1. Introduction
The science that studies the events that occur in the life cycle of plants is known as phenology. Phenology is a tool to interpret the interactions of culture with local climatic conditions. This allows us to characterize the occurrence of different stages and the duration of crop development periods, relating them to seasonal variations [
1].
Figure 1 shows the sequence of the phenological stages of the apple tree. Phenological phases can be seen as organ transformations in plants, such as germination, budding, flowering, defoliation, and maturation. Phenological stages are specific phases or subdivisions that involve significant changes or characterize any plant condition of the plant [
2]. Phenological events vary between years due to the variety of climatic elements, especially temperature [
2]. Thermal availability has a direct influence on plant phenology. Detecting changes in Phenology has become a recurrent theme, and precision agriculture has increasingly attracted the attention of farmers, governments, and researchers, since plant monitoring is one of the essential tools for the management and optimization of agricultural resources [
3]. The complex interactions between plant development and the environment represent a significant source of uncertainty for growers. The climate can change very quickly and have significant implications for fruit production, representing costs for growers. Predicting the harvest time is a challenge to develop sustainable fruit production and reduce food waste [
4]. Apples are perishable, high-value, and seasonal, and selling prices are often time-sensitive, making harvest characteristics extremely valuable to growers [
5].
Machine Learning (ML) is an area of Artificial Intelligence (AI) that, according to Mitchell et al. [
6], is concerned with the question of how to construct computer programs that automatically improve with experience. ML approaches have been used in several areas including, for example, applications in the construction industry [
7], in the medical field [
8,
9], in meteorology [
10], and in biochemistry [
11]. In the research field of agriculture, ML has been used in a variety of applications [
12,
13,
14,
15]. Agri-technology and precision agriculture have emerged as new scientific fields that use data-intensive approaches to boost agricultural productivity and minimize environmental impact. The data generated in modern agricultural operations allows a better understanding of the operating environment (an interaction of dynamic crop, soil, and climatic conditions) and the operation, leading to faster decision making [
12]. In this context, ML is an important tool to support decision making, assisting in planning, handling and management, forecasting, disease detection, and the quality of agricultural production.
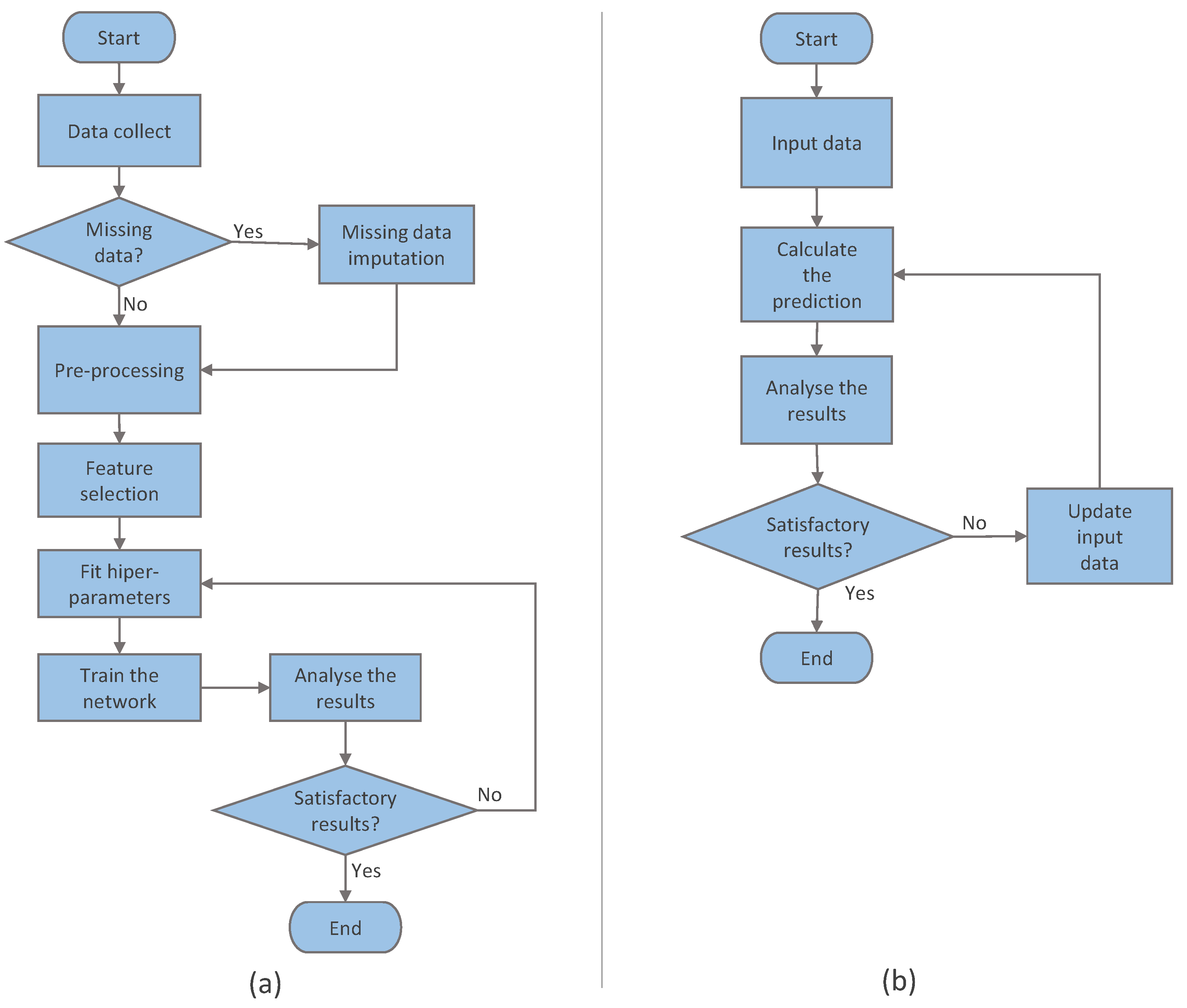
Linear models based on thermal sum have been used to estimate the occurrence of phenological stages of different crops. However, these models, when adjusted to the apple crop, show high variability for certain stages, failing to adequately represent the occurrence of the phenomenon. Solutions proposed for other cultures need adaptation due to the particularities of the apple tree culture. In this work, we developed PredHarv, a machine learning model, based on thermal sum, but using a multivariate approach with an RRN-based supervised learning algorithm. The model was developed to predict the start date of the apple harvest, given the climatic conditions related to the expected temperature for the period. A conventional pipeline of an LSTM network is used, which is a type of network designed specifically for sequence prediction problems that can deal with the temporal structure of inputs and capture the behavior dependent on the sequence of environmental stimuli, which is implicit in the time series. We assumed as basic hypotheses, which guided the development of this work, that the apple harvest date can be estimated through ML methods using a multivariate approach based on historical data of phenology and climatic parameters related to temperature, and also that multivariate models based on thermal summation can improve the accuracy of predictions in days, better explaining the relationship between temperature variables and the amount of heat needed for the plant to complete its cycle. The model contributes with a methodology that makes the predictive capacity more effective, enabling the prospection of future scenarios. The development of this work contributes to the fruit growing area, making it possible to anticipate information about the harvest date, improving the accuracy of predictions. This information can be helpful to the fruit grower to perform planned activities, avoiding unnecessary costs with treatments, handling, and management as well as reflecting the quality of agricultural production. It can be used as an essential tool to support decision making, generating financial savings for the fruit grower.
This work is organized as follows.
Section 2 presents an analysis of the works related to the theme proposed in this article.
Section 3 presents the model for predicting the harvest date.
Section 3.3 presents the evaluation methodology, details about prototype, input data and parameters, evaluation metrics, and evaluation scenarios. Then, in
Section 4, the results obtained with the experiments carried out are presented.
Section 5 includes a discussion of the results obtained. Finally,
Section 6 features the conclusion.
2. Related Works
The prediction of phenological stages has been extensively investigated in the literature [
1,
16,
17,
18,
19,
20,
21]. Many initiatives are found, which use different methods to offer solutions for the most varied cultures. Among the works related to apple phenology, in Petri et al. [
1], the authors present studies on the phenology of apple trees in subtropical climatic conditions. The study uses phenological and climatic data, using a statistical approach, and presents important conclusions about the impacts on fruit production under subtropical climate conditions. In Putti et al. [
16], the authors evaluated the phenological development of different fruit structures of apple trees with the objective of characterizing the behavior of the phenological period from the complete flowering until the beginning of the ripening of the apple. In Blazek and Pistekova [
18], the fruit growth of apple cultivars was evaluated. The authors recommend using the relationship between the diameters of fruits at the T stage and fruits reached at harvest maturity to predict the harvest time and variety yield of four apple cultivars. In general, these works use statistical approaches, based on experiments, observing the evolution of the stages to verify the effect of the amount of cold or heat and to characterize the behavior of the phenological period of the apple. The authors conclude that the greater the number of cold units in dormancy, the shorter the time and need for heat for sprouting. Due to the peculiarities of fruit growing, the approaches generally developed for commodities need adaptations. In particular, there is a need to use unique methods with specific cultivation characteristics, which makes it difficult to apply techniques from other cultures without adaptation.
Thermal sum models, in the form of degree-days, have been adjusted to estimate heat accumulation [
21]. These models represent the integration of effective temperatures for plant growth, which is fixed between the lower and upper limits. In Boechel et al. [
19], the authors investigated the use of methods Fuzzy-based Time Series (FTS) to predict phenological stages of apple trees. The authors noted that the quality of results is improved by combining variables and using multivariate FTS methods. Studies, such as those by Rivero et al. [
22], Darbyshire et al. [
23], and Chitu and Paltineanu [
21], evaluate the impacts of rising temperatures and climate change on the flowering season of apple trees due to global warming. These works produce statistics and relate meteorological and phenological data due to global warming and how much the initial phenological stages have changed due to climate change.
Approaches using ML methods are present in Chen et al. [
20], Dai et al. [
24], Czernecki et al. [
25], and Haider et al. [
26]. Some authors have applied artificial neural networks (ANN) to predict phenological stages, as in Yazdanpanah et al. [
17] and Safa et al. [
27]. In Yazdanpanah et al. [
17], the authors used an ANN to anticipate different phonological phases of the apple. The authors identified that most of the error was related to the anticipation of the fruit development stage and concluded that it is possible to anticipate the phenological stages of the apple with acceptable accuracy using climatic parameters. In Safa et al. [
27], the authors present a study where an Artificial Neural Network was applied to predict the production of dry wheat. The results demonstrate precision and efficiency with a maximum error between 45 and 60 kg/ha. McCormick et al. [
28] proposed a hybrid model using a data-driven model using knowledge-based predictions to predict soybean phenology. According to McCormick et al. [
28], the potential that LSTM networks have to capture the impact depends on the sequence of environmental stimuli, which in the context of this work is analogous to, for example, a period of cold weather in plant development. In Chen et al. [
20], a hybrid method is proposed combining neural networks with integrated learning to predict the flowering period of “Red Fuji” apple trees. The method uses LSTM networks and the Random Forest and Adaboost classification functions. The proposed model has high applicability and accuracy for flowering prediction. Haider et al. [
26] developed a wheat yield production forecasting model using LSTM networks. The objective focuses on the development of a wheat yield prediction model using Robust-LOWESS as a smoothing function in conjunction with an LSTM neural network model. The results show that the proposed model achieves a good performance in terms of productivity prediction.
Aiming at a comparative analysis between the analyzed works,
Table 1 presents the main characteristics of each approach. All works present some solutions to related problems. Although they do not have the same focus, they have a solid relationship with interest. The Culture column shows the work related to the apple tree culture. The ML column shows works that use ML techniques. The Other approach column shows works that use some other strategy to predict phenological stages and harvest prediction. The ANN and RNN columns present jobs that use these techniques. The literature review resulted in a set of articles that focus on harvest time prediction initiatives and others related to predicting the phenological stages in general of apple trees and other crops. Among the works, we can emphasize some characteristics. We see a solid tendency to assess the impacts of rising global temperature and climate change on plant phenology. We observe works with approaches in the sense of analysis or even making the function of phenology as a function of climate or other factors that alter phenomena. Many jobs are related to the cultivation of wheat, soybeans, and corn. We observe that a large part of the work related to harvest forecasting is focused on yield forecasting. Although there are many solutions related to the prediction of phenological stages, we observed a gap regarding the use of computational intelligence for a prediction start date of the harvest of apple trees. We did not find an approach similar to the one proposed in this work.
5. Discussion
In the results obtained with the MR method (
Table 6), the RMSE metric obtained an average value of 2.58 in the selected samples, and the metric of the MLP method (
Table 7) obtained an average value of the RMSE metric of 3.09. Comparing these results, the MR method had a better result with a difference of 0.51. However, it was observed that the standard deviation measure, which is a measure of dispersion around the mean, shows that the results obtained with MLP are more uniform. The values obtained with PredHarv (
Table 3) in the RMSE metric are 0.90 with a standard deviation of 0.17 for the selected samples. These values are lower than those obtained with the MR and MLP method. The difference between the results obtained with PredHarv is 2.19 lower compared to MLP, and it is 1.68 lower than with MR. The standard deviation measurement of the PredHarv method also shows uniformity in the results obtained.
Auto-sklearn and Autokeras are fully automatic AutoML methods. They are black box models, and their internal structure is unknown, being limited to measures of input and output relationships. However, these methods search a vast space of models and build complex sets of high precision, building models based on the data, which collaborates with the purpose for which they were submitted in this work. Investigations of other methods that can be applied to the problem demonstrate that the choice of the LSTM method is adequate to the nature of the problem. The ML method used exploits the potential of LSTM networks, which are a special type of RNN to deal with problems involving time series. PredHarv model predictions are made from the phenological stage of full bloom. These time series are a set of observations ordered in time, and they have a temporal dependence between the observations. Recurrent networks applied to this type of problem have the ability to capture part of the information implicit in the series, reflecting the impact of a sequence of environmental stimuli on plant development.
Linear models that use the sum of degree-days have been used to estimate the duration of phenological periods of apple trees and other crops [
37]. These models, when adjusted to estimate phenological sub-periods of apple trees, present results with a lower variability in the accumulation of degree-days for most phenological stages between seasons, compared to the number of days, responding better to the thermal sum than to the chronological time (calendar days). According to [
38], linear models have the obvious defect that the capability of the model is limited to a linear function, and therefore, the model may not explain the interaction between any two input variables. The PredHarv model uses thermal sum models as a baseline, but it uses a multivariate approach. We use the thermal sum relating the accumulation of degree-days to the duration of the period and other temperature-related variables in order to estimate the chronological time. The inclusion of other variables, with the multivariate strategy associated with the use of an ML method as proposed in this work, significantly improves the response, as can be seen in the comparative graphs of predictions with the PredHarv model and the linear model, in
Figure 9 and
Figure 10, managing to better explain the occurrence of the phenomenon.
The results observed in the experiments carried out confirm the basic hypotheses that guided the development of this work: that the apple harvest date can be estimated through ML methods using a multivariate approach based on historical data of phenology and climatic parameters related to temperature, and also that multivariate models based on thermal summation can improve the accuracy of predictions in days, better explaining the relationship between temperature variables and the amount of heat needed for the plant to complete its cycle.
6. Conclusions
This work proposed a new approach to predict the harvest date in apple trees. The computational model PredHarv uses a multivariable approach, using historical and meteorological data with a strategy that uses RNN. The proposed evaluation scenarios and the comparative tests between the models show that the PredHarv model is a useful alternative that is capable of improving the accuracy of the prediction results. This work contributes to fruit growing, enabling anticipating information about the harvest date, generating financial savings for the fruit grower, avoiding unnecessary costs, and improving planning and productivity. The PredHarv model contributes with a methodology that makes the predictive capacity and applicability more effective, enabling the prospecting of future scenarios.
A prototype of the PredHarv model was developed and submitted to evaluation scenarios. The results were evaluated according to the RMSE and MAE metrics. In the tests of the first PredHarv evaluation scenario, it demonstrated a generalization capacity when submitted to new data. In the second scenario, PredHarv showed results very close to the real values in tests with real data. In the third scenario, when submitted to synthetic data, the results showed that the PredHarv model showed a positive response to the stimuli caused by the changes made to the input data, adjusting the prediction as the data are being introduced. We performed tests with other supervised learning methods, and the average of the RMSE metric results obtained with LSTM was superior to the results obtained with other algorithms.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}