
MPVF: Multi-Modal 3D Object Detection Algorithm with Pointwise and Voxelwise Fusion


Abstract
1. Introduction
2. Related Works
2.1. Camera-Based 3D Object Detection
2.2. LIDAR-Based 3D Object Detection
2.3. Multi-Modal Fusion-Based 3D Object Detection
2.3.1. Early Fusion
2.3.2. Late Fusion
2.3.3. Intermediate Fusion
3. Methodology
3.1. Network Architecture
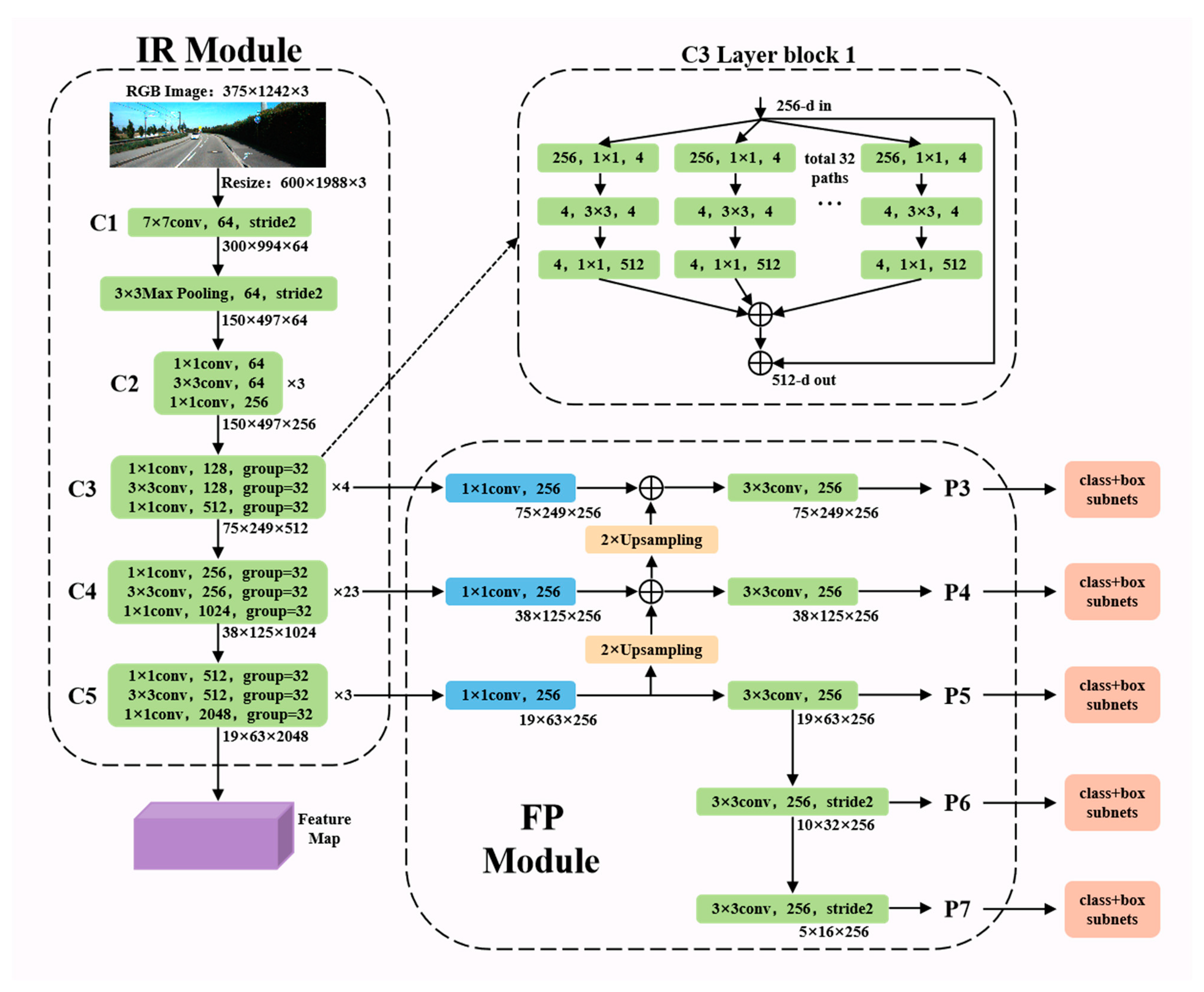
3.2. IRFP Module
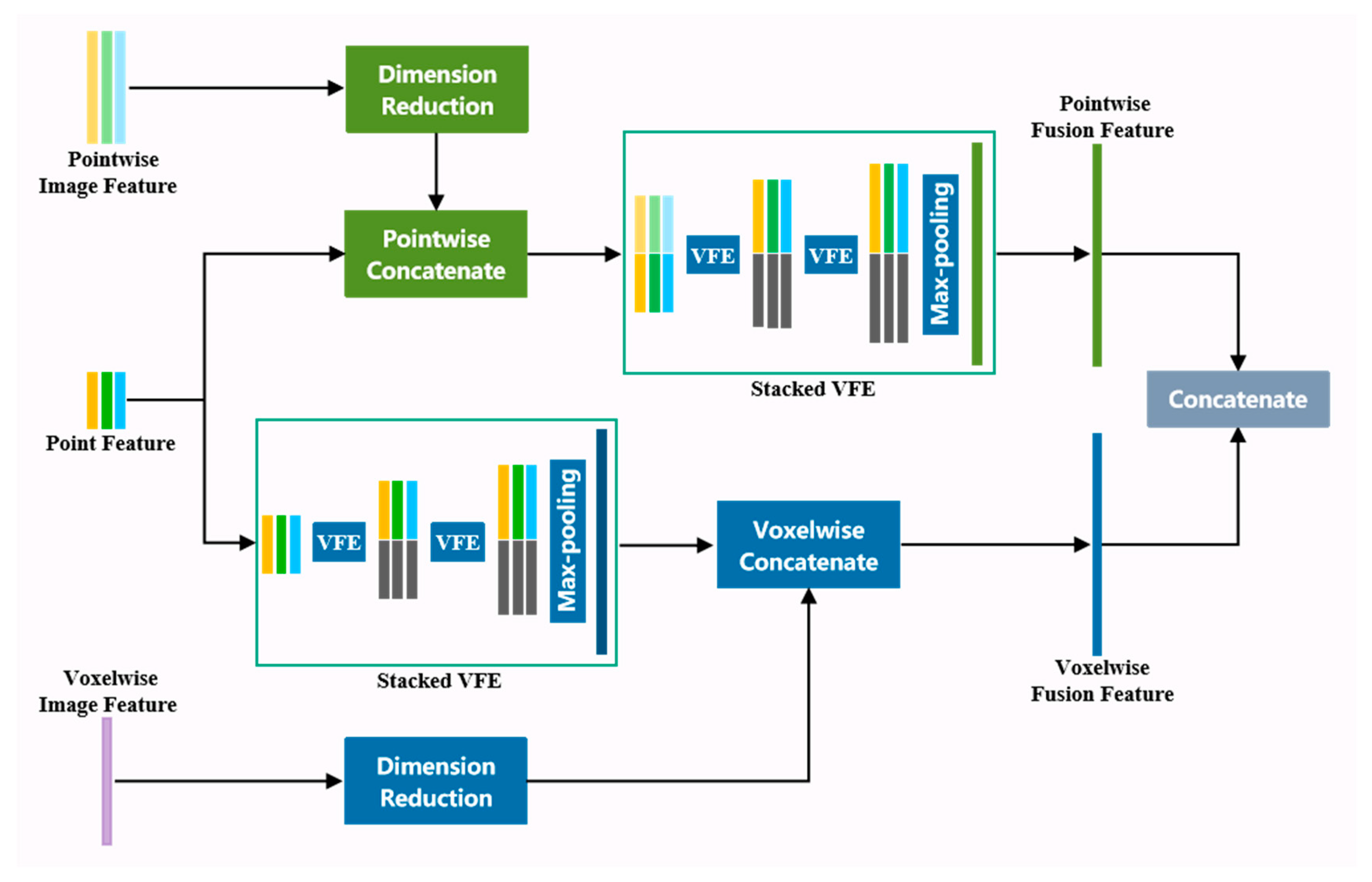
3.3. PVWF Module
3.4. Detection Network
4. Experiments and Results
4.1. Dataset
4.2. Evaluation Metrics
4.3. Experimental Details
4.4. Experimental Results
4.4.1. Quantitative Analysis
- Evaluation on the KITTI Test Set
- 2.
- Evaluation on the KITTI Validation Set
4.4.2. Qualitative Analysis
4.5. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A survey on 3D object detection methods for autonomous driving applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef]
- Meier, J.; Scalerandi, L.; Dhaouadi, O.; Kaiser, J.; Araslanov, N.; Cremers, D. CARLA Drone: Monocular 3D Object Detection from a Different Perspective. arXiv 2024, arXiv:2408.11958. [Google Scholar]
- Xu, G.; Khan, A.S.; Moshayedi, A.J.; Zhang, X.; Shuxin, Y. The object detection, perspective and obstacles in robotic: A review. EAI Endorsed Trans. AI Robot. 2022, 1, e13. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, Z.; Tóth, R. Smoke: Single-stage monocular 3D object detection via keypoint estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 996–997. [Google Scholar]
- Rukhovich, D.; Vorontsova, A.; Konushin, A. Imvoxelnet: Image to voxels projection for monocular and multi-view general-purpose 3D object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2397–2406. [Google Scholar]
- Mao, J.; Shi, S.; Wang, X.; Li, H. 3D object detection for autonomous driving: A comprehensive survey. Int. J. Comput. Vis. 2023, 131, 1909–1963. [Google Scholar] [CrossRef]
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel r-cnn: Towards high performance voxel-based 3D object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 1201–1209. [Google Scholar]
- Yang, H.; Wang, W.; Chen, M.; Lin, B.; He, T.; Chen, H.; He, X.; Ouyang, W. Pvt-ssd: Single-stage 3D object detector with point-voxel transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13476–13487. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential fusion for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4604–4612. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3D object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 918–927. [Google Scholar]
- Qian, R.; Lai, X.; Li, X. 3D object detection for autonomous driving: A survey. Pattern Recognit. 2022, 130, 108796. [Google Scholar] [CrossRef]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 10386–10393. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. Fast-CLOCs: Fast camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 187–196. [Google Scholar]
- Sindagi, V.A.; Zhou, Y.; Tuzel, O. Mvx-net: Multimodal voxelnet for 3D object detection. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 7276–7282. [Google Scholar]
- Huang, T.; Liu, Z.; Chen, X.; Bai, X. Epnet: Enhancing point features with image semantics for 3D object detection. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, part XV 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 35–52. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Luo, S.; Dai, H.; Shao, L.; Ding, Y. M3dssd: Monocular 3D single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 6145–6154. [Google Scholar]
- Chen, H.; Huang, Y.; Tian, W.; Gao, Z.; Xiong, L. Monorun: Monocular 3D object detection by reconstruction and uncertainty propagation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 10379–10388. [Google Scholar]
- Zhang, Y.; Lu, J.; Zhou, J. Objects are different: Flexible monocular 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3289–3298. [Google Scholar]
- Li, Y.; Ge, Z.; Yu, G.; Yang, J.; Wang, Z.; Shi, Y.; Sun, J.; Li, Z. Bevdepth: Acquisition of reliable depth for multi-view 3D object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 1477–1485. [Google Scholar]
- Li, Y.; Bao, H.; Ge, Z.; Yang, J.; Sun, J.; Li, Z. Bevstereo: Enhancing depth estimation in multi-view 3D object detection with temporal stereo. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 1486–1494. [Google Scholar]
- Wang, Y.; Guizilini, V.C.; Zhang, T.; Wang, Y.; Zhao, H.; Solomon, J. Detr3d: 3D object detection from multi-view images via 3d-to-2d queries. In Proceedings of the Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022; pp. 180–191. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3D object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Shi, W.; Rajkumar, R. Point-gnn: Graph neural network for 3D object detection in a point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1711–1719. [Google Scholar]
- Ali, W.; Abdelkarim, S.; Zidan, M.; Zahran, M.; El Sallab, A. Yolo3d: End-to-end real-time 3D oriented object bounding box detection from lidar point cloud. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 716–728. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3dssd: Point-based 3D single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11040–11048. [Google Scholar]
- Zheng, W.; Tang, W.; Chen, S.; Jiang, L.; Fu, C.-W. Cia-ssd: Confident iou-aware single-stage object detector from point cloud. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 3555–3562. [Google Scholar]
- Wang, Z.; Jia, K. Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal 3D object detection. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macao, China, 3–8 November 2019; pp. 1742–1749. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3D proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Liang, M.; Yang, B.; Wang, S.; Urtasun, R. Deep continuous fusion for multi-sensor 3D object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 641–656. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Liang, M.; Yang, B.; Chen, Y.; Hu, R.; Urtasun, R. Multi-task multi-sensor fusion for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7345–7353. [Google Scholar]
- Liang, T.; Xie, H.; Yu, K.; Xia, Z.; Lin, Z.; Wang, Y.; Tang, T.; Wang, B.; Tang, Z. Bevfusion: A simple and robust lidar-camera fusion framework. Adv. Neural Inf. Process. Syst. 2022, 35, 10421–10434. [Google Scholar]
- Ross, T.-Y.; Dollár, G. Focal loss for dense object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2980–2988. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Chen, X.; Kundu, K.; Zhu, Y.; Berneshawi, A.G.; Ma, H.; Fidler, S.; Urtasun, R. 3D object proposals for accurate object class detection. Adv. Neural Inf. Process. Syst. 2015, 28, 424–432. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Simonelli, A.; Bulo, S.R.; Porzi, L.; López-Antequera, M.; Kontschieder, P. Disentangling monocular 3D object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1991–1999. [Google Scholar]
- Guo, X.; Shi, S.; Wang, X.; Li, H. Liga-stereo: Learning lidar geometry aware representations for stereo-based 3D detector. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 3153–3163. [Google Scholar]
- Liu, Z.; Ye, X.; Tan, X.; Ding, E.; Bai, X. Stereodistill: Pick the cream from lidar for distilling stereo-based 3D object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 1790–1798. [Google Scholar]
- Cao, J.; Tao, C.; Zhang, Z.; Gao, Z.; Luo, X.; Zheng, S.; Zhu, Y. Accelerating Point-Voxel Representation of 3-D Object Detection for Automatic Driving. IEEE Trans. Artif. Intell. 2023, 5, 254–266. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Q.; Zhu, Z.; Hou, J.; Yuan, Y. Glenet: Boosting 3D object detectors with generative label uncertainty estimation. Int. J. Comput. Vis. 2023, 131, 3332–3352. [Google Scholar] [CrossRef]
- Tian, Y.; Zhang, X.; Wang, X.; Xu, J.; Wang, J.; Ai, R.; Gu, W.; Ding, W. ACF-Net: Asymmetric cascade fusion for 3D detection with lidar point clouds and images. IEEE Trans. Intell. Veh. 2023, 9, 3360–3371. [Google Scholar] [CrossRef]
- Wu, H.; Wen, C.; Shi, S.; Li, X.; Wang, C. Virtual sparse convolution for multimodal 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21653–21662. [Google Scholar]
- Song, Z.; Jia, C.; Yang, L.; Wei, H.; Liu, L. GraphAlign++: An accurate feature alignment by graph matching for multi-modal 3D object detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 2619–2632. [Google Scholar] [CrossRef]
- Yujian, M.; Wu, Y.; Zhao, J.; Yinghao, H.; Wang, J.; Yan, J. Sparse Query Dense: Enhancing 3D Object Detection with Pseudo points. In Proceedings of the ACM Multimedia 2024, Melbourne, VIC, Australia, 28 October–1 November 2024. [Google Scholar]
- Song, Z.; Zhang, G.; Liu, L.; Yang, L.; Xu, S.; Jia, C.; Jia, F.; Wang, L. Robofusion: Towards robust multi-modal 3D obiect detection via sam. arXiv 2024, arXiv:2401.03907. [Google Scholar]
- Chen, Y.; Liu, S.; Shen, X.; Jia, J. Dsgn: Deep stereo geometry network for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12536–12545. [Google Scholar]
- Zhang, R.; Qiu, H.; Wang, T.; Guo, Z.; Cui, Z.; Qiao, Y.; Li, H.; Gao, P. MonoDETR: Depth-guided transformer for monocular 3D object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 17–24 June 2023; pp. 9155–9166. [Google Scholar]
- Yan, L.; Yan, P.; Xiong, S.; Xiang, X.; Tan, Y. MonoCD: Monocular 3D Object Detection with Complementary Depths. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 10248–10257. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Std: Sparse-to-dense 3D object detector for point cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 1951–1960. [Google Scholar]
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From points to parts: 3D object detection from point cloud with part-aware and part-aggregation network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2647–2664. [Google Scholar] [CrossRef] [PubMed]
- He, C.; Zeng, H.; Huang, J.; Hua, X.-S.; Zhang, L. Structure aware single-stage 3D object detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11873–11882. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10529–10538. [Google Scholar]
- Mao, J.; Niu, M.; Bai, H.; Liang, X.; Xu, H.; Xu, C. Pyramid r-cnn: Towards better performance and adaptability for 3D object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 2723–2732. [Google Scholar]
- Guan, T.; Wang, J.; Lan, S.; Chandra, R.; Wu, Z.; Davis, L.; Manocha, D. M3detr: Multi-representation, multi-scale, mutual-relation 3D object detection with transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 772–782. [Google Scholar]
- Xie, T.; Wang, L.; Wang, K.; Li, R.; Zhang, X.; Zhang, H.; Yang, L.; Liu, H.; Li, J. FARP-Net: Local-global feature aggregation and relation-aware proposals for 3D object detection. IEEE Trans. Multimed. 2023, 26, 1027–1040. [Google Scholar] [CrossRef]
- Paigwar, A.; Sierra-Gonzalez, D.; Erkent, Ö.; Laugier, C. Frustum-pointpillars: A multi-stage approach for 3D object detection using rgb camera and lidar. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 2926–2933. [Google Scholar]
- Liu, Z.; Huang, T.; Li, B.; Chen, X.; Wang, X.; Bai, X. Epnet++: Cascade bi-directional fusion for multi-modal 3D object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 8324–8341. [Google Scholar] [CrossRef] [PubMed]
- Wang, M.; Zhao, L.; Yue, Y. PA3DNet: 3-D vehicle detection with pseudo shape segmentation and adaptive camera-LiDAR fusion. IEEE Trans. Ind. Inform. 2023, 19, 10693–10703. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Running Time(s) | Sensor | Car 3D AP (%) | Pedestrians 3D AP (%) | Cyclists 3D AP (%) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | ||||
| SMOKE [4] | 2020 | 0.03 | Camera | 14.03 | 9.76 | 7.84 | - | - | - | - | - | - |
| DSGN [51] | 2020 | 0.67 | 73.50 | 52.18 | 45.14 | 20.53 | 15.55 | 14.15 | 27.76 | 18.17 | 16.21 | |
| M3DSSD [17] | 2021 | - | 17.51 | 11.46 | 8.98 | 5.16 | 3.87 | 3.08 | 2.10 | 1.51 | 1.58 | |
| MonoRUn [18] | 2021 | 0.07 | 19.65 | 12.30 | 10.58 | 10.88 | 6.78 | 5.83 | 1.01 | 0.61 | 0.48 | |
| MonoFlex [19] | 2021 | 0.03 | 19.94 | 13.89 | 12.07 | 9.43 | 6.31 | 5.26 | 4.17 | 2.35 | 2.04 | |
| LiGA-Stereo [42] | 2021 | 0.40 | 81.39 | 64.66 | 57.22 | 40.46 | 30.00 | 27.07 | 54.44 | 36.86 | 32.06 | |
| ImVoxelNet [5] | 2022 | 0.20 | 17.15 | 10.97 | 9.15 | - | - | - | - | - | - | |
| MonoDETR [52] | 2023 | 0.04 | 25.00 | 16.47 | 13.58 | - | - | - | - | - | - | |
| StereoDistill [43] | 2023 | 0.40 | 81.66 | 66.39 | 57.39 | 44.12 | 32.23 | 28.95 | 63.96 | 44.02 | 39.19 | |
| MonoCD [53] | 2024 | 0.04 | 25.53 | 16.59 | 14.53 | - | - | - | - | - | - | |
| VoxelNet [33] | 2018 | 0.22 | LIDAR | 77.47 | 65.11 | 57.73 | 39.48 | 33.69 | 31.51 | 61.22 | 48.36 | 44.37 |
| SECOND [54] | 2018 | 0.05 | 83.13 | 73.66 | 66.20 | 51.07 | 42.56 | 37.29 | 70.51 | 53.85 | 46.90 | |
| PointRCNN [23] | 2019 | 0.10 | 86.96 | 75.64 | 70.70 | 47.98 | 39.37 | 36.01 | 74.96 | 58.82 | 52.53 | |
| STD [55] | 2019 | 0.08 | 87.95 | 79.71 | 75.09 | 53.29 | 42.47 | 38.35 | 78.69 | 61.59 | 55.30 | |
| Part-A2 Net [56] | 2020 | 0.08 | 87.81 | 78.49 | 73.51 | 53.10 | 43.35 | 40.06 | 79.17 | 63.52 | 56.93 | |
| Point-GNN [24] | 2020 | 0.60 | 88.33 | 79.47 | 72.29 | 51.92 | 43.77 | 40.14 | 78.60 | 63.48 | 57.08 | |
| 3DSSD [27] | 2020 | 0.04 | 88.36 | 79.57 | 74.55 | 54.64 | 44.27 | 40.23 | 82.48 | 64.10 | 56.90 | |
| SA-SSD [57] | 2020 | 0.04 | 88.75 | 79.79 | 74.16 | - | - | - | - | - | - | |
| PV-RCNN [58] | 2020 | 0.08 | 90.25 | 81.43 | 76.82 | 52.17 | 43.29 | 40.29 | 78.60 | 63.71 | 57.65 | |
| Pyramid R-CNN [59] | 2021 | 0.13 | 88.39 | 82.08 | 77.49 | - | - | - | - | - | - | |
| CIA-SSD [28] | 2021 | 0.03 | 89.59 | 80.28 | 72.87 | - | - | - | - | - | - | |
| Voxel R-CNN [7] | 2021 | 0.04 | 90.90 | 81.62 | 77.06 | - | - | - | - | - | - | |
| M3DETR [60] | 2022 | - | 90.28 | 81.73 | 76.96 | 45.70 | 39.94 | 37.66 | 83.83 | 66.74 | 59.03 | |
| FARP-Net [61] | 2023 | 0.06 | 88.36 | 81.53 | 78.98 | - | - | - | - | - | - | |
| PVT-SSD [8] | 2023 | 0.05 | 90.65 | 82.29 | 76.85 | - | - | - | - | - | - | |
| APVR [44] | 2023 | 0.02 | 91.45 | 82.17 | 78.08 | 55.76 | 44.87 | 41.34 | - | - | - | |
| GLENet-VR [45] | 2023 | 0.04 | 91.67 | 83.23 | 78.43 | - | - | - | - | - | - | |
| MV3D [30] | 2017 | 0.36 | Fusion | 74.97 | 63.63 | 54.00 | - | - | - | - | - | - |
| AVOD [31] | 2018 | 0.08 | 76.39 | 66.47 | 60.23 | 36.10 | 27.86 | 25.76 | 57.19 | 42.08 | 38.29 | |
| F-PointNet [10] | 2018 | 0.17 | 82.19 | 69.79 | 60.59 | 50.53 | 42.15 | 38.08 | 72.27 | 56.12 | 49.01 | |
| ContFuse [32] | 2018 | 0.06 | 83.68 | 68.78 | 61.67 | - | - | - | - | - | - | |
| MVX-Net [14] | 2019 | - | 83.20 | 72.70 | 65.20 | - | - | - | - | - | - | |
| F-ConvNet [29] | 2019 | 0.47 | 87.36 | 76.39 | 66.69 | 52.16 | 43.38 | 38.80 | 81.98 | 65.07 | 56.54 | |
| PointPainting [9] | 2020 | 0.40 | 82.11 | 71.70 | 67.08 | 50.32 | 40.97 | 37.87 | 77.63 | 63.78 | 55.89 | |
| CLOCs [12] | 2020 | 0.15 | 88.94 | 80.67 | 77.15 | - | - | - | - | - | - | |
| F-PointPillars [62] | 2021 | 0.07 | - | - | - | 51.22 | 42.89 | 39.28 | - | - | - | |
| Fast-CLOCs [13] | 2022 | 0.13 | 89.11 | 80.34 | 76.98 | 52.10 | 42.72 | 39.08 | 82.83 | 65.31 | 57.43 | |
| EPNet++ [63] | 2022 | 0.10 | 91.37 | 81.96 | 76.71 | 52.79 | 44.38 | 41.29 | 76.15 | 59.71 | 53.67 | |
| PA3DNet [64] | 2023 | 0.10 | 90.49 | 82.57 | 77.88 | - | - | - | - | - | - | |
| ACF-Net [46] | 2023 | 0.11 | 90.80 | 84.67 | 80.14 | 54.62 | 46.36 | 42.57 | 84.29 | 68.37 | 62.08 | |
| VirConv-L [47] | 2023 | 0.06 | 91.41 | 85.05 | 80.22 | - | - | - | - | - | - | |
| GraphAlign++ [48] | 2024 | 0.15 | 90.98 | 83.76 | 80.16 | 53.31 | 47.51 | 42.26 | 79.58 | 65.21 | 55.68 | |
| SQD [49] | 2024 | 0.06 | 91.58 | 81.82 | 79.07 | - | - | - | - | - | - | |
| RoboFusion-L [50] | 2024 | 0.30 | 91.75 | 84.08 | 80.71 | - | - | - | - | - | - | |
| MPVF(Ours) | 2024 | 0.33 | 91.93 | 85.12 | 79.14 | 56.10 | 48.61 | 43.96 | 85.47 | 70.12 | 62.69 | |
| Method | Year | Type | Car 3D AP (%) | ||
|---|---|---|---|---|---|
| Easy | Moderate | Hard | |||
| SMOKE [4] | 2020 | Camera | 14.76 | 12.85 | 11.50 |
| DSGN [51] | 2020 | 72.31 | 54.27 | 47.71 | |
| M3DSSD [17] | 2021 | 27.77 | 21.67 | 18.28 | |
| MonoRUn [18] | 2021 | 20.02 | 14.65 | 12.61 | |
| MonoFlex [19] | 2021 | 23.64 | 17.51 | 14.83 | |
| LIGA-Stereo [42] | 2021 | 84.92 | 67.06 | 63.80 | |
| ImVoxelNet [5] | 2022 | 24.54 | 17.80 | 15.67 | |
| MonoDETR [52] | 2023 | 28.84 | 20.61 | 16.38 | |
| StereoDistill [43] | 2023 | 87.57 | 69.75 | 62.92 | |
| MonoCD [53] | 2024 | 26.21 | 19.43 | 16.50 | |
| VoxelNet [33] | 2018 | LIDAR | 81.97 | 65.46 | 62.85 |
| SECOND [54] | 2018 | 87.43 | 76.48 | 69.10 | |
| PointRCNN [23] | 2019 | 88.88 | 78.63 | 77.38 | |
| STD [55] | 2019 | 89.70 | 79.80 | 79.30 | |
| Part-A2 Net [56] | 2020 | 89.47 | 79.47 | 78.54 | |
| Point-GNN [24] | 2020 | 87.89 | 78.34 | 77.38 | |
| 3DSSD [27] | 2020 | 89.71 | 79.45 | 78.67 | |
| SA-SSD [57] | 2020 | 92.23 | 84.30 | 81.36 | |
| PV-RCNN [58] | 2020 | 92.57 | 84.83 | 82.69 | |
| CIA-SSD [28] | 2021 | 93.59 | 84.16 | 81.20 | |
| Voxel R-CNN [7] | 2021 | 92.38 | 85.29 | 82.86 | |
| M3DETR [60] | 2022 | 92.29 | 85.41 | 82.25 | |
| FARP-Net [61] | 2023 | 89.91 | 83.99 | 79.21 | |
| APVR [44] | 2023 | 93.49 | 85.62 | 81.14 | |
| GLENet-VR [45] | 2023 | 93.51 | 86.10 | 83.60 | |
| MV3D [30] | 2017 | Fusion | 71.29 | 62.68 | 56.56 |
| AVOD [31] | 2018 | 84.41 | 74.44 | 68.65 | |
| F-PointNet [10] | 2018 | 83.76 | 70.92 | 63.65 | |
| ContFuse [32] | 2018 | 86.32 | 73.25 | 67.81 | |
| MVX-Net [14] | 2019 | 85.50 | 73.30 | 67.40 | |
| F-ConvNet [29] | 2019 | 89.02 | 78.80 | 77.09 | |
| CLOCs [12] | 2020 | 92.48 | 82.79 | 77.71 | |
| F-PointPillars [62] | 2021 | 88.90 | 79.28 | 78.07 | |
| EPNet++ [63] | 2022 | 92.51 | 83.17 | 82.27 | |
| PA3DNet [64] | 2023 | 93.18 | 86.02 | 83.74 | |
| ACF-Net [46] | 2023 | 93.17 | 88.80 | 86.53 | |
| VirConv-L [47] | 2023 | 93.36 | 88.71 | 85.83 | |
| GraphAlign++ [48] | 2024 | 92.58 | 87.01 | 84.68 | |
| RoboFusion-L [50] | 2024 | 93.30 | 88.04 | 85.27 | |
| MPVF(Ours) | 2024 | 93.68 | 89.87 | 85.59 | |
| Experiment | PWF Baseline | VWF Baseline | IRFP | PVWF | 3D AP (%) | |
|---|---|---|---|---|---|---|
| IR | FP | |||||
| 1 | √ | - | - | - | - | 77.30 |
| √ | - | √ | - | - | 79.72 | |
| √ | - | - | √ | - | 81.96 | |
| √ | - | √ | √ | - | 84.27 | |
| 2 | - | √ | - | - | - | 77.12 |
| - | √ | √ | - | - | 79.31 | |
| - | √ | - | √ | - | 81.82 | |
| - | √ | √ | √ | - | 83.94 | |
| 3 | √ | √ | √ | √ | √ | 89.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, P.; Wu, W.; Yang, A. MPVF: Multi-Modal 3D Object Detection Algorithm with Pointwise and Voxelwise Fusion. Algorithms 2025, 18, 172. https://doi.org/10.3390/a18030172
Shi P, Wu W, Yang A. MPVF: Multi-Modal 3D Object Detection Algorithm with Pointwise and Voxelwise Fusion. Algorithms. 2025; 18(3):172. https://doi.org/10.3390/a18030172
Chicago/Turabian StyleShi, Peicheng, Wenchao Wu, and Aixi Yang. 2025. "MPVF: Multi-Modal 3D Object Detection Algorithm with Pointwise and Voxelwise Fusion" Algorithms 18, no. 3: 172. https://doi.org/10.3390/a18030172
APA StyleShi, P., Wu, W., & Yang, A. (2025). MPVF: Multi-Modal 3D Object Detection Algorithm with Pointwise and Voxelwise Fusion. Algorithms, 18(3), 172. https://doi.org/10.3390/a18030172