
Active Learning for Rapid Targeted Synthesis of Compositionally Complex Alloys


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Sample Preparation and Synthesis
2.2. Sample Characterization
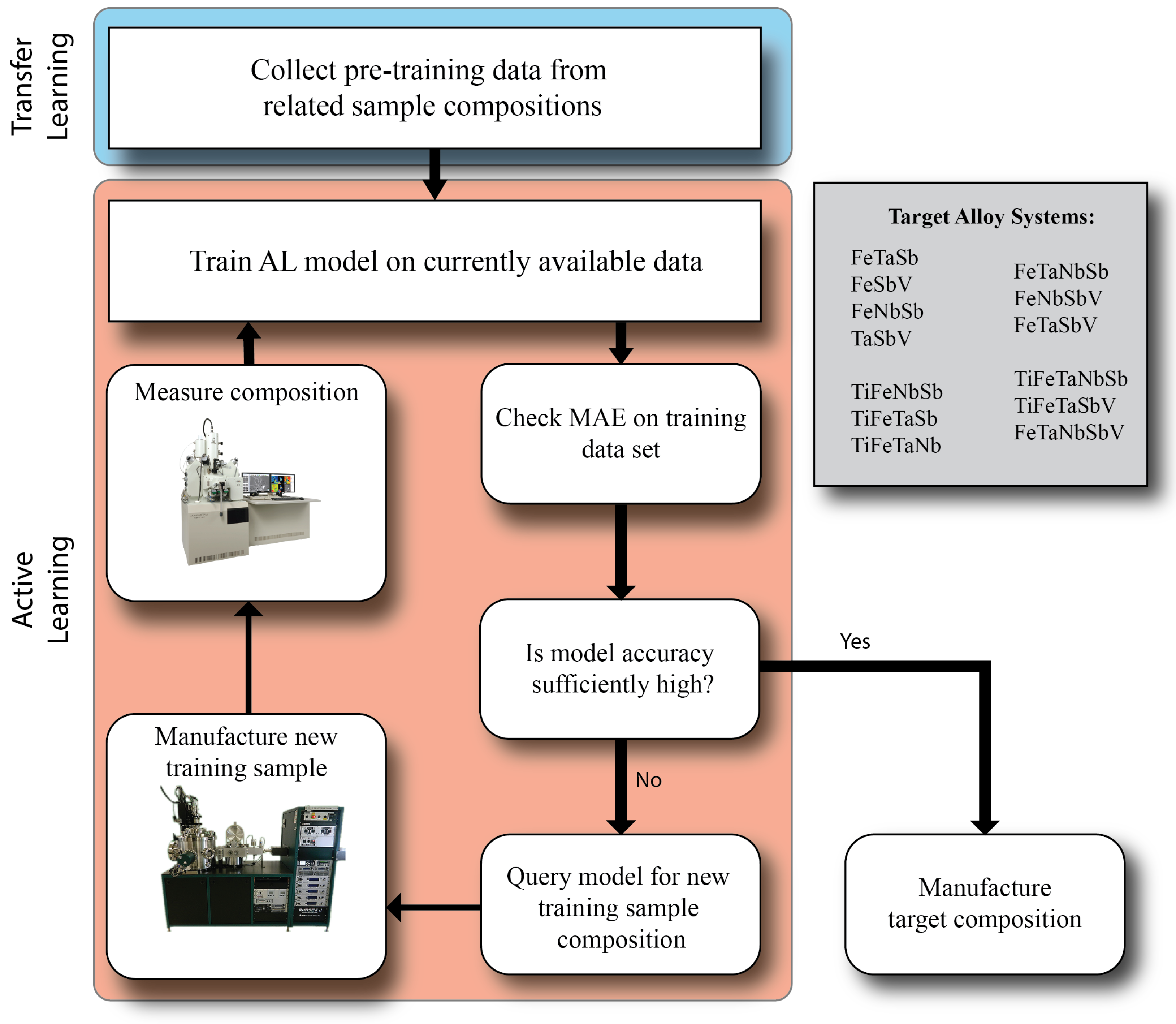
2.3. Active Learning
2.4. Transfer Learning
3. Results and Discussion
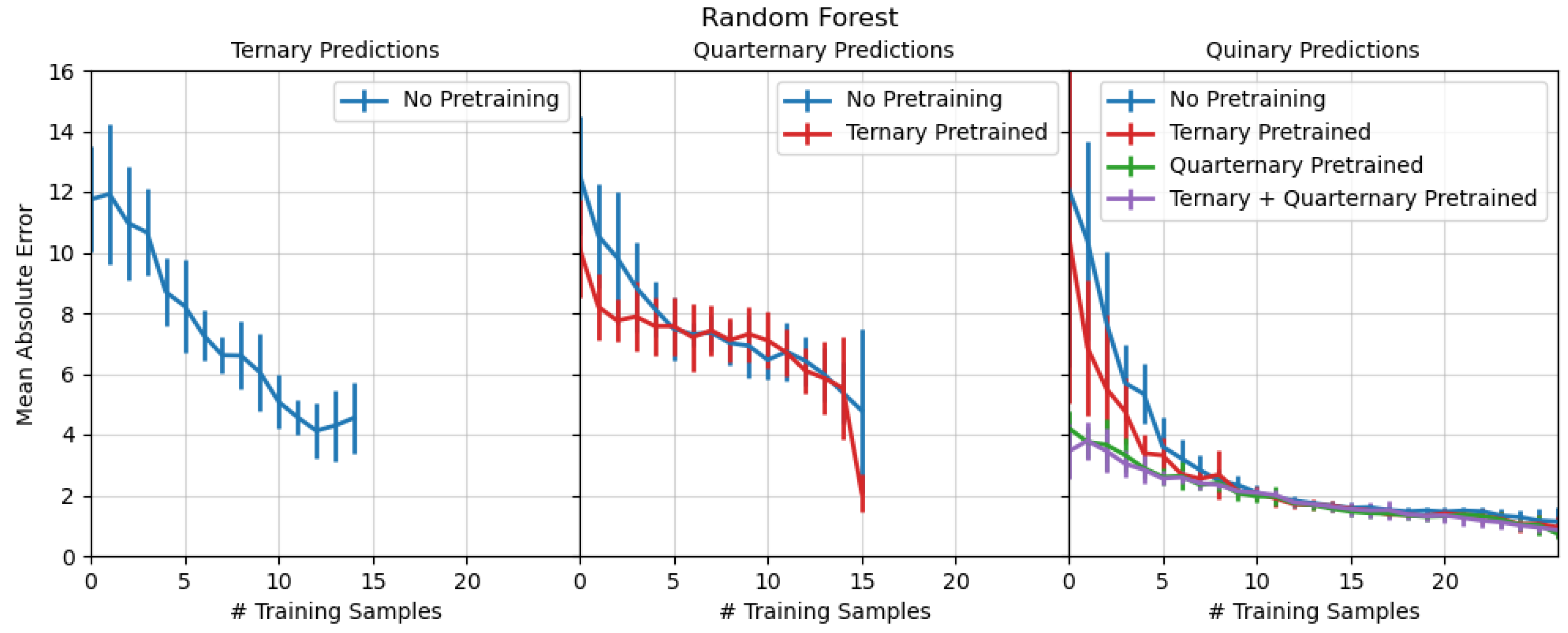
3.1. Transfer Learning into Higher Dimensional Systems
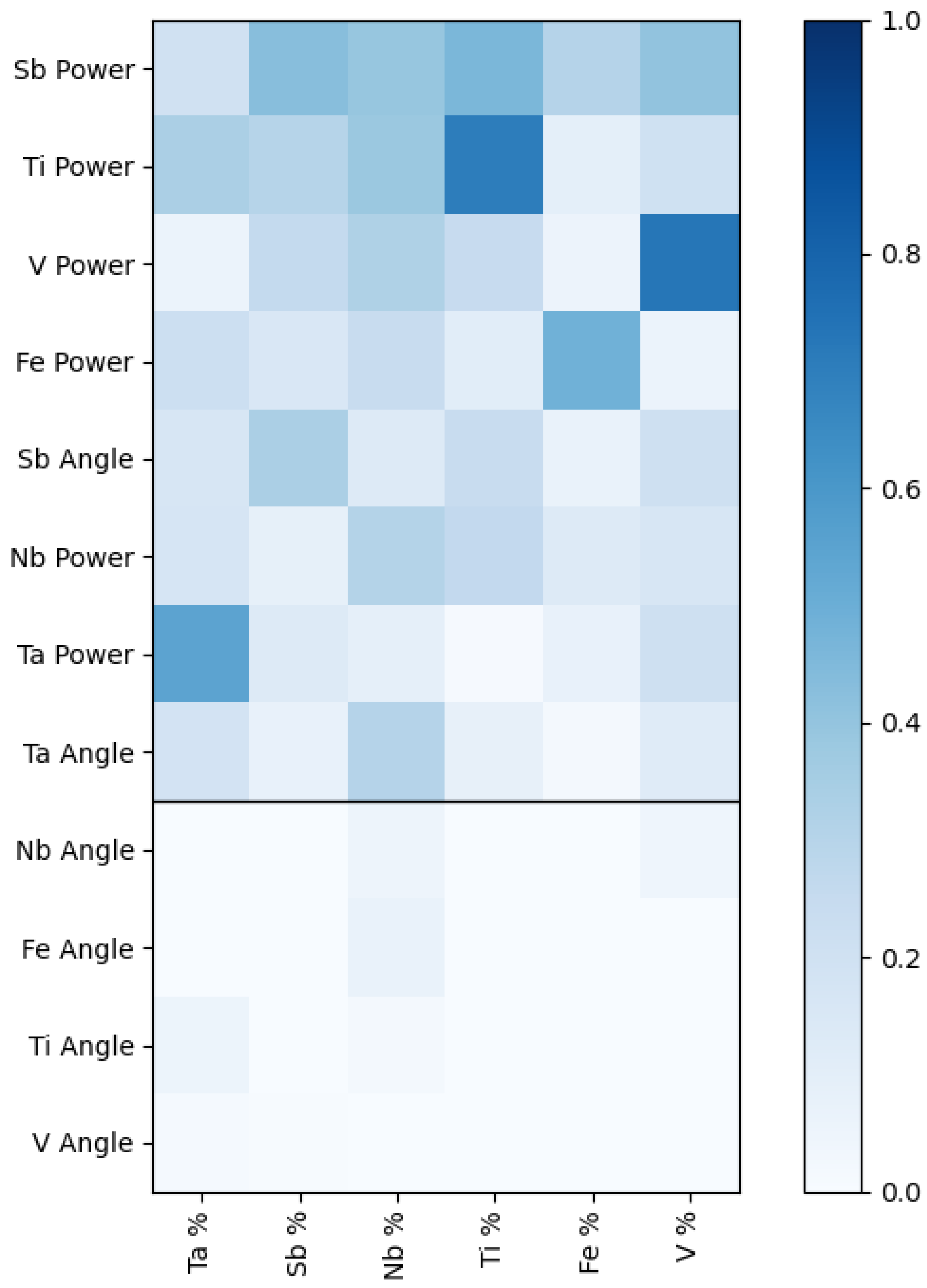
3.2. Feature Importance and Interdependence
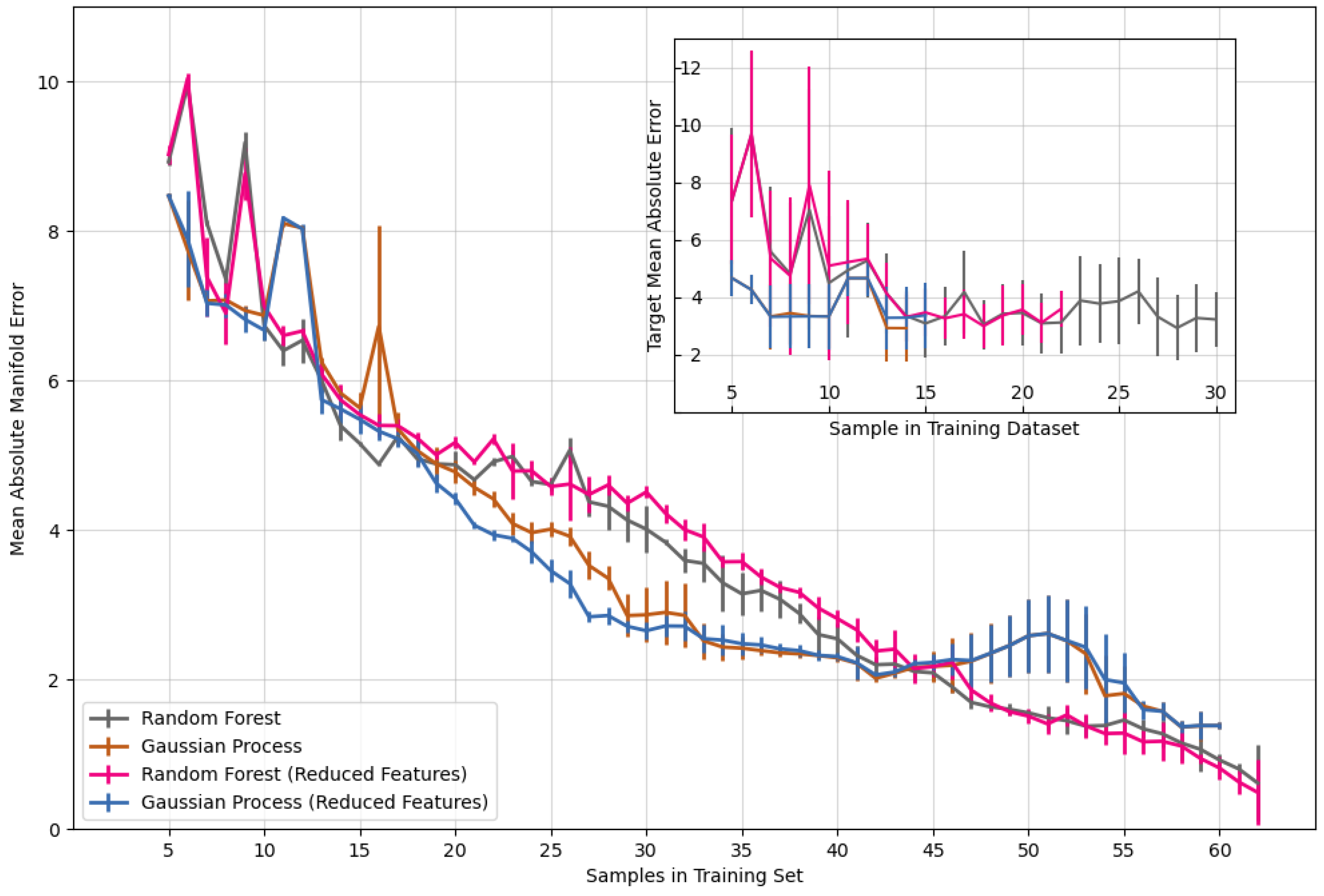
3.3. Comparison to Other Active Learning Optimization Approaches
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, S.Y.; Nguyen, T.X.; Su, Y.H.; Lin, C.C.; Huang, Y.J.; Shen, Y.H.; Liu, C.P.; Ruan, J.J.; Chang, K.S.; Ting, J.M. Sputter-Deposited High Entropy Alloy Thin Film Electrocatalyst for Enhanced Oxygen Evolution Reaction Performance. Small 2022, 18, 2106127. [Google Scholar] [CrossRef] [PubMed]
- Jung, S.G.; Han, Y.; Kim, J.H.; Hidayati, R.; Rhyee, J.S.; Lee, J.M.; nd Woo Seok Choi, W.N.K.; Jeon, H.R.; Suk, J.; Park, T. High critical current density and high-tolerance superconductivity in high-entropy alloy thin films. Nat. Commun. 2022, 13, 3373. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.; Wang, Y.; Xue, C.; Han, C.; Hei, H.; Xue, Y.; Liu, Z.; Wu, Y.; Ma, Y.; Gao, J.; et al. Chemical vapor deposition diamond nucleation and initial growth on TiZrHfNb and TiZrHfNbTa high entropy alloys. Mater. Lett. 2022, 309, 131366. [Google Scholar] [CrossRef]
- Han, C.; Zhi, J.; Zeng, Z.; Wang, Y.; Zhou, B.; Gao, J.; Wu, Y.; He, Z.; Wang, X.; Yu, S. Synthesis and characterization of nano-polycrystal diamonds on refractory high entropy alloys by chemical vapour deposition. Appl. Surf. Sci. 2023, 623, 157108. [Google Scholar] [CrossRef]
- Kim, Y.S.; Park, H.J.; Mun, S.C.; Jumaev, E.; Hong, S.H.; Song, G.; Kim, J.T.; Park, Y.K.; Kim, K.S.; Jeong, S.I.; et al. Investigation of structure and mechanical properties of TiZrHfNiCuCo high entropy alloy thin films synthesized by magnetron sputtering. J. Alloys Compd. 2019, 797, 834–841. [Google Scholar] [CrossRef]
- Rar, A.; Frafjord, J.J.; Fowlkes, J.D.; Specht, E.D.; Rack, P.D.; Santella, M.L.; Bei, H.; George, E.P.; Pharr, G.M. PVD synthesis and high-throughput property characterization of Ni—Fe—Cr alloy libraries. Meas. Sci. Technol. 2019, 16, 834–841. [Google Scholar] [CrossRef]
- Wang, K.; Nishio, K.; Horiba, K.; Kitamura, M.; Edamura, K.; Imazeki, D.; Nakayama, R.; Shimizu, R.; Kumigashira, H.; Hitosugi, T. Synthesis of High-Entropy Layered Oxide Epitaxial Thin Films: LiCr1/6Mn1/6Fe1/6Co1/6Ni1/6Cu1/6O2. Cryst. Growth Des. 2022, 22, 1116–1122. [Google Scholar] [CrossRef]
- Anand, S.; Xia, K.; Hegde, V.I.; Aydemir, U.; Kocevski, V.; Zhu, T.; Wolverton, C.; Snyder, G.J. A valence balanced rule for discovery of 18-electron half-Heuslers with defects. Energy Environ. Sci. 2018, 11, 1480–1488. [Google Scholar] [CrossRef]
- Zarnetta, R. Identification of quarternary shape memory alloys with near-zero thermal hysteresis and unprecedented functional stability. Adv. Funct. Mater. 2010, 20, 1917–1923. [Google Scholar] [CrossRef]
- Hasan, N.M.A.; Hou, H.; Sarkar, S.; Thienhaus, S.; Mehta, A.; Ludwig, A.; Takeuchi, I. Combinatorial Synthesis and High-Throughput Characterization of Microstructure and Phase Transformation in Ni-Ti-Cu-V Quarternary Thin-Film Library. Engineering 2020, 6, 637–643. [Google Scholar] [CrossRef]
- Liang, A.; Goodelman, D.C.; Hodge, A.M.; Farkas, D.; Branicio, P.S. CoFeNiTix and CrFeNiTix high entropy alloy thin films microstructure formation. Acta Mater. 2023, 257, 119163. [Google Scholar] [CrossRef]
- Oses, C.; Toher, C.; Curtarolo, S. High-entropy ceramics. Nat. Rev. Mater. 2020, 5, 295–309. [Google Scholar] [CrossRef]
- Gregoire, J.M.; Zhou, L.; Haber, J.A. Combinatorial synthesis for AI-driven materials discovery. Nat. Synth. 2023, 2, 493–504. [Google Scholar] [CrossRef]
- Bunn, J.K.; Voepel, R.Z.; Wang, Z.; Gatzke, E.P.; Lauterbach, J.A.; Hattrick-Simpers, J.R. Development of an Optimization Procedure for Magnetron-Sputtered Thin Films to Facilitate Combinatorial Materials Research. Ind. Eng. Chem. Res. 2016, 55, 1236–1242. [Google Scholar] [CrossRef]
- Xia, A.; Togni, A.; Hirn, S.; Bolelli, G.; Lusvarghi, L.; Franz, R. Angular-dependent deposition of MoNbTaVW HEA thin films by three different physical vapor deposition methods. Surf. Coatings Technol. 2020, 385, 119163. [Google Scholar] [CrossRef]
- Alami, J.; Eklund, P.; Emmerlich, J.; Wilhelmsson, O.; Jansson, U.; Högberg, H.; Hultman, L.; Helmersson, U. High-power impulse magnetron sputtering of Ti—Si—C thin films from a Ti3SiC2 compound target. Thin Solid Films 2006, 515, 1731–1736. [Google Scholar] [CrossRef]
- Deki, S.; Aoi, Y.; Asaoka, Y.; Kajinami, A.; Mizuhata, M. Monitoring the growth of titanium oxide thin films by the liquid-phase deposition method with a quartz crystal microbalance. J. Mater. Chem. 1997, 7, 733–736. [Google Scholar] [CrossRef]
- Gongora, A.E.; Xu, B.; Perry, W.; Okoye, C.; Riley, P.; Reyes, K.G.; Morgan, E.F.; Brown, K.A. A Bayesian experimental autonomous researcher for mechanical design. Sci. Adv. 2020, 6, eaaz1708. [Google Scholar] [CrossRef]
- Xue, D.; Balachandran, P.V.; Hogden, J.; Theiler, J.; Xue, D.; Lookman, T. Accelerated search for materials with targeted properties by adaptive design. Nat. Commun. 2016, 7, 11241. [Google Scholar] [CrossRef]
- Kusne, A.G.; Yu, H.; Wu, C.; Zhang, H.; Hattrick-Simpers, J.; DeCost, B.; Sarker, S.; Oses, C.; Toher, C.; Curtarolo, S.; et al. On-the-fly closed-loop materials discovery via Bayesian active learning. Nat. Commun. 2020, 11, 5966. [Google Scholar] [CrossRef]
- Nikolaev, P.; Hooper, D.; Webber, F.; Rahul Rao, K.D.; Krein, M.; Poleski, J.; Barto, R.; Maruyama, B. Autonomy in materials research: A case study in carbon nanotube growth. NPJ Comput. Mater. 2016, 2, 16031. [Google Scholar] [CrossRef]
- Ament, S.; Amsler, M.; Sutherland, D.R.; Chang, M.C.; Guevarra, D.; Connolly, A.B.; Gregoire, J.M.; Thompson, M.O.; Gomes, C.P.; Dover, R.B.V. Autonomous materials synthesis via hierarchical active learning of nonequilibrium phase diagrams. Sci. Adv. 2021, 7, eabg4930. [Google Scholar] [CrossRef] [PubMed]
- Zeier, W.G.; Schmitt, J.; Hautier, G.; Aydemir, U.; Gibbs, Z.M.; Felser, C.; Snyder, G.J. Engineering half-Heusler thermoelectric materials using Zintl chemistry. Nat. Mater. 2016, 1, 16032. [Google Scholar] [CrossRef]
- AJA International. ATC Orion Magnetron Sputtering System. 2023. Available online: https://www.ajaint.com/atc-orion-series-sputtering-systems.html (accessed on 1 March 2024).
- Kurt J. Lesker Co. Sputtering Targets. 2023. Available online: www.lesker.com/materials-division.cfm/section-sputtering-targets (accessed on 1 December 2023).
- JEOL Ltd. JEOL JXA-8230. 2023. Available online: https://www.jeol.com/products/scientific/epma/ (accessed on 1 March 2024).
- Takakura, M.; Takahashi, H.; Okumura, T. Thin-Film Analysis with Electron Probe X-ray MicroAnalyzer; Elsevier: Amsterdam, The Netherlands, 1998; Volume 33E. [Google Scholar]
- Abou-Ras, D.; Caballero, R.; Fischer, C.H.; Kaufmann, C.; Lauermann, I.; Mainz, R.; Mönig, H.; Schöpke, A.; Stephan, C.; Streeck, C.; et al. Comprehensive Comparison of Various Techniques for the Analysis of Elemental Distributions in Thin Films. Microsc. Microanal. 2011, 17, 728–751. [Google Scholar] [CrossRef] [PubMed]
- Lookman, T.; Balachandran, P.V.; Xue, D.; Yuan, R. Active learning in materials science with emphasis on adaptive sampling using uncertainties for targeted design. NPJ Comput. Mater. 2019, 5, 21. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K. Gaussian Processes for Machine Learning; Springer: Cham, Switzerland, 2006; Volume 1. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Grinsztajn, L.; Oyallon, E.; Varoquaux, G. Why do tree-based models still outperform deep learning on typical tabular data? Adv. Neural Inf. Process. Syst. 2022, 35, 507–520. [Google Scholar]
- Mishra, A.A.; Edelen, A.; Hanuka, A.; Mayes, C. Uncertainty quantification for deep learning in particle accelerator applications. Phys. Rev. Accel. Beams 2021, 24, 114601. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A. An empirical comparison of supervised learning algorithms. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 161–168. [Google Scholar]
- Rodriguez-Galiano, V.; Sanchez-Castillo, M.; Chica-Olmo, M.; Chica-Rivas, M. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geol. Rev. 2015, 71, 804–818. [Google Scholar] [CrossRef]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef] [PubMed]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Adhikari, A.; Tax, D.M.; Satta, R.; Faeth, M. LEAFAGE: Example-based and Feature importance-based Explanations for Black-box ML models. In Proceedings of the 2019 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), New Orleans, LA, USA, 23–26 June 2019; pp. 1–7. [Google Scholar]
- Davis, B.; Glenski, M.; Sealy, W.; Arendt, D. Measure utility, gain trust: Practical advice for XAI researchers. In Proceedings of the 2020 IEEE Workshop on Trust and Expertise in Visual Analytics (TREX), Salt Lake City, UT, USA, 25–30 October 2020; pp. 1–8. [Google Scholar]
- Neidhardt, J.; Mráz, S.; Schneider, J.M.; Strub, E.; Bohne, W.; Liedke, B.; Möller, W.; Mitterer, C. Experiment and simulation of the compositional evolution of Ti—B thin films deposited by sputtering of a compound target. J. Appl. Phys. 2008, 104, 063304. [Google Scholar] [CrossRef]
- Bishnoi, S.; Singha, S.; Ravindera, R.; Bauchyb, M.; Gosvamic, N.N.; Kodamanad, H.; Krishnan, N.A. Predicting Young’s modulus of oxide glasses with sparse datasets using machine learning. J. Non-Cryst. Solids 2019, 524, 119643. [Google Scholar] [CrossRef]
- Tripathi, B.M.; Sinha, A.; Mahata, T. Machine learning guided study of composition-coefficient of thermal expansion relationship in oxide glasses using a sparse dataset. Mater. Today Proc. 2022, 67, 326–329. [Google Scholar] [CrossRef]
- Mekki-Berrada, F.; Ren, Z.; Huang, T.; Wong, W.K.; Zheng, F.; Xie, J.; Tian, I.P.S.; Jayavelu, S.; Mahfoud, Z.; Bash, D.; et al. Two-step machine learning enables optimized nanoparticle synthesis. NPJ Comput. Mater. 2021, 7, 55. [Google Scholar] [CrossRef]
- MacLeod, B.P.; Parlane, F.G.L.; Morrisey, T.D.; Hase, F.; Roch, L.M.; Dettelbach, K.E.; Moreira, R.; Yunker, L.P.E.; Rooney, M.B.; Deeth, J.R.; et al. Self-driving laboratory for accelerated discovery of thin-film materials. Sci. Adv. 2020, 6, eaaz8867. [Google Scholar] [CrossRef]
- MacLeod, B.P.; Parlane, F.G.L.; Rupnow, C.C.; Dettelbach, K.E.; Elliott, M.S.; Morrissey, T.D.; Haley, T.H.; Proskurin, O.; Rooney, M.B.; Taherimakhsousi, N.; et al. A self-driving laboratory advances the Pareto front for material properties. Nat. Commun. 2022, 13, 995. [Google Scholar] [CrossRef] [PubMed]
- Merchant, A.; Batzner, S.; Schoenholz, S.S.; Aykol, M.; Cheon, G.; Cubuk, E.D. Scaling deep learning for materials discovery. Nature 2023, 624, 80–85. [Google Scholar] [CrossRef]
- Kelly, P.; Arnell, R. Magnetron sputtering: A review of recent developments and applications. Vacuum 2000, 56, 159–172. [Google Scholar] [CrossRef]
- Musila, J.; Barocha, P.; Vlcĕka, J.; Namc, K.; Hanc, J. Reactive magnetron sputtering of thin films: Present status and trends. Thin Solid Films 2005, 475, 208–218. [Google Scholar] [CrossRef]
- Sarakinos, K.; Alami, J.; Konstantinidis, S. High power pulsed magnetron sputtering: A review on scientific and engineering state of the art. Surf. Coatings Technol. 2010, 204, 1661–1684. [Google Scholar] [CrossRef]
- Sloyan, K.A.; May-Smith, T.C.; Eason, R.W.; Lunney, J.G. The effect of relative plasma plume delay on the properties of complex oxide films grown by multi-laser, multi-target combinatorial pulsed laser deposition. Appl. Surf. Sci. 2009, 255, 9066–9070. [Google Scholar] [CrossRef]
- Keller, D.A.; Ginsburg, A.; Barad, H.N.; Shimanovich, K.; Bouhadana, Y.; Rosh-Hodesh, E.; Takeuchi, I.; Aviv, H.; Tischler, Y.R.; Anderson, A.Y.; et al. Utilizing Pulsed Laser Deposition Lateral Inhomogeneity as a Tool in Combinatorial Material Science. ACS Comb. Sci. 2015, 17, 209–221. [Google Scholar] [CrossRef]
- Dunlap, J.H.; Ethier, J.G.; Putnam-Neeb, A.A.; Iyer, S.; Luo, S.X.L.; Feng, H.; Torres, J.A.G.; Doyle, A.G.; Swager, T.M.; Vaia, R.A.; et al. Continuous flow synthesis of pyridinium salts accelerated by multi-objective Bayesian optimization with active learning. Chem. Sci. 2023, 14, 8061–8069. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Johnson, N.S.; Mishra, A.A.; Kirsch, D.J.; Mehta, A. Active Learning for Rapid Targeted Synthesis of Compositionally Complex Alloys. Materials 2024, 17, 4038. https://doi.org/10.3390/ma17164038
Johnson NS, Mishra AA, Kirsch DJ, Mehta A. Active Learning for Rapid Targeted Synthesis of Compositionally Complex Alloys. Materials. 2024; 17(16):4038. https://doi.org/10.3390/ma17164038
Chicago/Turabian StyleJohnson, Nathan S., Aashwin Ananda Mishra, Dylan J. Kirsch, and Apurva Mehta. 2024. "Active Learning for Rapid Targeted Synthesis of Compositionally Complex Alloys" Materials 17, no. 16: 4038. https://doi.org/10.3390/ma17164038
APA StyleJohnson, N. S., Mishra, A. A., Kirsch, D. J., & Mehta, A. (2024). Active Learning for Rapid Targeted Synthesis of Compositionally Complex Alloys. Materials, 17(16), 4038. https://doi.org/10.3390/ma17164038