
A Deep Learning Method for Log Diameter Measurement Using Wood Images Based on Yolov3 and DeepLabv3+

Abstract
:1. Introduction
2. Materials and Methods
2.1. Dataset
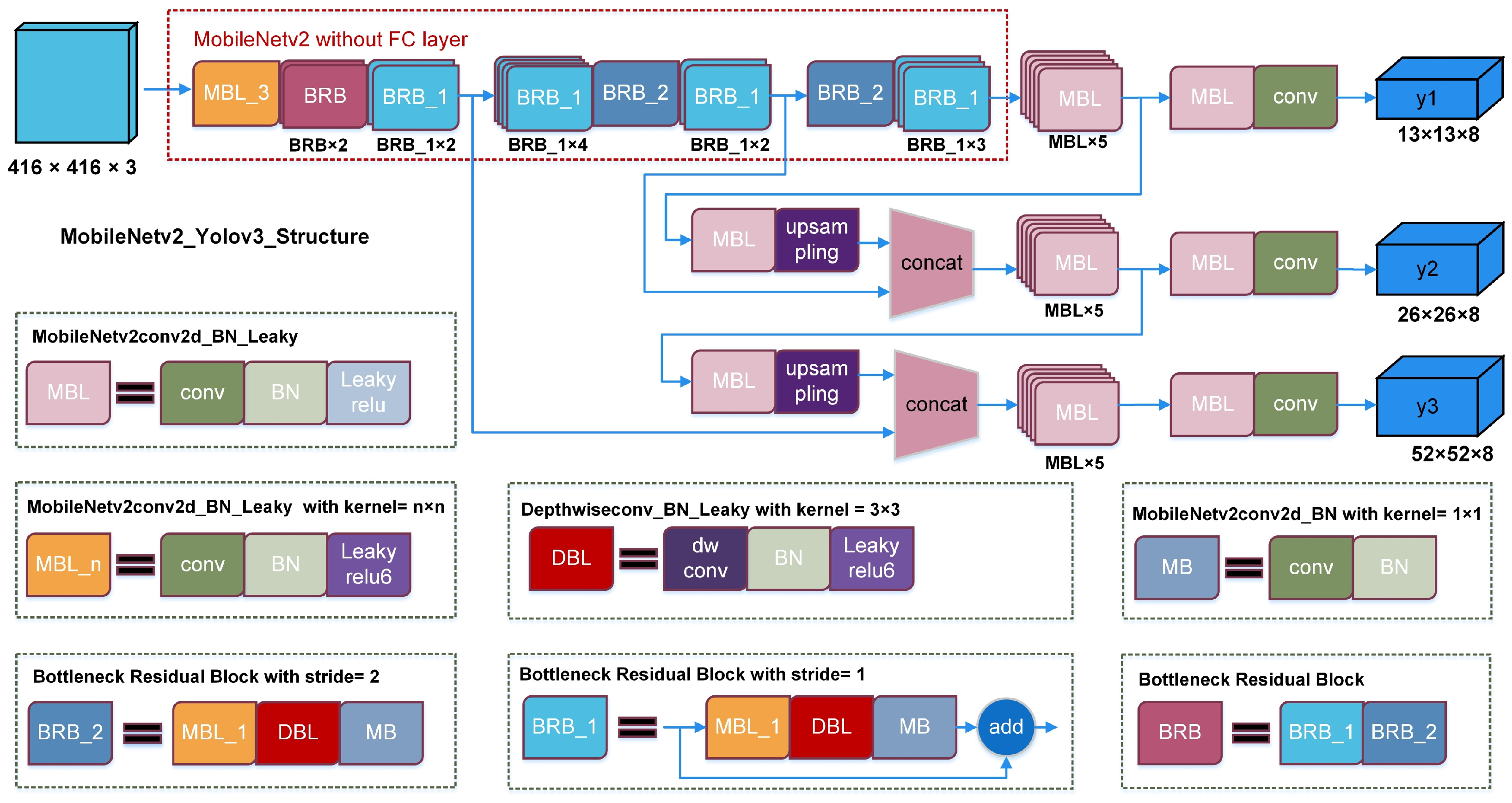
2.2. Backbone Feature Extraction Network
2.3. Experiment on the Best Shooting Angle
2.4. Evaluation Indicators
2.5. Training Environment
3. Results
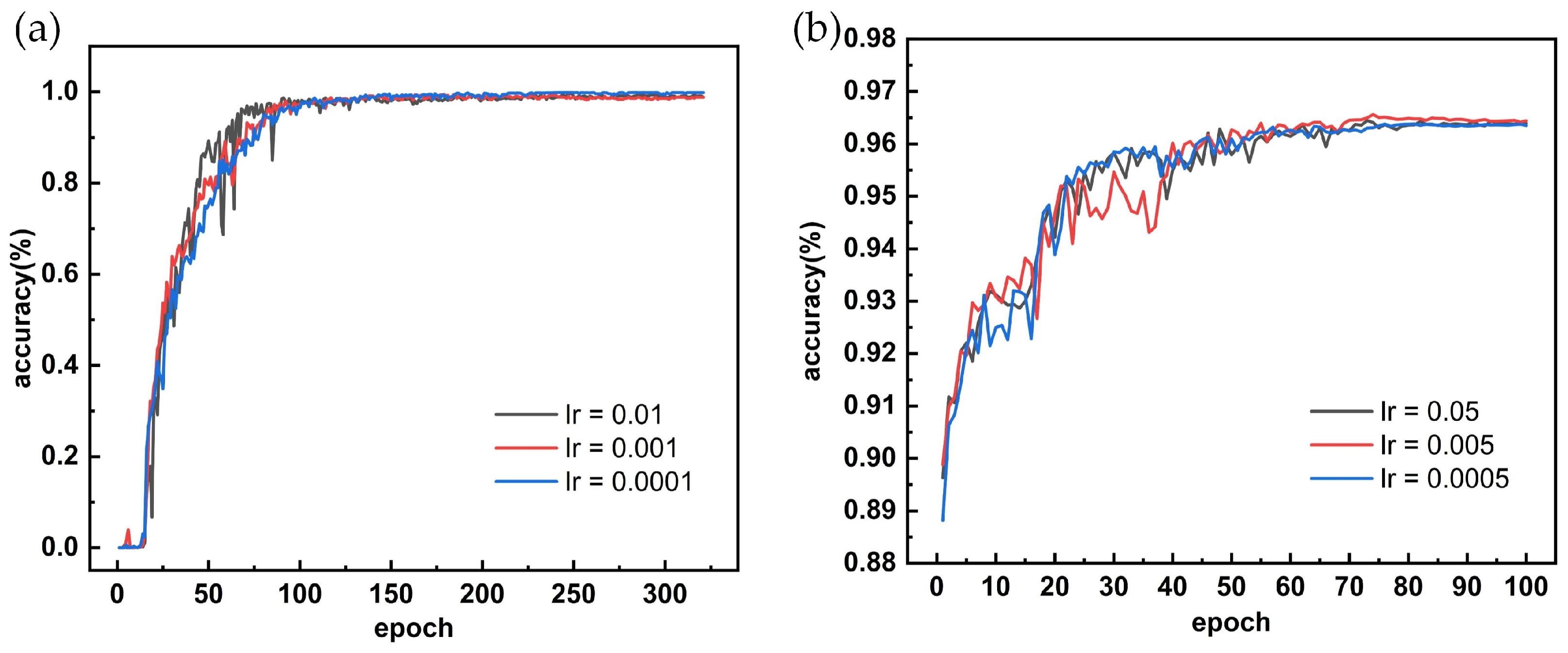
3.1. Results of Model Training
3.2. Results of Log-Diameter Measurement
4. Discussion
4.1. Comparison of Training Performance of Different Backbone Networks
4.2. Performance Comparison of Different Segmentation Methods
4.3. Advantage Analysis of Dual-Network Detection System
5. Conclusions
- The deformation of log images caused by shooting angles was reduced using AprilTags.
- The proposed method was trained and evaluated using a log dataset and tested in a forest.
- A comparative study was conducted to verify the segmentation advantages of the proposed method over other commonly used segmentation methods, namely K-means clustering and HSV threshold segmentation.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Moskalik, T.; Tymendorf, Ł.; van der Saar, J.; Trzciński, G. Methods of Wood Volume Determining and Its Implications for Forest Transport. Sensors 2022, 22, 6028. [Google Scholar] [CrossRef] [PubMed]
- Xin, Y.; Xue, W. Counting Arithmetic of Log Pile in a Log Yard Based on Digital Image Processing. For. Eng. 2008, 24, 25–27. [Google Scholar] [CrossRef]
- Marti, F.; Forkan, A.R.M.; Jayaraman, P.P.; McCarthy, C.; Ghaderi, H. LogLiDAR: An Internet of Things Solution for Counting and Scaling Logs. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events (PerCom Workshops), Kassel, Germany, 22–26 March 2021; pp. 413–415. [Google Scholar] [CrossRef]
- Raumonen, P.; Kaasalainen, M.; Åkerblom, M.; Kaasalainen, S.; Kaartinen, H.; Vastaranta, M.; Holopainen, M.; Disney, M.; Lewis, P. Fast Automatic Precision Tree Models from Terrestrial Laser Scanner Data. Remote Sens. 2013, 5, 491–520. [Google Scholar] [CrossRef]
- Panagiotidis, D.; Abdollahnejad, A. Reliable Estimates of Merchantable Timber Volume from Terrestrial Laser Scanning. Remote Sens. 2021, 13, 3610. [Google Scholar] [CrossRef]
- Panagiotidis, D.; Abdollahnejad, A.; Slavík, M. 3D point cloud fusion from UAV and TLS to assess temperate managed forest structures. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102917. [Google Scholar] [CrossRef]
- Chen, G.; Qiang, Z.; Chen, M.; Yin, H. Rapid detection algorithms for log diameter classes based on stereo vision. In Proceedings of the 4th International Conference on Systems and Informatics (ICSAI), Hangzhou, China, 11–13 November 2017. [Google Scholar]
- Jing, L.; Lin, Y.-H.; Wen, Y.-X.; Huang, S.-G.; Lin, Y.-K. Method for Outline Identification of Bundled Logs Based Upon Color and Spatial Features. Comput. Syst. Appl. 2013, 22, 191+196–199. [Google Scholar]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Smith, A.R. Color gamut transform pairs. ACM Siggraph Comput. Graph. 1978, 12, 12–19. [Google Scholar] [CrossRef]
- Zhong, X.-X.; Jing, L.; Lin, Y.-H.; Sun, L. Log Counting Method Combined with K-means Clustering and Hough Transform. J. Yibin Univ. 2016, 16, 40–43. [Google Scholar] [CrossRef]
- ISO/CIE 11664-4:2019; Colorimetry-Part 4: CIE 1976 L* a* b* Colour Space. ISO: Geneva, Switzerland, 2007.
- Pelleg, D.; Moore, A. Accelerating exact k-means algorithms with geometric reasoning. In Proceedings of the 5th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 277–281. [Google Scholar] [CrossRef]
- Ballard, D.H. Generalizing the Hough transform to detect arbitrary shapes. Pattern Recognit. 1981, 13, 111–122. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 algorithm with pre-and post-processing for apple detection in fruit-harvesting robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Cai, M.; Yi, X.; Wang, G.; Mo, L.; Wu, P.; Mwanza, C.; Kapula, K.E. Image Segmentation Method for Sweetgum Leaf Spots Based on an Improved DeeplabV3+ Network. Forests 2022, 13, 2095. [Google Scholar] [CrossRef]
- Zhu, S.; Ma, W.; Lu, J.; Ren, B.; Wang, C.; Wang, J. A novel approach for apple leaf disease image segmentation in complex scenes based on two-stage DeepLabv3+ with adaptive loss. Comput. Electron. Agric. 2023, 204, 107539. [Google Scholar] [CrossRef]
- Samdangdech, N.; Phiphobmongkol, S. Log-end cut-area detection in images taken from rear end of eucalyptus timber trucks. In Proceedings of the 15th International Joint Conference on Computer Science and Software Engineering (JCSSE), Nakhonpathom, Thailand, 11–13 July 2018; pp. 1–6. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Lin, Y.-h.; Zhao, H.-l.; Yang, Z.-c.; Lin, M.-t. An equal length log volume inspection system using deep-learning and Hough transformation. J. For. Eng. 2021, 1, 136–142. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, Y.; Cai, R.; Lin, P.; Cheng, S. A detection approach for bundled log ends using K-median clustering and improved YOLOv4-Tiny network. Comput. Electron. Agric. 2022, 194, 106700. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Olson, E. AprilTag: A robust and flexible visual fiducial system. In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3400–3407. [Google Scholar]
- Zhang, Z. Flexible camera calibration by viewing a plane from unknown orientations. In Proceedings of the 7th IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 666–673. [Google Scholar]
- Slabaugh, G.G. Computing Euler angles from a rotation matrix. Retrieved August 1999, 6, 39–63. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | Yolov3 | DeepLabv3+ | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | mAP | Precision | Recall | mIoU | |
| MobleNetv2 | 98.52% | 98.34% | 97.28% | 97.28% | 95.84% | 92.22% |
| Rank of Log Size (cm) | 6 | 8 | 10 | 12 | 14 | 16 | 18 | 20 | Log Volume (m3) | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Log Length 2.2 m | Number of logs | forest farm | 84 | 153 | 162 | 136 | 77 | 37 | 9 | 1 | 16.356 |
| image | 60 | 142 | 163 | 160 | 66 | 34 | 12 | 4 | 16.558 | ||
| Error of log volume | 1.2% | ||||||||||
| Log Number | Actual Diameters [3] | Model Measure Diameters [3] | Error (%) |
|---|---|---|---|
| 1 | 91 | 97 | 6.06 |
| 2 | 81 | 85 | 5.49 |
| 3 | 92 | 90 | −1.97 |
| 4 | 88 | 84 | −4.70 |
| 5 | 96 | 97 | 0.54 |
| 6 | 79 | 85 | 8.16 |
| 7 | 127 | 131 | 3.41 |
| 8 | 98 | 95 | −3.13 |
| 9 | 98 | 95 | −3.13 |
| 10 | 100 | 101 | 1.27 |
| 11 | 106 | 111 | 4.49 |
| 12 | 101 | 104 | 3.40 |
| 13 | 108 | 111 | 2.56 |
| 14 | 106 | 106 | 0.01 |
| 15 | 109 | 114 | 4.52 |
| 16 | 109 | 108 | −1.29 |
| 17 | 142 | 138 | −3.06 |
| 18 | 204 | 204 | 0.06 |
| 19 | 121 | 122 | 0.69 |
| 20 | 124 | 128 | 3.36 |
| 21 | 151 | 141 | −6.74 |
| 22 | 145 | 139 | −3.97 |
| Comprehensive average error (%) | 0.73% | ||
| Model | Backbone | Precision | Recall | mAP | Number of Parameters | Training Time |
|---|---|---|---|---|---|---|
| Yolov3 | Darknet53 | 98.91% | 98.37% | 98.34% | 61.52 MB | 73 min |
| MobileNetv2 | 98.35% | 98.34% | 97.28% | 22.25 MB | 67 min |
| Model | Backbone | Precision | Recall | mIoU | Number of Parameters | Training Time |
|---|---|---|---|---|---|---|
| Deeplabv3+ | Xception | 96.34% | 95.98% | 92.61% | 54.71 MB | 178 min |
| MobileNetv2 | 96.05% | 95.84% | 92.22% | 5.81 MB | 55 min |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Z.; Yao, H.; Lyu, Y.; He, S.; Ning, H.; Yu, Y.; Zhai, L.; Zhou, L. A Deep Learning Method for Log Diameter Measurement Using Wood Images Based on Yolov3 and DeepLabv3+. Forests 2024, 15, 755. https://doi.org/10.3390/f15050755
Lu Z, Yao H, Lyu Y, He S, Ning H, Yu Y, Zhai L, Zhou L. A Deep Learning Method for Log Diameter Measurement Using Wood Images Based on Yolov3 and DeepLabv3+. Forests. 2024; 15(5):755. https://doi.org/10.3390/f15050755
Chicago/Turabian StyleLu, Zhenglan, Huilu Yao, Yubiao Lyu, Sheng He, Heng Ning, Yuhui Yu, Lixia Zhai, and Lin Zhou. 2024. "A Deep Learning Method for Log Diameter Measurement Using Wood Images Based on Yolov3 and DeepLabv3+" Forests 15, no. 5: 755. https://doi.org/10.3390/f15050755