


Assessment of the Applicability of Selected Data Mining Techniques for the Classification of Mortars Containing Recycled Aggregate


Abstract
1. Introduction
2. Materials and Methods
2.1. Materials
2.2. Methods
2.2.1. Physico-Mechanical Research Methods
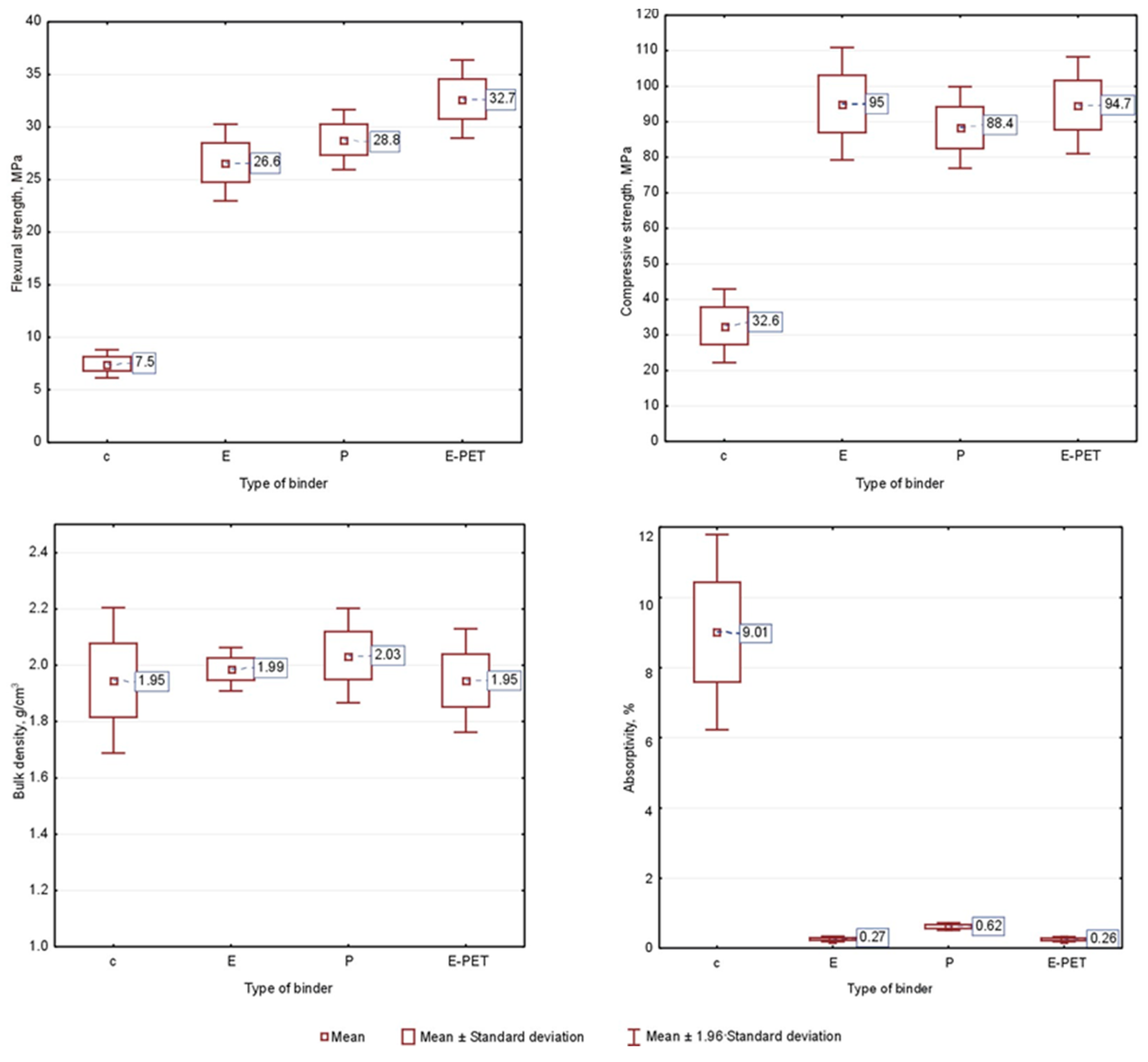
- Flexural and compressive strength
- Bulk density
- bd—bulk density, g/cm3,
- m—sample weight, g,
- V—sample volume, cm3.
- Absorptivity
- Abs—absorptivity, %,
- mn—mass of the sample saturated with water, g,
- ms—mass of the sample dried to constant mass, g.
2.2.2. Statistical Methods
- Discriminant analysis
- The learning stage (model building), in which classification rules are created based on the research results stored in the database.
- 2.
- The classification stage, in which a set of objects, the membership of which is unknown, is classified based on previously identified class characteristics.
- Decision trees (classification)
- ➢
- Root, the beginning of the recursive partitioning process;
- ➢
- The branches lead from the root to the next nodes;
- ➢
- Node, a place where a certain condition concerning a given observation is checked, and on its basis one of the branches leading to the next, lower node is selected;
- ➢
- Parent of nodes, the place from which branches directed to subsequent nodes emerge;
- ➢
- Descendants, nodes connected to the parent;
- ➢
- Leaf—terminal node terminating the path of inference in which there is no subdivision of data (no children). It contains information about the assignment of data in a subspace to a specific class.
- Cluster analysis
- (a)
- Hierarchical agglomeration—hierarchical cluster analysis.
- (b)
- Iterative division in the light of the selected criterion, e.g., minimizing the dispersion within a cluster—cluster analysis using the k-means method.
3. Results and Discussion
3.1. Descriptive Statistics
3.2. Discriminant Analysis
3.3. Decision Trees
- Rule 1: if flexural strength ≤ 11.446 MPa then c;
- Rule 2: if flexural strength ≥ 11.446 MPa and absorptivity ≥ 0.42204% then P;
- Rule 3: if absorptivity ≤ 0.42204% and flexural strength ≥ 29.417 MPa then E-PET;
- Rule 4: if absorptivity ≤ 0.42204% and flexural strength ≥ 11.446 MPa and flexural strength ≤ 29.417 MPa then E.
3.4. Cluster Analysis
4. Conclusions
- It was found that the modification of cement and resin mortars, consisting in partial replacement of aggregate with PE waste agglomerate, allows for obtaining mortars with very good strength parameters;
- It has been observed that the inclusion of waste into the composition of the mortar does not significantly change the bulk density and water absorption;
- It has been shown that simultaneous modification of mortar composition by glycolysate formed on the basis of PET waste and PE waste agglomerate has a particularly beneficial effect on the properties and cost of obtaining epoxy mortars;
- The variety and multiplicity of data mining methods make it difficult for potential users to choose the methods that are most appropriate to their data analysis needs. When different methods give similar results, the strength of the conclusions drawn increases;
- The three methods of data mining used led to similar results; however, in the discriminant analysis, the degree of correctness of the classification is much lower than in the other two methods;
- On the other hand, unlike decision trees and cluster analysis, discriminant analysis allows one to build classification functions that make it possible to predict the composition of mortars for a larger number of desired properties;
- For decision trees and cluster analysis, the ease of understanding and interpretation of the visualized results is important. The possibility of creating logical decision rules on their basis may be easier to interpret than explaining the meaning of the coefficients of the generated classification functions obtained after applying discriminant analysis;
- The developed methodology for creating classification systems can be used in research on other composites.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- da Silva, T.R.; de Azevedo, A.R.G.; Cecchin, D.; Marvila, M.T.; Amran, M.; Fediuk, R.; Vatin, N.; Karelina, M.; Klyuev, S.; Szelag, M. Application of Plastic Wastes in Construction Materials: A Review Using the Concept of Life-Cycle Assessment in the Context of Recent Research for Future Perspectives. Materials 2021, 14, 3549. [Google Scholar] [CrossRef] [PubMed]
- Beghetto, V.; Sole, R.; Buranello, C.; Al-Abkal, M.; Facchin, M. Recent Advancements in Plastic Packaging Recycling: A Mini-Review. Materials 2021, 14, 4782. [Google Scholar] [CrossRef] [PubMed]
- Shang, M.; Li, H.; Ahmad, A.; Ahmad, W.; Ostrowski, K.A.; Aslam, F.; Joyklad, P.; Majka, T.M. Predicting the Mechanical Properties of RCA-Based Concrete Using Supervised Machine Learning Algorithms. Materials 2022, 15, 647. [Google Scholar] [CrossRef] [PubMed]
- Belmokaddem, M.; Mahi, A.; Senhadji, Y.; Pekmezci, B.Y. Mechanical and physical properties and morphology of concrete containing plastic waste as aggregate. Constr. Build. Mater. 2020, 257, 119559. [Google Scholar] [CrossRef]
- Jacob-Vaillancourt, C.L. Characterization of concrete composites with recycled plastic aggregates from postconsumer material streams. Constr. Build. Mater. 2018, 182, 561–572. [Google Scholar] [CrossRef]
- Assaad, J.J.; Khatib, J.M.; Ghanem, R. Bond to Bar Reinforcement of PET-Modified Concrete Containing Natural or Recycled Coarse Aggregates. Environments 2022, 9, 8. [Google Scholar] [CrossRef]
- Li, G.; Zhang, L.; Zhao, F.; Tang, J. Acoustic Emission Characteristics and Damage Mechanisms Investigation of Basalt Fiber Concrete with Recycled Aggregate. Materials 2020, 13, 4009. [Google Scholar] [CrossRef]
- Thorneycroft, J.; Orr, J.; Savoikar, P.; Ball, R.J. Performance of structural concrete with recycled plastic waste as a partial replacement for sand. Constr. Build. Mater. 2018, 161, 63–69. [Google Scholar] [CrossRef]
- Jones, H.; Saffar, F.; Koutsos, V.; Ray, D. Polyolefins and Polyethylene Terephthalate Package Wastes: Recycling and Use in Composites. Energies 2021, 14, 7306. [Google Scholar] [CrossRef]
- Awoyera, P.O.; Adesina, A. Plastic wastes to construction products: Status, limitations and future perspective. Case Stud. Constr. Mater. 2020, 12, e00330. [Google Scholar] [CrossRef]
- Meza, A.; Pujadas, P.; Meza, L.M.; Pardo-Bosch, F.; López-Carreño, R.D. Mechanical Optimization of Concrete with Recycled PET Fibres Based on a Statistical-Experimental Study. Materials 2021, 14, 240. [Google Scholar] [CrossRef] [PubMed]
- Poonyakan, A.; Rachakornkij, M.; Wecharatana, M.; Smittakorn, W. Potential Use of PlasticWastes for Low Thermal Conductivity Concrete. Materials 2018, 11, 1938. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Xu, L.; Xuan, W.; Zhou, Z. Experimental study on four-point cyclic bending behaviours of concrete with high density polyethylene granules. Constr. Build. Mater. 2019, 201, 691–701. [Google Scholar] [CrossRef]
- Dębska, B.; Lichołai, L. Long-term chemical resistance of ecological epoxy polymer composites. J. Ecol. Eng. 2018, 19, 204–212. [Google Scholar] [CrossRef]
- STATISTICA 12, StatSoft Polska Sp. z. o. o. Available online: www.statsoft.pl (accessed on 10 November 2022).
- Ahmad, M.; Hu, J.-L.; Ahmad, F.; Tang, X.-W.; Amjad, M.; Iqbal, M.J.; Asim, M.; Farooq, A. Supervised Learning Methods for Modeling Concrete Compressive Strength Prediction at High Temperature. Materials 2021, 14, 1983. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, A.; Farooq, F.; Niewiadomski, P.; Ostrowski, K.; Akbar, A.; Aslam, F.; Alyousef, R. Prediction of Compressive Strength of Fly Ash Based Concrete Using Individual and Ensemble Algorithm. Materials 2021, 14, 794. [Google Scholar] [CrossRef]
- Chaabene, W.B.; Flah, M.; Nehdi, M.L. Machine learning prediction of mechanical properties of concrete: Critical review. Constr. Build. Mater. 2020, 260, 119889. [Google Scholar] [CrossRef]
- Rathakrishnan, V.; Beddu, S.B.; Ahmed, A.N. Predicting compressive strength of high-performance concrete with high volume ground granulated blast-furnace slag replacement using boosting machine learning algorithms. Sci. Rep. 2022, 12, 9539. [Google Scholar] [CrossRef]
- Czarnecki, S.; Sadowski, Ł.; Hoła, J. Evaluation of interlayer bonding in layered composites based on non-destructive measurements and machine learning: Comparative analysis of selected learning algorithms. Autom. Constr. 2021, 132, 103977. [Google Scholar] [CrossRef]
- Tran, V.Q.; Mai, H.-V.T.; Nguyen, T.-A.; Ly, H.-B. Investigation of ANN architecture for predicting the compressive strength of concrete containing GGBFS. PLoS ONE 2021, 16, e0260847. [Google Scholar] [CrossRef]
- Malazdrewicz, S.; Sadowski, Ł. An intelligent model for the prediction of the depth of the wear of cementitious composite modified with high-calcium fly ash. Compos. Struct. 2021, 259, 113234. [Google Scholar] [CrossRef]
- Kang, M.-C.; Yoo, D.-Y.; Gupta, R. Machine learning-based prediction for compressive and flexural strengths of steel fiber-reinforced concrete. Constr. Build. Mater. 2021, 266, 121117. [Google Scholar] [CrossRef]
- Wang, F.; Wang, Q.; Nie, F.; Li, Z.; Yu, W.; Ren, F. A linear multivariate binary decision tree classifier based on K-means splitting. Pattern Recognit. 2020, 107, 107521. [Google Scholar] [CrossRef]
- Behnood, A.; Golafshani, E.M. Machine learning study of the mechanical properties of concretes containing waste foundry sand. Constr. Build. Mater. 2020, 243, 118152. [Google Scholar] [CrossRef]
- Behnood, A.; Behnood, V.; Gharehveran, M.M.; Alyamac, K.E. Prediction of the compressive strength of normal and high-performance concretes using M5P model tree algorithm. Constr. Build. Mater. 2017, 142, 199–207. [Google Scholar] [CrossRef]
- Arora, S.; Singh, B.; Bhardwaj, B. Strength performance of recycled aggregate concretes containing mineral admixtures and their performance prediction through various modeling techniques. J. Build. Eng. 2019, 24, 100741. [Google Scholar] [CrossRef]
- Madra, A.; Adrien, J.; Breitkopf, P.; Maire, E.; Trochu, F. A clustering method for analysis of morphology of short natural fibers in composites based on X-ray microtomography. Compos. Part A 2017, 102, 184–195. [Google Scholar] [CrossRef]
- Jain, D.; Mukherjee, A.; Bera, T.K. A novel characterization method of fiber reinforced polymers with clustered microstructures for time dependent mass transfer. Sci. Eng. Compos. Mater. 2018, 25, 1003–1014. [Google Scholar] [CrossRef]
- Kılınçarslan, Ş.; İnce, E.Y.; Tuncay, E.B.; Yağmurlu, F. Clustering Analysis of Normal Strength Concretes Produced with Different Aggregate Types. Open Chem. 2018, 16, 918–922. [Google Scholar] [CrossRef]
- PN-EN 196-1: 2016-07; Cement Testing Methods—Part 1: Determination of Strength. PKN: Warsaw, Poland, 2016.
- Vítková, G.; Prokeš, L.; Novotný, K.; Pořízk, P.; Novotný, J.; Všianský, D.; Čelko, L.; Kaiser, J. Comparative study on fast classification of brick samples by combination of principal component analysis and linear discriminant analysis using stand-off and table-top laser-induced breakdown spectroscopy. Spectrochim. Acta Part B At. Spectrosc. 2014, 101, 191–199. [Google Scholar] [CrossRef]
- Sutton, C.D. Classification and regression trees, bagging and boosting. In Handbook of Statistics; Pfefferman, D., Ed.; Elsevier: New York, NY, USA, 2010; pp. 303–327. [Google Scholar] [CrossRef]
- Koronacki, J.; Ćwik, J. Statystyczne Systemy Uczące Się; Oficyna Wydawnicza Exit: Warszawa, Poland, 2008. [Google Scholar]
- Almuallim, H.; Kaneda, S.; Akiba, Y. Development and applications of decision trees. Expert. Syst. 2002, 1, 53–77. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Supervised machine learning: A review of classification techniques. Informatica 2007, 31, 249–268. [Google Scholar]
- StatSoft. Elektroniczny Podręcznik Statystyki PL, Krakow. 2006. Available online: http://www.statsoft.pl/textbook/stathome.html (accessed on 10 November 2022).
- Maciejewska, M. Analiza Danych w Czujnikowych Pomiarach Zanieczyszczeń Powietrza; Oficyna Wydawnicza Politechniki Wrocławskiej: Wrocław, Poland, 2012. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cement Properties | |||||
|---|---|---|---|---|---|
| Cement Type | Compressive Strength (28 Day), MPa | Loss on Ignition, % | Content of Sulphates, % | Chlorides Content, % | Beginning of Setting Time, min |
| CEM I 42,5 R | ≥42.5, ≤62.5 | ≤5 | ≤4.0 | ≤0.10 | ≥60 |
| Resin Properties | |||||
|---|---|---|---|---|---|
| Resin Type | Density, g/cm3 | Viscosity 25 °C, mPa s | Molecular Weight, g/mol | Epoxy Count LE, mol/100 g | Acid Numer LK, mg KOH/g |
| Epidian 5 | 1.17 | 30,000 | 450 | 0.49 | - |
| Polimal 109 | 1.10–1.16 | 350 | - | - | 32 |
| Hardener Properties | ||||
|---|---|---|---|---|
| Hardener Type | Density, g/cm3 | Gel Time, min | Viscosity 25 °C, mPa s | Amine Number, mg KOH/g |
| Z-1 | 0.978–0.983 | - | 20–30 | Min. 1100 |
| Metox-50 | 1.169–1.175 | 24–26 | - | - |
| Summary of the Discriminant Function Analysis: N var. in the Model: 4; Grouping: Type of Binder (4 Groups) Wilks’ Lambda: 0.00306 Approximately F (12.3) = 197.6 p < 0.0000 | ||||||
|---|---|---|---|---|---|---|
| N = 120 | Wilks’ Lambda | Partial Wilks | F Removed (3.113) | p | Toler. | 1-Toler. (R2) |
| Flexural strength | 0.017 | 0.176 | 176.55 | 0.0000 | 0.502 | 0.498 |
| Compressive strength | 0.006 | 0.507 | 36.67 | 0.0000 | 0.384 | 0.616 |
| Bulk density | 0.004 | 0.692 | 16.73 | 0.0000 | 0.652 | 0.348 |
| Absorptivity | 0.006 | 0.529 | 33.95 | 0.0000 | 0.911 | 0.089 |
| Chi-Square Tests of the Following Roots | ||||||
|---|---|---|---|---|---|---|
| Roots Removed | Eigenvalue | Canonical R | Wilks’ Lambda | Chi-Square | df | p |
| 0 | 74.083 | 0.993 | 0.003 | 665.876 | 12 | 0.0000 |
| 1 | 2.376 | 0.839 | 0.229 | 169.237 | 6 | 0.0000 |
| 2 | 0.290 | 0.474 | 0.775 | 29.309 | 2 | 0.0000 |
| Standardized Coefficients for Canonical Variables | |||
|---|---|---|---|
| Variable | Root 1 | Root 2 | Root 3 |
| Flexural strength | 0.926 | 1.064 | −0.004 |
| Compressive strength | −0.109 | −1.269 | −0.794 |
| Bulk density | −0.422 | 0.288 | 1.027 |
| Absorptivity | −0.612 | 0.335 | −0.569 |
| Eigenvalue | 74.083 | 2.376 | 0.290 |
| Cum. prop. | 0.965 | 0.996 | 1.000 |
| Average Canonical Variables | |||
|---|---|---|---|
| Group | Root 1 | Root 2 | Root 3 |
| c | −14.454 | 0.364 | −0.084 |
| E | 3.259 | −2.505 | −0.183 |
| P | 4.142 | 0.578 | 0.857 |
| E-PET | 7.053 | 1.564 | −0.590 |
| Classification Functions; Grouping Variable: Type of Binder | ||||
|---|---|---|---|---|
| Variable | c p = 0.25 | E p = 0.25 | P p = 0.25 | E-PET p = 0.25 |
| Flexural strength | −0.523 | 8.060 | 10.692 | 13.101 |
| Compressive strength | −0.986 | −0.716 | −1.446 | −1.509 |
| Bulk density | 296.214 | 206.263 | 223.188 | 197.176 |
| Absorptivity | 21.846 | 5.342 | 5.200 | 4.319 |
| Constant (free term) | −370.081 | −280.149 | −320.095 | −336.198 |
| Learning Sample Misclassification Matrix Predicted (Row) × Observed (Column) Matrix Learning Sample N = 96 | ||||
|---|---|---|---|---|
| Class | Class c | Class E | Class P | Class E-PET |
| c | 0 | 0 | 0 | |
| E | 0 | 0 | 0 | |
| P | 0 | 0 | 0 | |
| E-PET | 0 | 0 | 0 | |
| Test Sample Misclassification Matrix Predicted (Row) × Observed (Column) Matrix CV Cost = 0; s.d. CV Cost = 0 | ||||
|---|---|---|---|---|
| Class | Class c | Class E | Class P | Class E-PET |
| c | 0 | 0 | 0 | |
| E | 0 | 0 | 0 | |
| P | 0 | 0 | 0 | |
| E-PET | 0 | 0 | 0 | |
| Variable | Between SS | df | Int. SS | df | F | Relevant p |
|---|---|---|---|---|---|---|
| Flexural strength | 111.63 | 3 | 7.37 | 116 | 585.71 | 0.00000 |
| Compressive strength | 112.05 | 3 | 6.95 | 116 | 623.41 | 0.00000 |
| Bulk density | 53.34 | 3 | 65.66 | 116 | 31.41 | 0.00000 |
| Absorptivity | 114.82 | 3 | 4.18 | 116 | 1061.05 | 0.00000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dębska, B. Assessment of the Applicability of Selected Data Mining Techniques for the Classification of Mortars Containing Recycled Aggregate. Materials 2022, 15, 8111. https://doi.org/10.3390/ma15228111
Dębska B. Assessment of the Applicability of Selected Data Mining Techniques for the Classification of Mortars Containing Recycled Aggregate. Materials. 2022; 15(22):8111. https://doi.org/10.3390/ma15228111
Chicago/Turabian StyleDębska, Bernardeta. 2022. "Assessment of the Applicability of Selected Data Mining Techniques for the Classification of Mortars Containing Recycled Aggregate" Materials 15, no. 22: 8111. https://doi.org/10.3390/ma15228111
APA StyleDębska, B. (2022). Assessment of the Applicability of Selected Data Mining Techniques for the Classification of Mortars Containing Recycled Aggregate. Materials, 15(22), 8111. https://doi.org/10.3390/ma15228111