
Implementation of a Parallel Algorithm Based on a Spark Cloud Computing Platform

{kind=link}
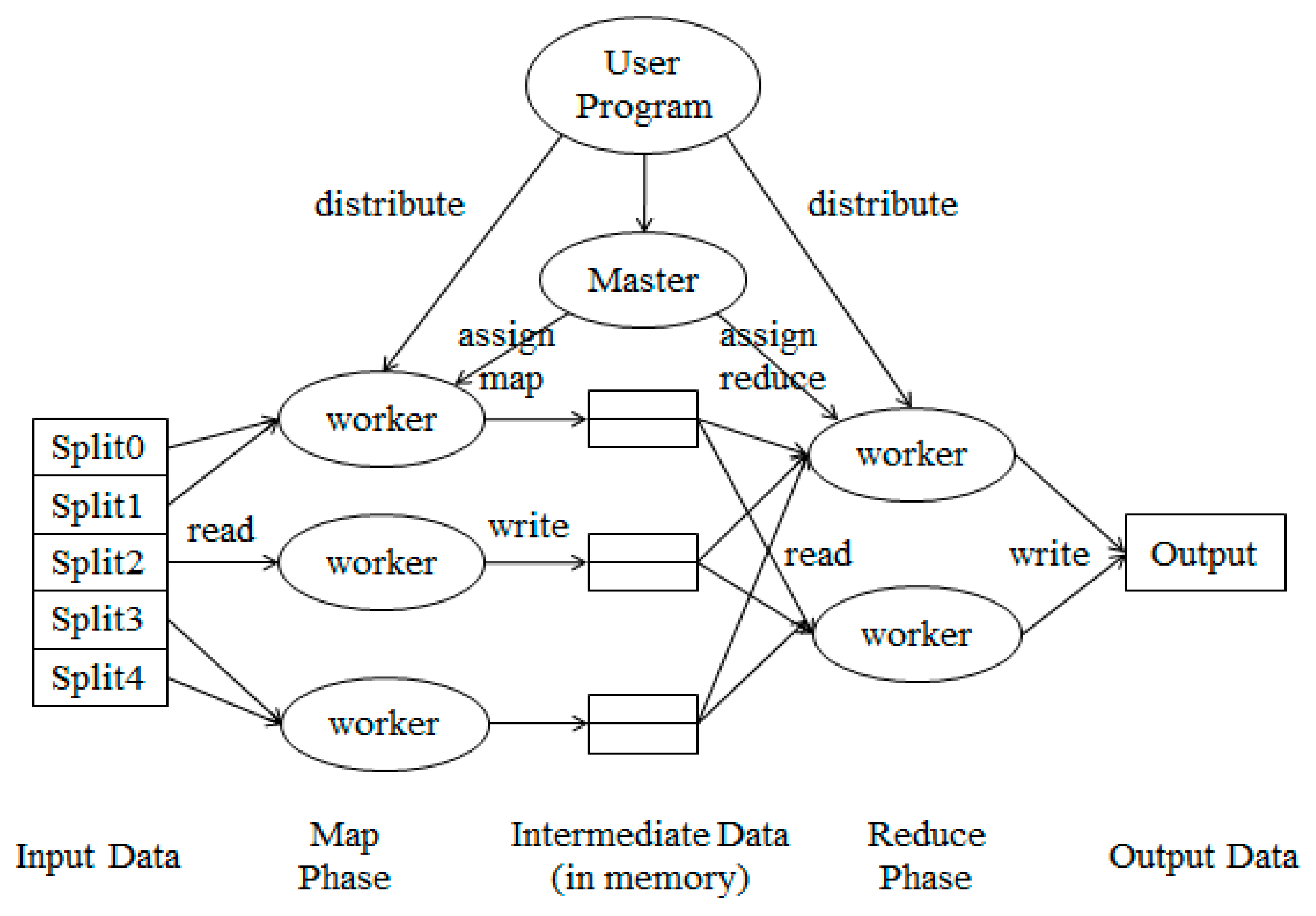{kind=link}
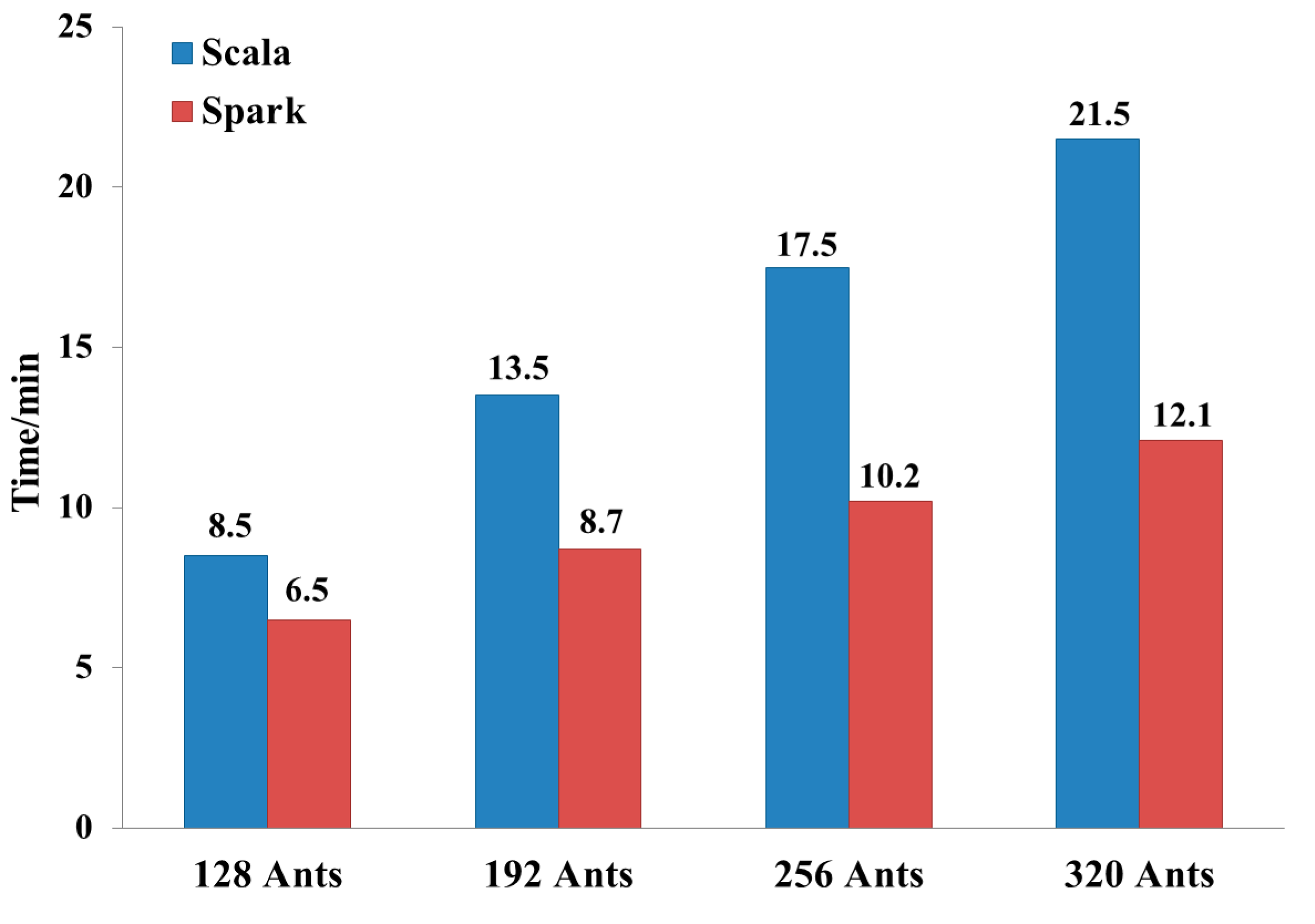{kind=link}
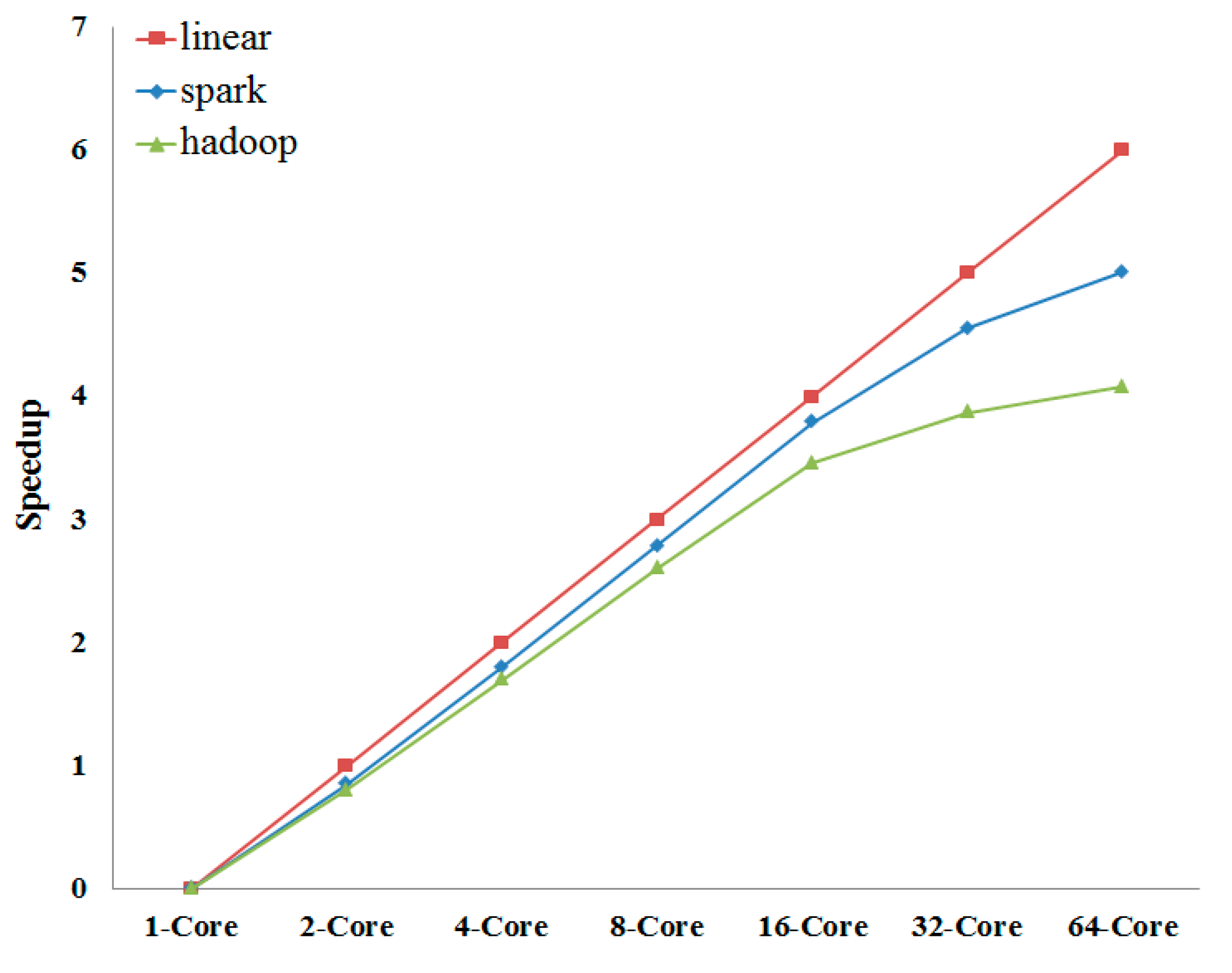{kind=link}
Abstract
Share and Cite
Wang, L.; Wang, Y.; Xie, Y. Implementation of a Parallel Algorithm Based on a Spark Cloud Computing Platform. Algorithms 2015, 8, 407-414. https://doi.org/10.3390/a8030407
Wang L, Wang Y, Xie Y. Implementation of a Parallel Algorithm Based on a Spark Cloud Computing Platform. Algorithms. 2015; 8(3):407-414. https://doi.org/10.3390/a8030407
Chicago/Turabian StyleWang, Longhui, Yong Wang, and Yudong Xie. 2015. "Implementation of a Parallel Algorithm Based on a Spark Cloud Computing Platform" Algorithms 8, no. 3: 407-414. https://doi.org/10.3390/a8030407
APA StyleWang, L., Wang, Y., & Xie, Y. (2015). Implementation of a Parallel Algorithm Based on a Spark Cloud Computing Platform. Algorithms, 8(3), 407-414. https://doi.org/10.3390/a8030407