1. Introduction
Ultrasonic (UT) non-destructive evaluation (NDE) is used in many applications to establish a fitness-for-service argument for components under test [
1]. Its usage is widely established in safety-critical contexts such as aviation and nuclear energy [
2]. Despite its usefulness, the manual analysis of UT datasets is costly and time-consuming and there is considerable interest in automating the process. This is true for nuclear energy in particular, as ongoing concerns for the environment have sponsored a renewed interest in nuclear energy production as the emissions-free energy it produces may help in stemming the tide of global warming. In order to enhance the cost-effectiveness of nuclear energy relative to emissions-producing alternatives, nuclear plant owner–operators are investigating the use of statistical learning techniques to reduce the financial impact of necessary but costly UT NDE data analysis.
While modern statistical learning methods [
3] providing decision support in industrial contexts show great promise, the risk and consequence of failure often prevents their usage in highly regulated safety-critical contexts. It is the failure of such methods to provide guarantees on out-of-distribution performance that most strongly prejudices against their usage in the field where any number of factors may impact or skew the distribution of acquired data away from the training data and perhaps negatively impact performance [
4]. Our contribution is to demonstrate a principled usage of a state-of-the-art generative model that trains offline on each dataset independently, and so depends only on the distribution of the data at hand, skirting any dependence on out-of-distribution generalization. We work with generative models based on variational inference that allow us to describe, understand, and proof test performance using probabilistic reasoning that captures the method’s rationale in a way that regulators familiar with probabilistic risk assessment might be comfortable with.
As shown in
Figure 1, we summarize a UT data set of
ascans as a time series consisting of the peak amplitude response time of flight for each
ascan. We express the UT data analysis task, on the time series, in probabilistic terms that relate it to a Conditional Score-Based Diffusion (CSDI) [
5] loss function and train a CSDI model to perform the probabilistically specified task. We use the threshold reconstruction error of a Variational Autoencoder trained to encode and decode UT
to partition the time series dataset as nominal and anomalous subsets; by ignoring the anomalous subset during training, the dataset distribution is effectively biased towards the nominal distribution. Sampling from the trained model and comparing sampled results to the observed data allows us to identify and quantify deviations from nominal.
The CSDI model is a conditional score-based derivative of DPM first introduced in [
6] and reformulated in [
7,
8]. The CSDI architecture differentiates itself by exhibiting state-of-the-art results for time series data imputation on numerous bench-marks and popular time series performance metrics [
5]. We use CSDI to impute or estimate unobserved nominal data in our UT NDE datasets. We investigate opportunities to improve nominal estimates by partitioning training datasets to induce bias towards the nominal distribution.
CSDI is based on DiffWave [
9], which in turn is based on a U-Net like architecture [
10]. U-Nets consist of a symmetric stacked encoder and decoder network; with the encoder a series of down-sampling blocks, and the decoder a series of up-sampling blocks. Skip connections run between the corresponding blocks of the encoder and decoder. CSDI models are defined as forward and reverse Markov chain processes, where the forward process noises an input data vector, bringing it from the input data distribution at time step
, to a Gaussian noise vector at time step
. The reverse process denoises, to bring a sampled noise vector at
, to the learned approximation of the data distribution at time step
. During training CSDI optimizes the error on a learned prediction of the noise that must be removed from the data at time step
t to bring it to the step-wise denoised data at time step
. In addition to time step information, CSDI models inject conditional masks, temporal embeddings, and feature embeddings to each up and down sampling block during training. The embeddings and masks get picked up by the attention mechanisms [
11] in the residual layers [
12] of the U-Net encoder and decoder blocks. The attention mechanisms facilitate the learning of the conditional data distribution.
2. Related Work
Automated Data Analysis of Pressure Tubes, an end-to-end expert system that provides decision support and explainability for automated flaw characterization in UT NDE data taken from PT, is proposed in [
13,
14,
15]. The system is based on deterministic rules and explainability is generated using a tree-based system developed with input from practitioners. Ref. [
16] investigates the use of a self-supervised two-stage Decibel Scan (DBSCAN)-based method to identify and cluster anomalies in UT NDE data taken from PT. The first stage clusters on the basis of learned features in the data, the second on the basis of location. A proof-of-concept supervised CNN based architecture is used in [
17] to identify flaws in PT UT data. Labels are provided by manual data analysis and training data are down-sampled and concatenated to manage compute requirements. The results suggest that supervised training methods are able to identify suitably labeled flaw regions in UT data, but the results are adversely impacted by noise in the dataset.
All referenced work shares a dependency on labelled data and out of distribution generalization. In the case of [
13,
14,
15] labels and analysis are required in order to generate the set of rules on which the system operates. In the case of [
17], labeled data are required to train the neural networks used to identify flaws. The robustness of any system relying on labelled data depends on the amount of labeled data provided; more is considered better. The use of large datasets supports generalization in the type of deep learning systems trained in [
17] and will allow rules-based systems, as in [
13,
14,
15], to account for a wider variety of field conditions. The difficulty in terms of real-world applications of sufficient complexity is that field conditions may vary widely and in an unanticipated fashion, so that a dataset of any size cannot be guaranteed to provide the information required for sufficient generalization.
4. Dataset Details
The UT probe acquiring the data is situated on a rotating mechanical head which when centered inside an empty PT, and pushed very slowly down its length as the head spins, allows data acquisition over the entire inner diameter surface of the PT in a tight corkscrew pattern. Our dataset contains 3600
per head rotation, on an axial raster of ∼0.2 mm. In this dataset the subject under test is a calibration fixture, which is a mock PT, scanned before every real PT inspection. The signal response from notches in the fixture is used to verify and tune UT probes to meet inspection quality requirements.
Figure 1 provides a detailed look at a portion of our dataset. Each
in the dataset is associated with the tool position (axial and rotary) and time of data acquisition. This allows the set to be ordered (and visualized) in time, or position, of acquisition as desired.
For our purposes we reduce the dimensionality of the
dataset, summarizing each
by the time of flight of its maximum value
, which we refer to as peak amplitude response time of flight. This is simply the time in
s at which the peak value of a given
(such as those in the top right column of
Figure 1) occurs. Multiplying
by the speed of sound
v in
(deuterium oxide, or heavy water, is the nuclear fuel coolant in a CANDU reactor) gives the round-trip distance between the UT probe and the primary reflector, in this case the calibration fixture inner diameter pipe wall.
We can extract
from a given
using an
function (scientific computing software libraries generally include an
function that will return an array’s maximum value and index) operating on the
data vector. So, given a set of
with elements
a, we construct dataset
as follows:
where
yields
for
.
5. Manual Data Analysis on the Manifold
UT NDE data analysis often involves the identification and characterization of variance from the nominal trend in some set of assumed continuous measured quantities. In fact, the estimation of the difference between an observed and an inferred nominal value constitutes the bulk of UT NDE data analysis effort. In most industrial contexts, anomalies have a relatively low rate of occurrence and this puts discriminative learning methods, which rely on a balance of classes within the dataset, at a disadvantage. As we will demonstrate, generative models like Variational Autoencoders (VAE) and Diffusion Probabilistic Models (DPM) are accommodating in this regard, in that they allow us to leverage the prevalence of the nominal trend within the data to predict a would-be nominal signal where it is unobserved. As an added bonus, the semantics of variational inference lend well to the expression of the UT NDE data analysis task as sampling from learnable distribution, which facilitates a technical justification for the use of generative methods in highly regulated contexts conversant in probabilistic risk assessment.
An extension of the manifold hypothesis [
19] is that there exists a set of distinct data-generating factors, each contributing to the distribution of an observed data set [
20]. Given this is true, we could say that in some sense the process of manual UT data analysis involves classifying the data caused by these factors as nominal or anomalous and then using the classification to identify and infer a possibly obscured nominal trend. We draw from the concept of data generating factors and assume the existence of two groups of factors in our dataset. A nominal group consisting of all factors supporting the smooth operation of the data-acquisition system over a continuous surface of the material under test. And an anomalous set of data generating factors—those causing spurious or noisy operation in data acquisition and those causing unanticipated discontinuity in the otherwise-continuous properties and features of the material under test.
On the basis of this understanding, we can reframe the task of the analyst as the determination of a partition for nominal and anomalous data and subsequent estimation of the nominal trend on the basis of the nominal information. Ultimately identifying the nominal trend allows the estimation of unobserved nominal data, which in turn supports the estimate of variance from an estimated nominal in observed anomalous data.
Traditional approaches to establish a useful partition may involve some form of data classification and curve fitting. For instance, some threshold may be used to partition observed data, and then some curve fitting technique applied to identify nominal trend. However, accurate identification of the nominal trend is sensitive to the quality of the partition. Given a correct partition the relative ease of identifying nominal trend follows. But, as in
Figure 2, heuristic approaches are brittle and fail when the partition mixes support from nominal and anomalous data-generating factors. This detracts from the usefulness of such methods, as the difficulty in diagnosing errors leads to a lack of confidence in results.
6. A Probabilistic Model for UT Data Analysis
Given an ordered set of
taken as a UT probe passes over the surface of a test subject. Let dataset
be the similarly ordered peak amplitude response time of flight of each
in the set. Let the ordering provide a one-to-one mapping between each
and a unique time and position of data acquisition. Define
as the union of nominal and anomalous data subsets
and
so that
is partitioned:
Then according to our understanding of data generating factors
x is distributed as joint probability
where
and
.
We define dataset with elements to allow reference to unobserved nominal data. The are the nominal signals that would have been observed were it not for the occurrence of an anomalous data generating factor. In terms of causality we might conceive of as the observations that would have occurred had we intervened to constrain the effect of anomalous data-generating factors.
We desire estimates for
. An analyst estimates the unobserved nominal data by first classifying observed data as either nominal or anomalous and then estimating unobserved nominal data on the basis of observed local nominal signal. This estimate relies on an inference process that makes strong use of the observed element wise continuity in
. We model this estimation process as sampling the unobserved nominal with a conditional dependence on the observed nominal:
In the unsupervised learning setting we are given no knowledge of membership in
,
, or
. The best we can do directly from the dataset is sample
. We believe that with some engineering we can do better than this, and make the reasonable assumption that unobserved nominal data are distributed as the observed nominal so that
Substituting
for
in Expression (
4) gives
which, given the assumptions, allows the estimation of
by way of some unsupervised generative model trained to sample from
by training on partitioned dataset
.
Because PT are well maintained, and data are acquired with very strict quality controls, we expect that cardinality
. This implies that in general
and allows us to consider the approximation
This circuitously suggests a model trained on all observed data
which could also allow the accurate estimation of
. We coin Expression (
6) the Nominal Data Model (NDM), and (
8) the Observed Data Model (ODM).
7. Diffusion Probabilistic Models
Diffusion Probabilistic Models (DPM) are a class of latent variable models of the form
where the data vector
is of the same dimension as latent vectors
and
p is parameterized by
[
7]. The model chains the input variable vector
with the
T latent variable vectors and defines a forward and reverse process over the chain. The model architecture presumes a learned Gaussian transition from each vector in the chain to the next, with each transition parameterized by a neural network of input and output dimension equal to the input variable vector. (We assume that the reader is familiar with the semantics and notation that is the lingua franca of variational inference and diffusion processes so that this high-level overview may serve as a refresher. For a full treatment and development of variational inference and VAE, see [
21], for Denoising Diffusion Probabilistic Models see [
7], and for Conditional Score-Based Diffusion, see [
5]).
The approximate posterior
, or forward process, is defined as a Markov chain that transforms input data vectors to a target distribution by gradually adding noise at each of
T steps according to a learnable variance schedule
:
The reverse process is a joint probability
defined as a Markov chain starting at
that transforms its input across
T learned Gaussian transitions:
Diffusion models admit closed form expressions for sampling
at arbitrary step
t. Being differentiable they support training by stochastic gradient descent to optimize the variational lower bound
L on negative log likelihood:
where
is the expectation. Sampling of
at arbitrary time step
t is achieved as follows:
where
and
.
7.1. Denoising Diffusion Probabilistic Models
Denoising Diffusion Probabilistic Models (DDPM) reformulate the variational bound in Equation (
11) [
7] as follows:
where the forward process variance schedule
, which may be learned, is fixed to constants. This removes all learnable parameters from the first term of Equation (
13); removing it from consideration during training. The reverse process covariance matrix
is also set to step dependent unlearned constants; which removes it from consideration during training also. Reparameterizing the sampling procedure in Equation (
12) with
where
leads to the parameterization
where
is a learnable denoising function that reverses the forward process. With this parameterization, the DDPM loss function reduces to
The DDPM model includes a decoder in the final step of the reverse process to improve sampling. The decoder relies on the linear scaling of data on the range and allows the direct sampling of without any addition of noise.
7.2. Conditional Score-Based Diffusion
Conditional Score-Based Diffusion (CSDI) [
5] models introduce a conditional into the reverse process of the DDPM as follows:
where imputation targets
are unobserved data, and
are the observed data on which estimates of the unobserved data are made conditional. Introducing a conditional into the expression for
in the DDPM parameterization in Equation (
14), we arrive at the parameterization for CSDI:
Which implies the corresponding CSDI loss function:
CSDI implements a self-supervised learning method, inspired by training in masked language models, which holds back observed data, in an amount determined by the “missing ratio” hyperparameter, as simulated unobserved targets with ground truth. The CSDI architecture uses an attention mechanism with multi-head and fully connected layers to identify temporal and feature dependencies. The feature dependencies are used to generate "side information" that is passed to the gated activation unit in each residual diffusion layer. The diffusion layers are each composed as a U-Net with skip connections all passing information to the final convolutional output layers.
8. Experiments and Results
We seek to interpret results in terms of the probabilistic models developed in
Section 6. Where alignment between the models and results gleaned from their implementations will be taken to imply that there exists a principled basis to which we may fix an understanding of performance, and that this may in turn provide the basis for a technical justification of the use of diffusion-based methods in safety-critical contexts. To make relevant observations we begin by constructing a number of datasets to train diffusion models on.
Dataset
that underlies the NPM and OPM of Expressions (
6) and (
8), respectively, is defined as a partition
that classifies the data as nominal or anomalous. To test the validity of the probabilistic models, and their DPM based implementations, we generate a collection of datasets each based on a unique partition of the data. We first use manual classification to construct a ground truth dataset
with partition formed by
, and
. We then use a method similar to that described in [
22] to construct a series of datasets with partitions generated using output from a VAE. Partitions are constructed by first training a VAE to encode and decode the
from which dataset
is derived. Then percentiles of the mean squared error of
reconstruction are used as thresholds to partition
so that the time of flight associated with
with a reconstruction error less than the threshold percentile value are classified as nominal, and otherwise anomalous. Thus, given the value of the 90th MSE percentile we construct dataset
the union of
, and
. Each of the constructed datasets is then a unique partition over the data.
We test DDPM and CSDI diffusion models on each of the datasets and train them for five epochs. Our implementations of DDPM and CSDI are based on the code provided with [
5]. The training of CSDI models requires a missing ratio hyperparameter which is equivalently expressed as the percentage rate of observed data held back as simulated ground truth during training. This percentage regulates the degree to which the conditional mechanism of the model is exercised on the observed nominal data. DDPM models do not exercise a conditional mechanism when training. We test CSDI models on the range of missing data rates
.
For each trained model we sample five estimates for each data-point in the dataset. We take the mean and standard deviation of each set of five samples and then fit a curve to the high confidence means with a standard deviation , using an SGF. We then take the mean squared, mean absolute, mean absolute percentage, and maximum absolute error of each fitted curve against a SGF fit of .
Table A1,
Table A2,
Table A3,
Table A4 and
Table A5 in
Appendix A tabulate the results of a series the experiments conducted as described above; results are also summarized in the series of plots given in
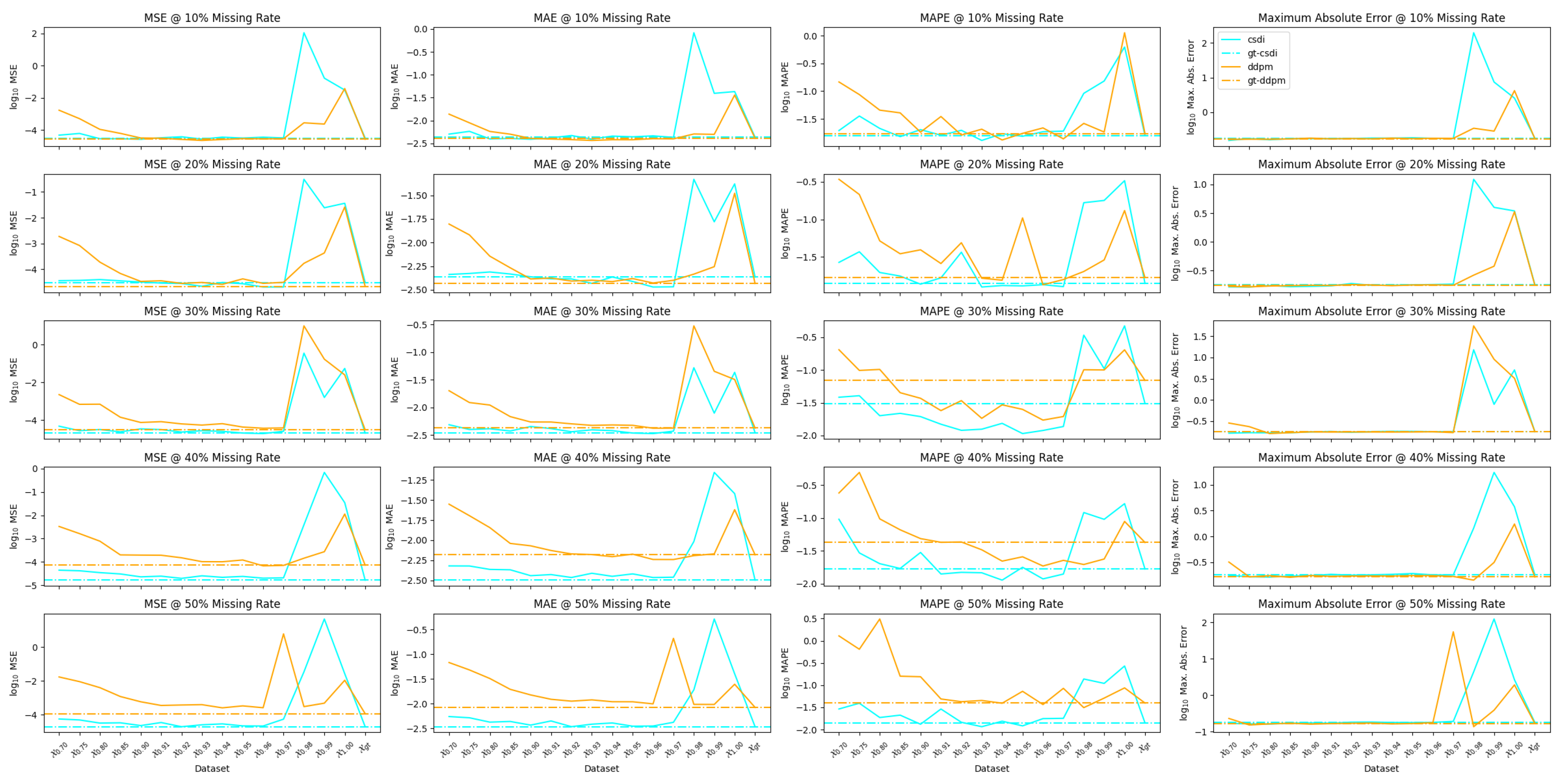
Figure 3. The plots in
Figure 3 reveal consistent dynamics related to the training of the models over the datasets. In general, the CSDI models outperform their DDPM counterparts and achieve the best performance in each error category with the exception of maximum absolute error. The hatched constant vertical lines in the plots of
Figure 3 show the performance of the models when trained on the ground truth dataset
. Although there are some exceptions, generally, models trained on the ground truth dataset out-perform their counterparts trained on the MSE threshold based datasets; this suggests that models trained on the ground truth datasets are indeed learning ∼
, while those trained on datasets whose partitions mix data from nominal and anomalous data generating factors are learning some other similar but different distributions. Further, we posit that when model performance on an arbitrary MSE dataset
meets or exceeds the performance of the same model when trained on
, then it is likely that the distribution learned by the model, presumably ∼
, is in some meaningful way similar to the distribution learned by the model trained on ground truth—presumably
. This line of thinking suggests that the NDM and ODM, in so far as they are able to predict aspects of implemented neural network performance, provide some measure of explainability to results. In a practical setting this explainability, in conjunction with quantitative targets for error, can be leveraged to generate confidence that a model has achieved a satisfactory level of performance, and allows regulators to understand the basis for results.
A consistent feature of the plots in
Figure 3 is a spike in error rates somewhere above the 96th MSE percentile.
Figure 4 may explain this by providing insight into the quality of the data being added to the nominal population at the high MSE threshold range. It is at just above the 96th MSE percentile that the qualitative nature of the intersection population growth curves changes. We note that at the lower range of threshold values, changes in intersection membership occur in large steps. At the upper range of threshold values, the change in membership occurs more smoothly. This speaks directly to the uniqueness, or alternatively to the amount of information, in the data being added to the intersection. As per information theory, the more unique a datum, the more information it carries relative to the data. So, we observe that as intersection set membership additions become increasingly unique, the model error in
Figure 3 increases dramatically. This suggests that the trend of the highly informative data are not as easily encoded as the more common low MSE data in the weights of the neural networks implementing the DPM.
From the perspective of the CSDI conditional loss function, the information content of the unique outliers is largely irrelevant. An outlying time of flight has very little information to relate about the largely continuous nominal signal in and around which it occurs. More over with their high information content the outliers are likely to generate some number of spurious correlations with the rest of the dataset. So the conditional CSDI model struggles, colloquially in two directions, to make sense of the highly informative anomalous information. Conversely, when on average there is less information per element in the nominal partition the CSDI model is enabled to learn the possibly continuous, possibly well-defined structure of the data. In the case of a highly structured dataset, each element bears a strong, identifiable, possibly causal conditional relation to neighboring data. CSDI leverages this conditional structure and given a largely nominal signal in the dataset readily learns the nominal distribution. DDPM models do not take advantage of this conditional perspective on the nominal information and, as borne out in the results, are slightly impaired in learning the nominal distribution. DDPM models are also more tolerant of outliers when they occur. This is directly observed in
Figure 3 where at thresholds less than the 96th MSE percentile CSDI models generally outperform DDPM models, but in the range above the 96th, their error ramps up quickly and often exceeds that of DDPM models.
Figure 5 show the results of a second set of experiments where we test the effect of enlarging a dataset with predominantly nominal signal. This drives the ratio of the nominal to total population in each dataset towards unity. This tests and affirms the assumption that
. We observe that as the dataset size increases MAE error improves across the range of datasets. We also observe that the range of error increases so that over and above the 96th percentile error ramps up more quickly as dataset size enlarges. This is suggests that as training becomes saturated by the nominal signal in the dataset the loss function naturally encodes information in the neural network weights that secure the most numerical benefit. This in turn causes error to become increasingly sensitive to anomalous data.
9. Practical Application and Future Work
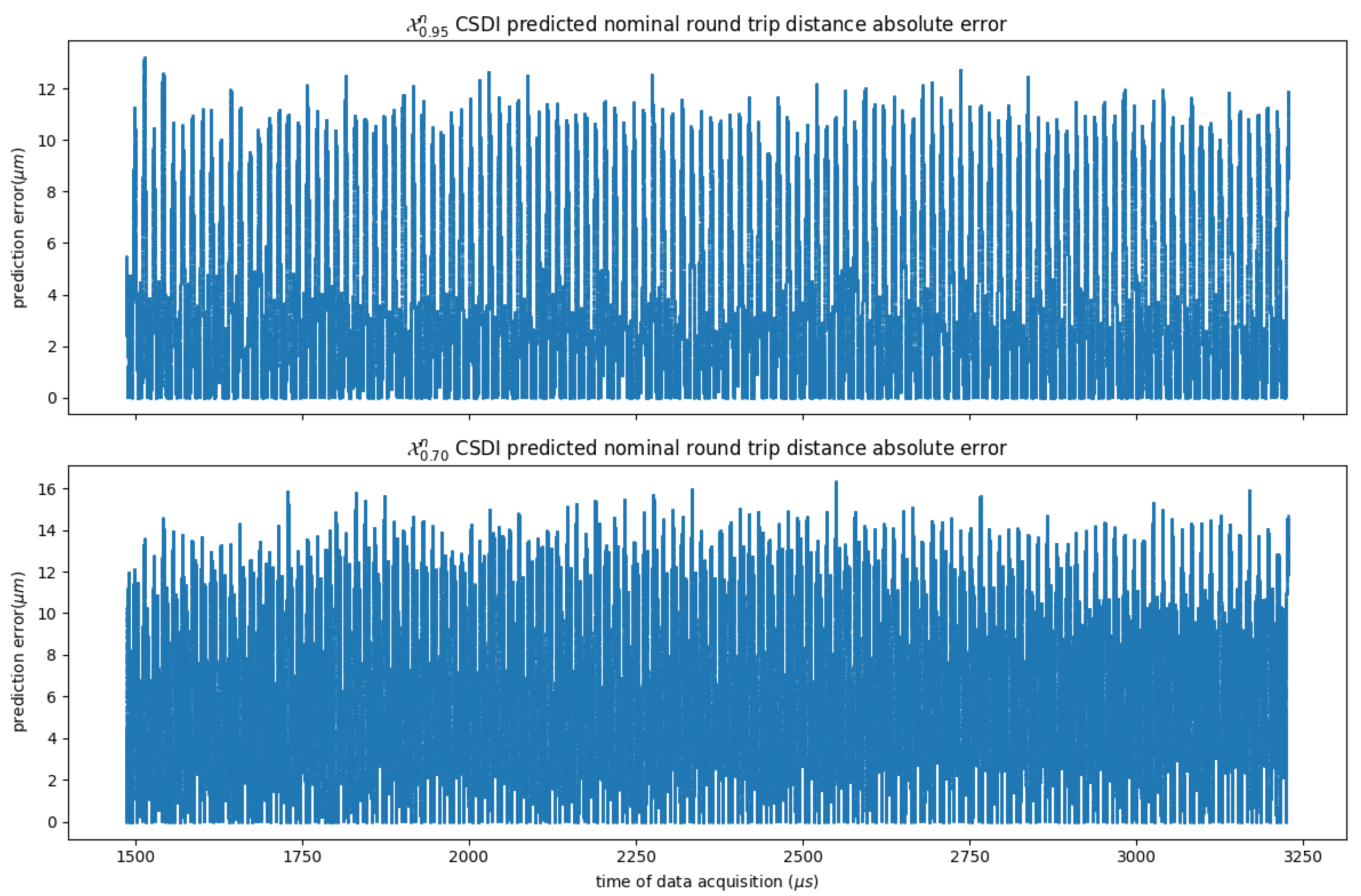
Figure 6 gives the error in microns (
m) against ground truth, for estimates of peak amplitude time of flight as provided by CSDI models trained on
and
partitioned datasets. For the UT NDE inspection of nuclear CANDU PT, the minimum deviation from nominal that must be reported is 100
m. In practice, the minimum reportable deviation sits at the edge of human cognitive abilities, and for anomalies in this range the data are often unclear, which causes analysis to be somewhat subjective. To support this point of view we note that, in the best conditions, subject matter experts consider the accuracy of manual analysis to be within a 40
m band. This suggests that the CSDI-based estimates are at least on par with manual analysis. To be sure, a further study and quantification of the delta between model-based estimates and manual analysis in the low range <100
m is required.
In-the-field usage of DPM-based estimates would require some means for fault diagnosis without reference to ground truth. There are numerous avenues for engineering solutions that involve the use of agreement between multiple independent estimation techniques. One opportunity for a second estimation technique, currently being investigated, involves the use of a dynamic nominal partition that changes in response to a self-supervised signal provided during training. Though this may improve the robustness of results, without ground truth we see no opportunity to provide concrete guarantees on model performance. Given that this is the case, we think it likely that automation and decision support for UT NDE data analysis will necessarily involve a human in the loop, driving an iterative process of training, verification, and reclassification. So for instance, a practical procedure might assign a well chosen partition to a UT NDE dataset and train a model on it, and after sampling allow an analyst to verify the classification of data in regions where the sampled estimates vary, beyond some bound, from observed data. The analyst might then tweak the partition and retrain the model to achieve superior results. This process of training and directed manual reclassification would continue, until some quantifiable error objective was achieved; this process would almost surely force the nominal partition in the direction of ground truth and ensure satisfactory performance across the dataset.
A number of opportunities exist for improving results.
Figure 7 shows in detail the fit of CSDI estimates, as well as the support of
on which the model was trained. What is clear is that the SGF fit on estimates overshoots the weight of the data in and around regions where its derivative is close to zero. This wig wag could in part be due to the Gaussian prior distribution used by CSDI models, and could also in part be due to the nature of SGF curve fitting. A post-processing step that introduced weight to the SGF from observed data in and around the neighborhood of estimates might serve to ameliorate the wig wag. A slightly more involved improvement might involve the use of alternative priors, with more degrees of freedom than the Gaussian, in the diffusion process [
23].
One area of concern is the degree of support from nominal data on which estimates are based. Typically, inspection processes have some data quality argument attached to them that specifies the minimum level of support from observed data on which an estimate must be based. We pay attention, in
Figure 7, to the shaded gray region of the scatter plot showing the set membership in
on which CSDI estimates are based. There we see that the partition selected by the 95th MSE percentile discriminates against likely nominal observed data, and places it in
. Although the estimates are of high quality, it would be better, from a process quality point of view, to include the discriminated data in the nominal set. Again an iterative process with a human in the loop could include tools that identify regions of low support, allow for suitable data reclassification, and then retraining.
10. Conclusions
We model the UT NDE data analysis task probabilistically as the NDM and ODM and evaluate the potential to provide decision support and automation to UT NDE data analysis using their CSDI- and DDPM-based implementations. We demonstrate the veracity and utility of the NDM and ODM by way of their ability to explain the variance in CSDI and DDPM performance across a variety of uniquely partitioned UT NDE datasets. We show that the NDM and ODM provide a basis for understanding the behavior of their CSDI and DDPM based implementations. And thus provide a basis for a technical justification needed to support the use of diffusion based methods in safety critical contexts in practice.
We train the CSDI model on various datasets to learn the NDM and sample from it to obtain estimates of peak amplitude response time of flight. We sample estimates from trained CSDI models and find their accuracy, against ground truth, to be on par with manual analysis. The unsupervised training procedure does not rely on dataset labelling or annotation, and the accuracy of sampled estimates depends only on learning the distribution of a single dataset. In this way, the approach may be used offline on a per-inspection basis, with no data annotation, and without recourse to out of distribution generalization. We suggest various means to improve results and confidence therein. We also suggest an iterative human-in-the-loop training verification process that may act, in lieu of the availability of ground truth, as a means for fault detection and remediation.
The method improves greatly upon prior work where results rely on data annotation, pre-processing, brittle heuristics, and out-of-distribution generalization. And the probabilistic model-based explainability provides a basis for interface with regulatory bodies seeking some justification for usage of novel methods in safety-critical contexts.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






