
Simulation of Calibrated Complex Synthetic Population Data with XGBoost


Abstract
1. Introduction
1.1. Synthetic Data
- -
- Socio-demographic-economic structure of persons and strata need to be reflected.
- -
- Marginal distributions and interactions between variables should be represented correctly.
- -
- Hierarchical and cluster structures have to be preserved.
- -
- Certain marginal distributions must exactly match known values.
- -
- Data confidentiality must be ensured; thus, replication of units (e.g., using a bootstrap approach) should be avoided.
1.2. Synthetic Populations
1.3. Non-Linear Synthesizers
1.4. Calibration
1.5. Calibration of Populations
1.6. Outline
- The synthetic hierarchical structure is simulated, e.g., age and gender of persons in households.
- Synthetic data simulation with XGBoost to simulate synthetic population data with (possible) complex structures (like persons in households) from complex samples with (possible) complex sampling plans.
- Calibration of the simulated population to known margins with a new calibration technique that allows multiple margins for different information (e.g., household information and personal information simultaneously).
- -
- In Section 2.3, the well-known XGBoost method is introduced in a general manner. After this short introduction, the simulation of the synthetic population is shown.
- -
- The first aim is to create a synthetic structural file (Section 2.2, cf. Figure 1, first point) that includes the cluster information.
- -
- Using the information of the non-anonymized data and the synthetic hierarchical/cluster structure, the remaining variables can now be simulated using XGBoost (cf. Figure 1, second point). While random forests build their regression trees independently (for each variable to be simulated), XGBoost improves the selection of trees at each step. XGBoost thus generally combines two important aspects: non-linear adjustments and improvements (due to a loss function) in each selected tree. The adaption of XGBoost to be used to simulate synthetic variables is described in Section 2.3.3 and the information used is visible in Figure 1. The cross-validation procedure to determine the hyperparameters in XGBoost is also reported in Section 2.3.4. After simulation of the synthetic population (see Figure 1, third step), the quality of the simulated data is discussed in Section 2.4.
- -
- Section 3 then shows how the simulated population can be calibrated to known multiple population margins (e.g., margins on households and information on persons in Section 3.2) considering the cluster structure in the data. Several subsections (Section 3.3, Section 3.4 and Section 3.5) are dedicated to this problem. Note that the draft version of this calibration method was already implemented in the R package simPop but has never been published in a scientific journal, and we have considerably extended the methods within this contribution.
- -
- Section 3.6 shows the impact of calibration on several statistics.
- -
- Section 4 discusses the implications of these methods for applications and science.
- -
- Since we have also implemented the methods in software, we outline the use of this software using complex data sets in Appendix A, Appendix B and Appendix C. The corresponding data set is described in Section 2.1. The illustration with code in an application allows the reader to see the connection from theory to application in software and to obtain an impression of how the methods can be used in practice.
2. Synthetic Data Generation
2.1. Data Set Used in the Method Application
2.2. Simulation of Cluster Structures
| Algorithm 1 Simulate cluster structure using simPop |
|
2.3. Synthetic Data Generation with XGBoost
2.3.1. General Comments on XGBoost
2.3.2. Advantages of XGBoost for Synthetic Data Generation
- Ensemble methods such as XGBoost are widely used in the data science community due to their solid out-of-the-box performance [23] allowing, e.g., also non-linear relationships. This solid out-of-the-box performance makes the XGBoost algorithm an optimal candidate for synthetic data generation, as the underlying distributions are often unknown.
- The key improvements to previous ensemble methods are subsampling the data set with replacement and choosing a random feature set. These improvements lead to highly independent base classifiers, and thus the XGBoost algorithm is robust to overfitting.
- The XGBoost algorithm is scalable and generally faster than the classical gradient boost machine (GBM), which makes it an excellent choice for generating large synthetic data sets.
- Another important advance that makes this algorithm convenient in practice is its sparsity awareness. With the sparsity-aware split finding, it works with missing values by default. The split-finding algorithm learns the default direction at each branch directly from the non-missing data.
- Cache awareness and out-of-core computing are improvements that allow XGBoost for parallel computing.
- For both regression and classification, both types are implemented in various software products, such as the R package XGBoost (see [20]).
2.3.3. Sequentional Approach to Simulate Variables of a Data Set Using XGBoost
2.3.4. Modified k-Fold Cross-Validation
| Algorithm 2 Simulate an Additional Variable using XGBoost |
|
2.4. Synthetic Data Validation
- Statistical similarity measures how well the synthetic data replicate the statistical properties of the real data. Key aspects include descriptive statistics, distributional properties and correlation structures.
- Data utility measures how well synthetic data can be used in place of real data for specific tasks. This includes the predictive performance by training the machine learning models on the synthetic data and evaluating their performance on real data. Moreover, models trained on synthetic data should generalize well to real data, indicating that the synthetic data capture the essential patterns and relationships.
- Integrity and consistency checks ensure that the synthetic data maintain logical and business rules inherent in the real data:
- While synthetic data should closely resemble real data, they should also introduce some variability, e.g., ensure the synthetic data contain new combinations of features that are plausible within the context of the real data but were not present in the original data set.
3. Calibration of a Population
3.1. Post-Calibration with Combinatorial Optimization
- It is only possible to supply one target distribution as constraint. This can be a major limitation if only the marginal and not the joint distribution of variables for re-calibration are not available or accessible.
- Convergence of the SA is very slow because households are replaced using simple random sampling. Applying this algorithm to real-world applications, a population of tens of millions of people will yield costly run times and possibly fail to converge.
- Parameters T, c and n can strongly influence the convergence of the SA and adopting the choice of these parameters when the problem is split into multiple smaller subgroups is not supported.
| Algorithm 3 Calibration of the Synthetic Population using Simulated Annealing |
|
3.2. Including Multiple Different Target Margins
3.3. Efficient Re-Sampling of Households
3.4. Initialise and Adjust Number of Swaps N
3.5. Automatically Choosing T and Forcing Cooldowns
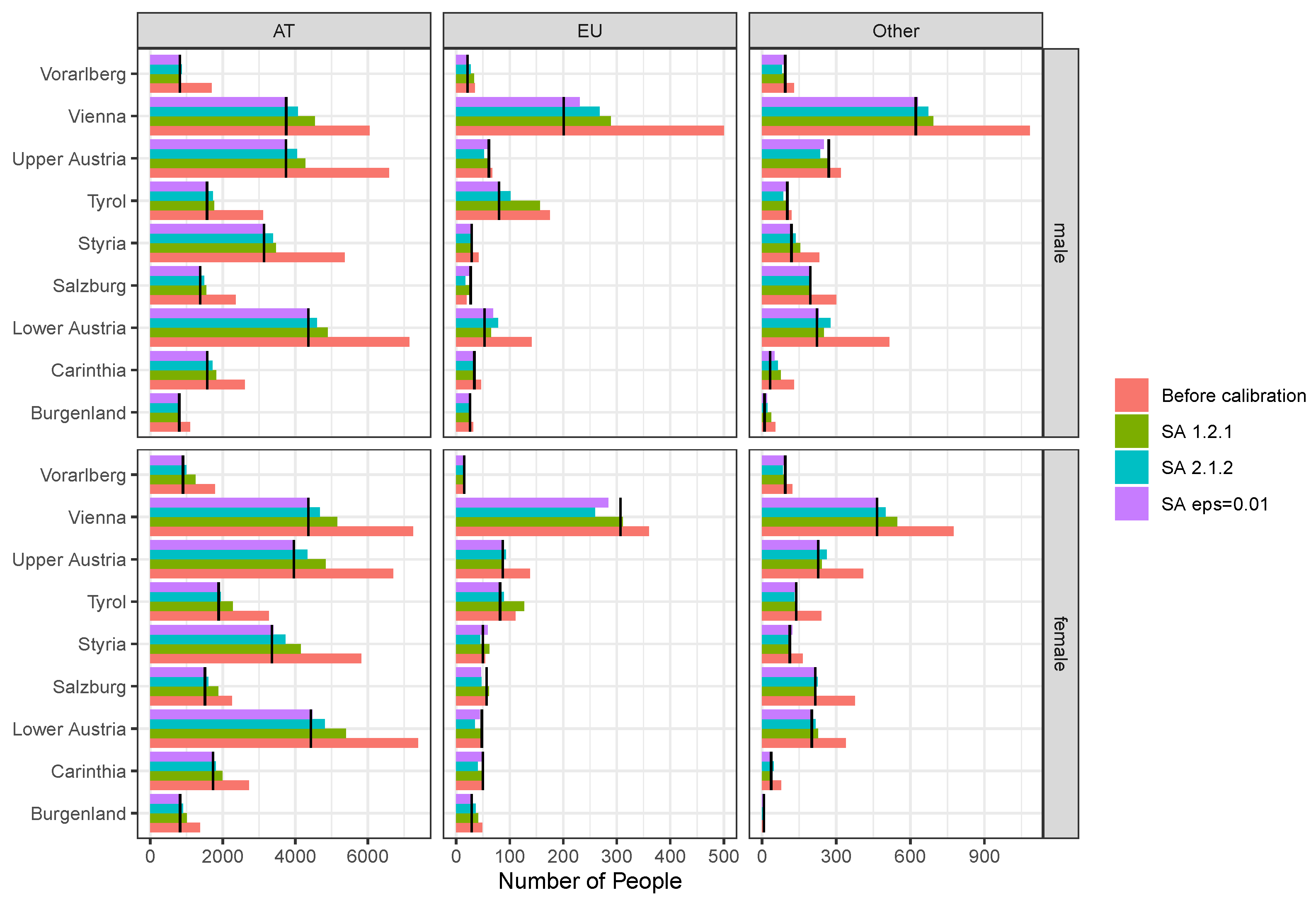
3.6. Application of the SA Algorithm
- Post-calibrate the synthetic population on a single target margin using the number of individuals by region, gender and citizenship
- Post-calibrate the synthetic population on two target margins using the number of individuals by region, gender and citizenship and number of households by region and household size.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Details on Selected Variables of the EU-SILC Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Type | Distribution |
|---|---|---|---|
| Equivalized household income | Yearly income according to OECD equivalence scale | continuous (median = 26.5) |  |
| HID | Longitudinal section household ID | multinomial 5983 levels | |
| D004010 | Household size | continuous (median = 2) |  |
| Name | Desc | Type | Distribution |
|---|---|---|---|
| sex | Sex | multinomial 2 levels |  |
| age | Age | continuous median 46 |  |
| bundesld | Region | multinomial 9 levels | 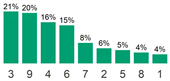 |
| P001000 | Economic status | multinomial 12 levels |  |
| P111010nu | Citizenship 1 | multinomial 7 levels |  |
| P114000 | Marital status | multinomial 7 levels |  |
| P137000 | Highest education level | multinomial 7 levels |  |
| P103000 | chronic illness | multinomial 4 levels |  |
Appendix B. Details on the Simulated Annealing Algorithm for the Calibration of Populations
Appendix B.1. Detailed Calibration Algorithm
| Algorithm A1 Detailed calibration algorithm |
|
Appendix B.2. Initialise and Adjust Number of Swaps N
Appendix B.3. Automatically Choosing T and Forcing Cooldowns
Appendix B.4. Hyperparameters in Package simPop for Population Calibration
| Function Argument | Parameter |
|---|---|
| choose.temp.factor | |
| scale.redraw | |
| observe.times | h |
| observe.break | |
| hhTables, persTables |
Appendix C. R-Code Examples
Appendix C.1. Simulation of Synthetic Data with XGBoost
Appendix C.2. Synthesizing Additional Variables
| db030 | hhsize | db040 | Age | rb090 | Pid | Weight | pl030 | pb220a | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 4570 | 1 | Lower Austria | 68 | male | 4570.1 | 1.00 | 5 | AT |
| 2 | 1735 | 1 | Carinthia | 65 | male | 1735.1 | 1.00 | 5 | AT |
| 3 | 655 | 2 | Burgenland | 55 | female | 655.1 | 1.00 | 5 | AT |
| 4 | 836 | 3 | Burgenland | 64 | female | 836.1 | 1.00 | 7 | AT |
| 5 | 2984 | 4 | Carinthia | 13 | female | 2984.4 | 1.00 | 4 | AT |
Appendix C.3. Hyperparameter Tuning for XGBoost
Appendix C.4. Post-Calibration First Scenario
Appendix C.5. Post-Calibration Second Scenario
References
- United Nations Economic Commission for Europe. Synthetic Data for Official Statistics: A Starter Guide; Technical Report, Report No. ECE/CES/STAT/2022/6; United Nations: Rome, Italy, 2022. [Google Scholar]
- Dwork, C. Differential Privacy. In International Colloquium on Automata, Languages, and Programming; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–12. [Google Scholar] [CrossRef]
- Fischetti, M.; Salazar-González, J. Complementary Cell Suppression for Statistical Disclosure Control in Tabular Data with Linear Constraints. J. Am. Stat. Assoc. 2000, 95, 916–928. [Google Scholar] [CrossRef]
- Enderle, T.; Giessing, S.; Tent, R. Calculation of Risk Probabilities for the Cell Key Method. In Privacy in Statistical Databases: UNESCO Chair in Data Privacy, Proceedings of the International Conference PSD 2020, Tarragona, Spain, 23–25 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 151–165. [Google Scholar] [CrossRef]
- Novák, J.; Sixta, J. Visualization of Record Swapping. Austrian J. Stat. 2024, 53, 1–16. [Google Scholar] [CrossRef]
- Yin, X.; Zhu, Y.; Hu, J. A Comprehensive Survey of Privacy-Preserving Federated Learning: A Taxonomy, Review, and Future Directions. ACM Comput. Surv. 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Templ, M.; Alfons, A. Disclosure Risk of Synthetic Population Data with Application in the Case of EU-SILC. In Privacy in Statistical Databases; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; pp. 174–186. [Google Scholar] [CrossRef]
- Templ, M. Providing Data with High Utility and No Disclosure Risk for the Public and Researchers: An Evaluation by Advanced Statistical Disclosure Risk Methods. Austrian J. Stat. 2014, 43, 247–254. [Google Scholar] [CrossRef]
- McClure, D.; Reiter, J. Assessing Disclosure Risks for Synthetic Data with Arbitrary Intruder Knowledge. Stat. J. IAOS 2016, 32, 109–126. [Google Scholar] [CrossRef]
- Alfons, A.; Kraft, S.; Templ, M.; Filzmoser, P. Simulation of Close-to-Reality Population Data for Household Surveys with Application to EU-SILC. Stat. Methods Appl. 2011, 20, 383–407. [Google Scholar] [CrossRef]
- Templ, M.; Filzmoser, P. Simulation and Quality of a Synthetic Close-to-Reality Employer–Employee Population. J. Appl. Stat. 2014, 41, 1053–1072. [Google Scholar] [CrossRef]
- Münnich, R.; Schürle, J. On the Simulation of Complex Universes in the Case of Applying the German Microcensus; DACSEIS Research Paper Series No. 4; University of Tübingen: Tubingen, Germany, 2003. [Google Scholar]
- Nowok, B.; Raab, G.; Dibben, C. synthpop: Bespoke Creation of Synthetic Data in R. J. Stat. Softw. 2016, 74, 1–26. [Google Scholar] [CrossRef]
- Templ, M.; Meindl, B.; Kowarik, A.; Dupriez, O. Simulation of Synthetic Complex Data: The R Package simPop. J. Stat. Softw. 2017, 79, 1–38. [Google Scholar] [CrossRef]
- Mendelevitch, O.; Lesh, M. Beyond Differential Privacy: Synthetic Micro-Data Generation with Deep Generative Neural Networks. In Security and Privacy from a Legal, Ethical, and Technical Perspective; IntechOpen: London, UK, 2020; pp. 1–14. [Google Scholar] [CrossRef]
- Solatorio, A.V.; Dupriez, O. REaLTabFormer: Generating Realistic Relational and Tabular Data using Transformers. arXiv 2023, arXiv:2302.02041. [Google Scholar] [CrossRef]
- Särndal, E. The Calibration Approach in Survey Theory and Practice. Surv. Methodol. 2007, 33, 99–119. [Google Scholar]
- Horvitz, D.G.; Thompson, D.J. A Generalization of Sampling Without Replacement from a Finite Universe. J. Am. Stat. Assoc. 1952, 47, 663–685. [Google Scholar] [CrossRef]
- Walker, A.J. An Efficient Method for Generating Discrete Random Variables with General Distributions. ACM Trans. Math. Softw. (TOMS) 1977, 3, 253–256. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ‘16, New York, NY, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Johnson, R.; Zhang, T. Learning Nonlinear Functions Using Regularized Greedy Forest. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 942–954. [Google Scholar] [CrossRef] [PubMed]
- Brandt, S. Statistical and Computational Methods in Data Analysis. Am. J. Phys. 1971, 39, 1109–1110. [Google Scholar] [CrossRef]
- Vorhies, W. Want to Win Competitions? Pay Attention to Your Ensembles. 2016. Available online: https://www.datasciencecentral.com/profiles/blogs/want-to-win-at-kaggle-pay-attention-to-your-ensembles (accessed on 25 February 2021).
- Huang, Z.; Williamson, P. A Comparison of Synthetic Reconstruction and Combinatorial Optimization Approaches to the Creation of Small-Area Micro Data; Working Paper 2001/02; Department of Geography, University of Liverpool: Liverpool, UK, 2001. [Google Scholar]
- Voas, D.; Williamson, P. An Evaluation of the Combinatorial Optimisation Approach to the Creation of Synthetic Microdata. Int. J. Popul. Geogr. 2000, 6, 349–366. [Google Scholar] [PubMed]
- Kirkpatrick, S.; Gelatt, C.; Vecchi, M. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Cerný, V. Thermodynamical Approach to the Traveling Salesman Problem: An Efficient Simulation Algorithm. J. Optim. Theory Appl. 1985, 45, 41–51. [Google Scholar] [CrossRef]
- Harland, K.; Heppenstall, A.; Smith, D.; Birkin, M. Creating Realistic Synthetic Populations at Varying Spatial Scales: A Comparative Critique of Population Synthesis Techniques. J. Artif. Soc. Soc. Simul. 2012, 15, 1. [Google Scholar] [CrossRef]
- Rubinyi, S.; Verschuur, J.; Goldblatt, R.; Gussenbauer, J.; Kowarik, A.; Mannix, J.; Bottoms, B.; Hall, J. High-Resolution Synthetic Population Mapping for Quantifying Disparities in Disaster Impacts: An Application in the Bangladesh Coastal Zone. Front. Environ. Sci. 2022, 10, 1033579. [Google Scholar] [CrossRef]
- Minnesota Population Center. Integrated Public Use Microdata Series, International: Version 7.3 [Dataset]; IPUMS: Minneapolis, MN, USA, 2020. [Google Scholar] [CrossRef]
- Müller, K. wrswoR: Weighted Random Sampling without Replacement; R package Version 1.1.1. 2020. Available online: https://CRAN.R-project.org/package=wrswoR (accessed on 1 May 2024).
- Fačevicová, K.; Hron, K.; Todorov, V.; Templ, M. Compositional Tables Analysis in Coordinates. Scand. J. Stat. 2016, 43, 962–977. [Google Scholar] [CrossRef]
- Fačevicová, K.; Hron, K.; Todorov, V.; Templ, M. General approach to coordinate representation of compositional tables. Scand. J. Stat. 2018, 45, 879–899. [Google Scholar] [CrossRef]
- Alfons, A.; Templ, M. Estimation of Social Exclusion Indicators from Complex Surveys: The R Package laeken. J. Stat. Softw. 2013, 54, 1–25. [Google Scholar] [CrossRef]
- Templ, M. Imputation and Visualization of Missing Values; Springer International Publishing: Cham, Switzerland, 2023; p. 561, in print. [Google Scholar]
- Chambers, J. Extending R; Chapman & Hall/CRC the R Series; CRC Press, Taylor & Francis Group: Boca Raton, FL, USA, 2016. [Google Scholar]
- XGBoost Developers. XGBoost Parameters. 2020. Available online: https://xgboost.readthedocs.io/en/latest/parameter.html (accessed on 15 December 2020).


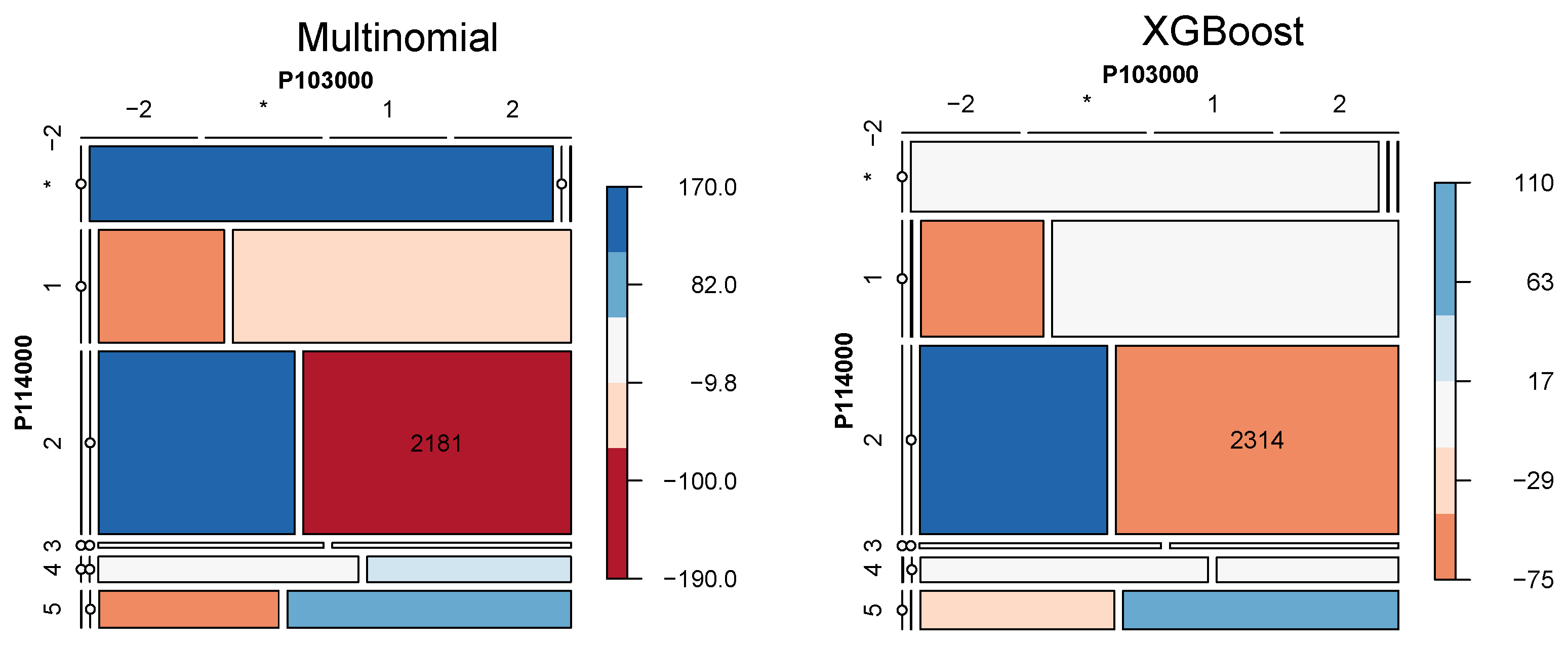


| MSE | MAE | Test Statistics | |
|---|---|---|---|
| Multinomial | 42 | 0.42 | 117.381 |
| XGBoost | 5 | 0.21 | 121.291 |
| MAE | MAPE | Avg. Aitchison | |
|---|---|---|---|
| Before calibration | 618.31 | 71.31 | 2.52 |
| SA 1.2.1 | 158.47 | 22.13 | 1.68 |
| SA 2.1.2 | 75.26 | 17.36 | 1.73 |
| SA | 8.02 | 7.41 | 1.27 |
| MAE | MAPE | Avg. Aitchison | ||
|---|---|---|---|---|
| Before calibration | 618.20 | 71.31 | 2.52 | |
| Person margins | Single margins | 75.26 | 17.36 | 1.73 |
| Multiple margins | 80.44 | 29.72 | 2.33 | |
| Before calibration | 280.22 | 40.03 | 0.31 | |
| Household margins | Single margins | 113.19 | 16.83 | 1.24 |
| Multiple margins | 54.72 | 9.75 | 0.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gussenbauer, J.; Templ, M.; Fritzmann, S.; Kowarik, A. Simulation of Calibrated Complex Synthetic Population Data with XGBoost. Algorithms 2024, 17, 249. https://doi.org/10.3390/a17060249
Gussenbauer J, Templ M, Fritzmann S, Kowarik A. Simulation of Calibrated Complex Synthetic Population Data with XGBoost. Algorithms. 2024; 17(6):249. https://doi.org/10.3390/a17060249
Chicago/Turabian StyleGussenbauer, Johannes, Matthias Templ, Siro Fritzmann, and Alexander Kowarik. 2024. "Simulation of Calibrated Complex Synthetic Population Data with XGBoost" Algorithms 17, no. 6: 249. https://doi.org/10.3390/a17060249
APA StyleGussenbauer, J., Templ, M., Fritzmann, S., & Kowarik, A. (2024). Simulation of Calibrated Complex Synthetic Population Data with XGBoost. Algorithms, 17(6), 249. https://doi.org/10.3390/a17060249