1. Introduction
There are many cases in which one is interested in forecasting the behavior of a chaotic system; an emblematic example is meteorology. The main obstacle is, of course, that in chaotic systems, by definition, a small uncertainty can amplify exponentially over time [
1]. Moreover, even if one assumes that a computational model of a natural, chaotic system is a good model, the exact values of parameters are needed to ensure a faithful representation of dynamics.
Schematically, one can assume that the natural, or target, system is well represented by some dynamical system, possibly with noise. One can measure some quantities of this system, but in general, one is not free to choose which variable (or combination of variables) to measure, nor to perform measurements at any rate.
On the other hand, if one has a good knowledge of the system under investigation, i.e., it can be modeled with good accuracy, then a simulated “replica” of the system can be implemented on a computer. If, moreover, it is possible to know the parameters and the initial state of the original system, in order to keep the replica synchronized to it (when running at the same speed), then the replica can be used to perform measurements that are otherwise impossible, and to obtain accurate forecasting (when run at higher speeds).
In general, the problem of extracting the parameters of a system from a time series of measurements on it is called data assimilation [
2].
The problem in data assimilation is that of determining the state and the parameters of the system by minimizing an error function between data measured on the target and the respective data from the simulated system. A similar task is performed by back-propagation techniques in machine learning [
3,
4].
The goal of this paper is to approach this problem from the point of view of dynamical systems [
5]. In this context, the theme of synchronization has been explored [
6], but it needs to be extended in order to cover the application field of data assimilation.
The synchronization technique is particularly recommendable when the amount of noise (in the measure and intrinsic to the system) is small, i.e., when the target system can be assumed to be well represented by deterministic dynamics, even if these dynamics are not continuous (as in Cellular Automata [
7]).
We shall investigate here the application of synchronization methods to the classic Lorenz system [
8]. However, the method can be applied to other chaotic systems and possibly to their implementation in electronic hardware.
The Lorenz system is chosen because, for classical values of parameter, there is only one chaotic attractor. Other systems, such as Chua’s [
9,
10], may present the coexistence of attractors (hidden attractors) [
11,
12], which may affect synchronization [
13].
Our investigation is carried out considering some synchronization schemes; see
Section 2.
We start from the classic Pecora–Carrol master–slave synchronization scheme, recalled in
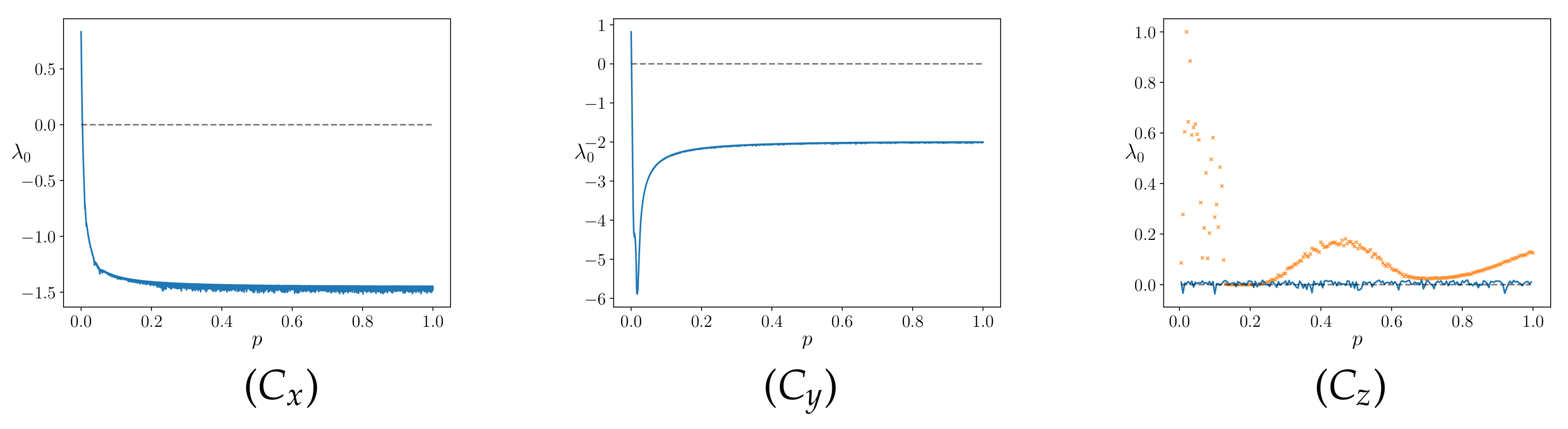
Section 2.1, in which the values of some of the state variables of the master are imposed to the corresponding variables of the slave system. This choice of coupling variables is denoted “coupling direction” in the tangent space of the system.
The synchronization threshold is connected to the value of the conditional Lyapunov exponent [
14,
15], i.e., the exponential growing rate along the difference space between master and slave, as reported in
Section 2.2.
This scheme is then extended to partial synchronization, i.e., to the case in which only a portion of the values of the state variables of the master system signal is fed to the slave, as shown in
Section 2.3. We can thus establish the minimum fraction of signal (coupling strength) able to synchronize the two replicas, which depends on the coupling direction.
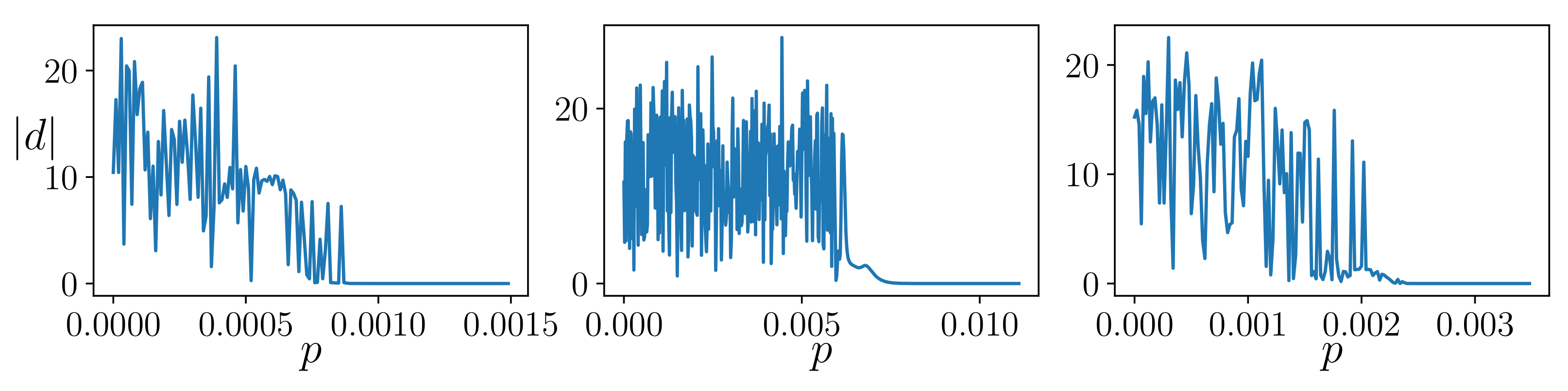
However, one cannot pretend to be able to perform measurements in continuous time, as achieved in the original synchronization scheme, in which the experimental reference system was a chaotic electronic circuit.
Therefore, we deal with the problem of intermittency, i.e., performing measurements, and consequently applying the synchronization scheme, only at certain time intervals. We show that the synchronization scheme also works for intermittent measurements, provided that the coupling strength is increased, as shown in
Section 2.4.
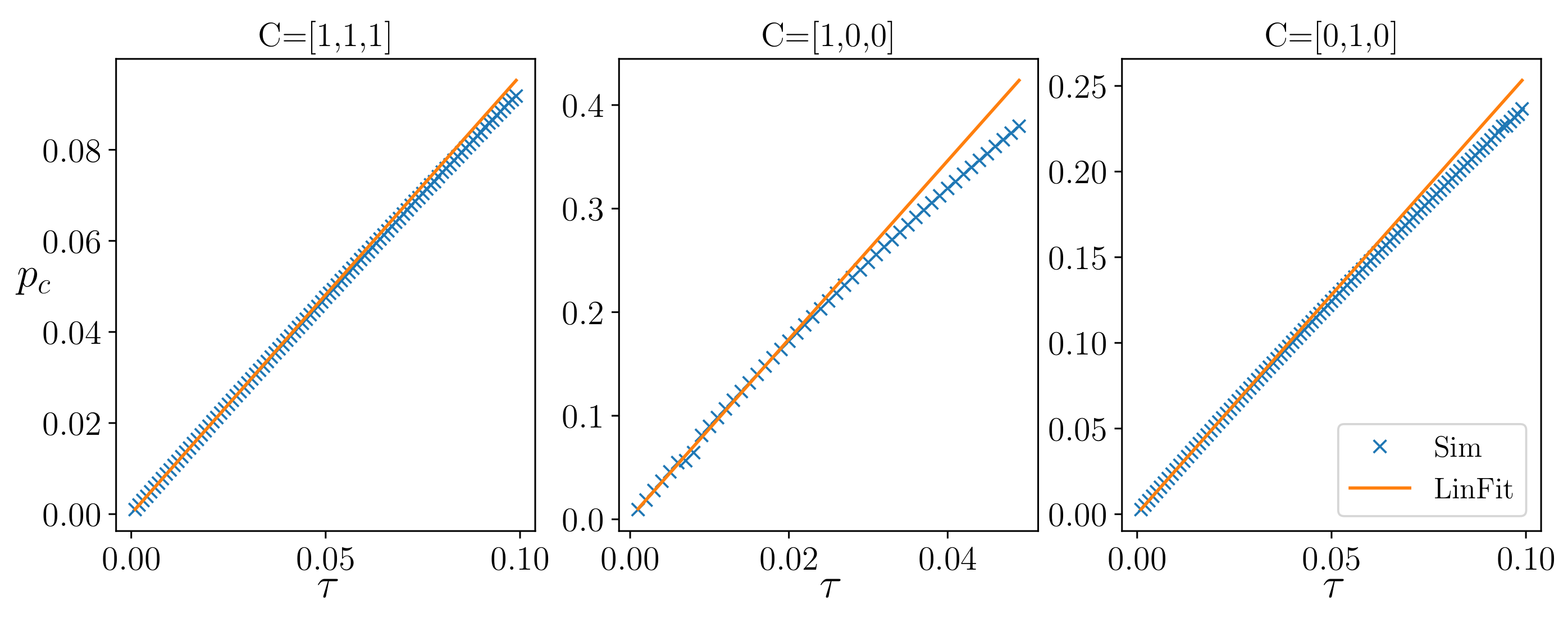
In the case of systems with different parameters, synchronization cannot be complete, and we discuss generalized synchronization; see
Section 2.5.
We report some results in
Section 3, showing that the distance among systems can be interpreted as a measure of the error and exploited to obtain the “true” values of parameters, using a simulated annealing scheme.
Finally, it may happen that the variables of the systems are not individually accessible to measurements, a situation which prohibits the application of the original method. In this case, one can still exploit schemes inspired by statistical mechanics, such as the pruned and enriching one, simulating an ensemble of systems with different state variables and parameters, selecting the instances with lower rates of error, and cloning them with perturbations. This kind of genetic algorithm is able to approximate the actual values of parameters, as reported in
Section 4.
4. Pruned-Enriching Approach
The previous scheme cannot be always followed, because we assumed the ability to measure some of the variables of the master system and inject this value (at least intermittently) into the slave one.
However, this might be impossible, either because the state variables
are not accessible individually, or because those that are accessible do not allow synchronization (for instance, if only the
z variable is accessible, as illustrated in
Section 2.3).
We can benefit from the Takens theorem [
21], which states that the essential features (among which is the maximum Lyapunov exponent) of a strange attractor
can be reconstructed by intermittent observations
using the time series
as surrogate data, provided that their number is larger than the dimensionality of the attractor [
22]. Other conditions are that the observation interval
must be large enough to have observations
sufficiently spaced, but not so large that the
are scattered along the attractor, making the reconstruction of the trajectory impossible. It is therefore generally convenient to take an interval
substantially larger than the minimum
, but of the same order of magnitude.
An interesting point is that one can choose for
f an arbitrary function of the original variables, provided that their correspondence is smooth. We therefore employed a method inspired by the pruned-enriching technique [
23,
24], or genetic algorithm without cross-over [
25].
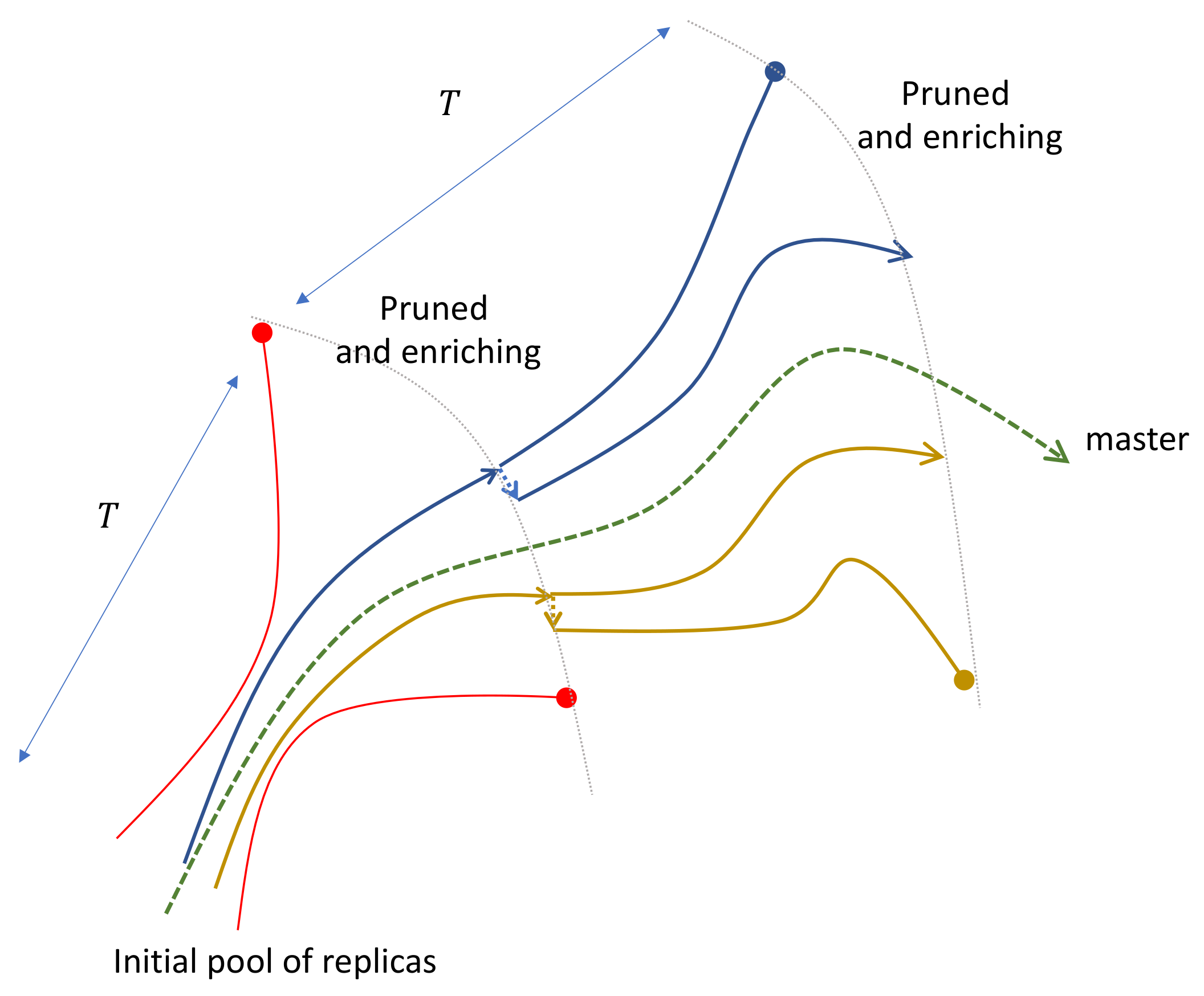
We assume that we can only measure a function of the master system, at time intervals . The master system evolves with parameters .
We simulate an ensemble composed by h replicas, each one starting from state variables () and evolving with the same equation as the master one, with parameters , where . At the beginning, and are random quantities.
We let the ensemble evolve for a time interval
T, and then we measure the distance
. We sort the replicas according to
and we replace half of them with larger distances, following an evolutionary law based on a cloning and perturbation scheme, as shown in
Figure 6. For a more detailed description of the procedure, we can refer to Algorithms 1 and 2.
We assume that we have at our disposal a time series measured on some experimental system. For this simulation, we generate the time series by taking a set of measures , for , where is the length of the simulated time series.
We then map the time series in an embedding space of size
defined by the vector
,
. We randomly initialize the state values of the
h replicas,
and the initial values of their parameters
,
, in a range that is consistent with the physical values.
| Algorithm 1 Pruned-enriching algorithm |
Require:
for
do
for do
if then
▷Algorithm 2
end if
end for
end for
return
|
| Algorithm 2 Parameter updating step |
Require:
▷ return index of d sorted in ascending order
for
do
if then
while do
end while
else
end if
end for
return
|
To create the initial embedding vectors , , we evolve the replica ensemble for a time interval so that for each replica we can build the first elements of their time series.
We can then start the optimization procedure. For a number of repetitions M, we evolve the ensemble using a time step , up to time . At each interval , we update the embedding vector , substituting the oldest measurements with the new ones and computing the Euclidean distances between the and the reference computed on the master system.
Notice that, for , we rescan the time series from the beginning, reinitializing the random conditions of the replicas as in the first repetition but without changing their parameters, and we recompute the initial vector , , evolving the ensemble members up to time .
The distance is used as the cost function of our optimization problem. In the parameter updating step (Algorithm 2), we sort the elements of the set in ascending order according to and replace the second half of the set with a copy of the first half, with either a random perturbation of amplitude in one of the parameters or a random perturbation of the state variables; see Algorithm 2.
We add some checks in order to be sure that the values of parameters are not inconsistent (in our case, all the need to be positive). After that, we compute , the estimated parameters, as the average of the first half of the ensemble elements with an associated ensemble error.
Because this procedure depends on the extraction of random numbers, it can then be repeated to estimate the consequent statistical error on parameters.
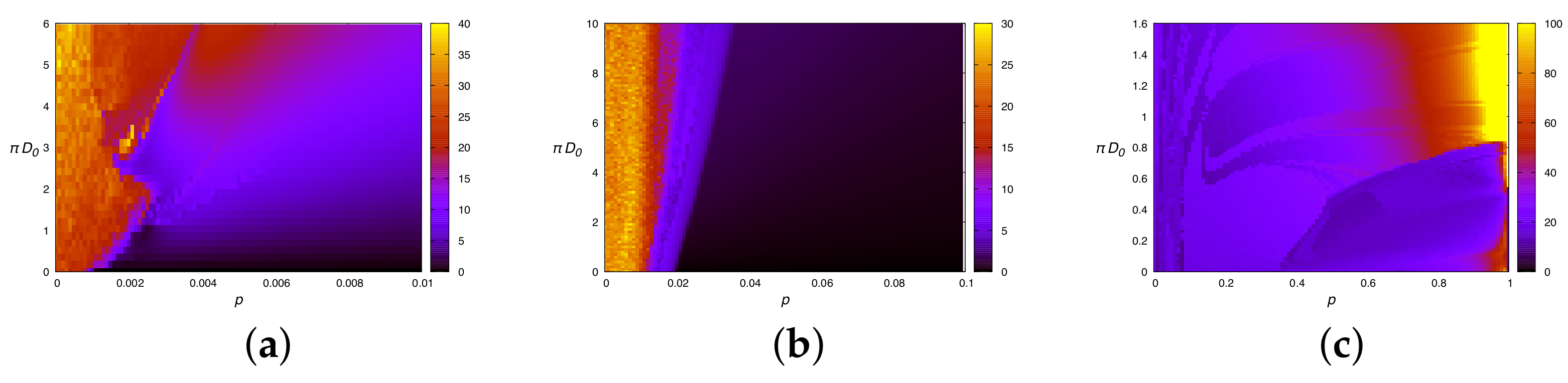
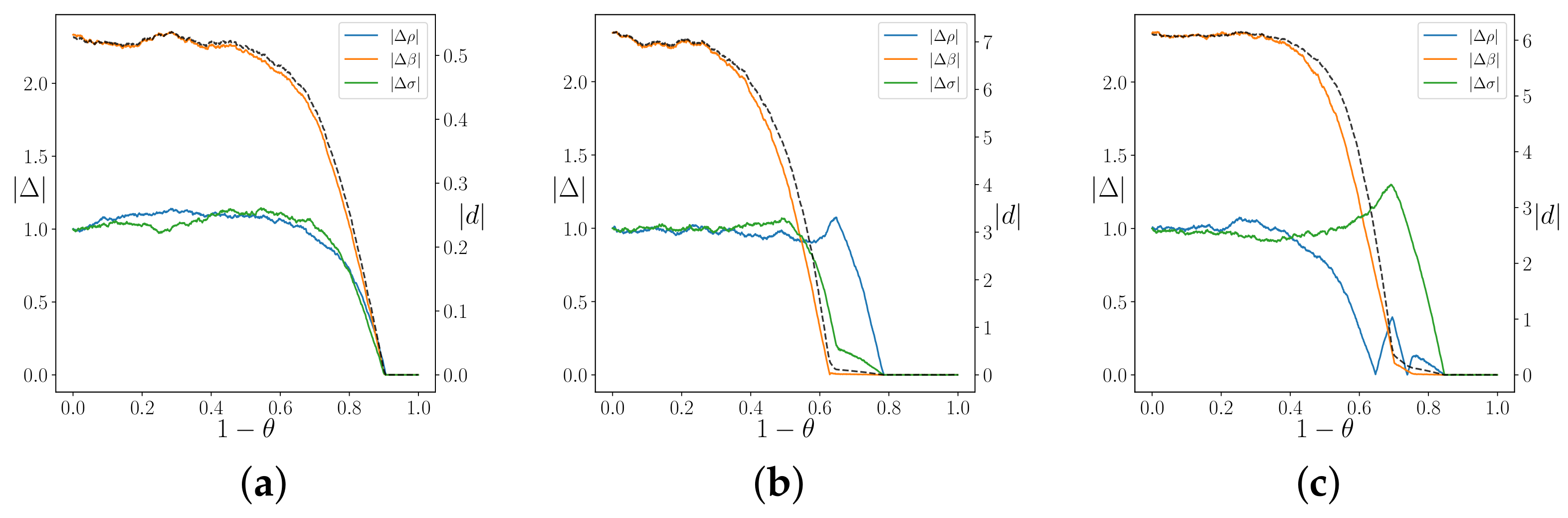
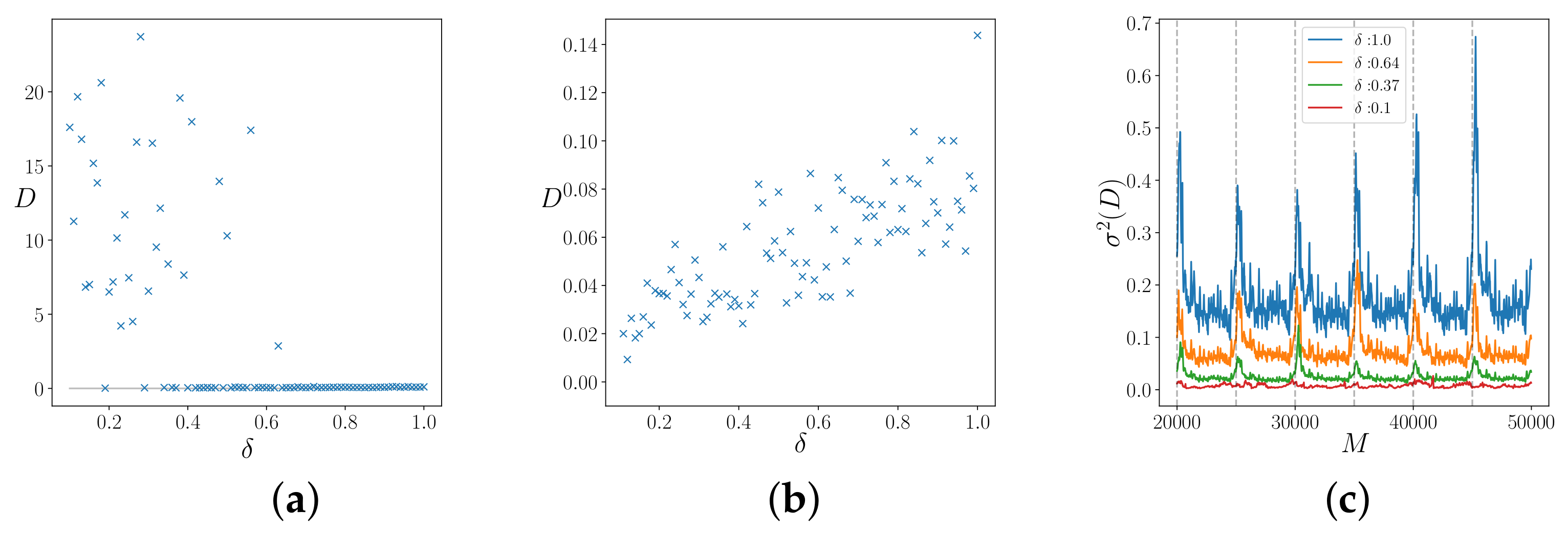
We analyze the convergence problem for different values of . We assume that only the x component of the real system is accessed, i.e., our measurement function is simply . We evolve the system up to with the time step , and we measure every . We embed the system in a embedding space of dimensions .
The ensemble is composed of
replicas, and we repeat the procedure for
times. The final results are shown in
Figure 7. In
Figure 7a, we initialize the ensemble parameters randomly in the interval
, and we measure the distance
D in the parameters space (Equation (
22)) for different
. Notice that, starting from a large initial distance, larger values of
are more effective for the convergence. The opposite phenomenon is reported in
Figure 7b. Here, we assume that the true parameter values are approximately known with an error
, and we test the dependence of the amplitude
in a fine-tuning regime. In this case, starting from a relatively small distance, smaller values of
are more effective.
In
Figure 7c, we instead show the behavior of the variance of the parameter distance
D during optimization for different amplitudes
. With a small amplitude
for the parameter updating step, the elements of the ensemble rapidly converge to the local minimum before having explored the parameter space sufficiently, so small amplitude values of
can be useful only for a fine-tuning approach. Using large values of
instead is helpful for better exploration of the parameter landscape, and allows us to converge to the true values, but with noisy results. These considerations suggest the use of an adaptive value of the parameter
.
Inspired by these results, we modify the updating rule, introducing a variable amplitude
, where, for every ensemble member
i,
. Then, for each replica, we define an amplitude that modulates the variation step in a self-consistent manner. To test this choice, we simply put
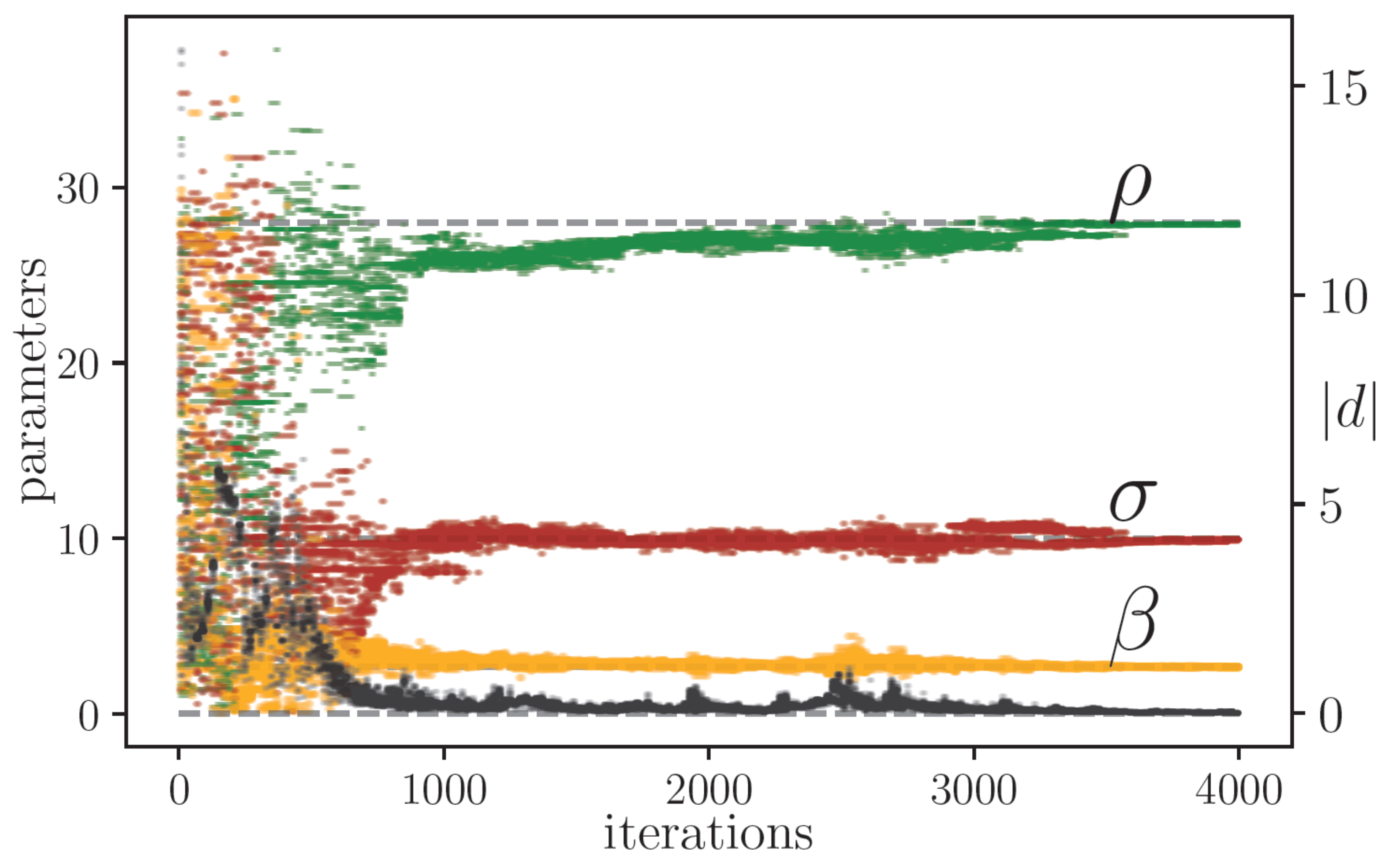
In
Figure 8, we plot the behavior of 50 randomly chosen ensemble members in the pruned-enriching optimization problem with the amplitude factor
, defined as in Equation (
24). We assume the situation to be the same as those of the last simulations, so we measure the real system only in the
direction every
. The ensemble dimension is equal to
, and we choose the embedding dimension
. In this simulation, we run the algorithm for
repetitions. The numerical results are reported in
Table 2.
We averaged these measurements over
repetitions in order to estimate the influence of the stochastic elements of Algorithm 2. The results are reported in
Table 3. It can be noticed that the values of the standard deviation over repetitions are essentially the same of those over ensemble, in
Table 2, divided by
, implying that the ensemble is self-averaging (i.e., averages over larger ensembles give the same results as averages over repetitions).
The pruned-enriching procedure is similar to a genetic algorithm without cross-over. In general, a cross-over operation aims to combine locally-optimized solutions, and depends crucially on the coding of the solution in the “genome”. When the cost function is essentially a sum of the functions of variables coded in the solution in nearby zones, the cross-over can indeed allow a jump to an almost-optimal instance.
In this case, we encode the parameters simply using their current values (a single genome is a vector of 3 real numbers), so there is no indication for this option to be present. It is, however, possible to pick parameters from “parents” instead of randomly altering them, i.e., performing “gene exchanging”. Because the pool of tentative solutions is obtained by cloning those corresponding to the lowest distances from the master, we expect little improvement using parameter exchange.
To add gene exchanging to our procedure, we modify the algorithms such that, for every element of the second half of the ensemble, we choose randomly whether to update the parameters as in Algorithm 2 or perform the gene exchanging step, generating the new replica from two parents randomly chosen from the first half of the ensemble. Children randomly inherit two of the parameters from one parent and one from the other.
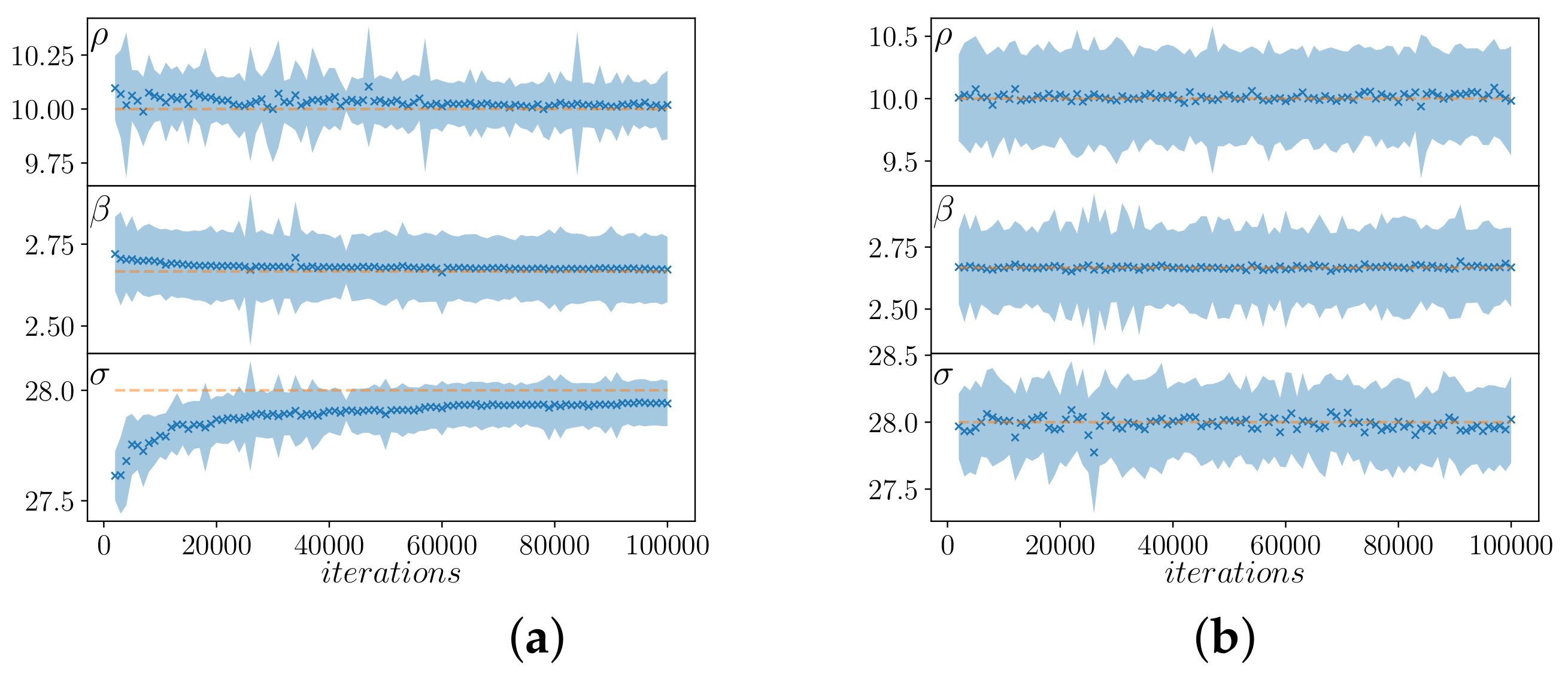
With no prior information about the true parameter values, we randomly initialize the initial states and the parameters. Therefore, using the gene exchanging operation can introduce a bias in the early stages of the optimization problem, as can be seen in
Figure 9, where we compare the estimated parameters for different repetitions using an amplitude
with (
Figure 9a) and without (
Figure 9b) gene exchanging. As in the other simulations, we randomly initialize the initial states and parameter values of the ensemble, we evolve the system, after the transient time
, up to
with
, and we assume that it is possible to measure the
x direction with
.
The gene exchanging operation allows jumps to be made in the parameters space, but, in the early stage of the optimization process, these jumps can cause the ensemble to converge on the wrong values. On the other hand, gene exchanging can reduce the variance of the ensemble estimation, so it can help in the final steps, or for fine tuning. Future work is needed to explore this option in more detail.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}