
Evaluation of High-Frequency Measurement Errors from Turned Surface Topography Data Using Machine Learning Methods




Abstract
1. Introduction
2. Materials and Methods
2.1. Analysed Surfaces
2.2. Measurement Process
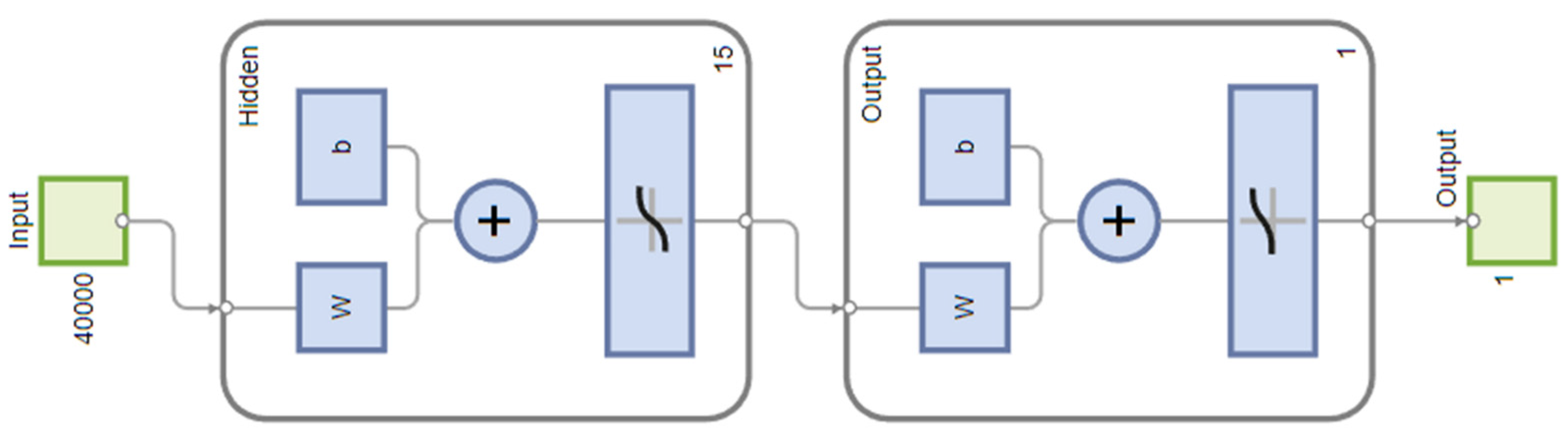
2.3. Machine Learning Methods
2.4. Modelling Methodology
- For each case in the dataset, using the quality indicators presented in Table 1, the filtration method and cut-off value for which the quality of the obtained image is the best were selected.
- Then, the index of the optimal model for each case was written in the designated table. The assignment of models to indexes is presented in Table 2.
3. Results and Discussion
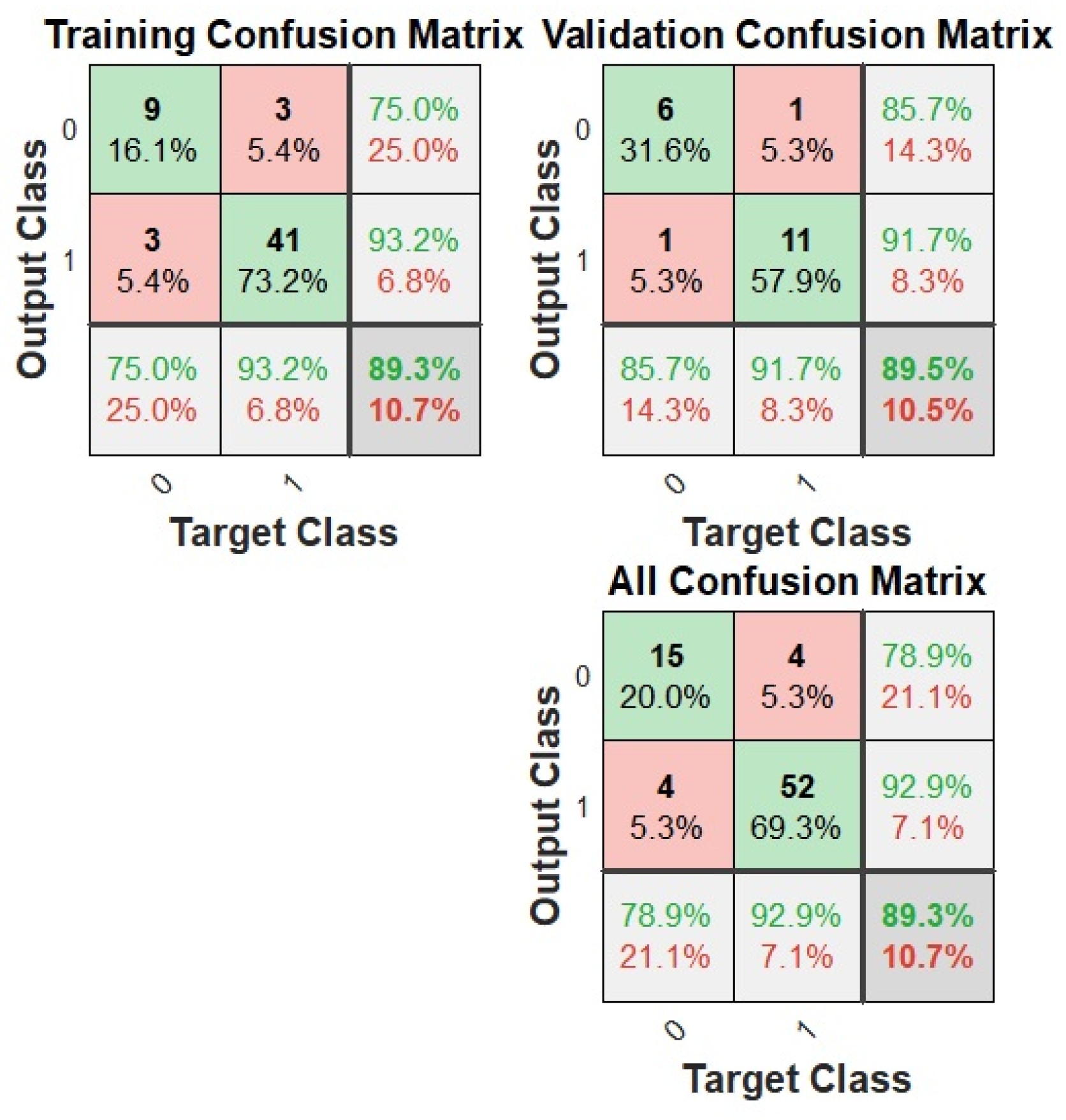
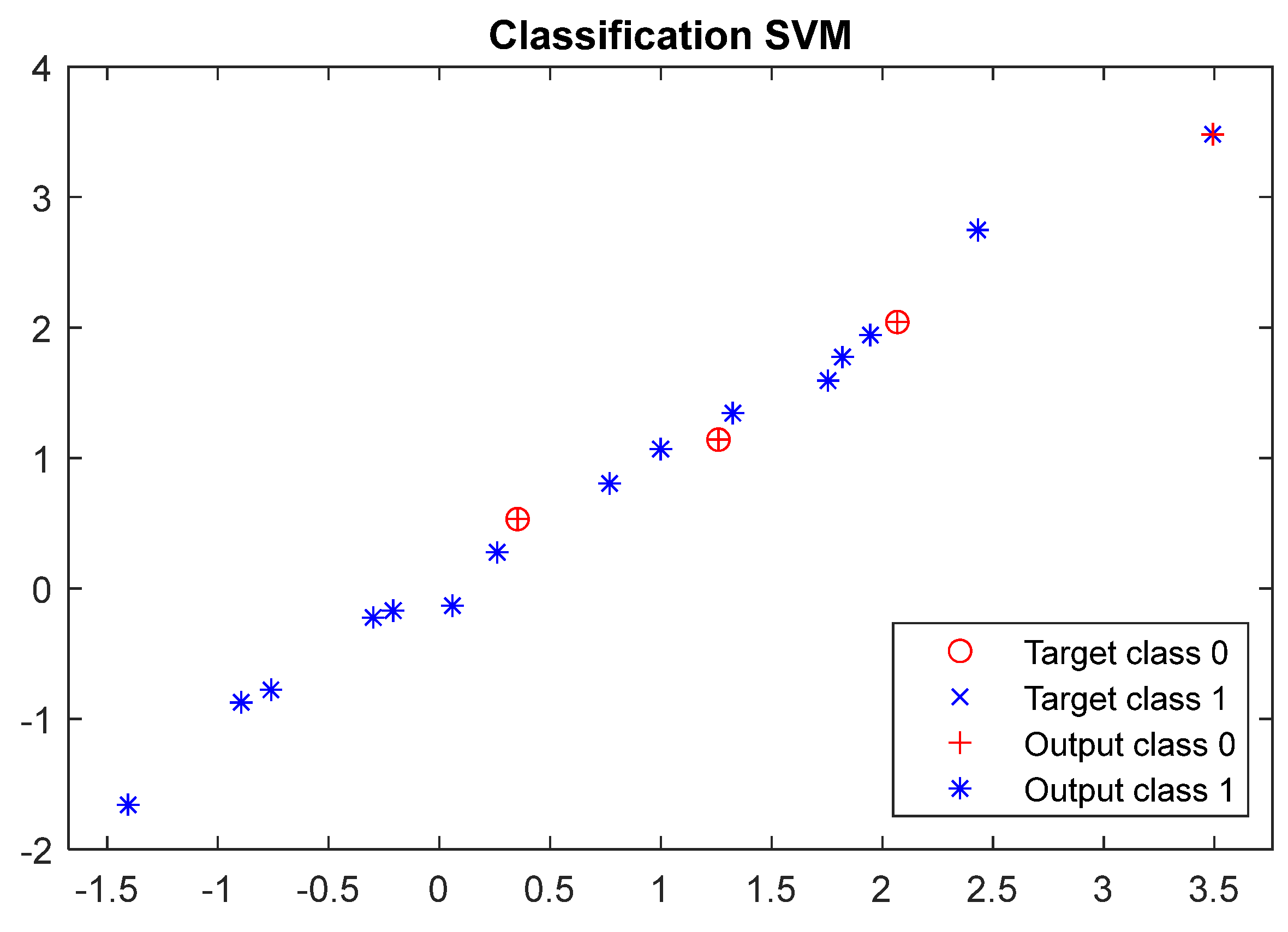
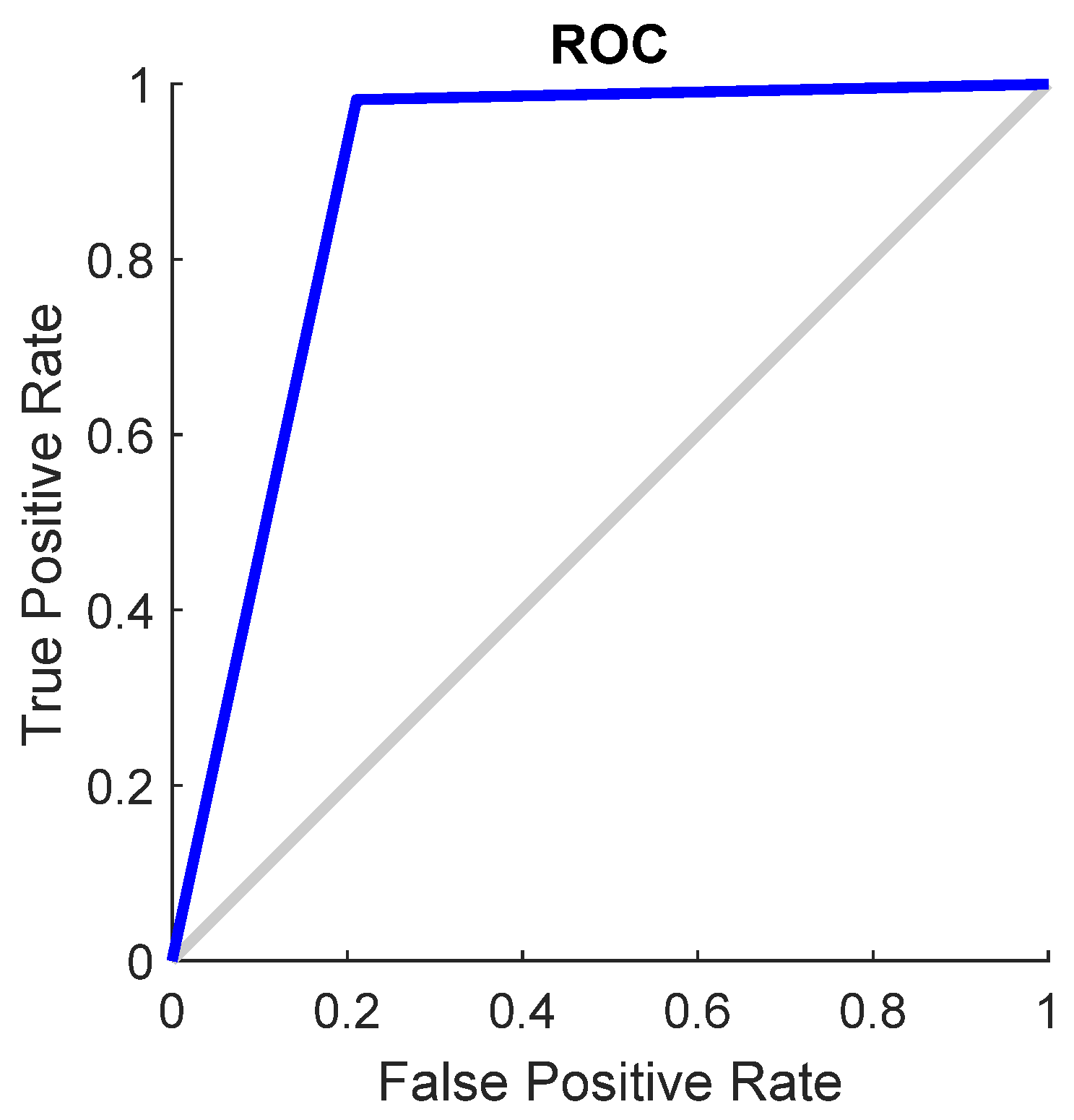
Classifier Training Results
4. Conclusions
5. Limitations and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, B.; Liu, S.; Shin, Y.C. In-Process monitoring of porosity during laser additive manufacturing process. Addit. Manuf. 2019, 28, 497–505. [Google Scholar] [CrossRef]
- Zhang, S.J.; To, S.; Wang, S.J.; Zhu, Z.W. A review of surface roughness generation in ultra-precision machining. Int. J. Mach. Tools Manuf. 2015, 91, 76–95. [Google Scholar] [CrossRef]
- Ulker, O. Surface Roughness of Composite Panels as a Quality Control Tool. Materials 2018, 11, 407. [Google Scholar] [CrossRef]
- Wei, H.; Hussain, G.; Iqbal, A.; Zhang, Z.P. Surface roughness as the function of friction indicator and an important parameters-combination having controlling influence on the roughness: Recent results in incremental forming. Int. J. Adv. Manuf. Technol. 2019, 101, 2533–2545. [Google Scholar] [CrossRef]
- Podulka, P.; Macek, W.; Rozumek, D.; Żak, K.; Branco, R. Topography measurement methods evaluation for entire bending-fatigued fracture surfaces of specimens obtained by explosive welding. Measurement 2024, 224, 113853. [Google Scholar] [CrossRef]
- Pawlus, P.; Reizer, R.; Wieczorowski, M. Functional Importance of Surface Texture Parameters. Materials 2021, 14, 5326. [Google Scholar] [CrossRef]
- Whitehead, S.A.; Shearer, A.C.; Watts, D.C.; Wilson, N.H.F. Comparison of two stylus methods for measuring surface texture. Dent. Mater. 1999, 15, 79–86. [Google Scholar] [CrossRef]
- Lee, D.H.; Cho, N.G. Assessment of surface profile data acquired by a stylus profilometer. Meas. Sci. Technol. 2012, 23, 105601. [Google Scholar] [CrossRef]
- Pawlus, P.; Reizer, R. Profilometric measurements of wear scars: A review. Wear 2023, 534–535, 205150. [Google Scholar] [CrossRef]
- Pawlus, P.; Reizer, R. Profilometric measurement of low wear: A review. Wear 2023, 532–533, 205102. [Google Scholar] [CrossRef]
- Vorburger, T.V.; Rhee, H.-G.; Renegar, T.B.; Song, J.-F.; Zheng, A. Comparison of optical and stylus methods for measurement of surface texture. Int. J. Adv. Manuf. Technol. 2007, 33, 110–118. [Google Scholar] [CrossRef]
- Zakharov, O.V.; Lysenko, V.G.; Ivanova, T.N. Asymmetric morphological filter for roughness evaluation of multifunctional surfaces. ISA Trans. 2023, 146, 403–420. [Google Scholar] [CrossRef] [PubMed]
- Rhee, H.; Lee, Y.; Lee, I.; Vorburger, T. Roughness Measurement Performance Obtained with Optical Interferometry and Stylus Method. J. Opt. Soc. Korea 2006, 10, 48–54. [Google Scholar] [CrossRef]
- Pawlus, P.; Reizer, R.; Wieczorowski, M. Comparison of results of surface texture measurement obtained with stylus methods and optical methods. Metrol. Meas. Syst. 2018, 25, 589–602. [Google Scholar] [CrossRef]
- Merola, M.; Ruggiero, A.; De Mattia, J.S.; Affatato, S. On the tribological behavior of retrieved hip femoral heads affected by metallic debris. A comparative investigation by stylus and optical profilometer for a new roughness measurement protocol. Measurement 2016, 90, 365–371. [Google Scholar] [CrossRef]
- Podulka, P. Reduction of Influence of the High-Frequency Noise on the Results of Surface Topography Measurements. Materials 2021, 14, 333. [Google Scholar] [CrossRef]
- ISO 2016 25178-600; Geometrical Product Specification (GPS)—Surface Texture: Areal Part 600: Metrological Characteristics for Areal-Topography Measuring Methods. International Organization for Standardization: Geneva, Switzerland, 2016.
- De Groot, P.; DiSciacca, J. Definition and evaluation of topography measurement noise in optical instruments. Opt. Eng. 2020, 59, 064110. [Google Scholar] [CrossRef]
- Syam, W.P. In-process surface topography measurements. In Advances in Optical Surface Texture Metrology; Leach, R.K., Ed.; IOP Publishing: Bristol, UK, 2020. [Google Scholar] [CrossRef]
- Gomez, C.; Su, R.; de Groot, P.; Leach, R.K. Noise Reduction in Coherence Scanning Interferometry for Surface Topography Measurement. Nanomanuf. Metrol. 2020, 3, 68–76. [Google Scholar] [CrossRef]
- Pawlus, P.; Reizer, R.; Wieczorowski, M.; Krolczyk, G. Study of surface texture measurement errors. Measurement 2023, 210, 112568. [Google Scholar] [CrossRef]
- Biruk-Urban, K.; Zagórski, I.; Kulisz, M.; Leleń, M. Analysis of Vibration, Deflection Angle and Surface Roughness in Water-Jet Cutting of AZ91D Magnesium Alloy and Simulation of Selected Surface Roughness Parameters Using ANN. Materials 2023, 16, 3384. [Google Scholar] [CrossRef]
- Zagórski, I.; Kulisz, M.; Szczepaniak, A. Roughness Parameters with Statistical Analysis and Modelling Using Artificial Neural Networks After Finish Milling of Magnesium Alloys with Different Edge Helix Angle Tools. Stroj. Vestn.-J. Mech. Eng. 2024, 70, 27–41. [Google Scholar] [CrossRef]
- Angermann, C.; Haltmeier, M.; Laubichler, C.; Jónsson, S.; Schwab, M.; Moravová, A.; Kiesling, C.; Kober, M.; Fimml, W. Surface topography characterization using a simple optical device and artificial neural networks. Eng. Appl. Artif. Intell. 2023, 123, 106337. [Google Scholar] [CrossRef]
- El-Sonbaty, I.A.; Khashaba, U.A.; Selmy, A.I.; Ali, A.I. Prediction of surface roughness profiles for milled surfaces using an artificial neural network and fractal geometry approach. J. Mater. Process. Technol. 2008, 200, 271–278. [Google Scholar] [CrossRef]
- Patil, D.; Dhisale, M.; Gandhshreewar, C.; Deshpande, P.; Verma, A.; Shah, B. Modelling of 3D topographic parameters of machined surfaces using Artificial Neural Network regression approach. Mater. Today Proc. 2022, 62, 3878–3885. [Google Scholar] [CrossRef]
- Krawczyk, B.; Szablewski, P.; Mendak, M.; Gapiński, B.; Smak, K.; Legutko, S.; Wieczorowski, M.; Miko, E. Surface Topography Description of Threads Made with Turning on Inconel 718 Shafts. Materials 2023, 16, 80. [Google Scholar] [CrossRef] [PubMed]
- Molnar, V. Tribological Properties and 3D Topographic Parameters of Hard Turned and Ground Surfaces. Materials 2022, 15, 2505. [Google Scholar] [CrossRef]
- Masoudi, S.; Esfahani, M.J.; Jafarian, F.; Mirsoleimani, S.A. Comparison the effect of MQL, wet and dry turning on surface topography, cylindricity tolerance and sustainability. Int. J. Precis. Eng. Manuf.-Green Technol. 2023, 10, 9–21. [Google Scholar] [CrossRef]
- Kozłowski, E.; Antosz, K.; Sęp, J.; Prucnal, S. Integrating Sensor Systems and Signal Processing for Sustainable Production: Analysis of Cutting Tool Condition. Electronics 2024, 13, 185. [Google Scholar] [CrossRef]
- Samala, T.; Manupati, V.K.; Machado, J.; Khandelwal, S.; Antosz, K. A Systematic Simulation-Based Multi-Criteria Decision-Making Approach for the Evaluation of Semi–Fully Flexible Machine System Process Parameters. Electronics 2022, 11, 233. [Google Scholar] [CrossRef]
- Podulka, P.; Macek, W.; Zima, B.; Lesiuk, G.; Branco, R.; Królczyk, G. Roughness evaluation of turned composite surfaces by analysis of the shape of autocorrelation function. Measurement 2023, 222, 113640. [Google Scholar] [CrossRef]
- Khellaf, A.; Aouici, H.; Smaiah, S.; Boutabba, S.; Yallese, M.A.; Elbah, M. Comparative assessment of two ceramic cutting tools on surface roughness in hard turning of AISI H11 steel: Including 2D and 3D surface topography. Int. J. Adv. Manuf. Technol. 2017, 89, 333–354. [Google Scholar] [CrossRef]
- Meddour, I.; Yallese, M.A.; Khattabi, R.; Elbah, M.; Boulanouar, L. Investigation and modeling of cutting forces and surface roughness when hard turning of AISI 52100 steel with mixed ceramic tool: Cutting conditions optimization. Int. J. Adv. Manuf. Technol. 2015, 77, 1387–1399. [Google Scholar] [CrossRef]
- Maculotti, G.; Feng, X.; Galetto, M.; Leach, R.K. Noise evaluation of a point autofocus surface topography measuring instrument. Meas. Sci. Technol. 2018, 29, 065008. [Google Scholar] [CrossRef]
- Podulka, P. Thresholding Methods for Reduction in Data Processing Errors in the Laser-Textured Surface Topography Measurements. Materials 2022, 15, 5137. [Google Scholar] [CrossRef]
- Haitjema, H. Uncertainty in measurement of surface topography. Surf. Topogr. Metrol. Prop. 2015, 3, 35004. [Google Scholar] [CrossRef]
- Podulka, P. Suppression of the High-Frequency Errors in Surface Topography Measurements Based on Comparison of Various Spline Filtering Methods. Materials 2021, 14, 5096. [Google Scholar] [CrossRef]
- Vanrusselt, M.; Haitjema, H.; Leach, R.K.; de Groot, P. International comparison of noise in areal surface topography measurements. Surf. Topogr. Metrol. Prop. 2021, 9, 025015. [Google Scholar] [CrossRef]
- Leach, R.; Evans, C.; He, L.; Davies, A.; Duparré, A.; Henning, A.; Jones, C.W.; O’Connor, D. Open questions in surface topography measurement: A roadmap. Surf. Topogr. Metrol. Prop. 2015, 3, 13001. [Google Scholar] [CrossRef]
- Królczyk, G.; Kacalak, W.; Wieczorowski, M. 3D Parametric and Nonparametric Description of Surface Topography in Manufacturing Processes. Materials 2021, 14, 1987. [Google Scholar] [CrossRef] [PubMed]
- Giusca, C.L.; Leach, R.K.; Helary, F.; Gutauskas, T.; Nimishakavi, L. Calibration of the scales of areal surface topography-measuring instruments: Part 1. Measurement noise and residual flatness. Meas. Sci. Technol. 2012, 23, 035008. [Google Scholar] [CrossRef]
- Yücel, E.; Günay, M. Modelling and optimization of the cutting conditions in hard turning of high-alloy white cast iron (Ni-Hard). Proc. Inst. Mech. Eng. Part C J. Mech. Eng. Sci. 2012, 227, 2280–2290. [Google Scholar] [CrossRef]
- Tooptong, S.; Park, K.-H.; Kwon, P. A comparative investigation on flank wear when turning three cast irons. Tribol. Int. 2018, 120, 127–139. [Google Scholar] [CrossRef]
- Tabaszewski, M.; Twardowski, P.; Wiciak-Pikuła, M.; Znojkiewicz, N.; Felusiak-Czyryca, A.; Czyżycki, J. Machine Learning Approaches for Monitoring of Tool Wear during Grey Cast-Iron Turning. Materials 2022, 15, 4359. [Google Scholar] [CrossRef]
- Bhattacharyya, S.K.; Ezugwu, E.O.; Jawahid, A. The performance of ceramic tool materials for the machining of cast iron. Wear 1989, 135, 147–159. [Google Scholar] [CrossRef]
- Jia, X.; Zuo, X.; Liu, Y.; Chen, N.; Rong, Y. High Wear Resistance of White Cast Iron Treated by Novel Process: Principle and Mechanism. Metall. Mater. Trans. A 2015, 46, 5514–5525. [Google Scholar] [CrossRef]
- Zhou, J.; Andersson, M. Effects of Lubricant Condition and Tool Wear in Hard Turning of Novel-Abrasion-Resistance (N-AR) Cast Iron. Mater. Manuf. Process. 2007, 22, 7–8. [Google Scholar] [CrossRef]
- Akinribide, O.J.; Ogundare, O.D.; Oluwafemi, O.M.; Ebisike, K.; Nageri, A.K.; Akinwamide, S.O.; Gamaoun, F.; Olubambi, P.A. A Review on Heat Treatment of Cast Iron: Phase Evolution and Mechanical Characterization. Materials 2022, 15, 7109. [Google Scholar] [CrossRef]
- ISO 11562:1996; Geometric Product Specifications (GPS)-Surface Texture: Profile Method Metrological Characteristics of Phase Correct Filters. International Organization for Standardization: Geneva, Switzerland, 1996.
- Baofeng, H.; Haibo, Z.; Siyuan, D.; Ruizhao, Y.; Zhaoyao, S. A review of digital filtering in evaluation of surface roughness. Metrol. Meas. Syst. 2021, 28, 217–253. [Google Scholar] [CrossRef]
- Lou, S.; Jiang, X.; Sun, W.; Zeng, W.; Pagani, L.; Scott, P. Characterisation methods for powder bed fusion processed surface topography. Precis. Eng. 2019, 57, 1–15. [Google Scholar] [CrossRef]
- ISO 16610-31:2016; Geometrical Product Specifications (GPS) Filtration Part 31: Robust Profile Filters: Gaussian Regression Filters. International Organization for Standardization: Geneva, Switzerland, 2016.
- Shao, Y.P.; Xu, F.C.; Chen, J.; Lu, J.S.; Du, S.C. Engineering surface topography analysis using an extended discrete modal decomposition. J. Manuf. Process. 2023, 90, 367–390. [Google Scholar] [CrossRef]
- Zhang, H.; Yuan, Y.; Piao, W. The spline filter: A regularization approach for the Gaussian filter. Precis. Eng. 2012, 36, 586–592. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Choi, R.Y.; Coyner, A.S.; Kalpathy-Cramer, J.; Chiang, M.F.; Campbell, J.P. Introduction to machine learning, neural networks, and deep learning. Transl. Vis. Sci. Technol. 2020, 9, 14. [Google Scholar]
- Otchere, D.A.; Ganat, T.O.A.; Gholami, R.; Ridha, S. Application of supervised machine learning paradigms in the prediction of petroleum reservoir properties: Comparative analysis of ANN and SVM models. J. Pet. Sci. Eng. 2021, 200, 108182. [Google Scholar] [CrossRef]
- Hamdan, Y.B.; Sathesh, A. Construction of statistical SVM based recognition model for handwritten character recognition. J. Inf. Technol. Digit. World 2021, 3, 92–107. [Google Scholar] [CrossRef]
- Gareth, J.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning with Applications with R; Springer: London, UK, 2013. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Chapman & Hall: New York, NY, USA, 1984. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Quality Indicator | Formula | Explanations of the Symbols |
|---|---|---|
| Mean square error (MSE) | R—the total count of pixels in the 2D image yi—the i-th pixel of the pattern image —the i-th pixel of the reconstructed image C1 = (0.01 · L)2, C2 = (0.03 · L)2, and L is set to 1 when the pixel s is in the range (0, 1) —the local means, —standard deviations, —cross-covariances —the average pixel distribution pattern image —the average pixel distribution reconstruction | |
| Peak Signal-to-noise ratio (PSNR) | ||
| Structural similarity index (SSIM) | ||
| Image correlation coefficient (ICC) |
| Model Index | Filtration Method |
|---|---|
| 1 | Gaussian regression filter |
| 2 | Robust Gaussian regression filter |
| 3 | Spline filter |
| 4 | Fast Fourier transform filter |
| Model Index | Formula | Explanations of the Symbols |
|---|---|---|
| Accuracy | TP—true positives TN—true negatives FP—false positives FN—false negatives | |
| Sensitivity | ||
| Precision | ||
| F1 score | ||
| Error rate |
| Quality Indicators | NN | SVM | DT |
|---|---|---|---|
| Accuracy [%] | 89.33 | 98.67 | 93.33 |
| Sensitivity [%] | 92.86 | 100.00 | 93.22 |
| Precision [%] | 92.86 | 98.21 | 98.21 |
| F1 Score [%] | 92.86 | 99.10 | 95.65 |
| Error Rate [%] | 10.67 | 1.33 | 6.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Podulka, P.; Kulisz, M.; Antosz, K. Evaluation of High-Frequency Measurement Errors from Turned Surface Topography Data Using Machine Learning Methods. Materials 2024, 17, 1456. https://doi.org/10.3390/ma17071456
Podulka P, Kulisz M, Antosz K. Evaluation of High-Frequency Measurement Errors from Turned Surface Topography Data Using Machine Learning Methods. Materials. 2024; 17(7):1456. https://doi.org/10.3390/ma17071456
Chicago/Turabian StylePodulka, Przemysław, Monika Kulisz, and Katarzyna Antosz. 2024. "Evaluation of High-Frequency Measurement Errors from Turned Surface Topography Data Using Machine Learning Methods" Materials 17, no. 7: 1456. https://doi.org/10.3390/ma17071456
APA StylePodulka, P., Kulisz, M., & Antosz, K. (2024). Evaluation of High-Frequency Measurement Errors from Turned Surface Topography Data Using Machine Learning Methods. Materials, 17(7), 1456. https://doi.org/10.3390/ma17071456