Testing a New Ensemble Model Based on SVM and Random Forest in Forest Fire Susceptibility Assessment and Its Mapping in Serbia’s Tara National Park





Abstract
:1. Introduction
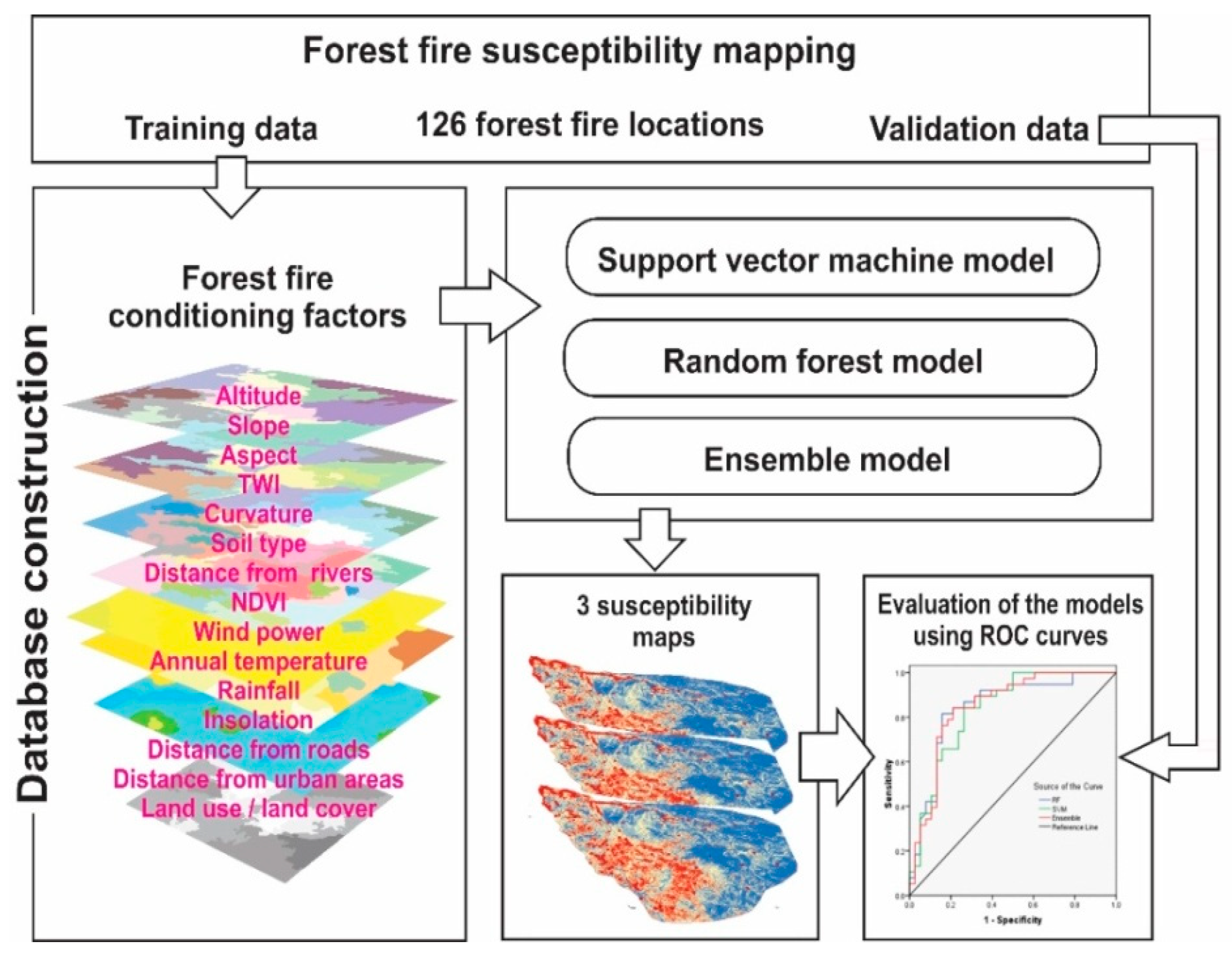
2. Materials and Methods
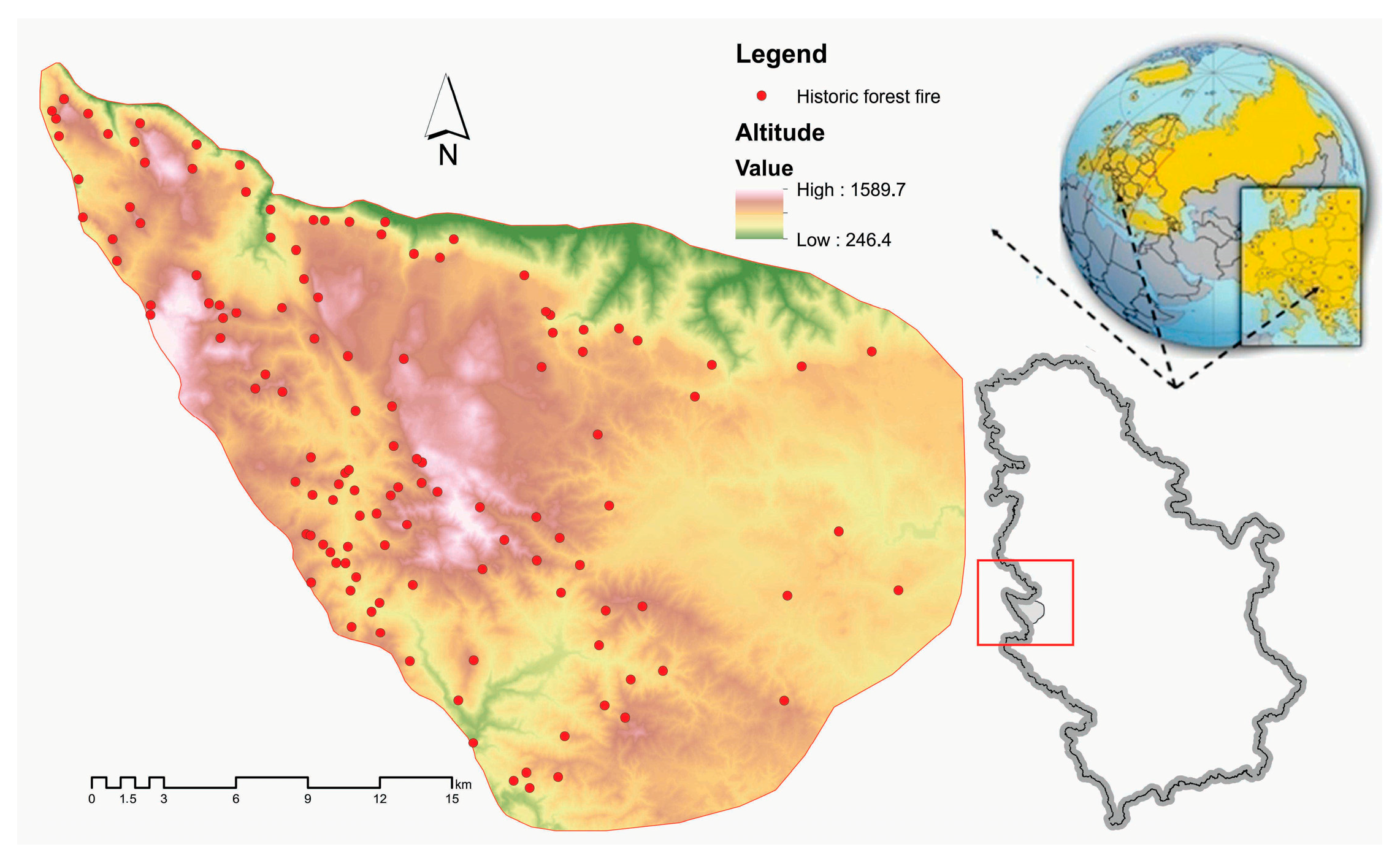
2.1. Study Area and Data
2.2. Methods
3. Input Variables
3.1. Conditioning Factors
3.2. Multi-Collinearity Test
4. Training Data Selection
5. Machine Learning Applications
5.1. Support Vector Machine
- SVM type applied for model: Radial Basis function.
- Hyper-parameter: sigma = 0.054
- Number of Support Vectors: 34
- Objective Function Value: −93.072
- Training error: 0.160
5.2. Random Forests
5.3. Ensemble Modeling
- Boosting, which is used to build multiple models (typically the same type) using previous chain model prediction errors.
- Bagging, which is used to create multiple models from different training dataset subsamples.
- Stacking, which is used to build multiple models and the supervisor model that best combines the predictions of the primary models.
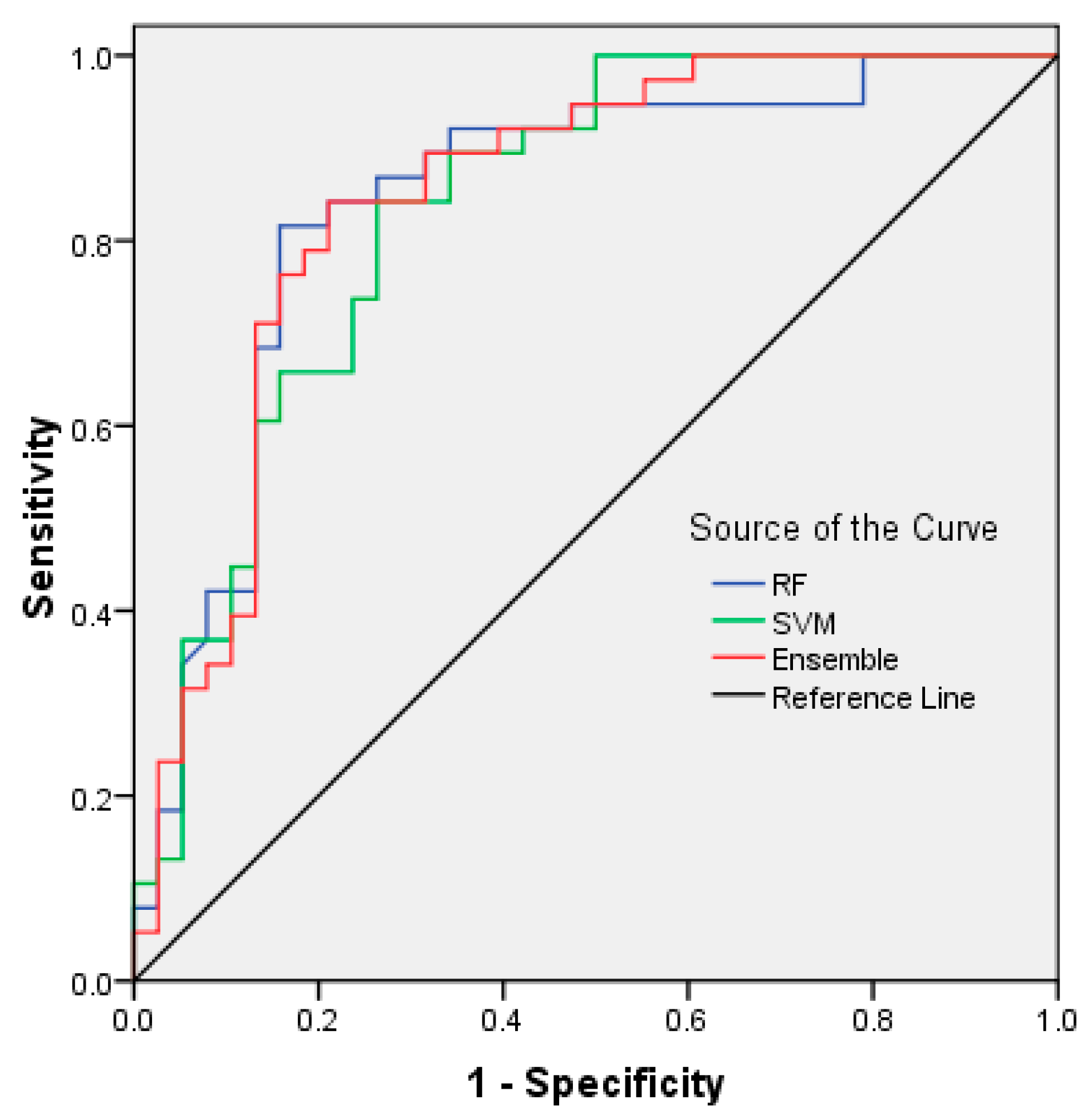
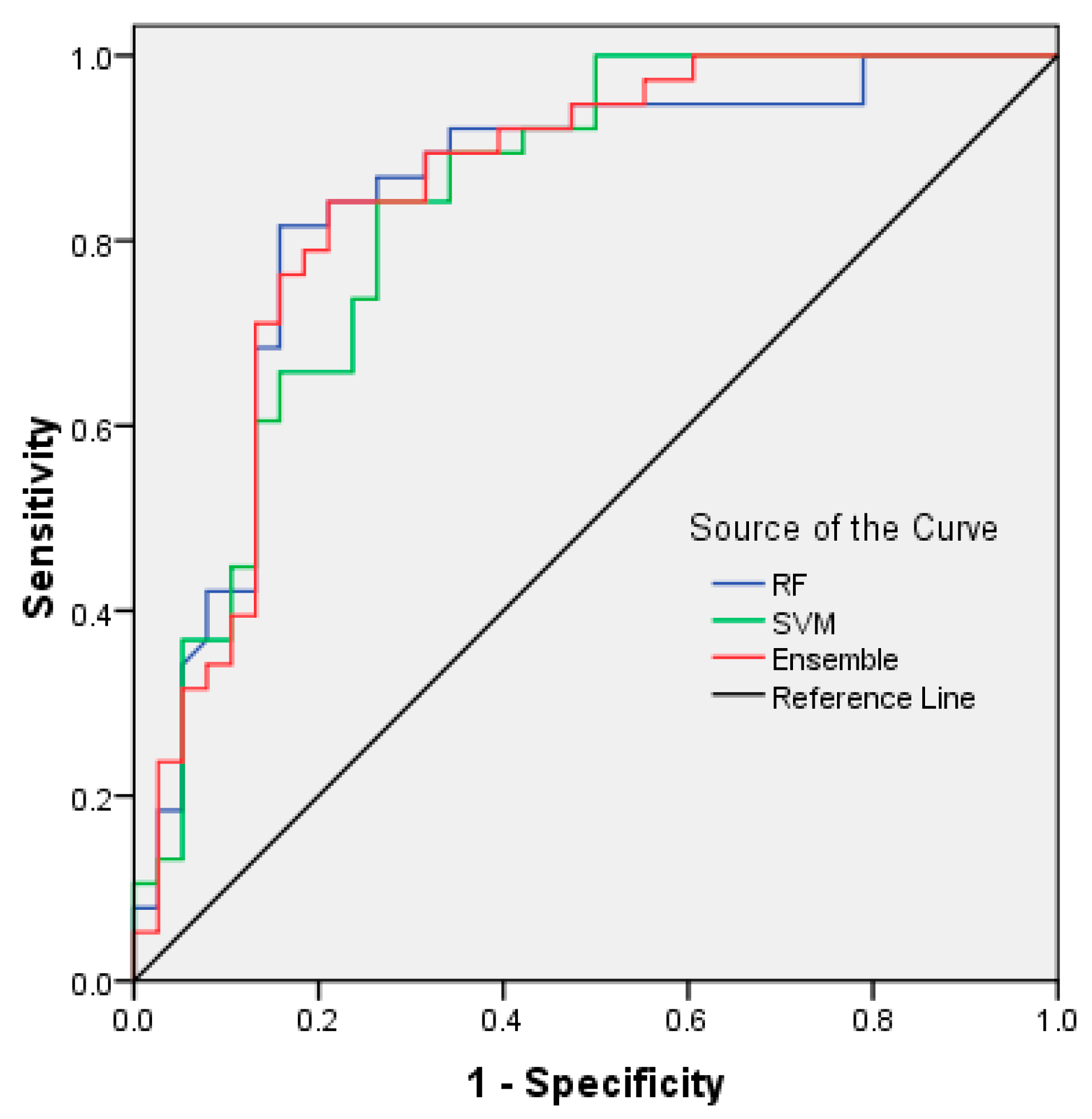
6. Validation
7. Discussion
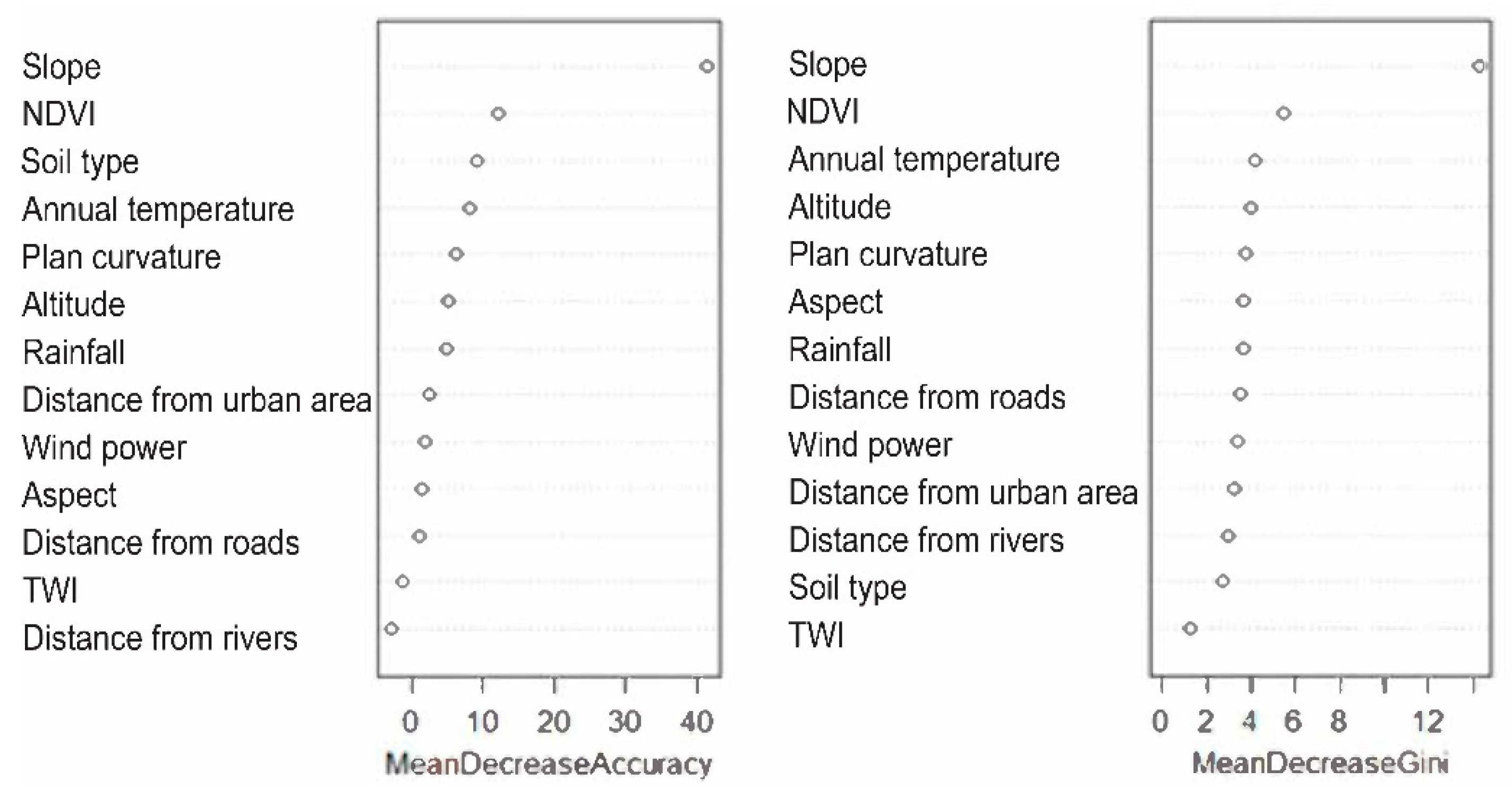
7.1. Importance of Conditioning Factors
7.2. Performance of the Used Models
8. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Satir, O.; Berberoglu, S.; Donmez, C. Mapping regional forest fire probability using artificial neural network model in a Mediterranean forest ecosystem. Geomatics, Nat. Hazards Risk 2016, 7, 1645–1658. [Google Scholar] [CrossRef]
- Chuvieco, E.; Aguado, I.; Yebra, M.; Nieto, H.; Salas, J.; Martín, M.P.; Vilar, L.; Martínez, J.; Martín, S.; Ibarra, P.; et al. Development of a framework for fire risk assessment using remote sensing and geographic information system technologies. Ecol. Model. 2010, 221, 46–58. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Z.; Huang, W.; Li, S.; Zeng, Y. Forest fire spread simulating model using cellular automaton with extreme learning machine. Ecol. Model. 2017, 348, 33–43. [Google Scholar] [CrossRef]
- Bui, D.T.; Le, K.-T.T.; Nguyen, V.C.; Le, H.D.; Revhaug, I. Tropical Forest Fire Susceptibility Mapping at the Cat Ba National Park Area, Hai Phong City, Vietnam, Using GIS-Based Kernel Logistic Regression. Remote. Sens. 2016, 8, 347. [Google Scholar] [Green Version]
- Wegner, J.D.; Roscher, R.; Volpi, M.; Veronesi, F. Foreword to the Special Issue on Machine Learning for Geospatial Data Analysis 2018. Available online: https://www.mdpi.com/2220-9964/7/4/147 (accessed on 24 September 2018).
- Pastor, E.; Zárate, L.; Planas, E.; Arnaldos, J. Mathematical models and calculation systems for the study of wildland fire behaviour. Prog. Energy Combust. Sci. 2003, 29, 139–153. [Google Scholar] [CrossRef]
- Andrews, P.L. BEHAVE: Fire behavior prediction and fuel modeling system-BURN Subsystem, part 1. 1986. Available online: https://www.fs.usda.gov/treesearch/pubs/29612 (accessed on 27 September 2018).
- Linn, R.; Reisner, J.; Colman, J.J.; Winterkamp, J. Studying wildfire behavior using FIRETEC. Int. J. Wildl. Fire 2002, 11, 233–246. [Google Scholar] [CrossRef] [Green Version]
- Lopes, A.M.G.; Cruz, M.G.; Viegas, D.X. FireStation — an integrated software system for the numerical simulation of fire spread on complex topography. Environ. Model. Softw. 2002, 17, 269–285. [Google Scholar] [CrossRef]
- Sturtevant, B.R.; Scheller, R.M.; Miranda, B.R.; Shinneman, D.; Syphard, A. Simulating dynamic and mixed-severity fire regimes: A process-based fire extension for LANDIS-II. Ecol. Model. 2009, 220, 3380–3393. [Google Scholar] [CrossRef]
- Perestrello De Vasconcelos, M.J.; Sllva, S.; Tome, M.; Alvim, M.; Pereira, J.M. Spatial Prediction of Fire Ignition Probabilities: Comparing Logistic Regression and Neural Networks. Photogramm. Eng. Remote Sens. 2001, 67, 73–81. [Google Scholar]
- Arndt, N.; Vacik, H.; Koch, V.; Arpacı, A.; Gossow, H. Modeling human-caused forest fire ignition for assessing forest fire danger in Austria. iFor. - Biogeosci. For. 2013, 6, 315–325. [Google Scholar] [CrossRef] [Green Version]
- Pourghasemi, H.R. GIS-based forest fire susceptibility mapping in Iran: a comparison between evidential belief function and binary logistic regression models. Scand. J. For. Res. 2016, 31, 80–98. [Google Scholar] [CrossRef]
- Conedera, M.; Torriani, D.; Neff, C.; Ricotta, C.; Bajocco, S.; Pezzatti, G.B. Using Monte Carlo simulations to estimate relative fire ignition danger in a low-to-medium fire-prone region. Ecol. Manag. 2011, 261, 2179–2187. [Google Scholar] [CrossRef]
- Amatulli, G.; Pérez-Cabello, F.; De La Riva, J. Mapping lightning/human-caused wildfires occurrence under ignition point location uncertainty. Ecol. Model. 2007, 200, 321–333. [Google Scholar] [CrossRef]
- Vilar, L.; Woolford, D.G.; Martell, D.L.; Martin, M.P. A model for predicting human-caused wildfire occurrence in the region of Madrid, Spain. Int. J. Wildl. Fire 2010, 19, 325–337. [Google Scholar] [CrossRef]
- Oliveira, S.; Oehler, F.; San-Miguel-Ayanz, J.; Camia, A.; Pereira, J.M.; Pereira, J.M.C. Modeling spatial patterns of fire occurrence in Mediterranean Europe using Multiple Regression and Random Forest. Ecol. Manag. 2012, 275, 117–129. [Google Scholar] [CrossRef]
- Sakr, G.E.; Elhajj, I.H.; Huijer, H.A.-S. Support Vector Machines to Define and Detect Agitation Transition. IEEE Trans. Affect. Comput. 2010, 1, 98–108. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Aretano, R.; Semeraro, T. Investigation of general indicators influencing on forest fire and its susceptibility modeling using different data mining techniques. Ecol. Indic. 2016, 64, 72–84. [Google Scholar] [CrossRef]
- Arpaci, A.; Malowerschnig, B.; Sass, O.; Vacik, H. Using multi variate data mining techniques for estimating fire susceptibility of Tyrolean forests. Appl. Geogr. 2014, 53, 258–270. [Google Scholar] [CrossRef]
- Maeda, E.E.; Formaggio, A.R.; Shimabukuro, Y.E.; Arcoverde, G.F.B.; Hansen, M.C. Predicting forest fire in the Brazilian Amazon using MODIS imagery and artificial neural networks. Int. J. Appl. Earth Obs. Geoinformation 2009, 11, 265–272. [Google Scholar] [CrossRef]
- Massada, A.B.; Syphard, A.D.; Stewart, S.I.; Radeloff, V.C. Wildfire ignition-distribution modelling: A comparative study in the Huron–Manistee National Forest, Michigan, USA. Int. J. Wildl. Fire 2013, 22, 174. [Google Scholar] [CrossRef]
- Renard, Q.; Pélissier, R.; Ramesh, B.R.; Kodandapani, N. Environmental susceptibility model for predicting forest fire occurrence in the Western Ghats of India. Int. J. Wildl. Fire 2012, 21, 368–379. [Google Scholar] [CrossRef]
- Adab, H.; Kanniah, K.D.; Solaimani, K. Modeling forest fire risk in the northeast of Iran using remote sensing and GIS techniques. Nat. Hazards 2013, 65, 1723–1743. [Google Scholar] [CrossRef]
- Gigović, L.; Pamučar, D.; Bajić, Z.; Drobnjak, S. Application of GIS-Interval Rough AHP Methodology for Flood Hazard Mapping in Urban Areas. Water 2017, 9, 360. [Google Scholar] [CrossRef]
- Moore, I.D.; Grayson, R.B.; Ladson, A.R. Digital terrain modelling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- O’Brien, R.M. A Caution Regarding Rules of Thumb for Variance Inflation Factors. Qual. Quant. 2007, 41, 673–690. [Google Scholar] [CrossRef]
- Pourghasemi, H.; Beheshtirad, M.; Pradhan, B. A comparative assessment of prediction capabilities of modified analytical hierarchy process (M-AHP) and Mamdani fuzzy logic models using Netcad-GIS for forest fire susceptibility mapping. Geomatics Nat. Hazards Risk 2016, 7, 861–885. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin, Germany, 1995. [Google Scholar]
- Foody, G.; Mathur, A. A relative evaluation of multiclass image classification by support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1335–1343. [Google Scholar] [CrossRef] [Green Version]
- Schölkopf, B.; Smola, A.J.; Williamson, R.C.; Bartlett, P.L. New support vector algorithms. Neural Comput. 2000, 12, 1207–1245. [Google Scholar] [CrossRef]
- Lee, S.; Hong, S.-M.; Jung, H.-S. A Support Vector Machine for Landslide Susceptibility Mapping in Gangwon Province, Korea. Sustainability 2017, 9, 48. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cutler, D.R.; Edwards Jr, T.C.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef]
- Breiman, L.; Cutler, A. Random forests — Classification description: Random forests. Available online: http//stat-www.berkeley.edu/users/breiman/RandomForests/cf_home.html (accessed on 28 September 2018).
- Kuhnert, P.M.; Henderson, A.; Bartley, R.; Herr, A. Incorporating uncertainty in gully erosion calculations using the random forests modelling approach. Environmetrics 2010, 21, 493–509. [Google Scholar] [CrossRef]
- McKay, G.; Harris, J.R. Comparison of the data-driven Random Forests model and a knowledge-driven method for mineral prospectivity mapping: a case study for gold deposits around the Huritz Group and Nueltin Suite, Nunavut, Canada. Nat. Resour. Res. 2016, 25, 125–143. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Proceedings of the ≪UML≫ 2001—The Unified Modeling Language. Modeling Languages; Springer Nature: Berlin, Germany, 2000; pp. 1–15. [Google Scholar]
- Brownlee, J. Machine learning mastery. Available online: http//machinelearningmastery.com (accessed on 25 September 2018).
- Hoang, N.-D.; Bui, D.T. A Novel Relevance Vector Machine Classifier with Cuckoo Search Optimization for Spatial Prediction of Landslides. J. Comput. Civ. Eng. 2016, 30, 4016001. [Google Scholar] [CrossRef]
- Cortez, P. Data Mining with Neural Networks and Support Vector Machines Using the R/rminer Tool. In Proceedings of the ≪UML≫ 2001—The Unified Modeling Language. Modeling Languages, Concepts, and Tools; Springer Nature: Berlin, Germany, 2010; pp. 572–583. [Google Scholar]
- Chen, W.; Pourghasemi, H.R.; Naghibi, S.A. A comparative study of landslide susceptibility maps produced using support vector machine with different kernel functions and entropy data mining models in China. Bull. Eng. Geol. Environ. 2018, 77, 647–664. [Google Scholar] [CrossRef]
- Rahmati, O.; Tahmasebipour, N.; Haghizadeh, A.; Pourghasemi, H.R.; Feizizadeh, B. Evaluation of different machine learning models for predicting and mapping the susceptibility of gully erosion. Geomorphology 2017, 298, 118–137. [Google Scholar] [CrossRef]
- Peters, J.; De Baets, B.; Verhoest, N.E.C.; Samson, R.; Degroeve, S.; De Becker, P.; Huybrechts, W. Random forests as a tool for ecohydrological distribution modelling. Ecol. Model. 2007, 207, 304–318. [Google Scholar] [CrossRef]
- Hong, H.; Naghibi, S.A.; Dashtpagerdi, M.M.; Pourghasemi, H.R.; Chen, W. A comparative assessment between linear and quadratic discriminant analyses (LDA-QDA) with frequency ratio and weights-of-evidence models for forest fire susceptibility mapping in China. Arab. J. Geosci. 2017, 10, 1723. [Google Scholar] [CrossRef]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Rossi, M. Forest fire susceptibility mapping in the Minudasht forests, Golestan province, Iran. Environ. Earth Sci. 2014, 73, 1515–1533. [Google Scholar] [CrossRef]
- Bui, D.T.; Bui, Q.-T.; Nguyen, Q.-P.; Pradhan, B.; Nampak, H.; Trinh, P.T. A hybrid artificial intelligence approach using GIS-based neural-fuzzy inference system and particle swarm optimization for forest fire susceptibility modeling at a tropical area. Agric. Meteorol. 2017, 233, 32–44. [Google Scholar]
- Ballabio, C.; Sterlacchini, S. Support Vector Machines for Landslide Susceptibility Mapping: The Staffora River Basin Case Study, Italy. Math. For. Geosci. 2012, 44, 47–70. [Google Scholar] [CrossRef]
- Aertsen, W.; Kint, V.; Van Orshoven, J.; Özkan, K.; Muys, B. Comparison and ranking of different modelling techniques for prediction of site index in Mediterranean mountain forests. Ecol. Model. 2010, 221, 1119–1130. [Google Scholar] [CrossRef]
- Aertsen, W.; Kint, V.; Van Orshoven, J.; Muys, B. Evaluation of modelling techniques for forest site productivity prediction in contrasting ecoregions using stochastic multicriteria acceptability analysis (SMAA). Environ. Model. Softw. 2011, 26, 929–937. [Google Scholar] [CrossRef] [Green Version]
- Catani, F.; Lagomarsino, D.; Segoni, S.; Tofani, V. Landslide susceptibility estimation by random forests technique: sensitivity and scaling issues. Nat. Hazards Earth Syst. Sci. 2013, 13, 2815–2831. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sub-Classification | Data Layers | Source of Data | GIS Data Type | Derived Map | Resolution |
|---|---|---|---|---|---|
| Fire Inventory Database | Historical forest Fire | Worldview-2 images, Landsat 8 OLI images, MODIS images, aerial photo, and National fire inventory database | Point | - | - |
| Topography | Elevation | DEM, contour lines with 20 m intervals | GRID | Elevation | 20 m |
| Slope | - | GRID | Slope degree | 20 m | |
| Aspect | - | GRID | Aspect degree | 20 m | |
| Curvature | - | GRID | Curvature | 20 m | |
| TWI | - | GRID | TWI | 20 m | |
| Soil type | Soil | National soil data | Polygon | Soil | 1:50,000 |
| Land use/land cover | Land use | CORINE data | ARC/INFO GRID | Land use | 30 m |
| NDVI | NDVI | Landsat 8 OLI images | ARC/INFO GRID | NDVI | 30 m |
| Annual rainfall | Rainfall | Republic Hydro-Meteorological Service http://www.hidmet.gov.rs/index_eng.php | GRID | Precipitation map (mm/m2) | 1:50,000 |
| Annual temperature | Max annual temperature | Republic Hydrometeorological Service http://www.hidmet.gov.rs/index_eng.php | GRID | Temperature map (°C) | 20 m |
| Wind power | Wind power | Republic Hydrometeorological Service http://www.hidmet.gov.rs/index_eng.php | GRID | Wind power map (m/s) | 20 m |
| River | Drainage network | MGI Digital topographic map http://www.vgi.mod.gov.rs/english/index_eng.html | Line | Distance from rivers (m) | 1:25,000 |
| Roads | Road network | MGI Digital topographic map http://www.vgi.mod.gov.rs/english/index_eng.html | Line | Distance from roads (m) | 1:25,000 |
| Urban areas | Urban areas | MGI Digital topographic map http://www.vgi.mod.gov.rs/english/index_eng.html | Polygon | Distance from urban areas (m) | 1:25,000 |
| Category | Description |
|---|---|
| Topography (Figure 3) | Altitude is an important forest fire conditioning factor. An altitude map is prepared from the 20 × 20 m digital elevation model (1:25,000—scale with 20 m contour intervals). |
| The slope is the gradient of the land expressed as percentages or angle and it has a great influence on fir behavior. Fires burn faster on a steeped slope due to convection column flame front proximately to new fuels. Slope influences the rate of speed and fire direction. | |
| Aspect is the direction in which a slope faces. It has an effect on the climate of the slope in terms of insolation, exposure of winds, etc. Therefore, the opposite aspect tends to retain more moisture supporting greenish and healthy vegetation. | |
| The curvature is defined as the change rate of slope gradient or aspect, usually in a particular direction. In addition, the curvature represents convergence or divergence of water level concurrently with an activity of downhill flow. Negative, zero, and positive curvature represent concave, flat, and convex, respectively. | |
| Topographic Wetness Index (TWI) describes the size of saturated areas of runoff generation and the effect of topography on the location. It is defined as [26]: TWI = ln (AS/tan β), where AS is the catchment area and β is the slope angle in degrees. | |
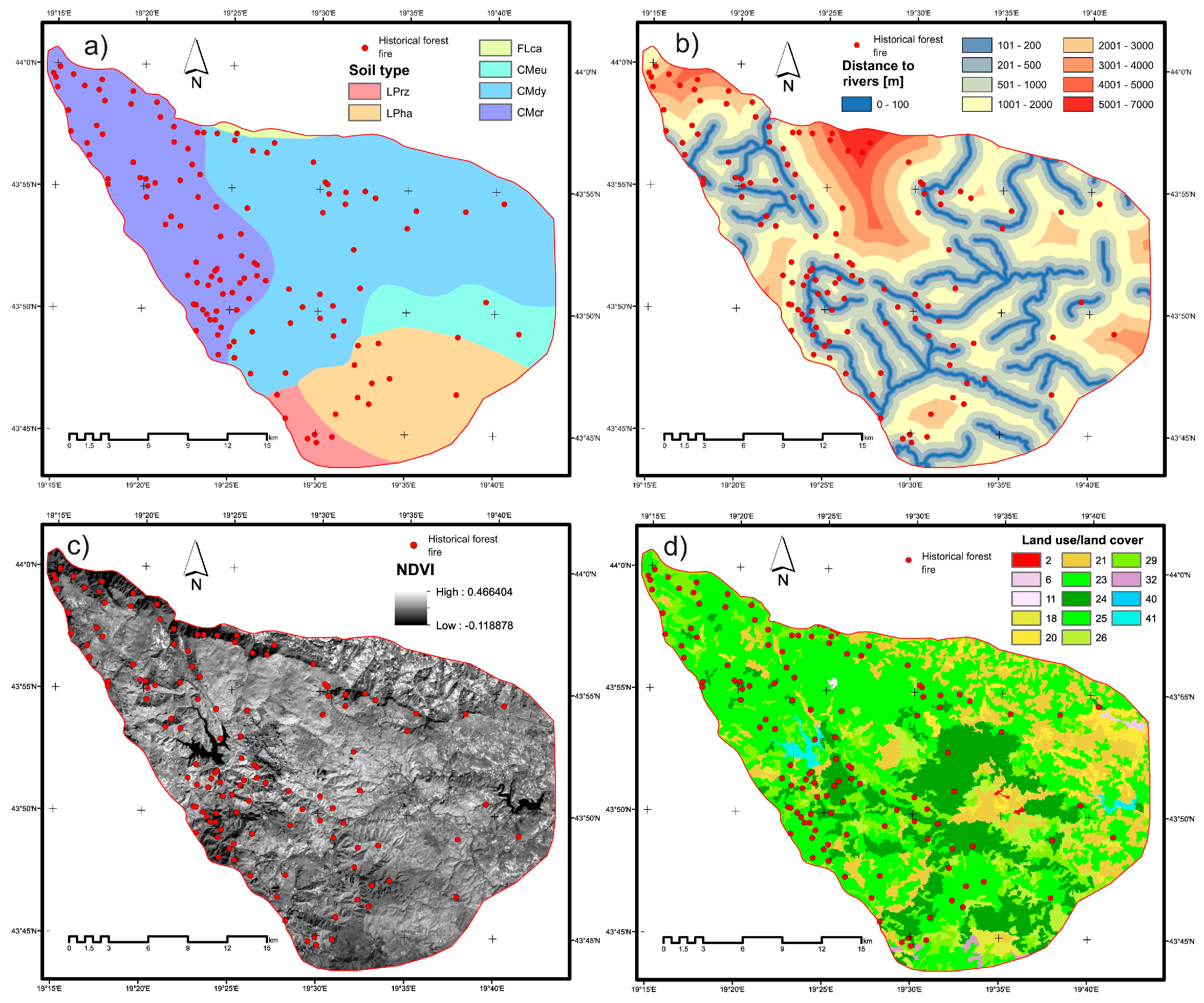
| Environmental (Figure 4) | Soil type reflects the affect of textures and compositions of soil materials on fire occurrence. The soil map was constructed from the soil map of the state and was classified into fine-silt, course-loamy, fine-loamy, mixed-loamy, and skeletal-loamy. |
| Distance from river was created using a topographical map and it was calculated based on the Euclidean distance method in ArcGIS 10.4 and were classified into (<100), (100–200), (200–500), (500–1000), (1000–2000), (2000–3000), (3000–4000), (4000-5000), and (>5000) meters classes | |
| Normalized Difference Vegetation Index (NDVI). The NDVI map was created using multispectral Landsat 8 OLI imagery showing the surface vegetation coverage and density in an image. | |
| Land use/land cover is considered as a factor in environmental protection. Data on land use/cover were taken on the basis of the Corine Land Cover 2006 (CLC2006) database, collected in the framework of the European Commission’s CORINE (Coordination of Information on the Environment) programme. | |
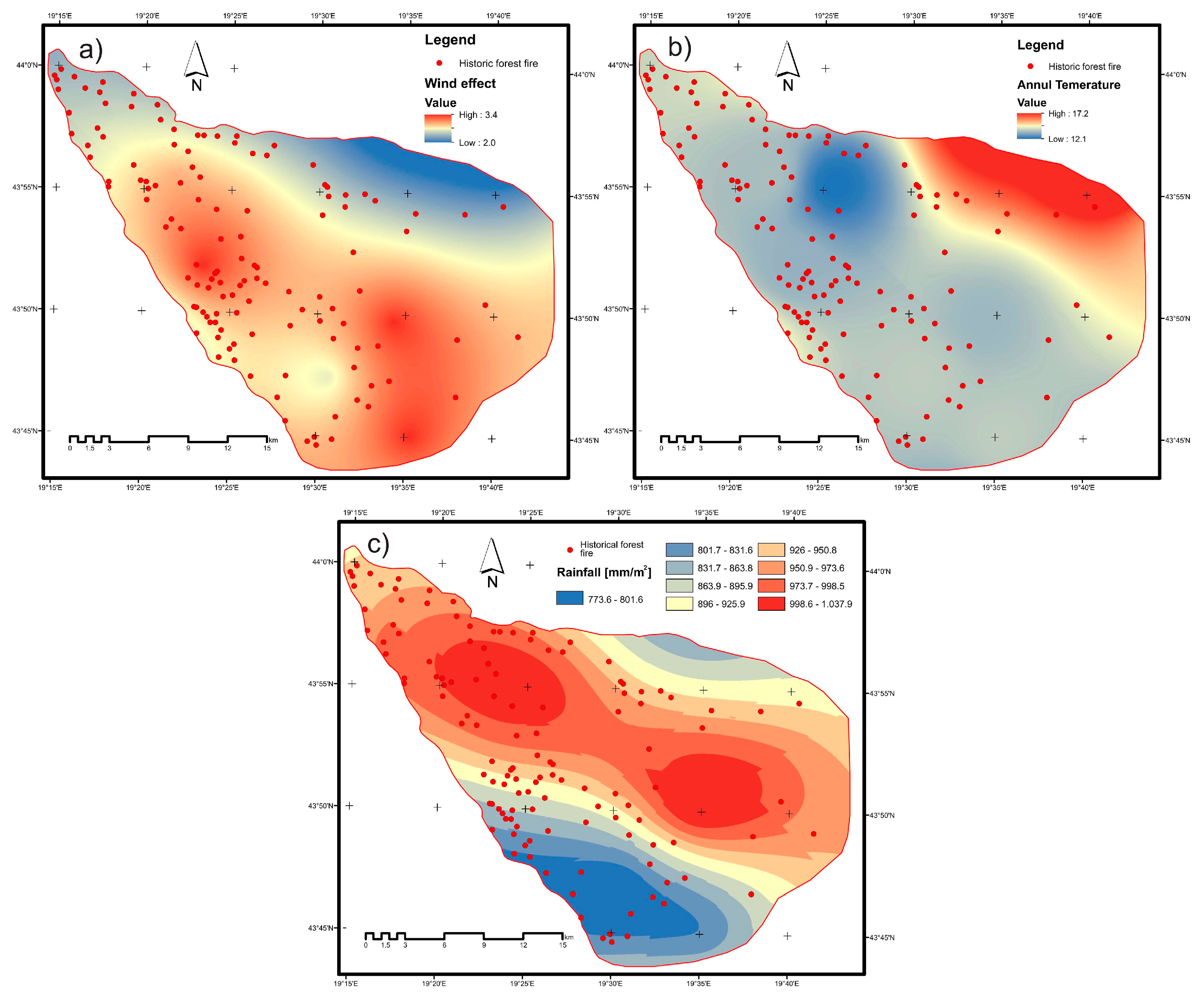
| Meteorological (Figure 5) | Wind power varies greatly, even at very short time scales (seconds to minutes). Two wind characteristics are used in wildfire susceptibility mapping: Wind speed and wind direction. |
| Annual temperature is a basic weather factor and should be taken into account. The temperature influences the condition of forest fuel, as its main effect is to dry the fuel. | |
| Rainfall is the important effect that contributes to high fuel humidity and therefore is a negative indicator of the spread of fire. The scale was reversed to conform to the linear trend of other parameters. Annual rainfall values are divided into nine classes: (773.6–801.6, 801.7–831.6, 831.7–863.8, 863.9–895.9, 896–925.9, 926–950.8, 950.9–973.6, 973.7–998.5, 998.6–1037.9 mm/m2) | |
| Social (Figure 6) | Distance from roads was created using a topographical map, was calculated based on the Euclidean distance method in ArcGIS 10.4, and was classified into (<100), (100–200), (200-300), (300–500), (500–750), (750–1000), (1000–2000), (2000–3000), and (>3000) meters classes |
| Distance from urban areas was created using a topographical map, was calculated based on the Euclidean distance method in ArcGIS 10.4, and was classified into (<1000), (1000–2000), (2000–3000), (3000–4000), (4000–5000), (5000–6000), (6000–7000), and (>7000) meters classes. |
| Number | Code/Value | Description |
|---|---|---|
| 1 | Flca | Calcaric Fluvisol |
| 2 | CMcr | Chromic Cambisol |
| 3 | Cmdy | Dystric Cambisol |
| 4 | Cmeu | Eutric Cambisol |
| 5 | Lpha | Haplic Leptosol |
| 6 | LPrz | Rendzic Leptosol |
| 7 | Pldy | Dystric Planosol |
| Number | Code/Value | RGB | Code | Description |
|---|---|---|---|---|
| 1 | 2 | 255,0,0 | 112 | Discontinuous urban fabric |
| 2 | 6 | 230,204,230 | 124 | Airports |
| 3 | 11 | 255,230,255 | 142 | Sport and leisure facilities |
| 4 | 12 | 255,255,168 | 211 | Non-irrigated arable land |
| 5 | 18 | 230,230,77 | 231 | Pastures |
| 6 | 20 | 255,230,77 | 242 | Complex cultivation patterns |
| 7 | 21 | 230,204,77 | 243 | Land principally occupied by agriculture, with significant areas of natural vegetation |
| 8 | 23 | 128,255,0 | 311 | Broad-leaved forest |
| 9 | 24 | 0,166,0 | 312 | Coniferous forest |
| 10 | 25 | 77,255,0 | 313 | Mixed forest |
| 11 | 26 | 204,242,77 | 321 | Natural grasslands |
| 12 | 29 | 166,242,0 | 324 | Transitional woodland-shrub |
| 13 | 32 | 204,255,204 | 333 | Sparsely vegetated areas |
| 14 | 40 | 0,204,242 | 511 | Water courses |
| 15 | 41 | 128,242,230 | 512 | Water bodies |
| Model | Unstandardized Coefficients | Standardized Coefficients | T | Significant | Collinearity Statistics | ||
|---|---|---|---|---|---|---|---|
| B | Standard Error | Beta | Tolerance | VIF | |||
| (Constant) | 1.674 | 1.726 | 0.970 | 0.334 | |||
| Aspect | 0.004 | 0.014 | 0.021 | 0.325 | 0.746 | 0.953 | 1.049 |
| Altitude | 0.000 | 0.000 | 0.182 | 2.088 | 0.038 | 0.510 | 1.961 |
| NDVI | 0.122 | 0.671 | 0.014 | 0.182 | 0.856 | 0.663 | 1.508 |
| Plan curvature | 0.039 | 0.048 | 0.052 | 0.808 | 0.420 | 0.947 | 1.056 |
| Rainfall | 0.000 | 0.001 | −0.056 | −0.700 | 0.485 | 0.610 | 1.640 |
| Distance from rivers | −3.372 × 10−5 | 0.000 | −0.072 | −0.950 | 0.344 | 0.671 | 1.491 |
| Distance from roads | 1.013 × 10−5 | 0.000 | 0.013 | 0.187 | 0.852 | 0.825 | 1.212 |
| Soil type | 0.007 | 0.037 | 0.016 | 0.184 | 0.854 | 0.541 | 1.850 |
| Maximum annual temperature | −0.084 | 0.069 | −0.155 | −1.208 | 0.229 | 0.234 | 4.272 |
| Distance from urban | 6.978 × 10−6 | 0.000 | 0.017 | 0.233 | 0.816 | 0.712 | 1.404 |
| Wind power | −0.233 | 0.236 | −0.130 | −0.987 | 0.325 | 0.222 | 4.496 |
| TWI | 0.000 | 0.008 | 0.002 | 0.032 | 0.974 | 0.942 | 1.061 |
| Slope | 0.023 | 0.004 | 0.528 | 6.503 | 0.000 | 0.587 | 1.704 |
| Models | Area | Standard Error | Asymptotic Significant | Asymptotic 95% Confidence Interval | |
|---|---|---|---|---|---|
| Lower Bound | Upper Bound | ||||
| RF | 0.844 | 0.047 | 0.001 | 0.751 | 0.937 |
| SVM | 0.834 | 0.047 | 0.001 | 0.743 | 0.926 |
| Ensemble | 0.848 | 0.046 | 0.001 | 0.758 | 0.938 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gigović, L.; Pourghasemi, H.R.; Drobnjak, S.; Bai, S. Testing a New Ensemble Model Based on SVM and Random Forest in Forest Fire Susceptibility Assessment and Its Mapping in Serbia’s Tara National Park. Forests 2019, 10, 408. https://doi.org/10.3390/f10050408
Gigović L, Pourghasemi HR, Drobnjak S, Bai S. Testing a New Ensemble Model Based on SVM and Random Forest in Forest Fire Susceptibility Assessment and Its Mapping in Serbia’s Tara National Park. Forests. 2019; 10(5):408. https://doi.org/10.3390/f10050408
Chicago/Turabian StyleGigović, Ljubomir, Hamid Reza Pourghasemi, Siniša Drobnjak, and Shibiao Bai. 2019. "Testing a New Ensemble Model Based on SVM and Random Forest in Forest Fire Susceptibility Assessment and Its Mapping in Serbia’s Tara National Park" Forests 10, no. 5: 408. https://doi.org/10.3390/f10050408
APA StyleGigović, L., Pourghasemi, H. R., Drobnjak, S., & Bai, S. (2019). Testing a New Ensemble Model Based on SVM and Random Forest in Forest Fire Susceptibility Assessment and Its Mapping in Serbia’s Tara National Park. Forests, 10(5), 408. https://doi.org/10.3390/f10050408