
Optimal CNN–Hopfield Network for Pattern Recognition Based on a Genetic Algorithm †


Abstract
:1. Introduction
- New hybrid CNN–RNN (recurrent neural network) architecture and approach and its optimization.
- Inference acceleration of a CNN-based architecture.
- Formulation of the optimization of the architecture as a knapsack problem.
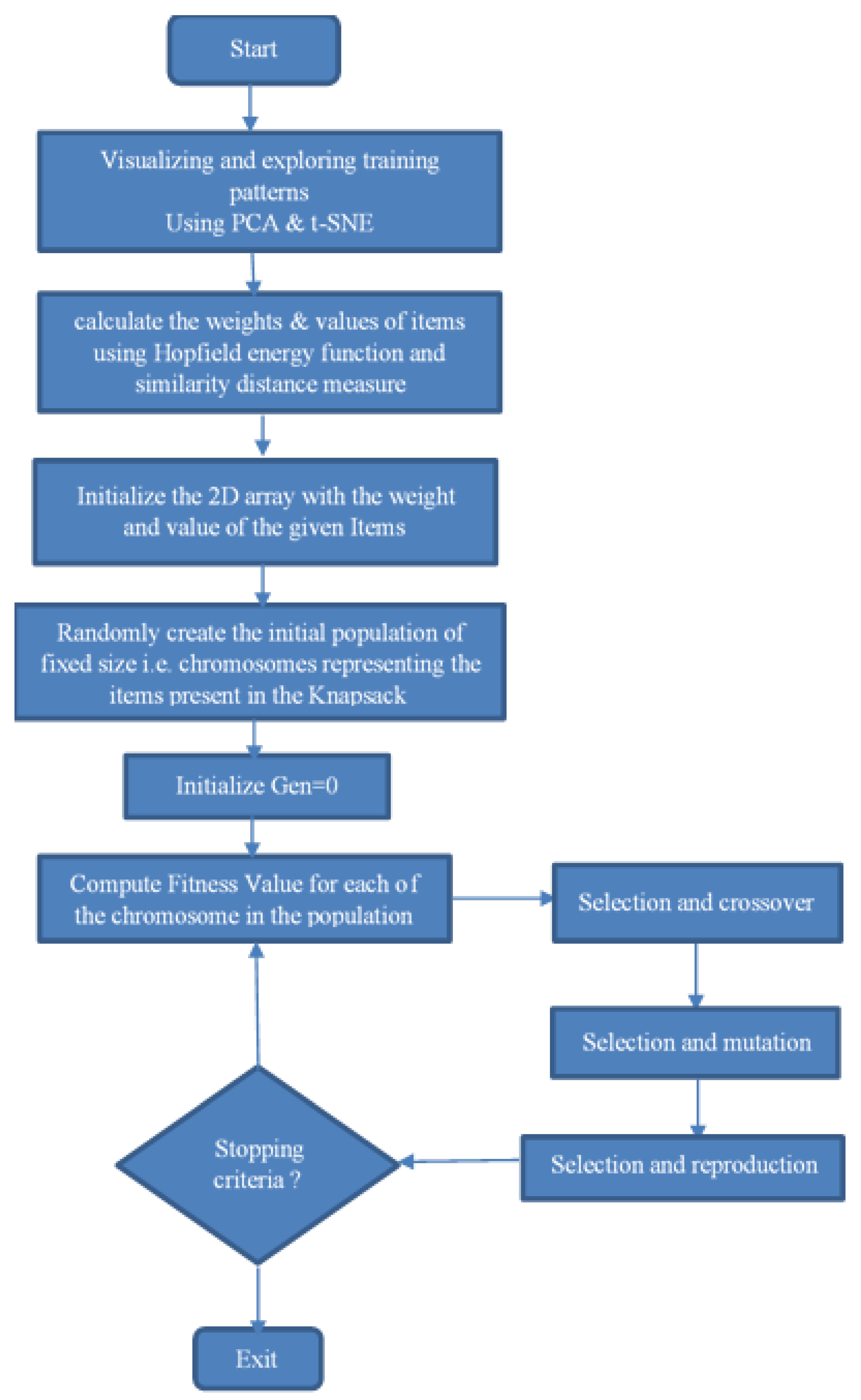
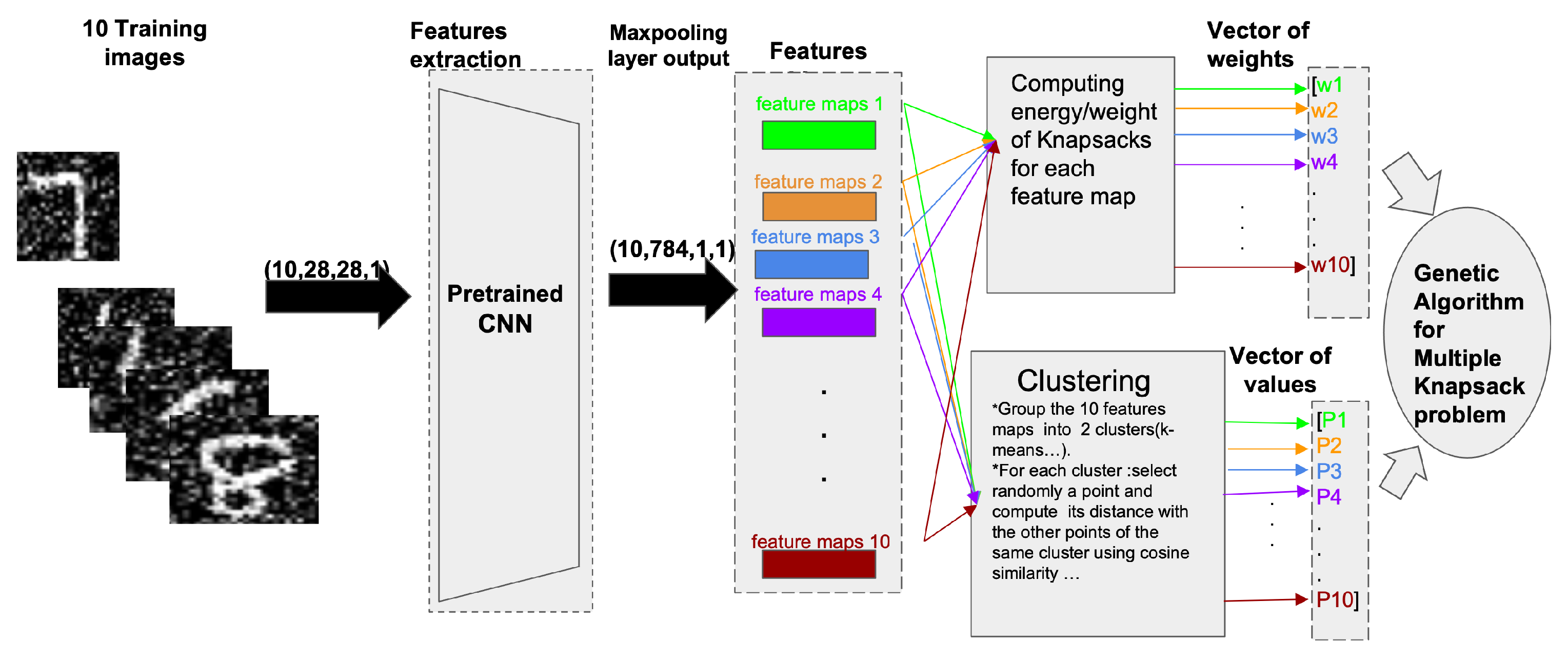
2. General Description of the Method
Feature Extraction
- (1)
- Extraction of the class-specific feature set: a set of all features of an image.
- (2)
- Averaging of the pixels’ gray level from the class-specific feature set.
- (3)
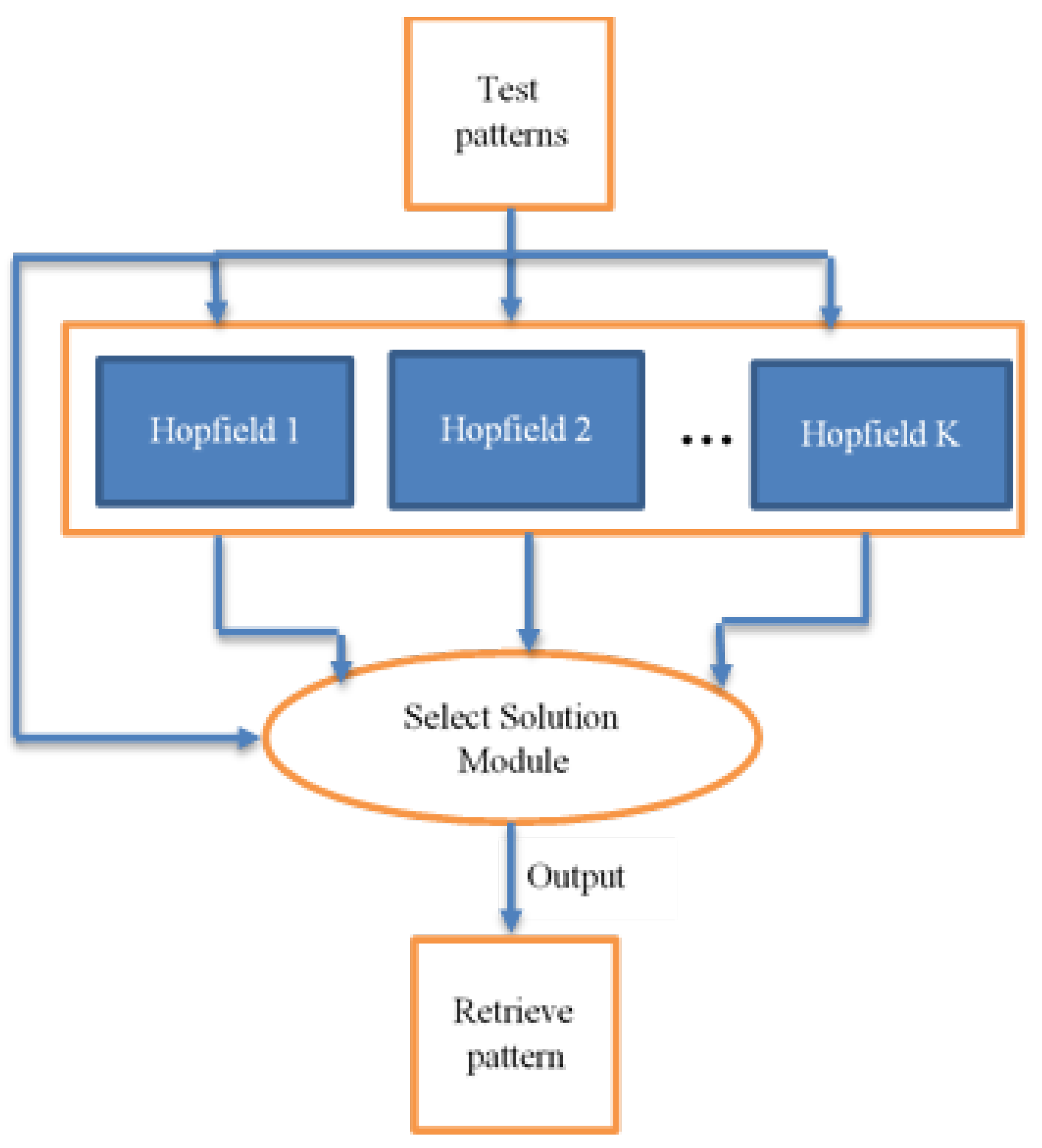
- Conversion of the training patterns into binary patterns and distribution over K parallel Hopfield networks.
3. Recall of the Hopfield Neural Network
4. Knapsack Model for Pattern Recognition
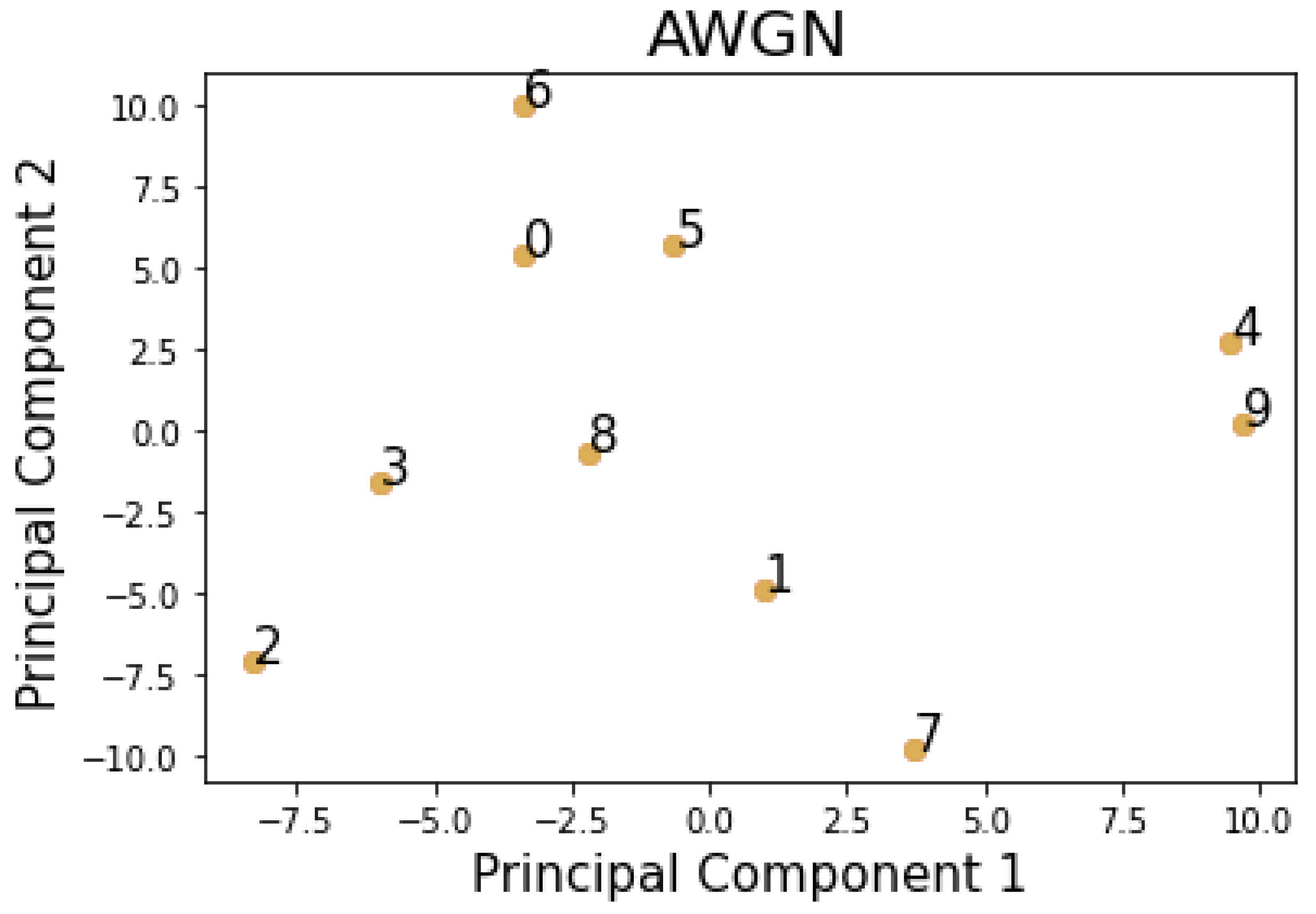
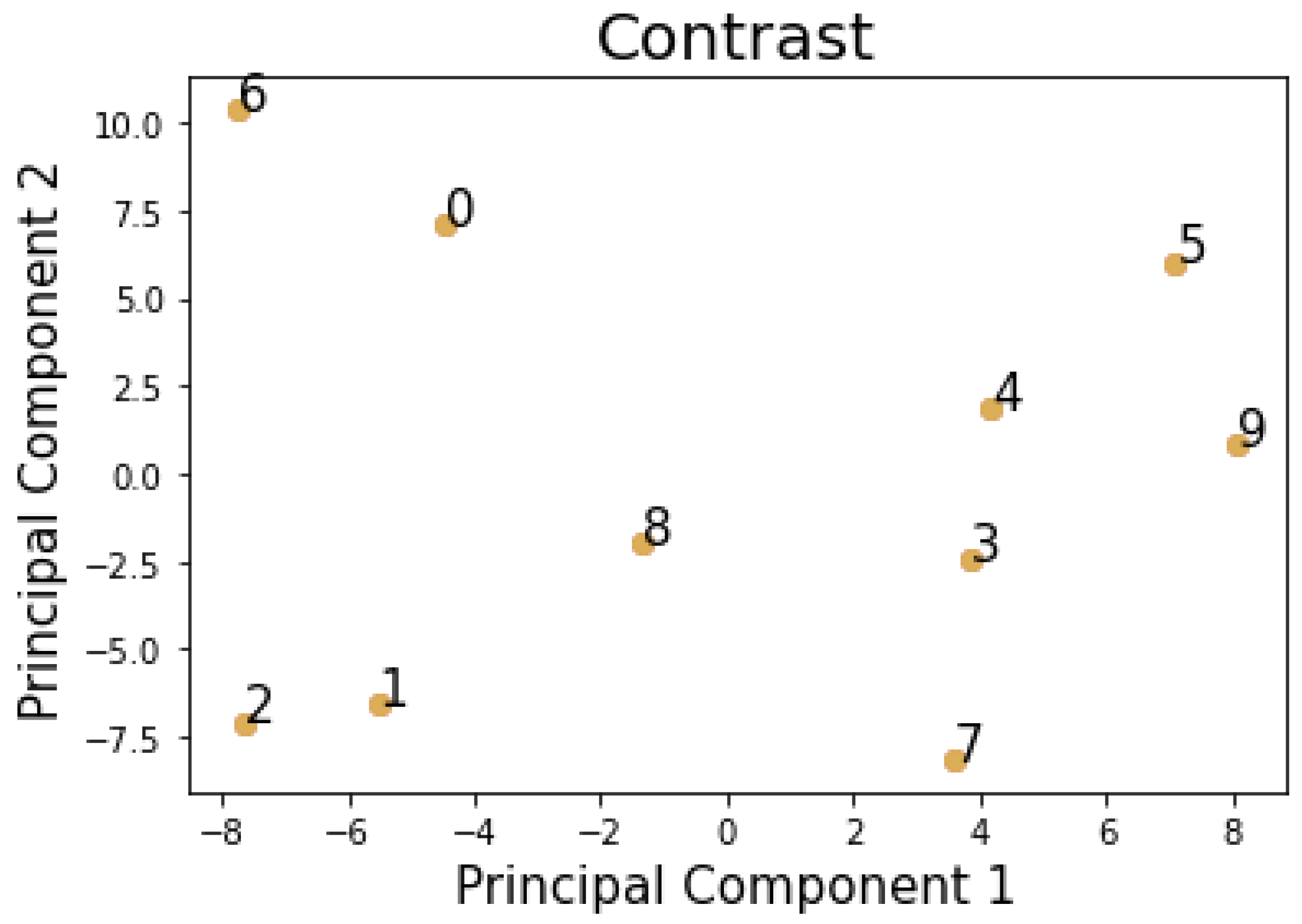
4.1. Similarity Measures
4.2. Setting of the Genetic Algorithm
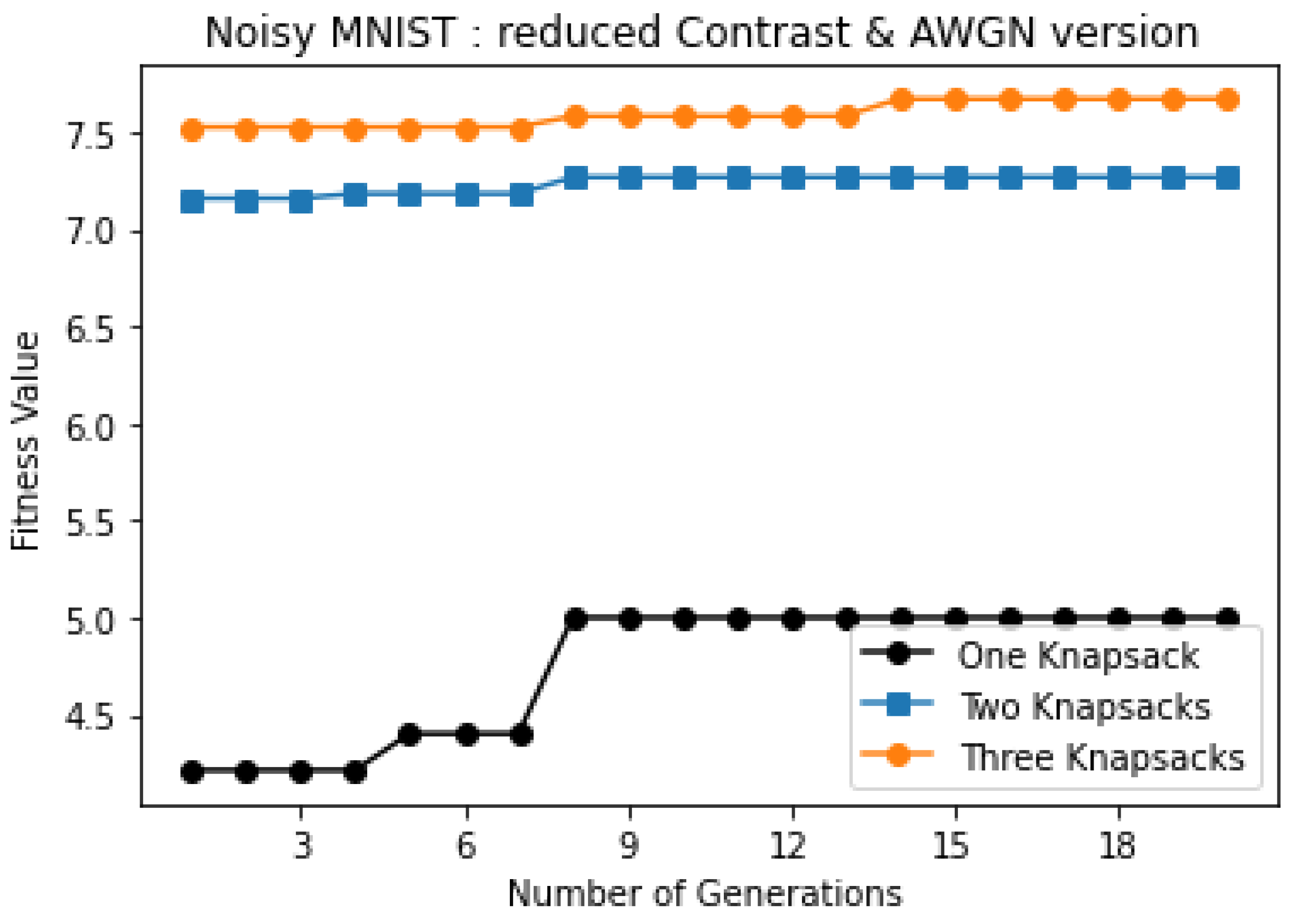
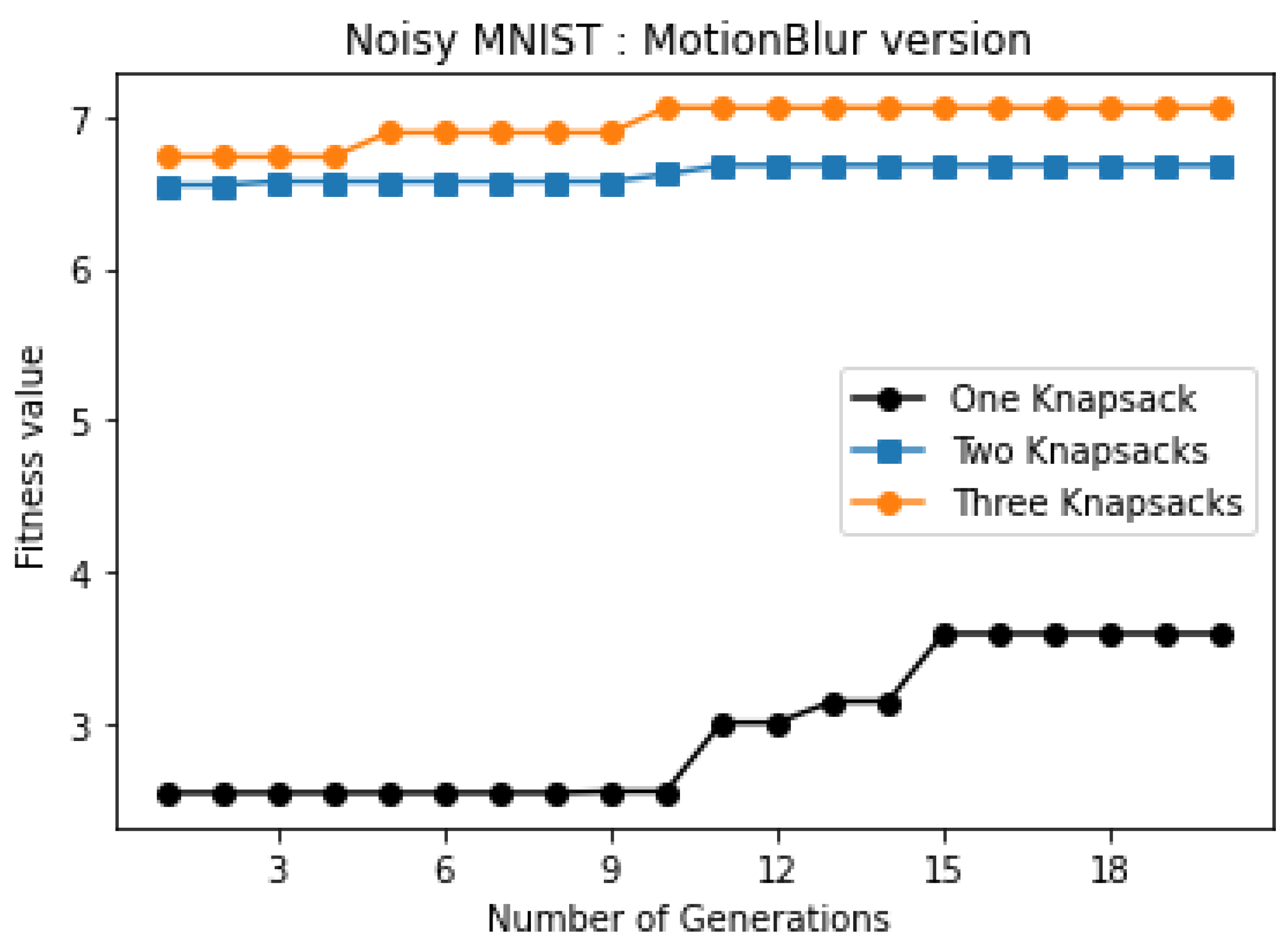
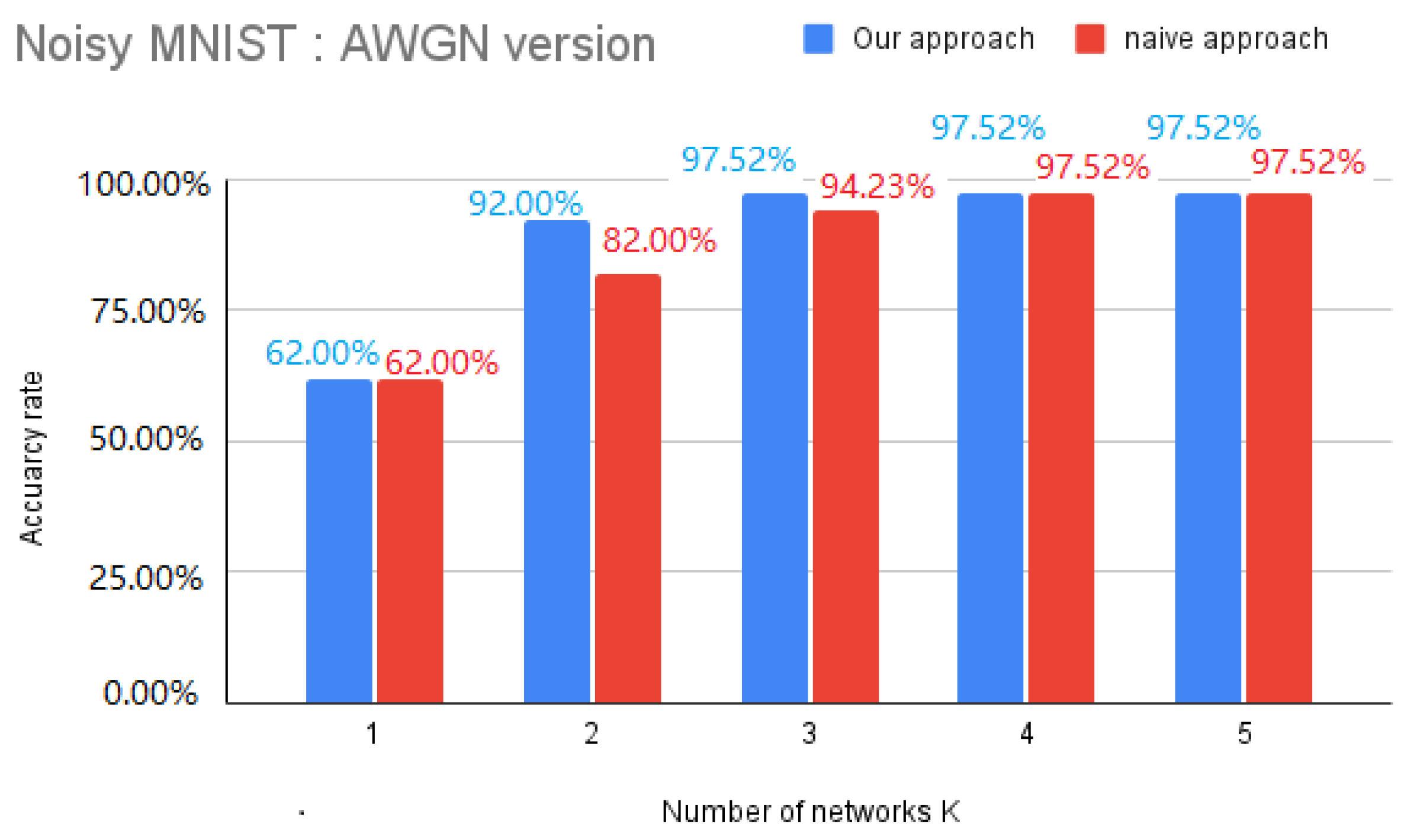
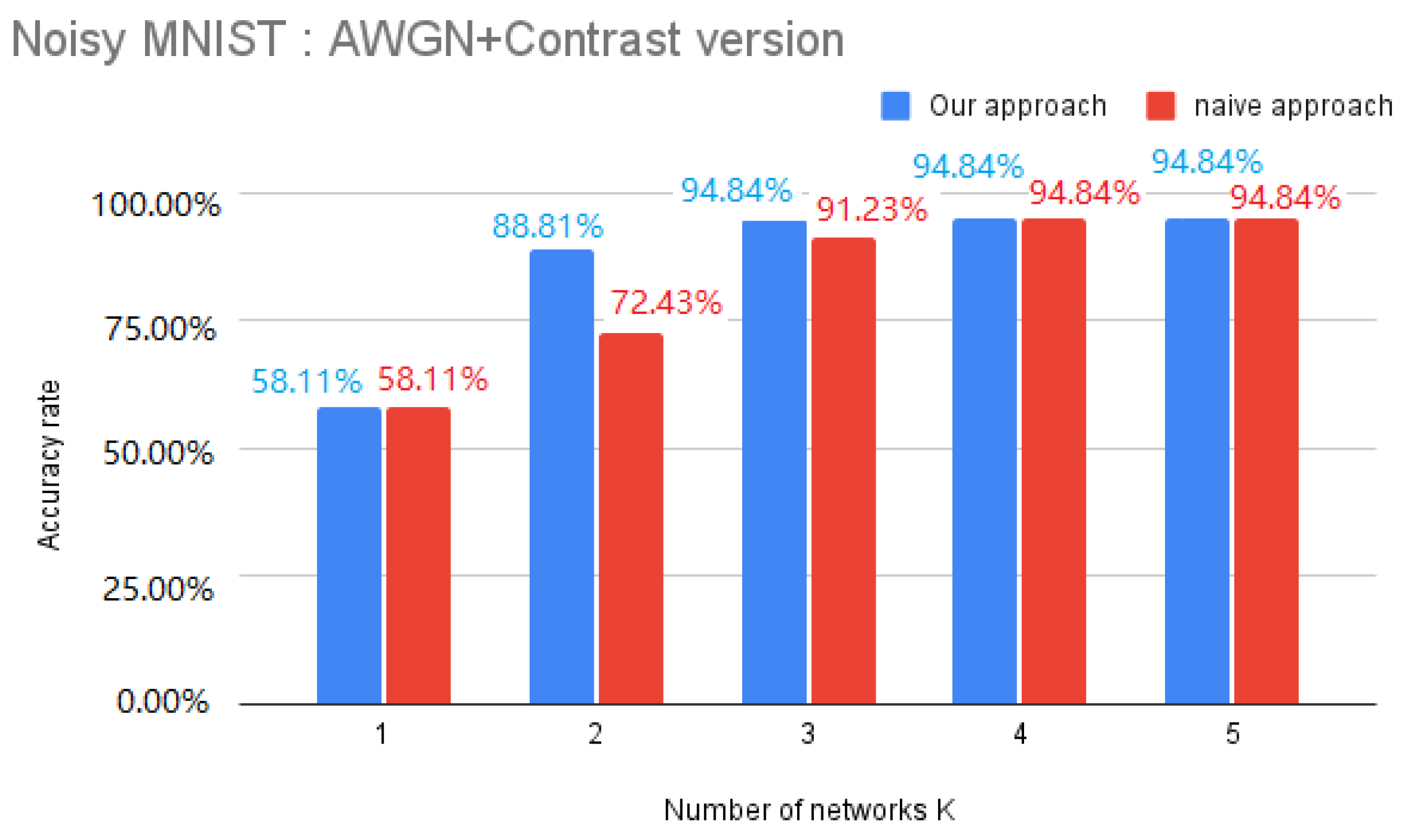
4.3. The Optimal Number of Knapsacks (K)
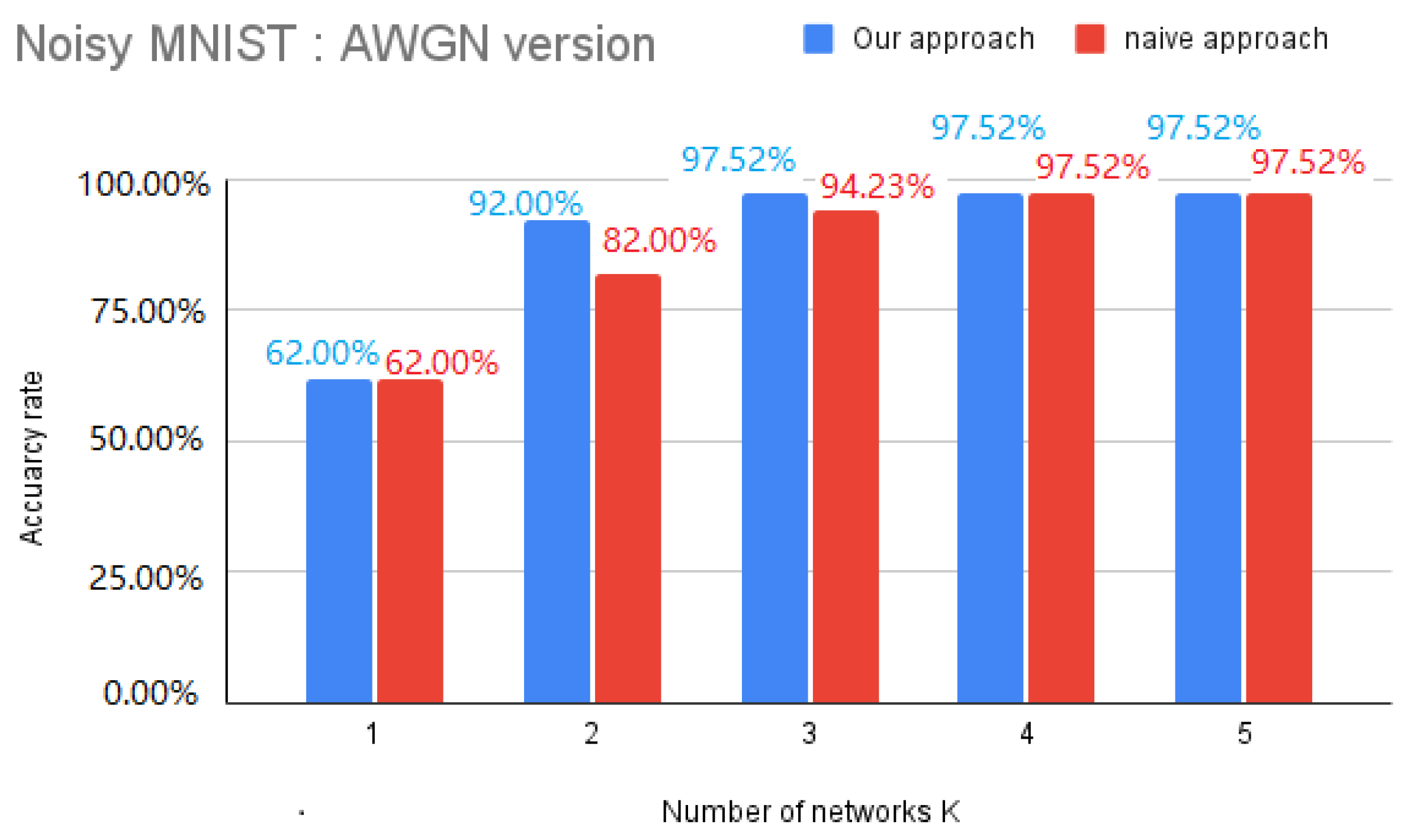
4.3.1. Naive Approach
4.3.2. Heuristic Approach
4.4. Pattern Distribution
4.5. Knapsack Selection
| Algorithm 1 Classification Algorithm |
|
5. Datasets and Benchmarks
6. Results and Discussion
6.1. Implementation Details
6.1.1. Pretrained CNN LeNet5-Like Model
- Maxpooling instead average pooling for reducing variance;
- Data augmentation to enhance the accuracy;
- A batch normalization layer after every set of layers (convolution + maxpooling and fully connected) to stabilize the network;
- Addition of dropout layers with a hyperparameter of 40% after the pooling layers;
- Addition of some connected layers;
- Addition of two more convolution layers with the same hyperparameters, and the number of filters in the convolutional layers was significantly increased from 6 to 32 in the first two layers and 16 to 100 in the next two layers to handle bias.
6.1.2. Defining Weights and Values of the Knapsack
6.1.3. Genetic Algorithm
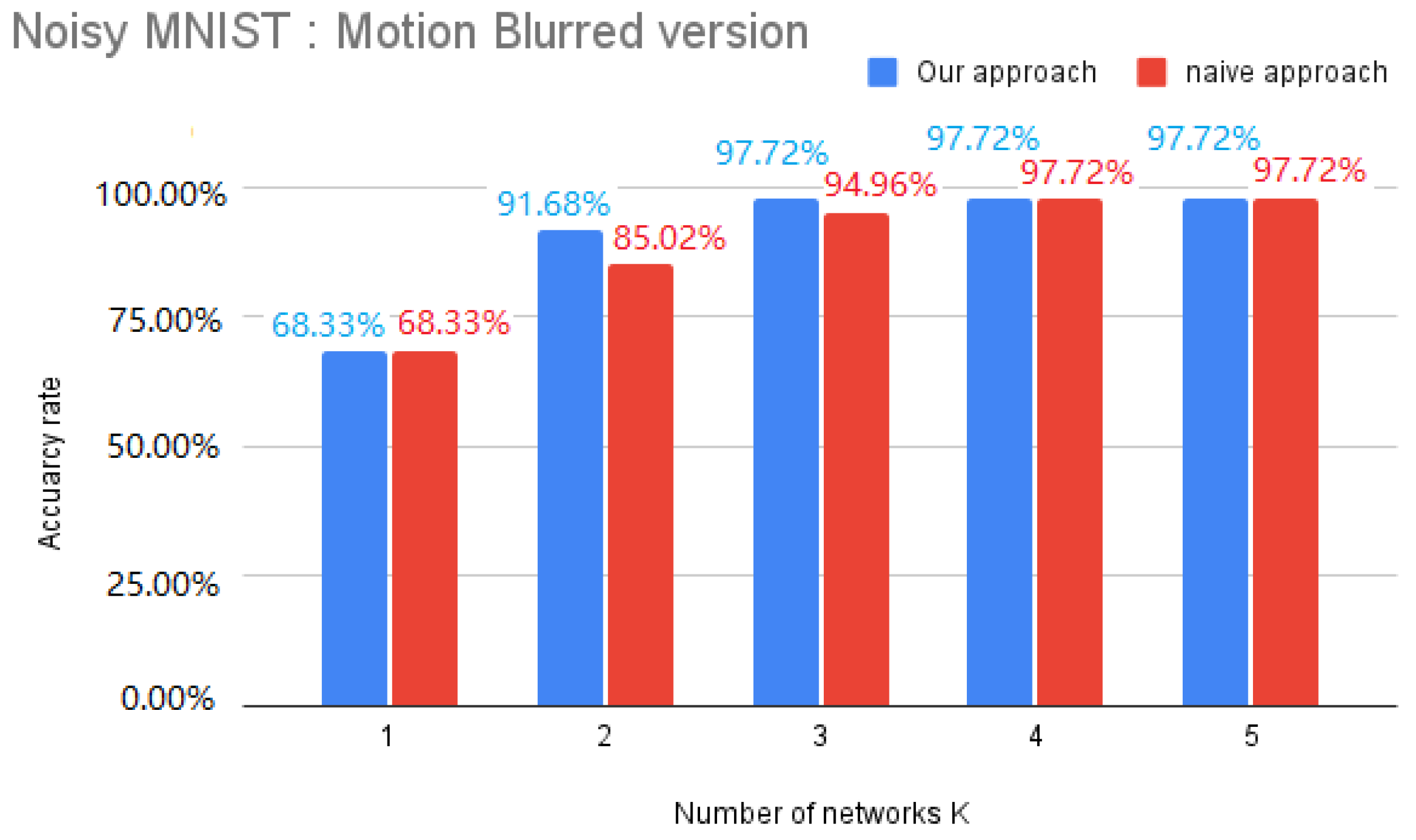
6.2. Evaluation of the Performance
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Simonyan, K.; Andrew, Z. Very deep convolutional networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Sultana, F.; Abu, S.; Paramartha, D. Advancements in image classification using convolutional neural network. In Proceedings of the 2018 IEEE Fourth International Conference on Research in Computational Intelligence and Communication Networks (ICRCICN, Kolkata, India, 22–23 November 2018. [Google Scholar]
- Sun, Y. Automatically designing CNN architectures using the genetic algorithm for image classification. IEEE Trans. Cybern. 2020, 50, 3840–3854. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Hongbin, P.; Da-Wen, S. Efficient extraction of deep image features using convolutional neural network (CNN) for applications in detecting and analysing complex food matrices. Trends Food Sci. Technol. 2021, 113, 193–204. [Google Scholar] [CrossRef]
- Zhou, Q. Multi-scale deep context convolutional neural networks for semantic segmentation. World Wide Web 2019, 22, 555–570. [Google Scholar] [CrossRef]
- Bakas, S. Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the BRATS challenge. arXiv 2018, arXiv:1811.02629. [Google Scholar]
- Heller, N. The kits19 challenge data: 300 kidney tumor cases with clinical context, ct semantic segmentations, and surgical outcomes. arXiv 2019, arXiv:1904.00445. [Google Scholar]
- Simpson, A.L. A large annotated medical image dataset for the development and evaluation of segmentation algorithms. arXiv 2019, arXiv:1902.09063. [Google Scholar]
- Qayyum, A. Medical image retrieval using deep convolutional neural network. Neurocomputing 2017, 266, 8–20. [Google Scholar] [CrossRef] [Green Version]
- Radenović, F.; Giorgos, T.; Ondřej, C. Fine-tuning CNN image retrieval with no human annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1655–1668. [Google Scholar] [CrossRef] [Green Version]
- Yu, W. Exploiting the complementary strengths of multi-layer CNN features for image retrieval. Neurocomputing 2017, 237, 235–241. [Google Scholar] [CrossRef]
- Dhillon, A.; Gyanendra, K.V. Convolutional neural network: A review of models, methodologies and applications to object detection. Prog. Artif. Intell. 2020, 9, 85–112. [Google Scholar] [CrossRef]
- Ren, S. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Du, J. Understanding of object detection based on CNN family and YOLO. In Journal of Physics: Conference Series, Volume 1004, 2nd International Conference on Machine Vision and Information Technology (CMVIT 2018), Hong Kong, China, 23–25 February 2018; IOP Publishing: Bristol, UK, 2018. [Google Scholar]
- Basha, S.H.S. Impact of fully connected layers on performance of convolutional neural networks for image classification. Neurocomputing 2020, 378, 112–119. [Google Scholar] [CrossRef] [Green Version]
- Xu, Q. Overfitting remedy by sparsifying regularization on fully-connected layers of CNNs. Neurocomputing 2019, 328, 69–74. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Ilya, S.; Geoffrey, E.H. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- LeCun, Y. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Supratik, M. Unsupervised learning using pretrained CNN and associative memory bank. In Proceedings of the 2018 IEEE International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Krotov, D.; John, J.H. Dense associative memory for pattern recognition. arXiv 2016, arXiv:1606.01164. [Google Scholar]
- Demircigil, M. On a model of associative memory with huge storage capacity. J. Stat. Phys. 2017, 168, 288–299. [Google Scholar] [CrossRef] [Green Version]
- Widrich, M. Modern hopfield networks and attention for immune repertoire classification. arXiv 2020, arXiv:2007.13505. [Google Scholar]
- Ramsauer, H. Hopfield networks is all you need. arXiv 2020, arXiv:2008.02217. [Google Scholar]
- Hopfield, J.J.; David, W.T. “Neural” computation of decisions in optimization problems. Biol. Cybern. 1985, 52, 141–152. [Google Scholar] [PubMed]
- Löwe, M. On the storage capacity of Hopfield models with correlated patterns. Ann. Appl. Probab. 1998, 8, 1216–1250. [Google Scholar] [CrossRef]
- Lowe, M. On the storage capacity of the Hopfield model with biased patterns. IEEE Trans. Inf. Theory 1999, 45, 314–318. [Google Scholar] [CrossRef] [Green Version]
- Matsuda, S. Optimal Hopfield network for combinatorial optimization with linear cost function. IEEE Trans. Neural Netw. 1998, 9, 1319–1330. [Google Scholar] [CrossRef]
- Wen, U.-P.; Kuen-Ming, L.; Hsu-Shih, S. A review of Hopfield neural networks for solving mathematical programming problems. Eur. J. Oper. Res. 2009, 198, 675–687. [Google Scholar] [CrossRef]
- Belyaev, M.A.; Velichko, A.A. Classification of handwritten digits using the Hopfield network. In IOP Conference Series: Materials Science and Engineering; Information Technologies, Reliability and Data Protection in Automation Systems; IOP Publishing: Bristol, UK, 2020; Volume 862, pp. 1–10. [Google Scholar]
- Li, C. A generalized Hopfield network for nonsmooth constrained convex optimization: Lie derivative approach. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 308–321. [Google Scholar] [CrossRef]
- Crisanti, A.; Daniel, J.A.; Hanoch, G. Saturation level of the Hopfield model for neural network. EPL (Europhys. Lett.) 1986, 2, 337. [Google Scholar] [CrossRef]
- Hertz, J. Introduction to the theory of neural computation. Phys. Today 1991, 44, 70. [Google Scholar] [CrossRef] [Green Version]
- Li, J. Hopfield neural network approach for supervised nonlinear spectral unmixing. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1002–1006. [Google Scholar] [CrossRef]
- Song, Y. System parameter identification experiment based on Hopfield neural network for self balancing vehicle. In Proceedings of the 36th IEEE Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017; pp. 6887–6890. [Google Scholar]
- Chen, S. A Novel Blind Detection Algorithm Based on Adjustable Parameters Activation Function Hopfield Neural Network. J. Inf. Hiding Multim. Signal Process. 2017, 8, 670–675. [Google Scholar]
- Zhang, Y. Blind Signal Detection Using Complex Transiently Chaotic Hopfield Neural Network. J. Inf. Hiding Multim. Signal Process. 2018, 9, 523–530. [Google Scholar]
- McEliece, R.; Posner, E.; Rodemich, E.; Venkatesh, S. The capacity of the Hopfield associative memory. IEEE Trans. Inf. Theory 1987, 33, 461–482. [Google Scholar] [CrossRef] [Green Version]
- Torres, J.J.; Lovorka, P.; Hilbert, J.K. Storage capacity of attractor neural networks with depressing synapses. Phys. Rev. E 2002, 66, 061910. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abu-Mostafa, Y.; St Jacques, J. Information capacity of the Hopfield model. IEEE Trans. Inf. Theory 1985, 31, 461–464. [Google Scholar] [CrossRef] [Green Version]
- Krotov, D.; John, H. Dense associative memory is robust to adversarial inputs. Neural Comput. 2018, 30, 3151–3167. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dudziński, K.; Stanisław, W. Exact methods for the knapsack problem and its generalizations. Eur. J. Oper. Res. 1987, 28, 3–21. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Geoffrey, H. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417. [Google Scholar] [CrossRef]
- Irani, J.; Nitin, P.; Madhura, P. Clustering techniques and the similarity measures used in clustering: A survey. Int. J. Comput. Appl. 2016, 134, 9–14. [Google Scholar] [CrossRef]
- E-G Talbi, Metaheuristics: From Design to Implementation; John Wiley & Sons: Hoboken, NJ, USA, 2009.
- Singh, R.P. Solving 0–1 knapsack problem using genetic algorithms. In Proceedings of the 2011 IEEE 3rd International Conference on Communication Software and Networks, Xi’an, China, 27–29 May 2011; pp. 591–595. [Google Scholar]
- Ho, Y.-C.; David, L.P. Simple explanation of the no-free-lunch theorem and its implications. J. Optim. Theory Appl. 2002, 115, 549–570. [Google Scholar] [CrossRef]
- Chu, P.C.; John, E.B. A genetic algorithm for the multidimensional knapsack problem. J. Heuristics 1998, 4, 63–86. [Google Scholar] [CrossRef]
- Saraç, T.; Aydin, S.; Aydin, S. A genetic algorithm for the quadratic multiple knapsack problem. In International Symposium on Brain, Vision, and Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Khuri, S.; Thomas, B.; Jörg, H. The zero/one multiple knapsack problem and genetic algorithms. In Proceedings of the 1994 ACM Symposium on Applied Computing, Phoenix, AZ, USA, 6–8 March 1994; pp. 188–193. [Google Scholar]
- Keddous, F.; Nguyen, H.-N.; Nakib, A. Characters Recognition based on CNN-RNN architecture and Metaheuristic. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Portland, OR, USA, 17–21 June 2021; pp. 500–507. [Google Scholar] [CrossRef]
- Amit, D.J.; Daniel, J.A. Modeling Brain Function: The World of Attractor Neural Networks; Cambridge University Press: Cambridge, UK, 1992. [Google Scholar]
- Bookstein, A.; Vladimir, A.K.; Timo, R. Generalized hamming distance. Inf. Retr. 2002, 5, 353–375. [Google Scholar] [CrossRef]
- Karki, M. Pixel-level reconstruction and classification for noisy handwritten bangla characters. In Proceedings of the 16th IEEE International Conference on Frontiers in Handwriting Recognition (ICFHR), Niagara Falls, NY, USA, 5–8 August 2018; pp. 511–516. [Google Scholar]
- Blank, J.; Kalyanmoy, D. Pymoo: Multi-objective optimization in python. IEEE Access 2020, 8, 89497–89509. [Google Scholar] [CrossRef]
- Liu, Q.; Edward, C.; Supratik, M. Pcgan-char: Progressively trained classifier generative adversarial networks for classification of noisy handwritten bangla characters. In Digital Libraries at the Crossroads of Digital Information for the Future—21st International Conference on Asia-Pacific Digital Libraries, ICADL 2019, KualaLumpur, Malaysia, 4–7 November 2019; Springer: Cham, Switzerland, 2019; pp. 3–15. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Weights | |
|---|---|
| Contrast | 2764268, 3030404, 3083368, 3496748, 3519312, |
| 3528504, 2773188, 3214824, 3508152, 4099424 | |
| AWG | 3336168, 3425580, 3184744, 3424400, 3675664, |
| 3653880, 3135436, 3355700, 3730228, 4031064 | |
| MotionBlur | 3126420, 3498624, 3133432, 3450532, 3199344, |
| 3243000, 3072960, 3299396, 3441172, 3760432 |
| Values | |
|---|---|
| Contrast | [1,0.403,1,0.605,1,1,0.491,1,0.449,0.722] |
| AWGN | [1,1,0.45,1,0.649,0.406,0.437,0.365,0.384,1] |
| MotionBlur | [1,1,0.38,1,0.442,0.588,0.52,1,0.552,0.578] |
| Parameters | Values |
|---|---|
| Dimension of the problem (N) | K |
| Number of runs | 20 |
| Number of generations | 20 |
| Population size (POP) | 100 |
| Max number of generations (ITER) | 100 |
| Mutation rate (MUT) | 0.1 |
| Crossover rate (CR) | 0.9 |
| Contrast | AWGN | MOTION | ||||
|---|---|---|---|---|---|---|
| Max. Fit. Found | Items Chosen | Max. Fit. Found | Items Chosen | Max. Fit. Found | Items Chosen | |
| One knapsack | 5 | 1,3,5,6,8 | 4 | 1,2,4,10 | 3.588 | 1,4,6,8 |
| Two knapsacks | 7.267 | 1,5,9,10 3,4,6,7,8 | 5.942 | 1,2,3,4 5,6,7,10 | 6.680 | 5,6,7,8,10 1,2,4,9 |
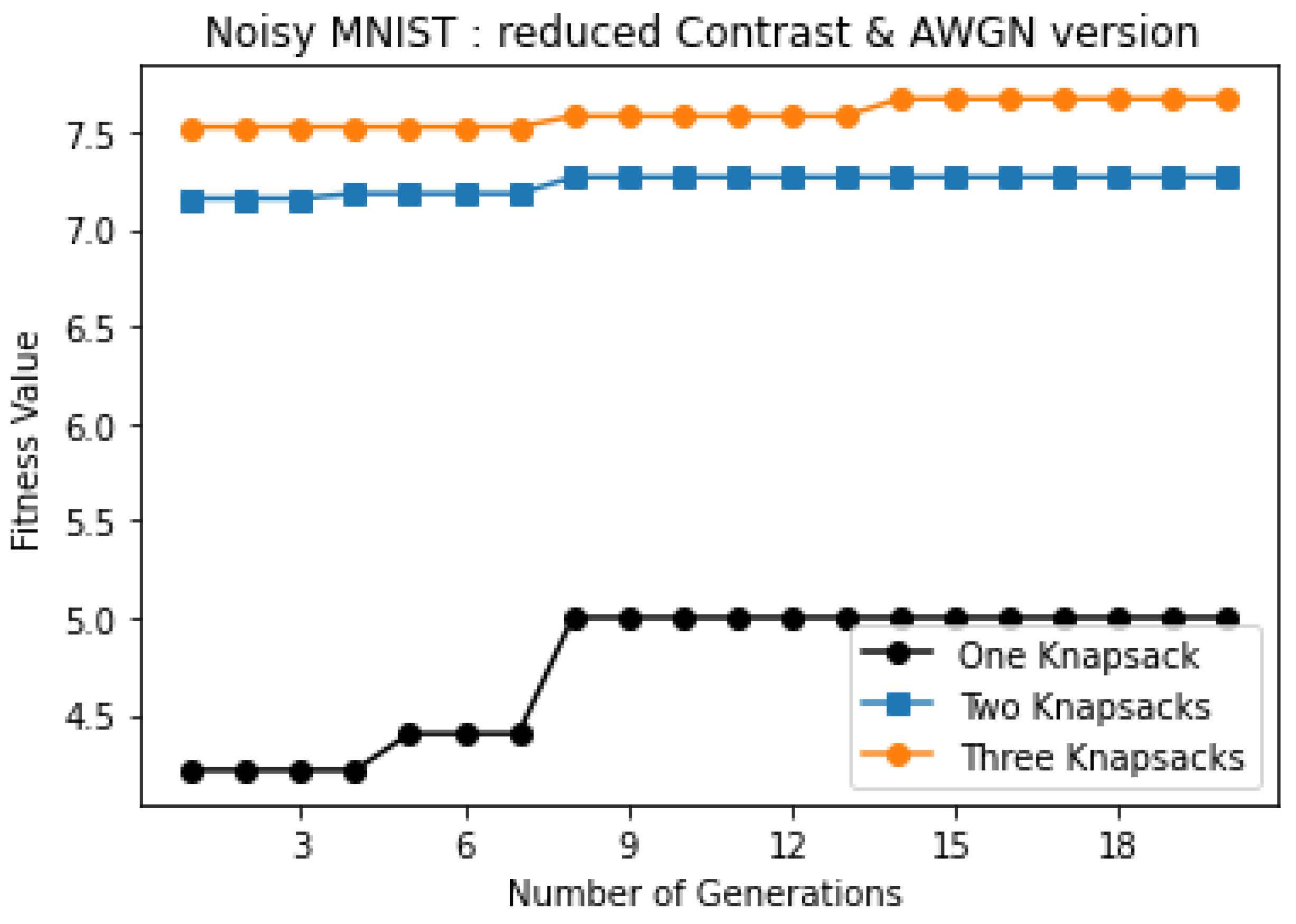
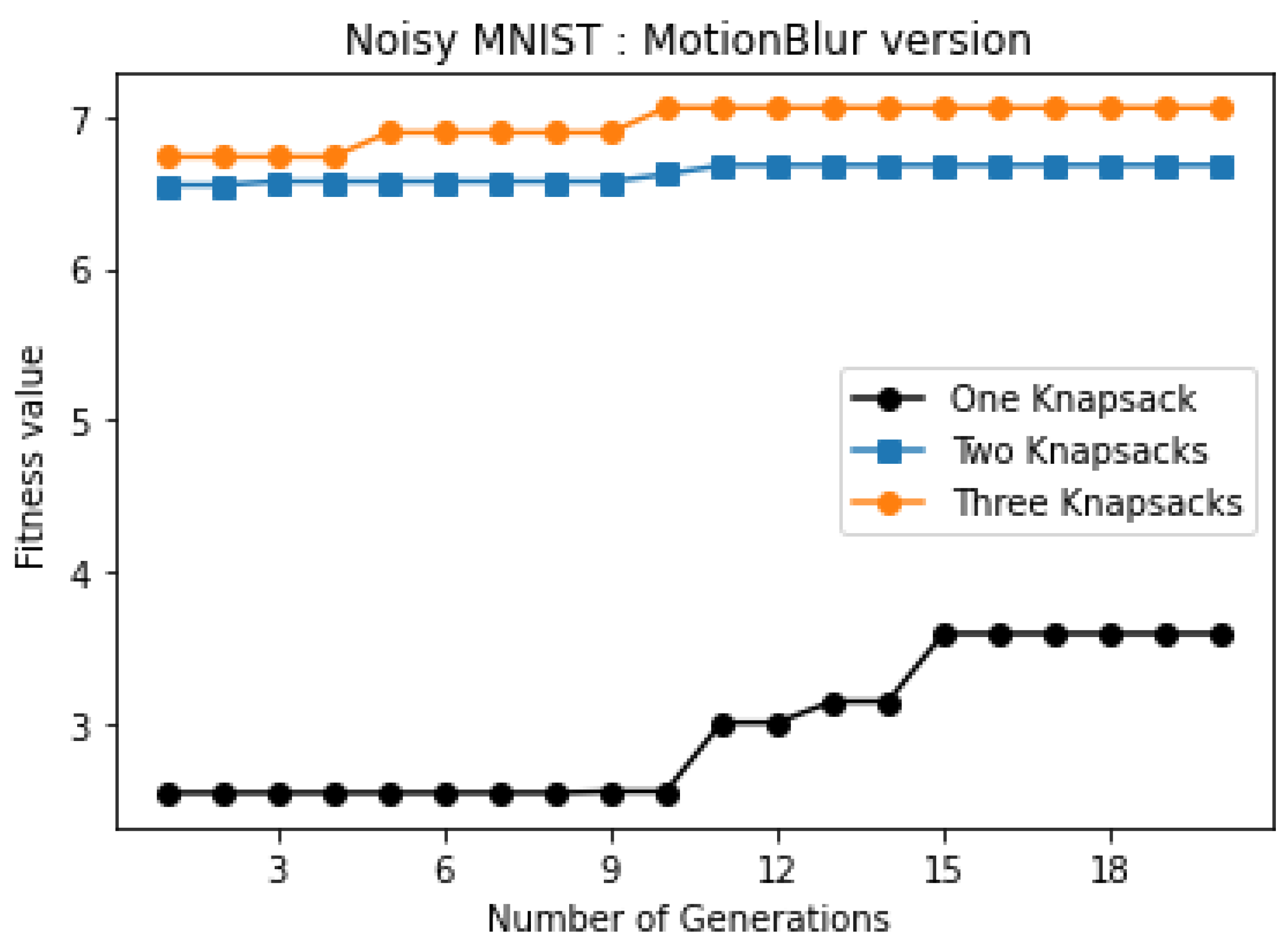
| Three knapsacks | 7.669 | 1,2,3,4,5 6,7,8,9 10 | 6.691 | 1,2,3,4 5,6,7,8 9,10 | 7.06 | 1,2,3,4 5,6,7,8 9,10 |
| Model | # of Parameters | Accuracy AWGN | Accuracy Motion | Accuracy Contrast |
|---|---|---|---|---|
| Lenet5-Like (with FC Layers) | 324,858 | 97.12% | 96.50% | 93.82 % |
| Our approach (parallel networks) | 124,344 | 97.52% | 97.72% | 94.84% |
| Models | AWGN | Motion | Contrast |
|---|---|---|---|
| Lenet | 0.8368 | 0.7228 | 0.9427 |
| Our approach | 0.7954 | 0.7020 | 0.8632 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Keddous, F.E.; Nakib, A. Optimal CNN–Hopfield Network for Pattern Recognition Based on a Genetic Algorithm. Algorithms 2022, 15, 11. https://doi.org/10.3390/a15010011
Keddous FE, Nakib A. Optimal CNN–Hopfield Network for Pattern Recognition Based on a Genetic Algorithm. Algorithms. 2022; 15(1):11. https://doi.org/10.3390/a15010011
Chicago/Turabian StyleKeddous, Fekhr Eddine, and Amir Nakib. 2022. "Optimal CNN–Hopfield Network for Pattern Recognition Based on a Genetic Algorithm" Algorithms 15, no. 1: 11. https://doi.org/10.3390/a15010011
APA StyleKeddous, F. E., & Nakib, A. (2022). Optimal CNN–Hopfield Network for Pattern Recognition Based on a Genetic Algorithm. Algorithms, 15(1), 11. https://doi.org/10.3390/a15010011