

Research on Distributed Fault Diagnosis Model of Elevator Based on PCA-LSTM

Abstract
1. Introduction
2. PCA-LSTM Based Fault Prediction Model
2.1. Introduction to Principal Component Analysis (PCA)
2.2. Long Short-Term Memory’s Introduction to Neural Networks (LSTM)
2.3. PCA-LSTM Fault Diagnosis Modeling
3. Distributed Elevator Fault Diagnosis System
3.1. Overview of Diagnostic Methods
3.2. Distributed Algorithms
- (1)
- Each node performs an aggregation operation (e.g., summing and averaging) on local data. Aggregation operations can be implemented using different algorithms, such as tree and butterfly algorithms.
- (2)
- Data are exchanged between nodes to accomplish the aggregation operation. These exchanges can be realized using peer-to-peer communication methods. For example, the MPI_Send and MPI_Recv functions are used in MPI, or they can be realized using aggregate communication methods such as the MPI_All reduce function in MPI.
- (3)
- Each node obtains an intermediate result.
- (1)
- The stochastic initialization of the model parameters is conducted.
- (2)
- For each training sample, the gradient (the inverse of the loss function with respect to the model parameters) is calculated.
- (3)
- The model parameters are updated using gradients, and the step size of the update is controlled based on the learning rate.
- (4)
- Steps 2 and 3 are repeated until a preset stopping condition is reached (e.g., a certain number of iterations is reached or the value of the loss function is less than a threshold), as shown in Figure 5.
- (1)
- Calculate the gradient of the loss function using a mini-batch on each elevator model.
- (2)
- Calculation of the average value of the gradient using interelevator communication.
- (3)
- Update the model; a schematic is shown in Figure 6.
| Algorithm 1: Decentralized distributed machine learning algorithm (D-PSGD) |
| The // algorithm is run on each individual worker node, here denoted as node k Initialize: Local model parameters on node k, the weight matrix, W, of network communication between individual nodes, i.e., the neighbor relationship, as well as the weights of the neighbors For t = 1, 2, …, T do Local construction of random samples (or small batches of random samples), Based on the , compute the local stochastic gradient Get each other’s parameters from neighboring nodes, and calculate the neighboring node parameter combinations Update the local parameters with a combination of the local gradient and the parameters of the neighbors together: end for Output: |
4. Experiments and Analysis
4.1. Description of the Experiment
4.2. Description of Data
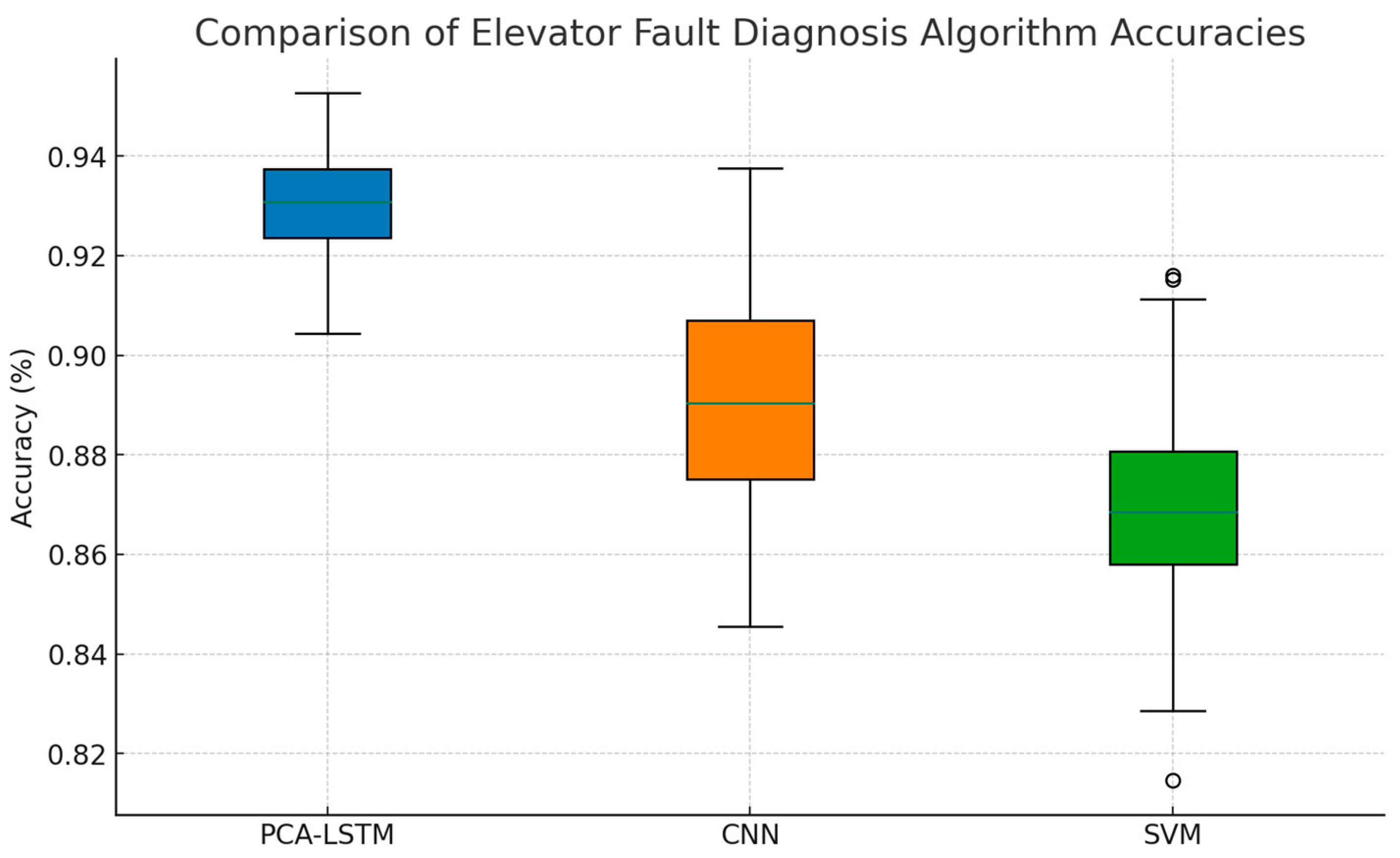
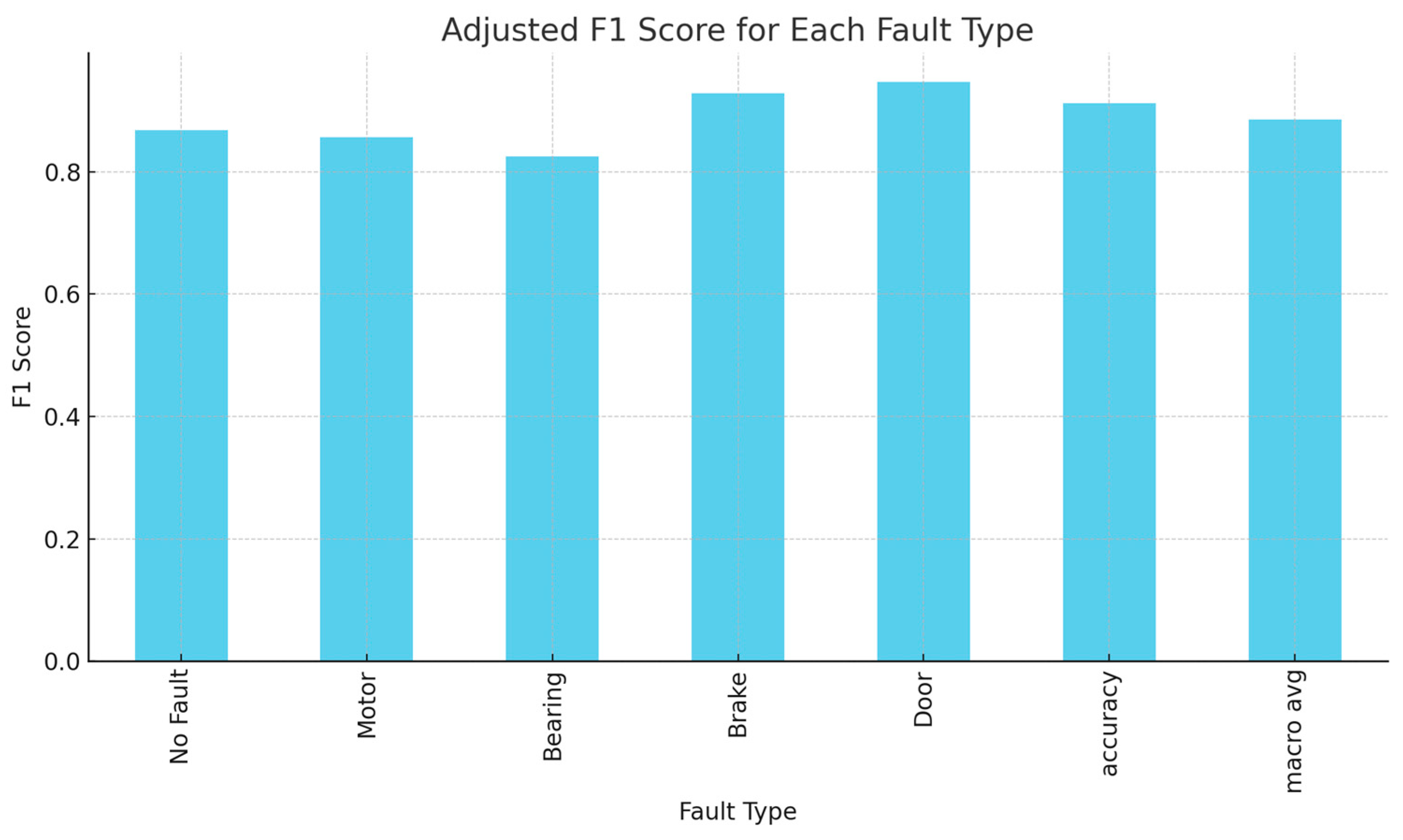
4.3. Results and Analysis
5. Conclusions
- (1)
- The PCA-LSTM-based elevator fault prediction method proposed in this study extracts feature information from various operational data of elevators and minimizes the reliance on manual labor for traditional elevator fault diagnosis.
- (2)
- The second core idea focuses on distributed elevator fault diagnosis. Through experiments, the proposed fault prediction method achieves an accuracy of more than 90% in classifying the fault types of multiple elevators under the same working conditions, and the distributed technology enables local fault diagnosis within the elevator, which alleviates pressure on the central processor.
- (3)
- Currently, the distributed elevator fault diagnosis technique based on the PCA-LSTM model proposed in this paper delivers more satisfactory results in terms of spatial distribution. However, concerning model integration and parameter exchanges, the communication time between adjacent elevators is prolonged, which, in turn, increases the training time. Consequently, the speed of elevator parameter exchanges in the distributed scenario requires further consideration in future developments.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lu, M.; Xie, Y.; An, Z. Elevator Error Diagnosis Method Based on Neural Network Model. In Proceedings of the 2023 International Conference on Network, Multimedia and Information Technology (NMITCON), Bengaluru, India, 1–2 September 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Liang, T.; Chen, C.; Wang, T.; Zhang, A.; Qin, J. A Machine Learning-Based Approach for Elevator Door System Fault Diagnosis. In Proceedings of the 2022 IEEE 18th International Conference on Automation Science and Engineering (CASE), Mexico City, Mexico, 20–24 August 2022; pp. 28–33. [Google Scholar] [CrossRef]
- Zheng, B. Intelligent Fault Diagnosis of Key Mechanical Components for Elevator. In Proceedings of the 2021 CAA Symposium on Fault Detection, Supervision, and Safety for Technical Processes (SAFEPROCESS), Chengdu, China, 17–18 December 2021; pp. 1–3. [Google Scholar] [CrossRef]
- Zhang, A.; Chen, C.; Wang, T.; Cheng, L. Fault diagnosis of Elevator Door Machines Based on Deep Convolutional Forest. In Proceedings of the 2022 27th International Conference on Automation and Computing (ICAC), Bristol, UK, 1–3 September 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Qiu, C.; Zhang, L.; Li, M.; Zhang, P.; Zheng, X. Elevator Fault Diagnosis Method Based on IAO-XGBoost under Unbalanced Samples. Appl. Sci. 2023, 13, 10968. [Google Scholar] [CrossRef]
- Chen, Z. An elevator car vibration fault diagnosis based on genetically optimized RBF neural network. China Sci. Technol. Inf. 2023, 30, 110–115. [Google Scholar]
- Liang, H.; Fushun, L.; Jie, L. Analysis of an elevator repeated door opening and closing fault using fault tree analysis. China Elev. 2023, 34, 71–73. [Google Scholar]
- Cong, W.; Mengnan, L.; Kun, L. Elevator bearing fault detection based on PBO and CNN. Inf. Technol. 2023, 47, 73–78. [Google Scholar]
- Li, Z.; Chai, Z.; Zhao, C. Abnormal vibration fault diagnosis of elevator based on multi-channel convolution. Control Eng. 2023, 30, 427–433. [Google Scholar]
- Wei, Y.; Liu, H.; Yang, L. Fault diagnosis method of elevator traction wheel bearing based on angular domain resampling and VMD. Mech. Electr. Eng. 2023, 8, 1259–1266. [Google Scholar]
- Jin, L.; Zhang, Z.; Shao, X.; Wang, X. Research on elevator fault identification method based on kernel entropy component analysis. Autom. Instrum. 2022, 39, 115–119. [Google Scholar]
- Liu, Y.; Zhao, Y.; Wei, B.; Ma, T.; Chen, Z. Research on elevator fault diagnosis system based on optimization neural network. Autom. Instrum. 2022, 39, 88–92. [Google Scholar]
- Dingsong, B.; Ziliang, A.; Ning, W.; Shaofeng, L.; Xintong, Y. The Prediction of the Elevator Fault Based on Improved PSO-BP Algorithm. J. Phys. Conf. Ser. 2021, 1906, 012017. [Google Scholar]
- Chen, L.; Lan, S.; Jiang, S. Elevators Fault Diagnosis Based on Artificial Intelligence. J. Phys. Conf. Series 2019, 1345, 042024. [Google Scholar] [CrossRef]
- Haoxiang, W.; Chao, L.; Dongxiang, J.; Zhanhong, J. Collaborative deep learning framework for fault diagnosis in distributed complex systems. Mech. Syst. Signal Process. 2021, 156, 107650. [Google Scholar]
- Jan, S.U.; Lee, Y.D.; Koo, I.S. A distributed sensor-fault detection and diagnosis framework using machine learning. Inf. Sci. 2021, 547, 777–796. [Google Scholar] [CrossRef]
- Murad, A.; Zakiud, D.; Evgeny, S.; Mehmood, C.K.; Ahmad, H.M.; Che, Z. Open switch fault diagnosis of cascade H-bridge multi level inverter in distributed power generators by machine learning algorithms. Energy Rep. 2021, 7, 8929–8942. [Google Scholar]
- Qiu, S.; Cui, X.; Ping, Z.; Shan, N.; Li, Z.; Bao, X.; Xu, X. Deep Learning Techniques in Intelligent Fault Diagnosis and Prognosis for Industrial Systems: A Review. Sensors 2023, 23, 1305. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Current (A) | Vibration (Gs) | Voltage (V) | … | Fault Type | |
|---|---|---|---|---|---|
| 1 | 10.8003144 | 0.5892473887 | 202.880298359057 | … | Motor |
| 2 | 13.52810469 | 0.5555962679 | 204.670789465698 | … | None |
| 3 | 11.90017683 | 0.5540773585 | 212.292156992934 | … | Bearing |
| …. | … | … | … | … | … |
| 21535 | 7.704778110 | 0.3858098580 | 207.87484255511 | … | Door |
| Sample Types | Number of Samples | |
|---|---|---|
| Monolayer | Anadromic | 500 |
| Descending | 500 | |
| Across 3 or 4 floors | Anadromic | 500 |
| Descending | 500 | |
| Across more than 4 floors | Anadromic | 500 |
| Descending | 500 | |
| Encodings | Failure Mode | Number of Samples |
|---|---|---|
| S1 | Safety circuit disconnected | 15 |
| S2 | Door lock disconnected | 15 |
| S3 | Drive Overload | 15 |
| S4 | Change-over stop failure | 15 |
| S5 | Current Detection Fault | 15 |
| S6 | Failure of door opening signal | 15 |
| S7 | Abnormal braking force of holding brake | 15 |
| S8 | Inadequate car damping system | 15 |
| S9 | Excessive leveling time | 15 |
| S10 | Composite faults | 15 |
| Principal Component | Classification Accuracy | Normal-State Accuracy | Open-Door-Failure Accuracy | Closed-Door-Failure Accuracy | Brake-Failure Accuracy | Number of Iterations |
|---|---|---|---|---|---|---|
| PCA1 | 83.61 | 90.36 | 83.92 | 81.65 | 88.82 | 100 |
| PCA2 | 90.23 | 90.87 | 85.22 | 72.56 | 89.64 | 100 |
| PCA3 | 82.25 | 88.55 | 71.33 | 73.52 | 93.21 | 100 |
| Model Type | Classification Accuracy/% | Number of Iterations | Testing Time | ||
|---|---|---|---|---|---|
| Training Set | Validation Set | Test Set | |||
| RNN | 73.61 | 72.65 | 71.50 | 100 | 60.22 |
| LSTM | 80.23 | 83.56 | 82.47 | 100 | 126.32 |
| PCA-LSTM | 95.03 | 93.70 | 92.85 | 100 | 153.96 |
| CNN | 78.45 | 76.59 | 75.33 | 100 | 110.47 |
| SVM | 69.85 | 68.97 | 67.81 | 100 | 50.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Ren, X.; Cheng, G. Research on Distributed Fault Diagnosis Model of Elevator Based on PCA-LSTM. Algorithms 2024, 17, 250. https://doi.org/10.3390/a17060250
Chen C, Ren X, Cheng G. Research on Distributed Fault Diagnosis Model of Elevator Based on PCA-LSTM. Algorithms. 2024; 17(6):250. https://doi.org/10.3390/a17060250
Chicago/Turabian StyleChen, Chengming, Xuejun Ren, and Guoqing Cheng. 2024. "Research on Distributed Fault Diagnosis Model of Elevator Based on PCA-LSTM" Algorithms 17, no. 6: 250. https://doi.org/10.3390/a17060250
APA StyleChen, C., Ren, X., & Cheng, G. (2024). Research on Distributed Fault Diagnosis Model of Elevator Based on PCA-LSTM. Algorithms, 17(6), 250. https://doi.org/10.3390/a17060250