2.1. Three-Dimensional Printing
The world is constantly witnessing several technological advances. These advances always require acquiring new knowledge so that they are better understood. A technology that has evolved significantly in recent decades is 3D printing [
1].
One of the significant advantages of this technology is the flexibility in producing 3D-modeled parts by computer-aided design (CAD), which, together with computer-aided manufacturing (CAM), allows for the fabrication of different geometries, complex or straightforward [
8]. Additive manufacturing technology can be divided into seven families: vat photopolymerization; powder bed fusion (PBF); binder jetting (BJ); material jetting (MJ); sheet lamination (SL); material extrusion (ME); directed energy deposition (DED) [
9]. In the material extrusion (ME) family, the FFF process is the most common and easily used nowadays. They are the printers that generally anyone can have at home due to their low cost and operational simplicity [
10].
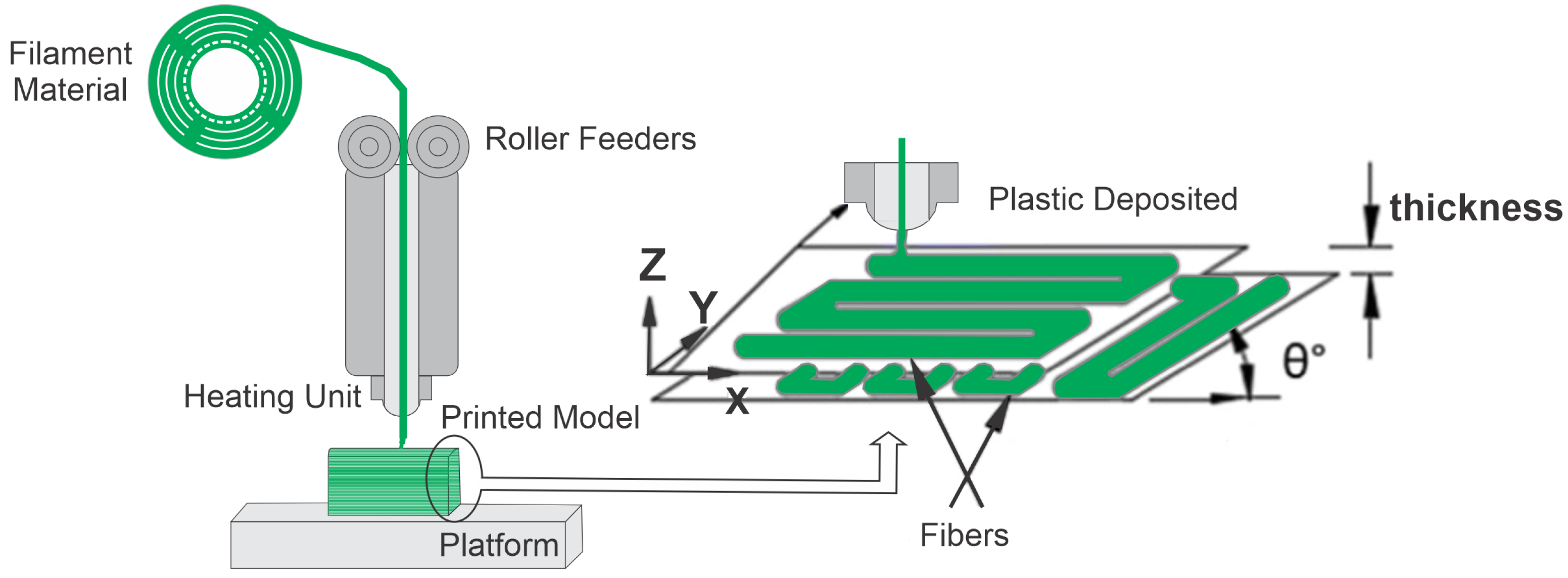
In the FFF process, the raw material, in the form of a filament, is hot extruded through a nozzle on a heated table following the coordinates defined by the digital file, where the material is deposited layer by layer until the piece is obtained [
2]; see
Figure 1. The most common materials in this type of process are plastic filaments, such as PLA, which is a rigid material, which allows fir greater detail in the parts produced with it, and acrylonitrile butadiene styrene (ABS), which is a thermoplastic with great flexibility and has more excellent resistance to impacts. Other materials also used in this process are polyester, polypropylene (PP), polycarbonate (PC), polyamide (PA), elastomers and waxes [
3,
11].
In the 3D printing process, several parameters influence the manufactured product [
12]. Therefore, to have greater control over the final part, each of these factors must be carefully analyzed. Some of these parameters are [
2,
13]:
Construction orientation: orientation with which the part is constructed relative to the base, along the X, Y and Z axes.
Layer thickness: height of the layer deposited by the extruder nozzle. Varies with nozzle diameter and material.
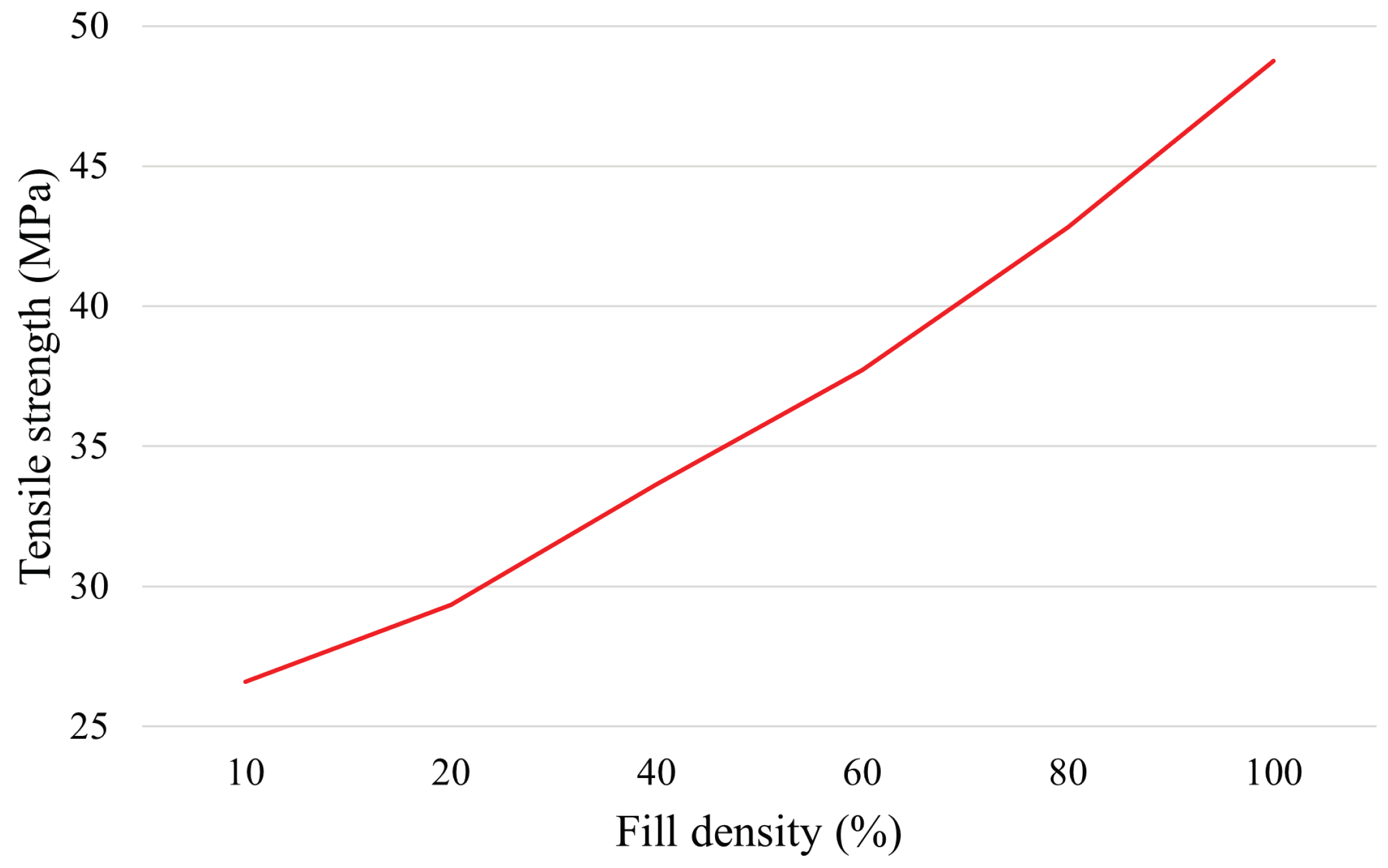
Fill density: space between adjacent filaments in the fill region of the part.
Fill angle: angle between the filler filament deposition and the X axis.
Filler filament width: width of the filament used for filling. It depends on the diameter of the extruder nozzle.
Number of contours: number of perimeters built along the part, internal and external.
Contour filament width: width of the filament used in the contour of the part.
Space between contour filaments: space between each of the filaments used in the contour.
Space between contour and fill: space between the contour and the effective fill of the part.
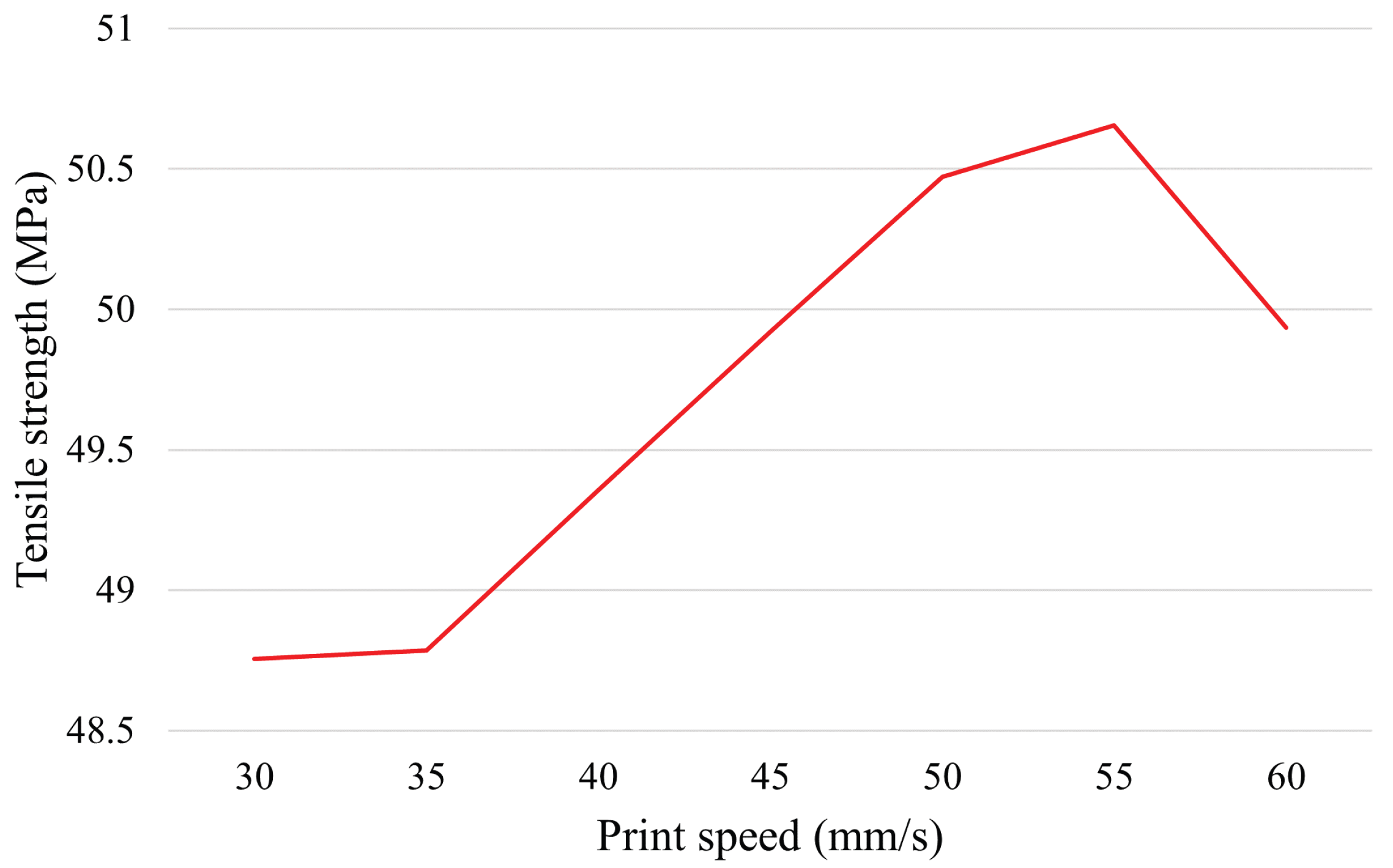
Extrusion speed: speed at which extruded filaments are deposited.
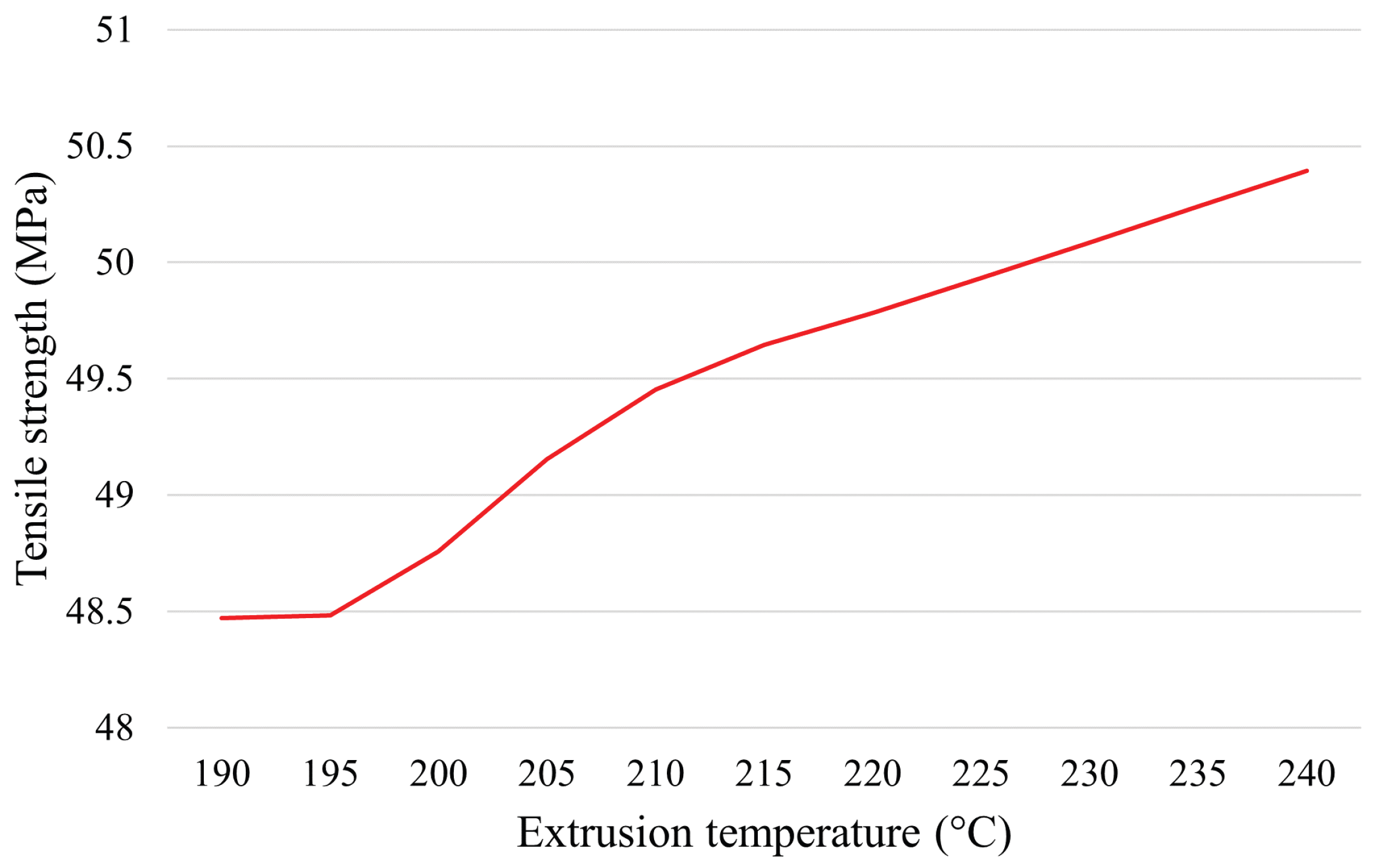
Extrusion temperature: temperature at which the filament is deposited.
Platform temperature or bed temperature: temperature of the surface of the table/bed where the printing is carried out.
Environmental conditions: temperature and humidity of the printing environment.
Due to this large number of factors that can influence the manufacture of parts produced by 3D printing, physical and mathematical formulations become challenging to develop [
14].
2.2. Artificial Neural Networks
Artificial neural networks are a computational representation of an information processing system with characteristics similar to biological neural networks, inspired by the functioning of the human brain [
15].
The artificial neuron is the basic processing unit of an ANN, its first model being proposed by McCulloch and Pitts in 1943 . In the model in question, the dendrites are represented by
n inputs
,
,⋯
. The axon is characterized by the
y output. The synapses (connections between neurons) are responsible for defining the intensity of each input signal, being represented by the synaptic weights
,
,⋯
, each one associated with its respective input. The nucleus and the cell body are responsible for handling the inputs and calculating the weighted sum
u of the inputs, in addition to verifying if this sum exceeds the threshold
; if it exceeds, the neuron fires a
y signal. Otherwise, no signal is fired. Some methods based on the McCulloch and Pitts model allow for different output signals. For this result, different activation functions were defined, such as linear, sigmoid, hyperbolic tangent, inverse tangent and ReLU, among others [
16].
There are some types of networks, the most common being perceptron, Kohonen, Hopfield and ART [
17]. In this paper, we applied the perceptron type ANN. The basic unit of this type of network is the simple perceptron, which works by receiving a set of input data and a bias, weighted by their respective synaptic weights. Then, the sum of these data is calculated, and then the activation function is triggered; the result sorts the input set between two different groups.
However, the simple perceptron has some limitations. This type of network has problems classifying sets that are not linearly separable, or even when this separation is not well defined. For this type of situation, it is more appropriate to use the multilayer perceptron (MLP) network.
MLP consists of an input layer, an output layer and one or more hidden layers between these two layers. Layers are intended to increase the network’s ability to model complex functions. Each layer in a network contains a sufficient number of neurons depending on the application. The input layer is passive and works by just receiving the data. The hidden and output layers actively process the data, the output layer being responsible for producing the results of the neural network [
18]. The MLP model has supervised learning by error correction, has more than one layer and is acyclic. The output of a neuron cannot serve as an input for any last neuron that is connected. Therefore, all neurons process each input. A propagation rule is given by the inner product of the inputs weighted by the weights with the addition of the bias term, and the output of the previous layer is the input of the current layer. It is important to note that, in this type of network, there may be more than one hidden layer, in addition to different numbers of neurons in each layer [
5].
Only a training set and arbitrary synaptic weights are not enough for a neural network to classify or predict values closest to an actual situation. For this, it is necessary to carry out training. The weights are adjusted, better describing the condition addressed. The training of an MLP network is usually divided into a few steps, called the feedforward step (forward phase) and the backpropagation with the adjustment of the weights (backward phase) [
19].
The backpropagation algorithm is one of the most used tools for ANN training. However, in some practical applications, it may be too slow.
Suppose, for example, that there are t training samples, f features and h hidden layers, each containing n neurons and o output neurons. The time complexity of backpropagation is O(), where i is the number of iterations. Since backpropagation has a high time complexity, it is advisable to start with a smaller number of hidden neurons and a few hidden layers for training. Note that Big-O quota is a mathematical notation that describes the limiting behavior of a function when the argument tends towards a particular value or infinity.
Even with a finalized optimization, ANNs can run into other problems, such as underfitting and overfitting. These two errors are more commonly seen in the construction of neural networks. They are the trend error and the variance error. The bias error arises because the network tries to describe a generalized behavior for its data, which does not suit the noise sufficiently and dictates a simplified trend.
The network is tied to noise in the variance error and generates an excessively complex model. Combining a high trend error with a low variance error generates underfitting, where the developed model is straightforward, not fitting the points and, consequently, not correctly describing the natural phenomenon. When the opposite happens—that is, the model has a low tendency and high variance—overfitting is generated, where the network adapts excessively to the training data and loses the ability to generalize to points outside of the training set [
17].
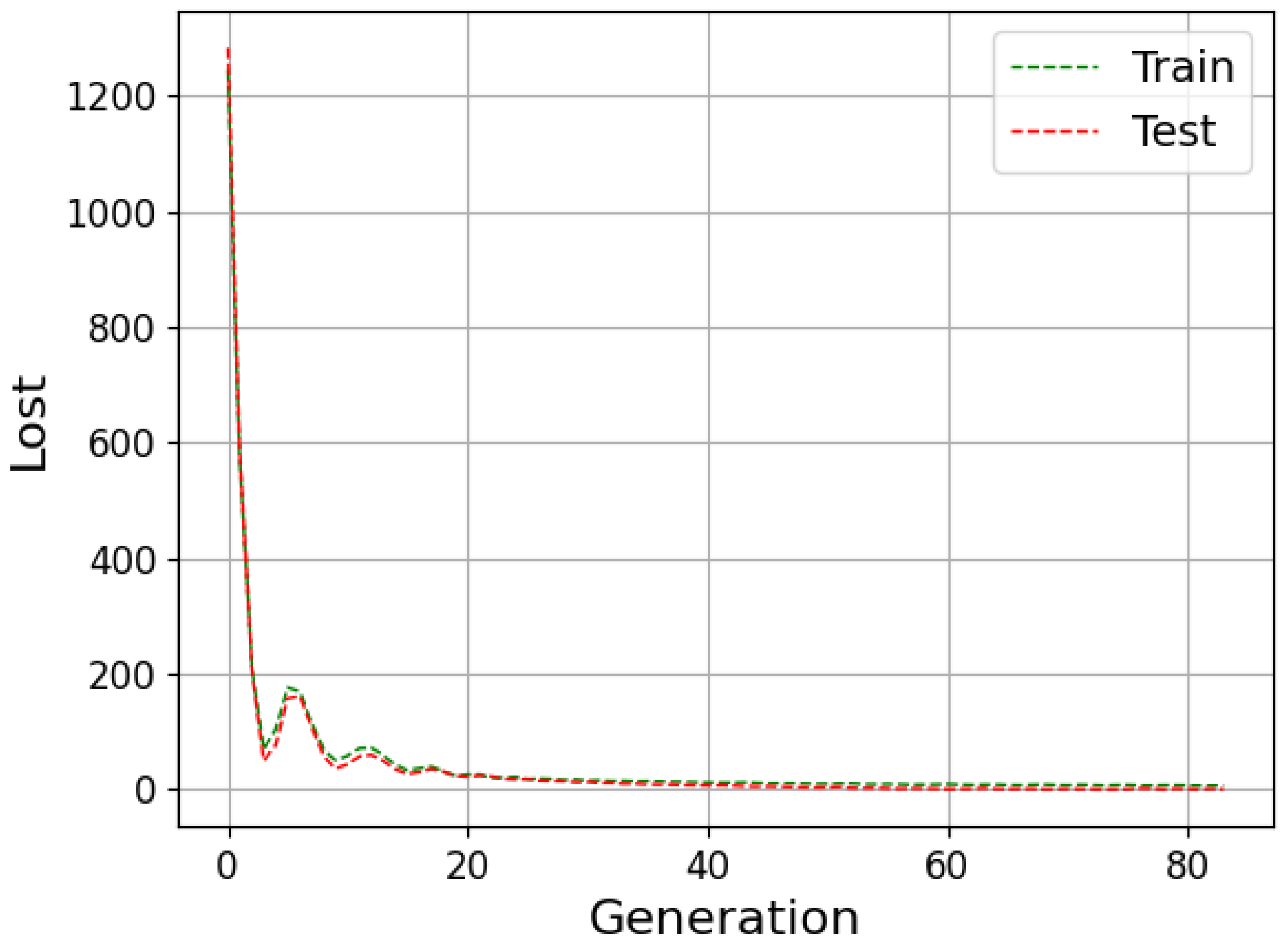
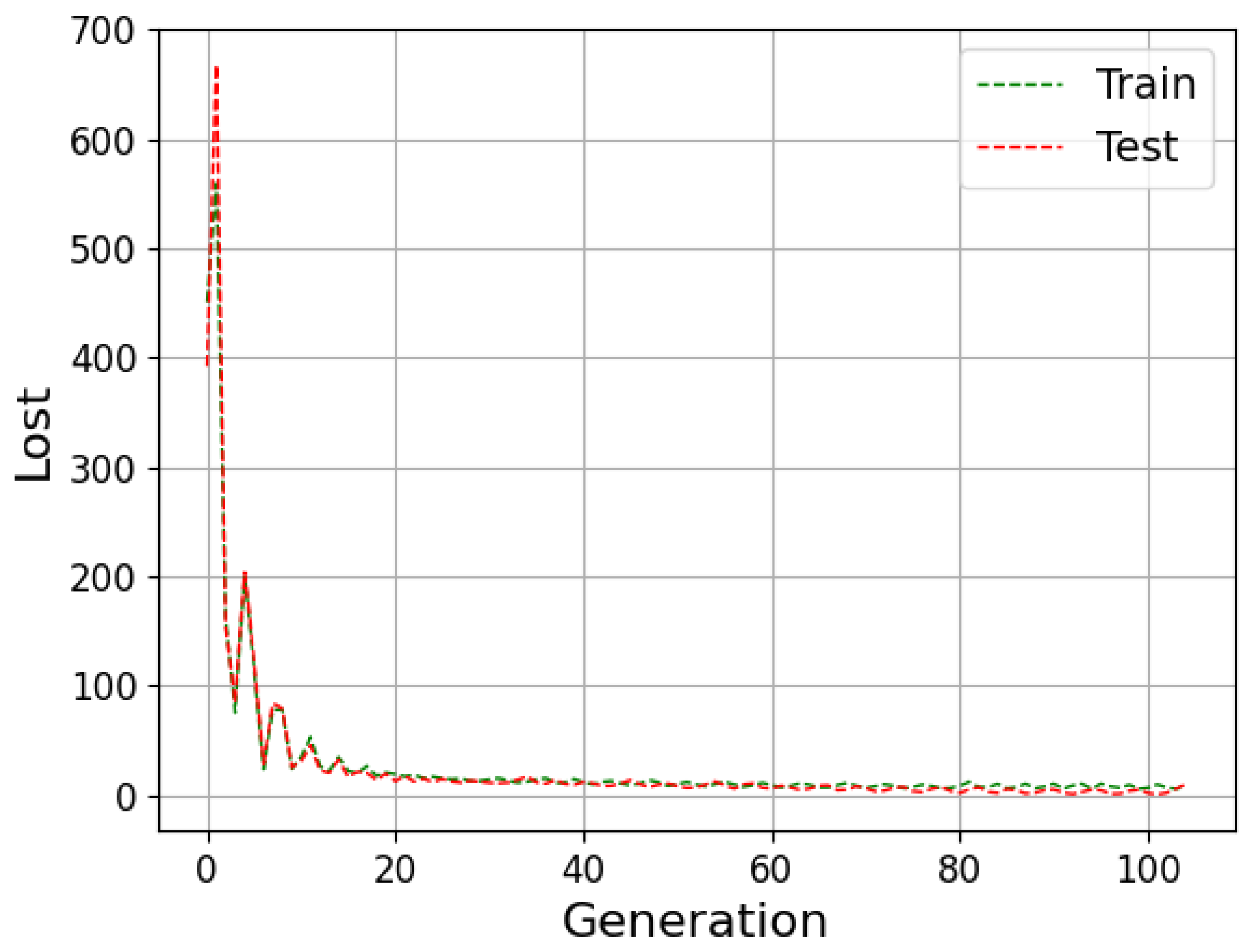
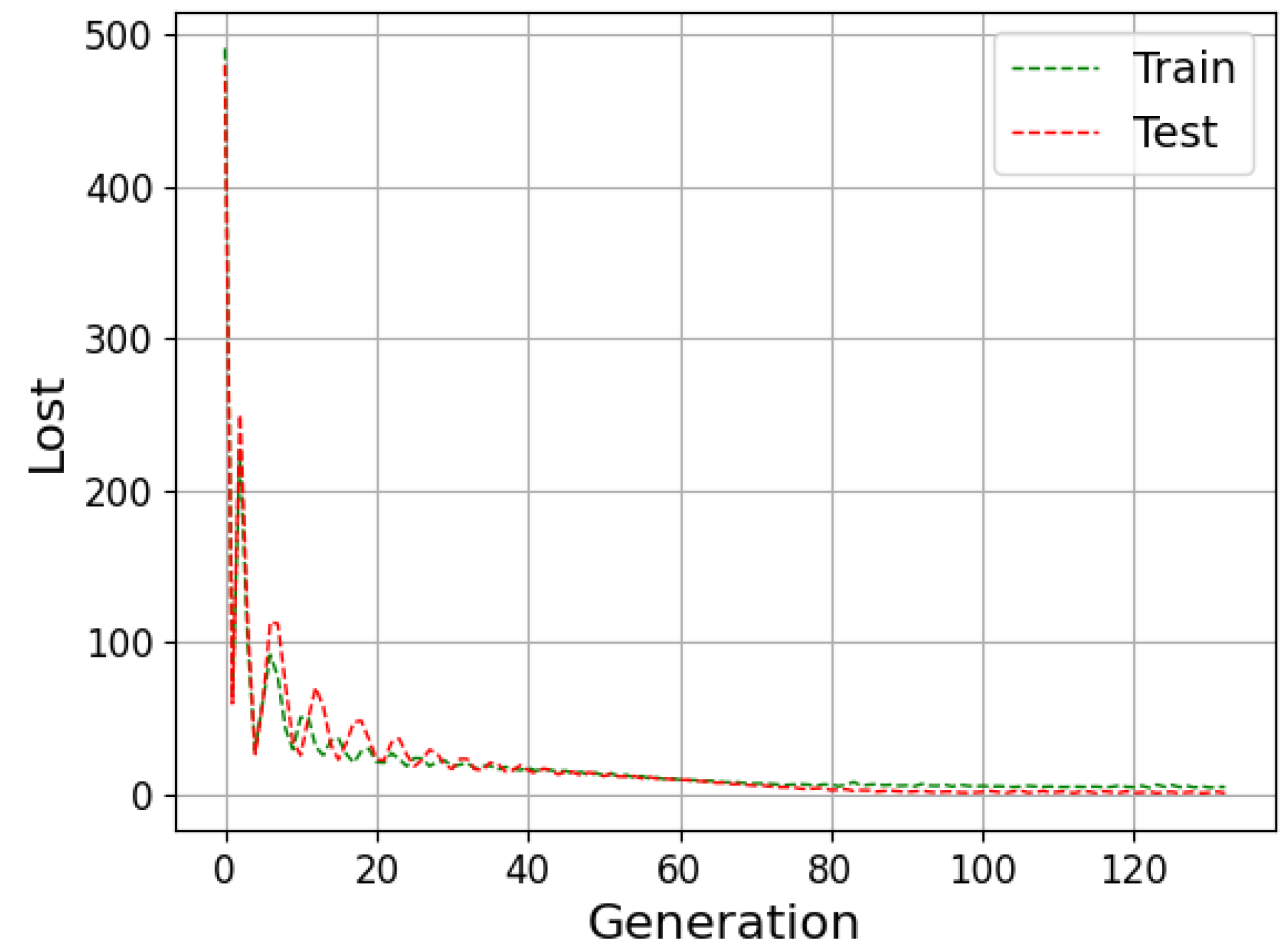
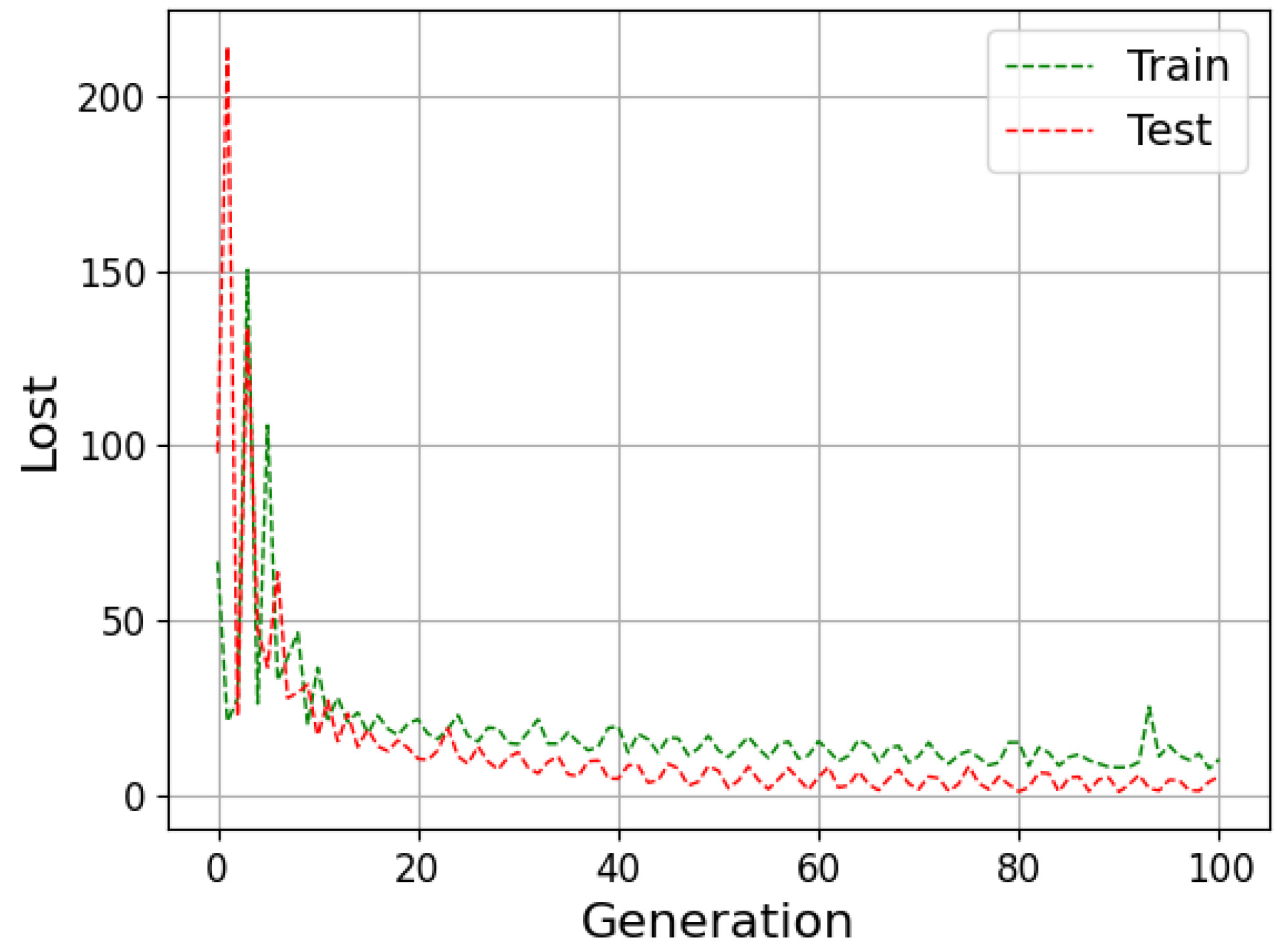
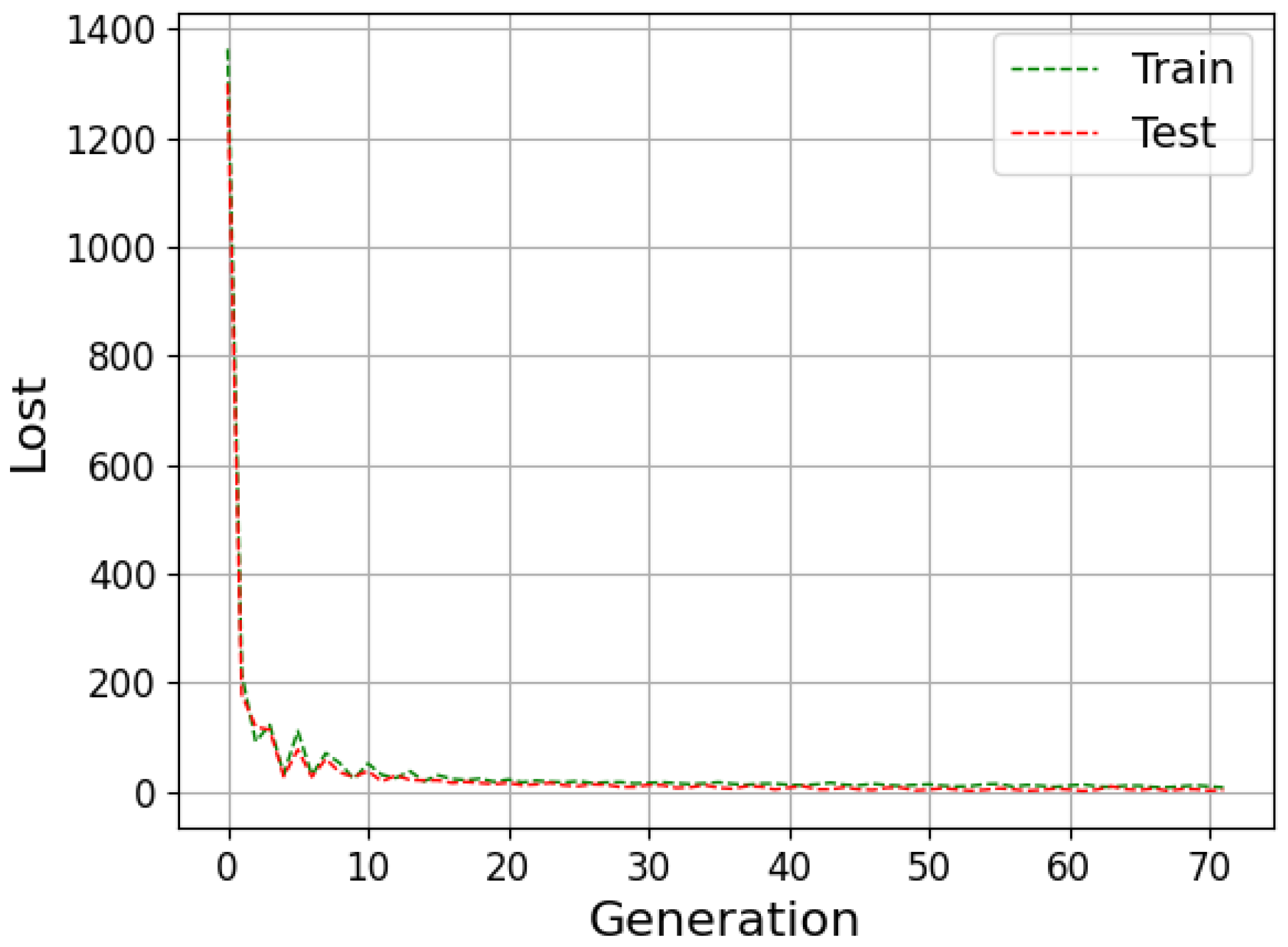
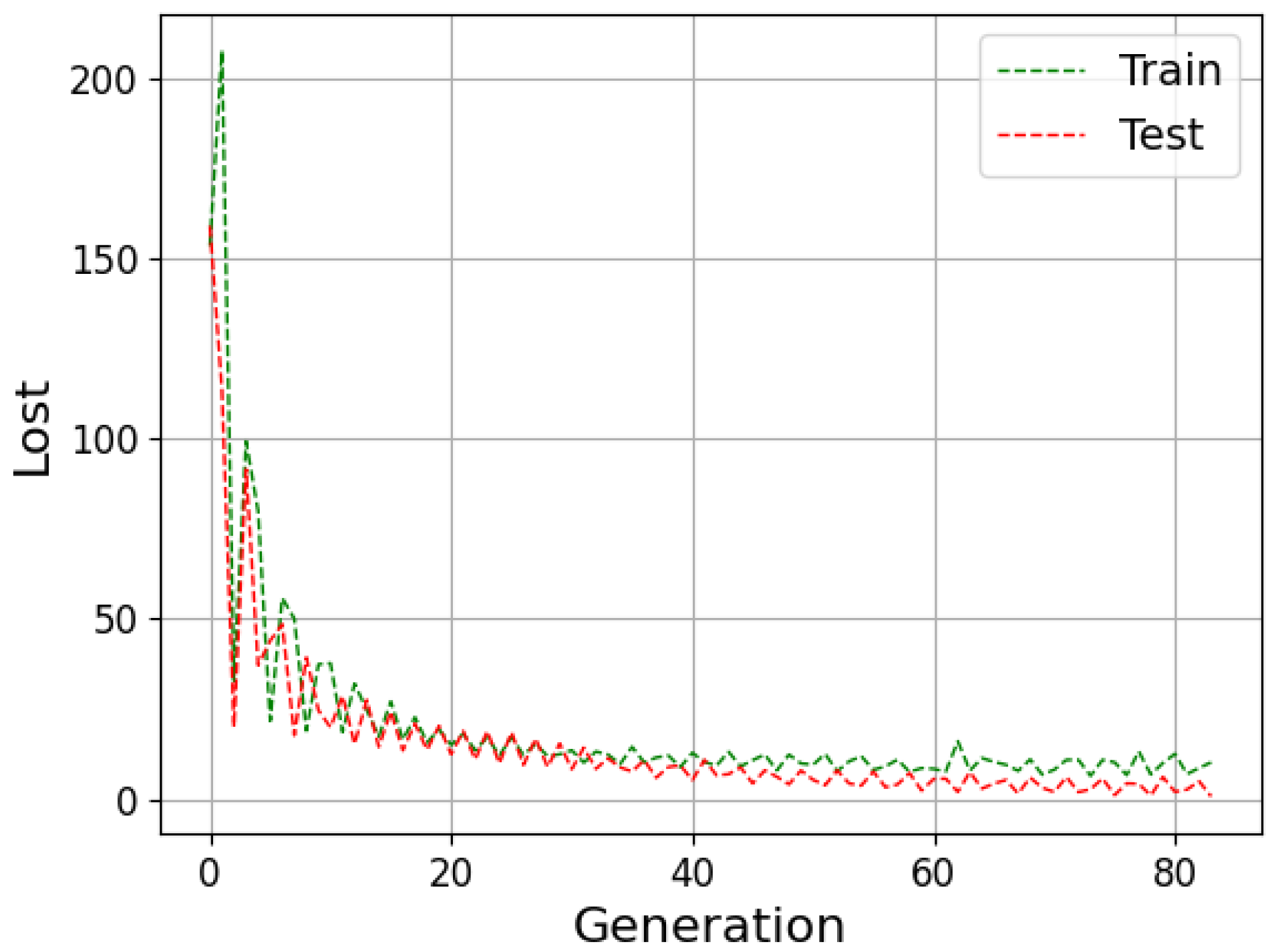
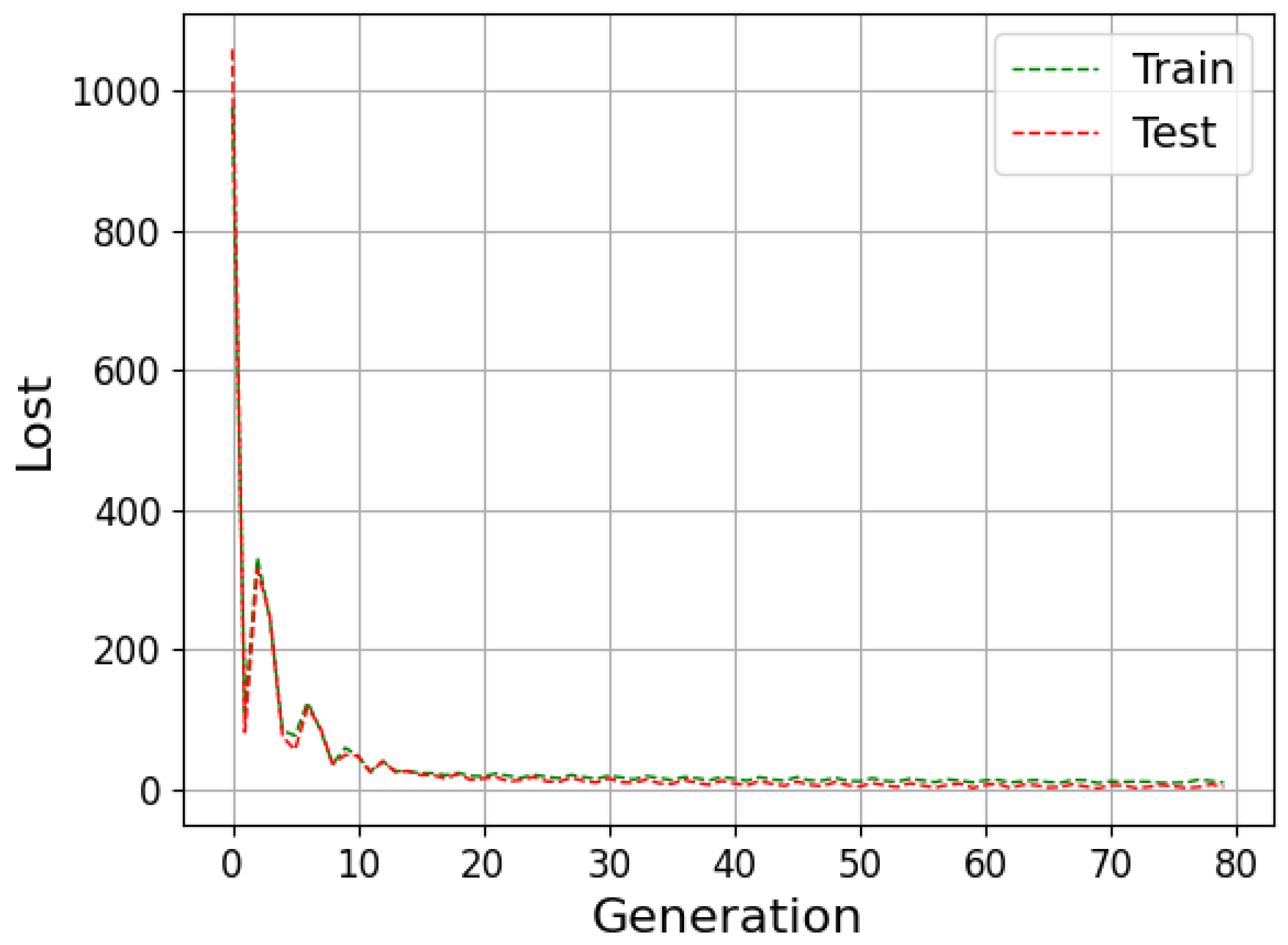
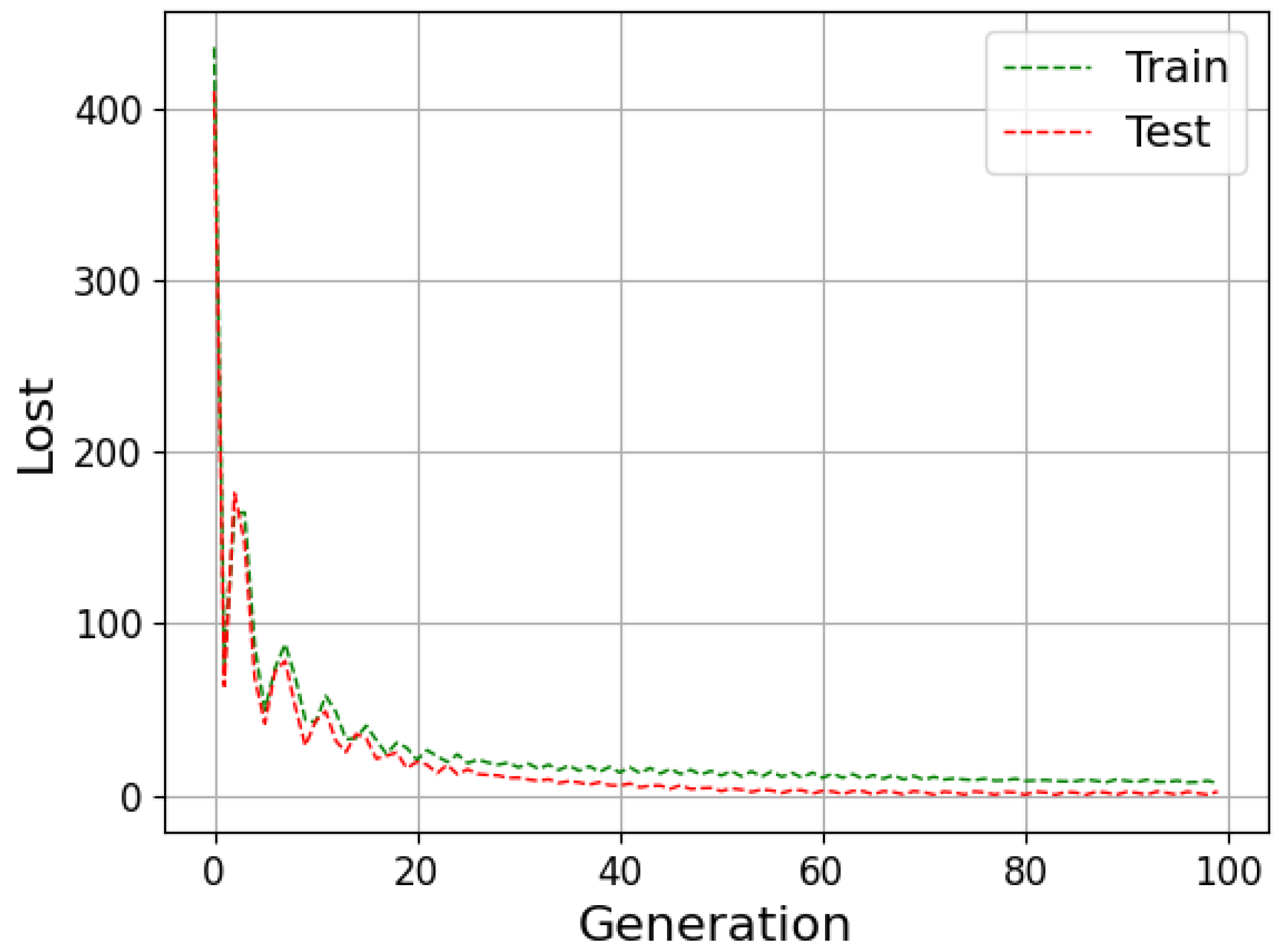
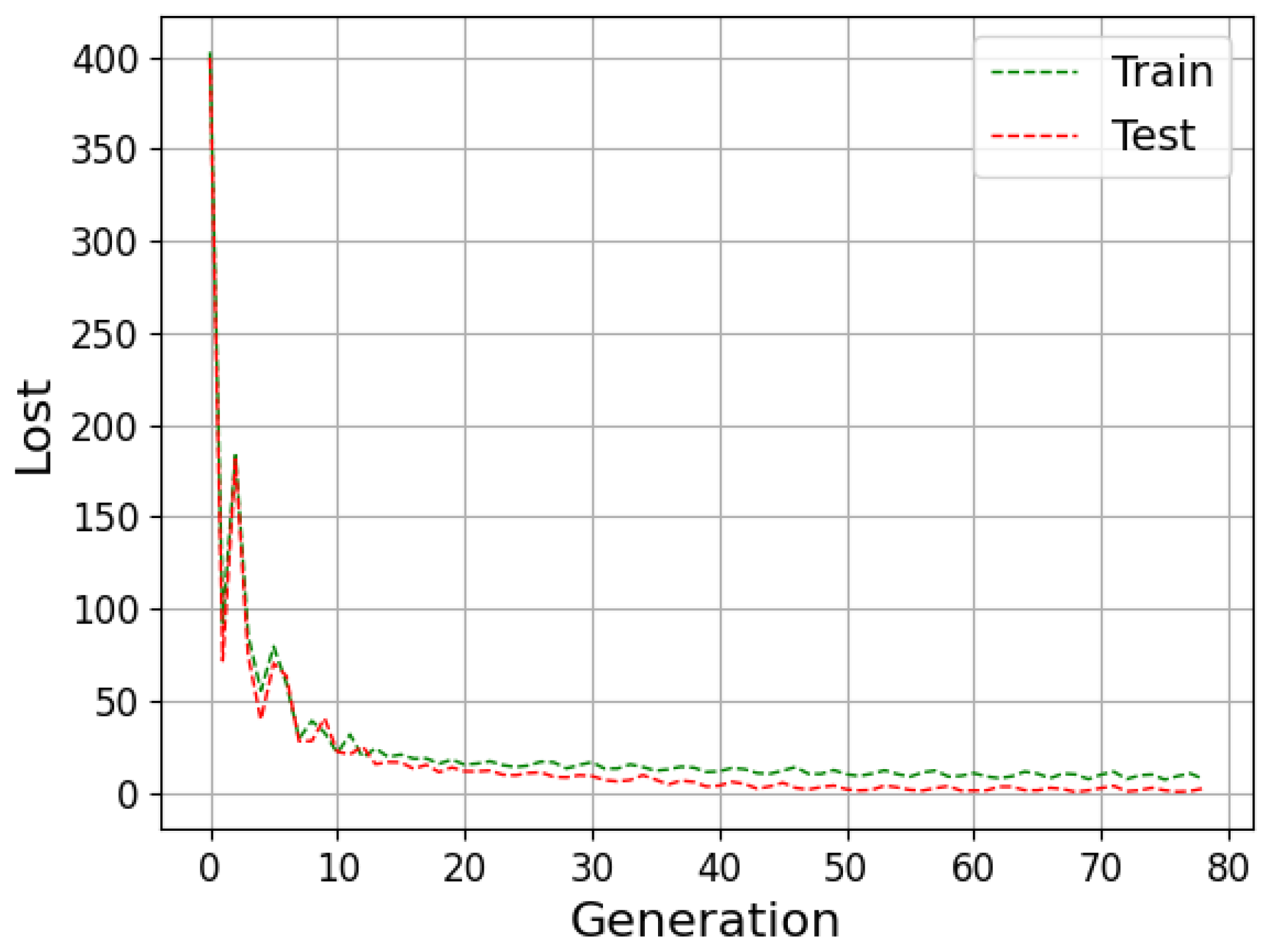
The neural network can be evaluated by its ability to fit the training data and predict data outside this set. The available data are generally divided into training, validation and testing to improve the model results. During the training stage, the outcomes calculated by the network are compared with the target (supervised learning); then, the weights are adjusted to approximate them. Then, in the validation step, the model undergoes a fine adjustment in the parameters, avoiding rigidity to the training data, thus reducing the chances of overfitting. Finally, the prediction is performed with the data that were separated for the test step, and then the result is compared with the absolute values [
20].
Underfitting represents when the model performs poorly on training and test data. In contrast, overfitting indicates that the model acted well on the training data but then struggled on the unrecognized inputs; this should not be the case, as both data groups came from the identical distribution. One of the ways to evaluate the model’s performance is the study of the learning curves. An analysis of the model with the training and test data can diagnose the possibilities of overfitting and underfitting [
21].
Many techniques have been explored to accelerate its performance, considering that it may fall into local minima. One of the potential treatments to escape from local minima is by operating a minimum learning rate, which slows down the learning process. In [
22], the authors present a new strategy based on the use of the bi-hyperbolic function, which offers greater flexibility and a faster evaluation time. On the other hand, we applied the genetic algorithm to the training of our neural networks.
2.3. Genetic Algorithm
The genetic algorithm (GA) is widely used in optimization, which simulates Darwin’s theory of evolution. GA differs from other methods in three main points:
This method works from a population of solutions to the problem.
This method does not depend on differential equations.
This method uses probabilistic and non-deterministic rules.
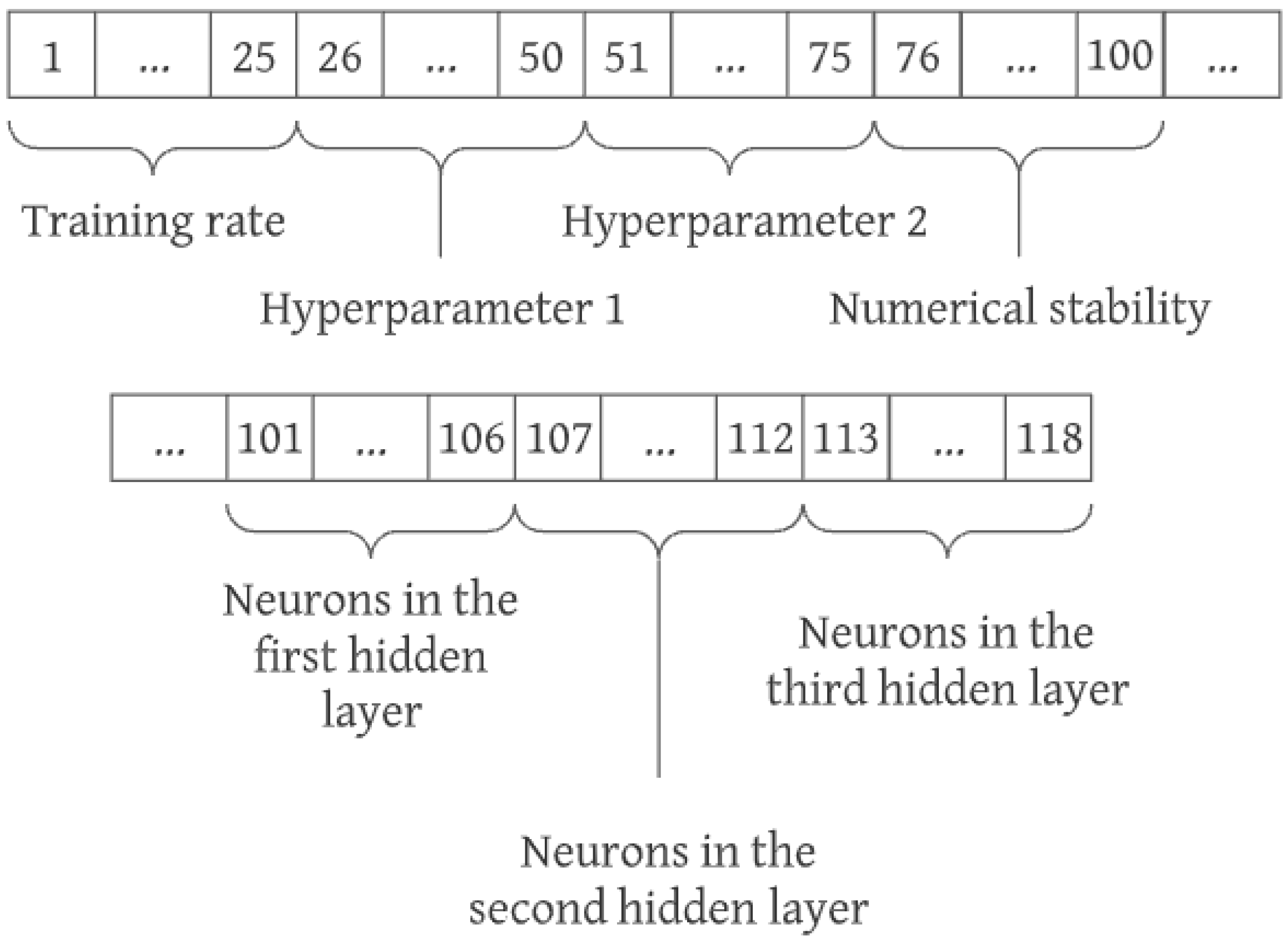
The GA starts from a set of possible solutions to the problem addressed. This set is known as the population. Each individual in this population is characterized by the chromosome, the set of values that solve the problem. Each of these values is known as a gene. Each gene can be encoded in different ways, such as in binary, integer, double precision or other ways [
23,
24].
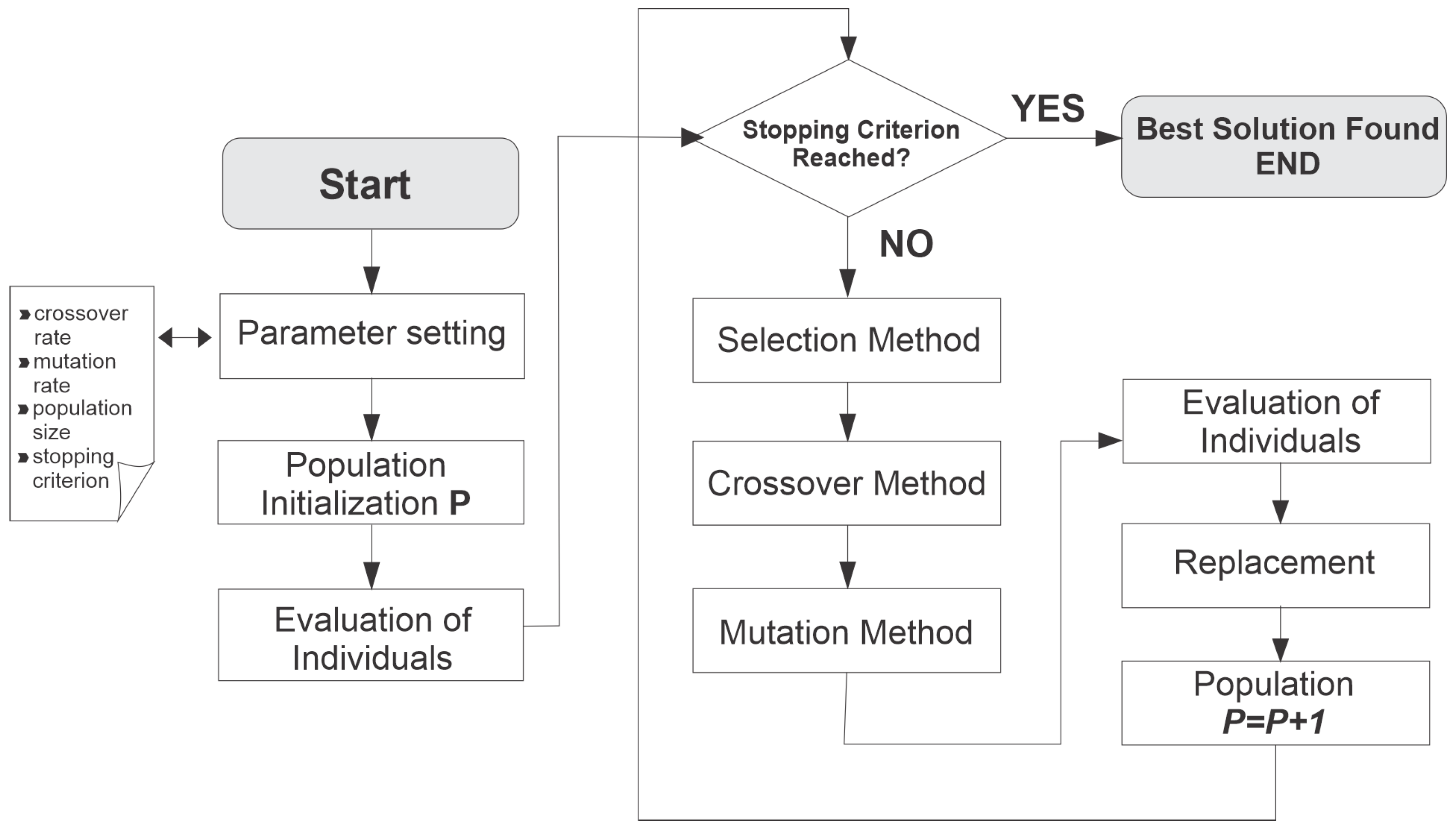
Figure 2 presents the GA process flowchart.
The zero-step process is the generation of a population with an amount
N of individuals, where each one of them has
i genes. The value of each gene must be generated randomly, and its encoding depends on the problem at hand [
24].
After the initial population is generated, the evolutionary process begins. The first step is the aptitude assessment or calculation. At this point, the adaptation degree of each individual is calculated. As each solution set improves, it tends to the desired response, thus offering the GA an aptitude measure of each individual in the population. Together with the chromosome coding, this step is the most dependent on the problem addressed, varying for each case. The choice of the fitness function is critical to the success of the algorithm [
6].
Then comes the crossing or reproduction step (crossover). This process creates more fit populations, with better solutions, from the individuals selected in the previous step. In this method, the individual’s temporary sets are separated into pairs, and if a specific number (crossover rate), randomly generated between 0 and 1 for each pair, is greater than the probability of mating, then the pair, known as parents, goes through the process of reproduction, giving rise to two new individuals, the children, who will make up the new population [
24].
Behind the crossover step, the mutation process takes place. The mutation operator is necessary for introducing and maintaining the population’s genetic diversity, arbitrarily altering one or more components of a chosen structure, thus providing means for introducing new elements into the population. In this way, mutation ensures that the probability of reaching any point in the search space will never be zero, in addition to circumventing the problem of local minimums [
6].
In most GA applications, all individuals in a population are replaced by new ones, but some of the previous population is propagated to the next generation. That is, not the entire set is renewed. There are also cases where the population size varies according to the generation. At the end of each generation, a population is generated with individuals that are, for the most part, more fit than the individuals of the previous generation [
25].
There are some stopping criteria for the genetic algorithm. The main ones are the number of generations or the degree of convergence of the current population. After each generation, the population passes an evaluation, and if the pre-established criterion is fulfilled, the algorithm stops. At the end of the algorithm’s execution, the population will contain the individuals that best fit as a solution to the problem studied, thus optimizing the practical case, be it maximization or minimization.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








