
Data Augmentation of a Corrosion Dataset for Defect Growth Prediction of Pipelines Using Conditional Tabular Generative Adversarial Networks



Abstract
:1. Introduction
- Outliers’ detection: deleting anomalous data points in the original corrosion dataset.
- Tabular data handling: The corrosion dataset consists of data with a variety of structures and has different distributions for continuous variables and uneven distributions for discrete variables.
- Oversampling: Ensuring that the model can capture the real data distribution and generate new samples following the same distribution. If the real data are randomly sampled during the training process, the rows with the smallest number of categories will not be fully represented, so the GAN may not be trained correctly. If the real data are oversampled, the GAN will learn the oversampled distribution instead of the real data distribution.
- Regression challenges: It is imperative that the relationship between environmental factors and corrosion depth remain unchanged in the generated data.
2. The Buried Pipeline Corrosion Dataset
2.1. Data Cleaning
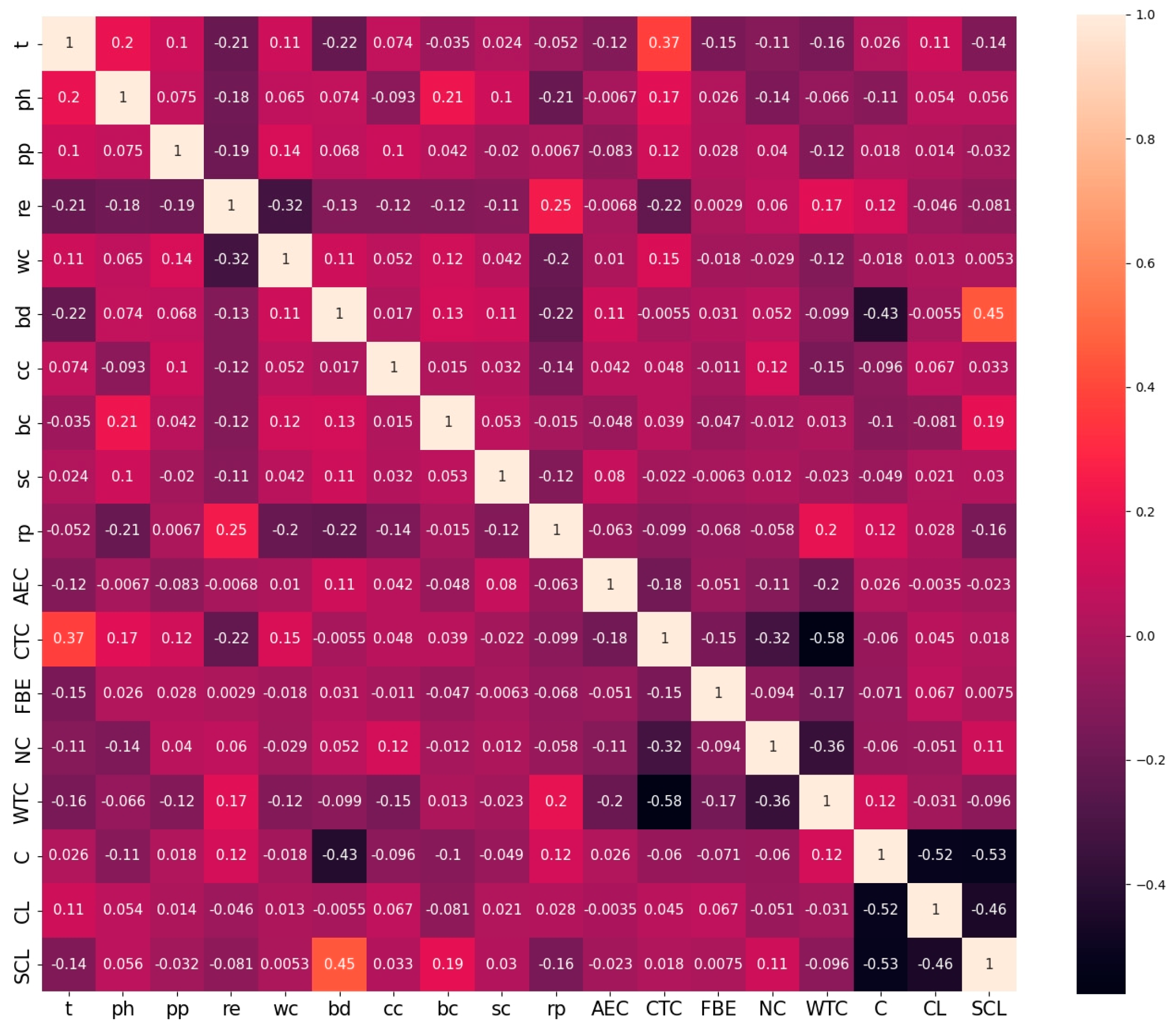
2.2. Relational Analysis
3. Methodology
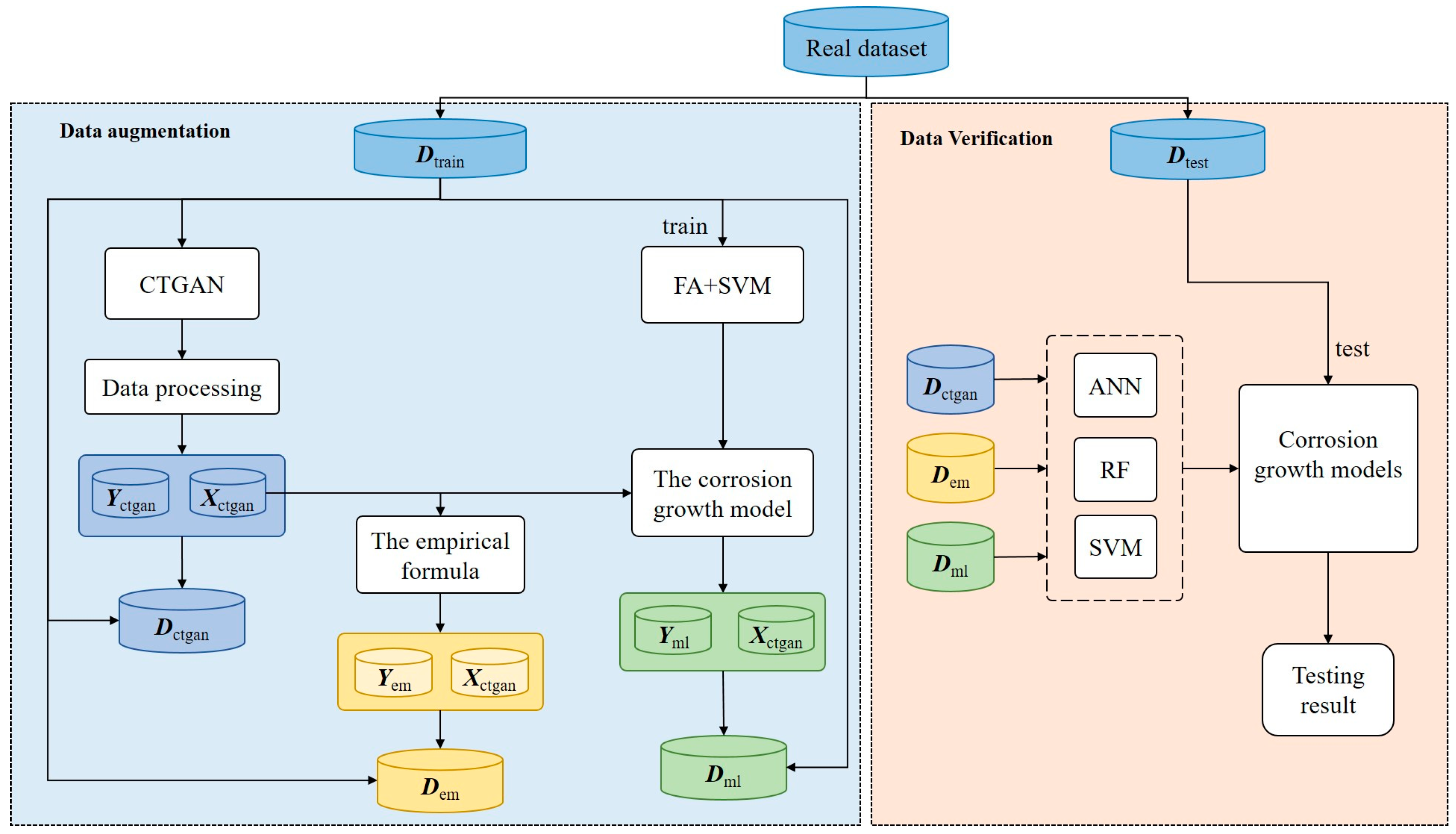
3.1. The Proposed Data Augmentation Strategy
3.2. Deep Generative Models
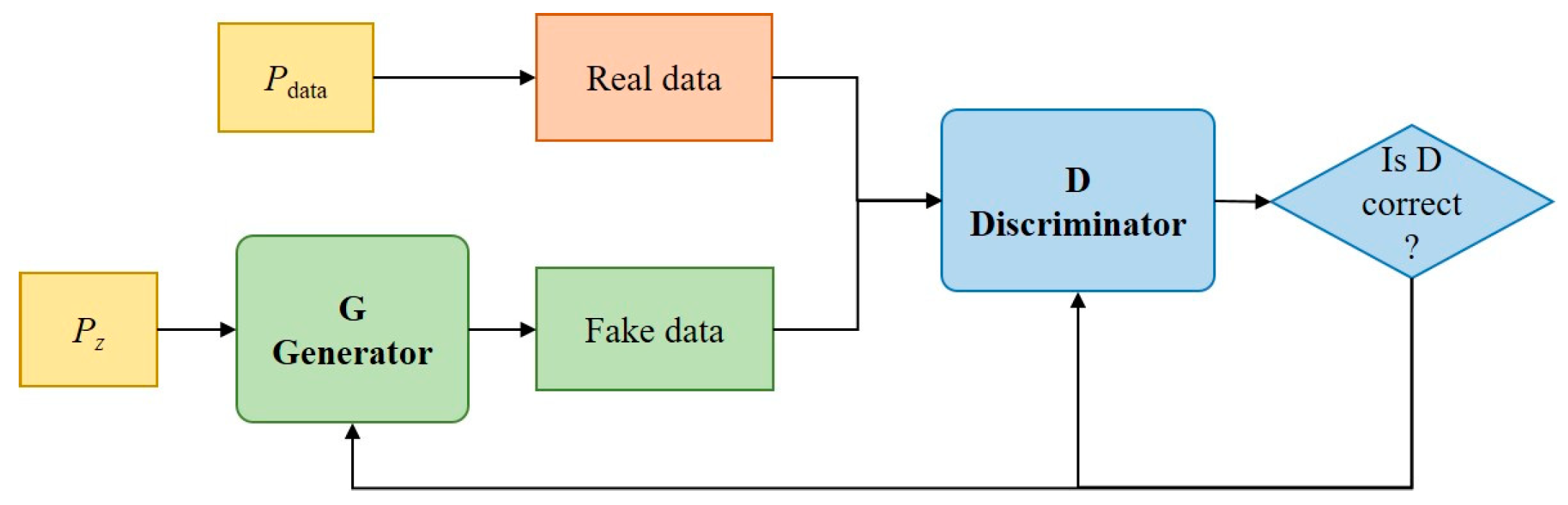
3.2.1. Generative Adversarial Networks
3.2.2. Conditional Tabular Generative Adversarial Networks
3.3. Machine Learning
- (1)
- Artificial neural networks
- (2)
- Random forest
- (3)
- Support vector machine
3.4. Evaluation Indicators
4. Results and Discussions
4.1. The Evaluation of the Synthetic Dataset
4.2. The Credibility of the Synthetic Dataset
4.3. Comparison with Other Data Generation Methods
- (1)
- The generation of corrosion depth through the deep generative model
- (2)
- The generation of corrosion depth through an empirical formula
- (3)
- The generation of corrosion depth through the proposed strategy
5. Conclusions
- (1)
- The proposed strategy can capture the real corrosion data and generate fake data that are the same as the real data. The variables in the synthetic dataset have similar distributions and Spearman correlation coefficients as the real dataset, and the two principal components obtained by the principal component analysis of the two datasets are similar.
- (2)
- The corrosion growth models established by using the synthetic dataset have better predictive performance than the models established by using the real dataset for any coating type. Therefore, the synthetic dataset can be used as a supplement to the real data for corrosion growth prediction.
- (3)
- The superiority of the proposed strategy is demonstrated by comparing it with existing deep generative models and empirical formulation methods. The results of this comparison show that the corrosion growth models established by using the synthetic dataset obtained by the proposed method have better prediction performance than those obtained via other methods.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yazdi, M.; Khan, F.; Abbassi, R. Operational subsea pipeline assessment affected by multiple defects of microbiologically influenced corrosion. Process Saf. Environ. Prot. 2022, 158, 159–171. [Google Scholar] [CrossRef]
- Ben Seghier, M.E.A.; Keshtegar, B.; Taleb-Berrouane, M.; Abbassi, R.; Trung, N.-T. Advanced intelligence frameworks for predicting maximum pitting corrosion depth in oil and gas pipelines. Process Saf. Environ. Prot. 2021, 147, 818–833. [Google Scholar] [CrossRef]
- Arzaghi, E.; Abbassi, R.; Garaniya, V.; Binns, J.; Chin, C.; Khakzad, N.; Reniers, G. Developing a dynamic model for pitting and corrosion-fatigue damage of subsea pipelines. Ocean Eng. 2018, 150, 391–396. [Google Scholar] [CrossRef]
- Khan, F.; Yarveisy, R.; Abbassi, R. Cross-country pipeline inspection data analysis and testing of probabilistic degradation models. J. Pipeline Sci. Eng. 2021, 1, 308–320. [Google Scholar] [CrossRef]
- Foorginezhad, S.; Mohseni-Dargah, M.; Firoozirad, K.; Aryai, V.; Razmjou, A.; Abbassi, R.; Garaniya, V.; Beheshti, A.; Asadnia, M. Recent Advances in Sensing and Assessment of Corrosion in Sewage Pipelines. Process Saf. Environ. Prot. 2021, 147, 192–213. [Google Scholar] [CrossRef]
- Akhlaghi, B.; Mesghali, H.; Ehteshami, M.; Mohammadpour, J.; Salehi, F.; Abbassi, R. Predictive deep learning for pitting corrosion modeling in buried transmission pipelines. Process Saf. Environ. Prot. 2023, 174, 320–327. [Google Scholar] [CrossRef]
- Arzaghi, E.; Chia, B.H.; Abaei, M.M.; Abbassi, R.; Garaniya, V. Pitting corrosion modelling of X80 steel utilized in offshore petroleum pipelines. Process Saf. Environ. Prot. 2020, 141, 135–139. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Y.; Abbassi, R.; Yang, M.; Zhang, R.; Chen, G. Dynamic probability assessment of urban natural gas pipeline accidents considering integrated external activities. J. Loss Prev. Process Ind. 2021, 69, 104388. [Google Scholar] [CrossRef]
- Ma, H.; Zhang, W.; Wang, Y.; Ai, Y.; Zheng, W. Advances in corrosion growth modeling for oil and gas pipelines: A review. Process Saf. Environ. Prot. 2023, 171, 71–86. [Google Scholar] [CrossRef]
- Yang, Y.; Khan, F.; Thodi, P.; Abbassi, R. Corrosion induced failure analysis of subsea pipelines. Reliab. Eng. Syst. Saf. 2017, 159, 214–222. [Google Scholar] [CrossRef]
- Yazdi, M.; Khan, F.; Abbassi, R. A dynamic model for microbiologically influenced corrosion (MIC) integrity risk management of subsea pipelines. Ocean Eng. 2023, 269, 113515. [Google Scholar] [CrossRef]
- Yarveisy, R.; Khan, F.; Abbassi, R. Data-driven predictive corrosion failure model for maintenance planning of process systems. Comput. Chem. Eng. 2022, 157, 107612. [Google Scholar] [CrossRef]
- Velázquez, J.; Caleyo, F.; Valor, A.; Hallen, J. Field study—Pitting corrosion of underground pipelines related to local soil and pipe characteristics. Corrosion 2010, 66, 016001-1–016001-5. [Google Scholar] [CrossRef]
- Xiang, W.; Zhou, W. A Nonparametric Bayesian Network Model for Predicting Corrosion Depth on Buried Pipelines. Corrosion 2020, 76, 235–247. [Google Scholar] [CrossRef]
- Demir, S.; Mincev, K.; Kok, K.; Paterakis, N.G. Data augmentation for time series regression: Applying transformations, autoencoders and adversarial networks to electricity price forecasting. Appl. Energy 2021, 304, 117695. [Google Scholar] [CrossRef]
- Lu, Y.; Tian, Z.; Zhang, Q.; Zhou, R.; Chu, C. Data augmentation strategy for short-term heating load prediction model of residential building. Energy 2021, 235, 121328. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F. Effective data generation for imbalanced learning using conditional generative adversarial networks. Expert Syst. Appl. 2018, 91, 464–471. [Google Scholar] [CrossRef]
- Tang, J.; Fan, B.; Xiao, L.; Tian, S.; Zhang, F.; Zhang, L.; Weitz, D. A new ensemble machine-learning framework for searching sweet spots in shale reservoirs. SPE J. 2021, 26, 482–497. [Google Scholar] [CrossRef]
- He, Z.; Zhou, W. Generation of synthetic full-scale burst test data for corroded pipelines using the tabular generative adversarial network. Eng. Appl. Artif. Intell. 2022, 115, 105308. [Google Scholar] [CrossRef]
- Woldesellasse, H.; Tesfamariam, S. Data augmentation using conditional generative adversarial network (cGAN): Application for prediction of corrosion pit depth and testing using neural network. J. Pipeline Sci. Eng. 2023, 3, 100091. [Google Scholar] [CrossRef]
- Habibi, O.; Chemmakha, M.; Lazaar, M. Imbalanced tabular data modelization using CTGAN and machine learning to improve IoT Botnet attacks detection. Eng. Appl. Artif. Intell. 2023, 118, 105669. [Google Scholar] [CrossRef]
- Moon, J.; Jung, S.; Park, S.; Hwang, E. Conditional Tabular GAN-Based Two-Stage Data Generation Scheme for Short-Term Load Forecasting. IEEE Access 2020, 8, 205327–205339. [Google Scholar] [CrossRef]
- Valor, A.; Caleyo, F.; Hallen, J.M.; Velázquez, J.C. Reliability assessment of buried pipelines based on different corrosion rate models. Corros. Sci. 2013, 66, 78–87. [Google Scholar] [CrossRef]
- Singh, K.; Upadhyaya, S. Outlier detection: Applications and techniques. Int. J. Comput. Sci. Issues (IJCSI) 2012, 9, 307. [Google Scholar]
- Vinutha, H.; Poornima, B.; Sagar, B. Detection of Outliers Using Interquartile Range Technique from Intrusion Dataset. In Information and Decision Sciences: Proceedings of the 6th International Conference on FICTA, Bhubaneswar, Odisha, India, 1 April 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 511–518. [Google Scholar]
- Khan, K.; Rehman, S.U.; Aziz, K.; Fong, S.; Sarasvady, S. DBSCAN: Past, Present and Future. In Proceedings of the Fifth International Conference on the Applications of Digital Information and Web Technologies (ICADIWT 2014), Chennai, India, 17–19 February 2014; IEEE: Washington, DC, USA, 2014; pp. 232–238. [Google Scholar]
- Hao, L.; Naiman, D.Q. Quantile Regression; Sage: Thousand Oaks, CA, USA, 2007. [Google Scholar]
- Myers, L.; Sirois, M.J. Spearman correlation coefficients, differences between. Encycl. Stat. Sci. 2004, 12. [Google Scholar] [CrossRef]
- Aldosari, H.; Rajasekaran, S.; Ammar, R. Generative Adversarial Neural Network and Genetic Algorithms to Predict Oil and Gas Pipeline Defect Lengths. In Proceedings of the ISCA 34th International Conference, Online, 2 November 2021; pp. 21–29. [Google Scholar]
- El Amine Ben Seghier, M.; Keshtegar, B.; Tee, K.F.; Zayed, T.; Abbassi, R.; Trung, N.T. Prediction of maximum pitting corrosion depth in oil and gas pipelines. Eng. Fail. Anal. 2020, 112, 104505. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Tian, C.; Li, C.; Zhang, G.; Lv, Y. Data driven parallel prediction of building energy consumption using generative adversarial nets. Energy Build. 2019, 186, 230–243. [Google Scholar] [CrossRef]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling tabular data using conditional gan. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Kumari, P.; Halim, S.Z.; Kwon, J.S.-I.; Quddus, N. An integrated risk prediction model for corrosion-induced pipeline incidents using artificial neural network and Bayesian analysis. Process Saf. Environ. Prot. 2022, 167, 34–44. [Google Scholar] [CrossRef]
- Marani, A.; Zhang, L.; Nehdi, M.L. Design of concrete incorporating microencapsulated phase change materials for clean energy: A ternary machine learning approach based on generative adversarial networks. Eng. Appl. Artif. Intell. 2023, 118, 105652. [Google Scholar] [CrossRef]
- Lopes, R.H.; Reid, I.; Hobson, P.R. The Two-Dimensional Kolmogorov-Smirnov Test. In Proceedings of the XI International Workshop on Advanced Computing and Analysis Techniques in Physics Research, Amsterdam, The Netherlands, 23–27 April 2007; Proceedings of Science: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Ma, H.; Wang, H.; Geng, M.; Ai, Y.; Zhang, W.; Zheng, W. A new hybrid approach model for predicting burst pressure of corroded pipelines of gas and oil. Eng. Fail. Anal. 2023, 149, 107248. [Google Scholar] [CrossRef]
- Caleyo, F.; Velázquez, J.C.; Valor, A.; Hallen, J.M. Probability distribution of pitting corrosion depth and rate in underground pipelines: A Monte Carlo study. Corros. Sci. 2009, 51, 1925–1934. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Para. | Unit | Mean | Min | Max | Std. |
|---|---|---|---|---|---|
| dmax | [mm] | 1.925 | 0.41 | 10.41 | 1.842 |
| t | [years] | 22.77 | 5 | 50 | 9.02 |
| pH | 6.124 | 4.14 | 9.88 | 0.921 | |
| wc | [%] | 23.73 | 8.8 | 57.6 | 6.16 |
| re | ] | 49.35 | 1.9 | 399.5 | 53.99 |
| cc | [ppm] | 41.28 | 3.2 | 351.0 | 55.66 |
| sc | [ppm] | 152.38 | 1.0 | 1370.2 | 158.87 |
| bc | [ppm] | 18.43 | 1.0 | 156.2 | 20.82 |
| bd | [g/mL] | 1.304 | 1.11 | 1.55 | 0.086 |
| pp | [mV] | −0.879 | −1.97 | −0.42 | 0.234 |
| rp | [mV] | 170.20 | 2.1 | 348.0 | 86.17 |
| ct | 48.2 | 6 | 101 | ||
| class | 80.3 | 59 | 107 |
| Para. | Mean | Min | Max | Std. |
|---|---|---|---|---|
| dmax | 1.448 | 0.407 | 7.59 | 0.784 |
| t | 21.46 | 2 | 51 | 7.83 |
| pH | 6.044 | 4.03 | 8.18 | 0.850 |
| wc | 21.95 | 8.43 | 39.3 | 5.42 |
| re | 51.81 | 2.65 | 208.7 | 41.66 |
| cc | 27.72 | 0.34 | 164.1 | 28.09 |
| sc | 138.24 | 1.48 | 457.7 | 91.38 |
| bc | 18.43 | 0.29 | 117.2 | 8.96 |
| bd | 1.306 | 1.04 | 1.51 | 0.093 |
| pp | −0.892 | −2.65 | −0.47 | 0.225 |
| rp | 181.16 | 0.07 | 423.6 | 85.24 |
| ct | 115 | 24 | 226 | |
| class | 191 | 178 | 215 |
| ct | MAE | RMSE | MAPE | R2 | ||
|---|---|---|---|---|---|---|
| WTC | Model_Ori | ANN | 0.5169 | 0.7934 | 0.4000 | −0.3026 |
| RF | 0.5842 | 0.8080 | 0.5970 | −0.3511 | ||
| SVM | 0.3906 | 0.6119 | 0.3271 | 0.2251 | ||
| Model_Syn | ANN | 0.3997 | 0.6519 | 0.3299 | 0.1206 | |
| RF | 0.3974 | 0.5603 | 0.4081 | 0.3504 | ||
| SVM | 0.3853 | 0.5957 | 0.3271 | 0.2658 | ||
| NC | Model_Ori | ANN | 0.3663 | 0.4587 | 0.1518 | 0.8069 |
| RF | 0.7487 | 0.8960 | 0.4516 | 0.2631 | ||
| SVM | 0.6308 | 0.7768 | 0.2908 | 0.4462 | ||
| Model_Syn | ANN | 0.5602 | 0.6971 | 0.2336 | 0.5539 | |
| RF | 0.5408 | 0.6302 | 0.2367 | 0.6354 | ||
| SVM | 0.6269 | 0.7707 | 0.2889 | 0.4547 | ||
| CTC | Model_Ori | ANN | 0.8785 | 1.0958 | 0.4995 | 0.2603 |
| RF | 0.8463 | 1.0372 | 0.5398 | 0.3373 | ||
| SVM | 0.6057 | 0.7530 | 0.3222 | 0.6508 | ||
| Model_Syn | ANN | 0.5238 | 0.6342 | 0.3504 | 0.7522 | |
| RF | 0.6062 | 0.7881 | 0.3179 | 0.6174 | ||
| SVM | 0.6098 | 0.7631 | 0.3156 | 0.6413 | ||
| FBE | Model_Ori | ANN | 0.4879 | 0.4885 | 0.4291 | −1.1911 |
| RF | 0.2419 | 0.2820 | 0.1765 | 0.2696 | ||
| SVM | 0.1170 | 0.1368 | 0.0852 | 0.8282 | ||
| Model_Syn | ANN | 0.2148 | 0.2367 | 0.2094 | 0.4854 | |
| RF | 0.2884 | 0.3447 | 0.2067 | −0.0912 | ||
| SVM | 0.1001 | 0.1207 | 0.0713 | 0.8663 | ||
| AEC | Model_Ori | ANN | 0.0087 | 0.0087 | 0.0045 | |
| RF | 1.3584 | 1.3584 | 0.7112 | |||
| SVM | 0.0390 | 0.0390 | 0.0204 | |||
| Model_Syn | ANN | 0.0467 | 0.0467 | 0.0245 | ||
| RF | 0.1240 | 0.1240 | 0.0649 | |||
| SVM | 0.0497 | 0.0497 | 0.0260 | |||
| ALL | Model_Ori | ANN | 0.6079 | 0.8605 | 0.3944 | 0.3615 |
| RF | 0.6950 | 0.9025 | 0.5464 | 0.2976 | ||
| SVM | 0.4793 | 0.6716 | 0.3073 | 0.6111 | ||
| Model_Syn | ANN | 0.4504 | 0.6373 | 0.3147 | 0.6498 | |
| RF | 0.4779 | 0.6449 | 0.3427 | 0.6414 | ||
| SVM | 0.4772 | 0.6673 | 0.3046 | 0.6160 |
| Para. (Variable) | Soil Category | ||
|---|---|---|---|
| C | CL | SCL | |
| t0 | 3.05 | 3.06 | 2.57 |
| k0 | |||
| k1 (rp) | |||
| k2 (pH) | |||
| k3 (re) | |||
| k4 (cc) | |||
| k5 (bc) | |||
| k6 (sc) | |||
| a0 | |||
| a1 (pp) | |||
| a2 (wc) | |||
| a3 (bd) | |||
| a4 (ct) | |||
| MAE | RMSE | MAPE | R2 | ||
|---|---|---|---|---|---|
| Dctgan | ANN | 0.5884 | 0.8385 | 0.4203 | 0.3938 |
| RF | 0.4753 | 0.6743 | 0.3429 | 0.6079 | |
| SVM | 0.5420 | 0.7299 | 0.3445 | 0.5405 | |
| Dem | ANN | 0.6182 | 0.8372 | 0.4219 | 0.3957 |
| RF | 0.4763 | 0.6395 | 0.3609 | 0.6474 | |
| SVM | 0.5138 | 0.6801 | 0.3535 | 0.6011 | |
| Dml | ANN | 0.4970 | 0.6801 | 0.3649 | 0.6011 |
| RF | 0.4567 | 0.5937 | 0.3446 | 0.6668 | |
| SVM | 0.4756 | 0.6603 | 0.3129 | 0.6240 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, H.; Geng, M.; Wang, F.; Zheng, W.; Ai, Y.; Zhang, W. Data Augmentation of a Corrosion Dataset for Defect Growth Prediction of Pipelines Using Conditional Tabular Generative Adversarial Networks. Materials 2024, 17, 1142. https://doi.org/10.3390/ma17051142
Ma H, Geng M, Wang F, Zheng W, Ai Y, Zhang W. Data Augmentation of a Corrosion Dataset for Defect Growth Prediction of Pipelines Using Conditional Tabular Generative Adversarial Networks. Materials. 2024; 17(5):1142. https://doi.org/10.3390/ma17051142
Chicago/Turabian StyleMa, Haonan, Mengying Geng, Fan Wang, Wenyue Zheng, Yibo Ai, and Weidong Zhang. 2024. "Data Augmentation of a Corrosion Dataset for Defect Growth Prediction of Pipelines Using Conditional Tabular Generative Adversarial Networks" Materials 17, no. 5: 1142. https://doi.org/10.3390/ma17051142