1. Introduction
Additive manufacturing (AM) of metals is known as a promising technology for a wide range of industrial applications. In general, AM involves the production of components through the melting of precursor material, called the feedstock, by a powerful, localized heat source based on information from a computer-aided design (CAD) file [
1]. AM has certain advantages over conventional subtractive manufacturing techniques such as grinding or milling; it produces less wasted material, can create more complex shapes, and offers reduction in lead time [
2,
3]. Customization of the manufacturing process is much easier with AM, as there is no need to create custom tooling or molds [
4]. Wire-arc AM (WAAM) is a particular form of AM derived from welding, where the feedstock is a metal wire and the heat source is a welding arc [
5,
6,
7]. Compared with other AM techniques like powder-bed-based methods, WAAM offers faster deposition rates and larger part size, at the expense of a reduced ability to create complex designs and reduced surface quality [
7]. There are many potential industrial applications of WAAM, such as for aluminum parts for aerospace applications, steel bars for construction, or large parts like propellers and rudders for use in shipbuilding [
3,
8,
9,
10,
11].
Today, there are still challenges which limit the spread of the AM of metals for industrial application. The powerful localized heat source used causes steep temperature gradients, which in turn cause significant residual stresses in the material. These stresses can further lead to cracking and distortion, reducing the quality of the manufactured parts [
12,
13,
14]. The rapid heating and cooling can also result in pore defects, which result in parts with lower tensile strength and greater susceptibility to fatigue [
15]. To mitigate this, postprocessing with heat treatment to reduce the residual stress and reduce porosity is necessary [
15,
16]. The cycles of rapid heating, cooling, and reheating is unique to metal AM, and since it is a young technology compared with conventional manufacturing techniques, the exact relationship between process parameters and the resulting mechanical properties is not yet known [
14,
17]. However, it is well established that the temperature distribution during AM affects the residual stresses, with a more uniform distribution resulting in stresses of lower magnitude [
17,
18,
19,
20,
21]. A greater understanding of the WAAM process in general and the temperature distribution specifically is therefore needed if widespread industrial application is to become a reality. A potential aid here is a digital twin (DT), which is defined as “a digital representation of a production system or service” [
22]. A DT could be used to predict properties like temperature and residual stress distribution before the AM procedure is performed, integrate measured data for real-time prediction, and even alter the manufacturing process based on results from the digital model [
23,
24]. DT models are believed to greatly increase the viability of metal AM for industry [
24,
25].
One tool which can be used to model AM is finite element (FE) simulation. FE simulations can model various AM processes with a high degree of accuracy and give insight into the temperature evolution during production as well as the resulting residual stress profile [
16,
26,
27]. However, FE simulation has a major drawback: it is slow and computationally expensive, often requiring hours or days to obtain results. Real-time prediction of temperature evolution is therefore impossible with an FE model alone. For this reason, surrogate models, simplified alternatives to numerical simulations, are being explored as an option [
28]. Many researchers have investigated the possibility of using machine learning (ML) to create surrogate models, with the ultimate goal of achieving real-time prediction while retaining good accuracy [
29,
30]. Many different ML methods have been explored, with varying degrees of complexity.
Mozaffar et al. [
31] developed a surrogate method for determining the thermal history during directed energy deposition (DED), a subset of AM processes which includes WAAM, as a function of process parameters. Their surrogate model used a recurrent neural network (RNN), with its inputs being an engineered feature for the tool path, deposition time, laser intensity, and current layer height. To aid with process optimization for powder-bed-based methods, another major subgroup of AM, Stathatos et al. [
32] created a multilayer perceptron (MLP)-based model for predicting temperature evolution and density. The model consisted of several neural networks in sequence—one main network for determining the temperature and additional “rider” networks for predicting other properties that depend on the temperature. As input, the main network in their model took in information about the laser path and past temperatures, and they applied it to data from a simulation of a laser following a random path.
More recently, there have been many more studies performed using a variety of different ML methods. Ness et al. [
33] created data-driven models for temperature prediction using the extra trees algorithm. Extra trees is in the decision-tree family of algorithms, and their model utilized several engineered features, including the distance between the node and the heat source and the power influence of the heat source [
34]. They applied their models to FE-simulated AM depositions of aluminum alloy, with varying deposition patterns and power intensities, to investigate how well the models would perform when applied to another system with a different pattern or intensity. Their results showed that while the models worked well for prediction on the training system, with a mean absolute percentage error (MAPE) of less than 5%, transferability to different systems gave worse results, with the MAPE ranging from around 5 to 25% [
33]. Le et al. [
35] applied an MLP-based method to model temperature distribution in the WAAM of 316L steel using FE simulations. As input features, they used the heat input, node coordinates, and time. Even with these relatively simple inputs, they were able to obtain good prediction accuracy with their model for WAAM-deposited multilayer bars. Xie et al. [
36] used a hybrid physical/data-driven method, a physics-informed neural network (PINN), to model the three-dimensional temperature field during the DED of bars of nickel–chromium alloy. Their model used an approximation of the partial differential equation for heat conduction during the process for the physics-informed part and the laser power and scanning speed, time, and coordinates as input for the data-driven part. The data were obtained from FE simulations of deposition of single-layer and multilayer bars. They found that they were able to achieve high-accuracy prediction with a smaller amount of data than purely data-driven models require. Wacker et al. [
37] used two kinds of neural network models to predict the resulting accuracy and distortion for multilayer parts produced by WAAM. The training data were obtained experimentally through WAAM performed on steel. The first data-driven model used only the welding parameters as inputs, while the second model also included recursive parameters from the output.
Our overarching goal is to construct a comprehensive dataset for WAAM. This dataset will facilitate real-time predictions of the thermal history of WAAM-produced components, regardless of their shape or size, once the component design is finalized by CAD and fundamental process parameters are selected. We refer to this predictive capability as transferability, meaning that we can transfer the thermal history from known components to new and unknown ones. In this study, we used MLP models to test the transferability for WAAM production of different thin rectangular bars. MLP models were chosen over RNNs, which are by definition more appropriate for a time-series prediction [
38]. We wanted to evaluate the feasibility of simple MLPs as an alternative, since they are very simple to implement and train. Additionally, if simple MLPs are found to perform well at predicting WAAM temperature history, more advanced RNN-based models will be expected to perform even better.
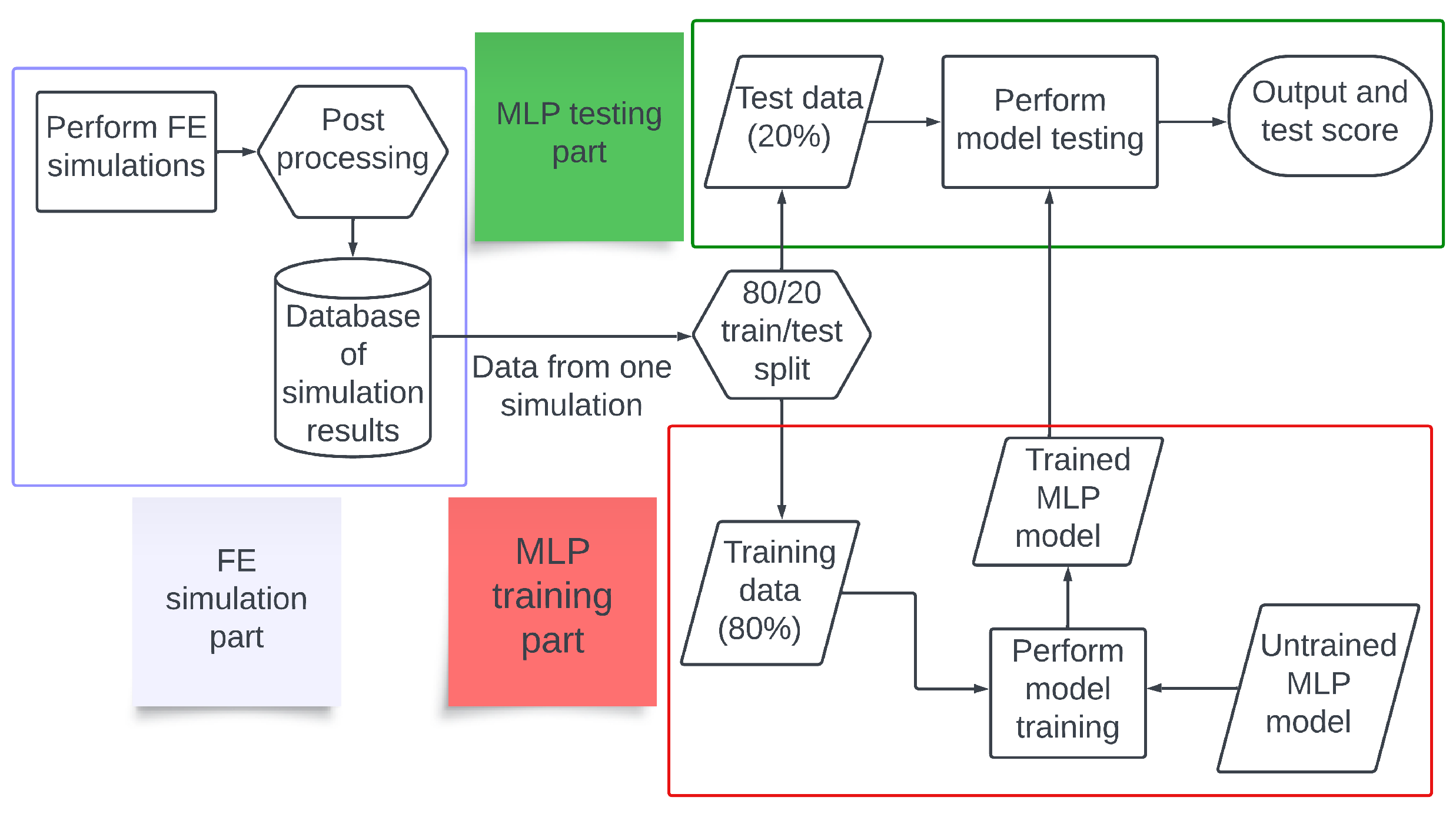
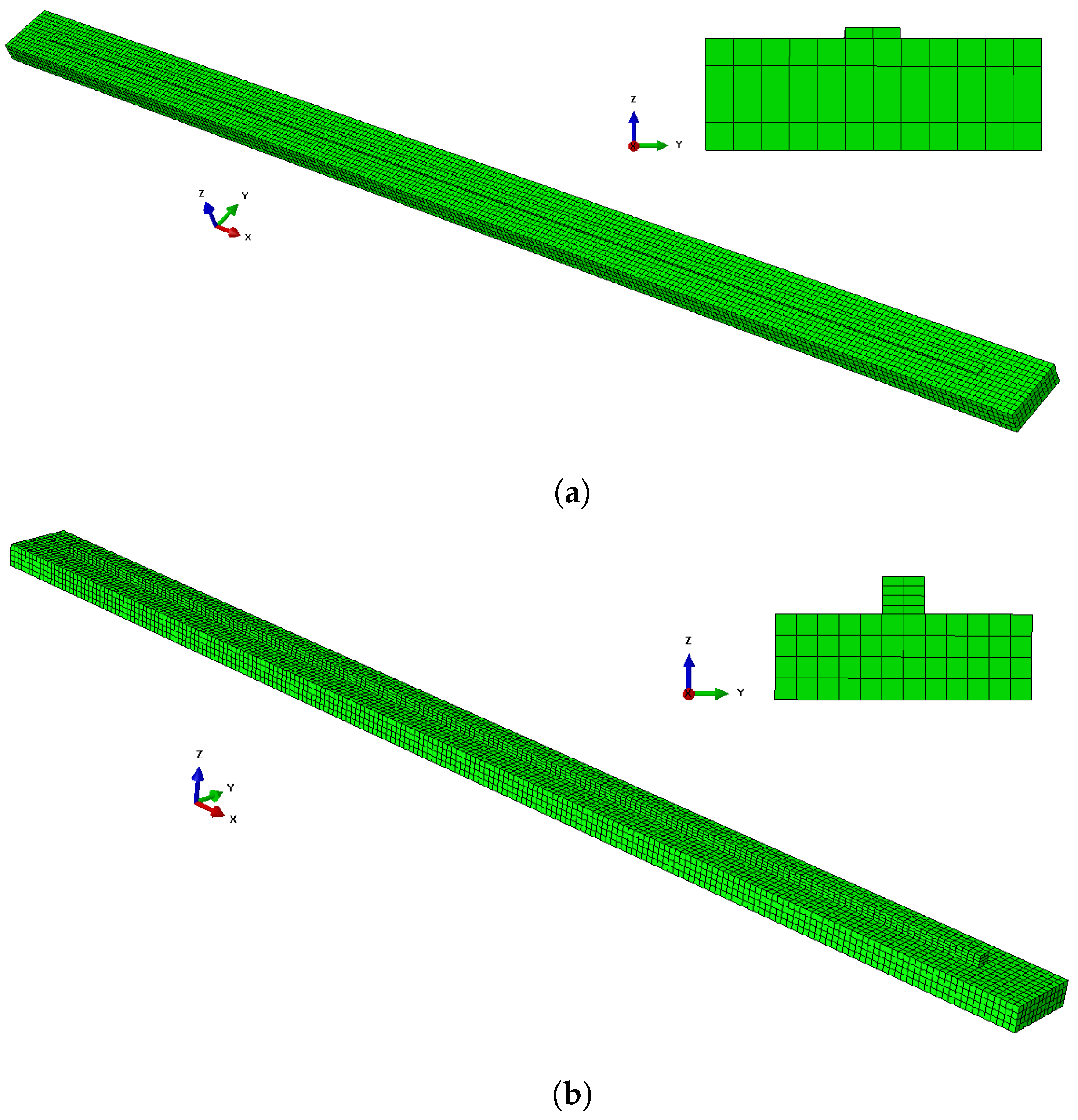
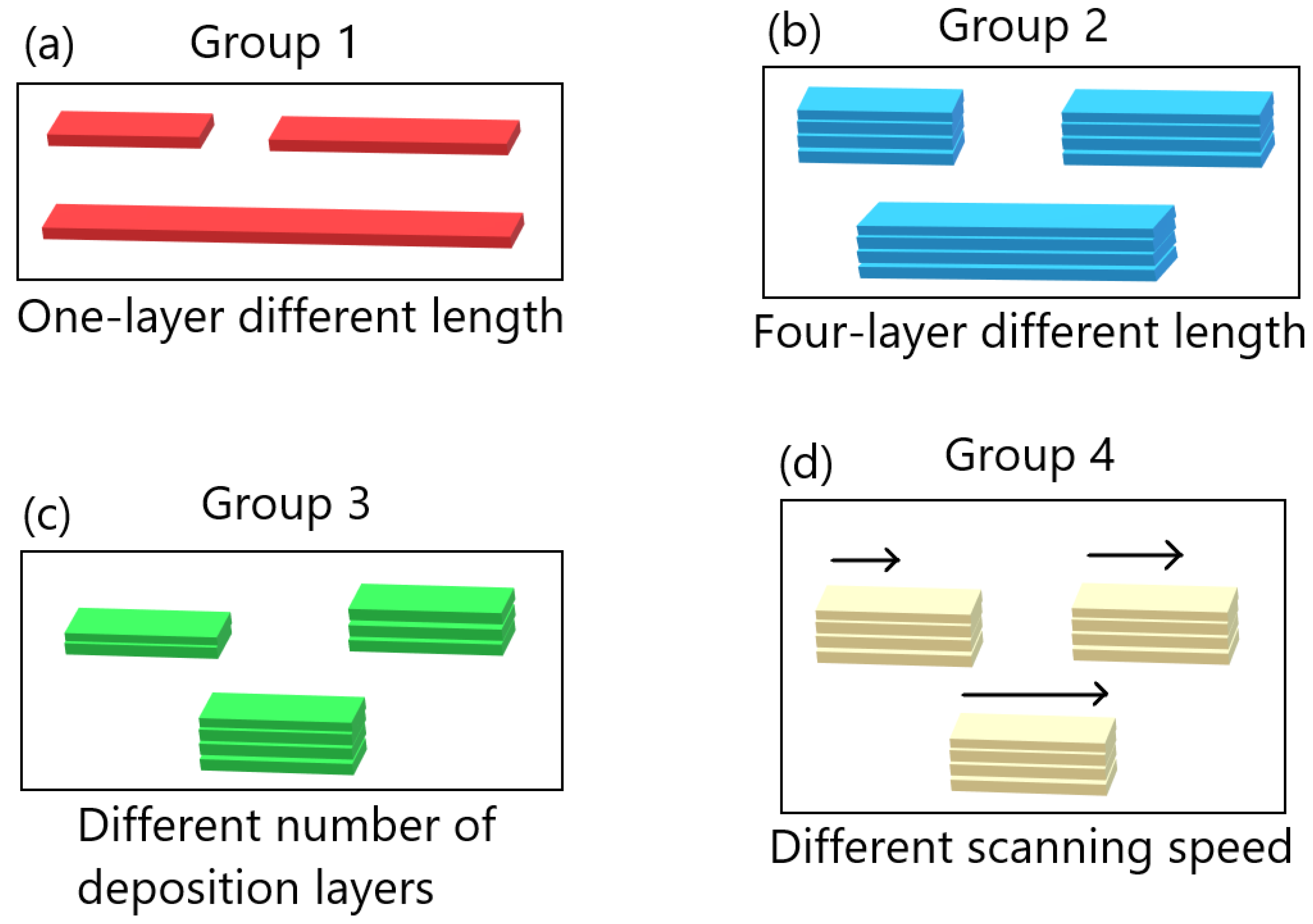
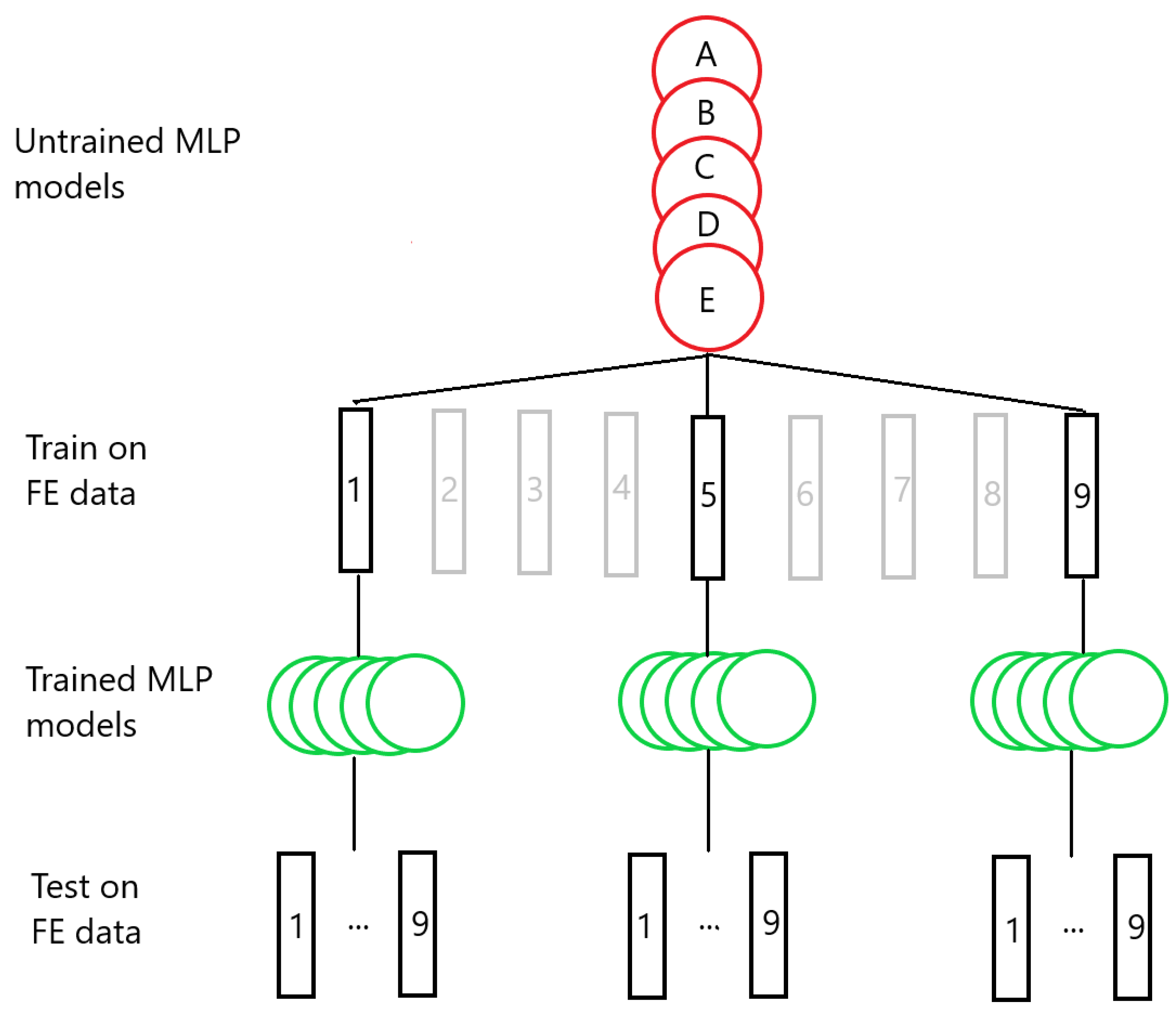
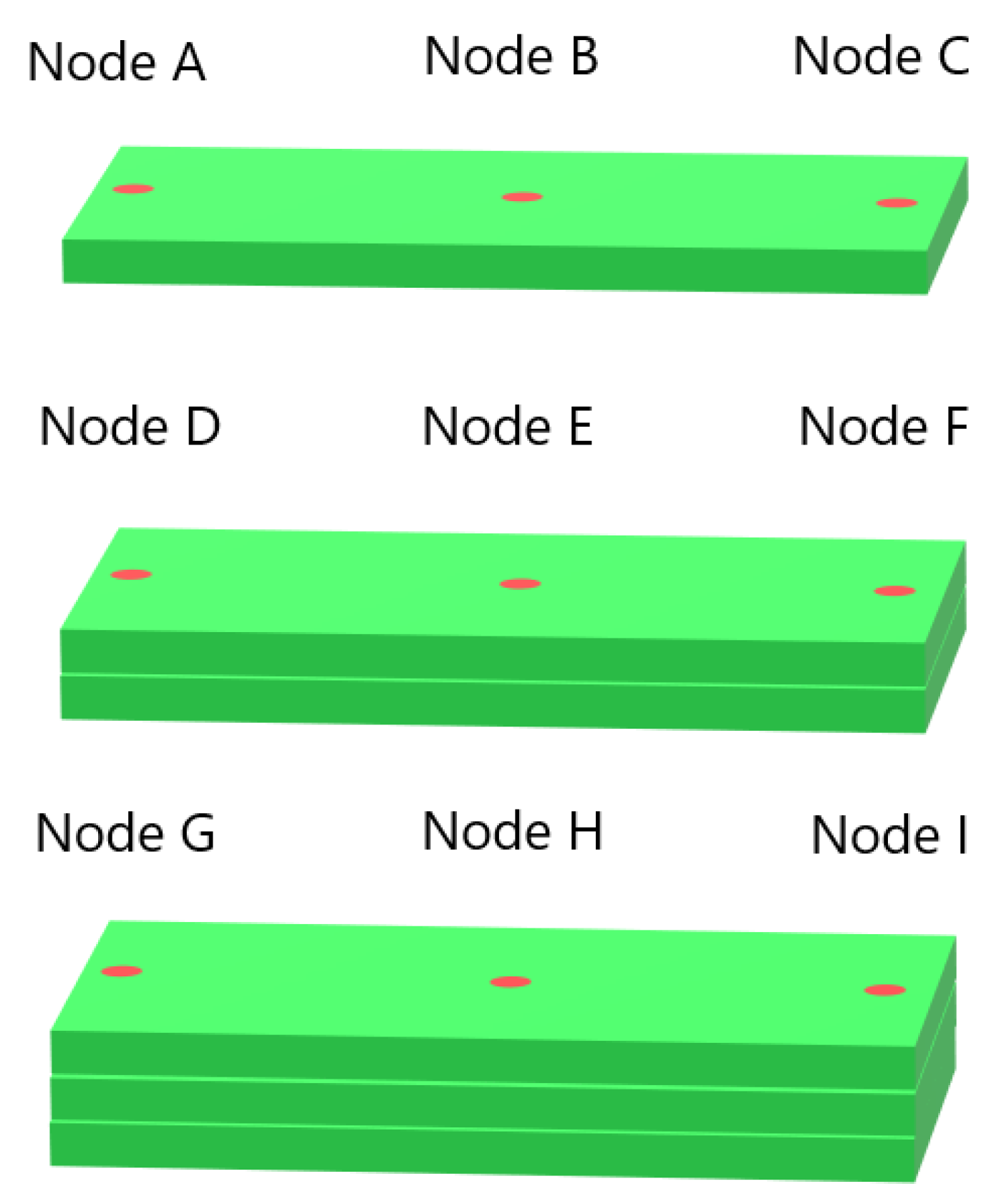
We performed 40 FE simulations of different WAAM processes with varying bar lengths, numbers of deposition layers, and scanning speeds. Unlike the MLP models used by Le et al. [
35], our MLP models used only the current time and past temperatures of the node as input. The MLPs were trained on data from one of the FE simulations and were tested on data from other simulations with different parameters. In
Section 2, we discuss how the FE simulations were conducted and how the MLPs were set up. Then, in
Section 3 we present the results of testing the transferability using the MLP models. Finally, in
Section 4 we sum up our conclusions and present some future perspectives.
4. Conclusions
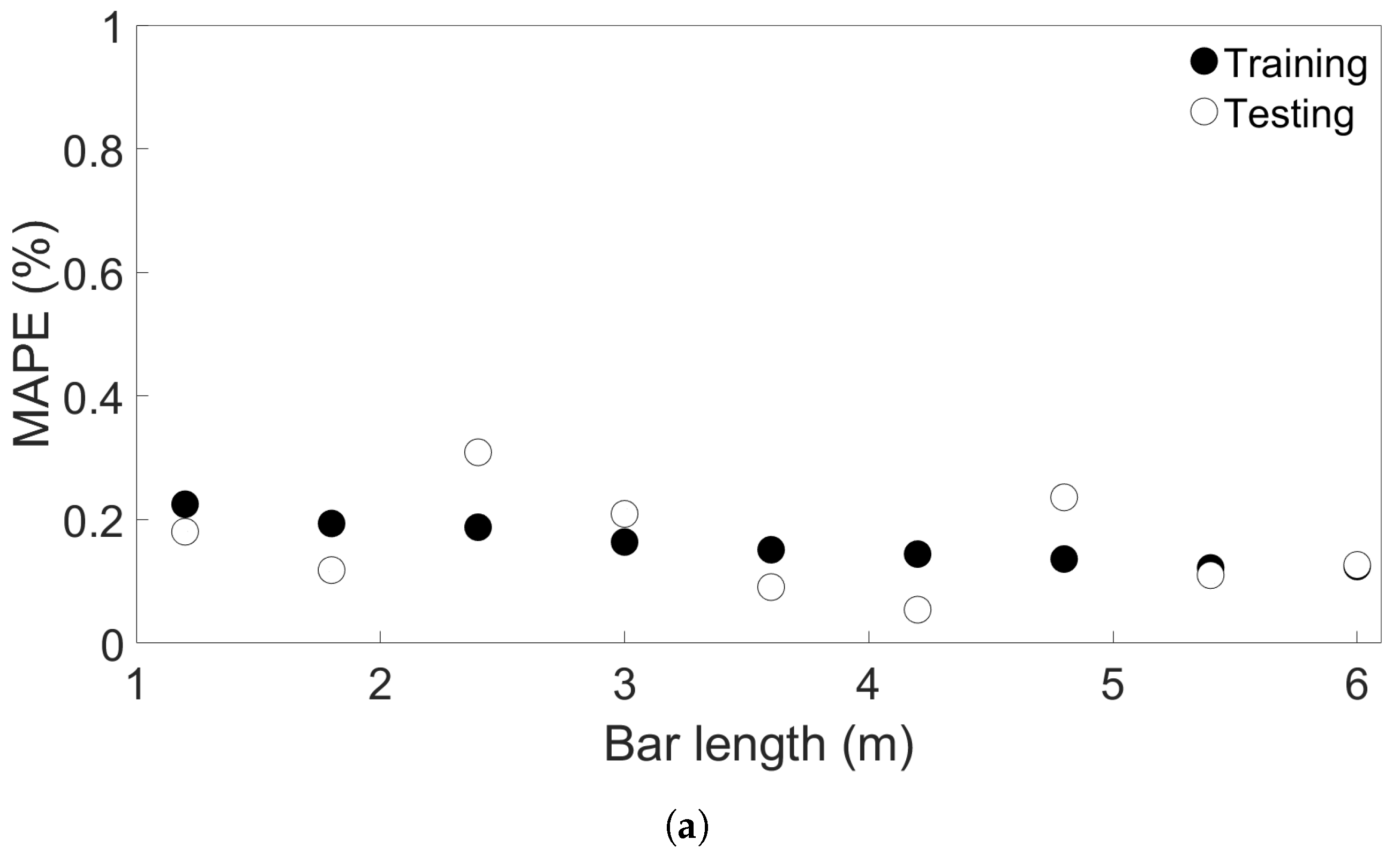
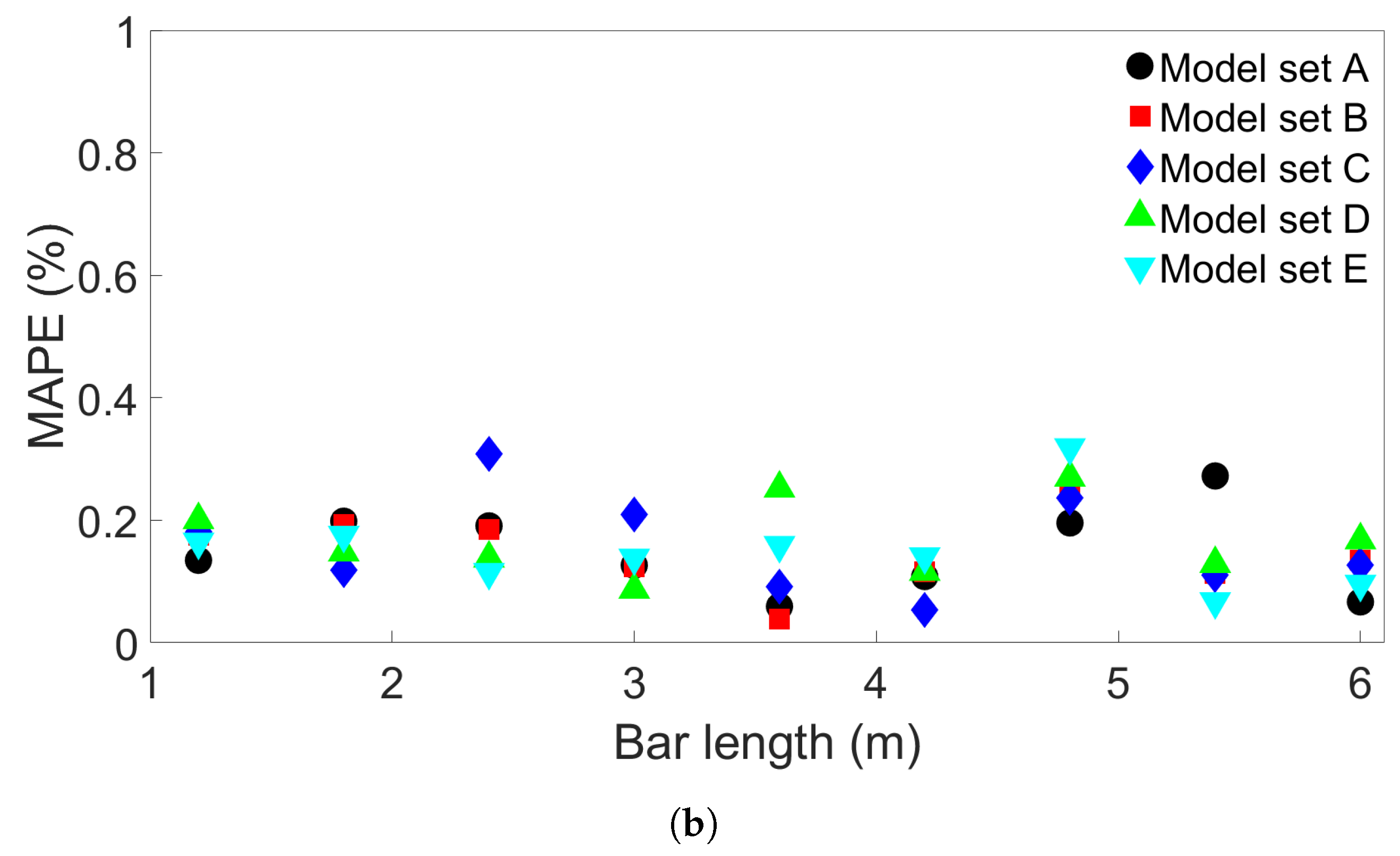
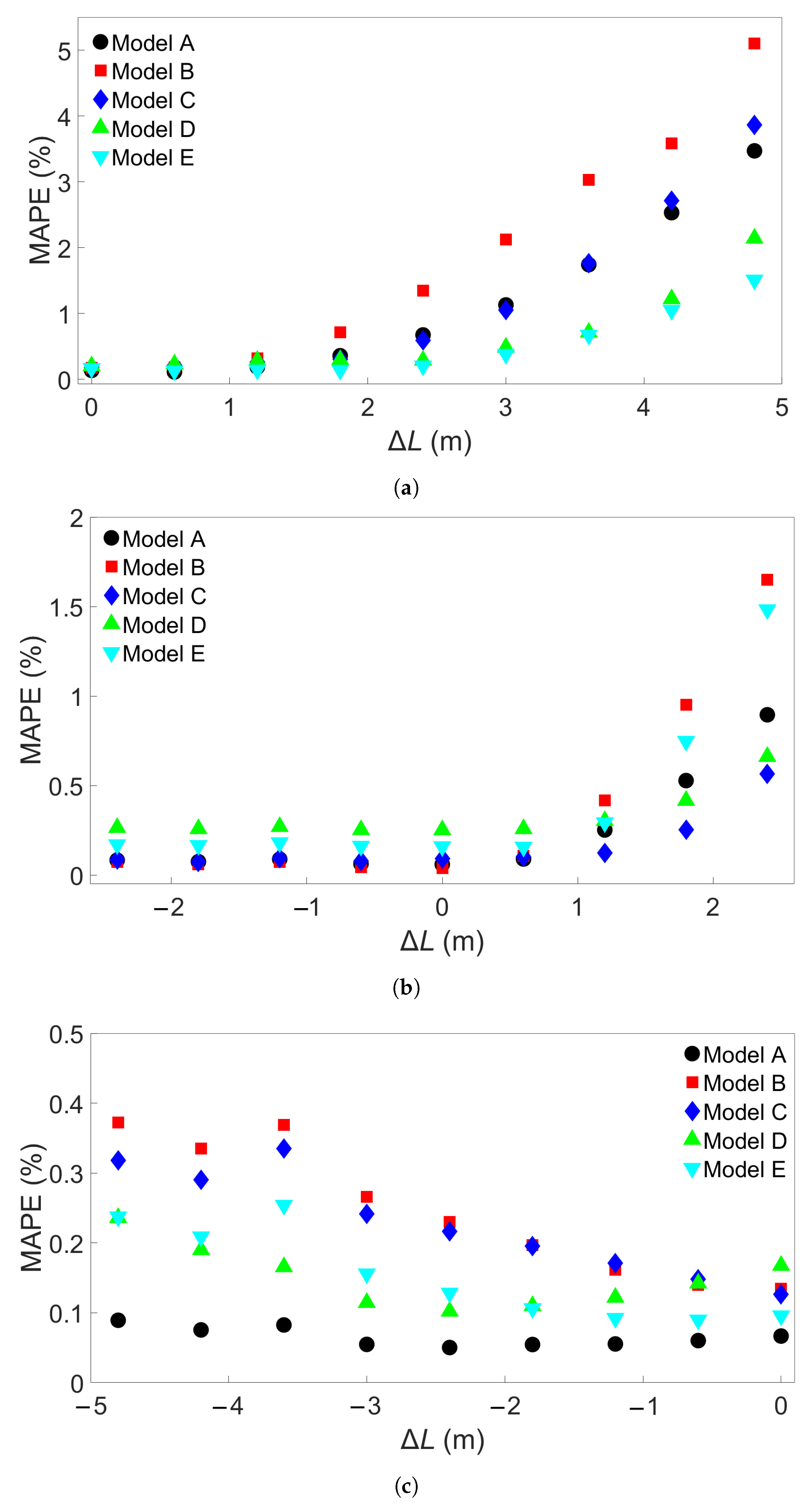
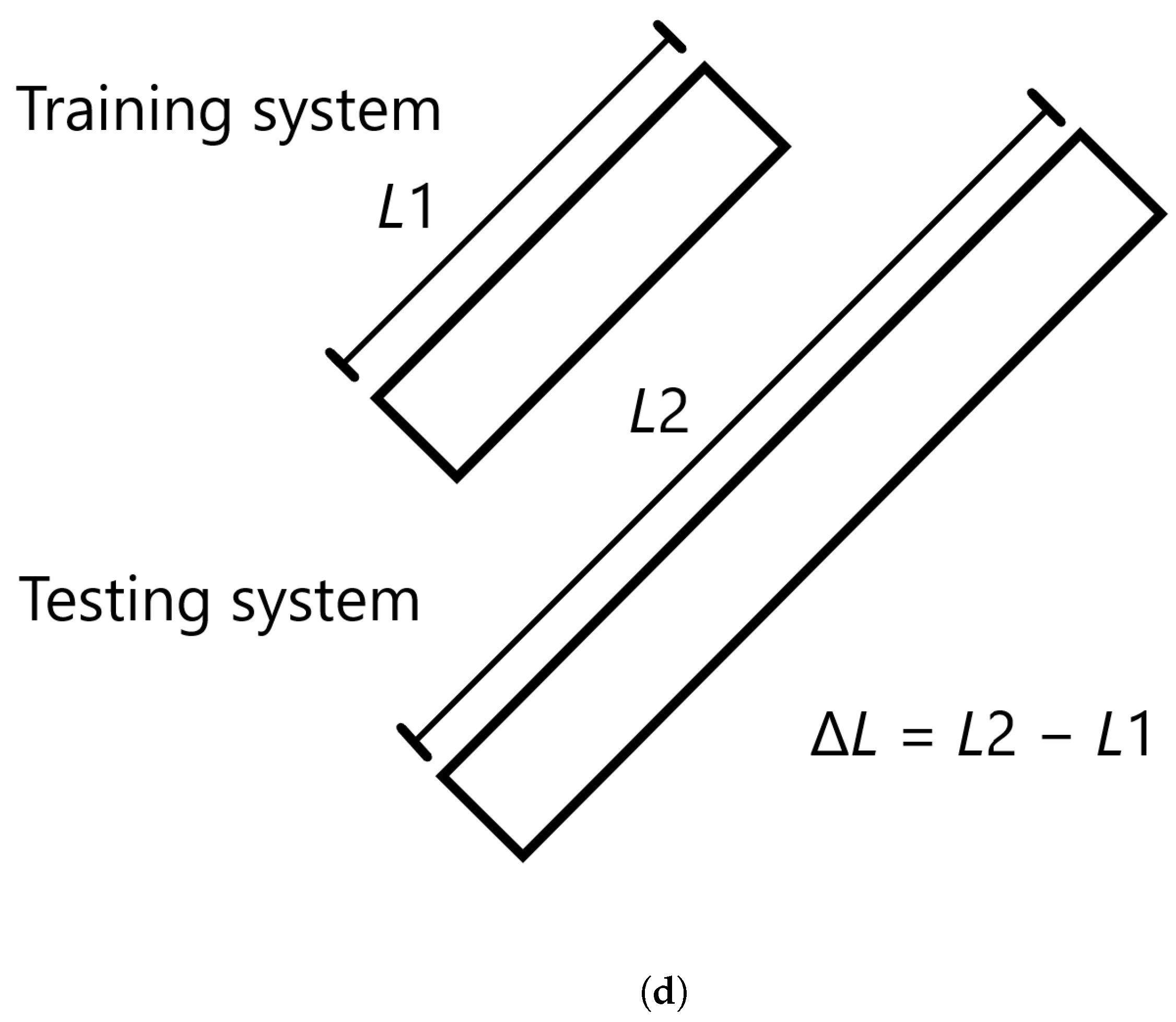
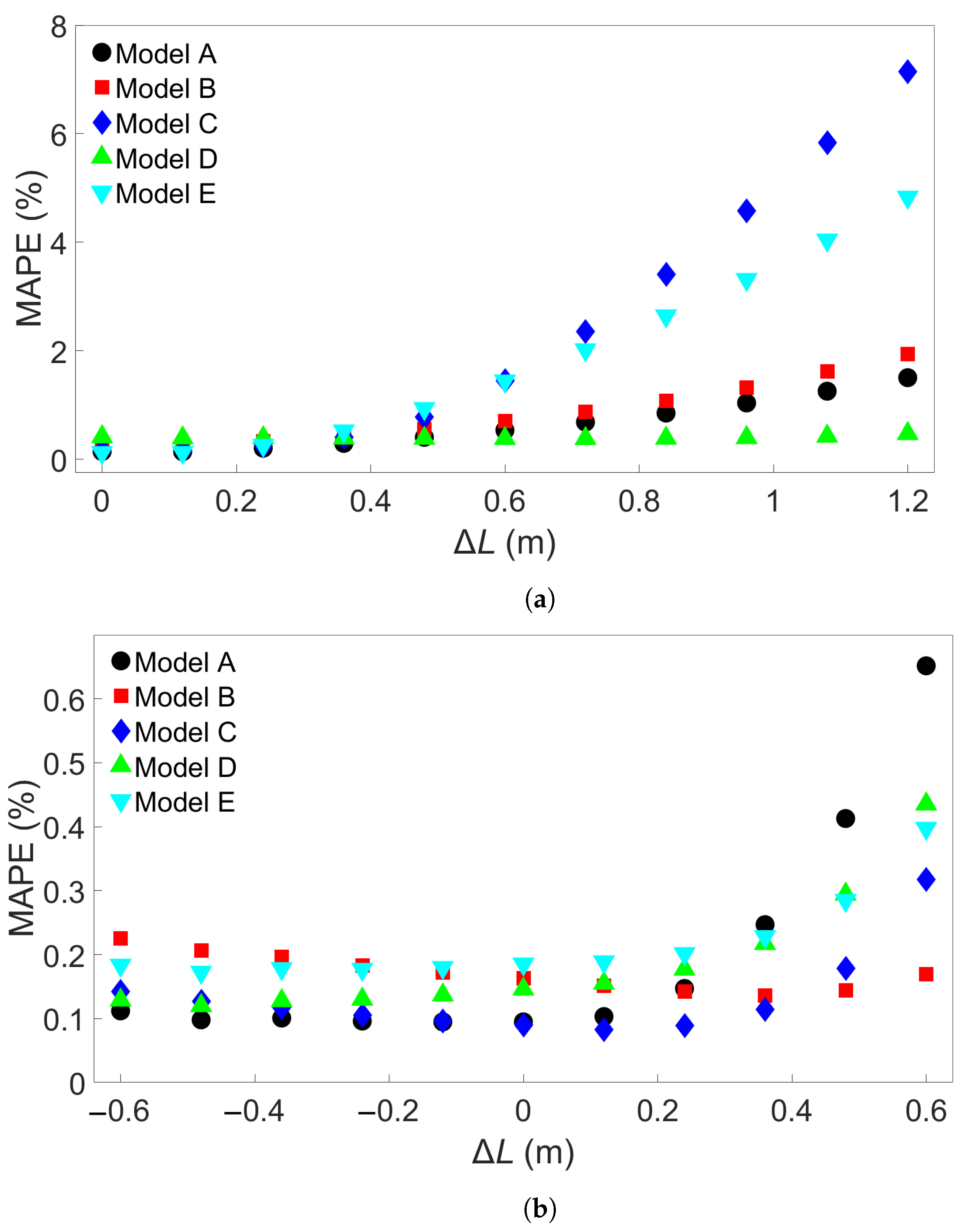
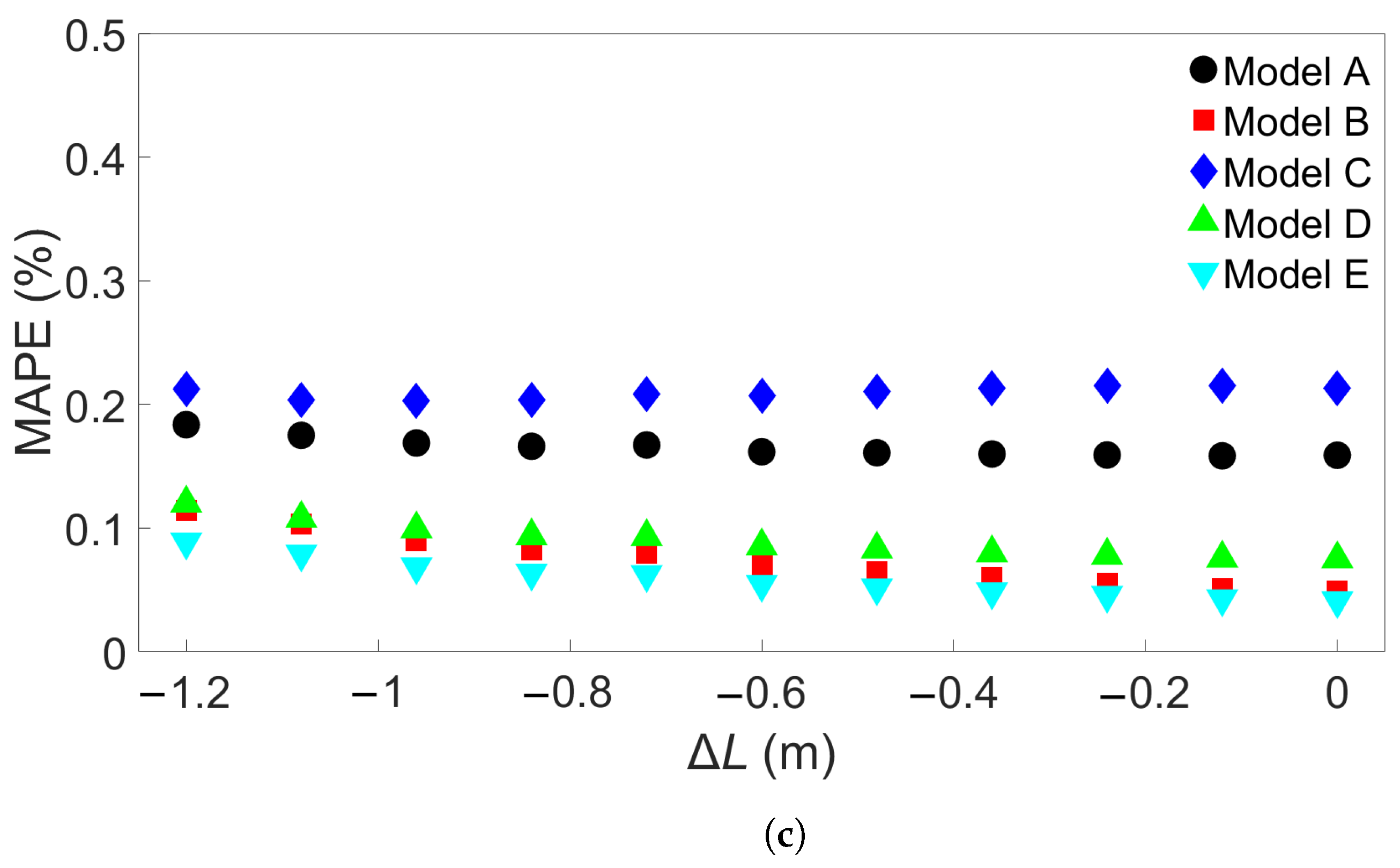
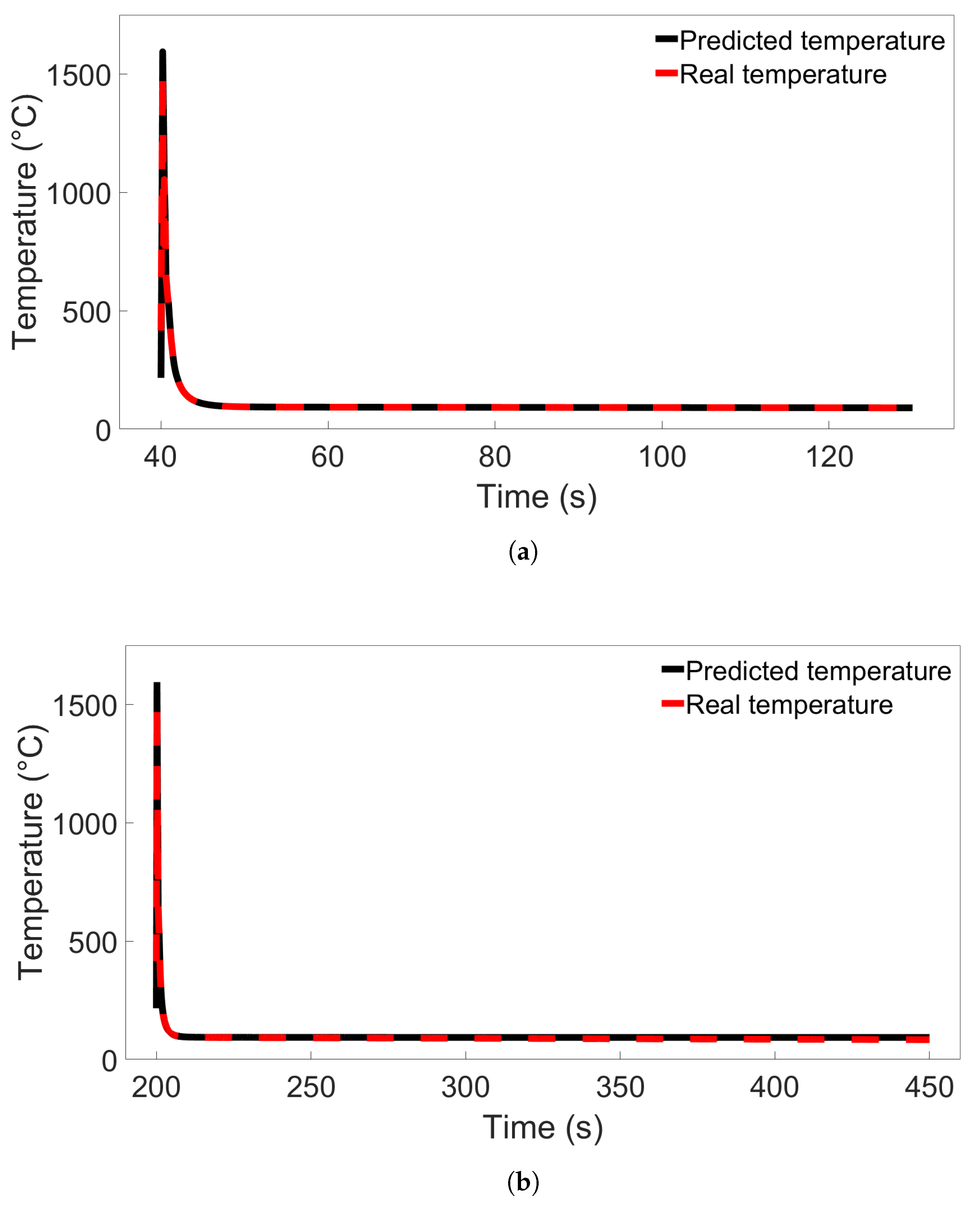
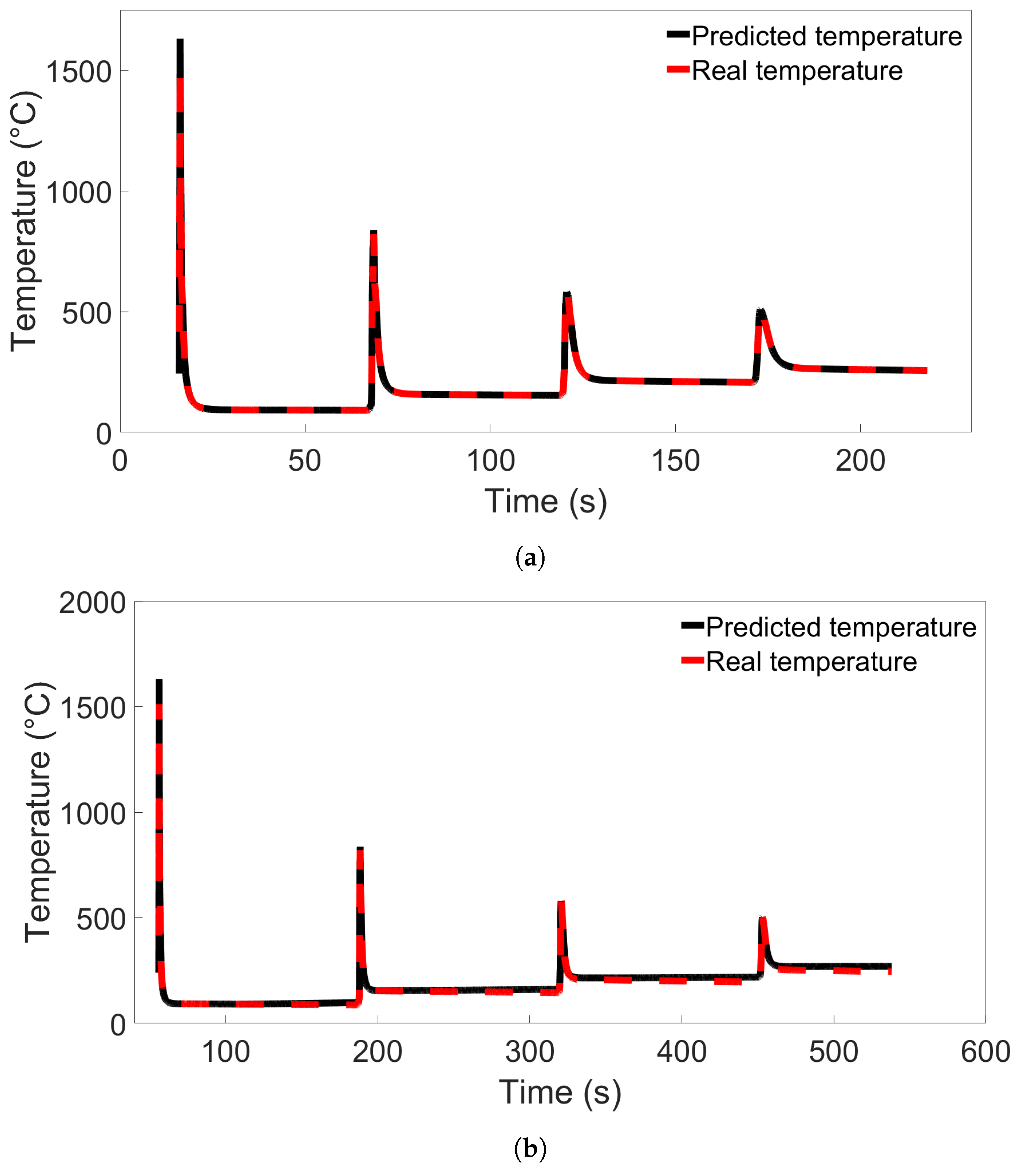
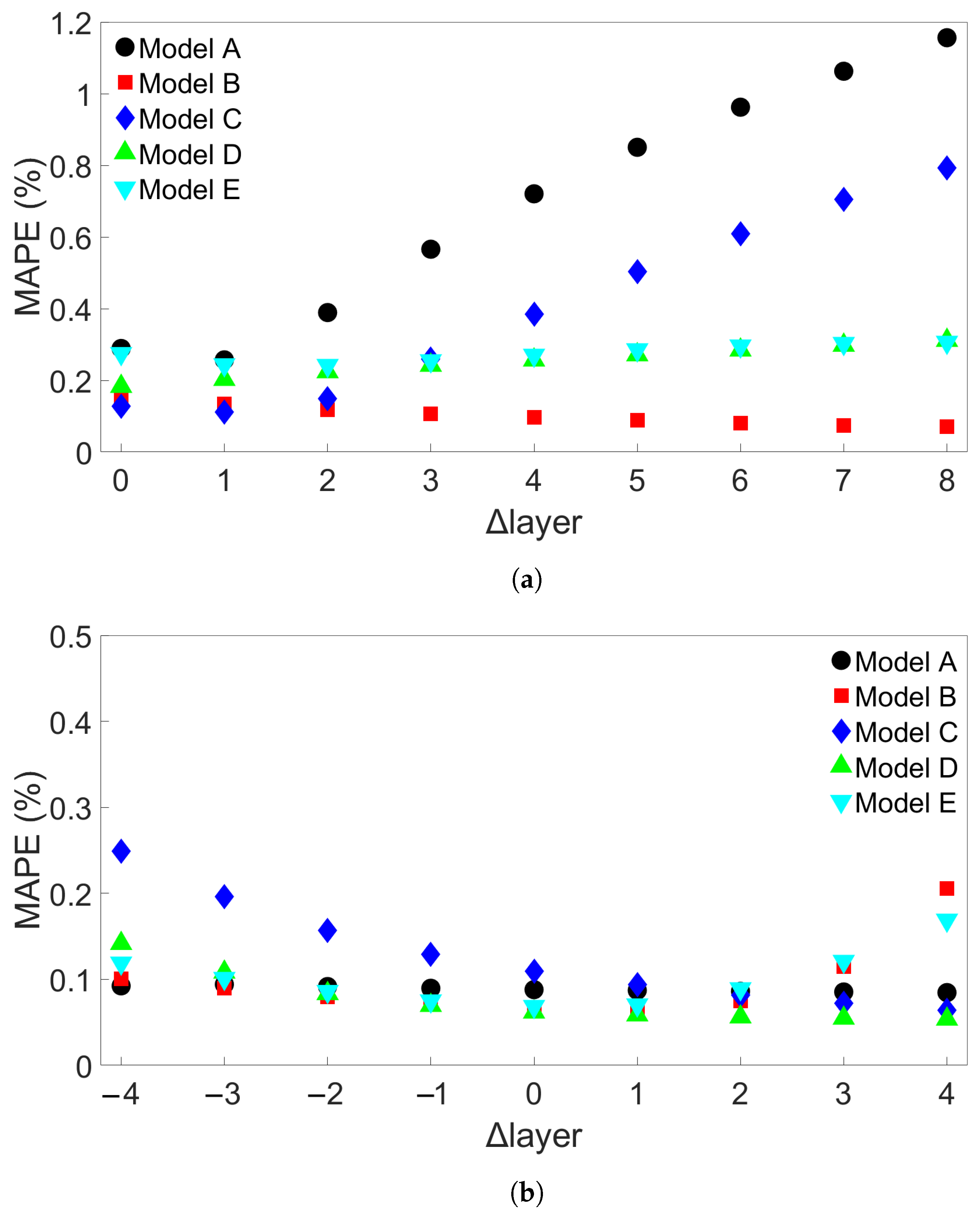
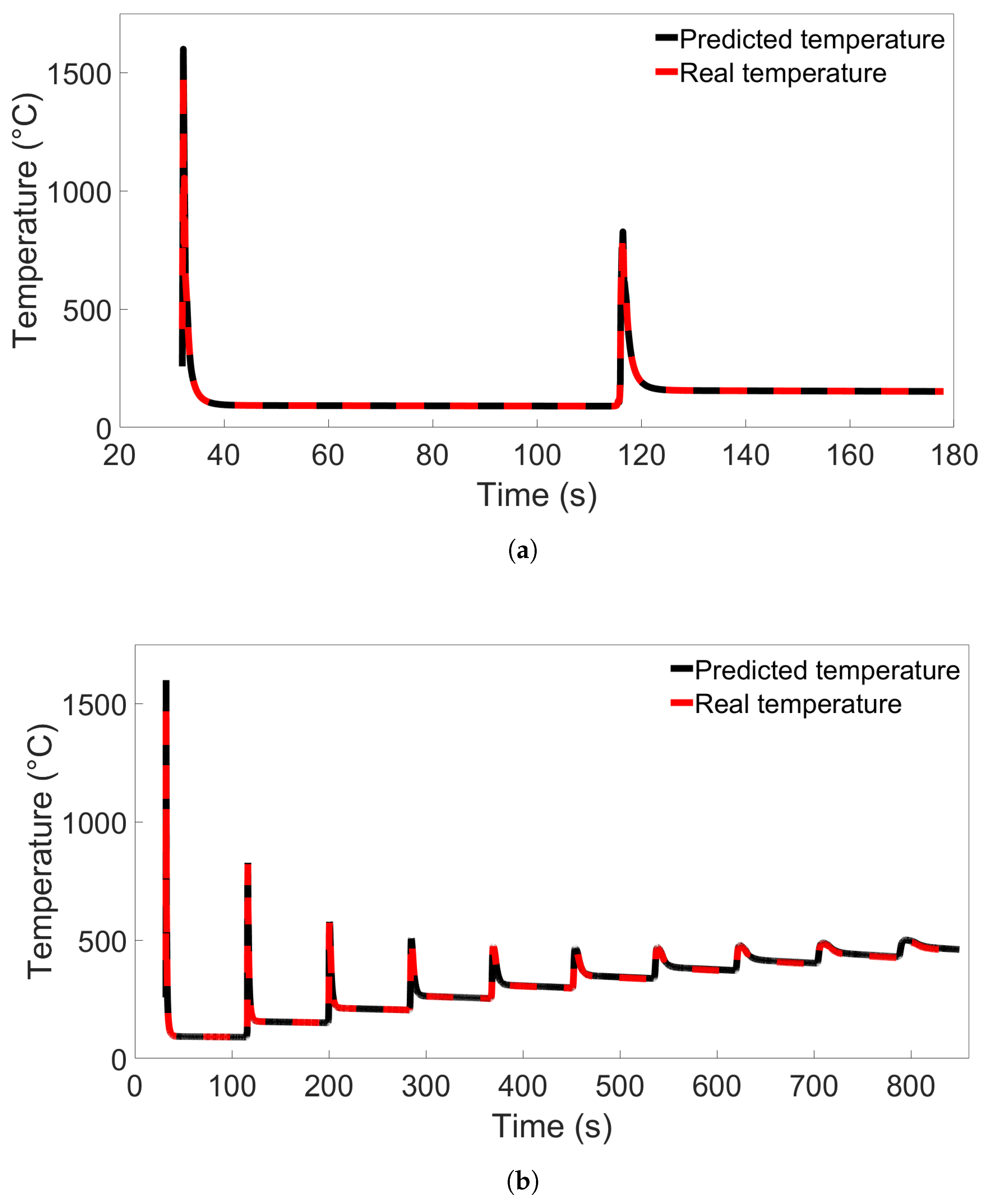
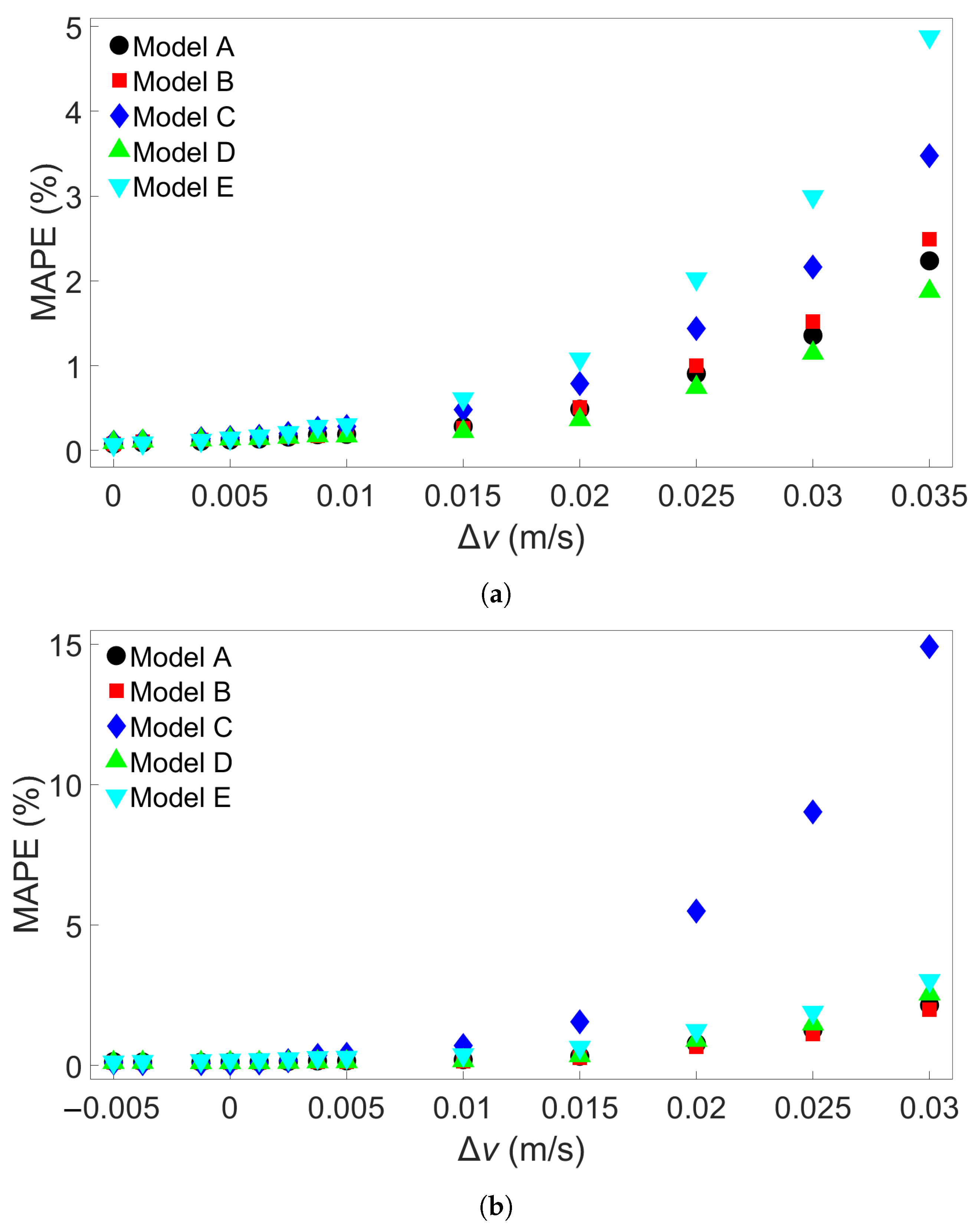
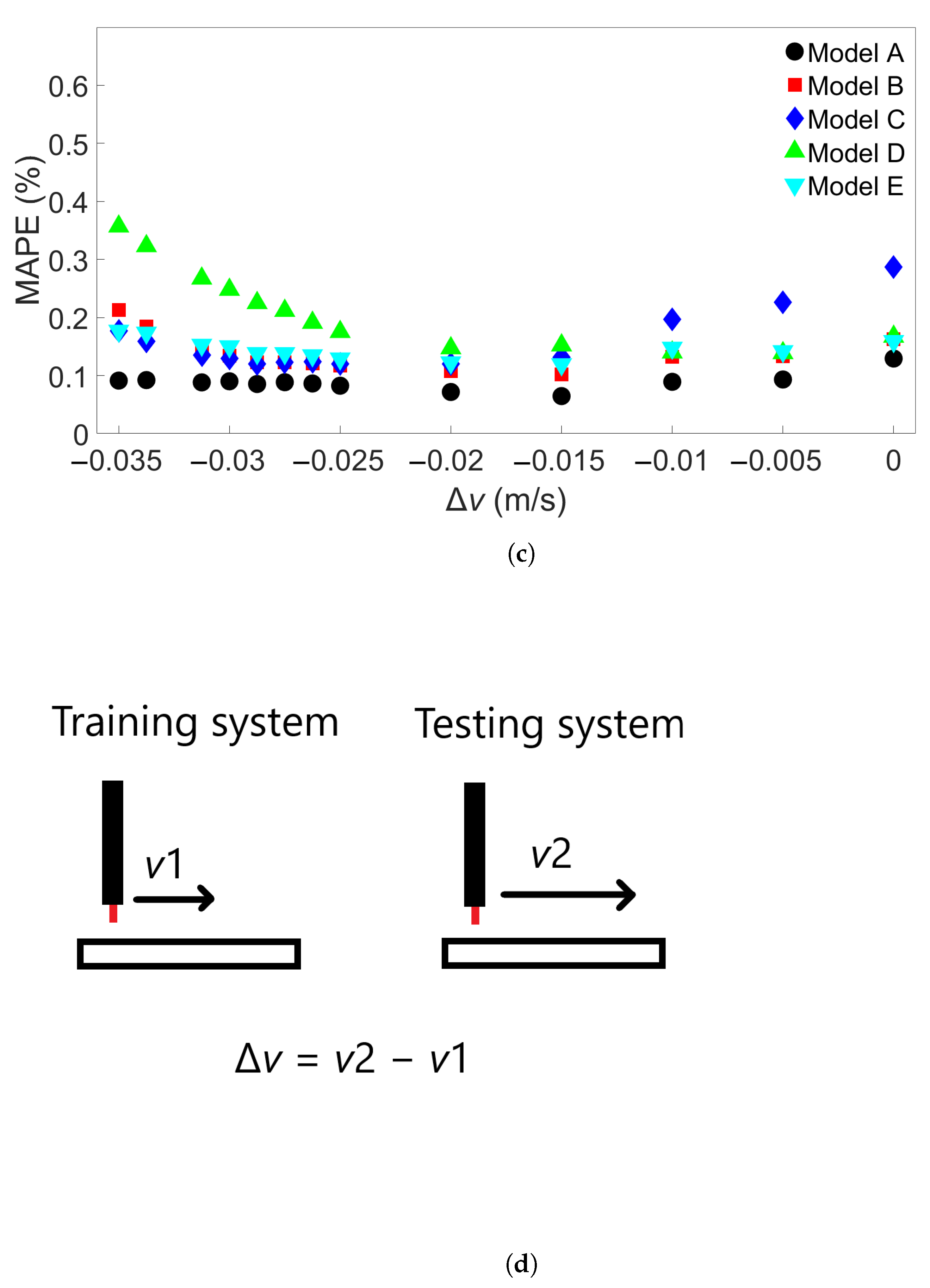
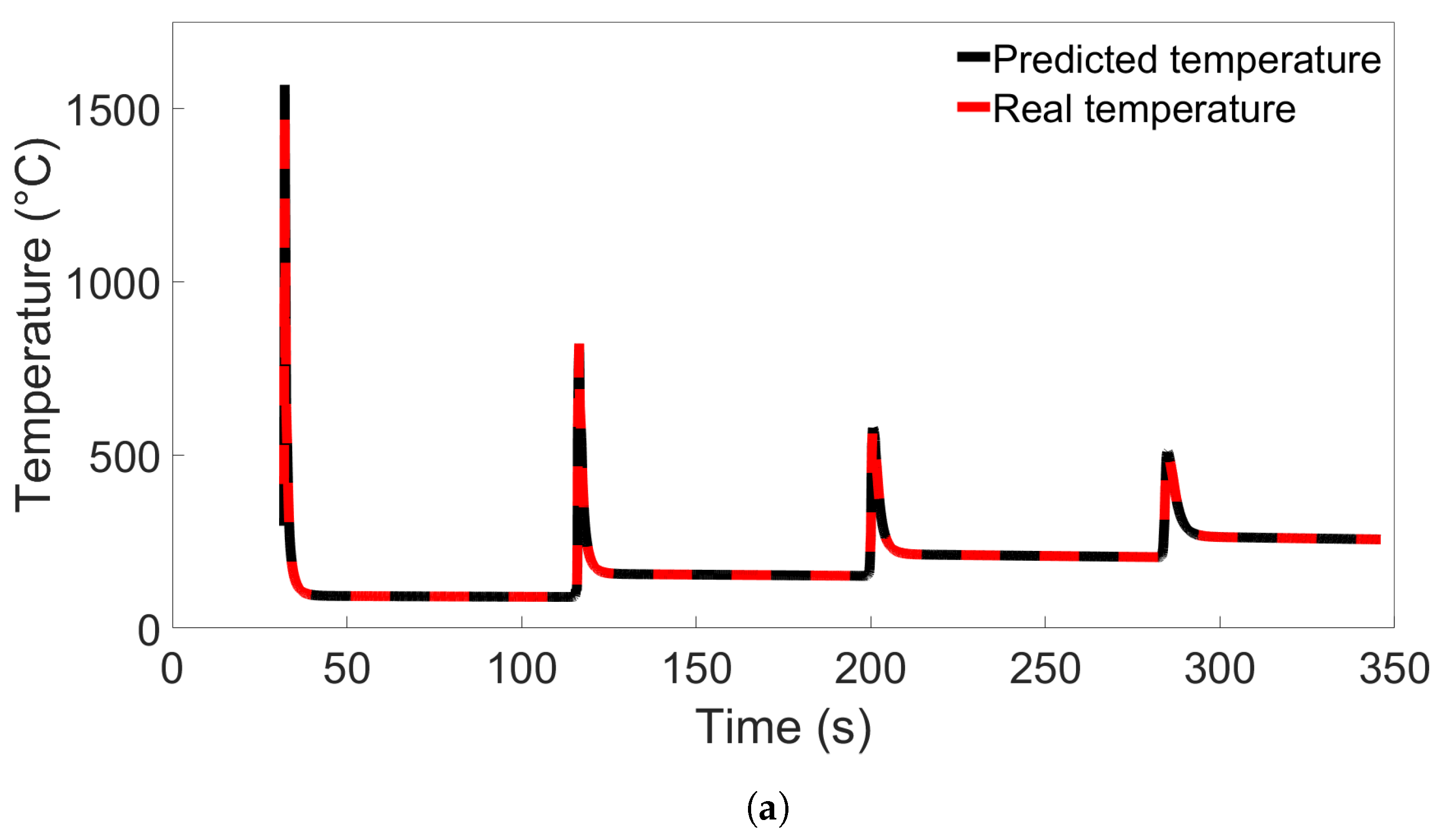
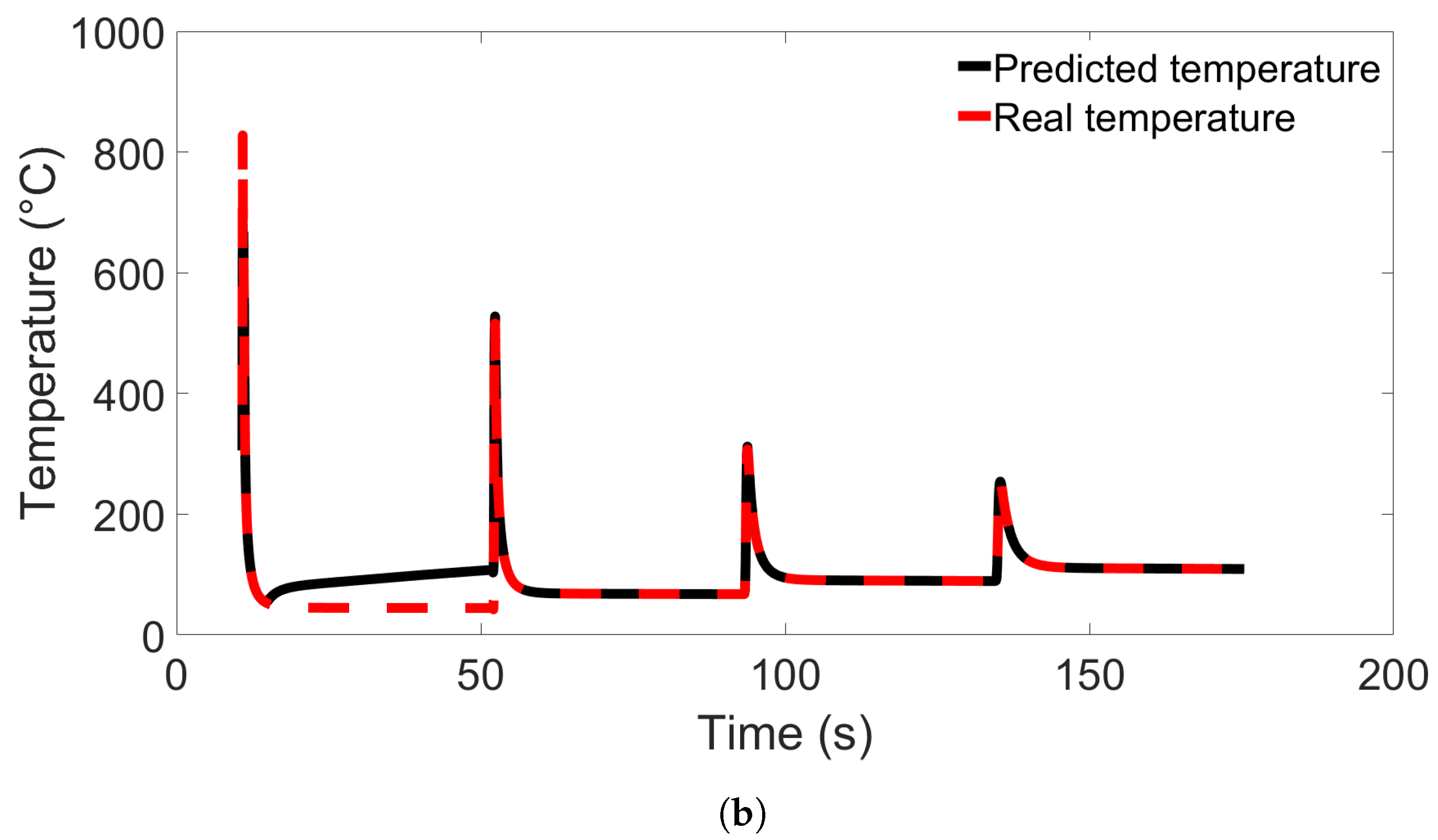
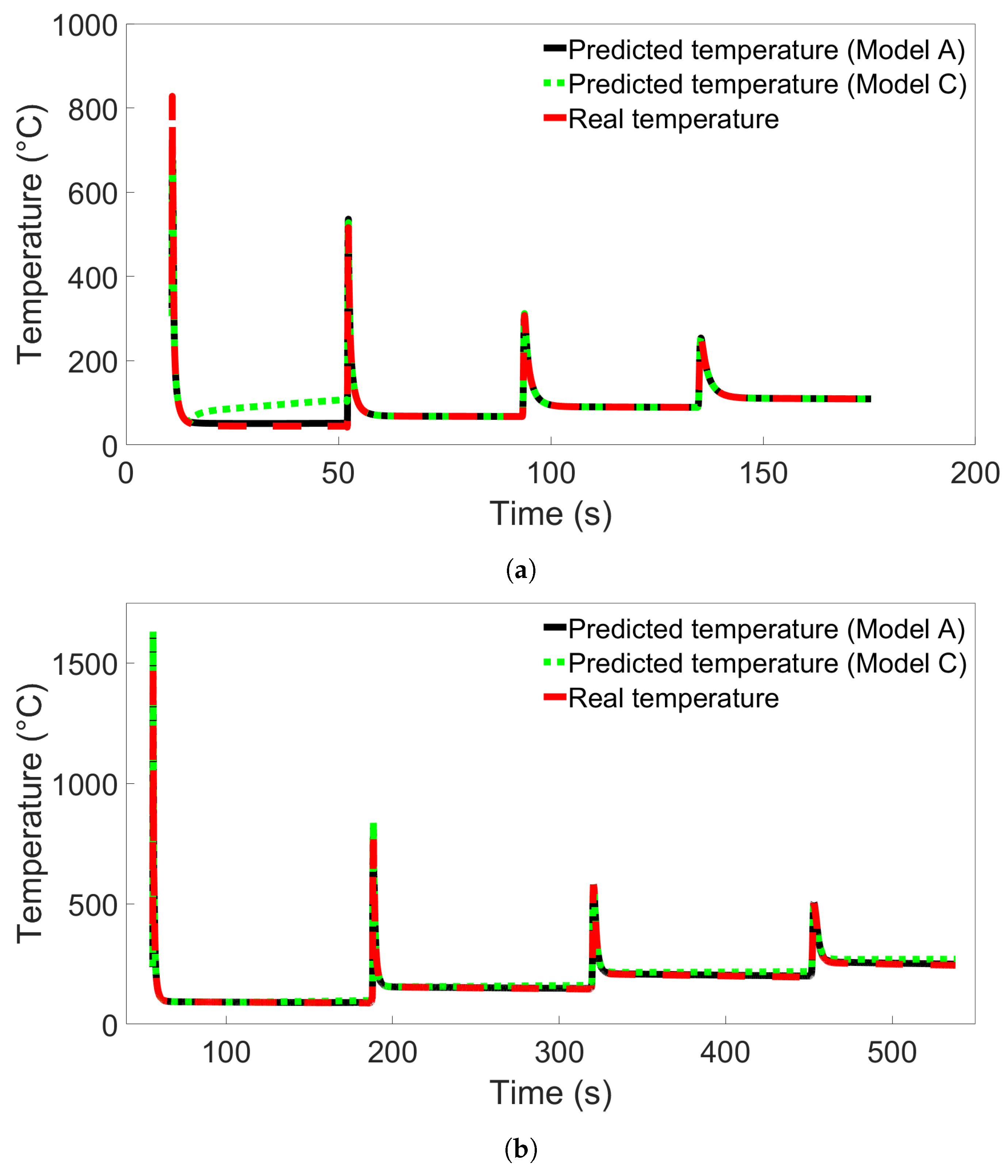
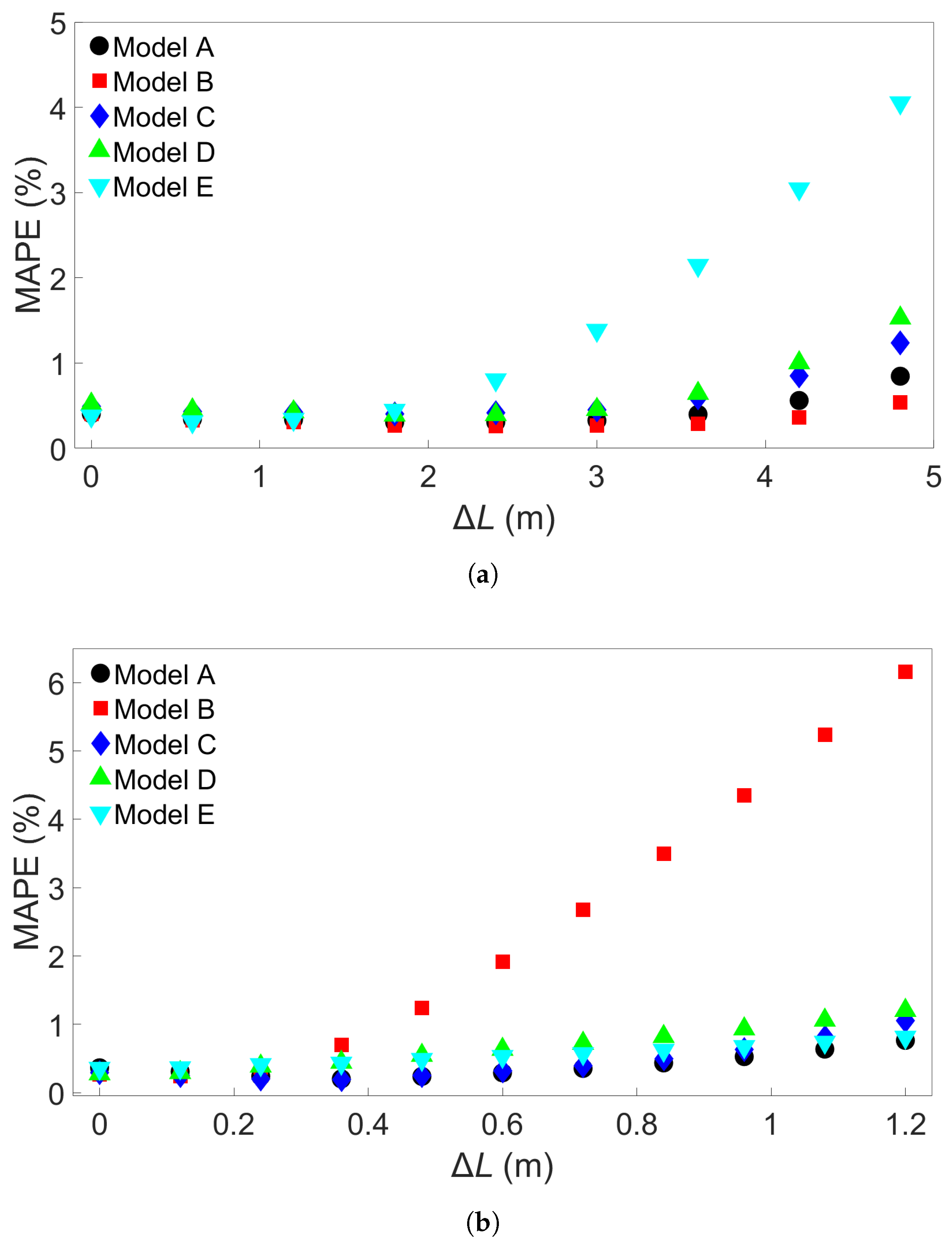
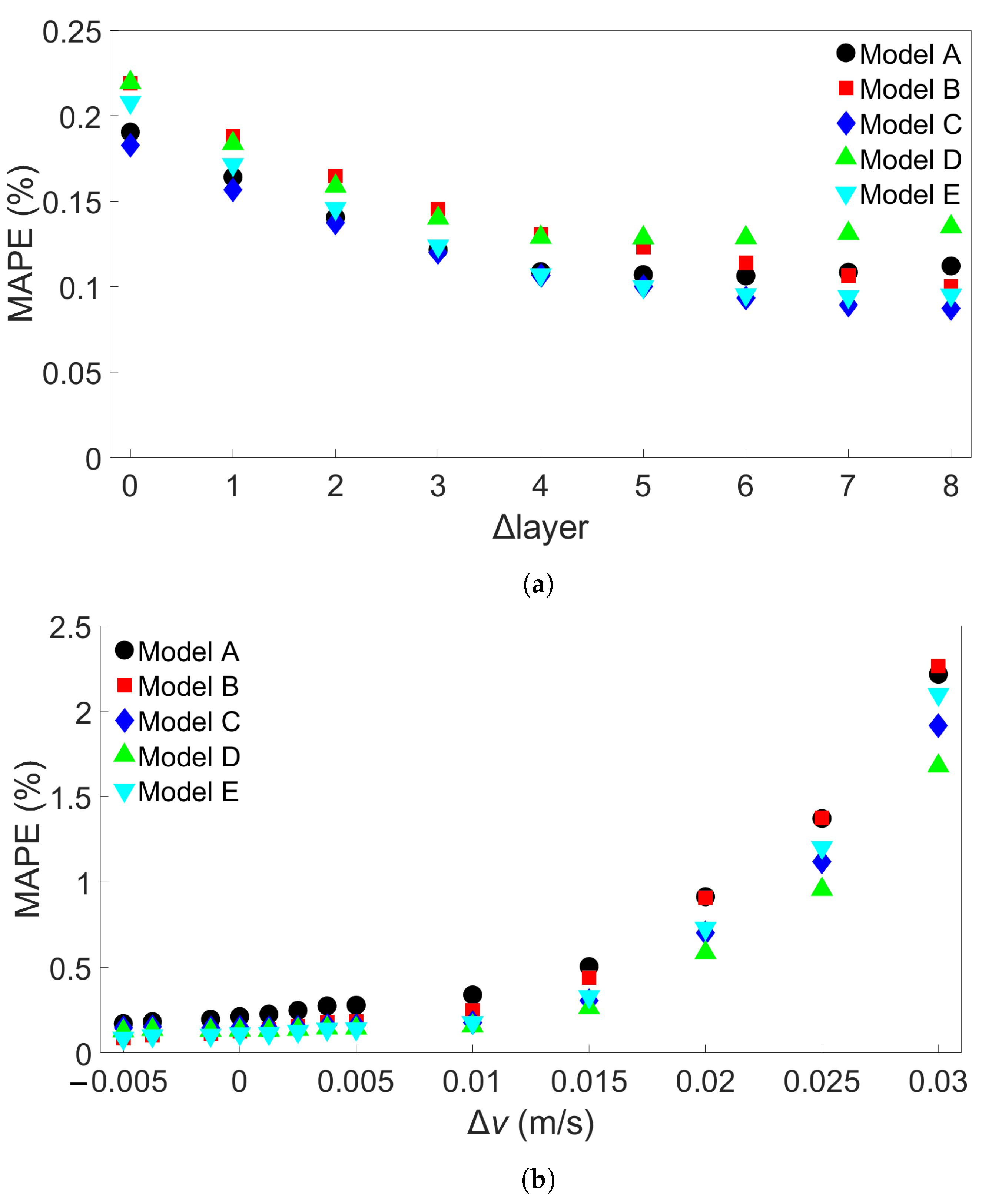
In this study, we performed 40 FE simulations and used the simulation data to train and test multilayer perceptron (MLP) models for predicting temperature evolution. Our goal for this study was to investigate the transferability of thermal history in wire-arc additive manufacturing (WAAM) by using a simple MLP model which takes past temperature history and time as input. Particular attention was paid to situations where high error was found to occur, and additional MLP models were created for further testing when necessary. We have shown that, with proper precautions taken, the simple MLP-based model explored in this study is able to predict temperature evolution in finite element (FE) simulations with different bar lengths, numbers of layers, or scanning speeds. When a trained model is used to test data from FE systems with shorter bar lengths, fewer layers, or slower scanning speeds, the MLP models consistently result in a small error. A slight growth in error is observed as the difference from the simulation used for training increases, but the mean absolute percentage error (MAPE) remains less than 0.5% for one-layer systems of different lengths and four-layer systems with different scanning speeds, and less than 0.3% for four-layer systems of different lengths and systems with different numbers of layers and a bar length of 0.96 m.
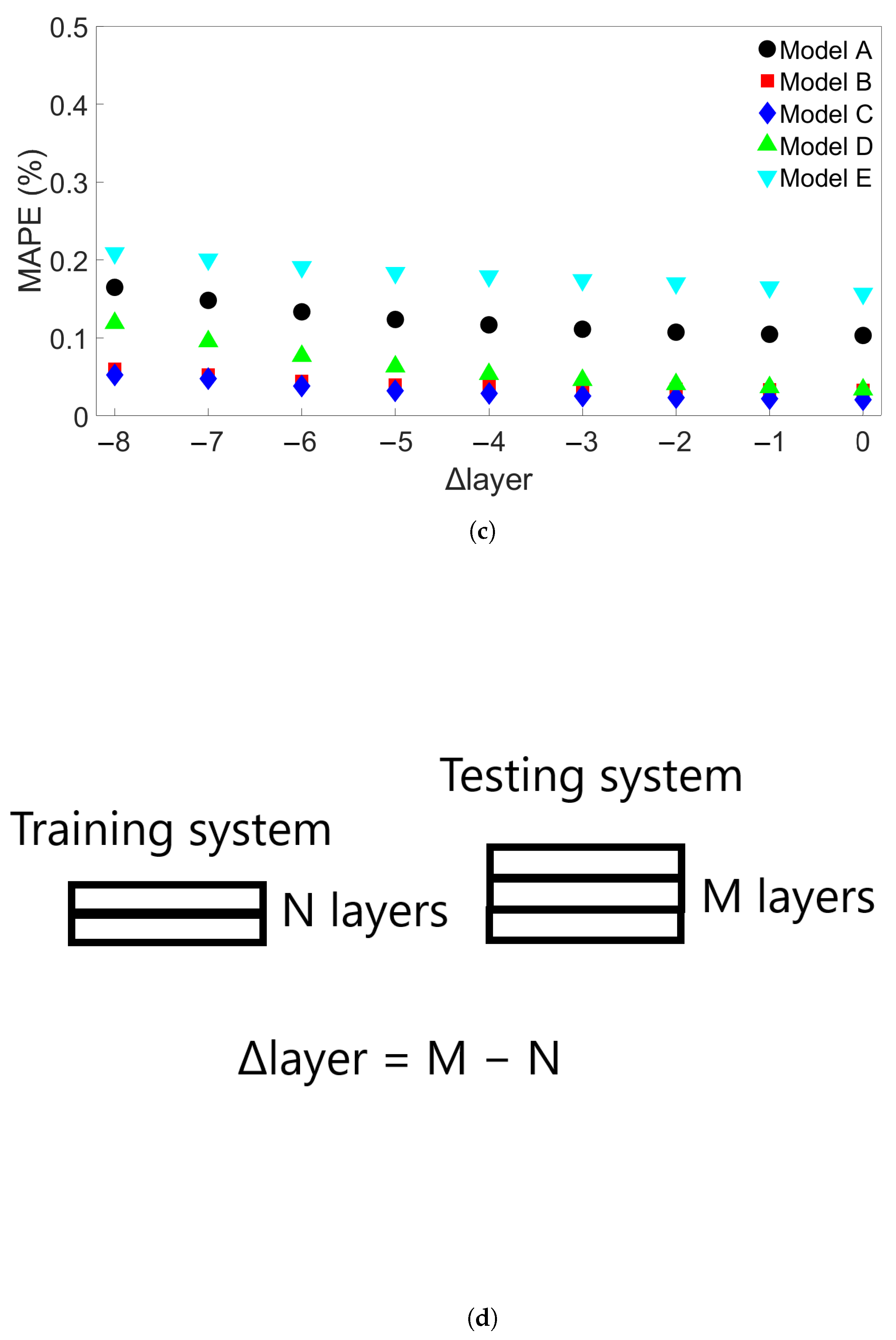
When a trained model is used to test simulations with longer bar lengths, more layers, or faster scanning speeds, low error is still observed when the difference in length, number of layers, or speed is small. As the difference increases, the average MAPE increases as well, as does the variation in model performance due to randomness. In the groups of one-layer and four-layer bars of different lengths and bars with different numbers of layers and a length of 0.96 m, we were still able to identify models which yielded a MAPE of less than 1% in the cases of greatest difference. For four-layer bars with different scanning speeds, testing on data from a system with a faster scanning speed can in a few cases result in unusually high error. The difference in error shows more natural variation in the variable-length and variable-layer cases.
The performance of a given model is observed to be consistent for an increasing difference in length, number of layers, or scanning speed. Models which show a relatively low error growth when tested on an FE system with a certain difference from the training system tend to also give relatively low error when tested on an FE system with a greater difference. Similarly, if the model shows a relatively high error when applied to a system with a certain difference, it tends to give a high error when applied to systems with greater difference. Therefore, it is possible that the performance of a given model can be predicted through preliminary testing before the model is applied.
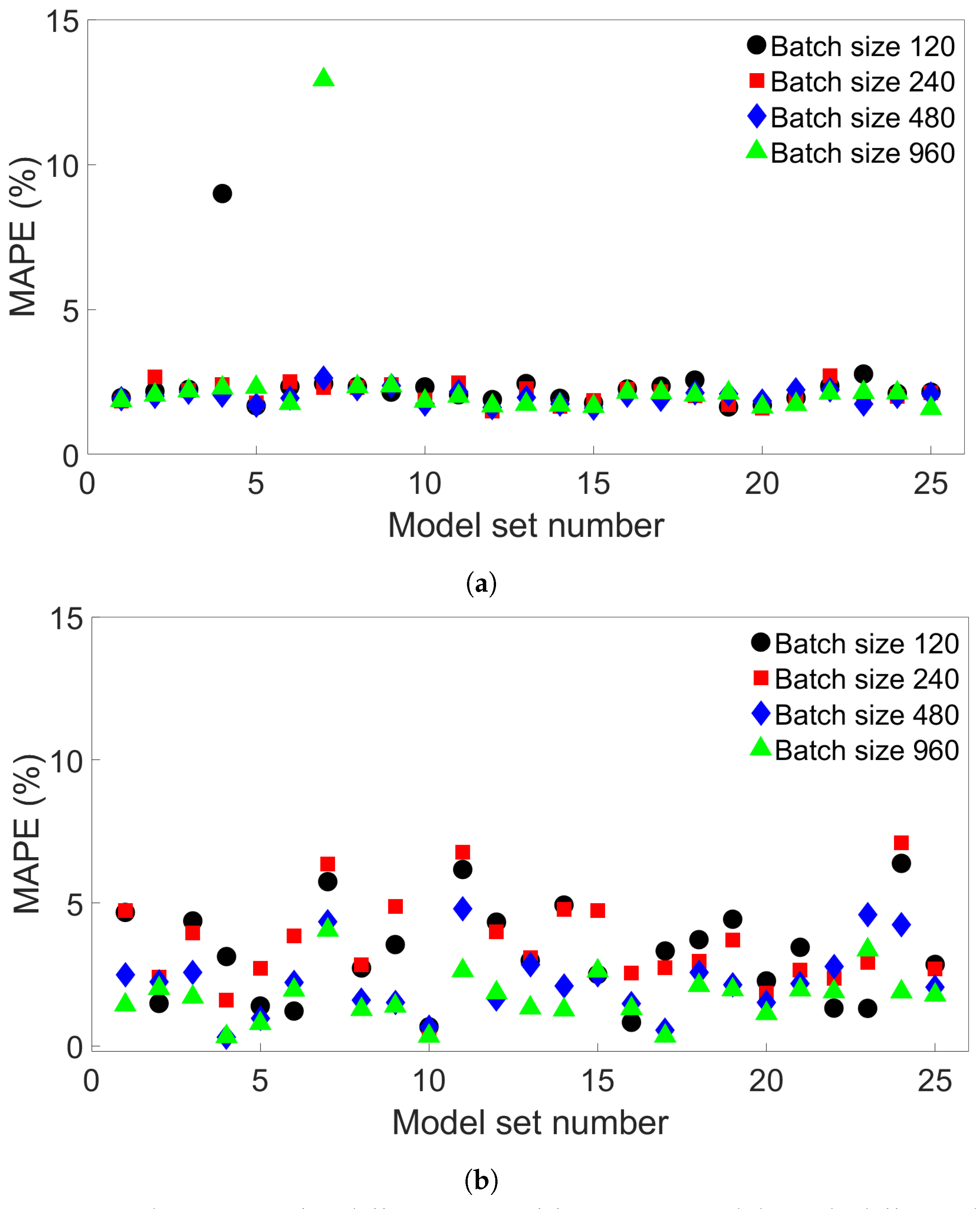
Increasing the batch size from the initial value of 64 to 640 was found to result in overall better results, though increasing the batch size of a particular model does not guarantee it will perform better. Of course, the optimal values for the batch size and number of epochs depends on how many data points are used for training. We found that the particularly high errors obtained with some of the models trained on four-layer systems with different scanning speeds could be found in models with both small and large batch sizes, suggesting that these errors are not caused by overfitting. From single-node considerations, we observe that this increase in error comes from the model performance between the first and second passes of the heat source; this is not the case for the other multilayer systems.
In the future, we plan to continue the systematic study by creating recurrent neural network (RNN)- and physics-informed neural network (PINN)-based models and comparing their performance to the MLP models studied in the current work. We will examine whether the same patterns that were found in this work also appear when different models are used. We will also perform simulations of WAAM deposition of two-dimensional plates and once again compare how different models perform for these cases. Another possible candidate for further study is the effect of varying other process parameters, like laser power.






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}