2.1. Influence Spreading Model
In this section, we describe the influence spreading model [
6] that is at the core of the presented algorithms. A similar model, called Independent Cascade Model, was presented by Kempe et al. [
16] Our model may be viewed as a generalisation of the Independent Cascade Model, which does not allow self-intersecting paths or breakthrough influence.
The model describes a form of diffusion in a social network, and it is based on assigning a spreading probability to each edge of the network. Diffusion starts from a specified starting node, and each node has one chance to spread influence to each of the neighbouring nodes with the probability specified by the assigned edge probabilities.
We store all pairwise spreading probabilities in a two-dimensional influence spreading matrix , where denotes the probability of spreading from the starting node s to the target node t. The matrix elements are computed based on all possible paths between the corresponding pair of nodes. In other words, for computing , we will combine the influence of all paths from node s to node t. It is important to note that and will not always be equal as probabilities are assigned to each directed edge individually. Notice that paths between two nodes may have arbitrarily many nodes when we place no restrictions on them. Thus, to keep the set of paths finite, we need to limit path length. Let denote the maximum number of edges allowed on a path.
In addition to edge-specific probabilities, Poisson distribution is used to model temporal spreading. It is applied as a factor to the probability of spreading through a path. The Poisson distribution is a discrete probability distribution that expresses the probability for a giving a number of events occurring in a fixed interval of time provided that these events take place with a known constant rate and independently of the time since the previous event. In this context, the Poisson process describes a process where spreading via successive links occurs randomly as a function of time [
6]. The unconditional probability of temporal spreading at time
T on a path of length
L is given by
where
is the intensity parameter of the Poisson distribution.
and
T are constants throughout the calculation. Here, the interpretation is that the spreading has advanced up to
L or more links at time
T [
6]. When
, the values of
approach to one. Additionally, other path length-dependent distributions could be used to more accurately model the different kinds of real-world influence spreading.
Now, we are ready to calculate the probability of a single spreading path. Let
denote the probability of spreading through path
, starting from the first node and traversing the path through each edge until the end.
is the product of corresponding edge probabilities and the Poisson distribution coefficient from Equation (
1); that is,
where
denotes the spreading probability through the edge from
u to
v,
the set of edges on path
, and
the size of the edge set; that is, the number of edges on the path [
6].
To combine the probabilities of two different paths
and
between the same pair of nodes, we let
denote the longest common prefix (LCP) of the paths. If there are no common nodes, i.e.,
is an empty path, we say that
. Otherwise, let us derive a formula for calculating
from
and
. We assume that the probabilities of two paths, after the first diversion, become unconditional and that the probabilities of non-intersecting paths are not dependent on each other. As a node can be influenced only once, we have to subtract the possibility that influence spreads through both
and
. Now [
6],
The probability of spreading from node s to node t, , is calculated by combining all paths from node s to node t. If there are no paths from node s and to t, we say that . To ensure that the common prefixes of paths are combined correctly, we require that the paths are sorted lexicographically by their nodes, and that only adjacent paths are combined—in decreasing order of the number of common prefix nodes. Eventually, paths with no common links are combined until there is only one path left. The last path’s spreading probability is interpreted as the probability of influence spreading between the nodes. The process of combining paths is described in more detail in Algorithm 1. While it is a simplified version of the model and inefficient for most of the real-world network sizes, it serves as a foundation for our algorithms and provides a base model to implement more efficiently.
An important aspect of our algorithm is that nodes have no state during the path-merging process. This is in contrast to the independent cascade model [
16], where each node, after
activating has one chance to spread influence to each of its inactive neighbours, after which the node becomes active, and will not spread influence again. Even though we can restrict the search to self-avoiding paths, that is to paths where each node only appears once, we are not able to take control of breakthrough influence, i.e., influence through a node that has been influenced before. The fact that the nodes have no state is one of the reasons our algorithm is efficient. However, this difference means that our model and the independent cascade model are for describing distinctly different real-world phenomena.
| Algorithm 1 The path combination process [7] |
- 1:
▹ Computes the probability of spreading from node s to node t in network G. - 2:
procedureSpread() - 3:
list of all paths from node s to node t in network G with at most edges - 4:
if then - 5:
0 - 6:
end if - 7:
Sort in lexicographically increasing order based on path prefixes - 8:
for do - 9:
if there are no paths of at least c edges then - 10:
continue - 11:
end if - 12:
while there are two adjacent paths and in with an LCP of c edges do - 13:
▹ Combine the probabilities of the two paths according to Equation ( 3) - 14:
- 15:
Remove from - 16:
end while - 17:
end for - 18:
the probability of the only path left in - 19:
end procedure
|
Because the model is built on top of the concept of spreading paths, we are able to reduce the search space by limiting path length. In addition to making computation more efficient, this allows for studying the influence of a node in its local neighbourhood, rather than studying its position in the global structure of the network.
2.2. Algorithms
In this section, we present two algorithms, Algorithms 2 and 3 which both implement the logic of Algorithm 1. While they are more efficient than the original algorithm, they still combine paths in the same manner and output the same values. The path combination process, more precisely the order in which paths are combined, is present in all algorithms, but readers may find it harder to grasp in the more efficient implementations below.
2.2.1. Complex Contagion Algorithm
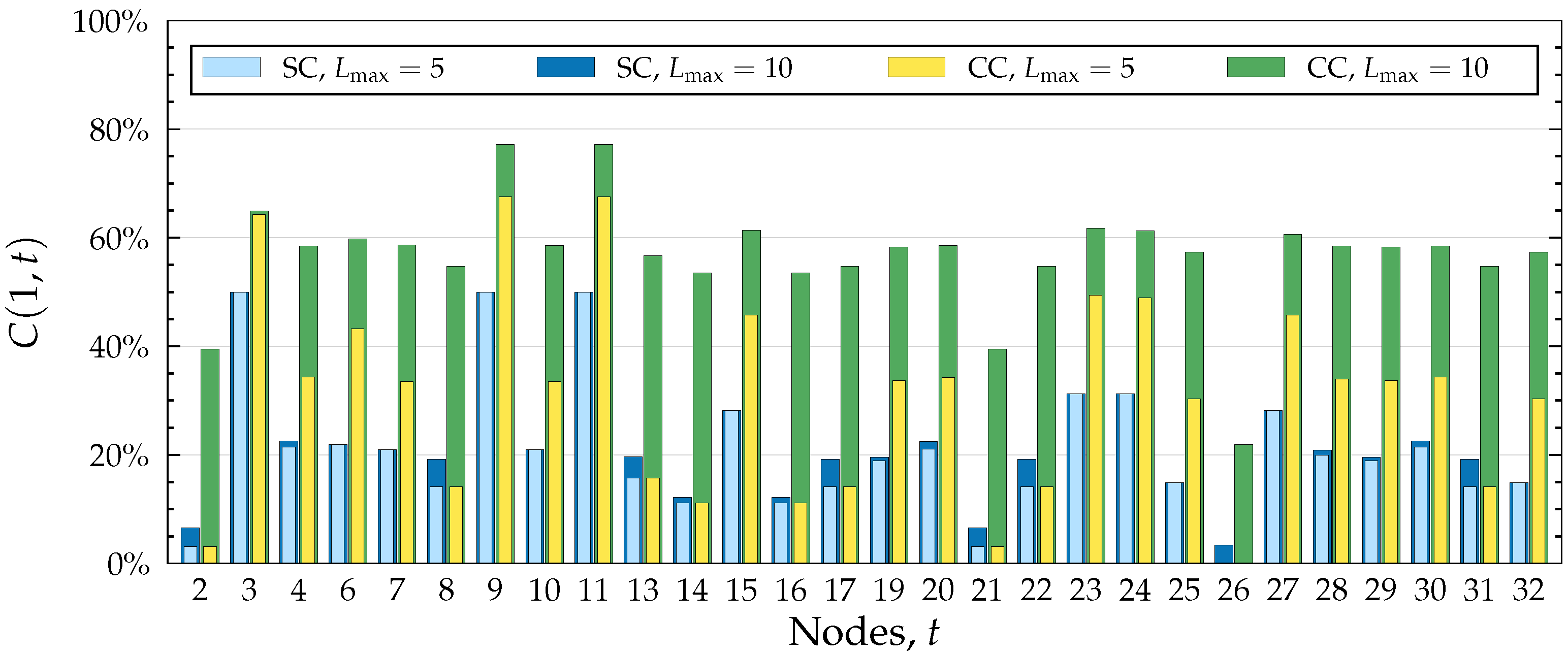
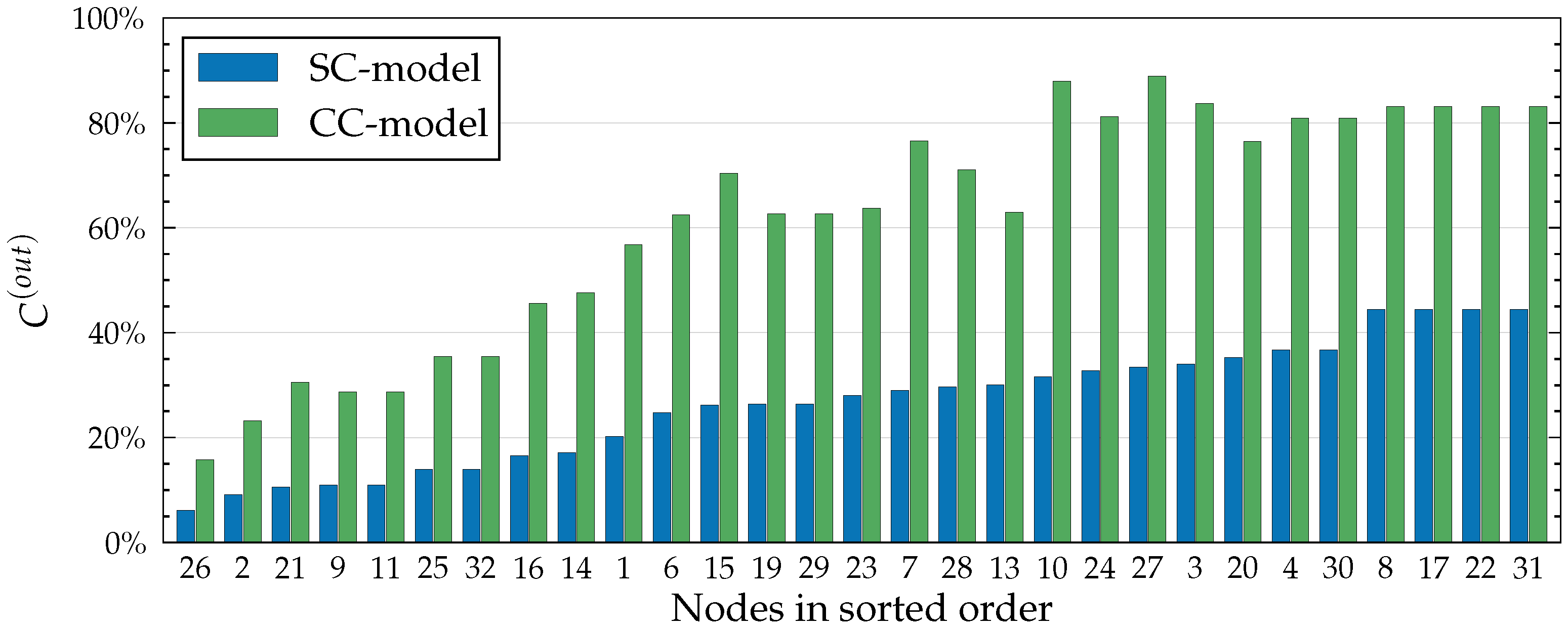
First, we describe an efficient algorithm for modelling complex contagion (CC). In the case of complex contagion, self-intersecting paths are allowed. Algorithm 2 solves this problem for a fixed target node t. To fill the influence spreading matrix, the procedure needs to be run times, once with each node as the target node. As mentioned, represents the maximum path length, that is, the number of edges on a path.
Two important factors contribute to the algorithm’s efficiency. Firstly, no restrictions, other than the maximum path length, are posed on paths. A spreading path may, for example, self-intersect. This means that we do not need to have the current path in memory in order to select the next node. Instead, it suffices to store the latest node and the length of the path. This allows us to save memory by grouping multiple paths together and combining their probabilities during the computation, rather than storing all individual paths until the end. Secondly, nodes have no state; that is, they are neither influenced nor uninfluenced. This means that we need not store the state of each node in memory nor do we need to process a great number of possible states individually.
| Algorithm 2 The Complex Contagion algorithm |
- 1:
▹ Computes the spreading probabilities from each node to node t in network G. - 2:
procedureProbabilities() - 3:
▹ Network G contains a node set, an edge set and the spreading probabilities for each edge - 4:
, for all ▹ Initialise the probability array - 5:
- 6:
for do ▹ Iterate L from to 0 - 7:
▹ Start new paths from t with L nodes left - 8:
for do ▹ Iterate all edges - 9:
▹ Extend paths ending at v with node u - 10:
▹ Combine probabilities (Equation ( 3)) - 11:
end for - 12:
end for - 13:
▹ Now, the spreading probabilities from i to t are found in , for all . - 14:
end procedure
|
| Algorithm 3 The Simple Contagion Algorithm |
- 1:
▹ Computes the spreading probabilities from s to each node in network G. - 2:
procedureProbabilities() - 3:
▹ The DFS function takes the current node and recursion depth as parameters - 4:
function Depth-First-Search(Node, Depth) - 5:
, ▹ Create a probability array of size - 6:
- 7:
if then - 8:
for each neighbor u of Node do - 9:
if u not on current path then - 10:
- 11:
for each do - 12:
- 13:
▹ Combine probabilities (Equation ( 3)) - 14:
end for - 15:
end if - 16:
end for - 17:
end if - 18:
return P - 19:
end function - 20:
return Depth-First-Search(s, 0) ▹ Start the recursive search from s - 21:
end procedure
|
The algorithm works backwards, building paths starting from the target node t, which is the last node on all paths. The backwards computation ensures that all pairs of paths are combined at the latest possible node as required by the model. The node, at which a pair of paths is combined, is the one where the paths diverge from each other for the first time. Spreading probabilities are stored in a two-dimensional array P, where corresponds to all paths with latest node i and L nodes missing. After calculations are finished, , i.e., paths ending at i with no nodes left, stores the probability of spreading from i to t. The value of is calculated by combining the values of for all j which are connected to i. At each step, we are essentially continuing all started paths backwards through all possible edges.
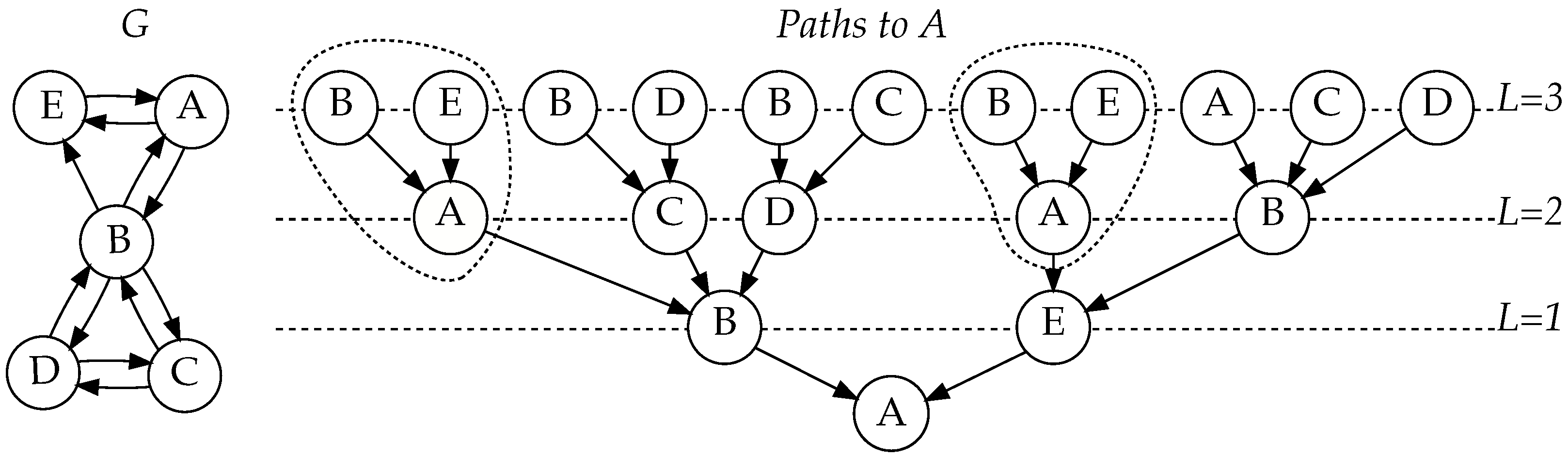
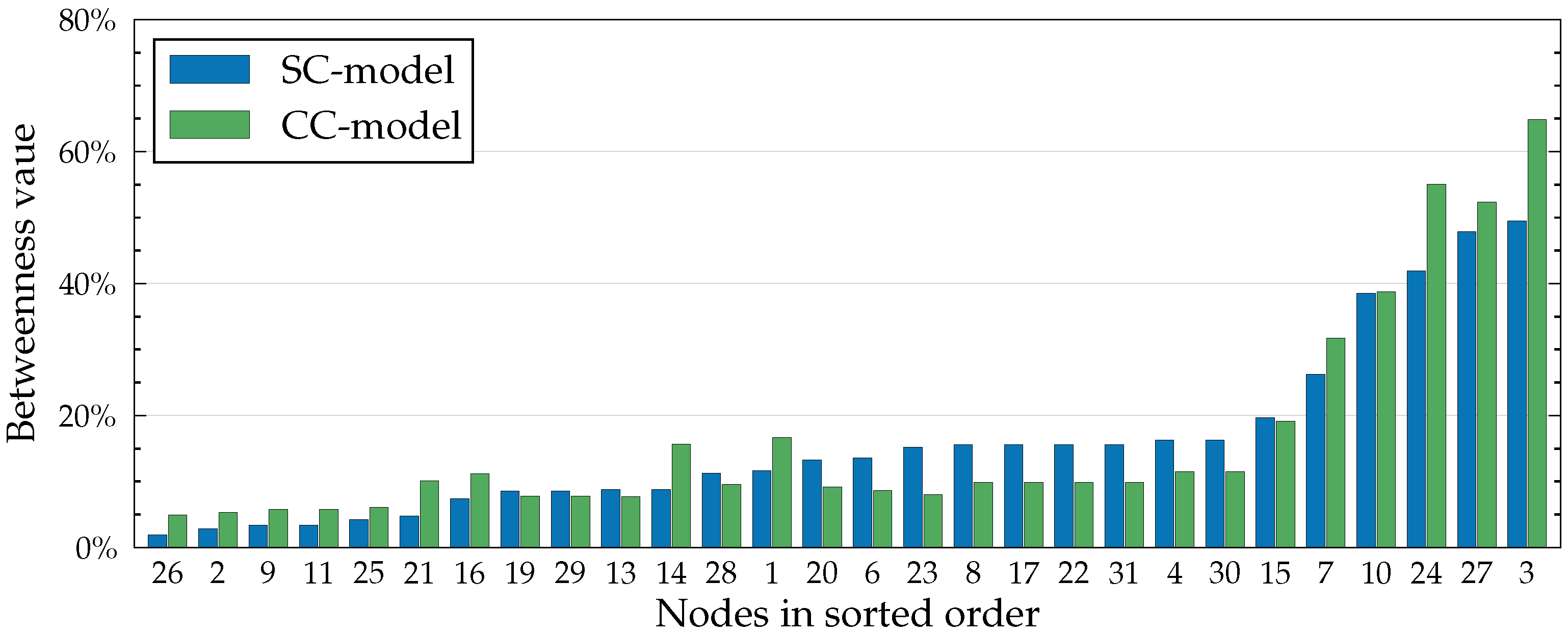
In
Figure 1, notice how length-one paths ending at
A are used in two different contexts. They are extended with edges
and
separately (circled in
Figure 1). Because, in the previous round, we have already computed and cached the value for
, we can use it in multiple contexts without needing to compute it again.
Before the computation,
is initialised with the corresponding Poisson factor from Equation (
1). Next,
iterations follow, numbered from
to 0. In iteration
i, new paths are started from
t, and already started paths obtain their
-th node. For example, in the first iteration, when
, paths of length
obtain their second to last node and paths of length
are started from
t, with
t as their
-th node.
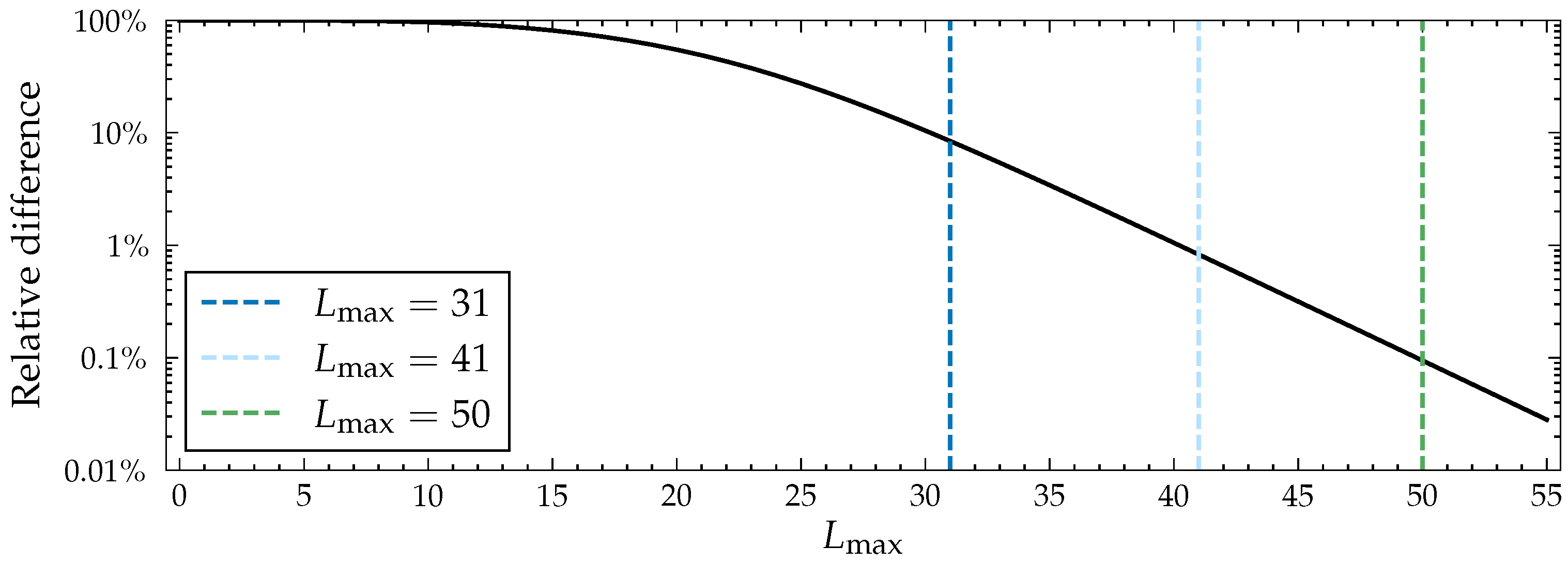
For a fixed end node, the algorithm works in time, where E denotes the number of edges in the network and the maximum allowed path length (measured in edges), making the total time complexity of solving the influence spreading matrix . The runs can easily be distributed to different cores or computation units as the calculations are completely independent, making the algorithm highly parallelisable. Moreover, the innermost loop’s iterations are also independent from each other, and can thus be parallelised, on the CPU instruction level. These factors combined make running the algorithm highly efficient in practice.
Memory-wise, the algorithm scales well for large networks as, at any time, we only need the values corresponding to the two latest values of L. Thus, we need to store two floating point numbers for each node per run, making the memory complexity of a single run .
2.2.2. Simple Contagion Algorithm
The second algorithm (Algorithm 3) known as the simple contagion(SC) algorithm models self-avoiding spreading. In self-avoiding spreading, paths must be non-intersecting. To avoid choosing a node which is already on the path, we must have the current path in memory, which slows down the computation significantly.
The algorithm itself is a recursive depth-first search, which goes through all possible paths with a suitable length. The search starts from the given starting node s and recursively traverses to each neighbouring node. At any point, the current stack of recursive calls corresponds to the current path prefix. Provided there are no duplicate edges, each possible prefix is only seen once. All paths which have the current call stack as their prefix are constructed either in the current function call or in the subsequent recursive calls inside of it.
Algorithm 3 uses the technique from Equation (
3) for combining paths and meets the model’s requirement that paths need to be combined at the end of their common prefix by, at each node, only constructing paths which first diverge at the node. Any pair of two differing paths has a specific node which corresponds to the end of the common prefix, which means that the procedure will, in fact, construct all possible paths—once and only once.
Each call to the depth-first search function has its own probability array P, which holds the probabilities spread to all other nodes. denotes the probability of spreading from the current node to node i. The values of depend on the current depth and thus cannot be used for calculating spreading probabilities from other starting nodes. After the probabilities for a node’s neighbours are recursively computed, they are combined into the probability array of the current node.
Note that were we to remove the self-avoiding restriction from line 9 of Algorithm 3, the algorithm would compute exactly the same values as the CC algorithm (Algorithm 2), but less efficiently. Another notable difference to the CC algorithm is that a single call to the SC algorithm (Algorithm 3) computes probabilities of spreading from a fixed start node s, while a single call to the CC algorithm calculates the values for a fixed end node.
It is well known that, in the worst case, there are paths with a fixed starting node and at most edges in a network of V nodes. The search function in Algorithm 3 updates the spreading probability of all nodes after processing each neighbour, making the total time complexity of a single run as each node has at most neighbours to process and there are nodes with a probability to update. As before, this algorithm needs to be run times, which increases the time complexity to fill the influence spreading matrix to . Both the SC algorithm and the original Algorithm 1 go through all spreading paths, but the fact that the SC algorithm does not store them in memory makes it significantly faster, more memory-efficient, and even usable in practice. It is scalable to large graphs with small values of . As was the case with Algorithm 2, the independent runs of this algorithm needed to fill the influence spreading matrix can be run in parallel to make computation more efficient. Combining the results of the runs is trivial, as each run corresponds to a single row in the final influence spreading matrix.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}