Abstract
Synonymous codon usage (SCU) bias in oil-tea camellia cpDNAs was determined by examining 13 South Chinese oil-tea camellia samples and performing bioinformatics analysis using GenBank sequence information, revealing conserved bias among the samples. GC content at the third position (GC3) was the lowest, with a preference for A or T, suggesting weak SCU bias. The GC contents at the first two codon positions (GC1 and GC2) were extremely significantly correlated with one another but not with the expected number of codons (ENC). GC3 was not correlated with GC1 and GC2 but was extremely significantly correlated with ENC. Of the 30 high-frequency codons, 15, 14, 1 and 0 codons had U, A, G and C at the third position, respectively. The points for most genes were distributed above the neutrality plot diagonal. The points for 20 genes, accounting for 37.74% of all coding sequences (CDSs), were distributed on or near the ENC plot standard curve, and the ENC ratio ranged from −0.05–0.05. However, those of the other genes were under the standard curve, with higher ENC ratios. The points for most genes were distributed in the lower part of the PR2 plot, especially the bottom right corner. Twenty-eight highly expressed codons were screened and 11, 9, 7 and 1 codons had U, A, C and G as the third base, respectively. Twenty optimal codons were screened by comparing high-frequency codons and 11, 8, 0 and 1 codons had U, A, C and G as the third base, respectively. All samples were divided into six clades (r2 = 0.9190, d = 0.5395) according to a relative synonymous codon usage (RSCU)-based phylogenetic tree. Camellia gauchowensis, C. vietnamensis, an undetermined oil-tea camellia species from Hainan province, and C. osmantha belonged to the same clade; the genetic relationships between C. gauchowensis, C. vietnamensis and the undetermined species were the closest. In summary, SCU bias is influenced by selection, while the influence of mutation cannot be ignored. As the SCU bias differed between species, this feature can be used to identify plant species and infer their genetic relationships. For example, C. vietnamensis and C. gauchowensis can be merged into one species, and the undetermined species can be considered C. vietnamensis. The results described here provide a basis for studying cpDNA gene expression and the development of cpDNA genetic engineering.
1. Introduction
There are 20 amino acids, yet there are 61 codons that encode them [1] and it is known that synonymous codons encode 18 different amino acids, but the usage of these synonymous codons is biased; meanwhile, the optimal codons can be identified from synonymous codon usage (SCU) bias [2]. SCU is thought to be an evolutionary behavior for organisms to adapt to their environment [3], and it has been reported that mutation, selection and drift are the main reasons for SCU [4]; this is the most important issue to be debated. SCU research has been helpful in elucidating the molecular evolution and adaptation to the environment and thus the evolutionary relationships among different species [5]. Additionally, SCU research has been helpful in gene expression research [6] and genetic engineering [7].
Chloroplast genomes (cpDNAs) are generally covalently closed circular DNA with a genome size of 115~165 kb, which exists as multiple copies in cells and can be transcribed and translated during gene expression [8]. Due to their advantages of stable structure, conserved gene content and slow molecular evolution rate, cpDNAs have been widely used in research on species evolution, species classification and phylogeny [9].
In summary, analyzing the SCU of cpDNAs seems to be one of the best methods for researching the evolutionary relationships among different species of plants. To date, research on the SCU of cpDNAs has been reported in Phalaenopsis aphrodite [10], Gossypium hirsutum [11], Camellia oleifera [12], Gelidocalamus tessellatus [13] and Trollius chinensis [14], among others.
Oil-tea camellia plants belong to the Camellia genus and produce seeds containing large quantities of oil. These economically important plants are cultivated in many areas and distributed in 18 provinces or autonomous regions of South China. The oil produced by these plants is an important and unique high-value food oil [15]. High-yield cultivars for afforestation have not yet been selected in the oil-tea camellia plants in South China, such as C. vietnamensis, C. gigantocarpa and C. osmantha, in contrast to C. oleifera and C. meiocarpa; it is therefore extremely urgent to study issues related to the development of oil-tea camellia germplasm and the breeding of oil-tea camellia [16].
Studying the SCU bias in cpDNAs of different oil-tea camellia germplasms provides a new framework for understanding the genetic evolution of Camellia plants [12,17]. Researching the causes of SCU bias helps predict the expression efficiency of the cpDNA genes of oil-tea camellia plants, guides the development of cpDNA genetic engineering and aids in the construction of a technological system for the molecular breeding of oil-tea camellia plants [18]. Therefore, it is essential to study SCU bias in the cpDNA of oil-tea camellia plants.
Our research group sequenced the cpDNAs of 13 oil-tea camellia plant samples and analyzed and compared the structures of all cpDNAs. Then, the specificity of the cpDNAs of the different species was examined, and the identification of undetermined species of oil-tea camellia plants from Hainan province was carried out. All samples belonged to six species of oil-tea camellia, including C. vietnamensis, whose samples were collected from production areas in seven different counties or cities [19]. Further research on the SCU bias in the cpDNAs of 13 oil-tea camellia samples was performed to reveal the genetic relationships and cpDNA gene expression of these plants.
2. Materials and Methods
2.1. Experimental Materials
Leaf samples for cpDNA sequencing were collected from various plants, including 13 samples whose information is shown in Table 1. According to assembly and comparison after cpDNA sequencing, the cpDNA sequences of the HD10~HD13 samples (3 undetermined species from Hainan province and C. gauchowensis from Xuwen county, Guangdong Province) were identical, and four emerged from the cpDNA of HD10 [19]. Therefore, 10 cpDNAs were used to analyze SCU bias. Based on the annotation of the 10 cpDNAs and referring to the genome of C. oleifera (HD07, MN078090), 53 efficient coding sequences (CDSs) were screened to analyze SCU bias after deleting those with lengths less than 300 bp, repeat genes and termination codons.

Table 1.
Basic information on the different oil-tea camellia species.
2.2. Calculations of the GC Content and ENC Value
Using CUSP software, the contents of GC at the first, second and third positions of each codon of each gene were calculated (namely, GC1, GC2 and GC3, respectively), and the total GC content (GCall) and the effective number of codons (ENC) value of each codon of each gene were determined. ENC values range from 20 to 61, with 20 indicating extreme bias and only one codon used for each amino acid (AA) and 61 indicating no bias, with all synonymous codons used for each amino acid [20]. One-unit linear correlation analysis was performed in the R environment with a two-tailed test, with the symbol ** indicating extreme significance at p ≤ 0.01 and the symbol * indicating significance at p ≤ 0.05.
2.3. Analysis of Relative Synonymous Codon Usage (RSCU)
The formula for calculating RSCU values was as follows.
RSCU = Observed frequency of a codon/Expected frequency under the assumption that all synonymous codons for those amino acids are used equally.
RSCU was calculated with CodonW 1.4.2 software, and a corresponding plot was drawn with Microsoft Office Excel 2016 software. Cluster analysis was carried out with the single method by using the cluster procedure in SAS based on the RSCU of each synonymous codon.
2.4. Neutrality Plot Construction
A neutrality plot is used primarily to identify the factors influencing SCU bias [21]. The content of GC3 and the content of GC12 [GC12 = (GC1 + GC2)/2] are the horizontal and vertical ordinates, respectively, and a two-dimensional scatter diagram in which each point symbolizes a particular gene is drawn. If the points are distributed along the diagonal, the linear regression is near 1, then the GC12 and GC3 contents are essentially the same. In other words, the base compositions at the different positions in the codon are almost the same, indicating that the gene is only slightly influenced by selection pressure but strongly influenced by mutation pressure [22]. If the points are distributed far away from the diagonal, the linear regression approaches 0, meaning that the difference in the GC12 and GC3 contents is strong, i.e., that the gene is influenced mainly by selection pressure [23].
2.5. ENC Plot Construction
The ENC is used to identify the range of SCU bias. The expected value ranges from 20 to 61, where values closer to 20 indicate that SCU bias is influenced more by mutation pressure and, otherwise, more by selection pressure [24]. The content of GC in the third position of the synonymous codons (GC3s) in each cpDNA CDS and the actual value of ENC (ENCcobs) are the horizontal and vertical ordinates, respectively, and a two-dimensional scatter diagram is drawn. The curve of the ENC expected value (ENCexp) is drawn according to the formula ENCexp = 2 + GC3s + 29/[GC3s2 + (1 − GC3s)2]. Then, the ENCexp of each CDS is calculated based on the content of GC3s of each CDS [20], and the ratio of ENC (ENCratio) is calculated according to the formula ENCratio = (ENCexp-ENCcobs)/ENCexp [25].
2.6. PR2 Plot Construction
The analysis of PR2 plots is also called analysis of parity preference; it reveals whether the difference in the combination of the 4 bases, i.e., A, T, C and G, at the third position of a codon influences SCU bias [26]. In this study, the four degenerate codons with variation only at the third position for the amino acids (valine, proline, threonine, alanine, glycine, serine, leucine and arginine) were also used for PR2 evaluation [27]. The ratio of the G3s content to the sum of the G3s and C3s contents is the horizontal ordinate, and the ratio of the A3s content to the sum of the A3s and T3s contents is the vertical ordinate. Then, a two-dimensional scatterplot is drawn and analyzed. Points in the center show that the base content is even, i.e., that A = T and C = G, indicating that there is no parity preference or mutation, while the vector from the center point indicates the degree and direction of the base shift [28].
2.7. Optimal Codon Analysis
The high-frequency codons whose RSCU was more than 1 were chosen [29], while the 53 CDSs were arranged from high to low in terms of ENC value. Then, 10% of the genes were chosen from the highest and lowest ends, and the high- and low-expression gene groups were identified. For each codon, the RSCU of the high-expression group minus that of the low-expression group was calculated, and the difference was symbolized with ΔRSCU. If the codon’s ΔRSCU value was not less than 0.08, it was regarded as a high-expression codon [4]; eventually, the optimal codons were determined by comparing the high-frequency codons and the high-expression codons.
2.8. Construction of a cpDNA Phylogenetic Map
A total of 65 complete cpDNA sequences were obtained according to the method of a previous report [19], and 10 sample sequences were added for analysis. CDSs of the above 75 full cpDNA sequences were extracted for phylogenetic analysis. The phylogenetic tree was constructed according to the method in that same report [19]. The optimal model was selected through the IQ-TREE model finder, and the optimal mode was GTR + invgamma. The phylogenetic tree was constructed using IQ-TREE version 2 software. The outgroup was set as Hartia_laotica (NC_041509.1), and the IQ-TREE parameters were set as -BB 1000 and -ALRT 1000, which denoted a nucleic acid molecule replacement model set as GTR. Rate variation across sites was defined by the invgamma model; the prior probability model parameters were set to default values; and the parameters for Markov chain Monte Carlo sampling were Nruns = 2, Nchain = 4, Ngen = 1,000,000, Samplefreq = 500 and Temp = 0.05, indicating that the CDSs in the analysis were run simultaneously. When the original tree results were obtained, the branches unrelated to the sample were removed to obtain the final phylogenetic tree.
3. Results and Analysis
3.1. Base Composition of Oil-Tea Camellia cpDNAs
The same 53 cpDNA CDSs were screened from each sample, and the base compositions of these CDSs are shown in Table 2.
Table 2.
GC content at different positions and ENC values of codons in the chloroplast genome of oil-tea camellia.
The CDSs of all samples included 27 photosynthesis genes, 18 self-replication genes, 4 other genes, and 4 genes encoding proteins of unknown function; among them, the gene accD encoded the subunit of acetyl-CoA-carboxylase, the key enzyme in fatty acid synthesis. Examination of all samples separately revealed that the CDSs differed in the GC1, GC2, GC3 and GCall contents and ENC values. Examining the same CDS among different samples showed that 22 genes (atpA, atpE, atpI, cenA, clpP, ndhC, petA, petB, petD, psaB, psbC, psbD, rbcL, rpl14, rpl2, rpl22, rps12, rps14, rps3, rps4, rps7, and ycf3) had consistent GC contents among codons, representing 41.51% of all CDSs. Seven genes (accD, ndhF, ndhK, rpoB, rpoC2, ycf1 and ycf2) showed differences at each codon position, representing 13.21% of all CDSs. Two genes (ndhG and rps8) showed a difference only in the content of GC1. Three genes (ndhE, ndhI and rpl16) showed a difference only in the content of GC2. Thirteen genes (atpB, atpF, ccsA, ndhA, ndhB, ndhD, ndhJ, psaA, psbB, rpl20, rps18, rps2 and ycf4) showed a difference only in the content of GC3, accounting for 24.53% of all CDSs. The genes with differences in the contents of GC1 and GC3 included matK and rpoC1. The genes showing differences in the contents of GC2 and GC3 included ndhH and rpoA. Therefore, the GC contents varied among the different positions of codons or CDSs, and differences in GC3 among the CDSs were common. Moreover, the expression frequency was different among the CDSs. However, the GC content of the same CDS was the same or only slightly different among all samples, and the average GCall contents of all samples ranged from 37.42 to 37.44. These results indicated that the base composition of codons showed a preference for A or T, especially for the codons whose third base was A or T, which was the vast majority of all codons. Thus, the base composition of all CDSs was highly genetically conserved among all samples.
The ENC values of the different CDSs ranged from 35.23 to 56.67, and the average ENC values of the different samples ranged from 48.48 to 48.51. As the ENC values were over 35, the SCU bias of all samples was weak. Some CDSs showed the same ENC value among different samples, while some samples had the same average ENC values, indicating conservation of gene expression frequency and SCU bias among the samples.
When the differences among all samples were analyzed, several different genes from samples HD03~HD08 exhibited unique variance patterns in the GC content. For example, such a variance was observed for the GC3 contents of the atpF and ndhJ genes of C. gigantocarpa (HD03), the GC2 content of the rpl16 gene, the GC3 contents of the rps11 and rps18 genes of C. semiserrata (HD06), the GC2 content of the ndhE gene of C. oleifera (HD07), and the GC3 contents of the ccsA, ndhD, and rpl20 genes of C. osmantha (HD08). The other samples showed no difference in the corresponding GC contents, suggesting species specificity. The samples of C. gauchowensis, C. vietnamensis and undetermined species from Hainan province (HD01, HD02, HD09 and HD10) were similar to the sample of C. oleifera (HD07) in terms of the GC contents of the different CDSs. In particular, the samples of C. gauchowensis from Gaozhou city, C. vietnamensis and the undetermined species from Hainan province (HD01, HD09 and HD10) were more similar to each other, and the sample of C. osmantha (HD08) was more similar to the samples of C. gauchowensis, C. vietnamensis and the undetermined species from Hainan province (HD01, HD02, HD09 and HD10) than to the other samples.
The comparison of the average contents of GC1, GC2 and GC3 among all samples is shown in Figure 1. The GC1, GC2 and GC3 contents of all samples showed almost no differences. Specifically, the GC1, GC2 and GC3 contents were lower and were less than 50%, 40% and 30%, respectively, which indicated that different genes were expressed at different frequencies among all samples, and the base composition of the codons showed a preference for A or T. Finally, genetic conservation was observed among all samples.
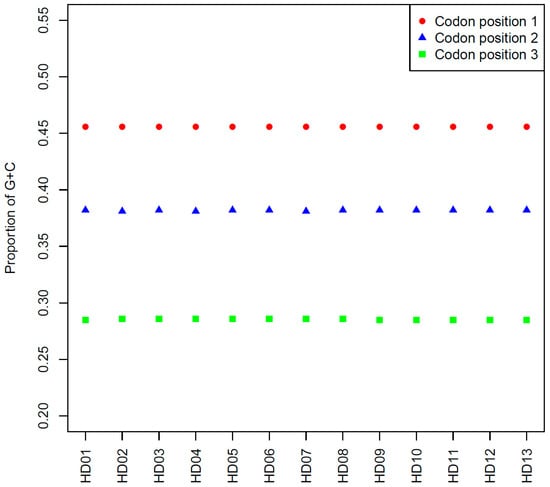
Figure 1.
Comparison among the average contents of GC at the different codon positions in the cpDNA of the various samples.
The results of one-unit linear correlation analyses between the GC contents of all codon sites, the GCall contents and the ENC values of all CDSs in each sample are shown in Table 3. There were extremely significant linear correlations between GC1 and GC2; GCall and GC1, GC2, and GC3; GCall and GC12; and GC12 and GC1 or GC2. However, the correlations of GC3 with GC1, GC2 and GC12 were not significant. This result indicated that the base compositions at the first and the second positions of codons were similar, yet those at the third position were significantly different from those of the former two. This result was consistent with the previous result of a preference for A or T at the third position. The ENC value was extremely significantly correlated with the content of GC3 but not with the GC1, GC2 and GC12 contents, indicating that the third position of the codons was strongly influenced by SCU bias. Moreover, this finding was consistent with the third position of the codons showing a strong preference for A or T.
Table 3.
Correlation analysis of the GC content and ENC value of different codon positions in oil-tea camellia.
3.2. Analysis of the RSCU of Oil-Tea Camellia cpDNAs
The RSCU of all cpDNA samples is shown in the stacked bar chart in Figure 2. The stacked bars of all the different samples were highly similar to each other in shape, indicating that all sample cpDNAs were highly genetically conserved. There were 30 high-frequency codons whose RSCU was over 1: the UUU codon of Phe; the Leu synonymous codons UUA, CUU and UUG; the AUU codon of Ile; the Val synonymous codons GUA and GUU; the UAU codon of Tyr; the Gly synonymous codons GGA and GGU; the AAU codon of Asn; the CAA codon of Gln; the AAA codon of Lys; the GAU codon of Asp; the GAA codon of Glu; the Ser synonymous codons UCU, AGU and UCA; the Pro synonymous codons CCU and CCA; the Thr synonymous codons ACU and ACA; the Ala synonymous codons GCU and GCA; the UGU codon of Cys; the CAU codon of His; the Arg synonymous codons AGA, CGA and CGU; and the termination codon UAA. Among the 30 high-frequency codons, U, A and G were the third base in 15, 14 and 1, respectively, indicating that the third position of codons showed a preference for A or U. Otherwise, the codons whose third bases were G or C were all low-frequency codons because their RSCU values were less than 1. Therefore, the third position of the codons showed a preference for A or T.
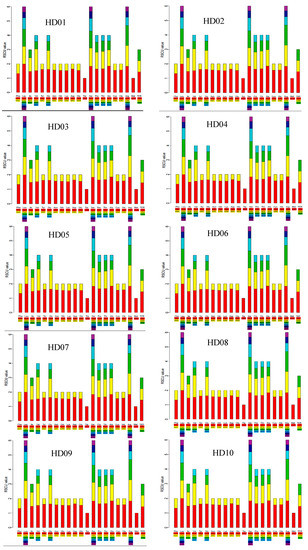
Figure 2.
RSCU of the codons in the cpDNA of all samples.
3.3. Neutrality Plot Analysis of Oil-Tea Camellia cpDNAs
The neutrality plots of all samples are shown in Figure 3. The diagrams of the different samples were highly similar to each other, and the vast majority of the points were distributed at the same locations, indicating that the cpDNAs of all samples were highly genetically conserved. The GC3 contents of all 53 CDSs of all samples ranged from 19.12% to 37.11%, and the average GC12 contents of all 53 CDSs of all samples ranged from 32.00% to 55.40%, indicating that the third position of the codons was significantly different from the first two positions. Only the points of the genes cemA and ycf2 were almost distributed along the diagonal, and the point of the gene atpF was extremely close to the diagonal. Thus, the SCU bias of these three genes was influenced by mutation pressure. However, the points of the other 50 genes were distributed above and farther away from the diagonal, and the point for the rps11 gene was the farthest from the diagonal. The SCU bias of all these genes was influenced by selection pressure. The one-unit linear regression and coefficients of determination of the GC12 contents against the GC3 contents ranged from 0.0768 to 0.1002 and from 0.0032 to 0.0054, respectively, which indicated that the linear regression and correlation relationships were not significant, and the maximum and minimum of the regression and correlation coefficients among all samples were observed for C. semiserrata (HD06) and C. meiocarpa (HD05), respectively. All these results indicated that the third position was significantly different from the first two positions in terms of quantity, while the SCU bias of the vast majority of the codons was influenced by selection pressure.
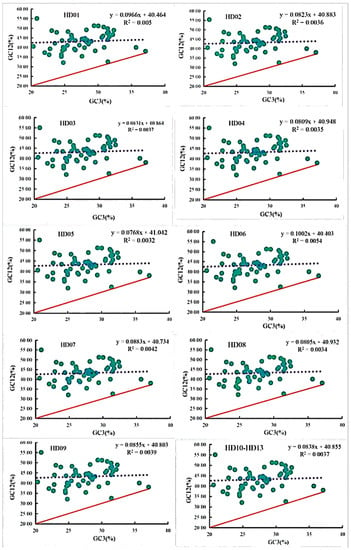
Figure 3.
Neutrality plot analysis of codons in the chloroplast genomes of oil-tea camellia.
3.4. ENP Plot Analysis of Oil-Tea Camellia cpDNA
The results of ENP plot analysis of all cpDNA samples are shown in Figure 4. The diagrams of all samples were highly similar to each other, and the majority of the points were distributed in the lower part of the standard curve, which showed the genetic conservation of all cpDNA samples. Two genes, clpP and ycf3, were almost distributed on the standard curve. Additionally, a few genes, including ndhK, rps11, rps3 and rps7, were extremely close to the standard curve. Therefore, the SCU bias of these 6 genes was mainly influenced by mutation pressure. However, the majority of the points were distributed far away from the standard curve, and the genes atpF, rps14, rps18 and ycf2 were located the farthest from the standard curve, indicating that their SCU bias was mainly influenced by selection pressure. In summary, the SCU bias of oil-tea camellia cpDNAs was mainly influenced by selection pressure, while that of some genes was influenced by mutation pressure.
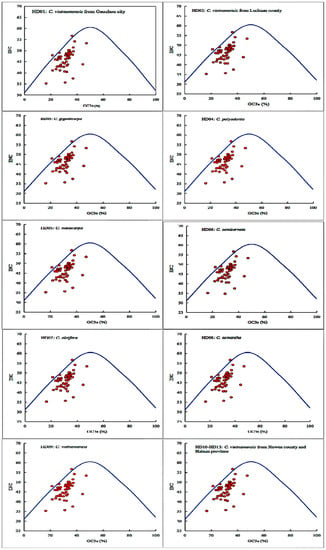
Figure 4.
ENC plot analysis of codons in the chloroplast genomes of oil-tea camellia.
The ENPexp values and the ratio of ENPexp to ENCcobs of the 53 CDSs of all samples are shown in Table 4, and the ratios showed the same distribution. The frequency of the ratios was clustered in the same frequency distribution chart shown in Table 5, reflecting the genetic conservation of all cpDNA samples. These results were consistent with the results shown in Figure 4. The ratio ranged from −0.051 to 0.051, and the number of genes displayed in Table 5 was 7, accounting for 13.21% of the 53 CDSs. Furthermore, the ratios of genes such as clpP, ndhC, clpP and ycf3 were almost 0, indicating that the SCU bias of these genes was mainly influenced by mutation pressure, and that of the 4 genes mentioned above was influenced almost exclusively by mutation pressure. As shown in Table 5, the SCU bias of the other 46 genes was influenced more by selection pressure, with the absolute values of the ENC ratios increasing. The ENC ratios of the atpF, rps14 and rps18 genes were the highest among all CDSs, indicating that their SCU bias was mainly influenced by selection pressure. In summary, the SCU bias of all 13 samples and their impact factors were generally consistent, which reflected the genetic conservation of Camellia plants, and the SCU bias of all samples was mainly influenced by selection pressure. However, the influences of mutation pressure cannot be ignored.
Table 4.
ENCexp value and ENCratio of the chloroplast genome of oil-tea camellia.
Table 5.
Frequency distribution of the ENCratio of the chloroplast genome of oil-tea camellia.
3.5. PR2 Plot Analysis of Oil-Tea Camellia cpDNA
The results of the PR2 plot analysis of all sample codons are shown in Figure 5. The diagrams of all samples were highly similar to each other. The minority of the points drifted slightly, and the third codon position of the genes ndhH, ndhK, rpl2 and rpl14 showed nearly equal use of all 4 bases, while that of the genes atpF, ccsA, ndhA, ndhB, ndhD, rpl20, rpoA, rpoB, rpoC1, rpoC2, rps4, rps11, rps12 and ycf3 used A and T evenly and that of the genes atpA, atpB, petB, petD, psbB, rpl14, ycf1 and ycf4 used G and C evenly. That of the other genes showed uneven use of the 4 bases, reflecting the genetic conservation of cpDNAs for all samples. The points of all 53 CDSs were distributed in the lower right, lower left, upper left and upper right in descending order, which indicated that the third position used A less than T and C less than G, and the difference between A and T was larger than that between G and C. In general, the SCU bias of all samples was mainly influenced by selection pressure, while the influences of mutation pressure could not be ignored.
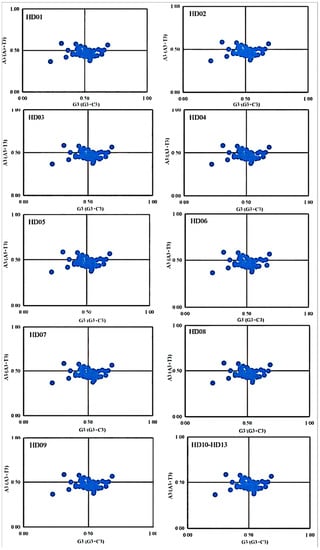
Figure 5.
PR2-plot analysis of codons in the cpDNA of oil-tea camellia.
3.6. Analysis of Optimal Codons in Oil-Tea Camellia cpDNAs
High-expression codons were screened in all samples, and some codons from high- and low-expression gene groups in the cpDNAs of the samples of C. gauchowensis, C. vietnamensis and the undetermined species from Hainan province (HD01, HD02 and HD09~HD13) showed the same ΔRSCU. A few of the other samples showed less different ΔRSCU values. The details of the results are shown in Table 6.
Table 6.
Preponderant codon analysis of the chloroplast genome of oil-tea camellia.
The codons with a ΔRSCU ≥ 0.08 could be regarded as high-expression codons. The 28 high-expression codons with the symbol * in Table 6 were screened, and U, A, C and G were the third bases in 11, 9, 7 and 1, respectively. Therefore, the third position of the cpDNA codons showed a preference for A or T. Meanwhile, the SCU bias of cpDNAs appeared to be genetically conserved among the different species of Camellia.
The codons found in both the high-expression and high-frequency groups mentioned above included 20 optimal codons. The optimal codons were as follows: codons of Ala including GCU and GCA, codons of Arg including CGA and CGU, the codon of Cys UGU, the codon of Glu GAA, the codon of Gly GGU, the codon of Ile AUU, codons of Leu including UUA, CUU, and UUG, the codon of Lys AAA, the codon of Pro CCU, codons of Ser including UCU and AGU, the codon of Thr ACU, codons of Val including GUA and GUU, and the termination codon UAA. The third base was U, A, C and G in 11, 8, 0 and 1 of these optimal codons, respectively, yet the codons whose third bases were C were not optimal, which indicated that the third position of the optimal codons in the cpDNAs of all samples showed a strong preference for A or T.
3.7. Phylogenetic Analysis
A phylogenetic tree was constructed with 10 samples based on the RSCU values and the results are shown in Figure 6. Ten samples clustered into 6 clades (r2 = 0.9196, d = 0.5395). The relationship between C. vietnamensis (HD09) and C. gauchowensis from Gaozhou city (HD01) was closer than that between C. gauchowensis from Gaozhou city (HD01) and C. gauchowensis from Luchuan county or Xuwen county (HD02 or HD10), and the relationships between C. osmantha (HD08) and C. gauchowensis from Gaozhou city (HD01) or Xuwen county (HD10), C. vietnamensis (HD09) and the undetermined species from Hainan province (HD10) were closer than that between C. osmantha (HD08) and C. gauchowensis from Luchuan (HD02). Therefore, these 5 samples were grouped into the same clade. The other samples were separated into independent clades. The relationship with C. oleifera (HD07) was progressively weaker for C. polyodonta (HD04), C. meiocarpa (HD05), C. semiserrata (HD06) and other taxa, such as C. gauchowensis, C. vietnamensis, C. osmantha and undetermined species from Hainan province (HD01, HD02, HD08, HD09 and HD10), and the relationship with C. gigantocarpa (HD03) was the most distant.
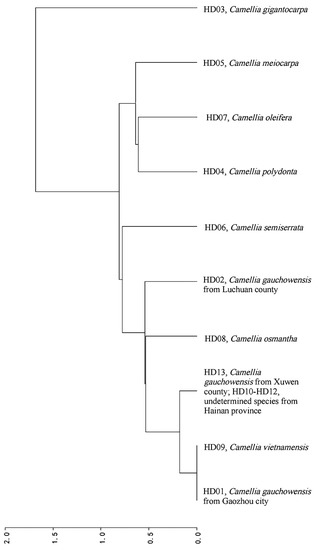
Figure 6.
Cluster analysis based on the RSCU of the different samples.
Hartia laotica was taken as the outgroup, and cpDNAs of all samples and the other 7 Camellia species were used to generate a phylogeny using the Bayesian method (BI) based on the CDSs. The results are shown in Figure 7. The tree divided all samples and the sequences from the NCBI into 2 clades: one included 2 subclades, and the other included 5 subclades. The subclade of C. granthamiana included samples of C. vietnamensis (HD09), C. gauchowensis (HD01, HD02 and HD13), undetermined species from Hainan province (HD10~HD12), C. osmantha (HD08) and C. granthamiana. The subclade of C. azalea included the samples of C. semiserrata (HD06) and C. azalea. The sample of C. gigantocarpa (HD03) formed an independent subclade. The subclade of C. japonica or C. chekiangoleosa included the samples of C. polyodonta (HD04), C. japonica and C. chekiangoleosa. The subclade of C. oleifera included the samples of C. oleifera (HD07) and C. japonica (the serial number in the NCBI database differed from the one in the above subclade). The subclade of C. sasanqua included the samples of C. sasanqua and C. meiocarpa (HD05). C. crapnelliana was an independent subclade.
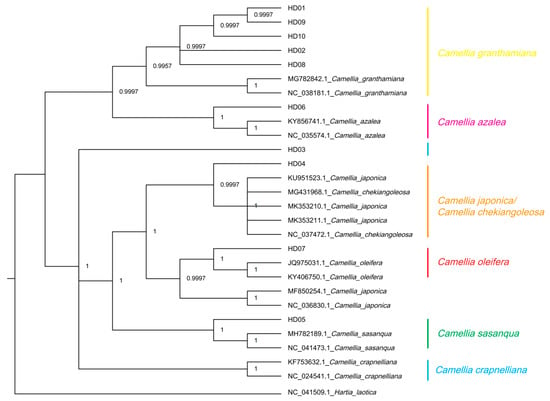
Figure 7.
Phylogenetic tree of 13 samples based on CDS using the MrBayes method (BI).
Figure 6 and Figure 7 show similar relationships among the 13 samples. Notably, for the samples of C. gauchowensis and C. vietnamensis, the cluster nodes of the population of C. gauchowensis from Gaozhou (HD01) and C. vietnamensis (HD09) were located at the outermost position, followed by the cluster nodes of these two and the samples of the undetermined species from Hainan province (HD10~HD12) or the population of C. gauchowensis from Xuwen (HD13). Finally, the next node included the samples of the population of C. gauchowensis from Luchuan (HD02) and C. osmantha (HD08); thus, the phylogenetic relationship among C. vietnamensis, C. gauchowensis and the undetermined species from Hainan province was closer than that between the populations of C. gauchowensis from Gaozhou and Luchuan, meaning that C. vietnamensis, C. gauchowensis and the undetermined species from Hainan province could be merged into the same species, with C. osmantha much closer to them. In summary, because SCU bias varied among the species, this metric can be used to identify the plant species and infer their genetic relationships.
4. Discussion
4.1. The Important Findings of This Paper
In this study, the third position of the codons of oil-tea camellia cpDNAs differed from the first two positions, and they showed a preference for base A or T. This result drove the detected SCU bias, which was influenced by the integrated influences of selection and mutation pressures, especially selection pressure. The third position of high-frequency codons showed an incomplete preference for A or U and occasionally showed a G or C. Similar results were reported in different plants in previous studies, indicating that the cpDNAs were highly genetically conserved and followed similar rules [30,31,32].
In this study, different species of Camellia were used, but the data for the species were highly similar, and the characteristics of SCU bias were consistent. The genes whose high-frequency codons, high-expression codons, optimal codons and SCU bias were mainly influenced by selection pressure were also consistent with each other, indicating that the SCU bias of the different species of Camellia was highly genetically conserved. This finding was consistent with a previous report that the cpDNAs of different oil-tea camellia species exhibited good collinearity [19].
Our research group reported that the exons of oil-tea camellia cpDNAs contained some phylogenetic divergence hotspots [19], and the variance in these CDSs was due to SNP site mutations. Meanwhile, SNP mutations at the third position were often synonymous, leading to SCU bias [33,34]. Thus, SCU bias may be used for the evolutionary analysis of species. In fact, the results of evolutionary analysis based on SCU bias and CDSs were consistent with one another, and two similar phylogenetic trees were constructed with 10 samples based on RSCU values and CDSs in this study. These results were consistent with a phylogenetic tree based on the full cpDNAs whose results were related to the samples described in this paper [19]. The relationships between C. gauchowensis, C. vietnamensis, the undetermined species from Hainan province and C. osmantha were consistent with one another and suggested the merging of C. vietnamensis and C. gauchowensis into one species. The undetermined species from Hainan province were C. vietnamensis, but determining whether C. osmantha is an independent species requires further genetic evidence. That C. gigantocarpa was separated into an independent clade was also consistent. Therefore, all results related to SCU bias, CDSs and full cpDNAs could be used to distinguish the species and could reveal the genetic relationships among the different species of oil-tea camellia.
4.2. Comparison with Previous Similar Reports
Previous studies revealed that C. oleifera cpDNA had 18 optimal codons [12], which was inconsistent with the findings presented in this paper. Moreover, because 17 optimal codons were consistent with each other, 3 optimal codons (UUA, CGA and UCU) were screened, and the optimal codon GAC was not observed. The reasons for the differences may be a discrepancy in the defined high- and low-expression gene groups or errors in cpDNA sequencing. This problem should be addressed in further studies to facilitate research on cpDNA gene expression [35,36,37] and the development of cpDNA genetic engineering [7,36,38].
In this study, the association between SCU bias and specific genes was determined through detailed analysis of a large quantity of data, and then the codon composition and SCU bias of the specific genes were confirmed, distinguishing our study from previous studies that generally ignored specific genes [12,39,40,41]. The patterns of some specific genes’ codon compositions were revealed, and the determinants of the SCU bias of some specific genes were confirmed.
4.3. The Value of the SCU Analysis in This Paper
The SCU bias of some specific genes was revealed in this paper, which will support further studies on the regulation of oil-tea camellia cpDNA gene expression [35,37] and the development of oil-tea camellia cpDNA genetic engineering [7,38].
SCU bias could be used to distinguish the species and could reveal the genetic relationships among the different species of oil-tea camellia in this study, indicating that SCU bias reflects species specificity [17,42,43] and could be used to construct a technological system for identifying oil-tea camellia germplasm species.
5. Conclusions
Even base composition was observed for very few genes in oil-tea camellia cpDNAs; instead, the codons of the vast majority of the genes showed a preference for A or T, the third position showed a strong preference for A or T, and the base at the third position determined SCU bias. The SCU bias of oil-tea camellia is weak, and it is influenced by selection pressure; meanwhile, the influences of mutation pressure cannot be ignored because 37.74% of all codons showed SCU bias influenced by mutation pressure. Among the oil-tea camellia cpDNAs, 30 high-frequency codons, 28 high-expression codons and 20 optimal codons were screened, and the third base of the codons showed a significant or strong preference for A or U. The characteristics of the codon composition and SCU bias of oil-tea camellia cpDNAs were confirmed, which can support studies of the regulation of oil-tea camellia cpDNA gene expression and the development of oil-tea cpDNA genetic engineering. As the SCU bias of oil-tea camellia cpDNAs is strongly genetically conserved but shows species specificity, the RSCU values of cpDNAs can be used for species identification of oil-tea camellia germplasm. The results suggest merging C. vietnamensis and C. gauchowensis into one species and that the undetermined species from Hainan province is C. vietnamensis. However, determining whether C. osmantha is an independent species requires further genetic evidence.
Author Contributions
Conceptualization, X.H. and K.Z.; methodology, K.Z. and W.M.; formal analysis, J.C.; investigation, J.C.; resources, J.C.; data curation, J.C. and W.M.; writing—original draft preparation, J.C.; writing—review and editing, X.H. and K.Z.; supervision, X.H. and K.Z.; project administration, X.H.; funding acquisition, X.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Key R&D Program of Hainan Province, China (ZDYF2022SHFZ020).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Liu, H.M.; Wuyun, T.N.; Du, H.Y. Analysis of characteristic of codon usage in Ref gene of Eucommia ulmoides. J. Cent. South Univ. For. Technol. 2016, 36, 8–12. (In Chinese) [Google Scholar]
- Hu, S.S.; Luo, H.; Wu, Q.; Yao, H.P. Analysis of codon bias of chloroplast genome of tartary buckwheat. Mol. Plant Breed. 2016, 14, 309–317. (In Chinese) [Google Scholar]
- Botzman, M.; Margalit, H. Variation in global Codon usage bias among prokaryotic organisms is associated with their lifestyles. Genome Biol. 2011, 12, R109. [Google Scholar] [CrossRef] [PubMed]
- Tang, X.F.; Chen, L.; Ma, Y.T. Review and Prospect of the Principle and Methods Quantifying Codon Usage Bias. Genom. Appl. Biol. 2013, 32, 660–666. (In Chinese) [Google Scholar]
- Wu, Z.J.; Zhong, J.C. Synonymous codons usage bias and its application. Biol. Bull. 2012, 47, 9–11. (In Chinese) [Google Scholar]
- Quax, T.; Claassens, N.; Söll, D.; John, V. Codon bias as a means to fine-tune gene expression. Mol. Cell 2015, 59, 149–161. [Google Scholar] [CrossRef]
- Danell, H.; Chase, C. Molecular Biology and Biotechnology of Plant Organelles; Springer: Dordrecht, The Netherlands, 2004. [Google Scholar]
- Azim, M.K.; Khan, I.A.; Zhang, Y. Characterization of mango (Mangifera indica L.) transcriptome and chloroplast genome. Plant Mol. Biol. 2014, 85, 193–208. [Google Scholar] [CrossRef]
- Suparman, S.; Pancoro, A.; Hidayat, T. Phylogenetic analysis of Mangifera based on rbcL sequences, chloroplast DNA. Sci. Pap. Ser. B Hortic. 2013, 57, 235–240. [Google Scholar]
- Xu, C.; Ben, A.L.; Cai, X.N. Analysis of synonymous codon usage in chloroplast genome of Phalaenopsis aphrodite sub sp. formosana. Mol. Plant Breed. 2010, 8, 945–950. (In Chinese) [Google Scholar]
- Shang, M.Z.; Liu, F.; Hua, J.P.; Wang, K.B. Analysis on codon usage of chloroplast genome of Gossypium hirsutum. Sci. Agric. Sin. 2011, 44, 245–253. (In Chinese) [Google Scholar]
- Wang, P.L.; Yang, L.P.; Wu, H.Y.; Long, Y.L.; Wu, S.C.; Xiao, Y.F.; Qin, Z.H.; Wang, H.Y.; Liu, H.L. Condon preference of chloroplast genome in Camellia oleifera. Guihaia 2018, 38, 135–144. (In Chinese) [Google Scholar]
- Li, J.P.; Qin, Z.; Guo, C.C.; Yang, G.Y.; Zhang, W.G. Codon bias in the chloroplast genome of Gelidocalamus tessellatus. J. Bamboo Res. 2019, 38, 79–87. (In Chinese) [Google Scholar]
- Lei, H.; Li, G.; Wang, N.Y. Analysis of codon usage bias in the chloroplast genome of Trollius chinensis Bunge. J. Shanxi Agric. Sci. 2019, 47, 1300–1305. (In Chinese) [Google Scholar]
- Chen, Y.Z. Excellent Germplasm Resources of Oil-Tea Camellia; Forestry Press: Beijing, China, 2008; p. 159. (In Chinese) [Google Scholar]
- Yao, X.H. Chinese Oil-Tea Camellia Cultivars; Forestry Press: Beijing, China, 2016; pp. 31–32. (In Chinese) [Google Scholar]
- Long, S.Y.; Yao, H.P.; Wu, Q.; Li, G.L. Analysis of compositional bias and codon usage pattern of the coding sequence in Banna virus genome. Virus Res. 2018, 258, 68–72. (In Chinese) [Google Scholar] [CrossRef] [PubMed]
- Zelasko, S.; Palaria, A.; Das, A. Optimizations to achieve high-level expression of cytochrome P450 proteins using Escherichia coli expression systems. Protein Expr. Purif. 2013, 92, 77–87. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Guo, Y.J.; Hu, X.W.; Zhou, K.B. Comparison of the Chloroplast Genome Sequences of 13 Oil-Tea Camellia Samples and Identification of an Undetermined Oil-Tea Camellia Species From Hainan Province. Front. Plant Sci. 2022, 12, 798581. [Google Scholar] [CrossRef]
- Wright, F. The ‘effective number of codons’ used in a gene. Gene 1990, 87, 23–29. [Google Scholar] [CrossRef]
- Liu, H.; Wang, M.X.; Yue, W.J.; Xing, G.W.; Ge, Q.L.; Nie, X.J.; Song, W.N. Analysis of codon usage in the chloroplast genome of Broomcorn millet (Panicum miliaceum L.). Plant Sci. J. 2017, 35, 362–371. (In Chinese) [Google Scholar]
- Liu, Y.J.; Tian, X.P.; Li, Q. Analysis of aynonymous codon usage bias of Fraxinus pennsylvanica cpDNA. Jiangsu Agric. Sci. 2020, 48, 83–88. (In Chinese) [Google Scholar]
- Liang, H.H.; Fu, H.Y.; Li, Z.P.; Li, Y.C. Analysis on codon usage bias of chloroplast genome from chlorella. Mol. Plant Breed. 2020, 18, 5665–5673. (In Chinese) [Google Scholar]
- Yuan, X.L.; Li, Y.Q.; Zhang, J.F.; Wang, Y. Analysis of codon usage bias in the chloroplast genome of Dalbergia odorifera. Guihaia 2021, 41, 622–630. (In Chinese) [Google Scholar]
- Shen, Z.N.; Gan, Z.M.; Zhang, F.; Yi, X.Y.; Zhang, J.Z.; Wan, X.H. Analysis of codon usage patterns in citrus based on coding sequence data. BMC Genom. 2020, 21, 234. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Liu, Z.; Yang, P.D.; Chen, Y.; Yang, Y. Codon bias analysis method and research progress on codon bias in Camellia sinensis. J. Tea Commun. 2016, 43, 3–7. (In Chinese) [Google Scholar]
- Sueoka, N. Translation-coupled violation of Parity Rule 2 in human genes is not the cause of heterogeneity of the DNA G + C content of third codon position. Gene 1999, 238, 53–58. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.; Deng, L.H.; Chen, F. Codon usage bias of chloroplast genome in Kandelia obovata. J. For. Environ. 2020, 40, 534–541. (In Chinese) [Google Scholar]
- Wu, X.M.; Wu, S.F.; Ren, D.M.; Zhu, Y.P.; He, F.C. The analysis method and progress in the study of codon bias. Hereditas 2007, 29, 420–426. (In Chinese) [Google Scholar] [CrossRef]
- Zhou, M.; Long, W.; Li, X. Analysis of synonymous codon usage in chloroplast genome of Populus alba. J. For. Res. 2008, 19, 293–297. [Google Scholar] [CrossRef]
- Morton, B.R. Selection on the codon bias of chloroplast and cyanelle genes in different plant and algal lineages. J. Mol. Evol. 1998, 46, 449–459. [Google Scholar] [CrossRef]
- Novembre, J.A. Accounting for background nucleotide composition when measuring codon usage bias. Mol. Biol. Evol. 2002, 19, 1390–1394. [Google Scholar] [CrossRef]
- Hu, X.Y.; Xu, Y.Q.; Han, Y.Z.; Du, S.H. Codon usage bias analysis of the chloroplast genome of Ziziphus jujuba var spinosa. J. For. Environ. 2019, 39, 621–628. (In Chinese) [Google Scholar]
- Zhao, C.L.; Peng, L.Y.; Wang, X.; Chen, J.L.; Wang, L.; Chen, H.; Lai, Z.X.; Liu, S.C. Codon bias and evolution analysis of AtGAI in Amaranthus tricolor L. J. China Agric. Univ. 2019, 24, 10–22. (In Chinese) [Google Scholar]
- Zhou, Z.; Dang, Y.; Zhou, M.; Li, L.; Yu, C.H.; Fu, J.J.; Chen, S.; Liu, Y. Codon usage is an important determinant of gene expression levels largely through its effects on transcription. Proc. Natl Acad. Sci. USA 2016, 113, E6117–E6125. [Google Scholar] [CrossRef]
- Wu, Y.Q.; Zhao, D.Q.; Tao, J. Analysis of codon usage patterns in herbaceous peony (Paeonia lactiflora Pall.) based on transcriptome data. Genes 2015, 6, 1125–1139. [Google Scholar] [CrossRef] [PubMed]
- Gu, W.J.; Zhou, T.; Ma, J.M.; Sun, X.; Lu, Z.H. Analysis of synonymous codon usage in SARS Coronavirus and other viruses in nidovirales. Virus Res. 2004, 101, 155–161. [Google Scholar] [CrossRef] [PubMed]
- Kwak, S.Y.; Lew, T.T.S.; Sweeney, C.J.; Koman, V.B.; Wong, M.H.; Bohmert-Tatarev, K.; Snell, K.D.; Seo, J.S.; Chua, N.H.; Strano, M.S. Chloroplast-selective gene delivery andexpression in planta using chitosan-complexed single-walled carbon nanotubecarriers. Nat. Nanotechnol. 2019, 14, 447–455. [Google Scholar] [CrossRef]
- Duan, H.R.; Zhang, Q.; Wang, C.M.; Li, F.; Tian, F.P.; Lu, Y.; Hu, Y.; Yang, H.S.; Cui, G.X. Analysis of codon usage patterns of the chloroplast genome in Delphinium grandiflorum L. reveals a preference for AT-ending codons as a result of major selection constraints. PeerJ 2021, 9, e10787. [Google Scholar] [CrossRef]
- Liu, H.; Lu, Y.; Lan, B.; Xu, J. Codon usage by chloroplast gene is bias in Hemiptelea davidii. J. Genet. 2020, 99, 8. [Google Scholar] [CrossRef]
- Tang, D.F.; Wei, F.; Cai, Z.Q.; Wei, Y.Y.; Khan, A.; Miao, J.H.; Wei, K.H. Analysis of codon usage bias and evolution in the chloroplast genome of Mesona chinensis Benth. Dev. Genes Evol. 2021, 231, 1–9. [Google Scholar] [CrossRef]
- Mo, R.; Ton, B.R. Strand asymmetry and codon usage bias in the chloroplast genome of Euglena gracilis. Proc. Nat. Acad. Sci. USA 1999, 96, 5123–5128. [Google Scholar]
- Liu, Q.; Xue, Q. Comparative studies on codon usage pattern of chloroplasts and their host nuclear genes in four plant species. J. Gene 2005, 84, 55–62. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).