1. Introduction
Many problems in science and industry are concerned with multi-objective optimization problems (MOPs). Multi-objective optimization seeks to optimize several components of an objective function vector. Contrary to single-objective optimization, the solution of a MOP is not a single solution, but a set of solutions known as Pareto optimal set, which is called Pareto front when it is plotted in the objective space. Any solution of this set is optimal in the sense that no improvement can be made on a component of the objective vector without worsening at least another of its components. The main goal in solving a difficult MOP is to approximate the set of solutions within the Pareto optimal set and, consequently, the Pareto front.
Definition 1 (MOP)
. A multi-objective optimization problem (MOP) may be defined as:where k is the number of objectives, is the vector representing the decision variables, and X represents the set of feasible solutions associated with equality and inequality constraints, and explicit bounds. is the vector of objectives to be optimized. The set of all values satisfying the constraints defines the feasible region X and any point is a feasible solution. As mentioned before, we seek for the Pareto optima.
Definition 2 (Pareto). A point is Pareto Optimal if for every and and there is at least one such that .
This definition states that is Pareto optimal if no feasible vector exists which would improve some criterion without causing a simultaneous worsening in at least one other criterion.
Definition 3 (Dominance). A vector is said to dominate (denoted by ) if and only if is partially less than , i.e.,
Definition 4 (Pareto set). For a given MOP , the Pareto optimal set is defined as .
Definition 5 (Pareto front). For a given MOP and its Pareto optimal set , the Pareto front is defined as .
Definition 6 (Reference point). A reference point is a vector which defines the aspiration level (or goal) to reach for each objective .
Definition 7 (Nadir point). A point is the nadir point if it maximizes each objective function of F over the Pareto set, i.e., .
The approaches developed for treating optimization problems can be mainly divided into deterministic and stochastic. Deterministic methods (e.g., linear programming, nonlinear programming, and mixed-integer nonlinear programming, etc.) provide a theoretical guarantee of locating the global optimum or at least a good approximation of it whereas the stochastic methods offer a guarantee in probability [
1,
2,
3].
Most of the well-known metaheuristics (e.g., evolutionary algorithms, particle swarm, ant colonies) have been adapted to solve multi-objective problems [
4,
5] with a growing number of applications [
6,
7,
8].
Multi-objective metaheuristics can be classified in three main categories:
Scalarization-based approaches: this class of multi-objective metaheuristics contains the approaches which transform a MOP problem into a single-objective one or a set of such problems. Among these methods one can find the aggregation methods, weighted metrics, cheybycheff method, goal programming methods, achievement functions, goal attainment methods and the
-constraint methods [
9,
10].
Dominance-based approaches: the dominance-based approaches (Also named Pareto approaches.) use the concept of dominance and Pareto optimality to guide the search process. Since the beginning of the nineties, interest concerning MOPs area with Pareto approaches always grows. Most of Pareto approaches use EMO (Evolutionary Multi-criterion Optimization) algorithms. Population-based metaheuristics seem particularly suitable to solve MOPs, because they deal simultaneously with a set of solutions which allows to find several members of the Pareto optimal set in a single run of the algorithm. Moreover, they are less sensitive to the shape of the Pareto front (continuity, convexity). The main differences between the various proposed approaches arise in the followins search components: fitness assignment, diversity management, and elitism [
11].
Decomposition-based approaches: most of decomposition based algorithms in solving MOPs operate in the objective space. One of the well-known frameworks for MOEAs using decomposition is MOEOA/D [
12]. It uses scalarization to decompose the MOP into multiple scalar optimization subproblems and solve them simultaneously by evolving a population of candidate solutions. Subproblems are solved using information from the neighbouring subproblems [
13].
We are interested in tackling MOPs using Chaotic optimization approaches. In our previous work, we proposed a efficient metaheuristic for single objective optimization called Tornado which is based on Chaotic search. It is a metaheuristic developed to solve large-scale continuous optimization problems. In this paper we extend our Chaotic approach Tornado to solve MOPs by using various Tchebychev scalarization approaches.
The paper is organized as follow.
Section 1 recalls the main principles of the Chaotic search Tornado algorithm. Then the extended Chaotic search for multi-objective optimization is detailed in
Section 3. In
Section 4 the experimental settings and computational results against competing methods are detailed and analyzed. Finally, the
Section 5 concludes and presents some future works.
2. The Tornado Chaotic Search Algorithm
2.1. Chaotic Optimization Algorithm: Recall
The chaotic optimization algorithm (COA) is recently proposed metaheuristic method [
14] which is based on chaotic sequences instead of random number generators and mapped as the design variables for global optimization. It includes generally two main stages:
Global search: This search corresponds to exploration phase. A sequence of chaotic solutions is generated using a chaotic map. Then, this sequence is mapped into the range of the search space to get the decision variables on which the objective function is evaluated and the solution with the best objective function is chosen as the current solution.
Local search: After the exploration of the search space, the current solution is assumed to be close to the global optimum after a given number of iterations, and it is viewed as the centre on which a little chaotic perturbation, and the global optimum is obtained through local search. The above two steps are iterated until some specified stopping criterion is satisfied.
In recent years COA has attracted widespread attention and have been widely investigated and many choatic approaches have been proposed in the litterature [
15,
16,
17,
18,
19,
20,
21].
2.2. Tornado Principle
The Tornado algorithm has been as an improvement to the basic COA approach to correct some of major drawbacks such as the inability of the method to deal with high-dimensional problems [
22,
23]. Indeed, the Tornado algorithm introduces new strategies such as symmetrization and levelling of the distribution of chaotic variables in order to break the rigidity inherent in chaotic dynamics.
The proposed Tornado algorithm is composed of three main procedures:
The chaotic global search (CGS): this procedure explores the entire research space and select the best point among a distribution of symmetrized distribution of chaotic points.
The chaotic local search (CLS): The CLS carries out a local search on neighbourhood of the solution initially found CGS, it exploits the of the solution. Moreover, by focusing on successive promising solutions, CLS allows also the exploration of promising neighboring regions.
The chaotic fine search (CFS): It is programmed after the CGS and CLS procedures in order to refine their solutions by adopting a coordinate adaptive zoom strategy to intensify the search around the current optimum.
As a COA approach, The Tornado algorithm relies on a chaotic sequence in order to generate chaotic variables that will be used in the search process. For instance, Henon map was adopted as a generator of a chaotic sequence in Tornado.
To this end. We consider a sequence
of normalized Henon vectors
built by the following linear transformation of the standard Henon map [
24]:
where
and
Thus, we obtain . In this paper, the parameters of the Henon map sequence are set as follows:
The structure of the proposed Tornado approach is given in Algorithm 1.
| Algorithm 1 The Tornado algorithm structure. |
Initialization of the Henon chaotic sequence; Set ; Repeat Chaotic Global Search (CGS); Set ; Repeat; Chaotic Local Search (CLS); Chaotic Finest Search (CFS); ; Until ; /* is the number of CLS/CFS by cycle */ ; Until; /* is maximum number of cycles of Tornado */
|
2.2.1. Chaotic Global Search (CGS)
CGS starts by mapping the chaotic sequence generated by the adopted standard Henon map variable
Z into ranges of design variable
X by considering the following transformations (
Figure 1):
Those proposed transformations aim to overcome the inherent rigidity of the chaos dynamics.
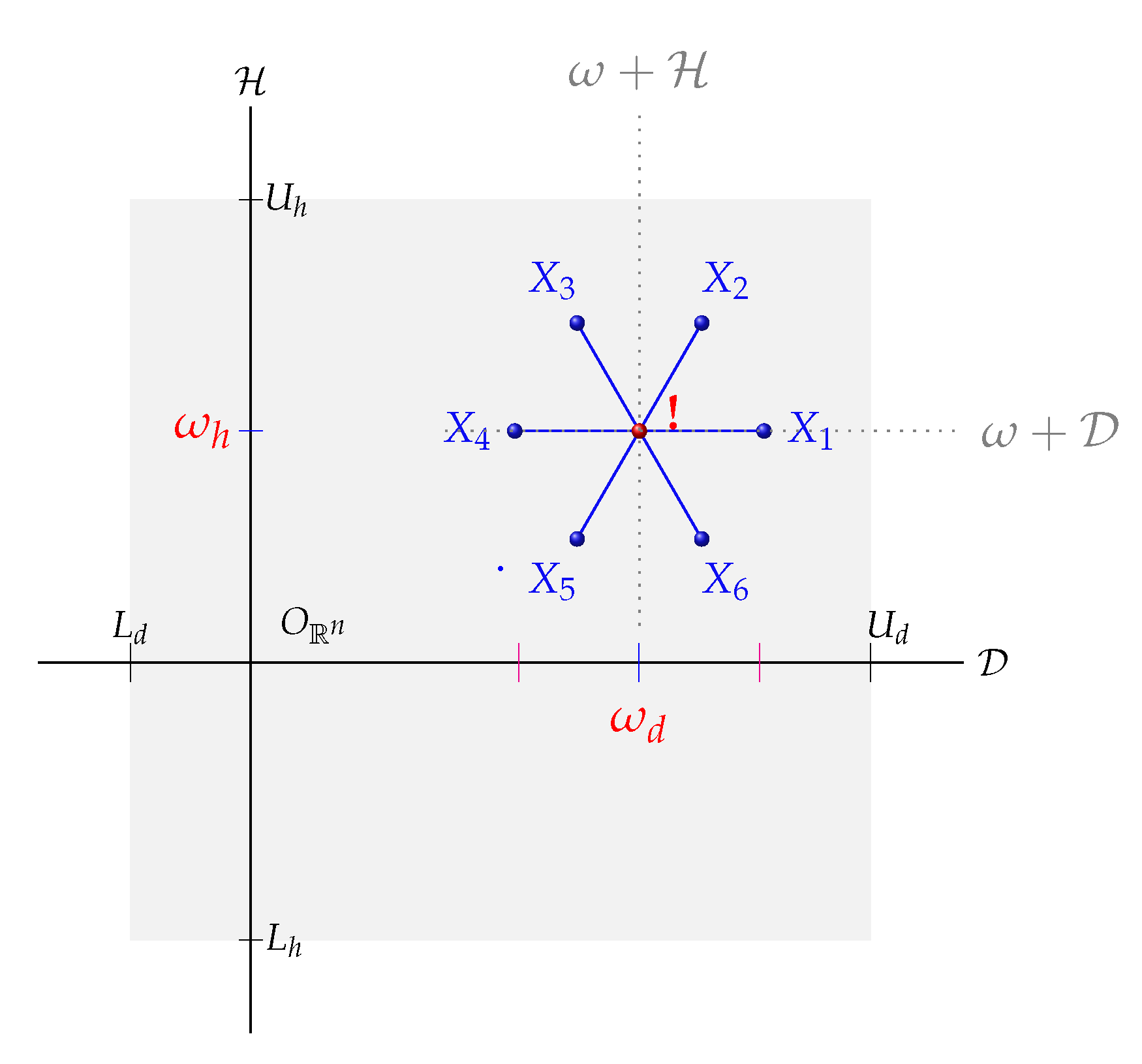
The symmetrization approach based on this stochastic decomposition of the design space offers two significant advantages:
- ∘
Significant reduction of complexity in the high dimensional problem in a way as if we were dealing with a 2D space with four directions.
- ∘
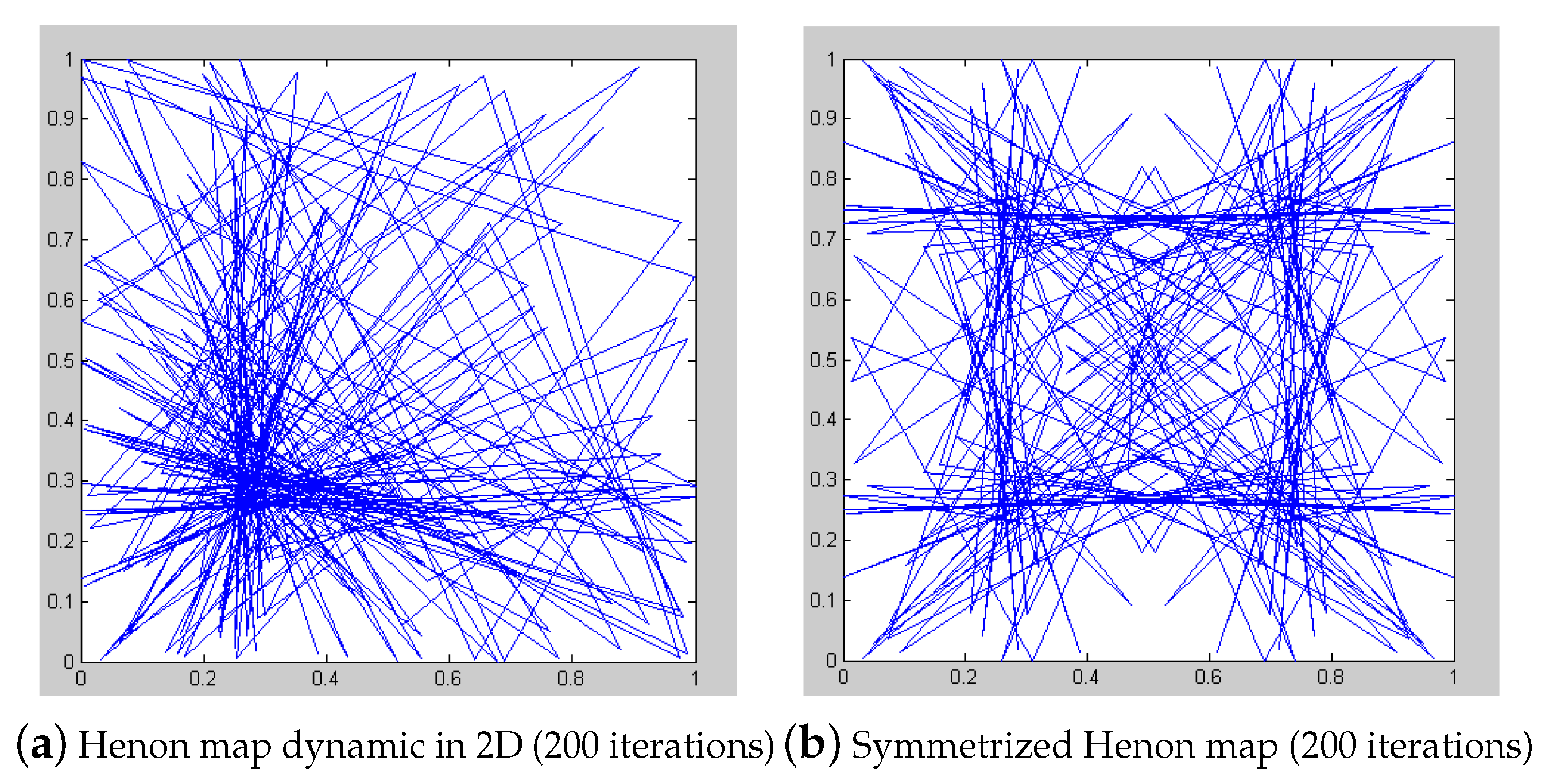
The symmetric chaos is more regular and more ergodic than the basic one (
Figure 2).
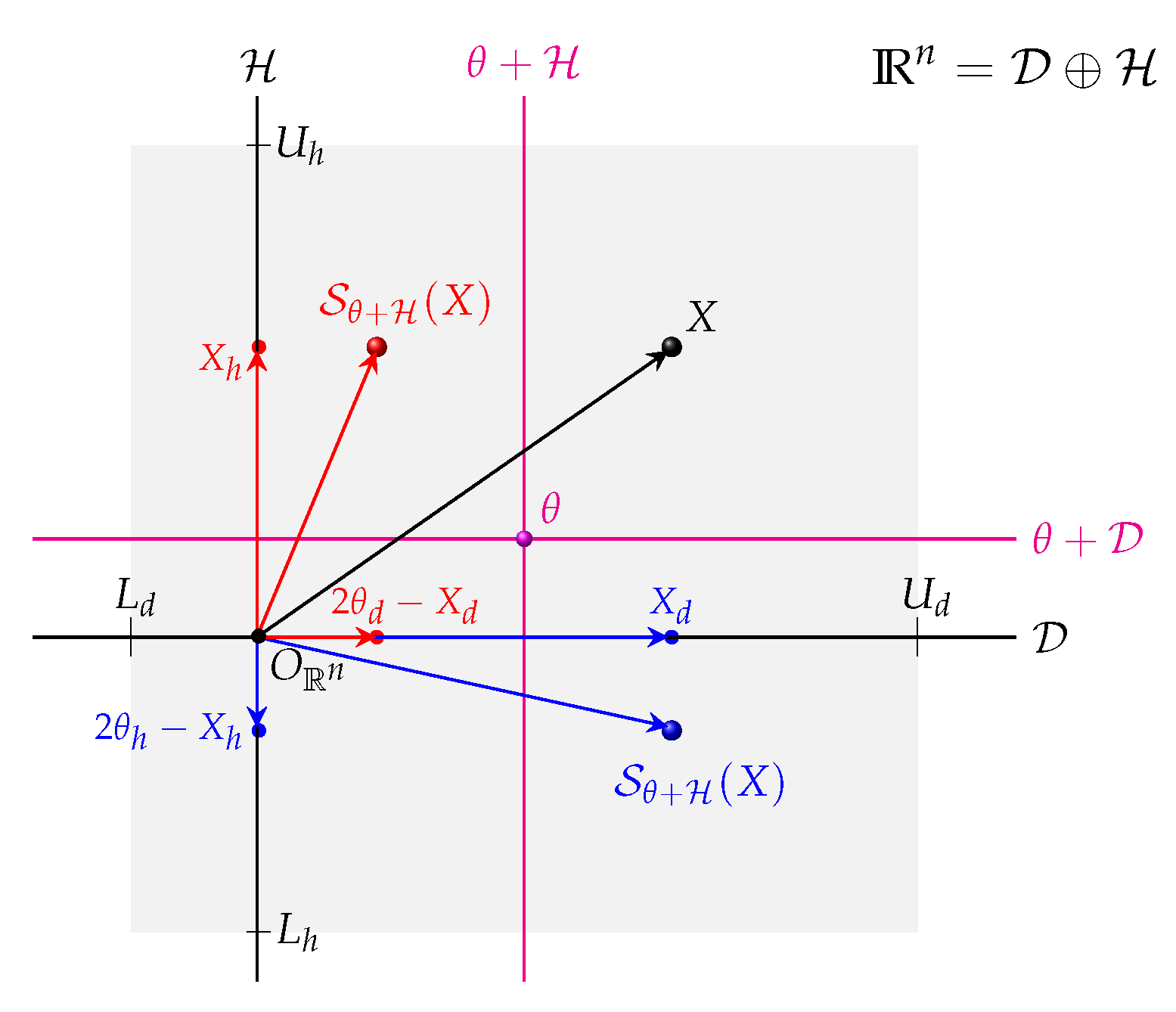
Thanks to the stochastic decomposition (Equation (
7)), CGS generates four symmetric chaotic points using axial symmetries
(
Figure 3):
where the axial symmetries
are defined as follows:
In other words,
:
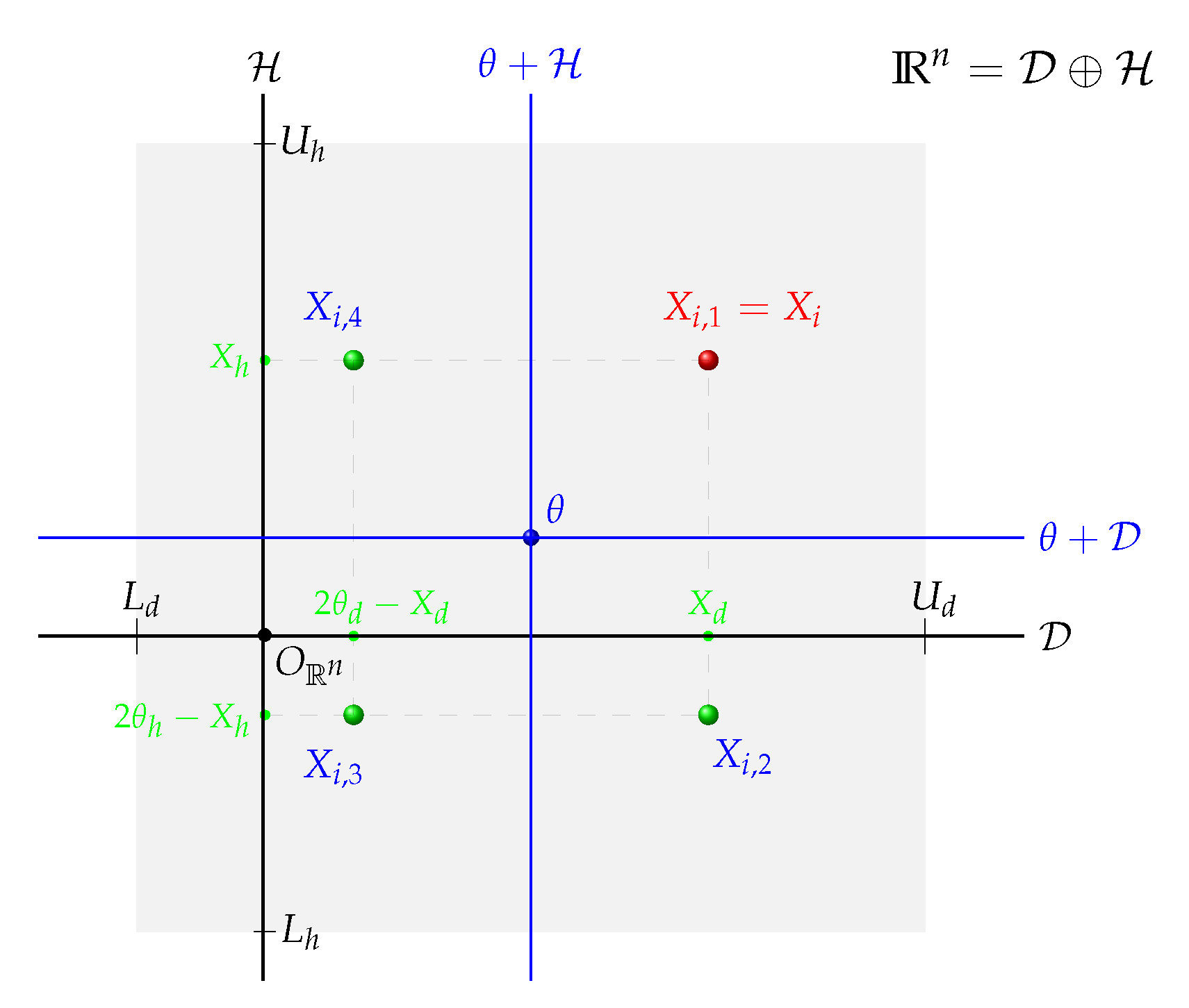
At last, the best solution among these all generated chaotic points is selected as illustrated by
Figure 4.
The code of CGS is detailed in Algorithm 2.
| Algorithm 2 Chaotic global search (CGS). |
- 1:
Input: - 2:
Output: - 3:
- 4:
for to - 5:
Generate 3 chaotic variables and according to (Equations ( 4)–( 6)) - 6:
for to 3 - 7:
Select randomly an index and decompose according to (Equation ( 8)) - 8:
Generate the 4 corresponding symmetric points according to (Equations ( 10)–( 13)) - 9:
for to 4 - 10:
if - 11:
- 12:
end if - 13:
end for - 14:
end for - 15:
end for
|
2.2.2. Chaotic Local Search (CLS)
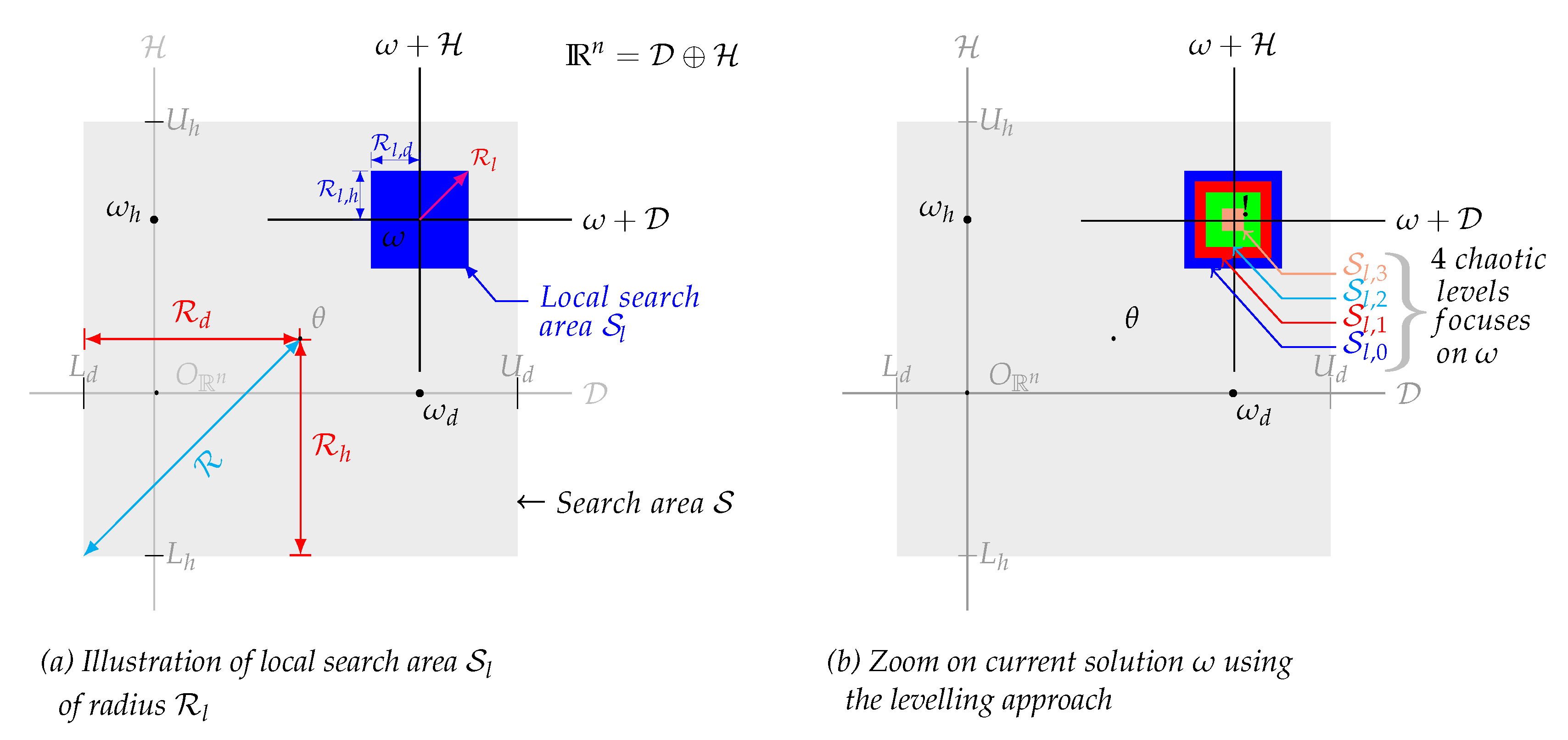
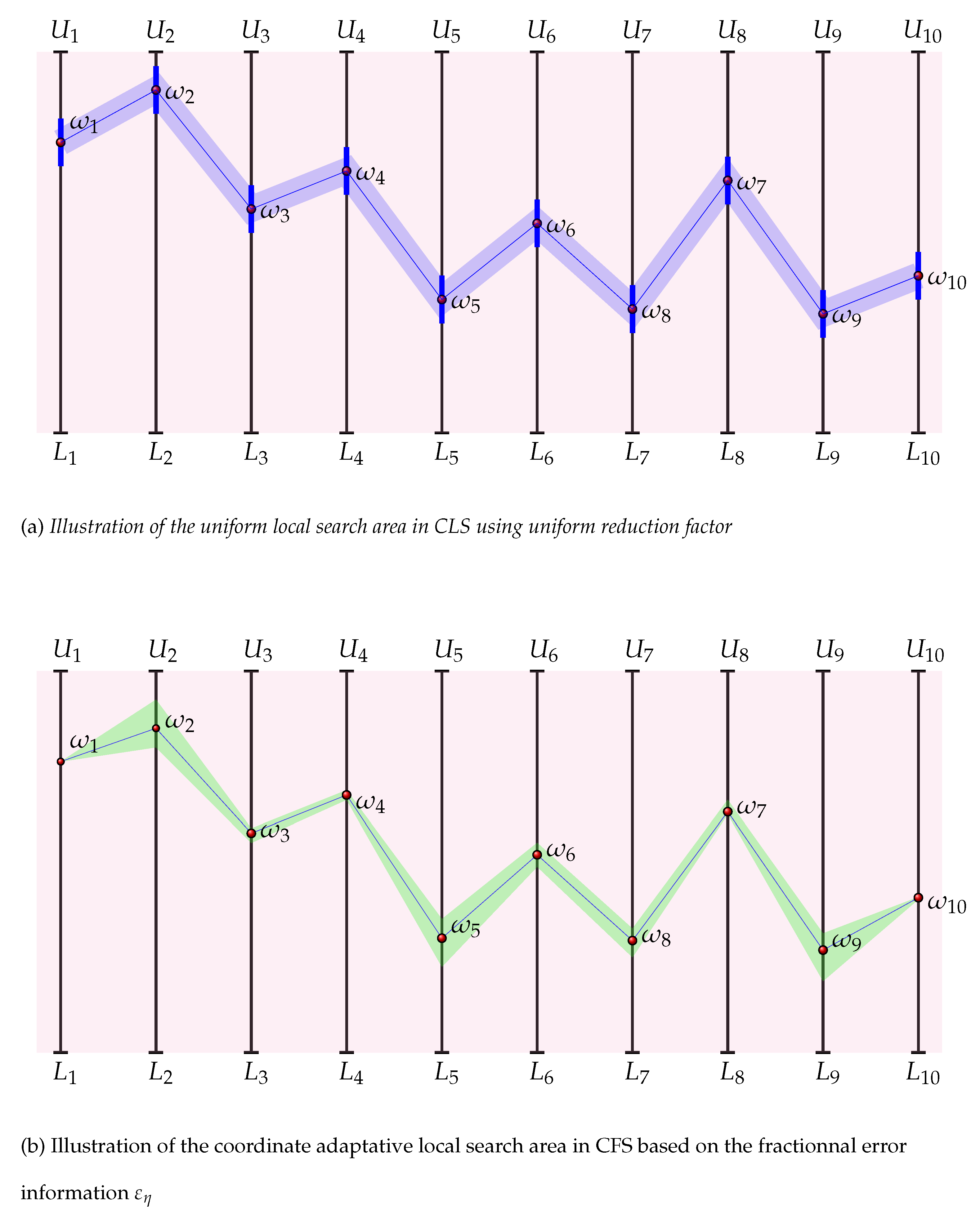
The CLS procedure is designed to refine the search by exploiting the neighborhood of the solution
found by the chaotic global search CGS. In fact, the search process is conducted near the current solution
within a local search area
whose radius is
focused on
(see
Figure 5a), where
is a random parameter that corresponds to the reduction rate, and
denotes the radius of the search zone
such as:
The CLS procedure uses the following strategy to produce chaotic variables:
Like the CGS, the CLS also involves a levelling approach by creating
chaotic levels focused on
. The local search process in each chaotic level
, is limited to a local area
focused on
(see
Figure 5b) characterized by its radius
defined by the following:
where
is a decreasing parameter through levels which we have formulated in this work as follows:
This levelling approach used by the CLS can be interpreted as a progressive zoom focus on the current solution
carried out through
chaotic levels, and
is the factor indicating the speed of this zoom process
(see
Figure 5b).
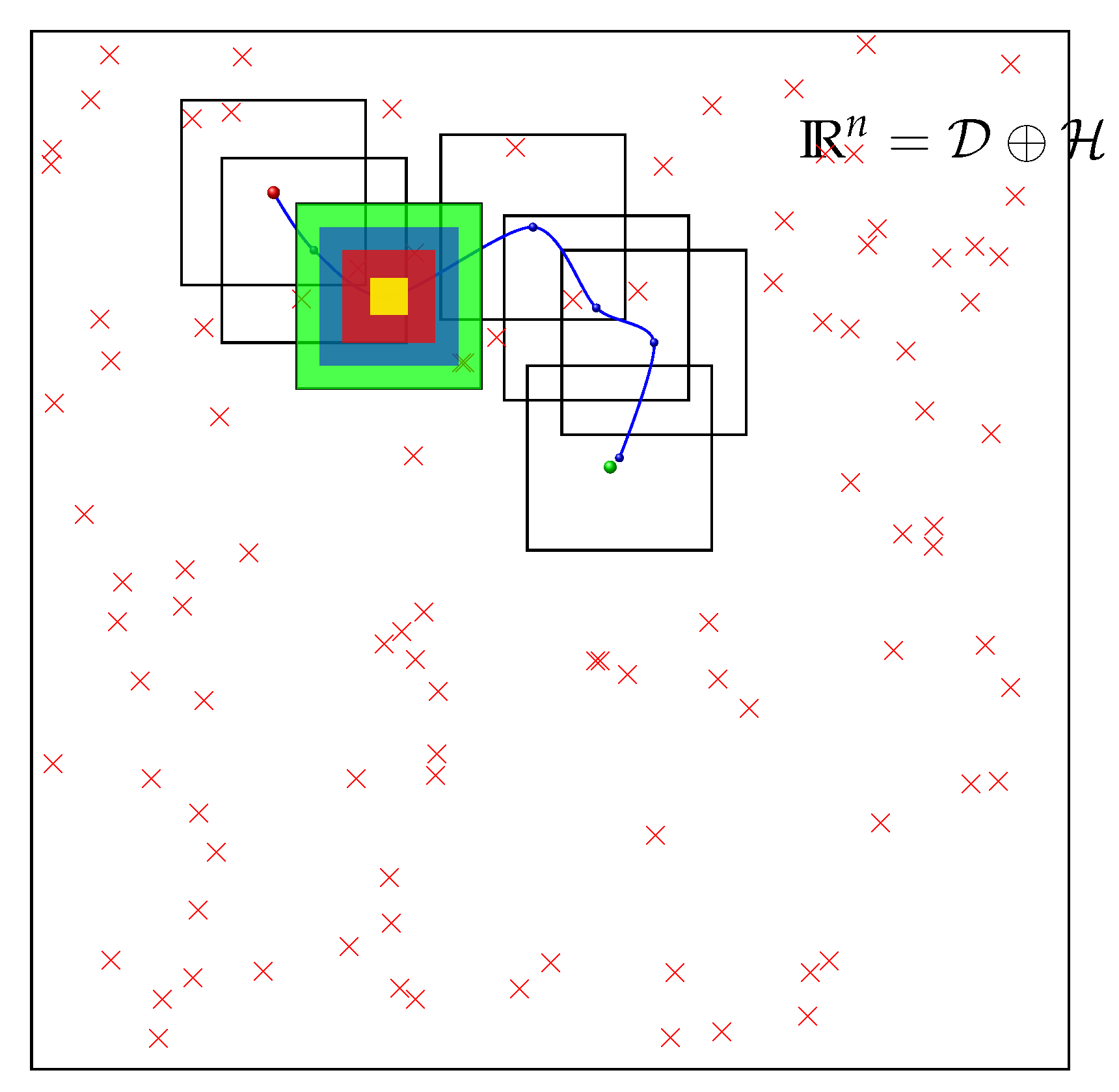
Furthermore, by looking for potential solutions relatively far from the current solution CLS contributes also to the exploration of the decision space. Indeed, once the CGS provides an initial solution
, the CLS intensifies the search around this solution, through several chaotic layers. After each CGS run, CLS carry out several cycles of local search (i.e.,
) This way, the CLS participates also to the exploration of neighboring regions by following the zoom dynamic through the CLS cycles as shown in
Figure 6.
Moreover, in each chaotic level
, CLS creates two symmetric chaotic variables
defined as follows (
Figure 7):
By randomly choosing an index
a stochastic decomposition of
is built given by:
Based on this, a decomposition of each chaotic variable
is applied:
Finally, from each chaotic variable
,
symmetric chaotic points
are generated using the polygonal model (
Figure 8): polygonal model
Moreover, if is close enough to the borders of the search area , the search process risks to leave it and then may give an infeasible solution localized outside .
Indeed, that particularly happens in case of
for at least one component
(
Figure 9), where
is the distance of the component
to borders
defined as follows:
To prevent this overflow, the local search radius
is corrected through the the following formula:
where
. This ensures
. Hence, Equation (
17) become
Finally, the chaotic local search (CLS) code is detailed in Algorithm 3.
| Algorithm 3 Chaotic Local Search (CLS). |
- 1:
Input: - 2:
Output: : best solution among the local chaotic points - 3:
- 4:
- 5:
- 6:
for to - 7:
Set and then compute - 8:
Generate 2 symmetric chaotic variables , according to ( 23) - 9:
for to 2 - 10:
Select an index randomly and decompose according to ( 19) - 11:
Generate the corresponding symmetric points according to ( 20) - 12:
for to - 13:
if then - 14:
- 15:
end if - 16:
end for - 17:
end for - 18:
end for
|
2.2.3. Chaotic Fine Search (CFS)
The proposed CFS procedure aims to speed up the intensification process and refines the accuracy of the search. Indeed, suppose that the solution
X obtained at the end of
search processes is close to the global optimum
with precision
,
. That can be formulated as:
Then the challenge is how to go beyond the accuracy ?
One can observe that the distance can be interpreted as a parasitic signal of the solution, which is enough to filter in a suitable way to reach the global optimum, or it corresponds to the distance to which is the global optimum of its approximate solution. Thus, one solution is to conducts a search in a local area in which the radius adapts to the distance component by component.
However, in practice, the global optimum is not known a priori. To overcome this difficulty, as we know that, as the search process proceeds the resulting solution X is supposed to be close enough to the global optimum, one solution is to consider instead of the relation (
24) the difference between the current solution X and its decimals fractional parts of order
,
:
where
is the fractional of order
i.e., the closest point of X to the precision
formalised as:
(see
Figure 10).
Furthermore, we propose to add a stochastic component in the round process in order to perturb a potential local optima. Indeed, we consider the stochastic round
defined by:
where
is a stochastic perturbation operated on
X alternatively through The Tornado cycles. This way, the new formulation of the
error of
X is given by:
The structure of the chaotic fine search CFS is similar to the CLS local chaotic search. Indeed, it proceeds by levelling approach creating
levels, except the fact that the local area of level
is defined by its radius
based on the
error
and given by:
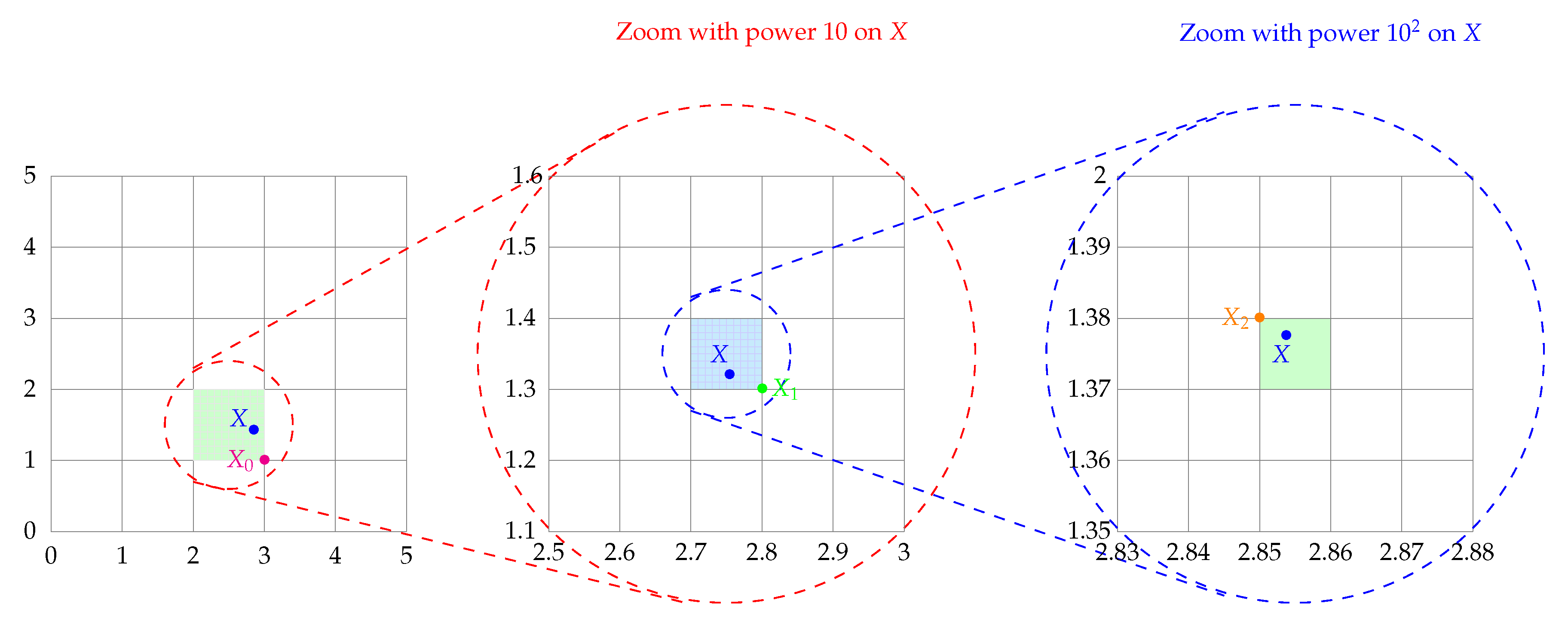
This way, the local area search in CFS is carried out in a narrow domain that allow a focus on the current solution adapted coordinate by coordinate unlike the uniform local search in CLS as illustrated in
Figure 11. The modified radius
is formulated as follows:
where
and
.
The design of the radius
allows to zoom at an exponential rate of decimal over the levels. Indeed, we have:
As a consequence, the CFS provides an ultra fast exploitation of the neighborhood of the current solution and allows in principle the refinement of the optimum with a good precision.
The Fine Chaotic Search (CFS) is described in Algorithm 4 and the Tornado algorithm is detailed in Algorithm 5:
| Algorithm 4 Chaotic Fine Search (CFS). |
- 1:
Input: - 2:
Output: : the best solution among local chaotic points - 3:
- 4:
- 5:
- 6:
for to do - 7:
Compute the error and then evaluate using Equations ( 27)−( 29) - 8:
Generate two symmetrical chaotic variables , according to ( 23) - 9:
for to 2 - 10:
Choose randomly p in and decompose using ( 19) - 11:
Generate symmetrical points according to ( 20) - 12:
for à - 13:
if then - 14:
- 15:
end if - 16:
end for - 17:
end for - 18:
end for
|
| Algorithm 5 Tornado Pseudo-Code. |
- 1:
Given: - 2:
Output: - 3:
- 4:
while do - 5:
- 6:
if then - 7:
- 8:
end if - 9:
- 10:
while do - 11:
- 12:
if do - 13:
- 14:
end if - 15:
- 16:
if do - 17:
- 18:
end if - 19:
- 20:
end while - 21:
- 22:
end while
|
4. Computational Experiments
The proposed algorithm X-Tornado is implemented on Matlab. The computing platform used consists of an Intel(R) Core(TM) i3 4005U CPU 1:70 GHz with 4 GB RAM.
4.1. Test Problems
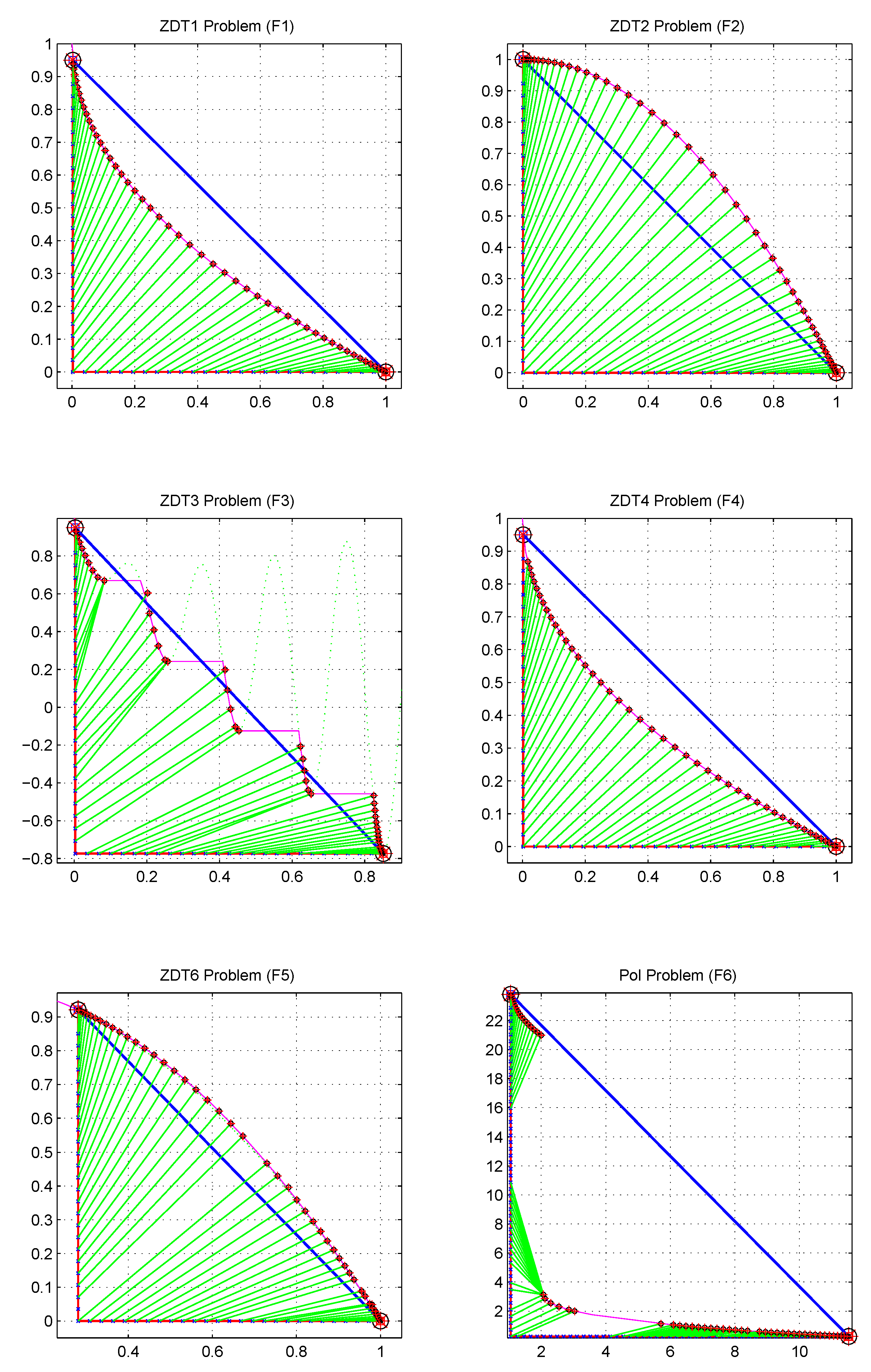
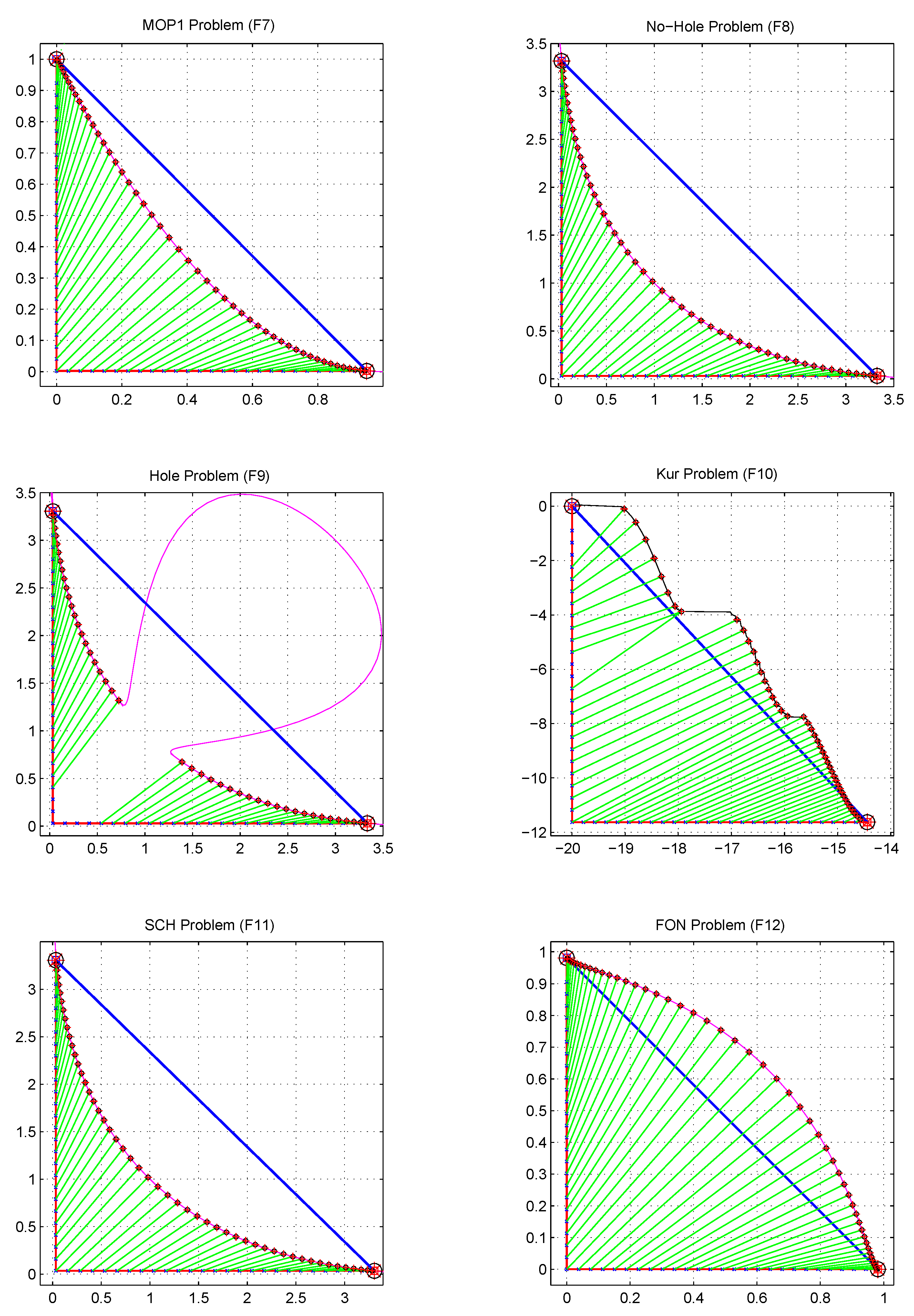
In order to evaluate the performance of the proposed X-Tornado algorithm, 14 test problems are selected from the literature. These functions will test the proposed algorithm’s performance in the different characteristics of the Pareto front: convexity, concavity, discreteness, non uniformity, and multimodality. For instance, the test problems KUR and ZDT3 have disconnected Pareto fronts; ZDT4 has too many local optimal Pareto solutions, whereas ZDT6 has non convex Pareto optimal front with low density of solutions near Pareto front. The test problems and their properties are shown in
Table 1.
4.2. Parameters Setting
In X-Tornado, the parameters setting were set as follows:
The number of CGS chaotic levels : .
The number of CLS chaotic levels : .
The number of CFS chaotic levels : .
The number of CLS-CFS per cycle : .
The number of subproblems resolved with the Tchebychev decomposition approach : .
4.3. Performances Measures
Due to the fact that the convergence to the Pareto optimal front and the maintenance of a diverse set of solutions are two different goals of the multi-objective optimization, two performance measures were adopted in this study: the generational distance () to evaluate the convergence, and the Spacing (S) to evaluate the diversity and cardinality.
The convergence metric
measure the extent of convergence to the true Pareto front. It is defined as:
where
N is the number of solutions found and
is the Euclidean distance between each solution and its nearest point in the true Pareto front. The lower value of GD, the better convergence of the Pareto front to the real one.
The Spacing metric
S indicates how the solutions of an obtained Pareto front are spaced with respect to each other. It is defined as:
4.4. Impact of the Tchebychev Scalarization Strategies
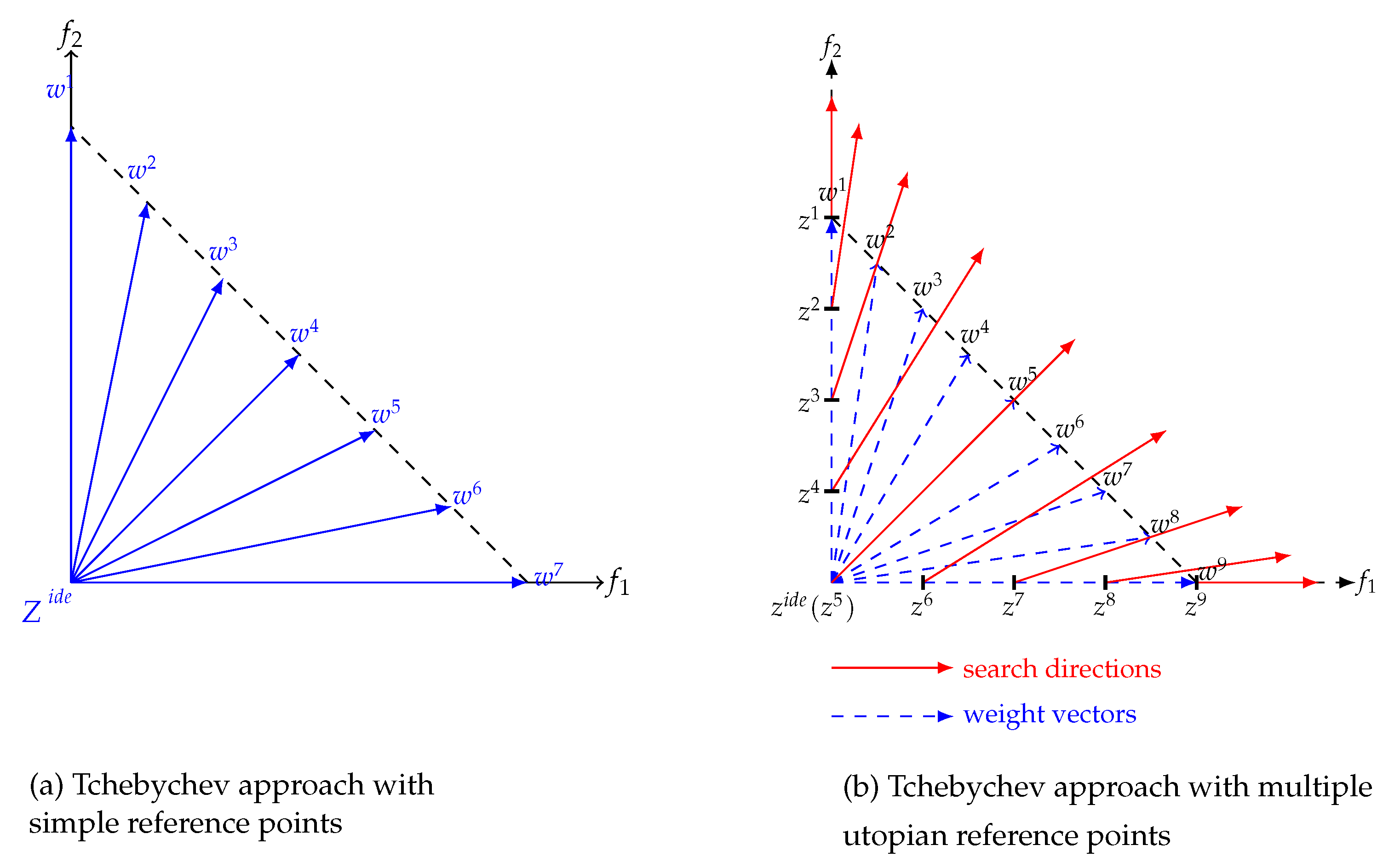
By adopting the three Tchebychev we have tested three X-Tornado variants as follows:
X-Tornado-TS: denotes X-Torando with Standard Tchebychev approach.
X-Tornado-TM: denotes X-Torando with Tchebychev variant involving multiple utopian reference points instead of just one reference point.
X-Tornado-ATS: denotes X-Torando with augmented Tchebychev approach.
The computational results in term of
,
S) for 300000 function evaluations are shown in
Table 2 and
Table 3 respectively, according to the three variants of X-Tornado.
The analysis of the results obtained for the 14 selected problems show that X-Tornado-TM achieves the best performance in term of the two considered metrics and S. Indeed, in term of convergence X-Tornado-TM wins the competition on 6 problems, X-Tornado-TS wins on 5 problems whereas X-Tornado-ATS wins on only 3 problems. In term of spacing metric, X-Tornado-TM releases clearly the best performance by winning the competition on whereas X-Tornado-TS and X-Tornado-ATS win both only on three problems.
Based on this performance analysis, X-Tornado-TM variant seems to be the most promising one and therefore, in the next section we will compare its performance against some state-of the-art evolutionary algorithms. Moreover, it will be designed as X-Tornado for sake of simplicity.
4.5. Comparison with Some State-Of The-Art Evolutionary Algorithms
In this section, we choose three well-known multiobjective evolutionary algorithms NSGA-II, PESA-II, and MOEA/D (MATLAB implementation obtained for the yarpiz library available at
www.yarpiz.com.). The Tchebychev function in MOEA/D was selected as the scalarizing function and the neighborhood size was specified as
of the population size. The population size in the three algorithms was set to 100, The size of the archive was set to 50 in PESA-II and MOEA/D.
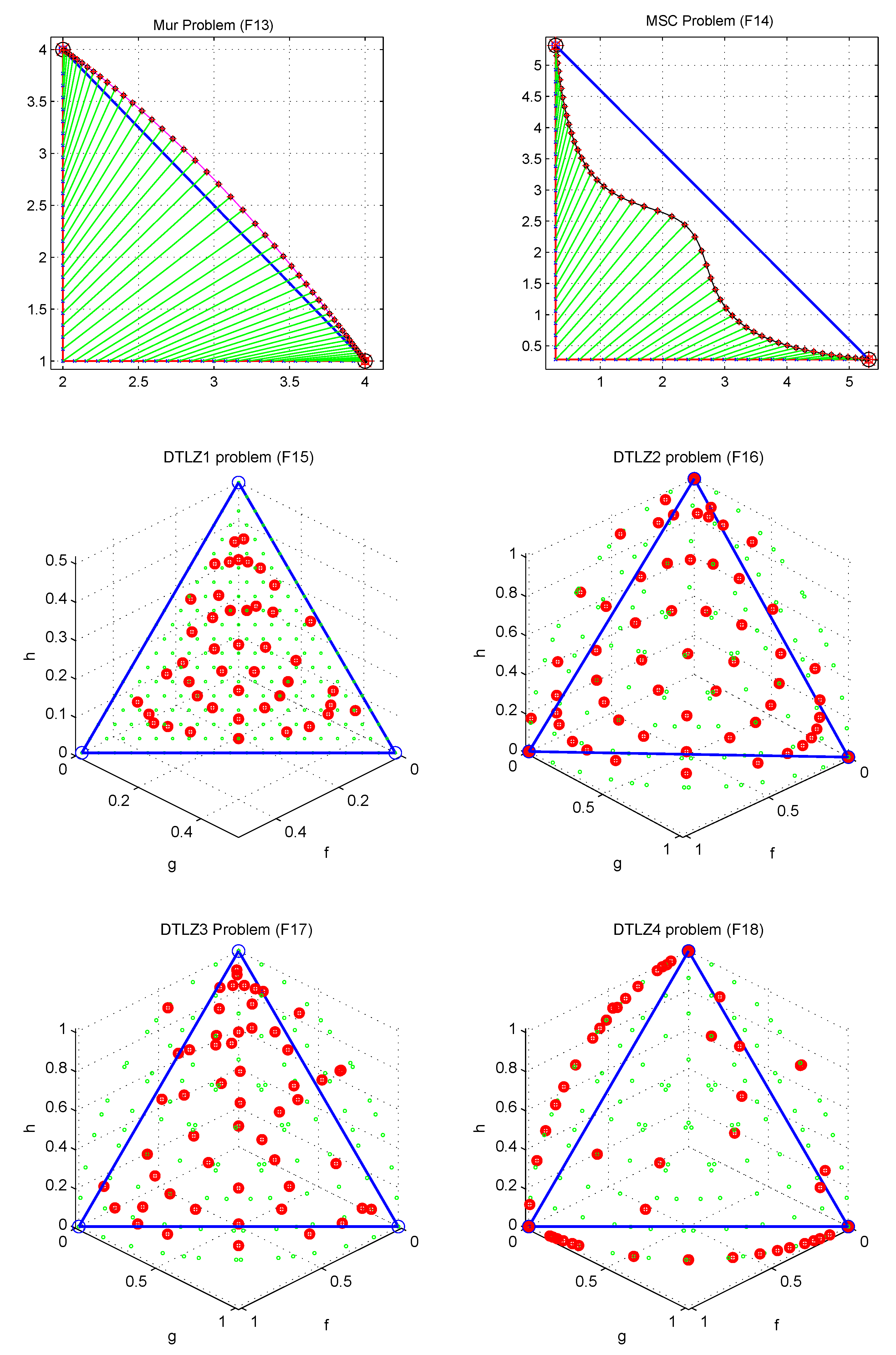
Besides the 14 bi-objective considered problems in the previous section, 4 additional 3d objective problems will be also tested, which are DTLZ1, DTLZ2, DTLZ3, DTLZ4. However, note that, as the TM decomposition is not suitable in the 3d cases, those 3d problems will be tested with X-Tornado-TS variant.
The computational results using the performance indicators
and
S for 300000 function evaluations are shown in
Table 4 and
Table 5 respectively, according to all four algorithms: NSGA-II, PESA-II, MOEA-D, and X-Tornado. The mean and variance of simulation results in 10 independent experiments are depicted for each algorithm. The mean of the metrics reveals the average evolutionary performance and represents the optimization results in comparison with other algorithms. The variance of the metrics indicates the consistency of an algorithm. The best performance is represented by bold fonts.
By analysing the obtained results in
Table 4, it is clear that the X-Tornado approach has the best performance in term of convergence to the front. Indeed the proposed X-Tornado obtains the lowest
metric value for twelve out of the 18 test problems and with small standard deviation in almost all problems. A low
metric value of an algorithm on a problem is significant for accuracy of the obtained Pareto front. That is to say, the proposed algorithm has a good accuracy and stability on the performance of these problems.
In
Table 5 X-Tornado outperforms all other algorithms on the mean of the spacing metric in almost all test problems except in ZDT3, KUR, MSC and DTLZ4.
The next
Table 6 and
Table 7 show the comparisons result in case of doubling the archive length used by the three meta heuristics involved in the comparison with our X-Tornado method. Indeed, as w can see, X-Tornado is still having slightly better performance among the compared methods. But, the most interesting thing that had motived this additional simulation is to demonstrate the superiority of our method over the classical approach adopting an archiving mechanism in term of Time execution. In fact, in this kind of metaheuristics, an update of the archive of non dominated points is carried out after each cycle of the algorithms. Therefore, if all the algorithms in comparison were adopting an archiving mechanism (which is often the case) the corresponding cost is usually not considered since it has no sensitive effect in comparison. However, in our case, dislike the methods in comparisons, X-Tornado don’t use an archiving mechanism, whereas on the other side doubling the archive has considerably increased the execution time as can be observed in
Table 8.
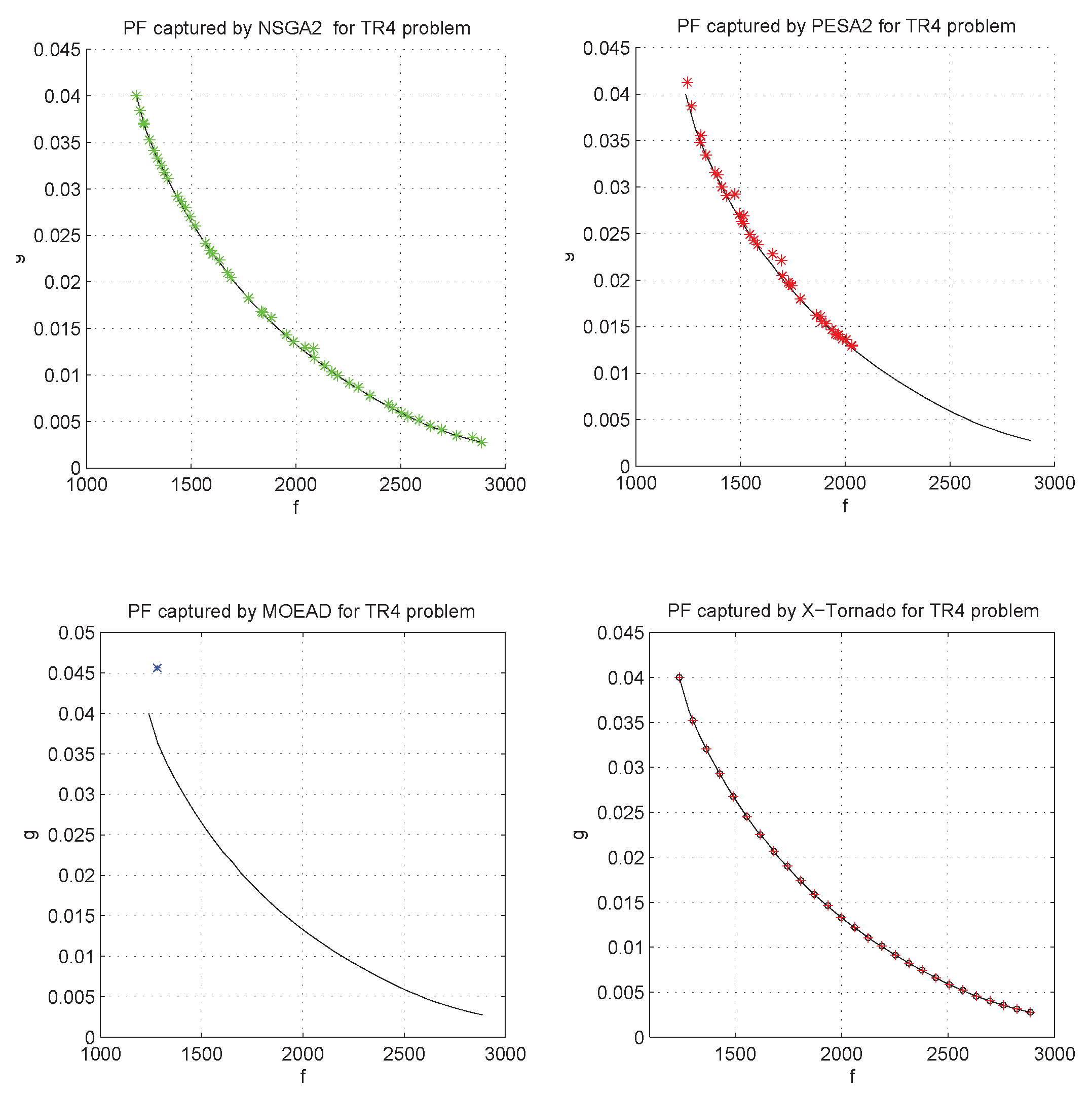
Moreover, the distribution of the non dominated points reflects automatically the regularity of the Tchebychev decomposition and unlike the three other algorithms in comparison, a filtering mechanism such as “crowding” is no longer required in our X-Tornado approach. The consequence of this important advantage is that unlike the other methods in comparison, the capture of the front by the X-Tornado method is more continuous and therefore more precise, as illustrated by the
Figure 13,
Figure 14 and
Figure 15. In addition, the X-Tornado method is much faster (at least 5 times less expensive in CPU time) compared to other methods as we can observe in
Table 9.
Application to Multi-Objective Structural Optimization Problem
In this section, we consider two applications: The first one is the four bar truss problem proposed by Stadler in [
28]. The goal is to find the optimal truss structure while simultaneously minimizing the total mass and static displacement at point C. These two criteria are in conflict since minimizing the mass of a structure tends to increase displacement. So the best solution is to find a trade off between the two criteria. For this, we consider two cost functions to minimize. the total volume (
(cm
))) and displacement (
(cm)). The four bar truss problem is shown in
Figure 16.
The second application is the two bar truss structure subjected to random Gaussian loading [
29]. The two bar problem is a bi-objective problem where the areas of the two bars are decision variables of the optimization. The left end of the bars is fixed while the other end is subjected to a mean plus a fluctuating load. Two objectives are considered for the optimization problem: the mean and the standard deviation of the vertical displacement.
Figure 17 illustrates the two bar problem and further technical details can be found in [
29].
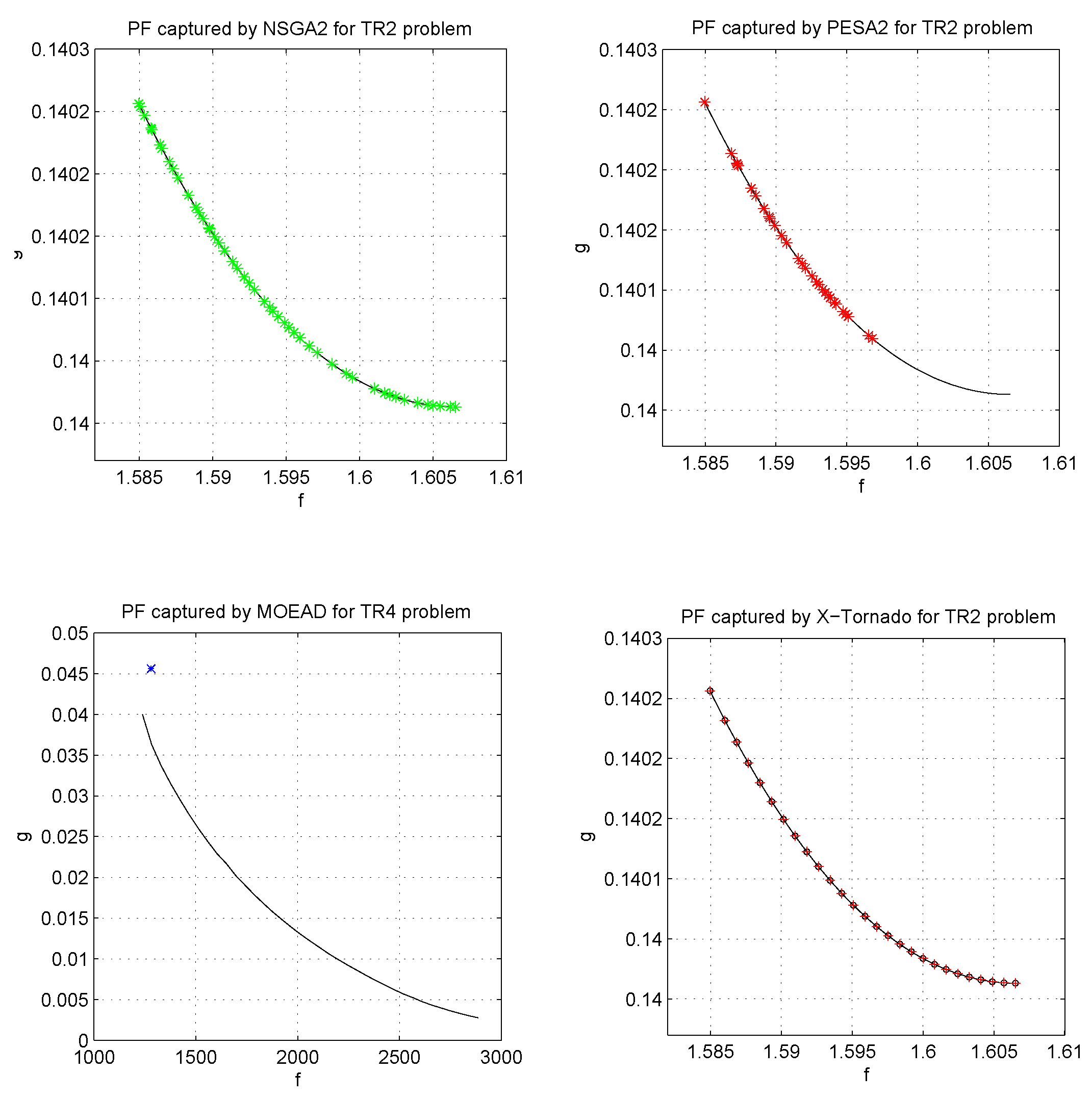
Table 10 show the comparison results for the four methods in comparisons in term of GD and Spacing metrics for 300,000 Fes. By analysing these results we observe that X-Tornado is performing as well as Nsga2 in term of convergence and spacing metrics and outperforms Pesa2 and MOEA/D for this two problems. Moreover, X-Tornado is much faster in comparison to the three algorithms.
In addition,
Figure 18 and
Figure 19 illustrate the advantages of X-Tornado PF in term of convergence and regularity over the other comparative algorithms.
5. Conclusions and Future Work
In this paper, we have successfully developed the X-Tornado algorithm which is based on Chaotic search.
The proposed X-Tornado algorithm was tested on various benchmark problems with different features and complexity levels. The results obtained amply demonstrate that the approach is efficient in converging to the true Pareto fronts and finding a diverse set of solutions along the Pareto front. Our approach largely outperforms some popular evolutionary algorithms such as MOEA/D, NSGA-II, and PESA-II in terms of the convergence, cardinality and diversity of the obtained Pareto fronts. The X-Tornado algorithm is characterized by its fast and accurate convergence, and parallel independent decomposition of the objective space.
We are investigating to develop new adaptive mechanism in order to extend X-Tornado to the field of challenging constrained problems involving multi-extremal problems [
30,
31].
A massively parallel implementation on heterogeneous architectures composed of multi-cores and GPUs is under development. It is obvious that the proposed algorithms have to be improved to tackle many objective optimization problems. We will also investigate the adaptation of the algorithms to large scale MOPs such as the hyperparameter optimization of deep neural networks.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
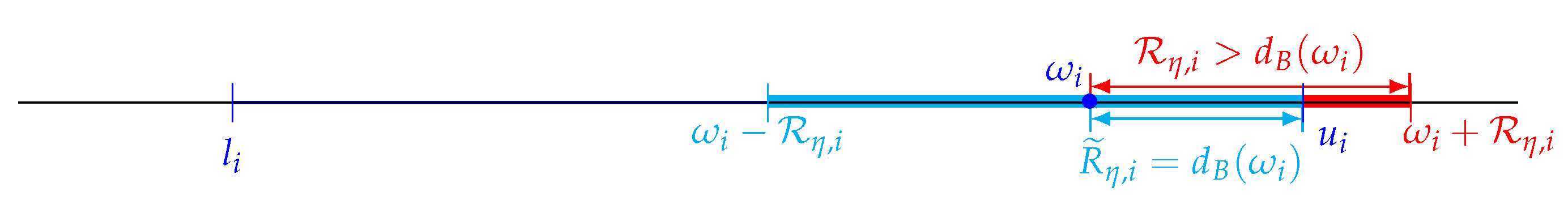{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
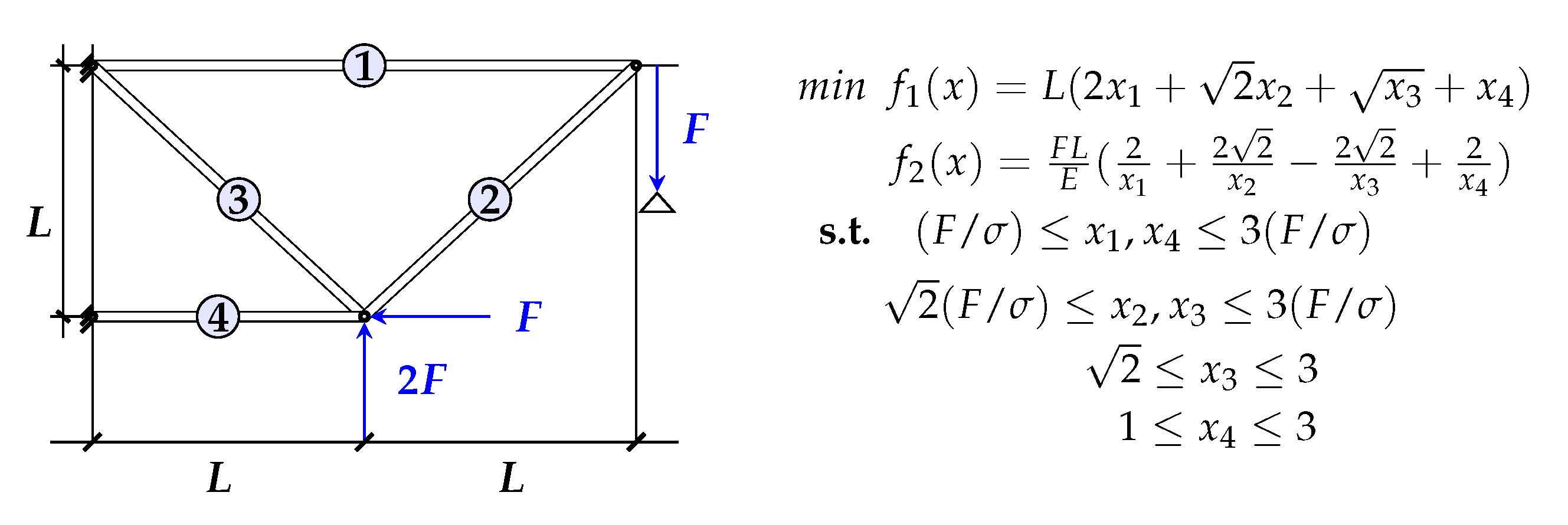{kind=link}
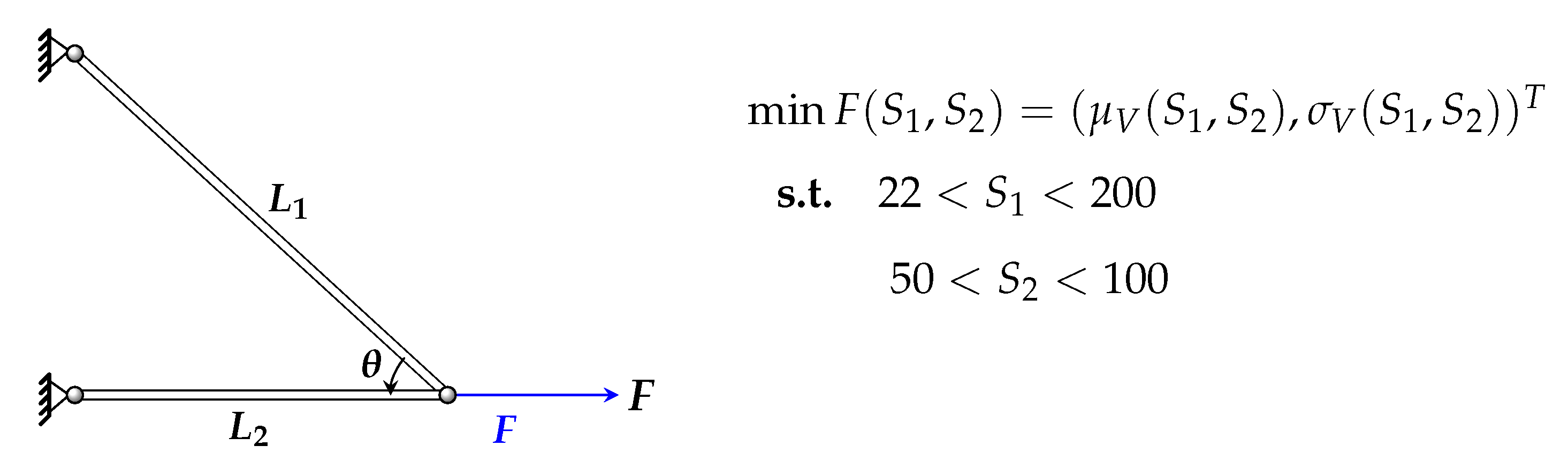{kind=link}
{kind=link}
{kind=link}