1. Introduction
Unsupervised clustering aims to group data into clusters in such a way that data within the same cluster are similar to each other, and data in different clusters are dissimilar.
K-means [
1,
2] is a widely used clustering algorithm due to its simplicity and efficiency. Another reason to prefer K-means instead of a more sophisticated algorithm is the fact that its properties and limitations have been thoroughly investigated [
3,
4]. Two main limitations of K-means are that (1) it operates on numerical data using Euclidean distance and (2) it requires calculation of the mean of the objects (centroid) in the set.
Dealing with data that have mixed numerical and categorical attributes or only categorical attributes is difficult [
5]. Such data can be handled either by preliminarily converting, most often in an unnatural way that can imply sparsity and multi-dimensional problem, categorical attributes to numerical ones, or by introducing a non-Euclidean distance function.
Adapting K-means to deal with data objects which are sets of elementary items [
6] poses similar problems to coping with categorical attributes. In addition, the need exists to handle sets of different sizes.
A histogram-based approach has been used for clustering categorical data [
5,
7] and recently for clustering sets [
8]. The idea is to use a histogram of the categorical values to represent the cluster. This eliminates the need to define the mean value. In the case of categorical data, the distance to the cluster can be defined based on the frequency of the category labels of the object in the cluster. In the case of sets, the distance between objects and the clusters can be derived from classical set-matching measures such as Jaccard and Otsuka–Ochiai cosine distance [
8].
As a practical example of an application of clustering sets, the records of medical patient diagnoses can be considered, where the goal is to find groups of similar patients to support the estimation of the risk for a patient to develop some future illness due to his/her previous medical history and from correlations to other patients with similar diseases.
In this paper, we propose a new approach for clustering sets which is based on K-medoids. Medoid is the object in the cluster having a minimum total distance from all other objects in the cluster. Then, all we need is a distance measure between the objects. Since both the data and the cluster representative (medoid) are sets, we can apply the classical set-distance measures slightly modified, as in [
8], by considering application-sensitive information.
We apply the medoid approach within two clustering algorithms: K-medoids [
9,
10] and random swap [
11,
12]. The proposed approach retains the generality and effectiveness of the corresponding K-sets and K-swaps algorithms described in [
8] at the cost of a somewhat slower running time.
The original contributions provided by this paper are the following:
Introducing two new algorithms for clustering sets: K-medoids and random swap using medoid and the two classical set-matching distances of Jaccard and Otsuka–Ochiai cosine coefficients [
13], adapted by considering the frequency of use of the items in the whole dataset.
Exploring the effect of random initialization versus K-means++ initialization [
14,
15,
16,
17,
18].
Implementing parallel variants using Java parallel streams and lambda expressions [
12,
19,
20], which provide better time efficiency on a multi-core machine.
The effectiveness of the new approach is demonstrated by applying it to the 15 synthetic datasets used in [
8]. The algorithms both achieve good clustering quality, which is very similar to that of the previous K-swaps algorithm. However, the proposed medoid-based approach is simpler to implement, and it avoids the threshold parameter for truncating the histogram size. While this might not be the big issue with most data, there are always some potential pathological cases that the proposed approach is likely to avoid.
This paper is organized as follows:
Section 2 summarizes the previous work on adopting K-means to the sets of data;
Section 3 describes the proposed algorithms for clustering sets based on medoids, together with some Java implementation issues;
Section 4 describes the experimental setup;
Section 5 reports the achieved clustering results;
Section 6 concludes this paper by highlighting some directions for further work.
2. Related Work
In this section, the work of [
8] is summarized as the fundamental background upon which the new approach proposed in this paper is based. For further related work the reader is referred to [
8].
A dataset consists of variable-sized
sets of elementary items taken from a vocabulary of size
(which is said to be the problem
resolution). Practical data can be the records of patient diagnoses expressed by ICD-10 [
8,
21] disease codes, preliminarily grouped by similar diseases, for medical applications.
To each cluster a
representative data object (centroid) is associated in the form of a
histogram which records the frequency of each item occurring in the cluster. A histogram contains at most
m = 20 distinct items. For clusters with more items, the
m most frequent items are selected. To apply K-means clustering, a distance measure between a data object (a set)
of size
and a representative histogram
must be defined. In [
8], adapted versions of the Jaccard or the Otsuka–Ochiai cosine distance were introduced. Adaptation is needed because in the case of large values of
, an intersection between two sets may contain only a few common elements, and the distance measure becomes meaningless. A weight is, therefore, defined as the frequency of the item in the local histogram
.
The two distance notions (Jaccard and cosine) are defined accordingly:
2.1. Example
The following example, taken from [
8], refers to a cluster with five data objects that are sets of elementary items denoted by a single capital letter:
The approach in [
8] first associates the
representative (centroid) to the cluster in the form of a
histogram with local frequencies of use of the data items, thus:
Since the number of distinct data items in the cluster (10) is less than 20, all items of the data objects are included in
. Then, the distances of the data objects to the representative can be calculated by (1) or (2). For example:
These distance measures are used to detect the nearest representative of a data object and to evaluate the contribution of a cluster to the sum of distances to histogram () function cost: .
The distance function is the basis of an adaptation of K-means [
1,
2] and random swap [
11,
12] to sets.
2.2. K-Sets and K-Swaps
K-sets is the direct adaption of k-means to sets. It initializes the centroids (representatives) through a uniform random selection in the dataset. The initial representatives have unitary frequency for each component item.
Then, the two basic steps, object
assignment and centroids
update, are carried out as follows: In the assignment step, each data object (set) is assigned to the cluster according to the nearest centroid rule. In the update step, the representative of each cluster is redefined by calculating the new histogram (of
m length) with the number of occurrences of each item in the data objects of the cluster. This operation replaces the classical centroid update of K-means because we cannot compute the
mean of the data objects which are variable-sized sets of elementary items. The quality of the clustering is evaluated by the
sum of the
distances to the
histogram (
):
The two basic steps (assignment and update) are iterated until stabilizes, that is, the difference between the current and previous value of is smaller than a threshold .
Similar modifications were also introduced in the random swap algorithm [
11] that result in the so-called K-swaps algorithm [
8]. It integrates K-sets in the logic of pursuing a global search strategy via centroids swaps. The initialization step is the same as in K-sets, which is immediately followed by a first partitioning. At each swap iteration, a centroid is randomly chosen among the K representatives, and replaced by a randomly chosen data object in the dataset. After the swap, two K-sets iterations are executed and the corresponding
value is evaluated. If the swap improves (reduces)
, the new centroid configuration is accepted and becomes the current solution for the next swap iteration.
Good clustering results are documented in [
8], by applying K-sets and K-swaps to 15 benchmark datasets, referred to as
data in [
22]. K-swaps resulted in low
SDH values and high clustering accuracy, measured in terms of the adjusted rand index (ARI) [
23,
24] values in the case of all benchmark datasets, and K-sets in the case of most datasets.
3. Medoid-Based Approaches
In the approach proposed in this paper, we use
medoid [
9,
10] as the cluster representative instead of a histogram. Medoid is defined as the data object in the cluster with a minimal sum of the distances to the other data objects in the same cluster. The medoid-based approach has two advantages. First, medoid is a more natural cluster representative than a histogram and does not require any parameters such as the threshold for the histogram size. Second, we can use the same distance measures for sets as in [
8] but with an adaption of the measures which considers the global frequency of using elementary items in the application dataset.
Specifically, we present two novel medoid-based algorithms. The first algorithm is the classical K-medoids adopted to the sets. The second algorithm is the random swap variant, in which medoid is used instead of the mean of the objects as the clustering representatives.
3.1. New Distance Functions
A dataset is defined as a set
of
objects, where each object
is a set of
items taken from a vocabulary of
distinct items:
From the dataset, a global histogram
is built from all the
L items and their corresponding frequencies in the dataset, denoted by
. The global histogram was adopted because the frequency of occurrences of an item (for example the disease code in a medical application) naturally can be interpreted as the relative importance of the item with reference to all the other items. Similar to [
8], the global frequency of an item, instead of its local frequency in a cluster, is here used as an application-dependent weight (priority) which replaces 1 when counting, by exact match, the size of the intersection of two sets.
We use two weighted distance functions,
Jaccard and
Otsuka–Ochiai cosine distance. They are defined as follows:
Here, if , 0 otherwise; if , 0 otherwise; if , 0 otherwise; if , 0 otherwise. So, the maximal distance between two sets is 1 and the minimal one is 0. If the weights of items evaluate to 1, the two distance measures reduce to the standard Jaccard and cosine distances.
The use of modified
or
distance measure, enables K-medoids [
9,
10] (see Algorithm 1) and random swap [
11,
12] (see Algorithm 2) to easily adapt to sets, and also to possibly exploit careful seeding methods.
| Algorithm 1: Pseudo-code of K-Medoids for sets |
| Input: The dataset and the number of required clusters |
| Output: The partitions and medoids of the emerged clustering solution, together with some accuracy measures including the cost |
| 1. Initialization. Initialize the medoids by a certain seeding method |
| 2. Partitioning: Assign each data object to the cluster , if |
| 3. Update. Define the new medoid of each cluster as that data object which has minimal sum of the distances from all the remaining points of the cluster: |
| 4. Check termination. If medoids are not stable, restart from Step 2; otherwise stop |
| Algorithm 2: Pseudo-code of Random Swap for sets |
| Input: The dataset and the number of required clusters |
| Output: The partitions and medoids of the emerged clustering solution, together with some accuracy measures including the cost |
| 1. Initialization. Initialize the medoids by a certain seeding method |
| 2. Initial Partitioning. Assign data objects to clusters according to the nearest initial medoids; |
| Repeat times: |
- 3.
Swap. A medoid is uniform randomly chosen in the vector of medoids, and it gets replaced by a data object uniform randomly chosen in the dataset: - 4.
Medoids refinement. A few iterations of K-medoids (Algorithm 1) are executed to refine medoids; - 5.
Test. If( then the new solution is accepted and becomes current for the next iteration, with ; otherwise, previous medoids and corresponding partitioning are restored.
End Repeat |
As in [
8], the total
sum of distances to medoids (
) objective function is assumed to be minimized by clusters. Let
denote the
clusters and
be the corresponding medoid data objects.
SDM is defined as:
where
is the
nearest medoid to the data object
, that is:
3.2. K-Medoids Algorithm for Sets
Algorithm 1 describes the steps of the algorithm in pseudo-code which differs from the Lloyd’s classical K-means only in the Update step, where instead of computing the mean of the points associated with a cluster, the medoid of the cluster is identified.
The two steps, Steps 2 and 3, are repeated until the medoids stop moving. The computational cost of the algorithm is where is the number of iterations. The cost is dominated by the cost for all pairwise distances calculation. The matrix of all pairwise distances can be built for tiny datasets in the initialization step. More in general, though, distances between data objects are computed on demand. Therefore, implementation of a parallel algorithm can be required to reduce the computational needs (see later in this paper).
Example
The process of computing medoids can be demonstrated using the cluster example introduced in the
Section 2.1. First, the global histogram
of the frequencies of elementary items in the dataset is defined:
:
| A | B | C | D | E | F | G | H | I | J | … |
| 35 | 20 | 22 | 20 | 24 | 12 | 10 | 8 | 22 | 7 | … |
The objects
and
of the cluster have two items in common (
) and five other items. The modified distance
can be calculated by (4):
It should be noted how the classical Jaccard similarity, i.e.,
is significantly increased by the usage of the global weights
and
, to
, and conversely for the distance. Something similar occurs when using (1) with local weights in [
8].
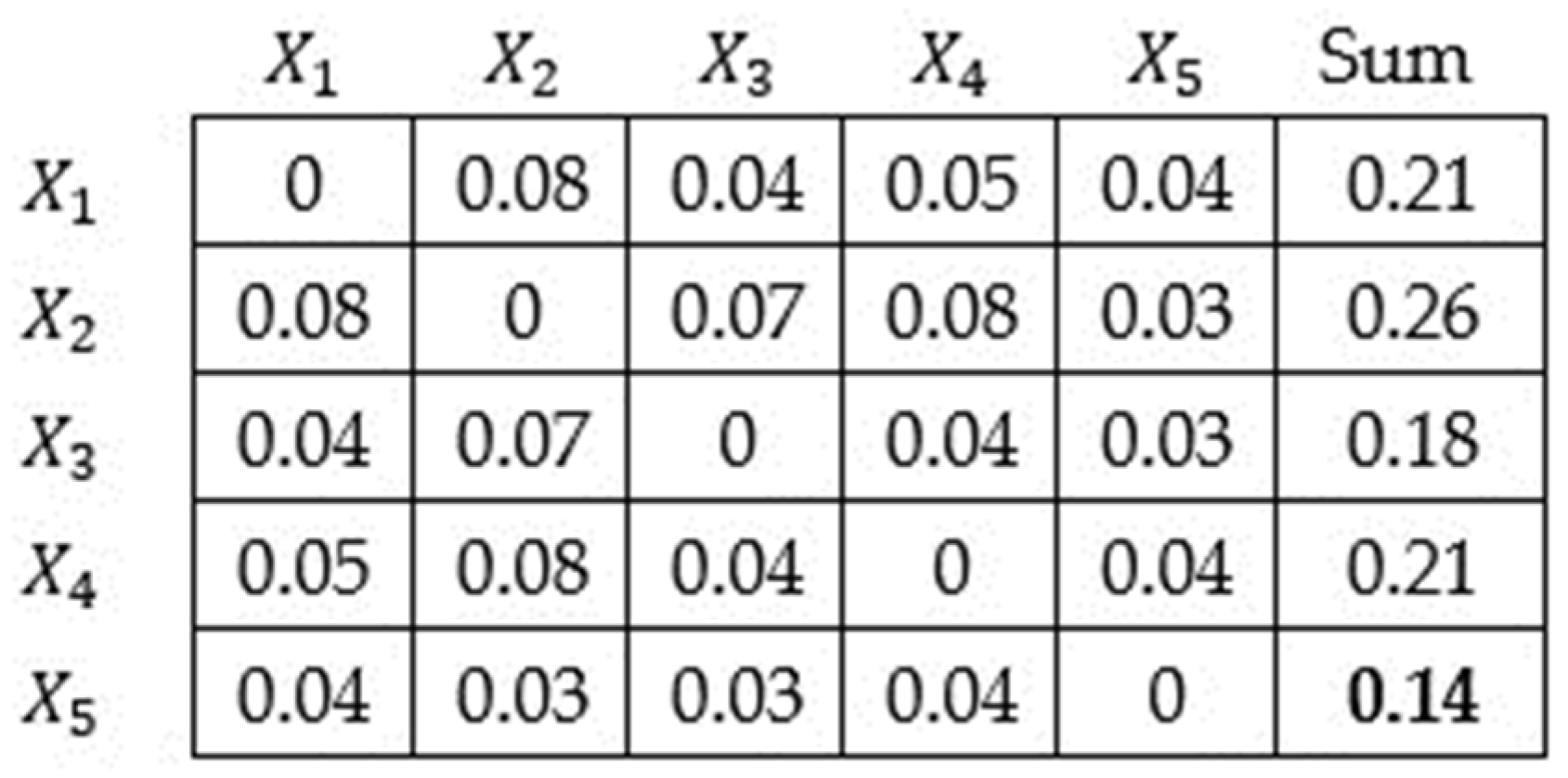
Figure 1 collects all the pairwise distances between the data objects of the cluster.
From the matrix in
Figure 1, it emerges that the medoid representative of the cluster is the
data object, which has a minimal sum (0.14) of the distances to all the other points in the cluster. Moreover, the contribution of the cluster to the function cost
is also 0.14.
3.3. Random Swap Algorithm for Sets
The operation of the algorithm is shown in Algorithm 2. With respect to the basic random swap algorithm [
11,
12], the use of medoids in the refinement Step 4 should be noted.
Due to its ability to search for medoid configurations in the whole data space, random swap is capable of approaching the optimal solution in many practical cases, hopefully, after a small number of iterations .
3.4. Medoids Initialization and Seeding Methods
It has been demonstrated [
3,
4] that the seeding method for centroids initialization can significantly affect the K-means clustering results. This is likely why the K-sets variant was inferior to the K-swaps algorithm in [
8]. It was shown in [
4] that significantly better results can be obtained for difficult datasets by using better initialization algorithms such as maximin and K-means++. We, therefore, consider different seeding strategies. We consider the uniform random method, maximin [
16], K-means++ [
14], and greedy K-means++ [
15,
17,
18].
Uniform: The medoids are defined by uniform random selections from the dataset.
Let be a data object and the minimal distance of from the currently defined centroids.
Maximin: The first medoid is chosen in the dataset by a uniform random selection. Then, maximin chooses the next medoid as a data object with maximal value. The procedure is continued until all the medoids have been selected.
K-Means++: This is a randomized variant of the same idea as in maximin; it selects the next medoid by a
random switch among the data objects of the dataset, after associating to each data object the probability of being chosen as:
Greedy K-Means++: This refines the K-means++ procedure with a sampling step (see Algorithm 3). Except for the first medoid, any new medoid is selected by sampling
candidates from the dataset, and by keeping the one which minimizes the
cost function, evaluated according to the currently defined medoids.
| Algorithm 3: The Greedy_K-Means++ seeding method |
| , |
|
| |
| |
| |
| a data object with the K-Means++ procedure |
| according to |
| |
| |
| |
| |
| |
| |
| |
| |
|
The value
is a trade-off between the improved seeding and the extra computational due to the
attempts. We fix
, as suggested in [
17].
The K-medoids Algorithm 1 is used in this work in a repeated way, where a different initialization of the medoids feeds each independent run. As for repeated K-means, the higher the number of repetitions, the higher the chance to achieve a solution “near” to the optimal one.
3.5. Accuracy Clustering Indexes
The proposed new distance functions in
Section 3.1 make it possible to qualify the accuracy of a clustering solution achieved by repeated K-medoids or random swaps, by using some well-known internal or external indexes. For benchmark datasets provided of ground truth partition labels (see also later in this paper), the external adjusted rand index (
) (used in [
8]) and the centroid index (
) [
12,
25,
26] can be used to qualify the similarity degree between an obtained solution and the ground truth solution. The
index ranges from 0 to 1, with 1 mirroring maximal similarity and 0 expressing the maximal dissimilarity. The
index ranges from 0 to
. A
is a precondition for a clustering solution to be structurally correct, with the found medoids which are very close to the optimal positions. A
indicates the number of medoids which were incorrectly determined.
In addition to the
function cost, in this work, the internal Silhouette index (
) [
16,
27] can be used for checking the degree of separation of the clusters. The
index ranges from −1 to 1 (see also [
12]), with 1 mirroring well-separated clusters. An
indicates high overlapping among clusters. An
toward −1 characterizes an incorrect clustering.
3.6. Java Implementation
The following gives a flavor of the Java implementation based on parallel streams [
12,
19,
20] of the proposed clustering algorithms for sets. The
and
are represented by native arrays of
instances. A
holds a set of items (strings) and provides the distance function (either Jaccard or cosine modified distance) and other useful methods for stream management. A
class exposes some global parameters such as the dataset dimension
, the number of clusters
, the number of distinct items
, the name and location of the dataset file and so forth.
For generality, the implementation does not rely on the matrix of pairwise distances which is difficult to manage in large datasets. Distances among data objects are, instead, computed on demand and purposely exploit the underlying parallel execution framework.
In Algorithm 4, the
method of
is shown. First, a stream is achieved from the dataset, with the
parameter which controls whether the stream must be processed in parallel. Then, the stream is open. The intermediate
() operation works on the stream by applying a
lambda expression to each data object. The lambda receives a
element and returns an
result. In Algorithm 4,
.
receives a
and accumulates in its field
the sum of distances from
to every other object in the same cluster (controlled by the
CID field of data objects). Then, the modified
is returned. The terminal
operation adds all the distances held in the data objects and returns a new
whose
contains the required
.
| Algorithm 4: Stream based sum of distances to medoids (SDM) method |
| public static double SDM() { |
| Stream<DataObject> pStream = |
| (PARALLEL) ? Stream.of(dataset).parallel() : Stream.of(dataset); |
| DataObject sdm = pStream |
| .map( |
| dO ->{ |
| int k = dO.getCID(); dO.setDist(0); |
| for(int i = 0; i<N; ++i) { |
| if(i! = dO.getID() && dataset[i].getCID() = = k) { //same cluster |
| dO.setDist(dO.getDist()+dO.distance(dataset[i])); |
| } |
| } |
| return dO; |
| } |
| ) |
| .reduce( |
| new DataObject(), |
| (d1,d2)->{ DataObject d = new DataObject(); |
| d.setDist(d1.getDist()+d2.getDist()); return d; } |
| ); |
| return sdm.getDist(); |
| }//SDM |
An important issue in the realization in Algorithm 4 is that stream objects can be processed in parallel using the built-in fork/join mechanism [
19], which splits the dataset into multiple segments and spawns a separate thread to process the data objects of a same segment. The various results are finally combined, in parallel, by the
operation which returns a new
containing the overall sum of distances.
The correctness and actual efficiency of the Java code in Algorithm 4 rests on the designer, which must absolutely avoid modifications of shared objects during the parallel execution of the lambda expressions. For example, the lambda of each operation in Algorithm 4 purposely modifies only the received parameter object; thus, data interferences are completely avoided.
The stream-based programming style shown in Algorithm 4 was also adopted in the implementation of K-medoids, random swap, and in all the operations which can benefit from a parallel execution.
Algorithm 5 shows an excerpt of the stream-based K-medoids algorithm.
| Algorithm 5: An excerpt of the K-Medoids algorithm in Java |
| … |
| //clusters’ queues for saving belonging data objects |
| ConcurrentLinkedQueue<DataObject>[] clusters = new ConcurrentLinkedQueue[K]; |
| for(int c = 0; c<K; ++c) clusters[c] = new ConcurrentLinkedQueue<>(); |
| … |
| seeding(INIT_METHOD); //initialize medoids |
| do{ |
| for(int c = 0; c<K; ++c) clusters[c].clear(); |
| //partitioning step: assign data objects to clusters |
| Stream<DataObject> do_stream = Stream.of(dataset); |
| if(PARALLEL) do_stream = do_stream.parallel(); |
| do_stream |
| .map(dO -> { |
| double md = Double.MAX_VALUE; |
| for(int k = 0; k<K; ++k) { |
| double d = dO.distance(medoids[k]); |
| if(d<md) { md = d; dO.setCID(k); } |
| } |
| clusters[ dO.getCID() ].add(dO); //add data object dO to its partition cluster |
| return dO; |
| }) |
| .forEach(dO->{}); //only to trigger the map operation |
| //update medoids step |
| for(int h = 0; h<K; ++h) { |
| Stream<DataObject> c_stream = clusters[h].stream(); //open stream on cluster[h] |
| if(PARALLEL) c_stream = c_stream.parallel(); |
| final int H = h; //turn h into an effective final variable H |
| DataObject neutral = new DataObject(); neutral.setDist(Double.MAX_VALUE); |
| DataObject best = c_stream |
| .map(dO->{ |
| double c = 0D; |
| for(DataObject q: clusters[H]) { if(q! = dO) c = c+ dO.distance(q); } |
| dO.setDist(c); //save the distance sum to other objects of the cluster |
| return dO; |
| }) |
| .reduce(neutral, (d1,d2)->{ if(d1.getDist()<d2.getDist()) return d1; return d2; }); |
| newMedoids[h] = new DataObject(best); newMedoids[h].setN(clusters[h].size()); |
| }//for(int h = 0;… |
| … |
| }while(!termination()); |
| … |
In the partitioning step (see also Algorithm 1), the nearest medoid to each data object is determined and the label of the medoid (its index) is assigned to the data object. As part of the operation, references of all the objects which belong to the same cluster are collected into distinct partition lists, to be used in the second step of medoids update. A critical issue concerns the modification of a shared partition list. To avoid data race conditions, partition lists are purposely realized as lists which are totally lock free and can be safely accessed simultaneously by multiple threads.
Partition lists can be processed in parallel in the update medoids step. As shown in Algorithm 5, for each data object of a cluster, first, the sum of distances from to all the remaining objects of the same cluster is accumulated in as part of a operation. Then, a operation is used which identifies and returns the data object () which has a minimal sum of distances to the other objects of the same cluster.
In Algorithm 5, new medoids are temporarily defined and are compared with current medoids in the method, which checks termination (by convergence or by maximum number of executed iterations) and, finally, makes new medoids current medoids for the next iteration.
4. Experimental Setup
We use the 15 artificial datasets described in [
8] for testing the algorithms. They are all available in [
22]. All datasets have
N = 1200 data objects and vary in the size
of the vocabulary of elementary items, the number
of clusters, the overlapping percentage
, and the type
which specifies how balanced are the cluster sizes. The value
denotes to equal cluster sizes. The datasets are named accordingly as
data_
N_
L_
K_
o_
t, see
Table 1.
Ground truth partitions are provided to measure the accuracy by the adjusted rand index (
) and the centroid index (
) [
25,
26] of a found clustering solution.
We cluster each dataset by repeated K-medoids using 1000 runs. For the initialization, we use uniform random, maximin, K-means++, and the greedy-K-means++ (G-K-means++) seeding.
The following quantities were observed: The best value of the sum of distances to medoids function cost (indicated as ) emerged from the various runs, and the corresponding (), (), and () indexes. In addition, the (), that is the number of runs that terminated with a , the average (), and the average () estimated in the 1000 runs, were also registered.
5. Clustering Results
The effects of the seeding methods were preliminarily studied using the
dataset (see
Table 1). The results are reported in
Table 2.
Simulation experiments were carried out on a Win11 Pro, Dell XPS 8940, Intel i7–10700 (8 physical cores), CPU@2.90 GHz, 32 GB Ram, and Java 17.
As one can see from
Table 2, all the four seeding methods agree on the best
,
,
and
SI. However, they significantly differ in the
and the average
and the average
.
The best results follow from the careful seeding ensured by G-K-means++ where a
of about 40%, an average
of 0.93, and an average
of about 0.69 were observed, although with an increased computational time.
Table 2 also confirms that maximin, after G-K-means++, is capable of offering better results than uniform random or K-means++ seeding. The Silhouette index (
) mirrors the limited overlapping percentage (
) present in the dataset.
The dataset
was also studied by using the parallel version of the implemented random swap algorithm (
) (see Algorithm 2) separately fed by each one of the four seeding methods. At most, 100 swap iterations were set. The minimal number of swaps required to detect the “best” solution (minimal
cost) and corresponding
,
, and
indexes are reported in
Table 3.
From
Table 3 it emerges that even with the uniform random seeding,
was able to find the best solution with few iterations.
The effect of seeding methods on the
dataset was also observed with the other datasets. Therefore, in the following, for simplicity, only the results gathered by using repeated K-medoids and parallel random swap when seeded, respectively, by uniform random and by G-K-means++ are reported in
Table 4,
Table 5,
Table 6 and
Table 7.
From the results in
Table 4 and
Table 5, it emerges that for
almost all the datasets, 1000 repetitions of K-medoids with uniform random seeding are sufficient for obtaining a good clustering solution. However, the use of G-K-means++ seeding not only enables a very good solution to be achieved in all the cases, as reflected by the values of the
,
, and
indexes, but it also increases significantly the
.
Only for the two datasets and , 1000 repetitions of K-medoids with uniform random seeding proved to be insufficient for generating a solution with minimal , highest and . This is due to the combination of design factors of the datasets, i.e., the number of clusters and the overlapping degree.
By increasing the number of runs to 104, both the datasets were correctly handled by K-medoids with uniform random seeding, with a resultant solution for which has minimal SDM = 3460, , and , and an average , average and .
For the dataset , the emerged best solution has minimal SDM = 1824, , CI = 0, , and average , average and .
The benefits of careful seeding are confirmed by all the results shown in
Table 5.
The results in
Table 6 and
Table 7 are the average of 10 repetitions of the parallel random swap (
) algorithm. As one can see, the collected data agree with the results achieved by repeated K-medoids under the same seeding method.
, though, was able to solve the clustering problem (
) even under the uniform random initialization of medoids. In addition, using G-K-means++ significantly reduces the number of iterations the clustering solution requires to stabilize.
Separate experiments were executed by using the modified Otsuka–Ochiai cosine distance. Except for the exact values, which clearly depend on the specific distance measure adopted, the bARI, , and results are identical to the case the modified Jaccard distance was adopted, especially when the G-K-means++ seeding is used. Therefore, such results are not reported for brevity.
For comparison purposes with the results documented in [
8] and achieved by using K-sets and K-swaps,
Table 8 collects the achieved clustering results when the number of clusters
varies from 4 to 32;
Table 9 shows the results when the resolution
varies from 100 to 800;
Table 10 reports the emerged data when the overlapping level
of clusters varies from 0% to 40%; and finally,
Table 11 illustrates the results when the type of clusters
is varied from 1 to 5.
The table results were confirmed by K-medoids and parallel random swap () under G-K-means++ seeding (GKM++).
Since in [
8] the
and
indexes were not reported, the table results show only the best-achieved
and the average
calculated along the values in a table row.
In light of the data shown in
Table 8,
Table 9,
Table 10 and
Table 11, the algorithms proposed in this paper for clustering sets are capable of generating solutions with the same accuracy as the approach described in [
8], and in some cases can deliver better performance.
Time Efficiency
The time complexity of the implemented K-medoids algorithm is , where is the number of the data objects (sets) of the dataset, is the number of medoids, is the number of iterations, and is the average length of a set.
In the following, some information is provided to determine the time computational benefits that can be gathered from using Java parallel streams. The experimental results reported in
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10 and
Table 11 were all achieved by executing the proposed K-medoids or random swap algorithms in parallel (parameter
).
Table 12 reports the results of 2000 repetitions of K-medoids, with G-K-means++ seeding and modified Jaccard distance, on the data_1200_200_32_5_1 dataset, separately, in sequential, and in parallel mode. The elapsed time
(in msec) and the total number of completed iterations (
) were also measured. Then, the average elapsed time per iteration,
, was computed.
Then, the speedup was estimated as follows:
From the results in
Table 12, we can calculate a speedup of 442/63 = 7.02. This corresponds to a parallel efficiency (eight physical cores) of 7.02/8 = 87.8%.
Note that the clustering algorithm executes the same computational steps in sequential and parallel modes. Despite the small value of the dataset size, and then of the clusters’ size, the speedup value reflects a good exploitation of the parallelism in the partitioning and the medoids update steps of K-medoids (see Algorithm 1), as well as in the recurrent calculations of the and of the Silhouette clustering index .
6. Conclusions
This paper proposes a novel approach to clustering variable-sized sets of elementary items. An example of such data occurs in medical applications where patient diagnoses can be clustered to help discover a patient’s risk of contracting a future illness due to its similarity with other patients.
The new approach is based on medoids. Two algorithms (K-medoids and random swap) were implemented to work with the well-known Jaccard or Otsula–Ochiai cosine distance measures adjusted to exploit some application-sensitive information concerning the global frequency of elementary items in the dataset.
The proposal makes it possible to compute the distance between any pair of sets or data objects. This enables the centroid/medoid of a cluster to be any data object of the dataset. This differs from the inspiring work by [
8], where the representative of a cluster is a histogram of the uses of the items in the cluster, and a distance measure is introduced between a data object and the cluster histogram.
The new approach proves to be effective in generating reliable clustering solutions. In addition, an efficient implementation in Java based on parallel streams [
12,
19,
20] was realized to cope with the
computational cost related to computing the all pairwise distances in K-medoids and in the evaluation of some clustering accuracy indexes.
This paper demonstrates the benefits of the proposed approach by applying it to 15 synthetic datasets [
22] which were also used in [
8]. The experimental results confirm the achievement of high-quality clustering solutions, which can outperform the results reported in [
8].
Future research aims at improving the Java implementation of the algorithms; applying the algorithms to realistic datasets such as clustering healthcare records as in [
8]; and exploiting the approach in other clustering methods. In addition, considering the problems discussed in [
28] about weaknesses of medoids when averaging GPS trajectories, which in general can also be problems in clustering sets, another future issue of this work will concern a possible replacement of medoids by some specific definition of the mean of the data objects of a cluster.







{kind=link}