

Efficient Algorithm for Proportional Lumpability and Its Application to Selfish Mining in Public Blockchains


Abstract
:1. Introduction
2. Background
2.1. Stochastic Models
- stationary if its statistical properties do not change by time, i.e., the family of random variables has the same distribution as the collection for all .
- time-homogeneous if the conditional probability remains constant regardless of t, i.e., the behavior of the system does not depend on when it is observed. In particular, the transitions between states are independent of the time at which the transitions occur.
- irreducible if all states in its state space can be reached from all other states by following the transitions of the process.
2.2. Strong (or Ordinary) Lumpability
3. Proportional Lumpability
3.1. Three Alternative Characterizations of Proportional Lumpability
- if and only if
- if then
- if and only if and
- if , then
| Algorithm 1 Computation of the Maximum Proportional Partition |
|
3.2. Comparison with Lumpability of the Embedded Markov Chain
4. A Case Study
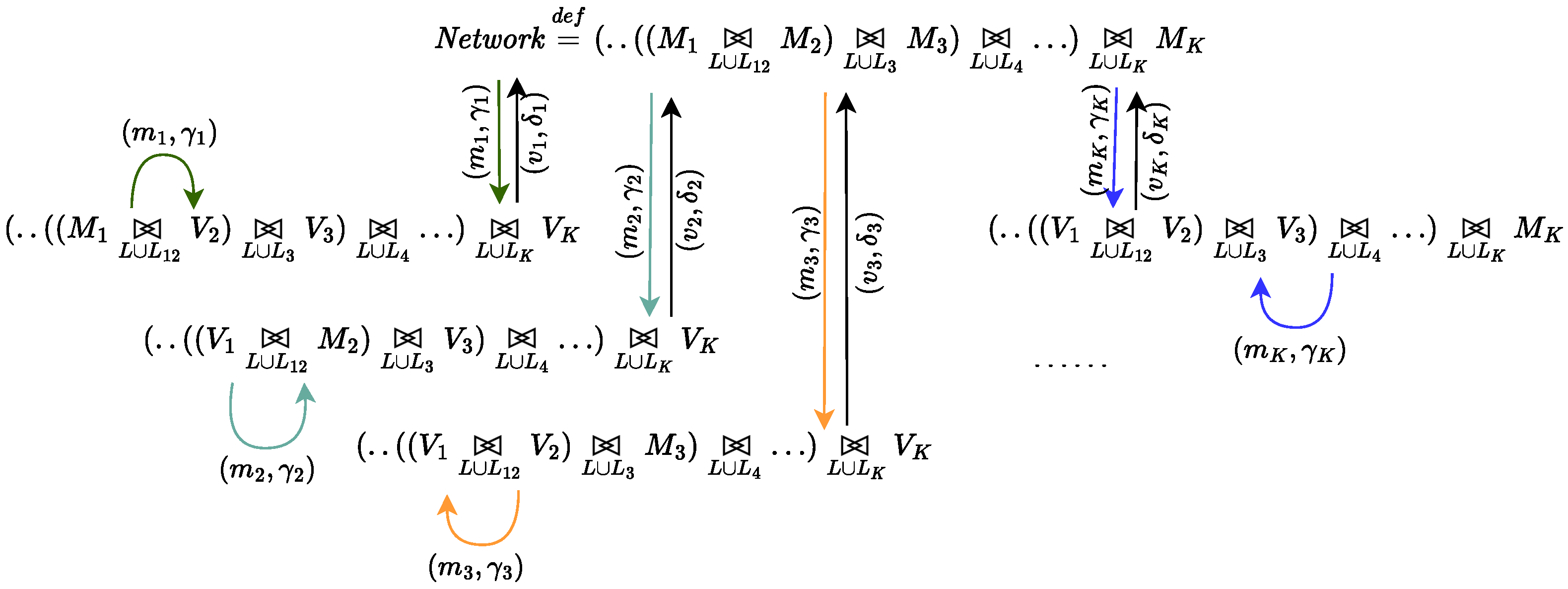
4.1. The Process Algebra PEPA
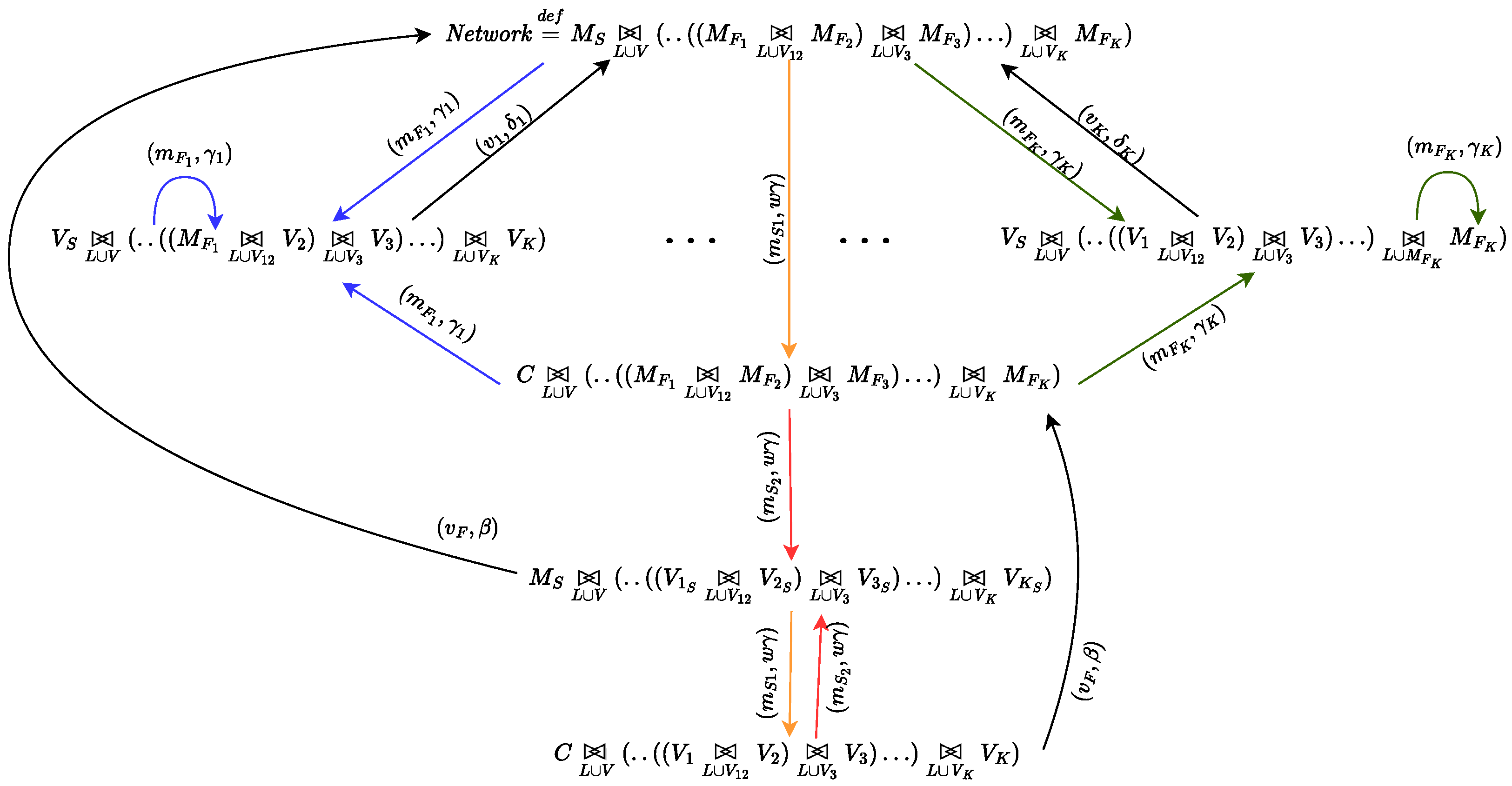
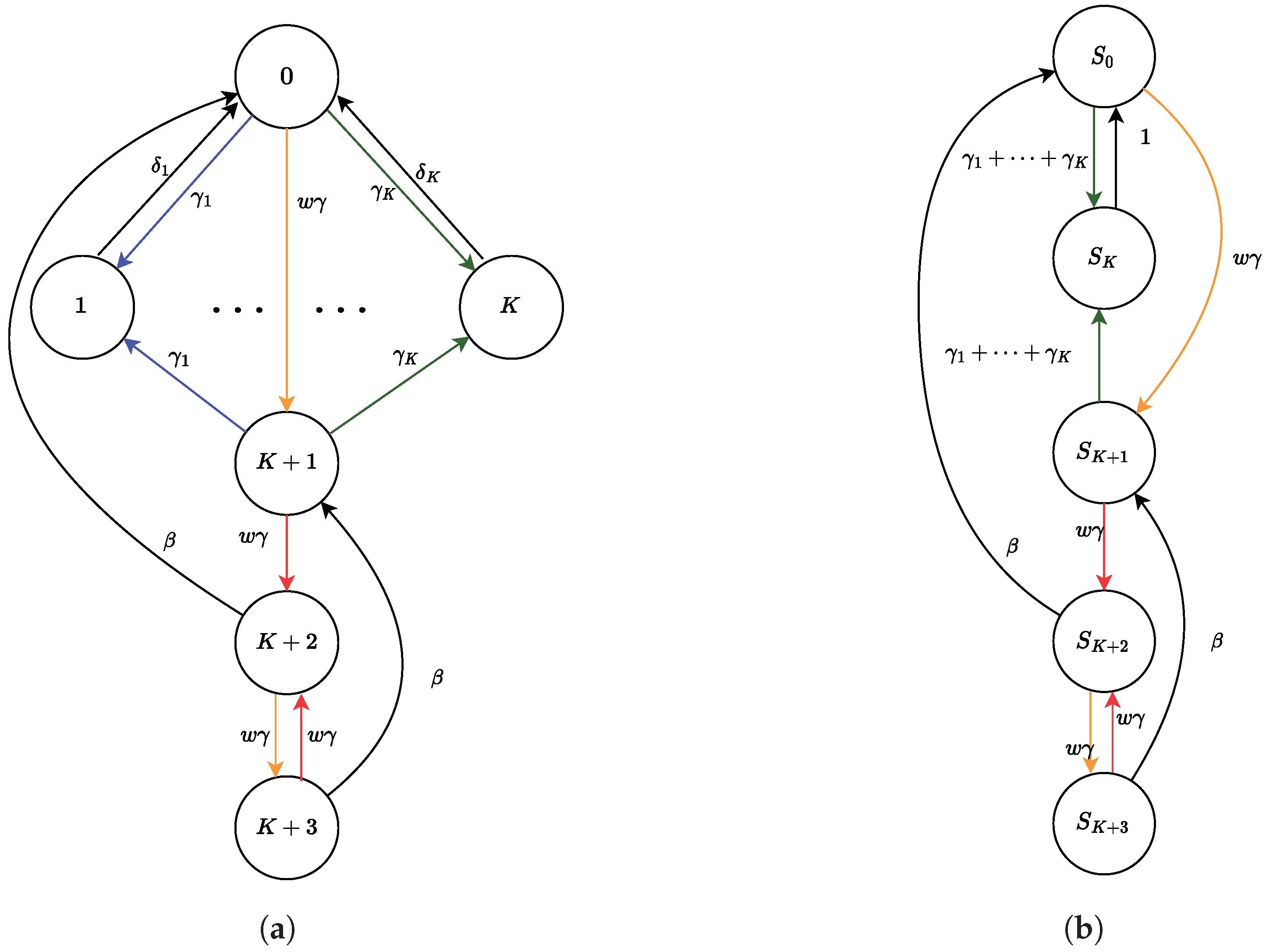
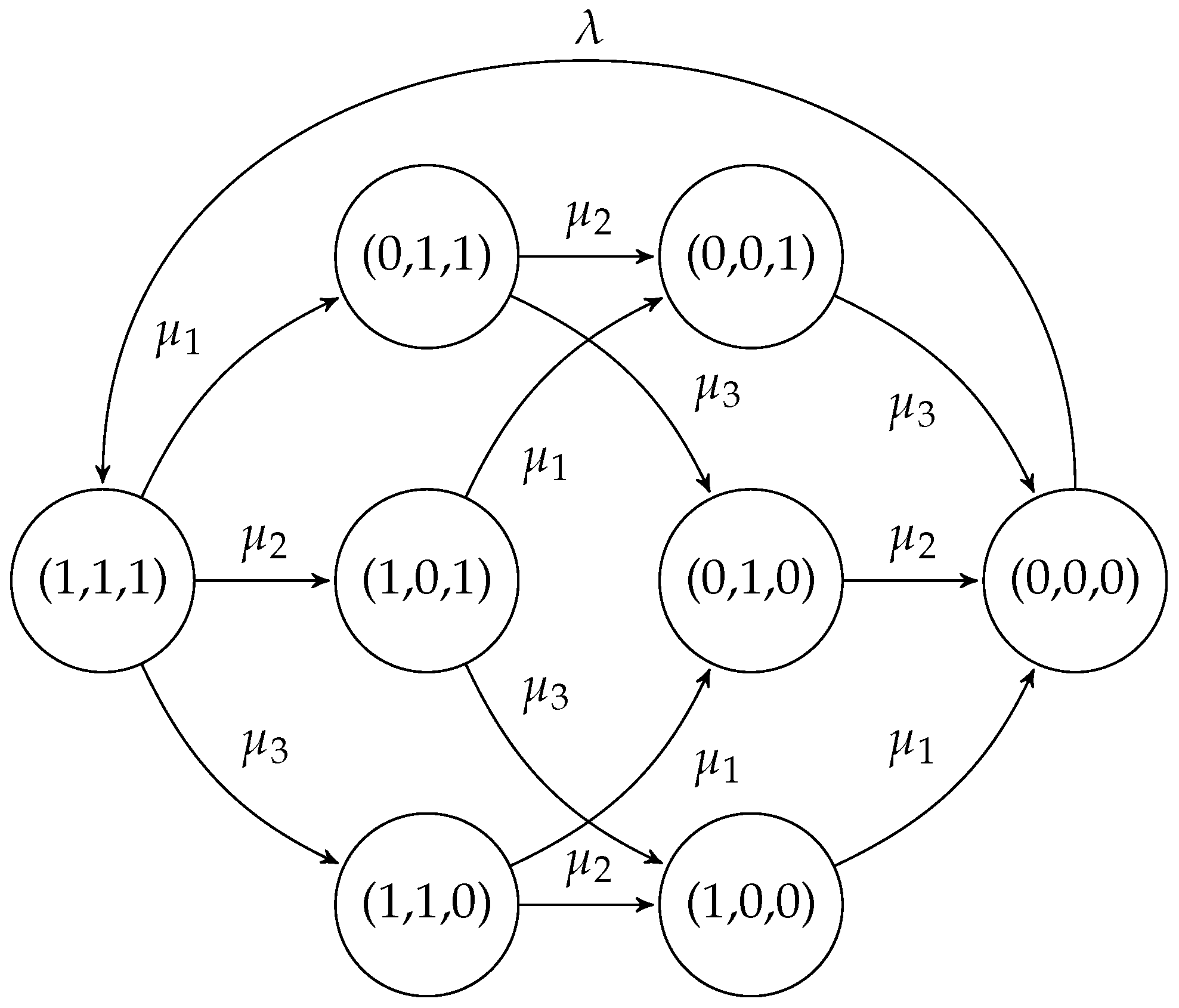
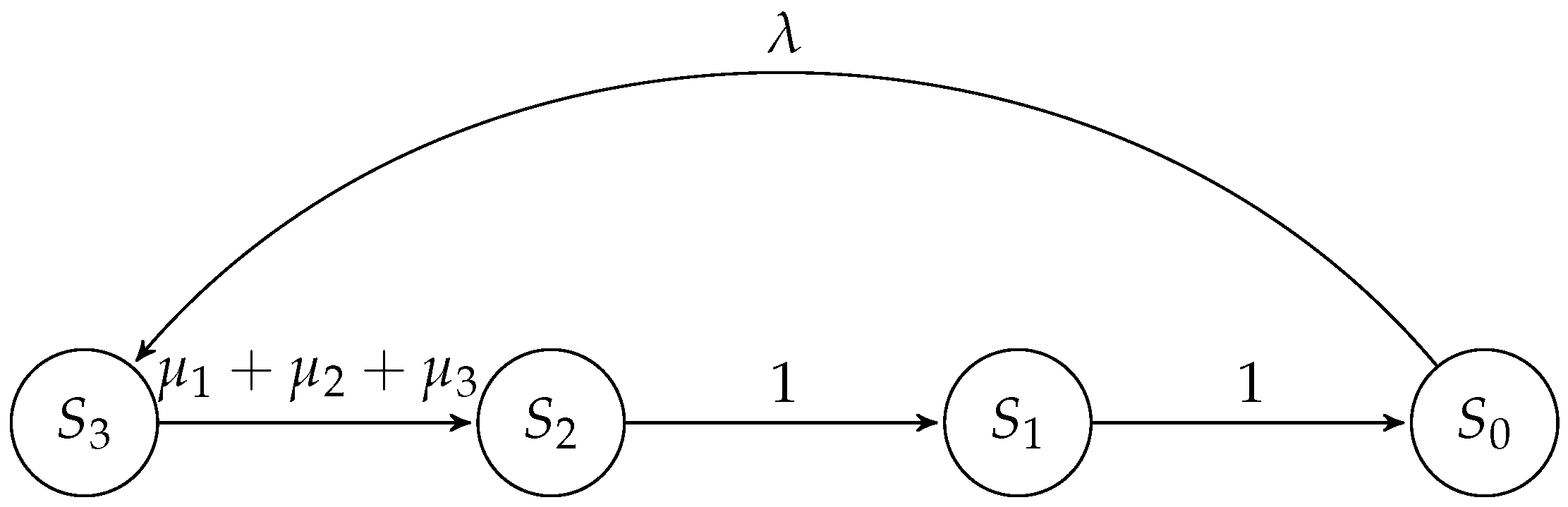
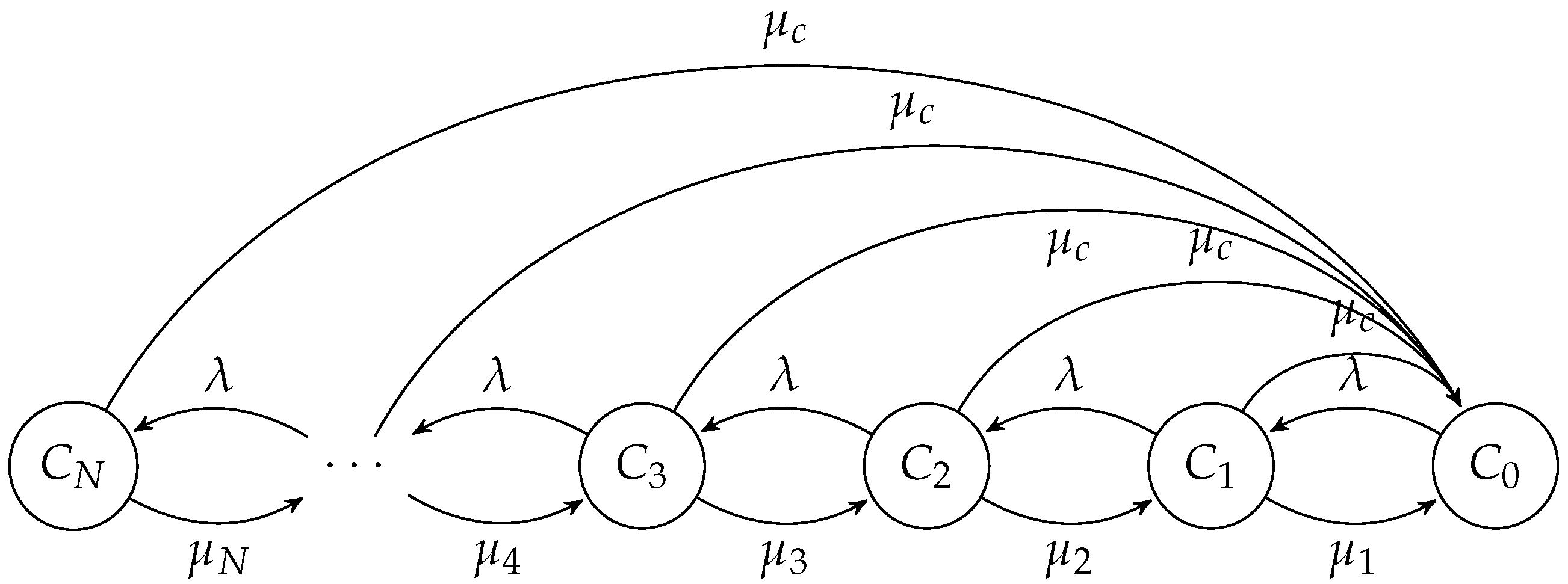
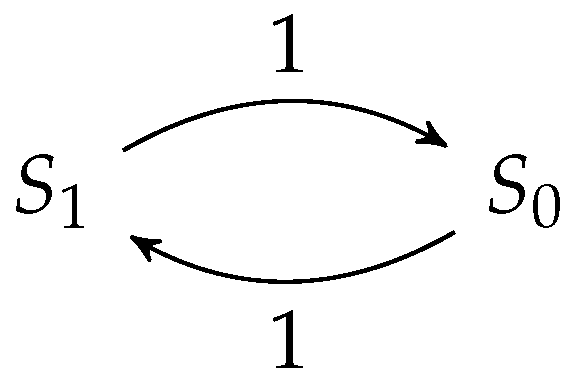
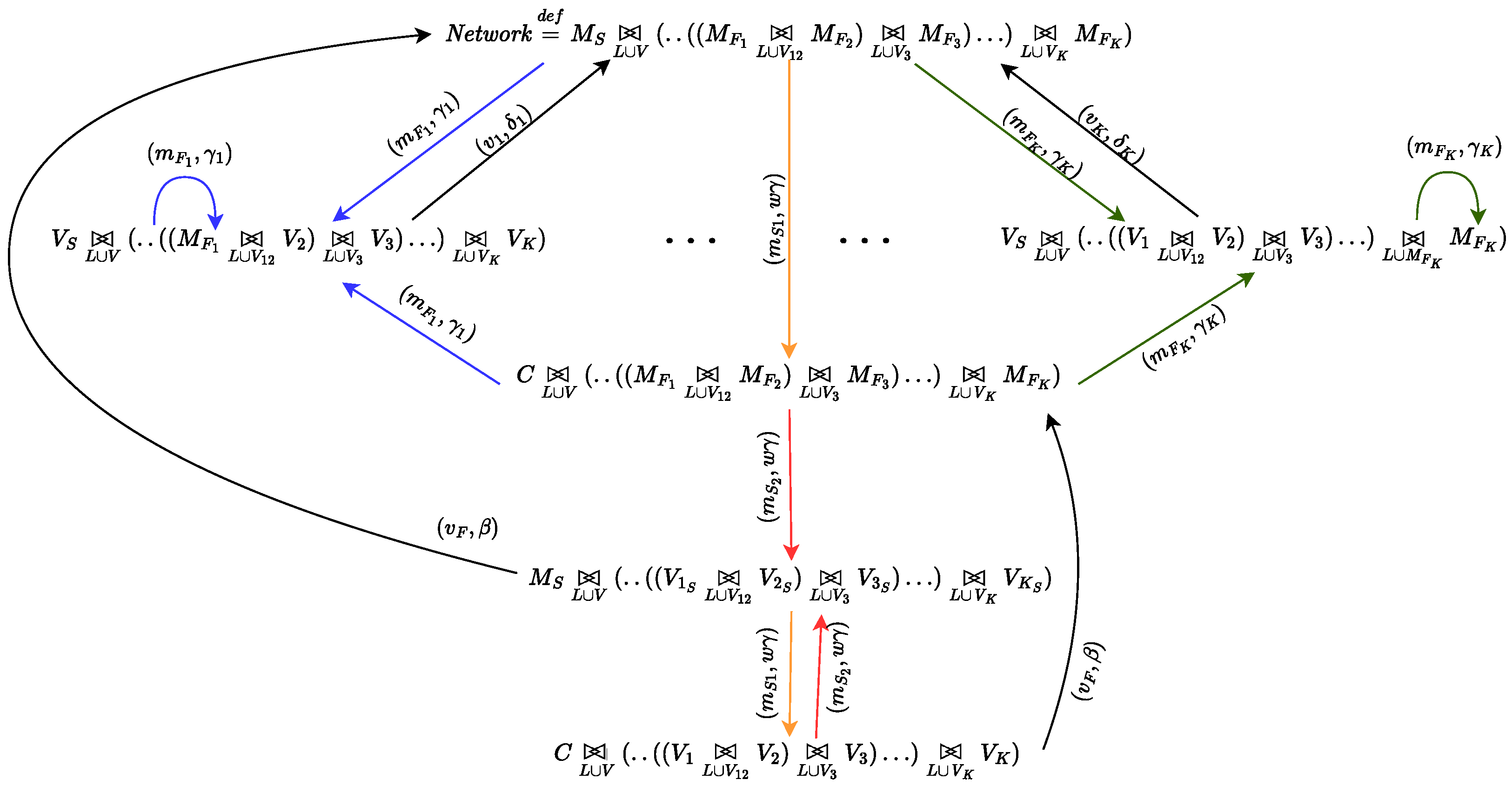
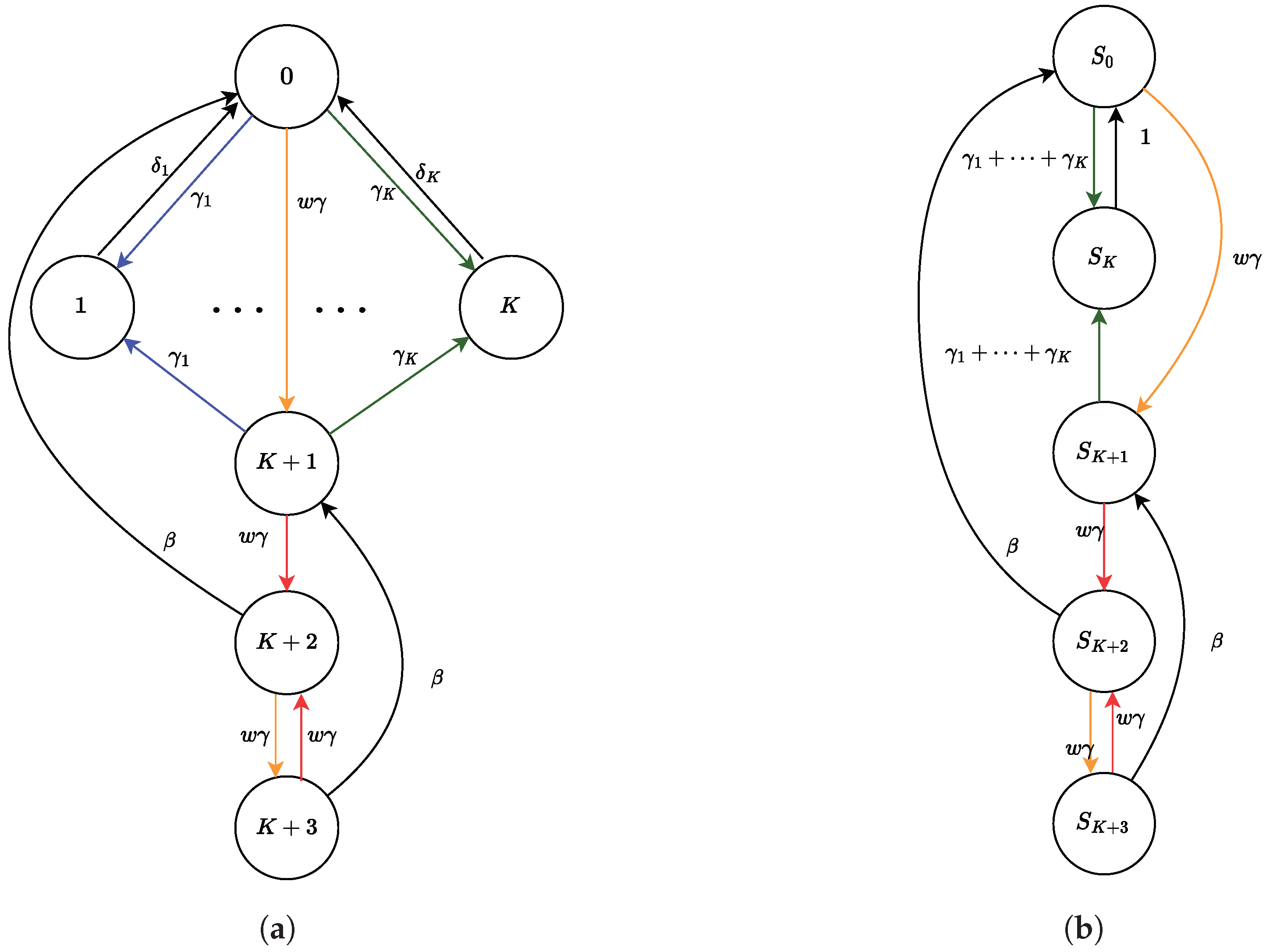
4.2. Selfish Mining in Public Blockchains
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Molloy, M.K. Performance Analysis Using Stochastic Petri Nets. IEEE Trans. Comput. 1982, 31, 913–917. [Google Scholar] [CrossRef]
- Valk, R.; Vidal-Naquet, G. Petri nets and regular languages. J. Comput. Syst. Sci. 1981, 23, 299–325. [Google Scholar] [CrossRef]
- Plateau, B. On the stochastic structure of parallelism and synchronization models for distributed algorithms. Sigmetrics Perf. Eval. Rev. 1985, 13, 147–154. [Google Scholar] [CrossRef]
- Fourneau, J.M.; Plateau, B.; Stewart, W.J. Product form for stochastic automata networks. In Proceedings of the ValueTools 2007 Conference, ICST, Brussels, Belgium, 22–27 October 2007; pp. 1–10. [Google Scholar]
- Balsamo, S.; Marin, A. Queueing Networks in Formal methods for performance evaluation. In LNCS; Springer: Berlin/Heidelberg, Germany, 2007; Chapter 2; pp. 34–82. [Google Scholar] [CrossRef]
- Lazowska, E.D.; Zahorjan, J.L.; Graham, G.S.; Sevcick, K.C. Quantitative System Performance: Computer System Analysis Using Queueing Network Models; Prentice Hall: Englewood Cliffs, NJ, USA, 1984. [Google Scholar]
- Hermanns, H. Interactive Markov Chains; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar] [CrossRef]
- Hillston, J. A Compositional Approach to Performance Modelling; Cambridge University Press: Cambridge, UK, 1996. [Google Scholar] [CrossRef]
- Schweitzer, P. Aggregation Methods for Large Markov Chains. In Proceedings of the International Workshop on Computer Performance and Reliability, Pisa, Italy, 26–30 September 1983; pp. 275–286. [Google Scholar]
- Stewart, G. Computable error bounds for aggregated Markov chains. J. ACM 1983, 30, 271–285. [Google Scholar] [CrossRef]
- Kemeny, J.G.; Snell, J.L. Finite Markov Chains; Springer: Berlin/Heidelberg, Germany, 1976. [Google Scholar] [CrossRef]
- Baarir, S.; Dutheillet, C.; Haddad, S.; Iliè, J.M. On the use of exact lumping in partially symmetrical Well-formed Petri Nets. In Proceedings of the International Conference on the Quantitative Evaluaiton of Systems (QEST’05), Torino, Italy, 19–22 September 2005; pp. 23–32. [Google Scholar] [CrossRef]
- Buchholz, P. Exact and Ordinary lumpability in finite Markov chains. J. Appl. Probab. 1994, 31, 59–75. [Google Scholar] [CrossRef]
- Kant, K. Introduction to Computer System Performance Evaluation; McGraw-Hill: New York, NY, USA, 1992. [Google Scholar]
- Franceschinis, G.; Muntz, R. Bounds for quasi-lumpable Markov chains. Perform. Eval. 1994, 20, 223–243. [Google Scholar] [CrossRef]
- Courtois, P.J.; Semal, P. Computable Bounds for Conditional Steady-State Probabilities in Large Markov Chains and Queueing Models. IEEE J. Sel. Areas Commun. 1986, 4, 926–937. [Google Scholar] [CrossRef]
- Franceschinis, G.; Muntz, R. Computing Bounds for the Performance Indices of Quasi-Lumpable Stochastic Well-Formed Nets. IEEE Trans. Softw. Eng. 1994, 20, 516–525. [Google Scholar] [CrossRef]
- Baarir, S.; Beccuti, M.; Dutheillet, C.; Franceschinis, G. From partially to fully lumped Markov chains in stochastic well formed Petri nets. In Proceedings of the Valuetools 2009 Conference, Pisa, Italy, 20–22 October 2009; ACM: New York, NY, USA, 2009; p. 44. [Google Scholar] [CrossRef]
- Milios, D.; Gilmore, S. Component aggregation for PEPA models: An approach based on approximate strong equivalence. Perform. Eval. 2015, 94, 43–71. [Google Scholar] [CrossRef]
- Marin, A.; Piazza, C.; Rossi, S. Proportional Lumpability. In Proceedings of the International Conference on Formal Modeling and Analysis of Timed Systems, FORMATS, Amsterdam, The Netherlands, 27–29 August 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 265–281. [Google Scholar] [CrossRef]
- Marin, A.; Piazza, C.; Rossi, S. Proportional Lumpability and Proportional Bisimilarity. Acta Inform. 2021, 59, 211–244. [Google Scholar] [CrossRef]
- Ledoux, J. A necessary condition for weak lumpability in finite Markov processes. Oper. Res. Lett. 1993, 13, 165–168. [Google Scholar] [CrossRef]
- Kuo, J.; Wei, J. Lumping analysis in monomolecular reaction systems. analysis of approximately lumpable system. Ind. Eng. Chem. Fundam. 1969, 8, 124–133. [Google Scholar] [CrossRef]
- Li, G.; Rabitz, H. A general analysis of exact lumping in chemical kinetics. Chem. Eng. Sci. 1989, 44, 1413–1430. [Google Scholar] [CrossRef]
- Piazza, C.; Rossi, S. Reasoning about Proportional Lumpability. In Proceedings of the Quantitative Evaluation of Systems, Paris, France, 23–27 August 2021; Springer: Berlin/Heidelberg, Germany, 2021; Volume 12846, pp. 372–390. [Google Scholar] [CrossRef]
- Smuseva, D.; Marin, A.; Rossi, S. Selfish Mining in Public Blockchains: A Quantitative Analysis. In Proceedings of the EAI International Conference on Performance Evaluation Methodologies and Tools, Crete, Greece, 6–7 September 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 18–32. [Google Scholar] [CrossRef]
- Ross, S.M. Stochastic Processes, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 1996. [Google Scholar]
- Taylor, H.M.; Karlin, S. An Introduction to Stochastic Modeling; Academic Press: Cambridge, MA, USA, 1998; Chapter IX. [Google Scholar]
- Jacobi, M.N. A robust spectral method for finding lumpings and meta stable states of non-reversible Markov chains. Elect. Trans. Numer. Anal. 2010, 37, 296–306. [Google Scholar]
- Derisavi, S.; Hermanns, H.; Sanders, W.H. Optimal state-space lumping in Markov chains. Elsevier Inf. Process. Lett. 2003, 87, 309–315. [Google Scholar] [CrossRef]
- Baarir, S.; Beccuti, M.; Dutheillet, C.; Franceschinis, G.; Haddad, S. Lumping partially symmetrical stochastic models. Perform. Eval. 2011, 68, 21–44. [Google Scholar] [CrossRef]
- Sumita, U.; Rieders, M. Lumpability and time-reversibility in the aggregation-disaggregation method for large Markov chains. Commun. Stat. Stoch. Models 1989, 5, 63–81. [Google Scholar] [CrossRef]
- Wei, J.; Kuo, J.C. Lumping analysis in monomolecular reaction systems. Analysis of the exactly lumpable system. Ind. Eng. Chem. Fundam. 1969, 8, 114–123. [Google Scholar] [CrossRef]
- Tomlin, A.S.; Li, G.; Rabitz, H.; Tóth, J. The effect of lumping and expanding on kinetic differential equations. SIAM J. Appl. Math. 1997, 57, 1531–1556. [Google Scholar] [CrossRef]
- Frostig, E. Jointly optimal allocation of a repairman and optimal control of service rate for machine repairman problem. Eur. J. Oper. Res. 1999, 116, 274–280. [Google Scholar] [CrossRef]
- Hooghiemstra, G.; Koole, G. On the convergence of the power series algorithm. Perform. Eval. 2000, 42, 21–39. [Google Scholar] [CrossRef]
- Katehakis, M.; Derman, C. Optimal Repair Allocation in a Series System. Math. Oper. Res. 1984, 9, 615–623. [Google Scholar] [CrossRef]
- Katehakis, M.; Smit, L. A successive lumping procedure for a class of markov chains. Probab. Eng. Informational Sci. 2012, 26, 483–508. [Google Scholar] [CrossRef]
- Ungureanu, V.; Melamed, B.; Katehakis, M.; Bradford, P. Deferred Assignment Scheduling in Cluster-Based Servers. Clust. Comput. 2006, 9, 57–65. [Google Scholar] [CrossRef]
- Valmari, A.; Franceschinis, G. Simple O(m logn) Time Markov Chain Lumping. In Proceedings of the International Conference on TACAS, Edinburgh UK, 15–19 July 2010; Springer Verlag: Berlin/Heidelberg, Germany, 2010; Volume 6015, pp. 38–52. [Google Scholar] [CrossRef]
- Groote, J.F.; Rivera Verduzco, J.; De Vink, E.P. An Efficient Algorithm to Determine Probabilistic Bisimulation. Algorithms 2018, 11, 131. [Google Scholar] [CrossRef]
- Hillston, J.; Marin, A.; Piazza, C.; Rossi, S. Persistent stochastic non-interference. Fundam. Informaticae 2021, 181, 1–35. [Google Scholar] [CrossRef]
- Tribastone, M.; Duguid, A.; Gilmore, S. The PEPA Eclipse Plug-in. Perf. Eval. Rev. 2009, 36, 28–33. [Google Scholar] [CrossRef]
- Carlsten, M.; Kalodner, H.; Weinberg, S.M.; Narayanan, A. On the instability of bitcoin without the block reward. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 154–167. [Google Scholar] [CrossRef]
- Eyal, I.; Sirer, E.G. Majority is not enough: Bitcoin mining is vulnerable. Commun. ACM 2018, 61, 95–102. [Google Scholar] [CrossRef]
- Göbel, J.; Keeler, H.P.; Krzesinski, A.E.; Taylor, P.G. Bitcoin blockchain dynamics: The selfish-mine strategy in the presence of propagation delay. Perform. Eval. 2016, 104, 23–41. [Google Scholar] [CrossRef]
- Wright, C.S. The Fallacy of the Selfish Miner in Bitcoin: An Economic Critique. Soc. Sci. Res. Netw. 2018. [Google Scholar] [CrossRef]
- Motlagh, S.G.; Mišić, J.; Mišić, V.B. The Impact of Selfish Mining on Bitcoin Network Performance. IEEE Trans. Netw. Sci. Eng. 2021, 8, 724–735. [Google Scholar] [CrossRef]
- Pattipati, K.R.; Kostreva, M.M.; Teele, J.L. Approximate mean value analysis algorithms for queuing networks: Existence, uniqueness, and convergence results. J. ACM 1990, 37, 643–673. [Google Scholar] [CrossRef]
- Chandy, K.M.; Hergox, U.; Woo, L. Approximate Analysis of General Queueing Networks. IBM J. Res. Dev. 1975, 19, 43–49. [Google Scholar] [CrossRef]
- Miner, A.S.; Ciardo, G.; Donatelli, S. Using the exact state space of a Markov model to compute approximate stationary measures. In Proceedings of the 2000 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, New York, NY, USA, 18–21 June 2000; pp. 207–216. [Google Scholar] [CrossRef]
- Gilmore, S.; Hillston, J.; Ribaudo, M. An Efficient Algorithm for Aggregating PEPA Models. IEEE Trans. Softw. Eng. 2001, 27, 449–464. [Google Scholar] [CrossRef]
- Casagrande, A.; Dreossi, T.; Piazza, C. Hybrid Automata and ϵ-Analysis on a Neural Oscillator. In Proceedings of the Proceedings First International Workshop on Hybrid Systems and Biology, HSB, Newcastle Upon Tyne, UK, 3 September 2012; Volume 92, pp. 58–72. [Google Scholar] [CrossRef]
- Thomas, N.; Bradley, J.T.; Thornley, D.J. Approximate solution of PEPA models using component substitution. In Proceedings of the IEE Proceedings—Computers and Digital Technique; IET Digital Library: Stevenage, UK, 2023; Volume 150, pp. 67–74. [Google Scholar] [CrossRef]
- Thomas, N. Behavioural independence and control in PEPA. In Proceedings of the First Workshop on Process Algebra with Stochastic Timed Activities (PASTA’02), Edinburgh, UK, 2002; Newcastle University Library: Newcastle Upon Tyne, UK, 2002. [Google Scholar]
- Gribaudo, M.; Sereno, M. Approximation Technique of Finite Capacity Queuing Networks Exploiting Petri Net Analysis. In Proceedings of the Fourth International Workshop on Queuing Networks with Finite Capacity (QNETs 2000), lkley, UK, 20–21 July 2000. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
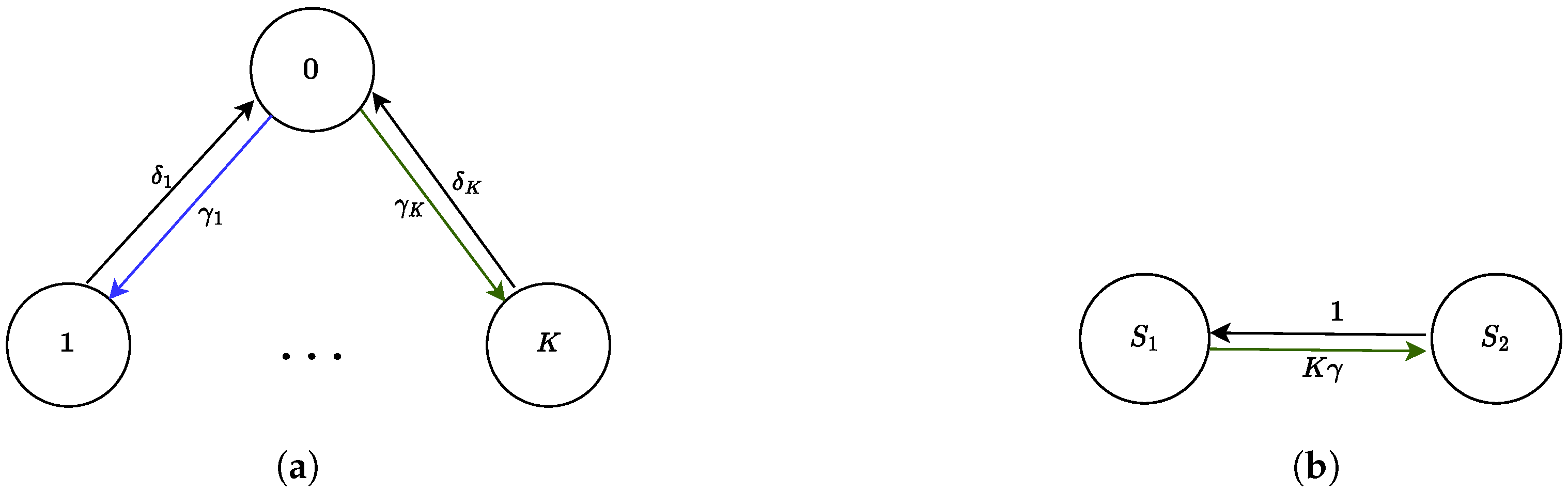{kind=link}
{kind=link}
{kind=link}
| where | and | |
| C | ||
| where | and | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Piazza, C.; Rossi, S.; Smuseva, D. Efficient Algorithm for Proportional Lumpability and Its Application to Selfish Mining in Public Blockchains. Algorithms 2024, 17, 159. https://doi.org/10.3390/a17040159
Piazza C, Rossi S, Smuseva D. Efficient Algorithm for Proportional Lumpability and Its Application to Selfish Mining in Public Blockchains. Algorithms. 2024; 17(4):159. https://doi.org/10.3390/a17040159
Chicago/Turabian StylePiazza, Carla, Sabina Rossi, and Daria Smuseva. 2024. "Efficient Algorithm for Proportional Lumpability and Its Application to Selfish Mining in Public Blockchains" Algorithms 17, no. 4: 159. https://doi.org/10.3390/a17040159