
Synthetic Face Discrimination via Learned Image Compression




Abstract
:1. Introduction
2. Related Works
3. Proposed Method
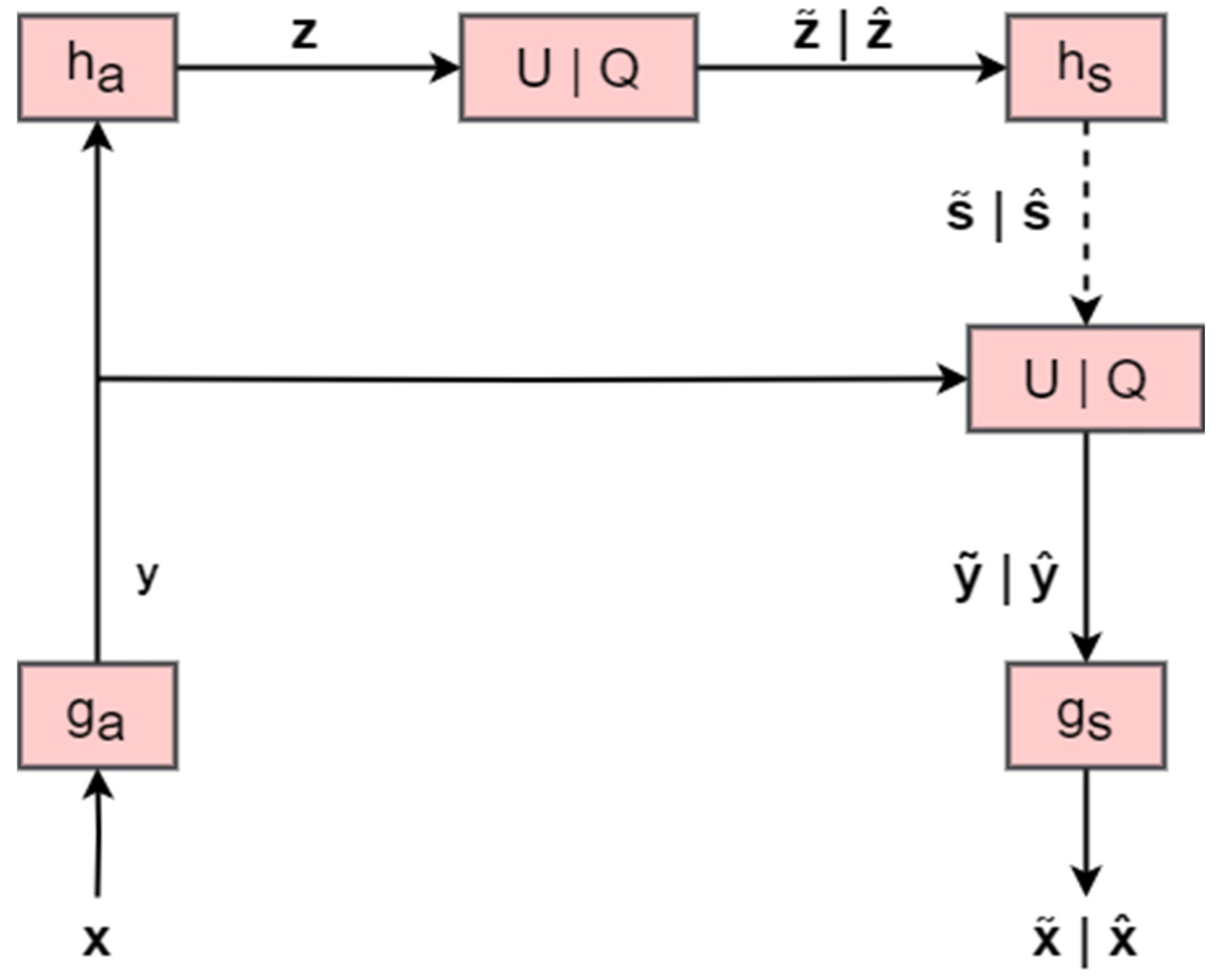
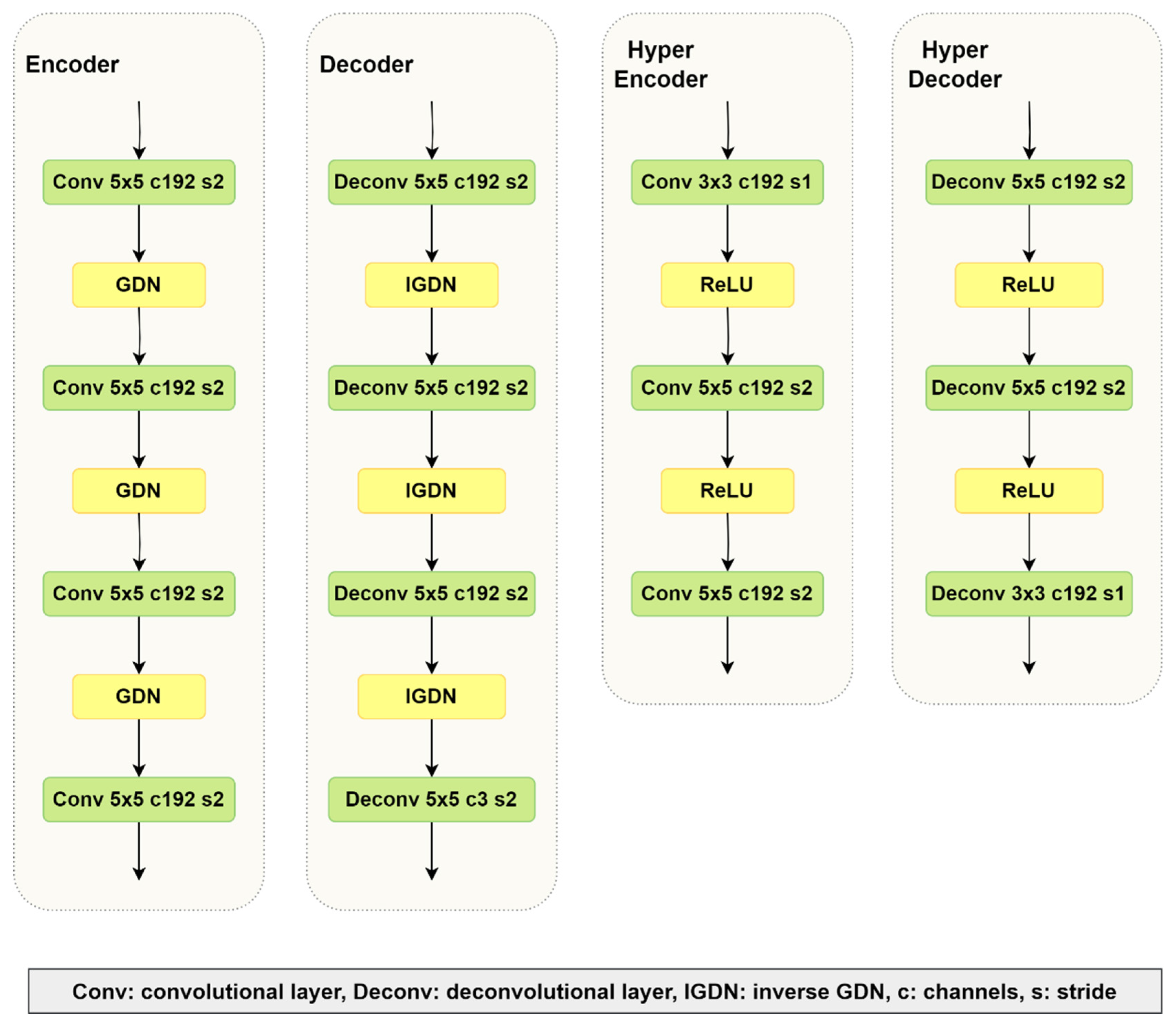
3.1. Image Compression
3.2. Synthetic Image Detection
| Process 1. Discrimination of synthetic images | |
| Step 1: | Train compression model A on a real dataset |
| Train compression model B on a synthetic dataset | |
| Step 2: | Evaluate model A on real dataset 1 |
| Evaluate model A on synthetic dataset 1 | |
| Evaluate model B on real dataset 1 | |
| Evaluate model B on synthetic dataset 1 | |
| Step 3: | Train classifier on the features extracted from Step 2 |
| Step 4: | Evaluate model A on real dataset 2 |
| Evaluate model A on synthetic dataset 2 | |
| Evaluate model B on real dataset 2 | |
| Evaluate model B on synthetic dataset 2 | |
| Step 5: | Evaluate classifier on the features extracted from Step 4 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier |
|---|
| Dense 12 |
| ReLU |
| Dense 8 |
| ReLU Dense 1 Sigmoid |
4. Methodology and Experimental Results
4.1. Datasets
4.2. Training Setting
4.3. Results
4.3.1. Performance Analysis
4.3.2. Robustness
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dogoulis, P.; Kordopatis-Zilos, G.; Kompatsiaris, I.; Papadopoulos, S. Improving Synthetically Generated Image Detection in Cross-Concept Settings. In Proceedings of the 2nd ACM International Workshop on Multimedia AI against Disinformation (MAD ‘23), Thessaloniki, Greece, 12–15 June 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 28–35. [Google Scholar] [CrossRef]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Karras, T.; Aittala, M.; Laine, S.; Härkönen, E.; Hellsten, J.; Lehtinen, J.; Aila, T. Alias-free generative adversarial networks. In Adv. Neural Inf. Process. Syst. 2021, 34, 852–863. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat GANs on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar] [CrossRef]
- Farid, H. Photo Forensics; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Guo, H.; Hu, S.; Wang, X.; Chang, M.C.; Lyu, S. Eyes Tell All: Irregular Pupil Shapes Reveal GAN-Generated Faces. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 2904–2908. [Google Scholar] [CrossRef]
- Farid, H. Lighting (In)consistency of Paint by Text. arXiv 2022, arXiv:2207.13744. [Google Scholar]
- Farid, H. Perspective (In)consistency of Paint by Text. arXiv 2022, arXiv:2206.14617. [Google Scholar]
- Corvi, R.; Cozzolino, D.; Poggi, G.; Nagano, K.; Verdoliva, L. Intriguing Properties of Synthetic Images: From Generative Adversarial Networks to Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Vancouver, BC, Canada, 17–24 June 2023; pp. 973–982. [Google Scholar]
- Yang, X.; Li, Y.; Qi, H.; Lyu, S. Exposing GAN-synthesized Faces Using Landmark Locations. In Proceedings of the ACM Workshop on Information Hiding and Multimedia, Paris France, 3–5 July 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 113–118. [Google Scholar] [CrossRef]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting Visual Artifacts to Expose Deepfakes and Face Manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa, HI, USA, 7–11 January 2019; pp. 83–92. [Google Scholar] [CrossRef]
- Nataraj, L.; Mohammed, T.M.; Manjunath, B.S.; Chandrasekaran, S.; Flenner, A.; Bappy, J.H.; Roy-Chowdhury, A. Detecting GAN generated Fake Images using Co-occurrence Matrices. Electron. Imaging 2019, 2019, 532-1–532-7. [Google Scholar] [CrossRef]
- Nowroozi, E.; Conti, M.; Mekdad, Y. Detecting High-Quality GAN-Generated Face Images using Neural Networks. arXiv 2022, arXiv:2203.01716. [Google Scholar]
- McCloskey, S.; Albright, M. Detecting GAN-Generated Imagery Using Saturation Cues. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4584–4588. [Google Scholar]
- Li, H.; Li, B.; Tan, S.; Huang, J. Identification of deep network generated images using disparities in color. Signal Process. 2020, 174, 107616. [Google Scholar] [CrossRef]
- Zhang, X.; Karaman, S.; Chang, S.-F. Detecting and Simulating Artifacts in GAN Fake Images. In Proceedings of the 2019 IEEE International Workshop on Information Forensics and Security (WIFS), Delft, The Netherlands, 9–12 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Frank, J.; Eisenhofer, T.; Schönherr, L.; Fischer, A.; Kolossa, D.; Holz, T. Leveraging frequency analysis for deep fake image recognition. arXiv 2020, arXiv:2003.08685. [Google Scholar]
- Durall, R.; Keuper, M.; Keuper, J. Watch Your Up-Convolution: CNN Based Generative Deep Neural Networks Are Failing to Reproduce Spectral Distributions. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 7887–7896. [Google Scholar] [CrossRef]
- Gragnaniello, D.; Cozzolino, D.; Marra, F.; Poggi, G.; Verdoliva, L. Are GAN Generated Images Easy to Detect? A Critical Analysis of the State-Of-The-Art. In In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Boroumand, M.; Chen, M.; Fridrich, J. Deep Residual Network for Steganalysis of Digital Images. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1181–1193. [Google Scholar] [CrossRef]
- Wang, J.; Tondi, B.; Barni, M. An Eyes-Based Siamese Neural Network for the Detection of GAN-Generated Face Images. Front. Signal Process. 2022, 2, 918725. [Google Scholar] [CrossRef]
- Fu, T.; Xia, M.; Yang, G. Detecting GAN-generated face images via hybrid texture and sensor noise-based features. Multimed. Tools Appl. 2022, 81, 26345–26359. [Google Scholar] [CrossRef]
- Cozzolino, D.; Poggi, G.; Corvi, R.; Nießner, M.; Verdoliva, L. Raising the Bar of AI-generated Image Detection with CLIP. arXiv 2023, arXiv:2312.00195. [Google Scholar] [CrossRef]
- Iliopoulou, S.; Tsinganos, P.; Ampeliotis, D.; Skodras, A. Learned Image Compression with Wavelet Preprocessing for Low Bit Rates. In Proceedings of the 2023 24th International Conference on Digital Signal Processing (DSP), Rhodes, Greece, 11–13 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Li, M.; Zhang, K.; Li, J.; Zuo, W.; Timofte, R.; Zhang, D. Learning Context-Based Nonlocal Entropy Modeling for Image Compression. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 1132–1145. [Google Scholar] [CrossRef] [PubMed]
- Minnen, D.; Ballé, J.; Toderici, G.D. Joint Autoregressive and Hierarchical Priors for Learned Image Compression. Adv. Neural Inf. Process. Syst. 2018, 31, 10771–10780. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Data Compression. In Elements of Information Theory, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2021; pp. 103–142. [Google Scholar]
- Toderici, G.; Vincent, D.; Johnston, N.; Hwang, S.; Minnen, D.; Shor, J.; Covell, M. “Full resolution image compression with recurrent neural networks. In Proceedings of the 2017 IEEE Conference on Computer Vision Pattern Recognit. (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5435–5443. [Google Scholar]
- Balle, J.; Minnen, D.; Singh, S.; Hwang, S.J.; Johnston, N. Variational image compression with a scale hyperprior. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Ballé, J.; Laparra, V.; Simoncelli, E.P. End-to-end optimized image compression. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Qian, Y.; Tan, Z.; Sun, X.; Lin, M.; Li, D.; Sun, Z.; Li, H.; Jin, R. Learning accurate entropy model with global reference for image compression. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the 37th Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; Volume 2, pp. 1398–1402. [Google Scholar] [CrossRef]
- Theis, L.; Shi, W.; Cunningham, A.; Huszár, F. Lossy Image Compression with Compressive Autoencoders. arXiv 2017, arXiv:1703.00395. [Google Scholar]
- Ballé, J.; Laparra, V.; Simoncelli, E.P. End-to-end optimization of nonlinear transform codes for perceptual quality. In Proceedings of the 2016 Picture Coding Symposium (PCS), Nuremberg, Germany, 4–7 December 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Ballé, J.; Laparra, V.; Simoncelli, E.P. Density Modeling of Images using a Generalized Normalization Transformation. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. Conference Track Proceedings 2016. [Google Scholar]
- Skodras, A.; Christopoulos, C.; Ebrahimi, T. The JPEG 2000 still image compression standard. IEEE Signal Process. Mag. 2001, 18, 36–58. [Google Scholar] [CrossRef]
- Bruckstein, A.M.; Elad, M.; Kimmel, R. Down-scaling for better transform compression. IEEE Trans. Image Process. 2003, 12, 1132–1144. [Google Scholar] [CrossRef]
- Chen, P.; Xu, M.; Wang, X. Detecting Compressed Deepfake Images Using Two-Branch Convolutional Networks with Similarity and Classifier. Symmetry 2022, 14, 2691. [Google Scholar] [CrossRef]
- Liu, C.; Zhu, T.; Shen, S.; Zhou, W. Towards Robust Gan-Generated Image Detection: A Multi-View Completion Representation. In Proceedings of the 32nd International Joint Conference on Artificial Intelligence (IJCAI-23), Macau SAR, China, 19–25 August 2023; pp. 464–472. [Google Scholar] [CrossRef]
- Marra, F.; Gragnaniello, D.; Cozzolino, D.; Verdoliva, L. Detection of GAN-Generated Fake Images Over Social Networks. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 384–389. [Google Scholar] [CrossRef]
- Dong, C.; Kumar, A.; Liu, E. Think Twice Before Detecting GAN-generated Fake Images from their Spectral Domain Imprints. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 7855–7864. [Google Scholar] [CrossRef]
- Stockl, A. Evaluating a Synthetic Image Dataset Generated with Stable Diffusion. In Proceedings of the Eighth International Congress on Information and Communication Technology, London, UK, 20–23 January 2023; pp. 805–818. [Google Scholar]
- Corvi, R.; Cozzolino, D.; Zingarini, G.; Poggi, G.; Nagano, K.; Verdoliva, L. On the Detection of Synthetic Images Generated by Diffusion Models. In Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4217–4228. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of StyleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980,. [Google Scholar]
- Perugachi-Diaz, Y.; Gansekoele, A.; Bhulai, S. Robustly overfitting latents for flexible neural image compression. arXiv 2024, arXiv:2401.17789. [Google Scholar]
- Mikami, Y.; Tsutake, C.; Takahashi, K.; Fujii, T. An Efficient Image Compression Method Based on Neural Network: An Overfitting Approach. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2084–2088. [Google Scholar] [CrossRef]
- Wu, H.; Zhou, J.; Zhang, S. Generalizable Synthetic Image Detection via Language-guided Contrastive Learning. arXiv 2023, arXiv:2305.13800. [Google Scholar]
- Wang, J.; Alamayreh, O.; Tondi, B.; Barni, M. Open Set Classification of GAN-based Image Manipulations via a ViT-based Hybrid Architecture. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Vancouver, BC, Canada, 20–22 June 2023; pp. 953–962. [Google Scholar] [CrossRef]
- Classification Metrics Based on True/False Positives & Negatives. Keras. Available online: https://keras.io/api/metrics/classification_metrics/ (accessed on 1 August 2024).










| Datasets | CelebA_HQ | StyleGAN | StyleGAN2 | Stable Diffusion |
|---|---|---|---|---|
| Class | Real | Synthetic | Synthetic | Synthetic |
| Training | 10,000 | 10,000 | 10,000 | None |
| Testing | 2000 | 2000 | 2000 | 2000 |
| Dataset | ACC/AUC | |
|---|---|---|
| Our Method | ResNet50 | |
| StyleGAN | 98.90/100.0 | 99.70/100.0 |
| StyleGAN2 | 95.30/99.0 | 99.70/100.0 |
| Stable Diffusion (our model trained on StyleGAN) | 99.00/100.0 | 49.70/32.50 |
| Stable Diffusion (our model trained on StyleGAN2) | 99.10/99.90 | 49.70/32.50 |
| Dataset | Precision/Recall | |
|---|---|---|
| Our Method | ResNet50 | |
| StyleGAN | 98.60/99.20 | 100.0/99.40 |
| StyleGAN2 | 95.20/95.40 | 100.0/99.40 |
| Stable Diffusion (our model trained on StyleGAN) | 99.20/99.50 | 49.84/99.40 |
| Stable Diffusion (our model trained on StyleGAN2) | 98.81/99.40 | 49.84/99.40 |
| Processing Operation | ACC/AUC | |||||||
|---|---|---|---|---|---|---|---|---|
| StyleGAN | StyleGAN2 | Stable Diffusion (Our Model Trained on StyleGAN) | Stable Diffusion (Our Model Trained on StyleGAN2) | |||||
| Our Method | ResNet50 | Our Method | ResNet50 | Our Method | ResNet50 | Our Method | ResNet50 | |
| Gaussian noise (σ2 = 0.01) | 97.90/99.30 | 64.60/58.30 | 95.30/98.90 | 64.60/64.80 | 98.30/99.50 | 49.90/54.20 | 97.70/99.80 | 49.90/54.20 |
| Median filter (3 × 3) | 88.20/97.30 | 99.90/99.90 | 93.50/97.90 | 99.80/99.90 | 95.30/99.10 | 49.90/51.10 | 96.40/98.90 | 49.90/51.10 |
| JPEG (QF = 90) | 94.00/97.10 | 99.70/99.80 | 95.30/98.80 | 99.70/99.80 | 98.60/99.90 | 49.70/42.60 | 98.30/99.80 | 49.70/42.60 |
| Cropping (512 × 512) | 98.90/100.0 | 99.30/98.70 | 95.30/99.0 | 99.20/98.70 | 99.00/100.0 | 49.30/39.50 | 99.10/99.90 | 49.30/39.50 |
| Resize (0.5) | 98.40/99.60 | 100.0/99.90 | 94.40/98.80 | 88.60/91.30 | 98.50/99.80 | 50.00/50.80 | 99.20/99.90 | 50.00/50.80 |
| Resize (1.5) | 94.10/98.20 | 100.0/100.0 | 92.30/98.10 | 100.0/100.0 | 94.70/98.60 | 50.00/50.40 | 93.90/98.90 | 50.00/50.40 |
| Processing Operation | Precision/Recall | |||||||
|---|---|---|---|---|---|---|---|---|
| StyleGAN | StyleGAN2 | Stable Diffusion (Our Model Trained on StyleGAN) | Stable Diffusion (Our Model Trained on StyleGAN2_ | |||||
| Our Method | ResNet50 | Our Method | ResNet50 | Our Method | ResNet50 | Our Method | ResNet50 | |
| Gaussian noise (σ2 = 0.01) | 97.60/98.20 | 100.0/29.20 | 94.50/96.20 | 100.0/29.20 | 98.99/97.60 | 49.95/99.80 | 99.18/96.20 | 49.95/99.80 |
| Median filter (3 × 3) | 96.40/79.40 | 100.0/99.80 | 91.90/95.40 | 100.0/99.80 | 95.21/95.40 | 49.95/99.80 | 95.14/97.80 | 49.95/99.80 |
| JPEG (QF = 90) | 92.64/95.60 | 100.0/99.40 | 94.50/96.20 | 100.0/99.40 | 98.80/98.40 | 49.84/99.40 | 98.20/98.40 | 49.84/99.40 |
| Cropping (512 × 512) | 98.60/99.20 | 100.0/98.60 | 95.20/95.40 | 100.0/98.60 | 99.20/99.50 | 49.65/98.60 | 98.81/99.40 | 49.30/98.60 |
| Resize (0.5) | 98.99/97.80 | 100.0/100.0 | 92.05/97.20 | 81.43/100.0 | 98.50/99.80 | 50.00/100.00 | 99.20/99.90 | 50.00/100.00 |
| Resize (1.5) | 93.00/97.40 | 100.0/100.0 | 92.50/93.20 | 100.0/100.0 | 94.60/94.80 | 50.00/100.00 | 93.10/93.60 | 50.00/100.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iliopoulou, S.; Tsinganos, P.; Ampeliotis, D.; Skodras, A. Synthetic Face Discrimination via Learned Image Compression. Algorithms 2024, 17, 375. https://doi.org/10.3390/a17090375
Iliopoulou S, Tsinganos P, Ampeliotis D, Skodras A. Synthetic Face Discrimination via Learned Image Compression. Algorithms. 2024; 17(9):375. https://doi.org/10.3390/a17090375
Chicago/Turabian StyleIliopoulou, Sofia, Panagiotis Tsinganos, Dimitris Ampeliotis, and Athanassios Skodras. 2024. "Synthetic Face Discrimination via Learned Image Compression" Algorithms 17, no. 9: 375. https://doi.org/10.3390/a17090375
APA StyleIliopoulou, S., Tsinganos, P., Ampeliotis, D., & Skodras, A. (2024). Synthetic Face Discrimination via Learned Image Compression. Algorithms, 17(9), 375. https://doi.org/10.3390/a17090375