

A Comparative Investigation of Machine Learning Algorithms for Pore-Influenced Fatigue Life Prediction of Additively Manufactured Inconel 718 Based on a Small Dataset



Abstract
:1. Introduction
2. Experimental Methods
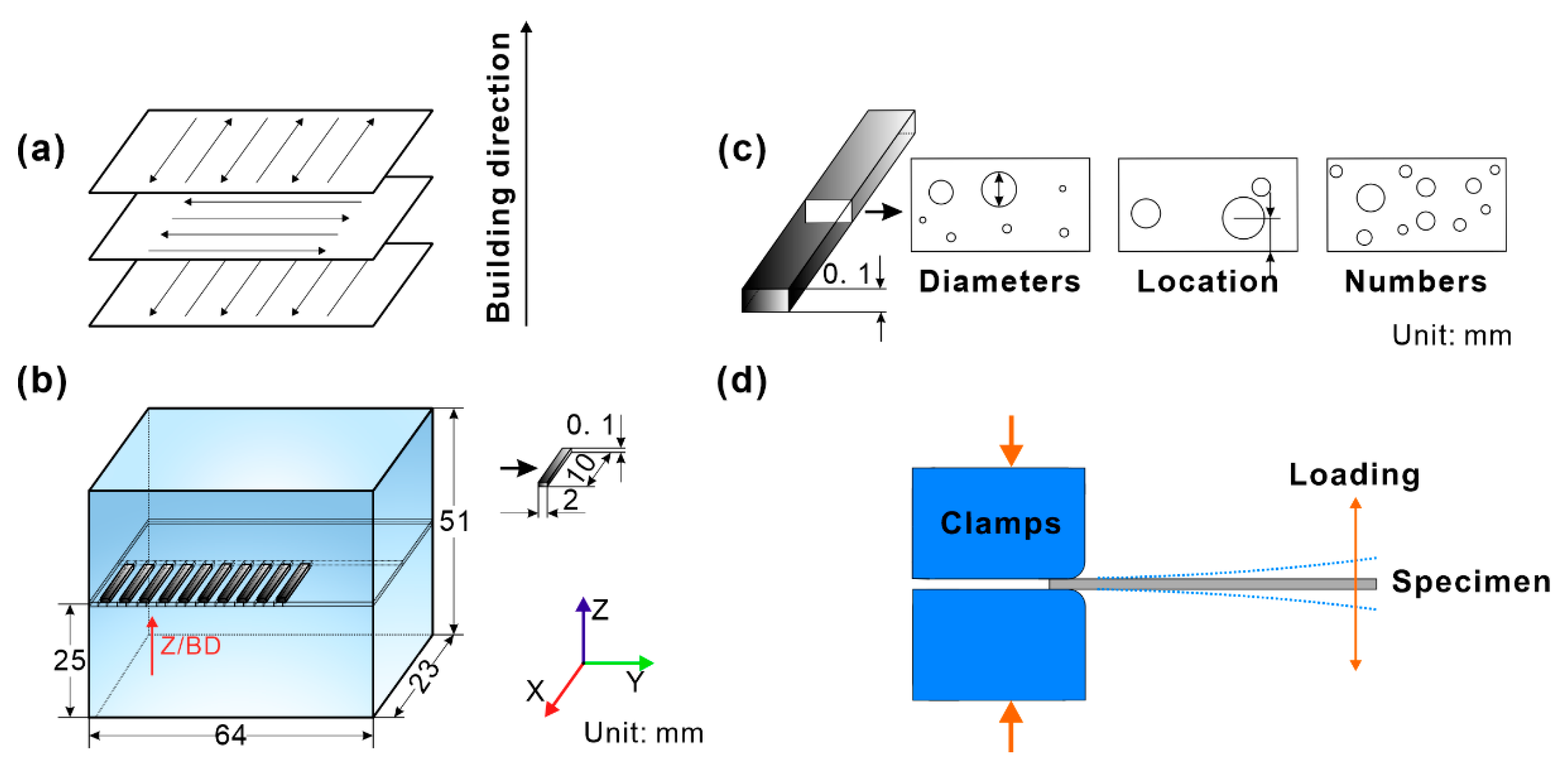
2.1. Specimen Preparation and Fatigue Testing
2.2. Finite Element Simulation Method
2.3. Microstructure Characterization
2.4. Dataset Acquisition
3. Machine Learning Methods
3.1. Machine Learning Framework
3.2. Data Preprocessing
- Division of dataset: First, 80% of the samples were selected randomly as a training dataset and 20% as a testing dataset. The Kolmogorov–Smirnov (K–S) test was then adopted to use the cumulative distribution function (CDF) for comparison of the consistency of distributions between the training and test sets under different features, as shown in Figure 3. The results indicated that the distribution of the training and test sets was approximately consistent. For more explanatory information, see Supplementary comments to Figure 3.
- 2.
- Data normalization: There are many ways to normalize data, and here, a simple max-min normalization method is adopted to standardize the fatigue dataset. More information on the simple max-min normalization method is present in Supplementary Information (SI) and shown in Figure S1.
- 3.
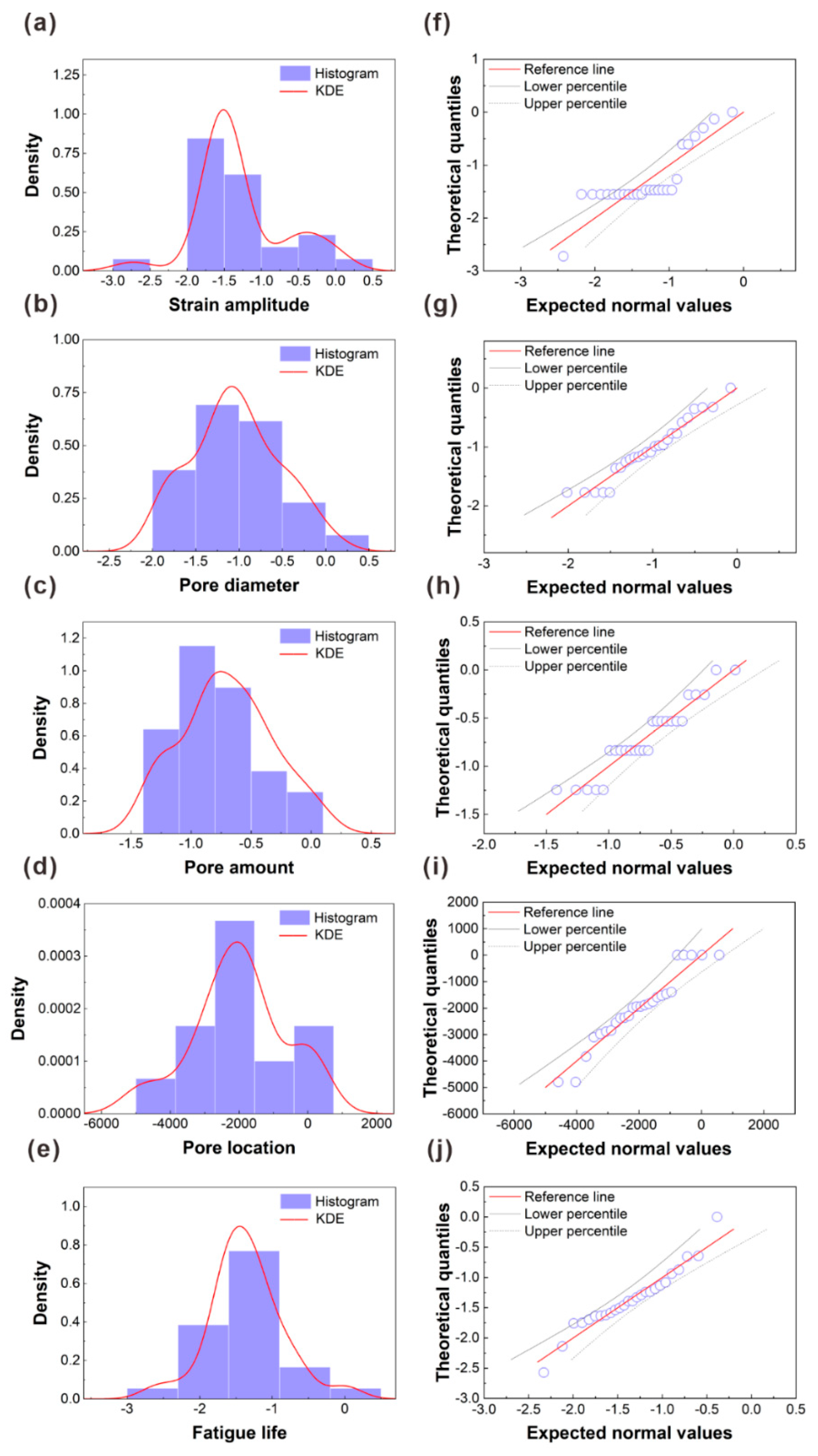
- Normal transformation: Figure S2 shows the Gaussian distribution for each feature in the normalized dataset. The results indicate that some features exhibit significant skewness issues, and detailed explanations and correction methods are shown in Figure S2 of SI. Figure 4 displays the Gaussian distribution of features in the dataset after normalization and Box–Cox transformation [38]. From Figure 4a–e, it is evident that the skewness of the features is improved compared to the distribution in Figure S2a–e in SI. Furthermore, compared to Figure S2f–j in SI, the data points for each feature more closely approximate the theoretical normal distribution line, as shown in Figure 4f–j, indicating the normality of the dataset was enhanced after the Box–Cox transformation.
3.3. ML Techniques
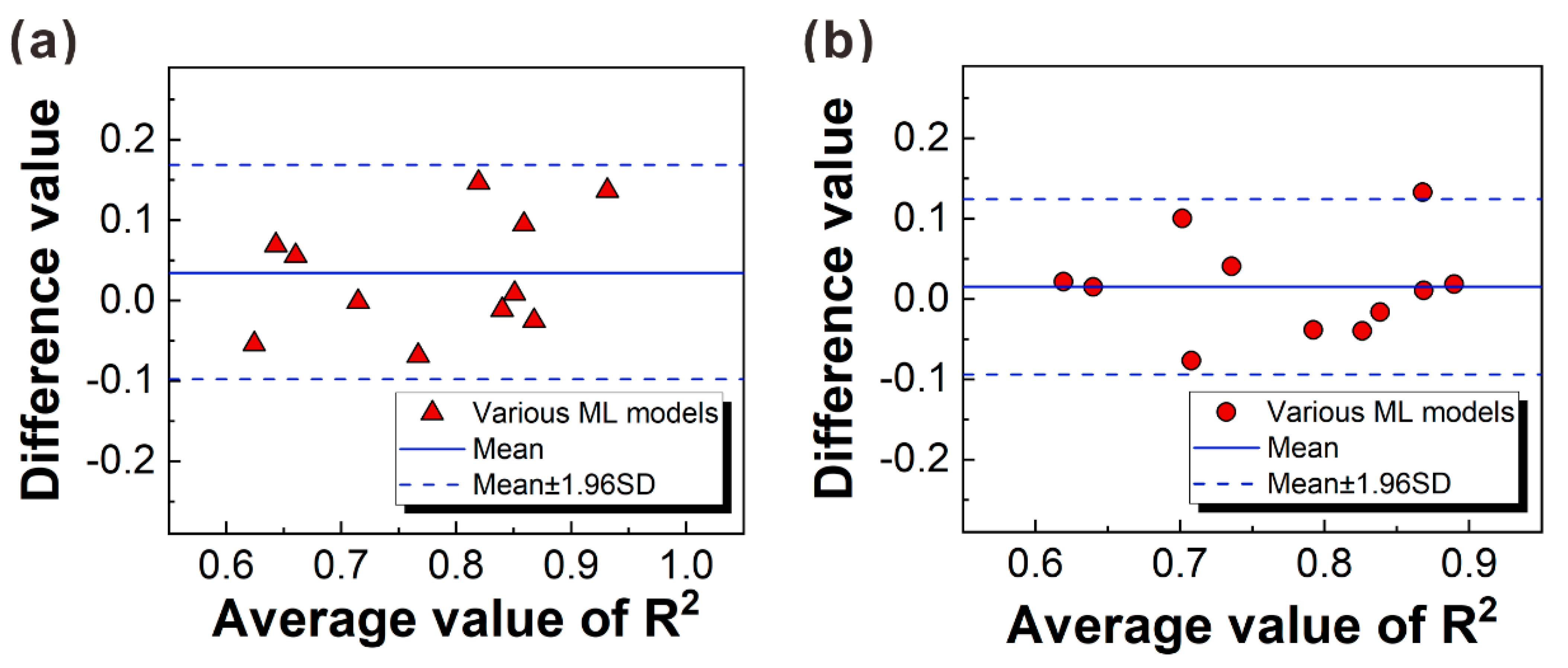
3.4. Reasonability of the Data Partitioning after Modeling
4. Finite Element Analysis of Effects of Surface Quality and Pore Features
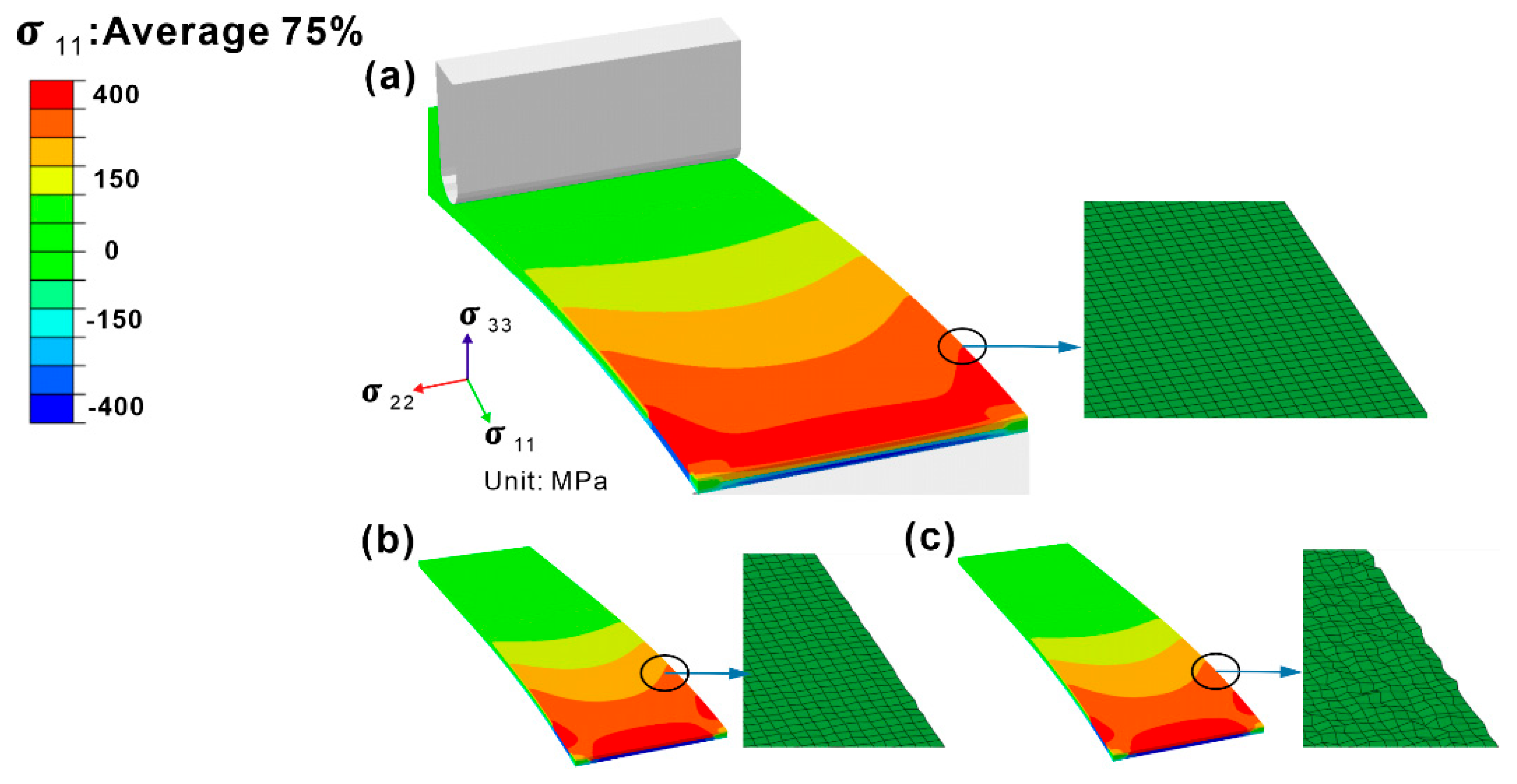
4.1. The Influence of Surface Quality
4.2. Analysis of the Interaction of Pore Feature and Stress Field under Bending Load
- For the specimen with pores on the surface (0 μm) and subsurface (5, 10, and 15 μm), increased with the increasing pore diameter from 4 μm to 16 μm. Among them, for the specimen with pores on the subsurface (5 μm), the increasing degree of became relatively large with the increase in pore diameter. However, for the specimen with pores in the matrix (30 μm and 45 μm), hardly changed with the increase in pore diameter, as shown by the red arrows in Figure 9.
- For specimens with three different pore diameters (4, 8, and 16 μm), significantly increased as the pore location increased from 0 μm (on the surface) to 5 μm (on the subsurface).
- For specimens with pore diameters of 4, 8, and 16 μm, as the pore location increased from 5 μm to 10 μm, slightly increased for specimens with a pore diameter of 4 μm. slightly decreased for specimens with pore diameters of 8 μm and 16 μm, and the reduction in for specimens with a pore diameter of 16 μm was the largest.
- of all specimens with pore diameters of 4, 8, and 16 μm showed a decreasing trend as the pore location increased from 10 μm to 15 μm. The reduction in of the 16 μm pore diameter specimen was also the largest.
- As the distance continued to increase toward the neutral plane along the thickness direction (30 μm), occurred on the specimen surface and significantly decreased, which was similar to that in the specimen with pores on the specimen surface. When the pore location became 45 μm, almost remained at a constant value at a location of 30 μm and did not change much.
5. Prediction Results and Discussion
5.1. Prediction Results of Fatigue Life
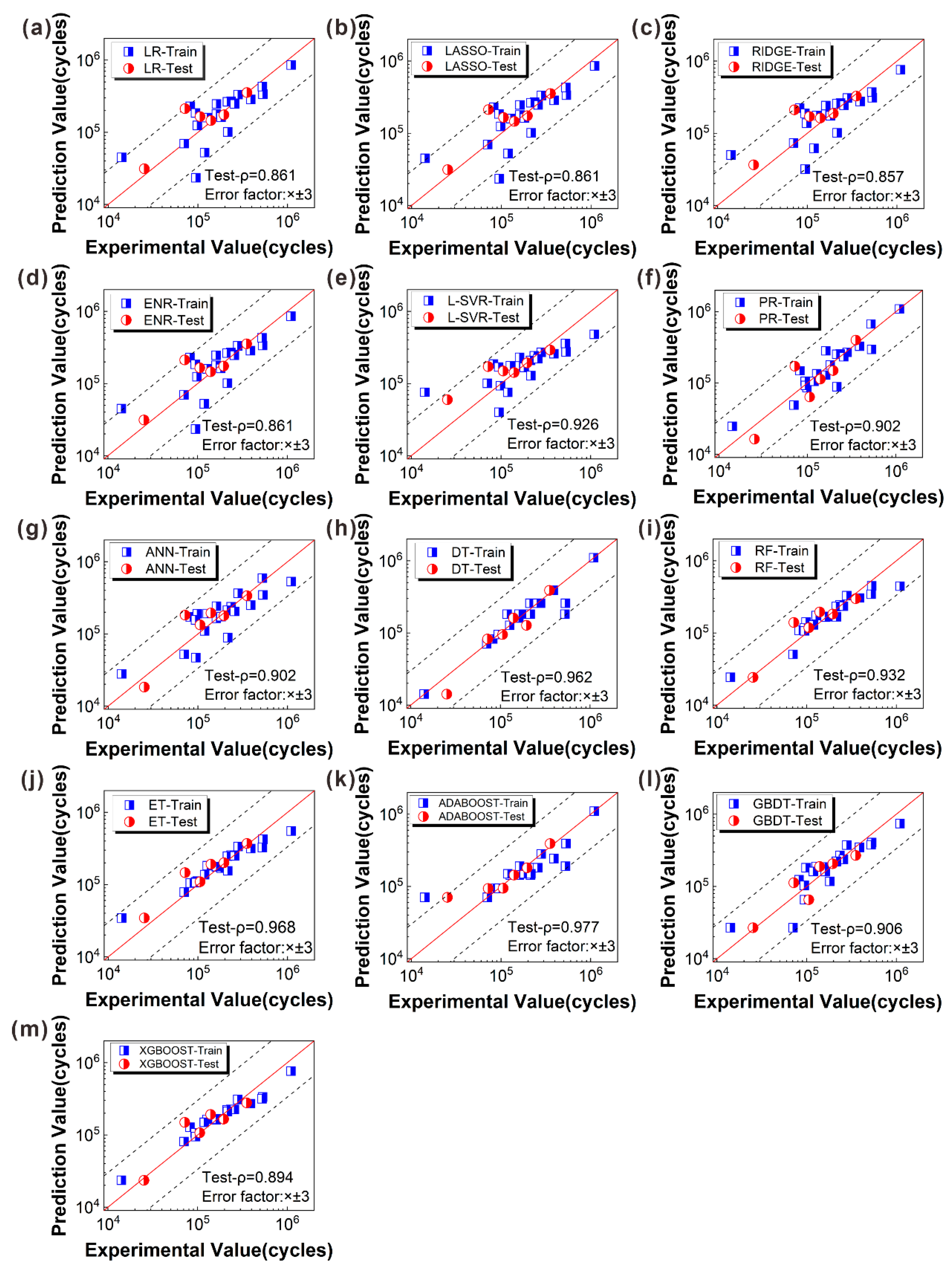
- Category of linear regression: For this category, the evaluation results of the model shown in Figure 10 are further discussed and analyzed. The L-SVR algorithm had the highest fitting accuracy (R2 = 0.752, MSE = 0.580) on the test set, while the fitting accuracy of the MLR model (R2 = 0.648, MSE = 0.854) on the test set was not ideal, and this study only reached the qualified level (R2 = 0.6). Since multicollinearity issues generally influence the predictive ability of models in linear regression, three regularization algorithms were proposed to check and address multicollinearity issues, including the LASSO algorithm (L1 regularization), the RIDGE algorithm (L2 regularization), and the ENR algorithm (L1 and L2 regularizations). The results in Figure 10 show that the accuracy of the three regularization models was not significantly improved compared to the MLR model. Among them, the fitting accuracy of the RIDGE algorithm decreased, which may have resulted from over-regularization. Thus, it is believed that there may not have been a multicollinearity problem in the small dataset, and the three regularization methods could not significantly improve the performance of the MLR model. In addition, the use of SVR was also investigated. However, when polynomial kernel functions, Gaussian kernel functions, or S-type kernel functions for model training were used, the evaluation results of the SVR-built model did not reach the qualified level. Ultimately, the L-SVR algorithm was selected for the model establishment, achieving a good fitting accuracy and being the best algorithm in the linear category. Zhao et al. [62] showed that the SVR algorithm had better generalization ability than the MLR algorithm in predicting the toxic activity of different datasets. Luo et al. [20] also demonstrated that the SVR algorithm was more suitable for fatigue life prediction of a small dataset than the MLR and RIDGE algorithms. This is consistent with the results of the above analysis.
- Category of nonlinear regression: Figure 10 also shows that the DT algorithm (R2 = 0.899, MSE = 0.193) had the highest fitting accuracy among the algorithms for this category, followed by the ANN algorithm (R2 = 0.756, MSE = 0.569), and finally, the PR algorithm (R2 = 0.670, MSE = 0.595). Although the PR algorithm was not sufficient to obtain a satisfactory prediction model, when the complete polynomial was used for fitting directly, the accuracy of the fitting improved after removing the combination term involving the feature itself. On the other hand, the ANN algorithm improved the fitting R2 value up to 0.756. The DT algorithm is rarely used for small datasets in predicting fatigue life, but research results showed that the R2 value of the DT algorithm was significantly improved to 0.899, and there was no overfitting phenomenon that often appears in this algorithm. Although the ANN algorithm is known for its strong robustness and is often used to establish prediction models, the above analysis shows that the DT algorithm is superior to the ANN algorithm in the prediction problem of pore-affected fatigue life.
- Bagging category: In the ensemble learning algorithms of this category, each learner has a parallel relationship. First, the RF algorithm used here achieved a better fitting accuracy of R2 = 0.830. Then, the corresponding prediction model was trained using the ET algorithm with a better generalization ability. Figure 10 shows that the fitting accuracy of the ET algorithm (R2 = 0.874, MSE = 0.258) was better than that achieved by the RF algorithm (R2 = 0.830, MSE = 0.354).
- Boosting category: Initially, the CART algorithm was used as the base learner, which was later enhanced by using the GBDT algorithm to build the predictive model, resulting in a good fitting effect (R2 = 0.806, MSE = 0.437). Subsequently, the XGBOOST algorithm was utilized to build the ML model, which had a lower overfitting probability. The evaluation result of the test set for this model was not significantly different from that (R2 = 0.773, MSE = 0.524) of the GBDT algorithm. Finally, the ADABOOST algorithm was adopted, which produced the best fitting (R2 = 0.934, MSE = 0.100) among all the algorithms.
5.2. Visualization of Prediction Results
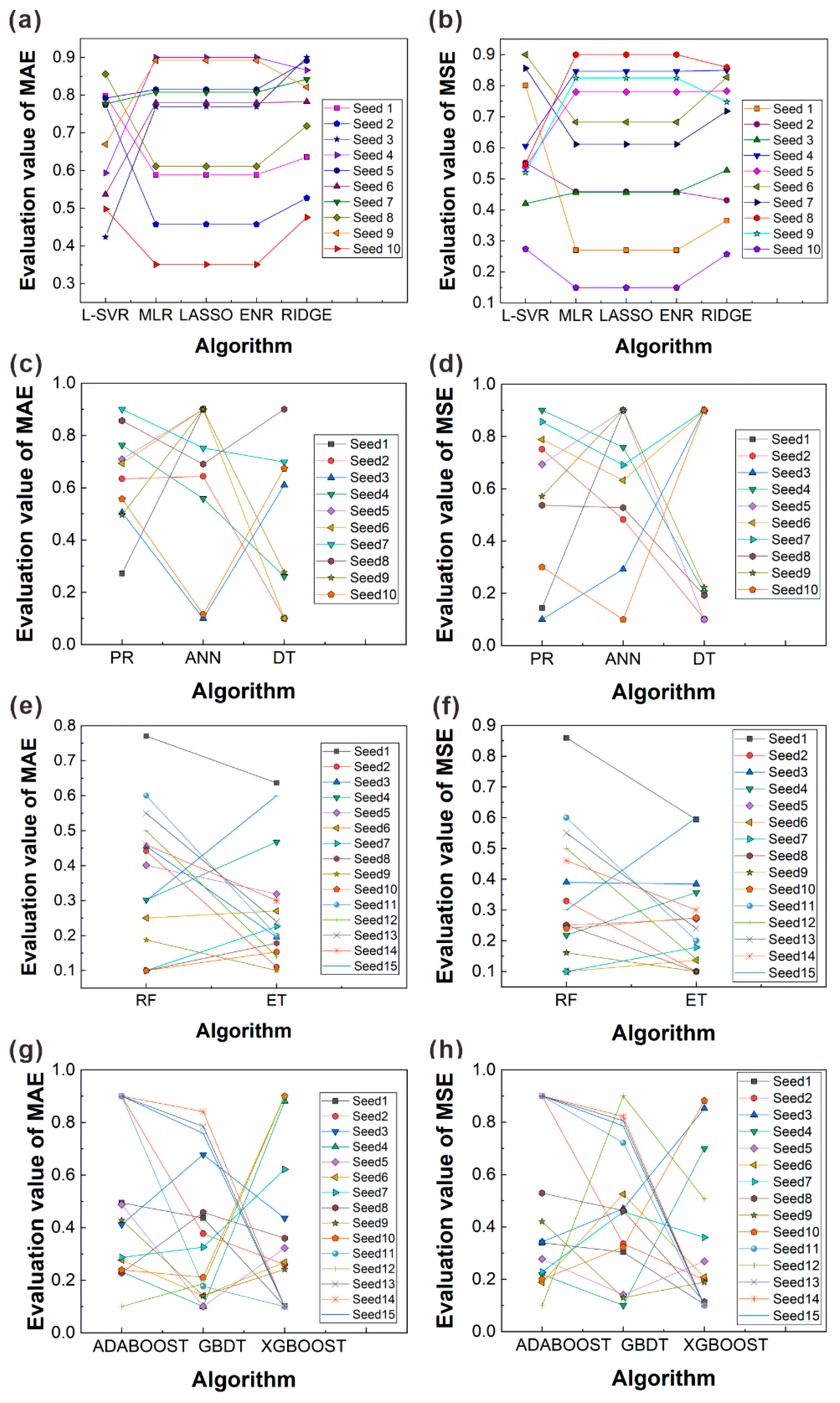
5.3. Verification of Prediction Results
5.4. Ranking Results of Thirteen Algorithms
6. Conclusions
- Among the thirteen popular ML algorithms investigated, all had R2 values above 0.6. Compared to previous studies on the influence of pores on fatigue life on small datasets, the predictive performance of the algorithms was improved. The ADABOOST algorithm from the boosting category exhibited the best fitting accuracy (R2 = 0.934, MSE = 0.100) for fatigue life prediction of the AM-fabricated Inconel 718 using the small dataset, followed by the DT algorithm (R2 = 0.899, MSE = 0.193) in the nonlinear category.
- The DT, RF, GBDT, and XGBOOST algorithms can well predict the fatigue life of the AM-fabricated Inconel 718 within the range of 1 × 105 cycles compared to others investigated in this study.
- By subjecting the prediction models to twenty or thirty verifications using R2 and MSE evaluation indicators, the ranking results of various ML algorithms for fatigue life prediction on a small dataset were obtained as follows: ADABOOST > DT > ET > RF > XGBOOST > GBDT > ANN > PR > L-SVR > ENR ≈ LASSO ≈ MLR > RIDGE. The fluctuation trends of the straight lines representing the performance of each algorithm informed these rankings, providing more reliable and robust conclusions.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kaletsch, A.; Qin, S.; Herzog, S.; Broeckmann, C. Influence of high initial porosity introduced by laser powder bed fusion on the fatigue strength of Inconel 718 after post-processing with hot isostatic pressing. Addit. Manuf. 2021, 47, 102331. [Google Scholar] [CrossRef]
- Ramkumar, K.D.; Dev, S.; Phani Prabhakar, K.V.; Rajendran, R.; Mugundan, K.G.; Narayanan, S. Microstructure and properties of inconel 718 and AISI 416 laser welded joints. J. Mater. Process. Technol. 2019, 266, 52–62. [Google Scholar] [CrossRef]
- Zhang, B.; Xiu, M.; Tan, Y.T.; Wei, J.; Wang, P. Pitting corrosion of SLM Inconel 718 sample under surface and heat treatments. Appl. Surf. Sci. 2019, 490, 556–567. [Google Scholar] [CrossRef]
- Zheng, H.; Li, H.; Lang, L.; Gong, S.; Ge, Y. Effects of scan speed on vapor plume behavior and spatter generation in laser powder bed fusion additive manufacturing. J. Manuf. Process. 2018, 36, 60–67. [Google Scholar] [CrossRef]
- Felix, H.K.; Moylan, S.P. Literature Review of Metal Additive Manufacturing Defects; US Department of Commerce, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2018; pp. 100–116. [Google Scholar] [CrossRef]
- Tammas-Williams, S.; Withers, P.J.; Todd, I.; Prangnell, P.B. The Influence of Porosity on Fatigue Crack Initiation in Additively Manufactured Titanium Components. Sci. Rep. 2017, 7, 7308. [Google Scholar] [CrossRef] [PubMed]
- Ye, D.S.; Hong, G.S.; Zhang, Y.J.; Zhu, K.P.; Fuh, J.Y.H. Defect detection in selective laser melting technology by acoustic signals with deep belief networks. Int. J. Adv. Manuf. Technol. 2018, 96, 2791–2801. [Google Scholar] [CrossRef]
- Biswal, R.; Syed, A.K.; Zhang, X. Assessment of the effect of isolated porosity defects on the fatigue performance of additive manufactured titanium alloy. Addit. Manuf. 2018, 23, 433–442. [Google Scholar] [CrossRef]
- Hu, Y.N.; Wu, S.C.; Withers, P.J.; Zhang, J.; Bao, H.Y.X.; Fu, Y.N.; Kang, G.Z. The effect of manufacturing defects on the fatigue life of selective laser melted Ti-6Al-4V structures. Mater. Des. 2020, 192, 108708. [Google Scholar] [CrossRef]
- Yadollahi, A.; Shamsaei, N.; Thompson, S.M.; Elwany, A.; Bian, L. Effects of building orientation and heat treatment on fatigue behavior of selective laser melted 17-4 PH stainless steel. Int. J. Fatigue 2017, 94, 218–235. [Google Scholar] [CrossRef]
- Serrano-Munoz, I.; Buffiere, J.-Y.; Mokso, R.; Verdu, C.; Nadot, Y. Location, location & size: Defects close to surfaces dominate fatigue crack initiation. Sci. Rep. 2017, 7, 45239. [Google Scholar] [CrossRef]
- Dezecot, S.; Maurel, V.; Buffiere, J.-Y.; Szmytka, F.; Koster, A. 3D characterization and modeling of low cycle fatigue damage mechanisms at high temperature in a cast aluminum alloy. Acta Mater. 2017, 123, 24–34. [Google Scholar] [CrossRef]
- Yadollahi, A.; Mahtabi, M.J.; Khalili, A.; Doude, H.R.; Newman, J.C., Jr. Fatigue life prediction of additively manufactured material: Effects of surface roughness, defect size, and shape. Fatigue Fract. Eng. Mater. Struct. 2018, 41, 1602–1614. [Google Scholar] [CrossRef]
- Fomin, F.; Horstmann, M.; Huber, N.; Kashaev, N. Probabilistic fatigue-life assessment model for laser-welded Ti-6Al-4V butt joints in the high-cycle fatigue regime. Int. J. Fatigue 2018, 116, 22–35. [Google Scholar] [CrossRef]
- Bergara, A.; Dorado, J.I.; Martin-Meizoso, A.; Martínez-Esnaola, J.M. Fatigue crack propagation in complex stress fields: Experiments and numerical simulations using the Extended Finite Element Method (XFEM). Int. J. Fatigue 2017, 103, 112–121. [Google Scholar] [CrossRef]
- Shen, H.; Li, Z.; Qi, L.; Qiao, L. A method for gear fatigue life prediction considering the internal flow field of the gear pump. Mech. Syst. Signal Process. 2018, 99, 921–929. [Google Scholar] [CrossRef]
- Bao, H.Y.X.; Wu, S.C.; Wu, Z.K.; Kang, G.Z.; Peng, X.; Withers, P.J. A machine-learning fatigue life prediction approach of additively manufactured metals. Eng. Fract. Mech. 2021, 242, 107508. [Google Scholar] [CrossRef]
- He, L.; Wang, Z.L.; Akebono, H.; Sugeta, A. Machine learning-based predictions of fatigue life and fatigue limit for steels. J. Mater. Sci. Technol. 2021, 90, 9–19. [Google Scholar] [CrossRef]
- Zhang, M.; Sun, C.N.; Zhang, X.; Goh, P.C.; Wei, J.; Hardacre, D.; Li, H. High cycle fatigue life prediction of laser additive manufactured stainless steel: A machine learning approach. Int. J. Fatigue 2019, 128, 105194. [Google Scholar] [CrossRef]
- Luo, Y.W.; Zhang, B.; Feng, X.; Song, Z.M.; Qi, X.B.; Li, C.P.; Chen, G.F.; Zhang, G.P. Pore-affected fatigue life scattering and prediction of additively manufactured Inconel 718: An investigation based on miniature specimen testing and machine learning approach. Mater. Sci. Eng. A 2021, 802, 140693. [Google Scholar] [CrossRef]
- Zhou, K.; Sun, X.Y.; Shi, S.W.; Song, K.; Chen, X. Machine learning-based genetic feature identification and fatigue life prediction. Fatigue Fract. Eng. Mater. Struct. 2021, 44, 2524–2537. [Google Scholar] [CrossRef]
- Li, D.C.; Yeh, C.W.; Tsai, T.I.; Fang, Y.H.; Hu, S.C. Acquiring knowledge with limited experience. Expert Syst. 2007, 24, 162–170. [Google Scholar] [CrossRef]
- Zhang, Y.; Ling, C. A strategy to apply machine learning to small datasets in materials science. npj Comput. Mater. 2018, 4, 25. [Google Scholar] [CrossRef]
- Feng, S.; Zhou, H.; Dong, H. Using deep neural network with small dataset to predict material defects. Mater. Des. 2019, 162, 300–310. [Google Scholar] [CrossRef]
- Huang, J.-C.; Ko, K.-M.; Shu, M.-H.; Hsu, B.-M. Application and comparison of several machine learning algorithms and their integration models in regression problems. Neural Comput. Appl. 2019, 32, 5461–5469. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Luo, Y.W.; Zhang, B.; Li, C.P.; Chen, G.F.; Zhang, G.P. Detecting void-induced scatter of fatigue life of selective laser melting-fabricated inconel 718 using miniature specimens. Mater. Res. Express 2019, 6, 046549. [Google Scholar] [CrossRef]
- Wang, L.Y.; Wang, Y.C.; Zhou, Z.J.; Wan, H.Y.; Li, C.P.; Chen, G.F.; Zhang, G.P. Small punch creep performance of heterogeneous microstructure dominated Inconel 718 fabricated by selective laser melting. Mater. Des. 2020, 195, 109042. [Google Scholar] [CrossRef]
- Parry, L.; Ashcroft, I.A.; Wildman, R.D. Understanding the effect of laser scan strategy on residual stress in selective laser melting through thermo-mechanical simulation. Addit. Manuf. 2016, 12, 1–15. [Google Scholar] [CrossRef]
- Wan, H.Y.; Zhou, Z.J.; Li, C.P.; Chen, G.F.; Zhang, G.P. Effect of scanning strategy on grain structure and crystallographic texture of Inconel 718 processed by selective laser melting. J. Mater. Sci. Technol. 2018, 34, 1799–1804. [Google Scholar] [CrossRef]
- Siewert, M.; Neugebauer, F.; Epp, J.; Ploshikhin, V. Validation of Mechanical Layer Equivalent Method for simulation of residual stresses in additive manufactured components. Comput. Math. Appl. 2019, 78, 2407–2416. [Google Scholar] [CrossRef]
- Wan, H.Y.; Chen, G.F.; Li, C.P.; Qi, X.B.; Zhang, G.P. Data-driven evaluation of fatigue performance of additive manufactured parts using miniature specimens. J. Mater. Sci. Technol. 2019, 35, 1137–1146. [Google Scholar] [CrossRef]
- Dai, C.Y.; Zhu, X.F.; Zhang, G.P. Tensile and Fatigue Properties of Free-Standing Cu Foils. J. Mater. Sci. Technol. 2009, 25, 721–726. [Google Scholar]
- Zheng, S.X.; Luo, X.M.; Wang, D.; Zhang, G.P. A novel evaluation strategy for fatigue reliability of flexible nanoscale films. Mater. Res. Express 2018, 5, 035012. [Google Scholar] [CrossRef]
- Dai, C.Y.; Zhang, B.; Xu, J.; Zhang, G.P. On size effects on fatigue properties of metal foils at micrometer scales. Mater. Sci. Eng. A 2013, 575, 217–222. [Google Scholar] [CrossRef]
- Ma, Y.; Song, Z.; Zhang, S.; Chen, L.; Zhang, G. Evaluation of Fatigue Properties of CA6NM Martensite Stainless Steel Using Miniature Specimens. Acta Metall. Sin. 2018, 54, 1359–1367. [Google Scholar]
- Dai, C.Y.; Zhang, G.P.; Yan, C. Size effects on tensile and fatigue behaviour of polycrystalline metal foils at the micrometer scale. Philos. Mag. 2011, 91, 932–945. [Google Scholar] [CrossRef]
- Taylor, N. Realised variance forecasting under Box-Cox transformations. Int. J. Forecast. 2017, 33, 770–785. [Google Scholar] [CrossRef]
- Ross, S.M. Linear Regression. In Introductory Statistics; Ross, S.M., Ed.; Academic Press: Oxford, UK, 2017; pp. 519–584. [Google Scholar]
- Melkumova, L.E.; Shatskikh, S.Y. Comparing Ridge and LASSO estimators for data analysis. Procedia Eng. 2017, 201, 746–755. [Google Scholar] [CrossRef]
- Hastie, T. Ridge Regularization: An Essential Concept in Data Science. Technometrics 2020, 62, 426–433. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Algorithms. In Data Mining; Witten, I.H., Frank, E., Hall, M.A., Pal, C.J., Eds.; Morgan Kaufmann: Burlington, MA, USA, 2017; pp. 91–160. [Google Scholar]
- Zeng, S.; Gou, J.; Deng, L. An antinoise sparse representation method for robust face recognition via joint l1 and l2 regularization. Expert Syst. Appl. 2017, 82, 1–9. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R. Support Vector Regression. In Efficient Learning Machines; Awad, M., Khanna, R., Eds.; Apress: Berkeley, CA, USA, 2015; pp. 67–80. [Google Scholar]
- Kotu, V.; Deshpande, B. Classification. In Data Science: Concepts and Practice; Kotu, V., Deshpande, B., Eds.; Morgan Kaufmann: San Francisco, CA, USA, 2019; pp. 65–163. [Google Scholar]
- Bellini, T. One-Year PD. In IFRS 9 and CECL Credit Risk Modelling and Validation; Bellini, T., Ed.; Academic Press: Cambridge, MA, USA, 2019; pp. 31–89. [Google Scholar]
- Wu, Y.C.; Feng, J.W. Development and Application of Artificial Neural Network. Wirel. Pers. Commun. 2018, 102, 1645–1656. [Google Scholar] [CrossRef]
- Brandt, S. Linear and Polynomial Regression. In Data Analysis; Brandt, S., Ed.; Springer International Publishing: Cham, Switzerland, 2014; pp. 321–329. [Google Scholar]
- Ahmad, M.W.; Reynolds, J.; Rezgui, Y. Predictive modelling for solar thermal energy systems: A comparison of support vector regression, random forest, extra trees and regression trees. J. Clean. Prod. 2018, 203, 810–821. [Google Scholar] [CrossRef]
- Malik, A.; Javeri, Y.T.; Shah, M.; Mangrulkar, R. Impact analysis of COVID-19 news headlines on global economy. In Cyber-Physical Systems; Poonia, R.C., Agarwal, B., Kumar, S., Khan, M.S., Marques, G., Nayak, J., Eds.; Academic Press: Cambridge, MA, USA, 2022; pp. 189–206. [Google Scholar]
- Wang, J.; Gao, R.X. Innovative smart scheduling and predictive maintenance techniques. In Design and Operation of Production Networks for Mass Personalization in the Era of Cloud Technology; Mourtzis, D., Ed.; Elsevier: Amsterdam, The Netherlands, 2022; pp. 181–207. [Google Scholar]
- Malfanti, F.; Panaro, D.; Riccomagno, E. An Online Algorithm for Online Fraud Detection. In Adaptive Mobile Computing; Migliardi, M., Merlo, A., Al-Haj Baddar, S., Eds.; Academic Press: Boston, MA, USA, 2017; pp. 83–107. [Google Scholar]
- Wang, W.Y.; Sun, D.C. The improved AdaBoost algorithms for imbalanced data classification. Inf. Sci. 2021, 563, 358–374. [Google Scholar] [CrossRef]
- Song, R.; Chen, S.; Deng, B.; Li, L. eXtreme Gradient Boosting for Identifying Individual Users Across Different Digital Devices. In Web-Age Information Management, 17th International Conference, WAIM 2016, Nanchang, China, 3–5 June 2016; Lecture Notes in Computer Science Book Series; Springer: Cham, Switzerland, 2016; pp. 43–54. [Google Scholar]
- Chapelle, O.; Chang, Y. Yahoo! Learning to Rank Challenge Overview. Proc. Mach. Learn. Res. 2011, 14, 1–24. [Google Scholar]
- Zhang, C.S.; Liu, C.C.; Zhang, X.L.; Almpanidis, G. An up-to-date comparison of state-of-the-art classification algorithms. Expert Syst. Appl. 2017, 82, 128–150. [Google Scholar] [CrossRef]
- Zhang, C.S.; Zhang, Y.; Shi, X.J.; Almpanidis, G.; Fan, G.J.; Shen, X.J. On Incremental Learning for Gradient Boosting Decision Trees. Neural Process. Lett. 2019, 50, 957–987. [Google Scholar] [CrossRef]
- Liu, X.; Wang, G.; Cai, Z.; Zhang, H. Bagging based ensemble transfer learning. J. Ambient Intell. Hum. Comput. 2016, 7, 29–36. [Google Scholar] [CrossRef]
- Dev, V.A.; Eden, M.R. Evaluating the Boosting Approach to Machine Learning for Formation Lithology Classification. In Computer Aided Chemical Engineering; Eden, M.R., Ierapetritou, M.G., Towler, G.P., Eds.; Elsevier: Amsterdam, The Netherlands, 2018; Volume 44, pp. 1465–1470. [Google Scholar]
- Zhao, J.; Jiao, L.; Xia, S.; Basto Fernandes, V.; Yevseyeva, I.; Zhou, Y.; Emmerich, M.T.M. Multiobjective sparse ensemble learning by means of evolutionary algorithms. Decis. Support Syst. 2018, 111, 86–100. [Google Scholar] [CrossRef]
- Liu, L.; Chen, Z.; Liu, C.; Wu, Y.; An, B. Micro-mechanical and fracture characteristics of Cu6Sn5 and Cu3Sn intermetallic compounds under micro-cantilever bending. Intermetallics 2016, 76, 10–17. [Google Scholar] [CrossRef]
- Zhao, C.Y.; Zhang, H.X.; Zhang, X.Y.; Liu, M.C.; Hu, Z.D.; Fan, B.T. Application of support vector machine (SVM) for prediction toxic activity of different data sets. Toxicology 2006, 217, 105–119. [Google Scholar] [CrossRef]
- Liu, Y.; Zhao, T.L.; Ju, W.W.; Shi, S.Q. Materials discovery and design using machine learning. J. Mater. 2017, 3, 159–177. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input and Output Values | Max | Min | Mean | Std | |
|---|---|---|---|---|---|
| Inputs | Strain amplitude (ε/%) | 1.21 | 0.17 | 0.43 | 0.28 |
| Pore diameter (d/µm) | 17.87 | 0.00 | 4.52 | 4.72 | |
| Pore amount (m/piece) | 4.00 | 0.00 | 1.43 | 1.20 | |
| Pore location—all data (l/µm) | 1.00 × 1010 | 0.00 | 2.14 × 109 | 4.18 × 109 | |
| Pore location—excluding data with zero number of pores (l/µm) | 50.00 | 0.00 | 16.19 | 15.38 | |
| Outputs | Fatigue life (N/cycles) | 1.10 × 106 | 1.42 × 104 | 2.30 × 105 | 2.18 × 105 |
| ML Models | Mathematical Model | Other Information | References |
|---|---|---|---|
| MLR | An optimal combination of multiple independent variables | [39] | |
| LASSO | Penalty coefficient (λ = 4.77 × 10−9) | [40] | |
| RIDGE | Penalty coefficient (λ = 0.408) | [41,42] | |
| ENR | Penalty coefficient (λ = 1.0 × 10−11) Hybrid parameter (ρ = 0.5) | [43] | |
| L-SVR | Linear kernel function | [44] | |
| DT | The classification and regression tree (CART) was employed | [45,46] | |
| ANN | The sigmoid activation function | [24,47] | |
| PR | The curve can better capture the nonlinearity | [48] | |
| ET | — | A selection of features in a more varied and diverse manner than the RF algorithm | [49] |
| RF | — | The algorithm is relatively more intricate than other ML algorithms | [50,51] |
| ADABOOST | It is widely considered one of the best learning algorithms | [52,53] | |
| XGBOOST | The algorithm adds a regular term to the loss function to control the complexity of the model | [54] | |
| GBDT | The least squares method was employed in this study to measure the regression effect of the regression tree | [55,56,57] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, B.-L.; Luo, Y.-W.; Zhang, B.; Zhang, G.-P. A Comparative Investigation of Machine Learning Algorithms for Pore-Influenced Fatigue Life Prediction of Additively Manufactured Inconel 718 Based on a Small Dataset. Materials 2023, 16, 6606. https://doi.org/10.3390/ma16196606
Hu B-L, Luo Y-W, Zhang B, Zhang G-P. A Comparative Investigation of Machine Learning Algorithms for Pore-Influenced Fatigue Life Prediction of Additively Manufactured Inconel 718 Based on a Small Dataset. Materials. 2023; 16(19):6606. https://doi.org/10.3390/ma16196606
Chicago/Turabian StyleHu, Bing-Li, Yan-Wen Luo, Bin Zhang, and Guang-Ping Zhang. 2023. "A Comparative Investigation of Machine Learning Algorithms for Pore-Influenced Fatigue Life Prediction of Additively Manufactured Inconel 718 Based on a Small Dataset" Materials 16, no. 19: 6606. https://doi.org/10.3390/ma16196606
APA StyleHu, B.-L., Luo, Y.-W., Zhang, B., & Zhang, G.-P. (2023). A Comparative Investigation of Machine Learning Algorithms for Pore-Influenced Fatigue Life Prediction of Additively Manufactured Inconel 718 Based on a Small Dataset. Materials, 16(19), 6606. https://doi.org/10.3390/ma16196606