1. Introduction
Fund of funds (FOF) has become a hot topic during the past several years. As a mutual fund scheme, FOF uses other funds as investment targets and achieve the purpose of indirectly holding securities such as stocks and bonds [
1]. The first target of FOF construction is to obtain optimal portfolio among different funds based on the tradeoff between return and risk. To meet this goal, one of the main research activities for the past few years has been FOF modeling. It is worth mentioning that many existing FOF optimization models are based on the Mean-Variance (MV) framework. In 1952, Markowitz introduced the seminal work, the MV model [
2], which is regarded as the fundamental finding of modern portfolio theory (MPT). Since then, it has become the most essential theory to study the FOF asset allocation problem. Despite huge attention, the MV model still has some obvious shortcomings. One drawback which many studies emphasize is that the optimal portfolio can be extremely sensitive to input parameters [
3,
4]. Another drawback of the MV model is that this approach sometimes provides over-concentrated portfolios, which would probably cause huge losses if a financial crisis were to happen. Moreover, the MV model ignores the subjective views of investors. These shortcomings limit the MV models’ application in the FOF construction. As a result, it is not surprising that many research efforts were placed on extending the MV model [
5,
6,
7,
8,
9,
10,
11].
From a practical perspective, there exist many trading restrictions in the real-world financial market. Transaction cost is one of which that should be paid attention. In fact, transaction costs in the financial market is usually treated as non-linear functions, which makes the FOF optimization model a nonlinear programming problem. The interior point method (IPM) [
12,
13], sequence quadratic programming (SQP) method [
14], parallel variable distribution (PVD) [
15] and line search algorithm [
16] are all popular methods for nonlinear programming problems. However, the aforementioned methods can be inefficient since they does not explore the structure of the objective function. For example, the general SQP procedure uses the derivative vector and the Hessian matrix of the Lagrangian function to construct quadratic approximation at each iteration [
17]. The Hessian matrix of FOF optimization models may not necessarily be positive semi-definite, so an approximation of the Hessian matrix is needed. Constructing a Hessian approximation by quasi-Newton methods may be poorly performed and time-consuming. The IPM maintains the feasibility during iterations but it is a centralized and computationally expensive method. Moreover, it is hard to parallelize. The PVD method is suitable for parallelization but needs to solve a difficult convex subproblem when applied to FOF optimization model, which makes it hard to be extended to large-scale problems.
Most of algorithms that developed in recent years have concentrated on structured nonlinear programming, which aims to characterize a range of nonlinear problems. In 1977, Glowinski and Marrocco [
18] proposed the alternating direction method of multiplies (ADMM) based on the decomposition. It is widely used in large-scale nonlinear optimization problems thanks to the advantage of being easily extended to parallel and distributed systems. However, it still faces the challenge of slow convergence when applied in the FOF optimization model. Chaves et al. [
19] first proposed a Newton-based efficient algorithm; however, it only works when facing a non-constrained FOF model, which is unrealistic in practice. A least-squares method and an alternating direction method were developed by Bai et al. [
20] and Costa et al. [
21], respectively. However, they still consume a lot of time as the scale of the problem grows.
The main contribution of this paper is to propose a parallel algorithm general enough to characterize most of the existing specific FOF optimization models. Moreover, our approach is able to solve a large number of FOF optimization models that have the same structure as this paper studied. The main contributions of this paper could be summarized as follows:
We develop a new FOF optimization model which integrates complicated and diversified constraints into the Mean-Variance framework accompanied by a Black–Litterman based-asset expected return and covariance.
We propose an approach to handle the FOF optimization model mentioned above based on elevating the original problem into a higher-dimension convex problem which is solved by a modified ADMM algorithm. Moreover, we compare the modified ADMM algorithm efficiency to two of the best performing methods, SQP and IPM.
To explore a larger search space for better solutions, we parallelize the proposed approach on GPU using CUDA and study its speedup on different problem scales.
The remainder of the paper is organized as follows. In
Section 2, we give the step-by-step formulation of our new FOF optimization model, especially focusing on the Black–Litterman based-asset expected return and covariance.
Section 3 contains an approach to handle the FOF optimization model mentioned above. More specifically, we introduce new variables to transfer the inequality constraints in the model to the equality constraints and use a modified ADMM algorithm to construct the optimal portfolio. In
Section 4, the GPU-based parallel approach using CUDA is introduced to improve computational efficiency and cope with large scale problems. This is followed by implementation details of the proposed parallel approach in
Section 5, where we present the efficiency of the proposed approach compared with some of the best performing methods, as well as the acceleration effect of the parallel approach. In
Section 6, we conclude the paper.
2. Problem Formulation
The core of FOF funds is to diversify investment, so it is no surprise that asset allocation has become an important part of FOF construction. Based on the asset allocation, we can improve the return-risk feature of a fund portfolio. For simplicity, we limit the fund type to equity funds, so asset allocation is beyond the scope of this paper. Furthermore, another determining factor for the performance of an FOF strategy is the quality of the fund pool. It is naturally an extremely important thing for fund managers to screen out their own fund pools from a huge number of funds and build fund portfolios accordingly. There are many fund selection criteria such as risk/return parameters and the professionalism of the management team. In this paper, we take return, standard deviation and fund size as the key factors of focus to screen out funds.
It is assumed that investors with initial capital
C will assign their wealth to
n equity funds in the following
T periods. Let
be the proportion on fund
i included in the portfolio at the previous period.
,
,
,
and
are the set of the funds with high risk and high return, with medium to high risk and medium to high return, with medium risk and medium return, with low to medium risk and low to medium return, and with low risk and low return, included in the portfolio, respectively. A new FOF optimization model is proposed as follows:
where the transaction cost
,
and
are the given parameters, which are various from different funds.
P denotes the covariance matrix of the fund returns, and
refers to the fund returns vector.
and
are the lower and upper bound of investment proportion on fund
i. Without loss of generality, we can abstract the new FOF optimization model into a general form.
Notation. Let
denote the set of real numbers,
the
n-dimensional real space, and
the set of real
n-by-
n symmetric positive (semi)definite matrices. We denote by
the set of real
m-by-
n matrices,
is the identity matrix and
is the zero matrix, and
is the
n-dimensional vector with all the entries being 1.
is the indicator function over the affine constraints of (5), i.e.,
For , the projection of z onto is given by
The FOF optimization model that considered transaction cost is given by:
where
is the optimization variable.
is a symmetric semidefinite covariance matrix and
.
and
.
and
are the lower and upper bound.
is the transaction cost function. The function
is the subscription and redemption cost for adjusting the
ith fund. If the transaction cost
is given by linear function or quadratic function, i.e.,
, then the optimization problem (
3) is quadratic programming. Throughout this paper, we consider the transaction cost function
to be convex, so that the objective function is nonlinear and convex. The linear constraints imply the bound of the portfolio weight and the investment requirement of the portfolio weight.
4. Acceleration Approaches
Another contribution of this paper is the GPU implementation of the proposed algorithms based on CUDA. In this section, we show how we parallized the proposed algorithm on CUDA and expose step by step the strategies that we used to achieve an optimal performance in our CUDA implementation of the proposed algorithm.
4.1. Parallelization
In the
k-th iteration for updating
, we solve the nonlinear optimization problems (
13). The procedure for solving each variable
is independent. We parallelize the steps for updating
by
To avoid solving the constrained problems, we solve the unconstrained problems since the objective function is convex.
And
is updated by
Listing 1 shows an overview of how we designed the kernel in the device on GPU. Each thread computes the new variables
by (
27) and (
28) in parallel. To make the program more extendable, we created a base class named Cost to implement the different types of the cost function by the subclass in the device and pass the point to launch the kernel.
Listing 1.
Computing the variables in parallel.
Listing 1.
Computing the variables in parallel.
In our implementation, we apply the quasi-Newton method for minimizing (
27), which is a second-order method that helps to quickly find the optimal value (see
Listing 2).
Listing 2.
Calling the quasi-Newton method (Davidon–Fletcher–Powell algorithm) in parallelin parallel.
Listing 2.
Calling the quasi-Newton method (Davidon–Fletcher–Powell algorithm) in parallelin parallel.
Remark 1. When the function is a linear or quadratic function, it is achievable to perform the matrix equilibration to transfer the matrix into diagonal matrix. After that, we do not have any term like , which will reduce the number of iterations. However, for more complicated functions, such preconditioning will make updates of difficult to be parallelized.
4.2. Do as Much as You Can on CUDA
CUDA is an extension of the C programming language created by NVIDIA. Its main idea is to have a large number of threads that solve a problem in parallel. To execute the program on GPU, we launch the kernels which are defined by the global keywords.
Before calling the kernel, CUDA needs the input data to be transferred from CPU to GPU through the PCI Express bus [
27]. This stage of data transfer is a necessary part of any GPU code and can be the bottleneck affecting the program’s performance. So once the data has been transferred to the device memory, it should not return to the CPU until all operations are finished. In our first CUDA implementation of the algorithm, this fact was not taken into account since the data is transferred from GPU to CPU during iterations. Therefore, the results of this first implementation are not outperform. This shows that direct implementations of not trivially parallelizable algorithms may initially disappoint the programmers expectations regarding GPU programming. This occurs regardless of the GPU used, which means that optimizations are necessary for this type of algorithms even when running on the latest CUDA architecture. We suggest finishing all the computing steps on GPU and avoid data copy as much as possible. First, we copy the matrix
and
to GPU and start the iteration. It is admirable to conduct the upgrade steps (
11)−(
14) on GPU at each iteration; however, when it comes to the steps for judging the stopping criteria, we have to copy the data from GPU to CPU, which will increase unnecessary time on data transmission. Usually, the stopping criteria is calculated by comparing some matrix or vector norms, so we suggest avoiding data transfer by calling the cuBLAS to compute the norms and output the result on a CPU, which will significantly reduce the time spending on data transmission (see
Listing 1).
4.3. Use CUDA Libraries
There exist excellent libraries shipped with the CUDA Toolkit that implement various functions on the GPU. We summarize the NVIDIA libraries used in our paper.
cuBLAS is a CUDA implementation of BLAS, which enables easy GPU acceleration of code that uses BLAS functions. We use the level-1 API function for the computation of norms. Level-2 and level-3 API functions are used for the matrix–vector product and matrix–matrix product (see
Listing 3).
Listing 3.
A general process for the proposed algorithm. The iteration is conducted on GPU and output of the residual is on CPU.
Listing 3.
A general process for the proposed algorithm. The iteration is conducted on GPU and output of the residual is on CPU.
cuSolver is a high-level package based on the cuBLAS and cuSPARSE libraries. It is a GPU accelerated library for decompositions and linear equation for both dense and sparse matrices. We use the syevj to compute the spectrum of a dense symmetric system.
4.4. Constant Memory and Page-Locked Memory Usage
Constant memory is a read-only memory, so it cannot be written from the kernels. Therefore, constant memory is ideal for storing data items that remain unchanged along with the whole algorithm execution and are accessed many times from the kernels. In our implementation of the proposed algorithm, we store the constant parameters we need during iteration. These values do not depend on the FOF model and do not change along with the thread execution, so they are ideal for constant memory. Our tests indicate that the algorithm is to faster, depending on the model size when using constant memory.
Page-locked (or “pinned”) memory is used as a staging area to transfer the device to the host. We can avoid the cost of the transfer between pageable and pinned host arrays by directly allocating our host arrays in pinned memory. Pinned memory is beneficial because it avoids copying data directly between the CPU and GPU.
Listing 4 shows how we apply fixed memory and compute residual norm in conjunction with the CuBLAS library. Since the residual is stored on the GPU, we need to calculate its norm to determine the stopping criteria on the CPU.
Listing 4.
Using the CUDA memory and the CuBLAS library to compute residual norm.
Listing 4.
Using the CUDA memory and the CuBLAS library to compute residual norm.
4.5. GPU Occupancy
Occupancy is the ratio of active warps per multiprocessor to the maximum number of possible active warps. The highest occupancy is no guarantee for obtaining the best overall performance, but the low occupancy always reduces the ability to hide latencies, resulting in general performance degradation. Therefore, we perform an experimental test on the device to determine exactly the best number of threads per block for our algorithm. The best values of serialized warps appear with a size of 128 threads and it achieves a maximum speedup. (See
Listing 5)
Listing 5.
Finding the optimal threads to achieve a maximum speedup.
Listing 5.
Finding the optimal threads to achieve a maximum speedup.
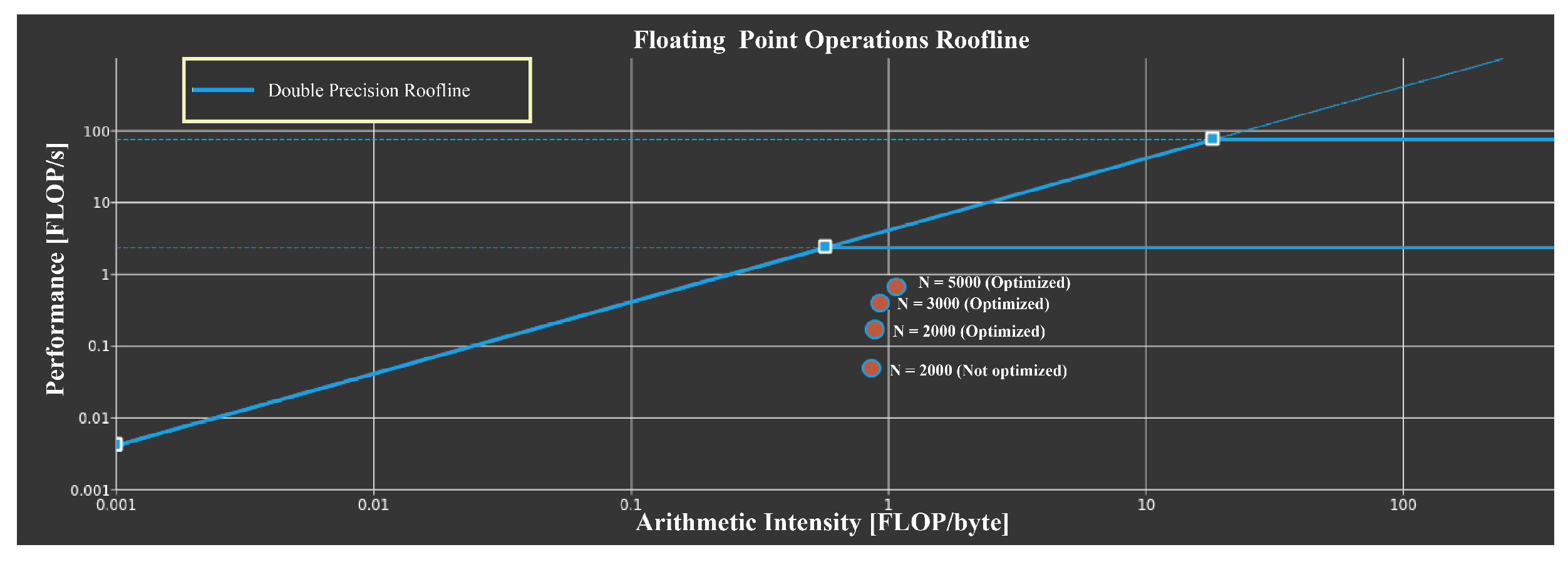
Figure 1 shows the roofline of the kernel for computing the variables
. The roofline provides a visually intuitive way for users to identify performance bottlenecks and motivate code optimization strategies. Performance (GFLOP/s) is bound by
which produces the traditional Roofline formulation when plotted on a log-log plot. As can be seen from
Figure 1, the performance of the kernel increases about 4.5× after optimization when solving an FOF model (
N = 2000). As the scale of the model increases, the utilization for compute and memory resource of the kernel approximates to the theoretical maximum performance bottleneck.
4.6. Storage Block Matrix on Device
In practice, we do not have to store the whole matrix
and
on CUDA. It is feasible to store the matrix in blocks since those matrices have many zero blocks. All of the matrix–vector or matrix–matrix operations presented in our algorithm could be done via block operation. For example,
could be calculated by
where
. For the diagonal matrix, it is stored as an array in GPU. The computation steps of
could be done via vector–vector operation.
5. Experiment
We implemented our algorithms on CPU and parallelized them on GPU. All the programs run on a server with i9-10940X with 128 M RAM and one NVIDIA RTX2080ti, 11 GB memory. The server’s CPU is i9-10940X, with 128 M memory and an NVIDIA RTX 2080ti GPU, 11 GB memory. The performance of the proposed methods is reported in comparison with the sequential quadratic programming (SQP) and the interior point method (IPM). We simulated the net value of
different funds with
N ranging from 50 to 5000, which could be the maximum portfolio capacity for the funds. All the fund data is simulated by the Geometric Brownian motion (GBM), with different risk level
with regard to the different type of funds. The following table shows the running time for solving the problems (
1) of SQP and the CPU implementation of our proposed method. The relative error is calculated by the
, where
and
represent the optimal value of the proposed method and the SQP, respectively. For smaller-scale problems, we ran numerical experiments 100 times and then averaged them, and for larger-scale problems, we ran the experiments 20 times.
Table 1 shows the running time and relative error for solving the portfolio proble with different methods. As
N increases to more than 2 ×
, it will be challenge for the commercial solver to solve the problems in an acceptable time (3 ×
s). The proposed algorithm does not show an outstanding performance in the CPU version.
Table 2 shows the GPU implementation of the proposed algorithm. By conducting the iteration in parallel, we reach a respectable acceleration.
Figure 2 shows the calculation time and relative error curves of the FOF model (2.1) solved by different methods. We implement this method in CPU(ADMM) and GPU(cuADMM). We can see that the CPU implementation of the proposed method is better than SQP and IPM. When solving problems of different scales, the relative error of this method decreases faster, and the solving speed of the GPU version accelerates significantly.
Figure 3 (left) shows the changes of relative error for
and 5000. We also implemented a fixed stepsize (
) for comparison. For
, the relative error of the fixed stepsize decreases very slowly. As the relative error decreases, the convergence speed becomes slower. The adaptive stepsize method converges and reaches the stopping criteria in only a few iteration.
Figure 3 (right) compares the speedup ratios for problems of different sizes. When
N is small (
), the acceleration of the GPU’s implementation is not obvious as the copying data step takes up most of the time to execute the code. As
N increases, the proposed algorithm not only maintains a fast convergence ratio but also significantly outperforms the existing methods.




{kind=link}
{kind=link}
{kind=link}