

A Perovskite Material Screening and Performance Study Based on Asymmetric Convolutional Blocks




Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset
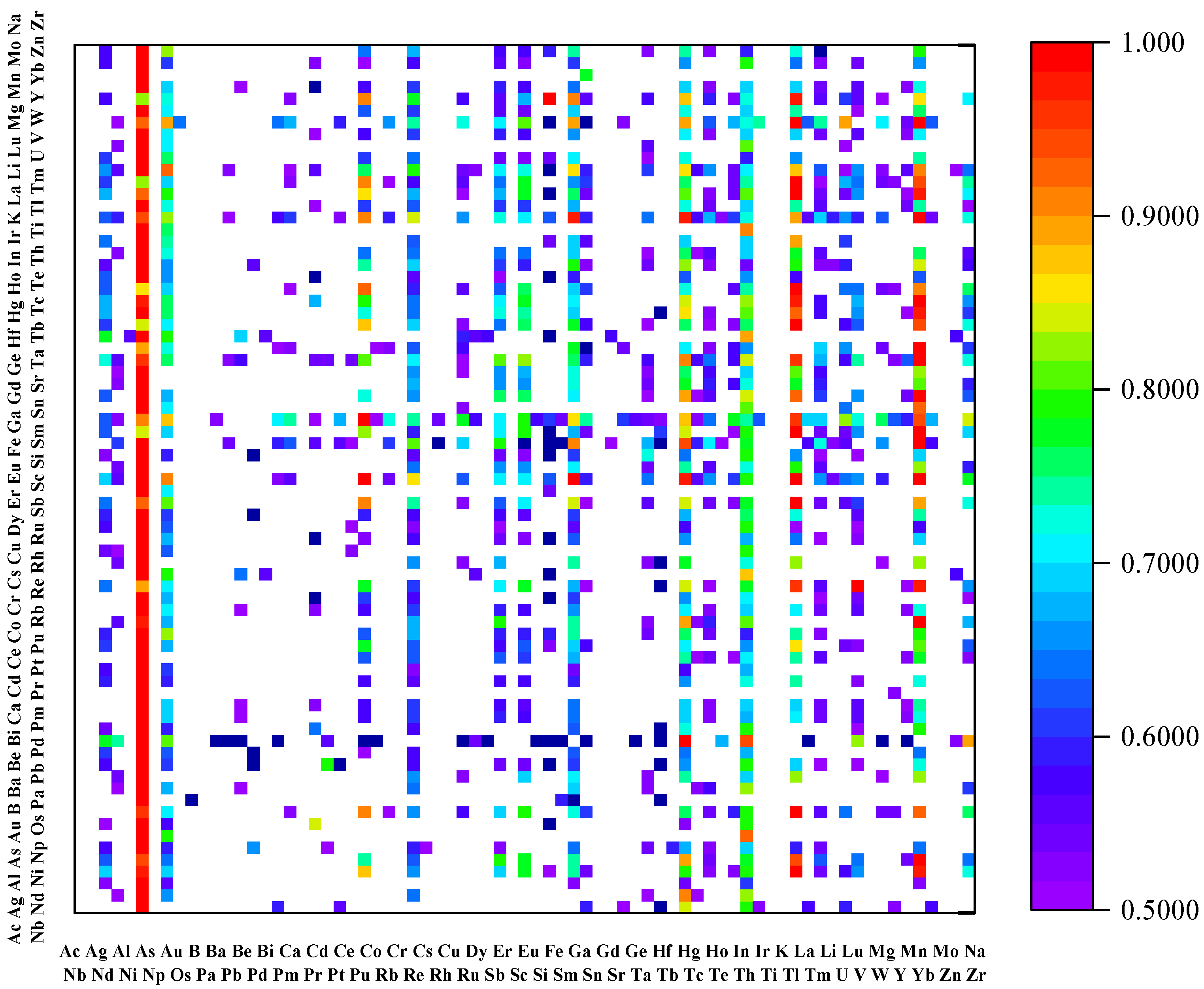
2.2. Feature Selection
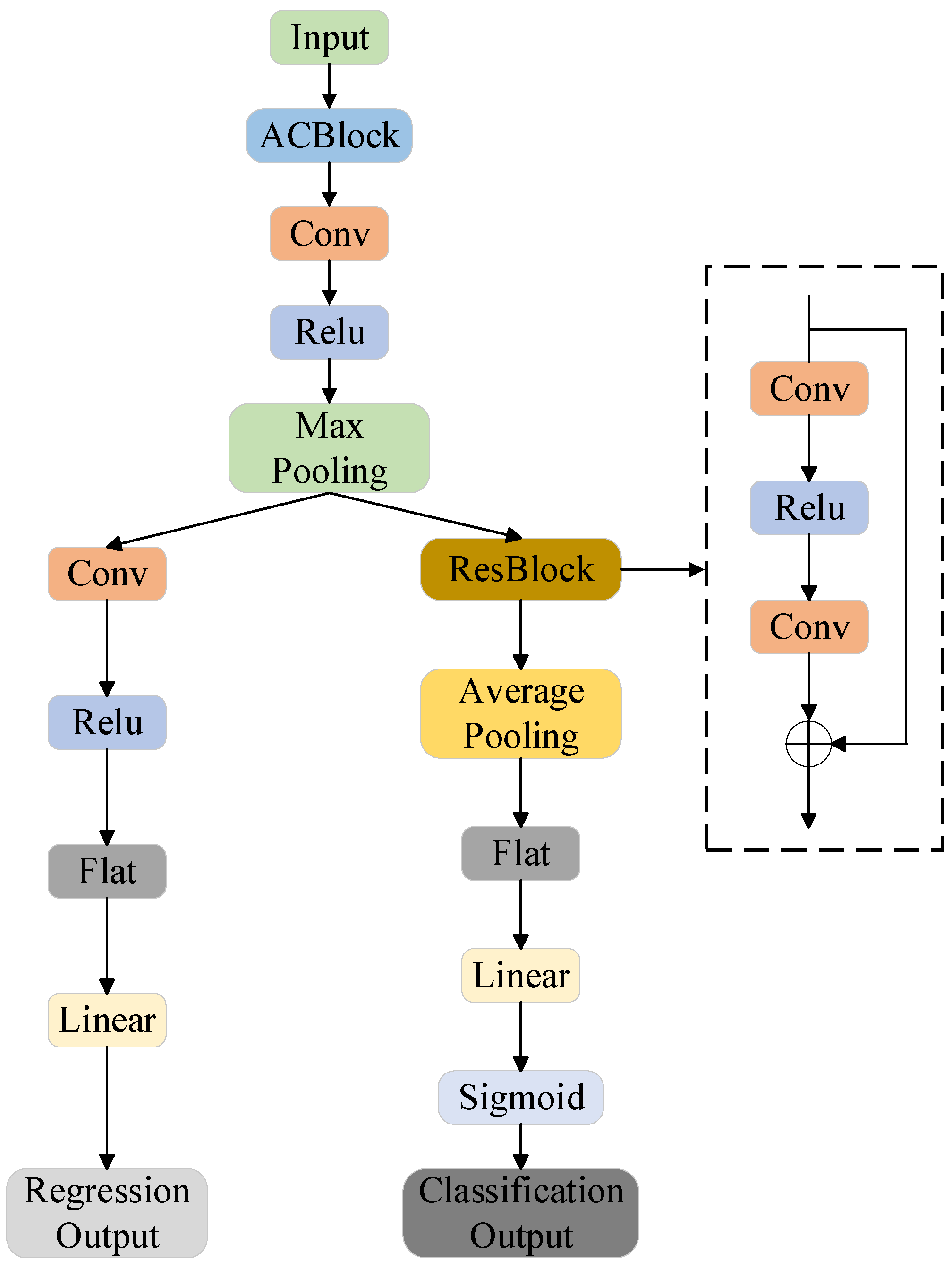
2.3. Model
3. Results and Discussion
3.1. Perovskite Stability Prediction
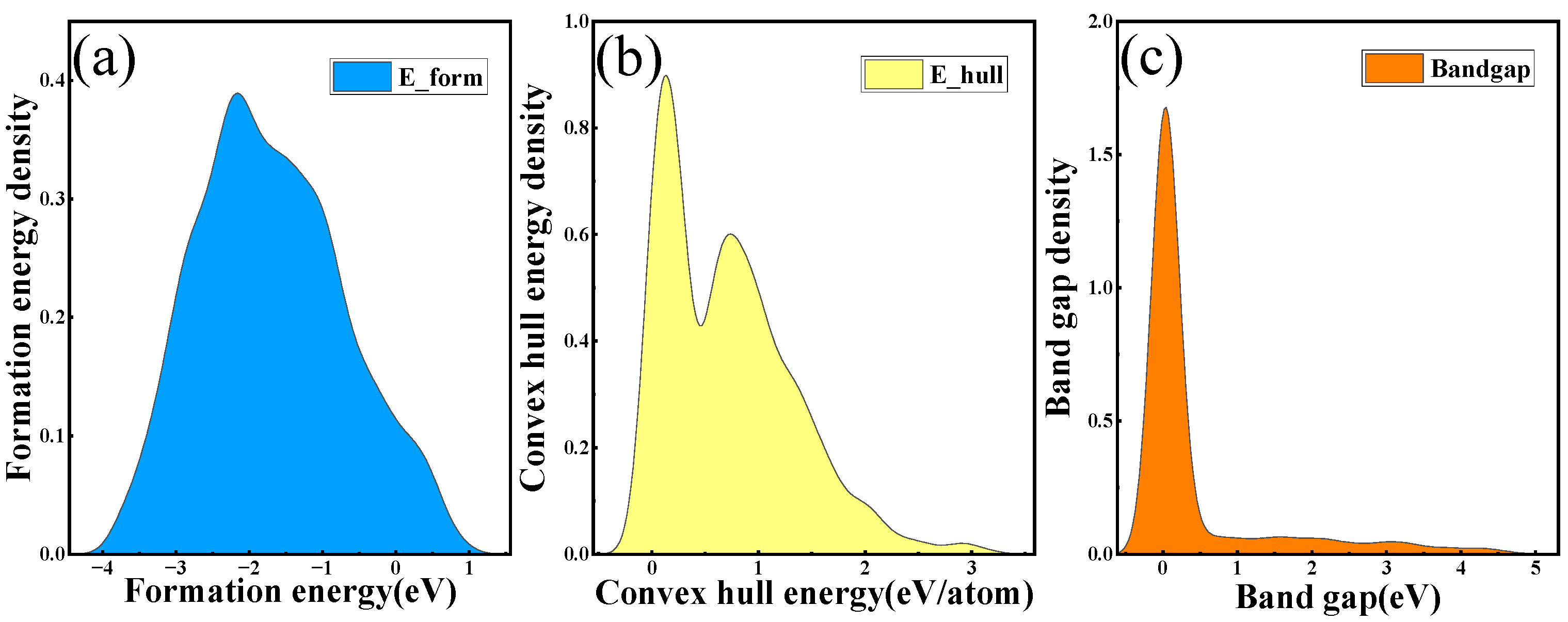
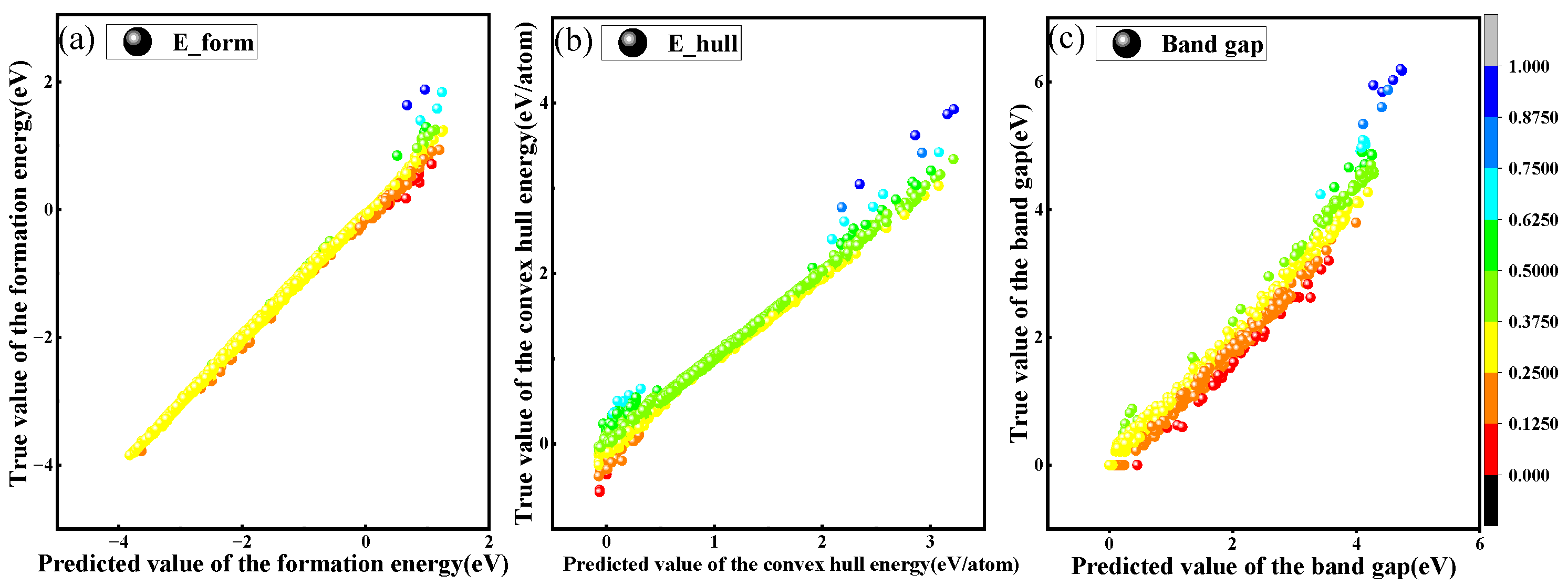
3.2. Perovskite Band Gap, Formation Energy, and Convex Hull Energy Prediction
3.3. Model Parameter Optimization
3.4. Comparison of Model Metrics
3.5. Screening of Solar-Cell Materials
4. Conclusions
- (1)
- Feature extraction and model structure: Initially, an ACB is employed to retain as much original feature information as possible, enhancing the model’s flexibility and generalization capabilities. Additionally, the use of ResBlock allows for skipping specific convolutional layers, thereby reducing the model’s complexity and computational demands and improving its suitability for large-scale material data predictions.
- (2)
- Classification task performance: In classification tasks, our model has demonstrated exceptional predictive performance, achieving an accuracy of 0.968 and an AUC of 0.965.
- (3)
- Regression task performance: In regression tasks, it has achieved an R2 value of 0.993, with lower MSE, RMSE, and MAE values compared to conventional machine-learning models.
- (4)
- Prediction of perovskite oxides: In the latest dataset predictions, based on convex hull energies and band gaps, materials such as DyCoO3 and YVO3 have been identified as promising candidates for solar-cell applications. This showcases the model’s extensive potential in predicting material stability, properties, and in effectively screening materials.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bati, A.S.; Zhong, Y.L.; Burn, P.L.; Nazeeruddin, M.K.; Shaw, P.E.; Batmunkh, M. Next-generation applications for integrated perovskite solar cells. Commun. Mater. 2023, 4, 2. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, M.; Xie, X.; Yu, C.; Jiang, Q.; Huang, M.; Algadi, H.; Guo, Z.; Zhang, H. Applications of machine learning in perovskite materials. Adv. Compos. Hybrid Mater. 2022, 5, 2700–2720. [Google Scholar] [CrossRef]
- Machín, A.; Márquez, F. Advancements in photovoltaic cell materials: Silicon, Organic, and Perovskite Solar cells. Materials 2024, 17, 1165. [Google Scholar] [CrossRef] [PubMed]
- Szabó, G.; Park, N.-G.; De Angelis, F.; Kamat, P.V. Are Perovskite Solar Cells Reaching the Efficiency and Voltage Limits? ACS Publications: Washington, DC, USA, 2023; Volume 8, pp. 3829–3831. [Google Scholar]
- Huang, L.; Huang, X.; Yan, J.; Liu, Y.; Jiang, H.; Zhang, H.; Tang, J.; Liu, Q. Research progresses on the application of perovskite in adsorption and photocatalytic removal of water pollutants. J. Hazard. Mater. 2023, 442, 130024. [Google Scholar] [CrossRef] [PubMed]
- Chenebuah, E.T.; Nganbe, M.; Tchagang, A.B. A Fourier-transformed feature engineering design for predicting ternary perovskite properties by coupling a two-dimensional convolutional neural network with a support vector machine (Conv2D-SVM). Mater. Res. Express 2023, 10, 026301. [Google Scholar] [CrossRef]
- Li, W.; Jacobs, R.; Morgan, D. Predicting the thermodynamic stability of perovskite oxides using machine learning models. Comput. Mater. Sci. 2018, 150, 454–463. [Google Scholar] [CrossRef]
- Lekesi, L.P.; Koao, L.F.; Motloung, S.V.; Motaung, T.E.; Malevu, T. Developments on perovskite solar cells (PSCs): A critical review. Appl. Sci. 2022, 12, 672. [Google Scholar] [CrossRef]
- Liu, H.; Feng, J.; Dong, L. Quick screening stable double perovskite oxides for photovoltaic applications by machine learning. Ceram. Int. 2022, 48, 18074–18082. [Google Scholar] [CrossRef]
- Yılmaz, B.; Yıldırım, R. Critical review of machine learning applications in perovskite solar research. Nano Energy 2021, 80, 105546. [Google Scholar] [CrossRef]
- Li, X.; Dan, Y.; Dong, R.; Cao, Z.; Niu, C.; Song, Y.; Li, S.; Hu, J. Computational screening of new perovskite materials using transfer learning and deep learning. Appl. Sci. 2019, 9, 5510. [Google Scholar] [CrossRef]
- Gao, Z.; Zhang, H.; Mao, G.; Ren, J.; Chen, Z.; Wu, C.; Gates, I.D.; Yang, W.; Ding, X.; Yao, J. Screening for lead-free inorganic double perovskites with suitable band gaps and high stability using combined machine learning and DFT calculation. Appl. Surf. Sci. 2021, 568, 150916. [Google Scholar] [CrossRef]
- Vakharia, V.; Castelli, I.E.; Bhavsar, K.; Solanki, A. Bandgap prediction of metal halide perovskites using regression machine learning models. Phys. Lett. A 2022, 422, 127800. [Google Scholar] [CrossRef]
- Sradhasagar, S.; Khuntia, O.S.; Biswal, S.; Purohit, S.; Roy, A. Machine learning-aided discovery of bismuth-based transition metal oxide double perovskites for solar cell applications. Solar Energy 2024, 267, 112209. [Google Scholar] [CrossRef]
- Ding, X.; Guo, Y.; Ding, G.; Han, J. Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 1911–1920. [Google Scholar]
- Liang, Y.; Peng, W.; Zheng, Z.-J.; Silvén, O.; Zhao, G. A hybrid quantum–classical neural network with deep residual learning. Neural Netw. 2021, 143, 133–147. [Google Scholar] [CrossRef]
- Teale, A.M.; Helgaker, T.; Savin, A.; Adamo, C.; Aradi, B.; Arbuznikov, A.V.; Ayers, P.W.; Baerends, E.J.; Barone, V.; Calaminici, P. DFT exchange: Sharing perspectives on the workhorse of quantum chemistry and materials science. Phys. Chem. Chem. Phys. 2022, 24, 28700–28781. [Google Scholar] [CrossRef]
- Bagayoko, D. Understanding density functional theory (DFT) and completing it in practice. AIP Adv. 2014, 4, 127104. [Google Scholar] [CrossRef]
- Jain, A.; Ong, S.P.; Hautier, G.; Chen, W.; Richards, W.D.; Dacek, S.; Cholia, S.; Gunter, D.; Skinner, D.; Ceder, G. Commentary: The Materials Project: A materials genome approach to accelerating materials innovation. APL Mater. 2013, 1, 011002. [Google Scholar] [CrossRef]
- Zhai, X.; Ding, F.; Zhao, Z.; Santomauro, A.; Luo, F.; Tong, J. Predicting the formation of fractionally doped perovskite oxides by a function-confined machine learning method. Commun. Mater. 2022, 3, 42. [Google Scholar] [CrossRef]
- Raghavender, A.; Hong, N.H.; Lee, K.J.; Jung, M.-H.; Skoko, Z.; Vasilevskiy, M.; Cerqueira, M.; Samantilleke, A. Nano-ilmenite FeTiO3: Synthesis and characterization. J. Magn. Magn. Mater. 2013, 331, 129–132. [Google Scholar] [CrossRef]
- Ward, L.; Dunn, A.; Faghaninia, A.; Zimmermann, N.E.; Bajaj, S.; Wang, Q.; Montoya, J.; Chen, J.; Bystrom, K.; Dylla, M. Matminer: An open source toolkit for materials data mining. Comput. Mater. Sci. 2018, 152, 60–69. [Google Scholar] [CrossRef]
- Emery, A.A.; Wolverton, C. High-throughput DFT calculations of formation energy, stability and oxygen vacancy formation energy of ABO3 perovskites. Sci. Data 2017, 4, 170153. [Google Scholar] [CrossRef] [PubMed]
- Tidrow, S.C. Mapping comparison of Goldschmidt’s tolerance factor with Perovskite structural conditions. Ferroelectrics 2014, 470, 13–27. [Google Scholar] [CrossRef]
- Travis, W.; Glover, E.; Bronstein, H.; Scanlon, D.; Palgrave, R. On the application of the tolerance factor to inorganic and hybrid halide perovskites: A revised system. Chem. Sci. 2016, 7, 4548–4556. [Google Scholar] [CrossRef] [PubMed]
- Bartel, C.J.; Sutton, C.; Goldsmith, B.R.; Ouyang, R.; Musgrave, C.B.; Ghiringhelli, L.M.; Scheffler, M. New tolerance factor to predict the stability of perovskite oxides and halides. Sci. Adv. 2019, 5, eaav0693. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Man, Y.; Xie, G.; Wang, C.; Zhang, B.; Xu, H.; Fu, H.; Zhu, J.; Lv, Z.; Ying, L. Optical Amplification at 637 and 1067 nm Based on Organic Molecule AQ (PhDPA) 2 and NdIII Complex Codoped Polymer Waveguides. Small Methods 2023, 7, 2201366. [Google Scholar] [CrossRef] [PubMed]
- Imambi, S.; Prakash, K.B.; Kanagachidambaresan, G. PyTorch. In Programming with TensorFlow. Solution for Edge Computing Applications; Springer: Cham, Switzerland, 2021; pp. 87–104. [Google Scholar]
- Chauhan, V.K.; Dahiya, K.; Sharma, A. Problem formulations and solvers in linear SVM: A review. Artif. Intell. Rev. 2019, 52, 803–855. [Google Scholar] [CrossRef]
- Segal, M.R. Machine Learning Benchmarks and Random Forest Regression; Technical report; Center for Bioinformatics and Molecular Biostatistics, UC San Fransisco: San Fransisco, CA, USA, 2004. [Google Scholar]
- Shah, K.; Patel, H.; Sanghvi, D.; Shah, M. A comparative analysis of logistic regression, random forest and KNN models for the text classification. Augment. Hum. Res. 2020, 5, 12. [Google Scholar] [CrossRef]
- Huang, Y.; Liu, Y.; Li, C.; Wang, C. GBRTVis: Online analysis of gradient boosting regression tree. J. Vis. 2019, 22, 125–140. [Google Scholar] [CrossRef]
- Shafiq, M.; Gu, Z. Deep residual learning for image recognition: A survey. Appl. Sci. 2022, 12, 8972. [Google Scholar] [CrossRef]
- Wu, S.; Zhong, S.; Liu, Y. Deep residual learning for image steganalysis. Multimed. Tools Appl. 2018, 77, 10437–10453. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, X.; Li, H.; Xu, X. Interpretable machine learning-assisted screening of perovskite oxides. RSC Adv. 2024, 14, 3909–3922. [Google Scholar] [CrossRef]
- Węglarczyk, S. Kernel density estimation and its application. In Proceedings of the ITM Web of Conferences, Rzeszów-Muczne, Poland, 11–14 June 2018; p. 00037. [Google Scholar]
- Zhang, K.; Sun, M.; Han, T.X.; Yuan, X.; Guo, L.; Liu, T. Residual networks of residual networks: Multilevel residual networks. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 1303–1314. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, J.; Qu, Z.; Jiang, S.; Liu, Y.; Wu, Z.; Yang, F.; Hu, W.; Xu, Z.; Dai, Y. Accelerating stability of ABX3 perovskites analysis with machine learning. Ceram. Int. 2024, 50, 6250–6258. [Google Scholar] [CrossRef]
- Gong, C.; Liu, J.; Dai, S.; Hao, H.; Liu, H. Machine learning assisted prediction of the phonon cutoff frequency of ABO3 perovskite materials. Comput. Mater. Sci. 2024, 239, 112943. [Google Scholar] [CrossRef]
- Khan, A.; Kandel, J.; Tayara, H.; Chong, K.T. Predicting the bandgap and efficiency of perovskite solar cells using machine learning methods. Mol. Inform. 2024, 43, e202300217. [Google Scholar] [CrossRef] [PubMed]
- Luo, W.; Guan, J.; Yan, Z. Predicting the band gap of lead-free inorganic double perovskites using modified parallel residual network. Can. J. Chem. 2024, 102, 382–390. [Google Scholar] [CrossRef]
- Mattur, M.N.; Nagappan, N.; Rath, S.; Thomas, T. Prediction of nature of band gap of perovskite oxides (ABO3) using a machine learning approach. J. Mater. 2022, 8, 937–948. [Google Scholar]
- Henriques, J.; Barboza, C.; Albuquerque, E.; Caetano, E.; Freire, V.; Da Costa, J. First-principles calculations of structural, electronic and optical properties of orthorhombic CaPbO3. J. Phys. D Appl. Phys. 2008, 41, 065405. [Google Scholar] [CrossRef]
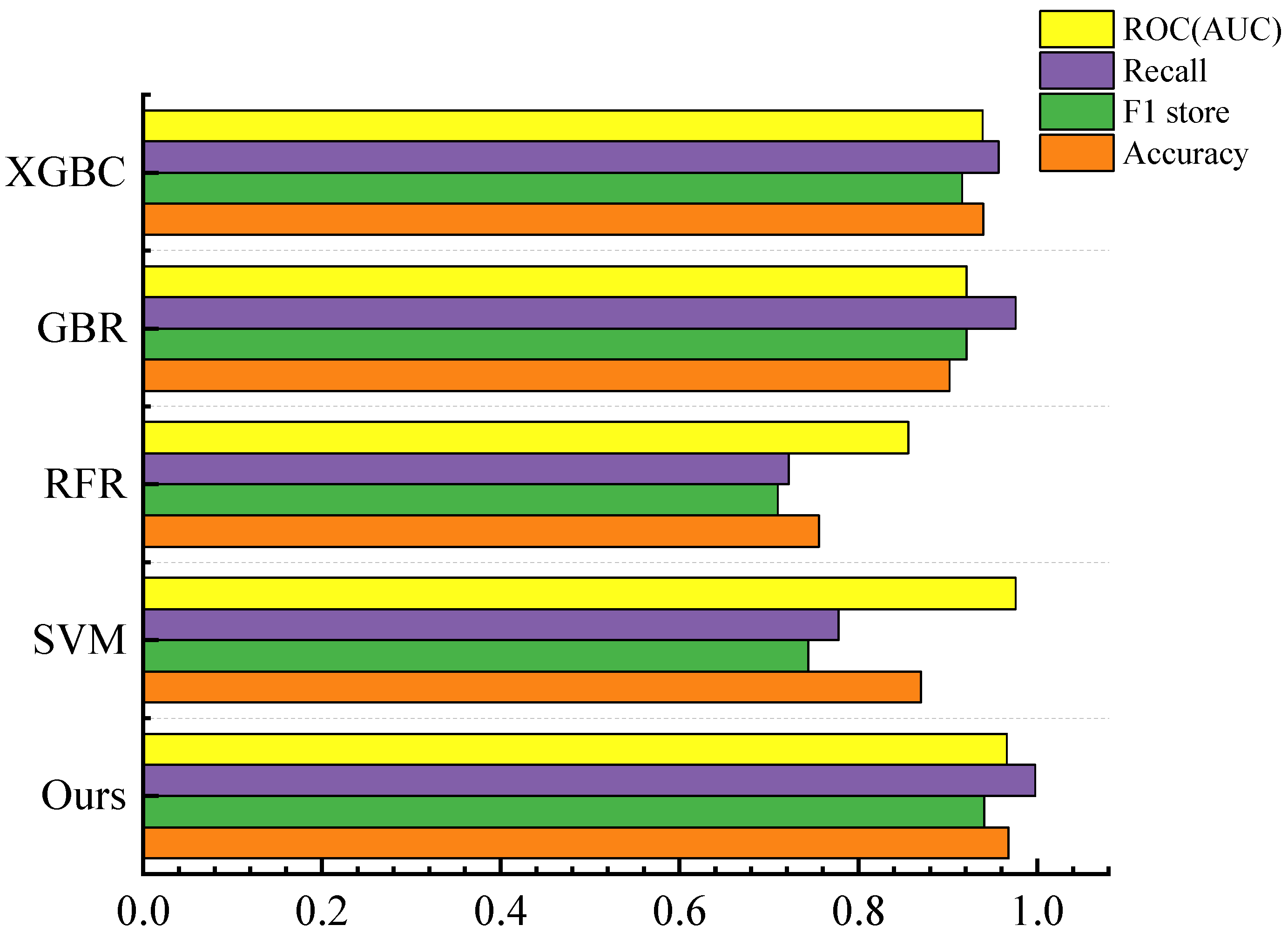


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Layers | Accuracy | R2 |
|---|---|---|
| 0 | 0.884 | 0.987 |
| 2 | 0.968 | 0.993 |
| 4 | 0.942 | 0.992 |
| Model | Accuracy | Recall | F1 Score | AUC |
|---|---|---|---|---|
| XGBC [14] | 0.950 | 0.960 | 0.940 | 0.950 |
| GBC [38] | 0.862 | 0.880 | 0.882 | 0.930 |
| TPOTC [38] | 0.838 | 0.851 | 0.861 | 0.933 |
| Ours | 0.968 | 0.998 | 0.941 | 0.966 |
| Model | MSE | RMSE | MAE | R2 |
|---|---|---|---|---|
| LightGBM [39] | 0.545 | 0.738 | 0.430 | 0.973 |
| CBR [40] | 0.014 | 0.120 | 0.083 | 0.790 |
| PRN [41] | 0.176 | 0.420 | 0.074 | 0.962 |
| Ours | 0.001 | 0.010 | 0.009 | 0.991 |
| ABO3 | Ehull [eV/atom] | Band Gap [eV] | ABO3 | Ehull [eV/atom] | Band Gap [eV] |
|---|---|---|---|---|---|
| ErVO3 | −0.0241 | 1.3734 | GdVO3 | −0.0408 | 1.4539 |
| CeFeO3 | −0.0555 | 0.9472 | CaPbO3 | 0.0347 | 1.1269 |
| SmFeO3 | −0.0316 | 1.1743 | LuFeO3 | 0.0021 | 1.2930 |
| YFeO3 | −0.0334 | 1.1794 | AgNbO3 | 0.0430 | 1.2360 |
| GdFeO3 | −0.0273 | 1.0481 | BiFeO3 | 0.0115 | 1.1050 |
| TbFeO3 | −0.0203 | 1.1870 | LaTiO3 | 0.0289 | 1.1780 |
| PrCoO3 | −0.0019 | 1.0769 | PrVO3 | −0.0561 | 1.4650 |
| DyFeO3 | −0.0353 | 1.0784 | PbPuO3 | −0.0333 | 1.2032 |
| NaPuO3 | −0.0555 | 1.1739 | TmVO3 | −0.0126 | 1.3021 |
| KPuO3 | −0.0833 | 1.1600 | HoCoO3 | 0.0299 | 1.4519 |
| HoFeO3 | −0.0271 | 1.1136 | DyCoO3 | 0.0171 | 1.2701 |
| YbPbO3 | 0.0295 | 1.2060 | HgPuO3 | −0.0201 | 1.1873 |
| AcVO3 | −0.0665 | 1.2351 | HgHfO3 | 0.0661 | 1.4360 |
| NdVO3 | −0.0489 | 1.3722 | YVO3 | −0.0320 | 1.2890 |
| ErFeO3 | −0.0030 | 1.1867 | PuCrO3 | −0.0450 | 1.5199 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, S.; Zhang, Y.; Huang, Y.; Yu, Z.; Zhou, Y.; Lin, X. A Perovskite Material Screening and Performance Study Based on Asymmetric Convolutional Blocks. Materials 2024, 17, 3741. https://doi.org/10.3390/ma17153741
Ji S, Zhang Y, Huang Y, Yu Z, Zhou Y, Lin X. A Perovskite Material Screening and Performance Study Based on Asymmetric Convolutional Blocks. Materials. 2024; 17(15):3741. https://doi.org/10.3390/ma17153741
Chicago/Turabian StyleJi, Shumin, Yujie Zhang, Yanyan Huang, Zhongwei Yu, Yong Zhou, and Xiaogang Lin. 2024. "A Perovskite Material Screening and Performance Study Based on Asymmetric Convolutional Blocks" Materials 17, no. 15: 3741. https://doi.org/10.3390/ma17153741
APA StyleJi, S., Zhang, Y., Huang, Y., Yu, Z., Zhou, Y., & Lin, X. (2024). A Perovskite Material Screening and Performance Study Based on Asymmetric Convolutional Blocks. Materials, 17(15), 3741. https://doi.org/10.3390/ma17153741