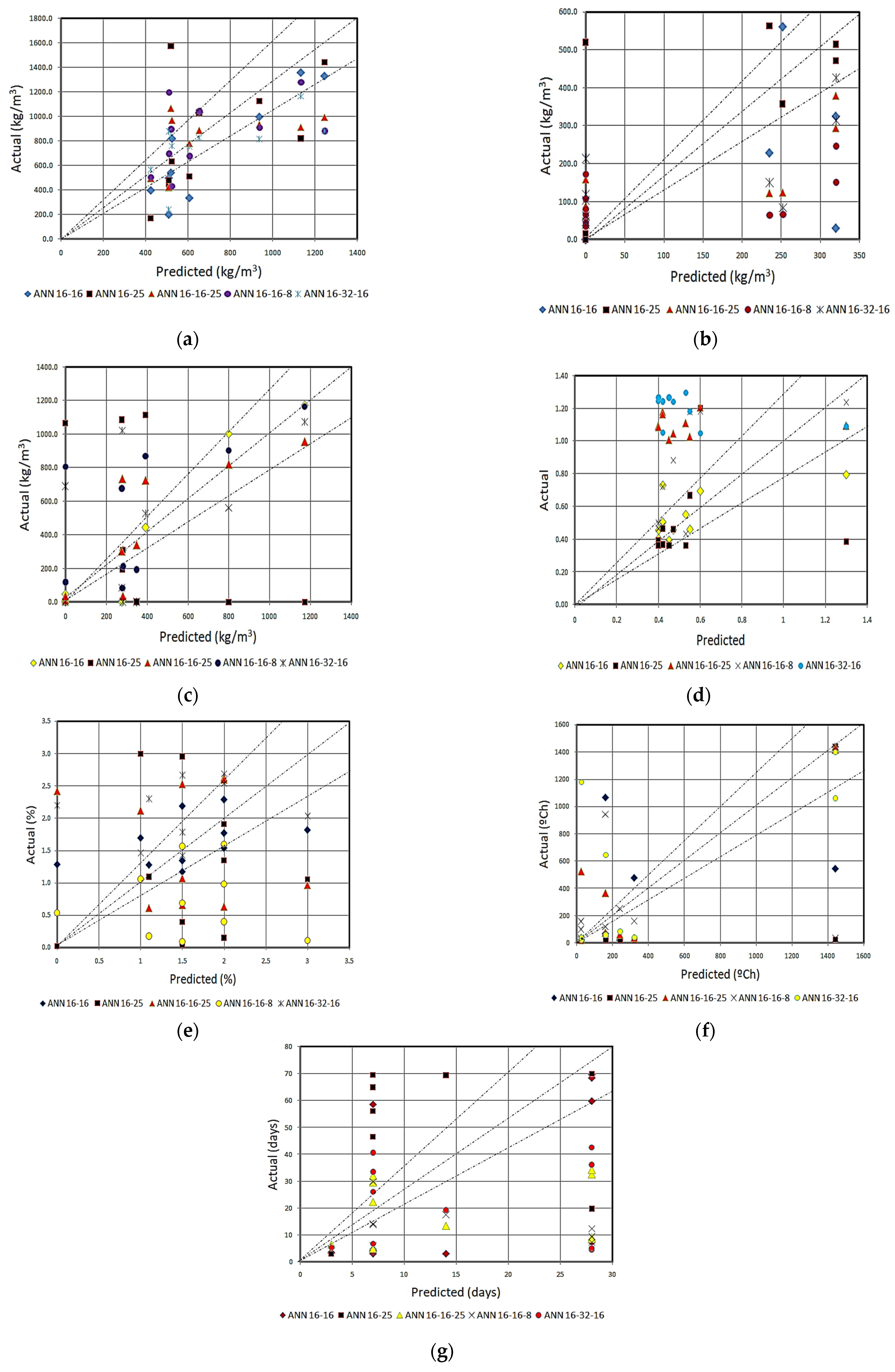
2) was performed for the predictions of mix-design obtained from the five best ANN-I models. The prediction results and the experimental literature database are summarized through
Table 4a–g with the coefficient of determination values. The results have been summarized as individual outputs of five ANN-I models. As mentioned earlier, the prediction of mix-design influencing factors with the variance of ±20% is quite acceptable, i.e., a coefficient of determination greater than 80% is considered to be the best result. Thus, perfect line analysis showing the variance of ±20% lines has been included in regression plots. However, a smaller coefficient of determination does not mean that the prediction is inaccurate or has lower predictive ability, for which the cross-validation was performed.
The fly ash content was predicted with the maximum accuracy of 75% with ANN [2:16:16:7] model upon regression analysis with the validation dataset, as shown in
Figure 5a. The highest prediction accuracy was obtained with the sand content prediction with the same ANN model with an accuracy of 85%. Similarly, looking upon GGBS prediction with the same ANN model, it was observed to be 48%, which is quite phenomenal. Thus, it is inferred that ANN [2:16:16:7] model performs well in predicting the material contents. The material contents and their proportion form the major part of the mix design and it is suggested to use the model in determining the mix proportion of binding and aggregate materials. As per
Figure 5a of the perfect line analysis, it is observed that most of the predictions fall within the ±20% range.
As far as the GGBS content prediction is concerned, 62% accuracy was achieved with ANN [2:16:16:25:7] model. The best prediction achieved was with ANN [2:16:16:7] model concerning the arithmetic error, i.e., with the validation dataset, this ANN model recognized wherever “0” content was exhibited and the arithmetic variance of other datasets were quite acceptable. In predicting the GGBS content, all the five ANN-I models performed well with 50% accuracy in regression, as shown in
Figure 5b. Briefly, 85% and 70% accuracy were obtained in predicting the sand content with ANN [2:16:16:7] and ANN [2:16:16:25:7], respectively, as per
Figure 5c. The former model is suggested in predicting the sand content since it was the most notable achievement in prediction [
21].
The prediction of the mix-design factor for activator/binder ratio shows two accumulations throughout the scatter plots, as shown in
Figure 5d. One of the accumulations lies within the 20% boundary, whereas the other group of values was a little far away from the acceptable range. Whereas predicting the PVA fiber percentage shows the distribution of values/results throughout the graph, only a few percent of the results are within the acceptable range, as shown in
Figure 5e. This is primarily because the ranges of these inputs were very low and the availability of an experimental literature database is not adequate. It is suggested to use the nominal values for activator/binder ratio and PVA volume fraction of the design of SHGC.
As shown in
Figure 4f,g, most predictions lie outside the 20% range. Though the ranges of the output “curing temperature x hours” is large as indicated in
Table 2, the values in the dataset were not uniformly distributed. 50% of the datasets lie within 25 °C.h whereas the other datasets were close to 1440 °C.h. The availability of large databases for training would help to avoid such inaccurate predictions. The ANN [2:16:16:25:7] model predicted the output with the accuracy of 86%, as per
Table 4f, but it was difficult to recognize whether to go for the type of curing. As per
Table 4g, ANN [2:16:16:7] could only predict the curing days to some extent, but the other models could not produce any significant results. The outputs obtained for this particular mix factor “curing temperature x hours” can be viewed in two ways. For output “100”, does it mean 100 °C for 1 h or 25 °C for 4 h? In geopolymer technology, the choice of ambient curing for long curing days or elevated temperature curing with a shorter duration depends entirely on the structural application [
51]. Similarly, using the nominal curing temperature and curing type is suggested based on its structural application; however, the ANN models gave the optimized duration for the desired mix.
6.2. Regression Analysis of Validation of ANN-II Model
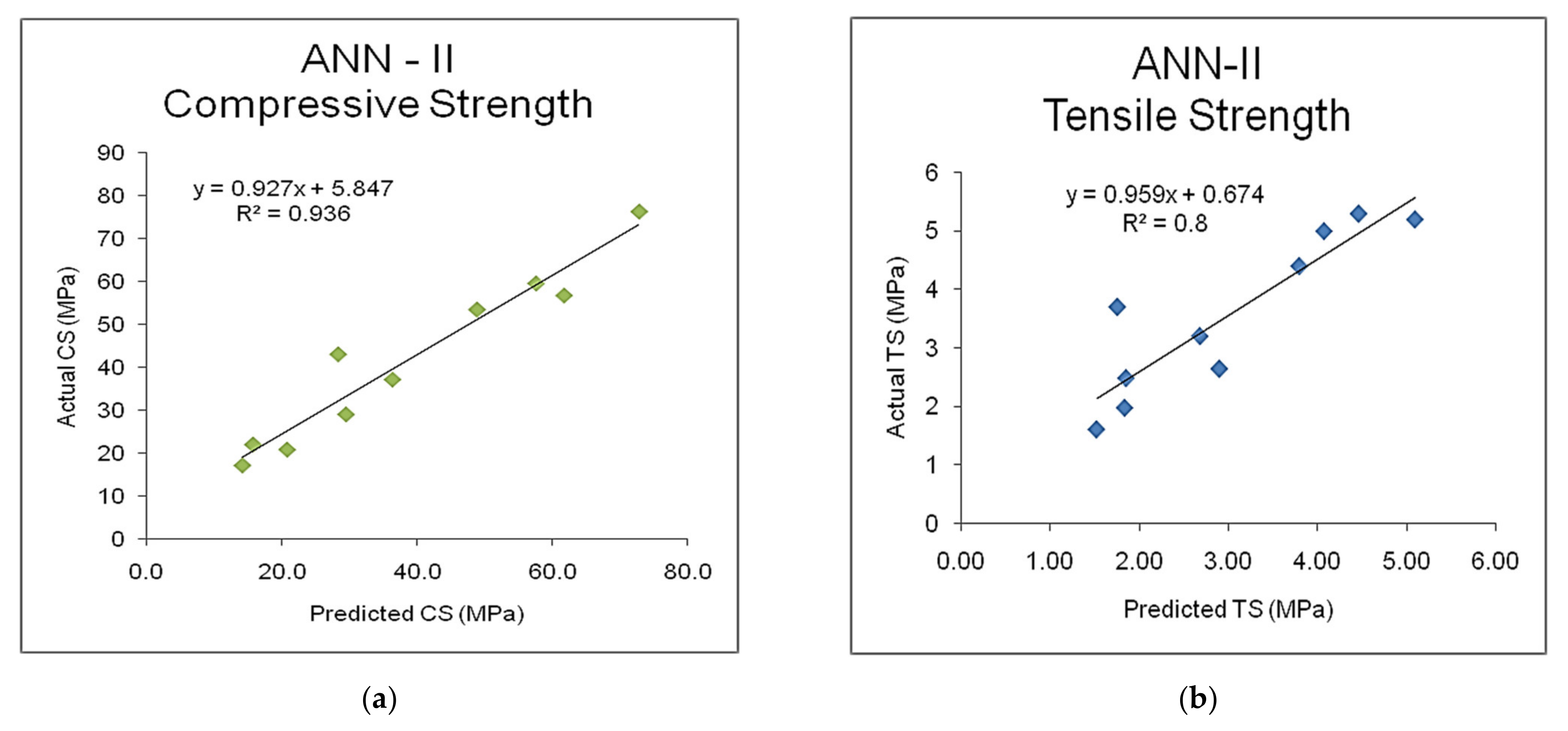
A GDX based ANN model was trained and validated with seven mix-design factors as inputs and compressive and tensile strength as outputs. To test the predictive ability and cross-validating ability of the ANN-II model, the validation dataset was also used, and the predicted results are compared with the experimental literature database.
Table 5 shows the comparison between the predicted output and literature experimental database along with the coefficient of determination, and root-mean-squared error (RMSE) upon testing the model. It is observed that overall 94% accuracy was obtained with the ANN-II model in predicting the compressive strength with those seven mix-design factors as inputs. It is adequate to check for the arithmetic error between the prediction and original data for more sensitive parameters like compressive strength. As given in
Table 5, on average, a magnitude of four was obtained as RMSE, which is quite acceptable. The regression analyses of the predicted outputs of compressive and tensile strengths and the experimental literature database are illustrated in
Figure 6a,b, respectively.
6.3. Tack-Together Outputs
Based on the regression analysis of mix-design prediction, each factor is isolated upon maximum coefficient of determination and tacked-together. The predicted outputs ANN [2:16:16:7] model showed the maximum accuracy of 74% in predicting the fly ash content; thus from the output fly ash content, the predicted results of ANN [2:16:16:7] were chosen. The same model’s prediction for the output sand content also was chosen because of its maximum accuracy of 85%. Similarly, the other five mix-design factors were also isolated and tacked together.
Adjusted values were taken for outputs activator/binder ratio and PVA fiber (%). For curing temperature x hours, ANN [2:16:16:25:7], and for ambient curing days, ANN [2:16:16:7] were chosen for its maximum accuracy. However, adjustments to the nominal values can be made wherever required, as described earlier. The tacked-together outputs of mix design are shown in
Table 6, which was also cross-validated to test its accuracy.
6.4. Cross-Validation of Mix Design and ‘Tacked-Together (TT)’ Outputs
The predicted mix design from ANN-I models (illustrated in
Table 4a–g) was given as inputs to the ANN-II model that can anticipate the compressive strength, i.e., the outputs obtained from LM-ANN (ANN-I) models were given as inputs to the GDX-ANN (ANN-II) model and the compressive strength was predicted, which was analyzed with the original experimental data as cross-validation. Apart from this, the combination of mix design obtained from the tacked-together model was also analyzed. The predicted compressive and tensile strength of ANN-II model as cross-validation, along with the literature experimental database upon regression analysis and RMSE are presented in
Table 7a,b.
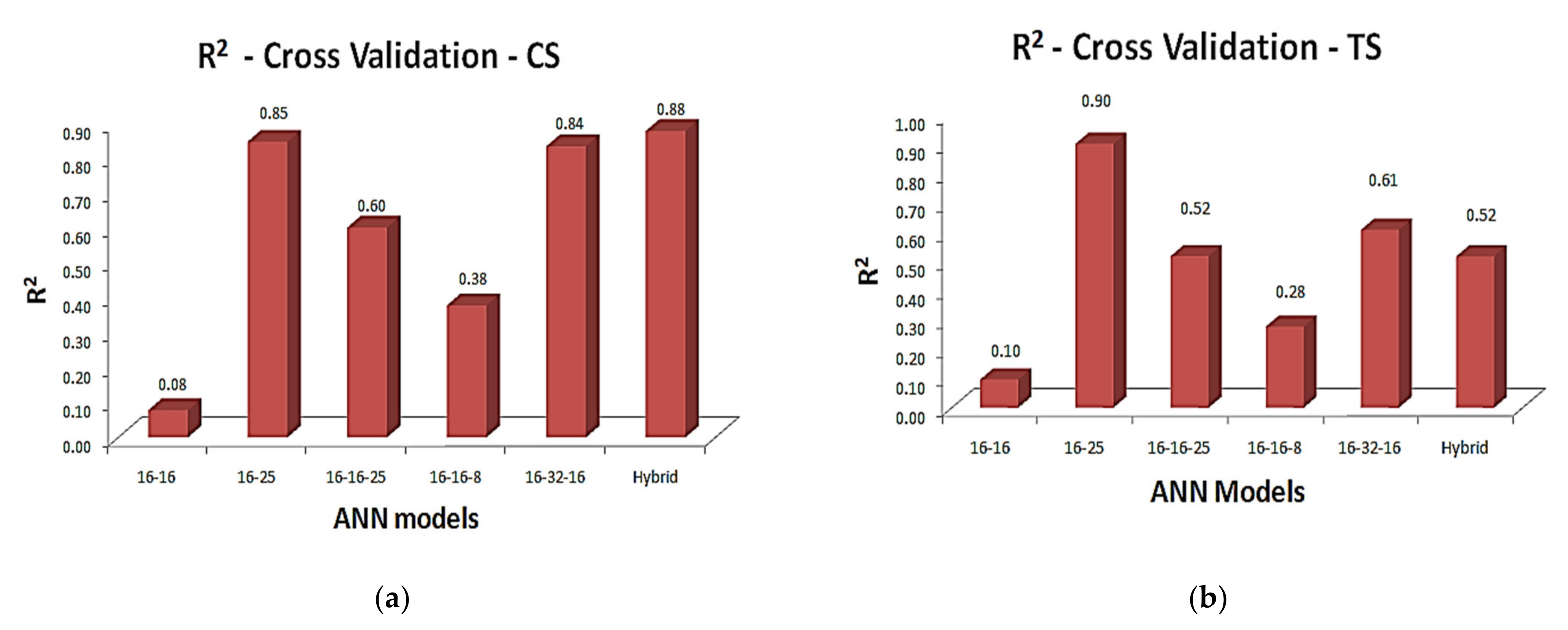
The regression analysis with a coefficient determination of ANN-I models and the hybrid model upon cross-validation for compressive and tensile strength are illustrated in
Figure 7a,b, respectively. Some interesting results could be observed upon cross-validation. For ANN [2:16:16:7] model, five outputs out of seven showed greater accuracy in terms of regression analysis, which as a whole mix fails in cross-validation, since as per the GDX-ANN model, the mix can give the compressive strength with only 8% accuracy, which is unreliable. In the same way, the ANN [2:16:25:7] and [2:16:32:16:7] models, which were not up to the mark upon regression analysis, showed accuracy of 85% in cross-validation, with the least RMSE, of magnitudes 7.45 and 8.53 respectively.
As discussed in
Section 3, the ANN-I models may fail upon individual regression analysis, but the models may perform best as a combination of the seven mix-design factors. Thus, it can be suggested to use those two models to predict the mix-design of SHGC upon the compressive strength with those mix-factors and curing conditions.
As per
Table 8, cross-validation of tacked-together outputs shows the accuracy up to 88% upon compressive strength and 52% upon tensile strength. The interesting interpretation here was five mix-design factors of ANN [2:16:16:7] model outputs (best ANN-I model upon regression analysis) and two mix-design factors of ANN [2:16:25:7] outputs (best ANN-I model upon cross-validation) were tacked together, which also performed best upon cross-validation.
The ANN model [2:16:25:7], which performed well upon compressive strength, was also found to be best upon the tensile strength, with the predictive ability of up to 90% with RMSE 0.27, which is phenomenal, as indicated in
Table 7b. For materials like EGC, its application in the field is mainly due to its high tensile strain capacity than conventional concrete. Thus, it is mandatory to achieve its desired tensile strength. The ANN model [2:16:16:7] showed better regression analysis, but upon cross-validation, it showed the accuracy only up to 10%, with huge RMSE, which is not highly recommended.
As far as the tacked-together model upon cross-validation is concerned, the combination of individual best results of ANN-I models as a mix also showed greater accuracy up to the level of 88% on compressive strength but showed accuracy of only 54% on tensile strength. Thus, it is also suggested to use the tacked-together output combinations of different trained ANN models to predict the mix-design of SHGC with proper nominal adjustments when compressive strength is the primary concern. It is also to be noted that the ANN-II model showed accuracy of 94% only, i.e., the coefficient of determination obtained from cross-validation may still have improved accuracy beyond the results obtained.
7. Conclusions
The ANN technique was attempted to predict the mix-design of SHGC for its desired compressive and tensile strength including curing conditions. Five LM-based ANN models were developed to predict seven mix-design factors based on two inputs, compressive and tensile strengths. The predicted outputs of these five models were analyzed upon regression using a coefficient of determination. The best resulting outputs of those five best models were summarized and “tack-together mix-design” was framed and also analyzed. A GDX-based ANN model was developed, trained, and tested with 94% accuracy to predict the compressive strength for cross-validation. The outputs obtained from LM-based ANN models were fed as inputs to GDX-based ANN for cross-validation. The regression and cross-validation results were analyzed, from which the following conclusions have been summarized.
This research study reveals that the basic mix-design parameters required to design the material EGC are feasible with few LM-based ANN models which can be cross-analyzed with GDX-based ANN and if only these seven mix-design influencing factors are involved, then ANN [2:16: 25:7] can be used to predict the mix which can be cross verified with GDX-ANN [7:14:2] for ensuring accuracy.
The five best ANN models that can predict the mix-design of SHGC were LM-based ANN [2:16:16:7], ANN [2:16:25:7], ANN [2:16:16:25:7], ANN [2:16:16:8:7], and ANN [2:16:32:16:7], and the best model for cross-validation was GDX-based ANN [7:14:2].
A few models, i.e., ANN [2:16:16:7], performed well on regression analysis, which failed to perform cross-validation. This insists on the importance of cross-validating since to predict the mix-design of composites, the performance of the combination of all the factors is the key concern and not the performance of individual factors/materials.
Even though the ANN [2:16:25:7] model showed less accuracy upon regression analysis, it performed well on cross-validation with the accuracy of prediction up to 85% and 90% upon compressive and tensile strength.
In addition to the identification of each best mix-design factor upon regression analysis, isolating and tacking-together also performed best with the accuracy of 88% upon cross-validation.
Thus it is recommended to use those predictive models for the material design of EGC involving the aforesaid mix factors with fewer trial mixes. This would certainly reduce the cost and time of trial experiments. However, the models cannot be applied directly for EGC involving surplus mix-factors.
Future Scope
The material EGC is in the developmental stage, so there may be the need for analytical and experimental studies in various aspects of EGC, such as material development, structural behaviors, micro-structural enhancements, etc. The utilization of such ANN models reduces the trial mixes in the methodology and finds its way to develop more accurate predictive models, as larger availability of data certainly strengthens the training stage of predictive models. This will allow researchers to develop more accurate predictive models with various other-computing techniques such as response surface methodology, gene expression programming, and other optimization techniques.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}