
Using a Logistic Regression Model to Examine the Variables Influencing Changes in Northern Thailand’s Forest Cover and Comparing Machine Learning Algorithms
 ,
,
Abstract
:1. Introduction
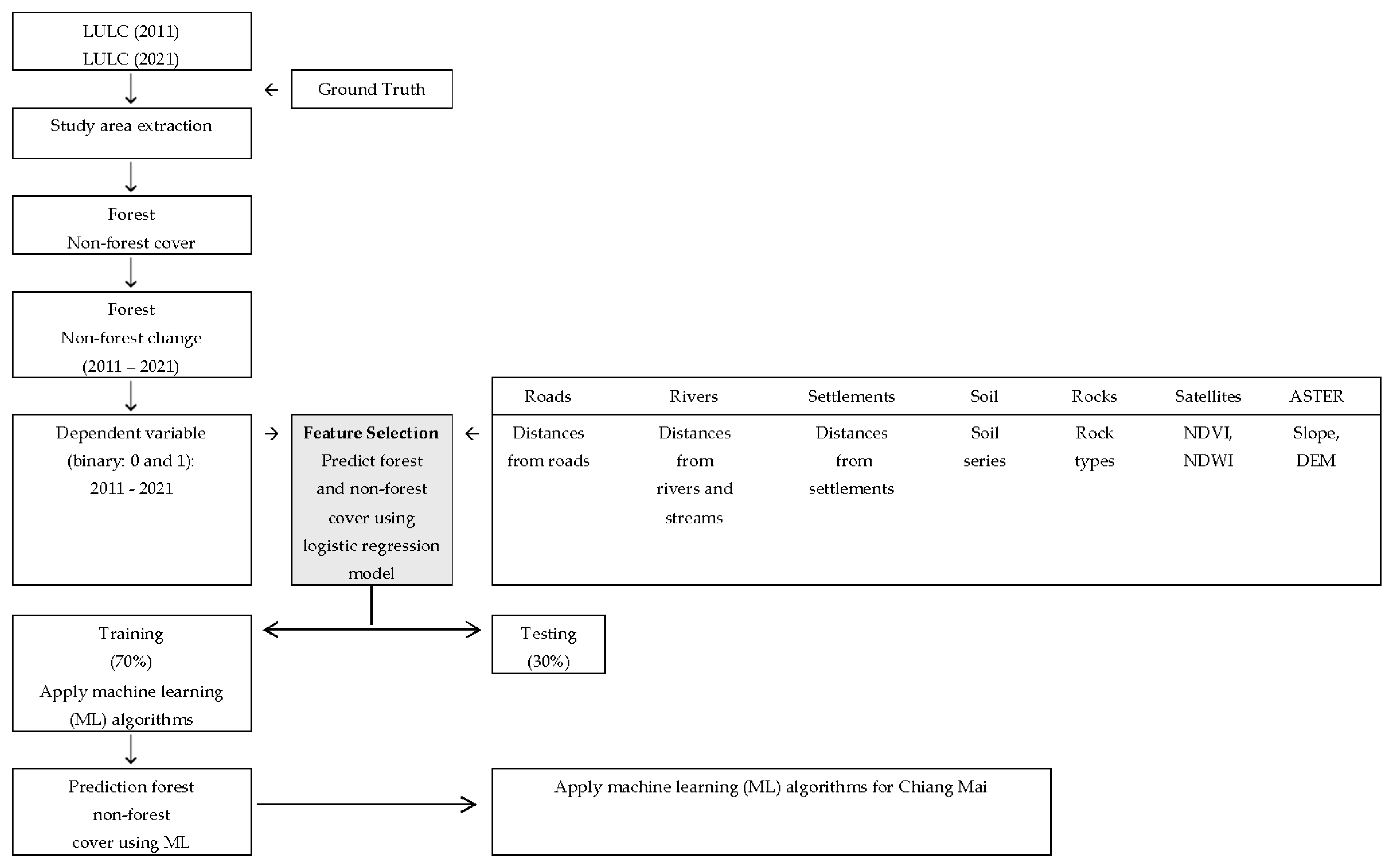
2. Materials and Methods
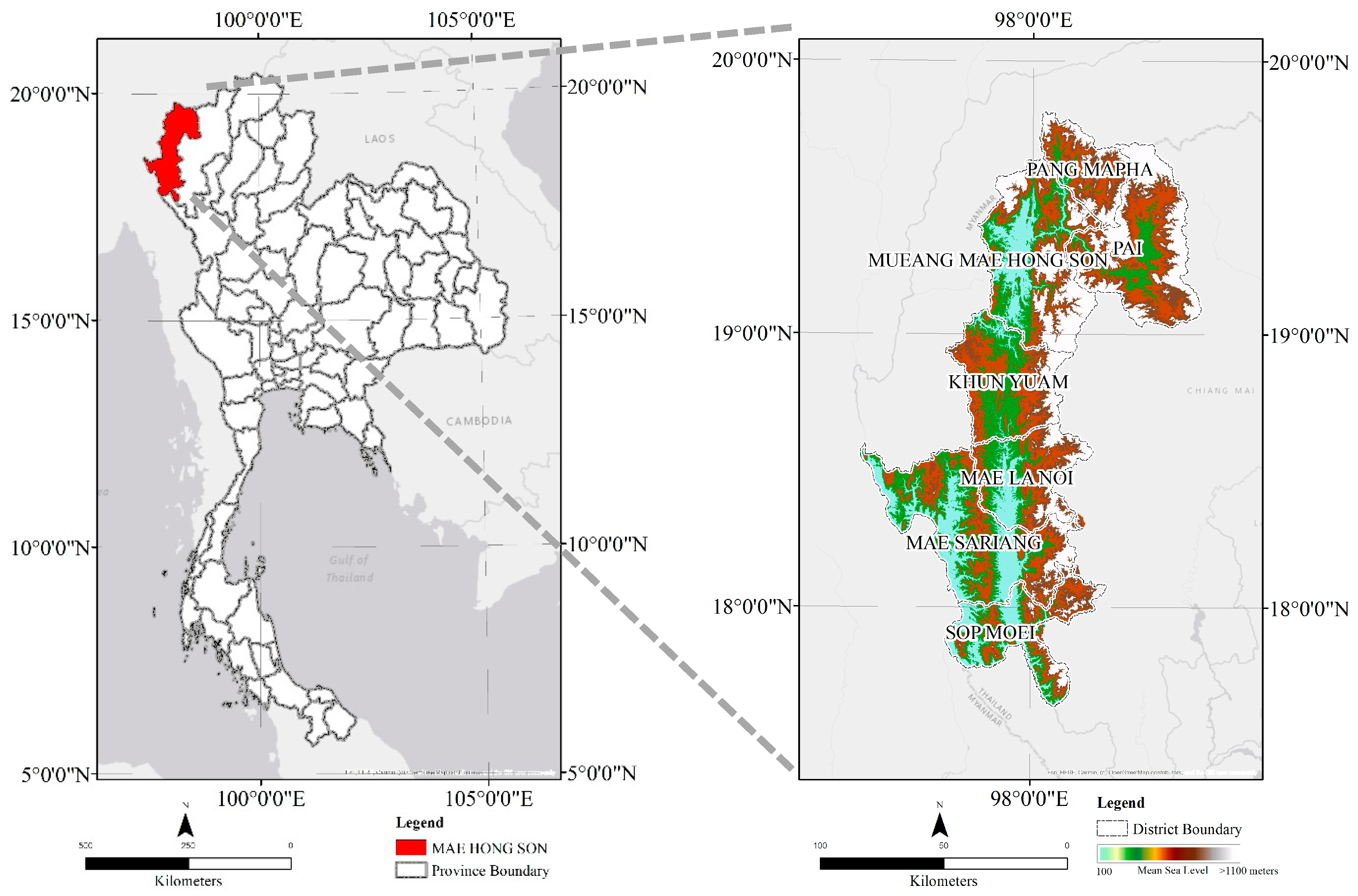
2.1. Study Area
2.2. Change Detection Analysis
2.3. Forest Cover Change Variable
2.4. Explanatory Variables of Forest Cover Change
2.5. Model Calibration and Classification of Forest Cover Change
2.5.1. Logistic Regression Model (LRM)
2.5.2. Random Forest (RF)
2.5.3. Support Vector Machine (SVM)
2.6. Measuring and Verifying Classification Accuracy
- True Positive (TP): the model predicts change, and the ground truth is change.
- True Negative (TN): the model predicts no change, and the ground truth is no change.
- False Positive (FP): the model predicts change, but the ground truth is no change.
- False Negative (FN): the model predicts no change, but the ground truth is change.
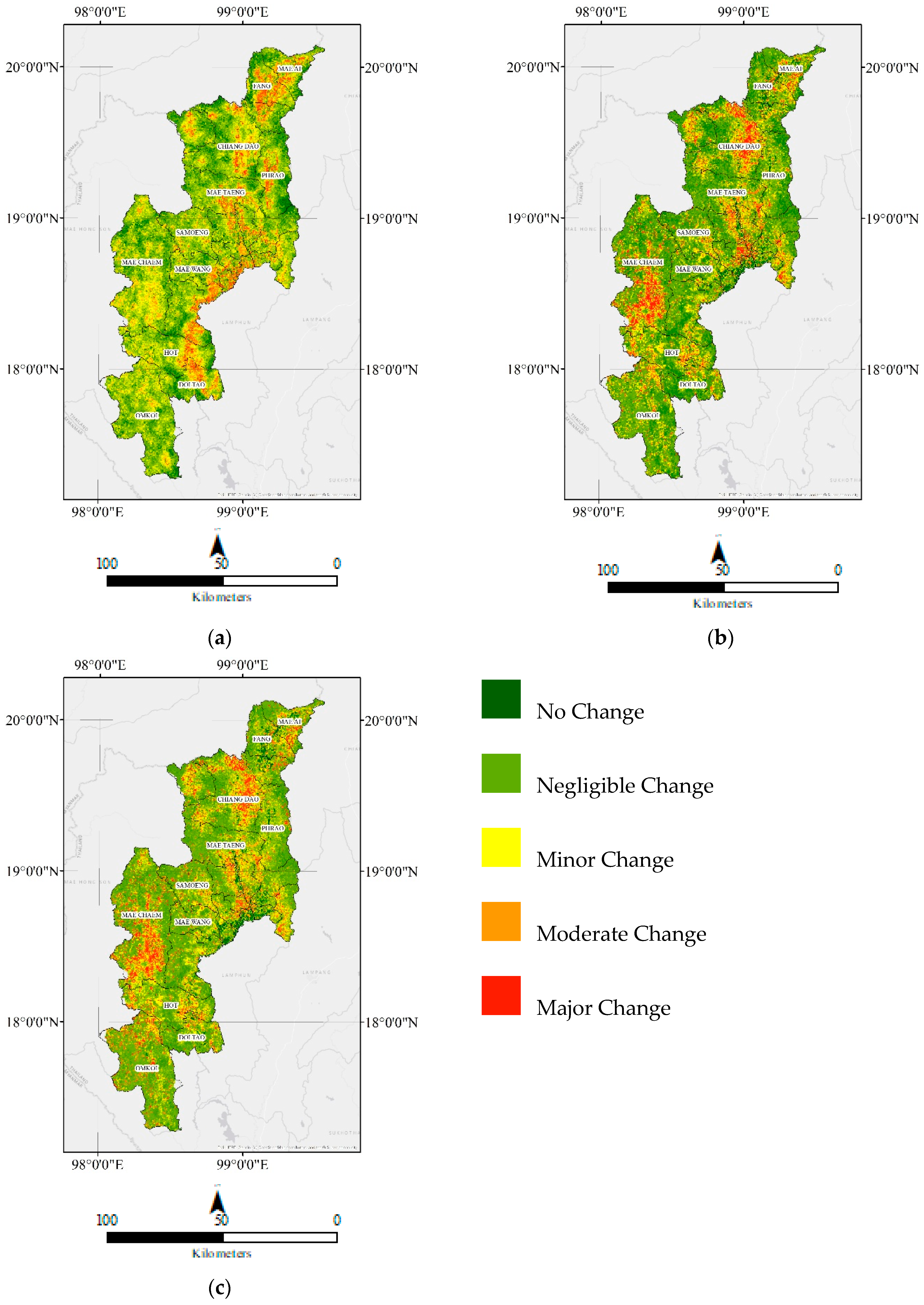
3. Results
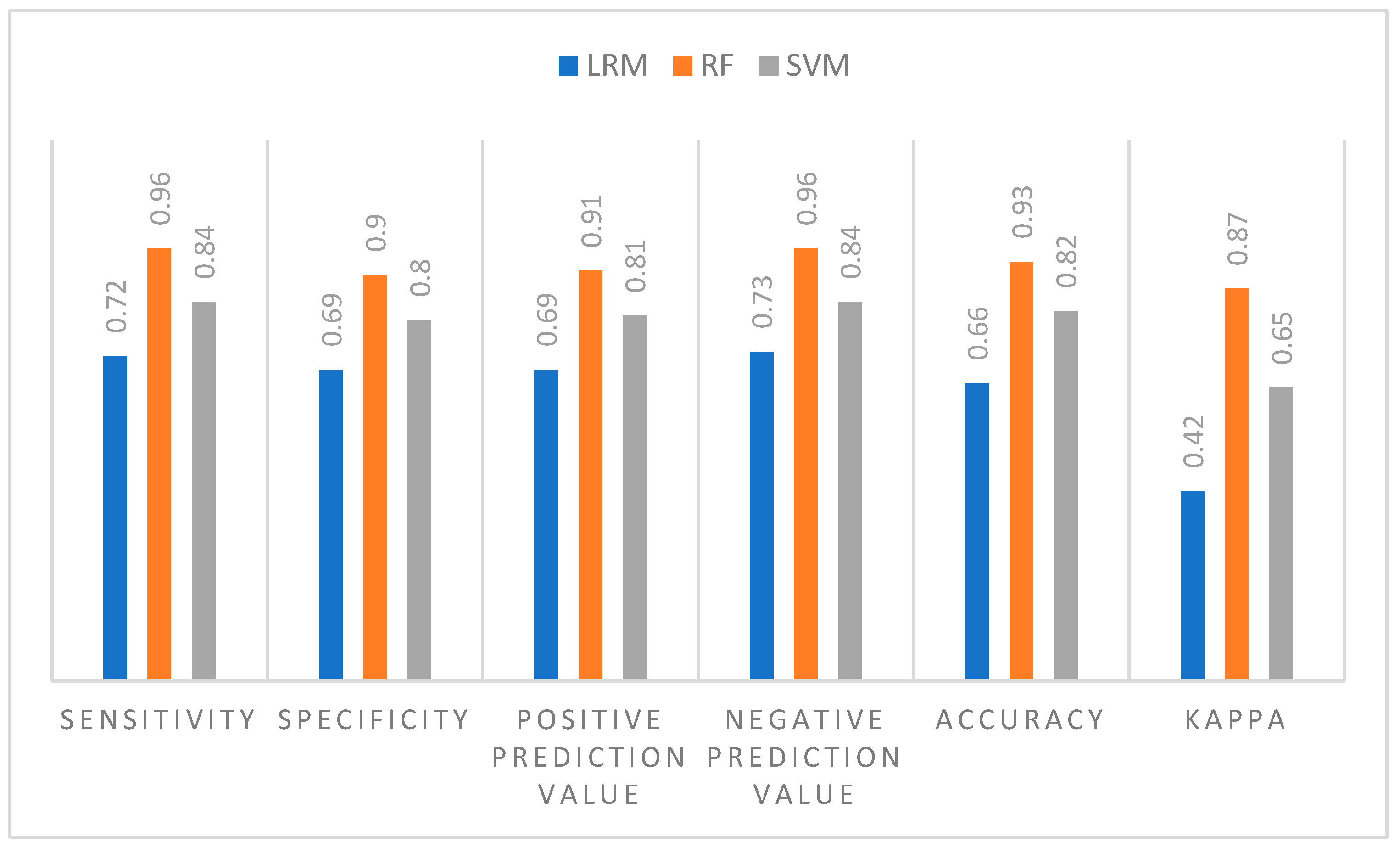
3.1. Measuring and Verifying Classification Accuracy
(−0.016687 ∗ “Rock Types”) + (−0.356960 ∗ “Slope”) + (−0.831213 ∗ “NDVI”) +
(1.045128 ∗ “NDWI”) + (−0.533503 ∗ Distance to Settlement)
3.2. Verifying Variables Influencing Forest Cover Change in Mae Hong Son
3.3. Verifying Variables Influencing Forest Cover Change in Chiang Mai
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Putz, F.E.; Blate, G.M.; Redford, K.H.; Fimbel, R.; Robinson, J. Tropical forest management and conservation of biodiversity: An overview. Conserv. Biol. 2001, 15, 7–20. [Google Scholar] [CrossRef]
- Mitchard, E.T. The tropical forest carbon cycle and climate change. Nature 2018, 559, 527–534. [Google Scholar] [CrossRef] [PubMed]
- FAO; UNEP. The State of the World’s Forests 2020: Forests, Biodiversity and People; FAO: Rome, Italy, 2020. [Google Scholar]
- Mitchell, A.L.; Rosenqvist, A.; Mora, B. Current remote sensing approaches to monitoring forest degradation in support of countries measurement, reporting and verification (MRV) systems for REDD+. Carbon Balance Manag. 2017, 12, 9. [Google Scholar] [CrossRef] [PubMed]
- Crutzen, P.J. The “anthropocene”. In Earth System Science in the Anthropocene; Springer: Berlin/Heidelberg, Germany, 2006; pp. 13–18. [Google Scholar]
- FAO. The State of the World’s Forests 2018—Forest Pathways to Sustainable Development; FAO: Rome, Italy, 2018. [Google Scholar]
- Díaz, S.; Settele, J.; Brondízio, E.; Ngo, H.; Guèze, M.; Agard, J.; Zayas, C. Summary for Policymakers of the Global Assessment Report on Biodiversity and Ecosystem Services of the Intergovernmental Science-Policy Platform on Biodiversity and Ecosystem Services; Intergovernmental Science-Policy Platform on Biodiversity and Ecosystem Services: Bonn, Germany, 2019. [Google Scholar]
- UN. The Sustainable Development Goals Report; United Nations: New York, NY, USA, 2016. [Google Scholar]
- Dibs, H.; Ali, A.H.; Al-Ansari, N.; Abed, S.A. Fusion Landsat-8 Thermal TIRS and OLI Datasets for Superior Monitoring and Change Detection using Remote Sensing. Emerg. Sci. J. 2023, 7, 428–444. [Google Scholar] [CrossRef]
- Mirpulatov, I.; Illarionova, S.; Shadrin, D.; Burnaev, E. Pseudo-Labeling Approach for Land Cover Classification Through Remote Sensing Observations With Noisy Labels. IEEE Access 2023, 11, 82570–82583. [Google Scholar] [CrossRef]
- Praticò, S.; Solano, F.; Di Fazio, S.; Modica, G. Machine Learning Classification of Mediterranean Forest Habitats in Google Earth Engine Based on Seasonal Sentinel-2 Time-Series and Input Image Composition Optimisation. Remote Sens. 2021, 13, 586. [Google Scholar] [CrossRef]
- Brovelli, M.A.; Sun, Y.; Yordanov, V. Monitoring Forest Change in the Amazon Using Multi-Temporal Remote Sensing Data and Machine Learning Classification on Google Earth Engine. ISPRS Int. J. Geo-Inf. 2020, 9, 580. [Google Scholar] [CrossRef]
- Li, Y.; Li, M.; Li, C.; Liu, Z. Forest aboveground biomass estimation using Landsat 8 and Sentinel-1A data with machine learning algorithms. Sci. Rep. 2020, 10, 9952. [Google Scholar] [CrossRef] [PubMed]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R. High-resolution global maps of 21st-century forest cover change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef]
- Shimada, M.; Itoh, T.; Motooka, T.; Watanabe, M.; Shiraishi, T.; Thapa, R.; Lucas, R. New global forest/non-forest maps from ALOS PALSAR data (2007–2010). Remote Sens. Environ. 2014, 155, 13–31. [Google Scholar] [CrossRef]
- Santoro, M.; Cartus, O.; Carvalhais, N.; Rozendaal, D.M.A.; Avitabile, V.; Araza, A.; de Bruin, S.; Herold, M.; Quegan, S.; Rodríguez-Veiga, P.; et al. The global forest above-ground biomass pool for 2010 estimated from high-resolution satellite observations. Earth Syst. Sci. Data 2021, 13, 3927–3950. [Google Scholar] [CrossRef]
- Brink, A.B.; Eva, H.D. Monitoring 25 years of land cover change dynamics in Africa: A sample based remote sensing approach. Appl. Geogr. 2009, 29, 501–512. [Google Scholar] [CrossRef]
- Petit, C.C.; Lambin, E.F. Integration of multi-source remote sensing data for land cover change detection. Int. J. Geogr. Inf. Sci. 2010, 15, 785–803. [Google Scholar] [CrossRef]
- Nomura, K.; Mitchard, E. More Than Meets the Eye: Using Sentinel-2 to Map Small Plantations in Complex Forest Landscapes. Remote Sens. 2018, 10, 1693. [Google Scholar] [CrossRef]
- Surono, S.; Afitian, M.Y.F.; Setyawan, A.; Eni Arofah, D.K.; Thobirin, A. Comparison of CNN Classification Model using Machine Learning with Bayesian Optimizer. HighTech Innov. J. 2023, 4, 531–542. [Google Scholar] [CrossRef]
- Wang, L.; Ye, C.; Chen, F.; Wang, N.; Li, C.; Zhang, H.; Wang, Y.; Yu, B. CG-CFPANet: A multi-task network for built-up area extraction from SDGSAT-1 and Sentinel-2 remote sensing images. Int. J. Digit. Earth 2024, 17. [Google Scholar] [CrossRef]
- Vega Isuhuaylas, L.; Hirata, Y.; Ventura Santos, L.; Serrudo Torobeo, N. Natural Forest Mapping in the Andes (Peru): A Comparison of the Performance of Machine-Learning Algorithms. Remote Sens. 2018, 10, 782. [Google Scholar] [CrossRef]
- Potić, I.; Srdić, Z.; Vakanjac, B.; Bakrač, S.; Đorđević, D.; Banković, R.; Jovanović, J.M. Improving Forest Detection Using Machine Learning and Remote Sensing: A Case Study in Southeastern Serbia. Appl. Sci. 2023, 13, 8289. [Google Scholar] [CrossRef]
- Siles, N.S. Spatial Modelling and Prediction of Tropical Forest Conversion in the Isiboro Sécure National Park and Indigenous Territory TIPNIS, Bolivia. Master’s Thesis, ITC: Faculty of Geo-information Science and Earth Observation, Enschede, The Netherlands, 2009. [Google Scholar]
- Saleh, A. Modeling spatial pattern of deforestation using GIS and logistic regression: A case study of northern Ilam forests, Ilam province, Iran. Afr. J. Biotechnol. 2011, 10, 16236–16249. [Google Scholar] [CrossRef]
- Weiss, A. Topographic position and landforms analysis. In Proceedings of the Poster Presentation, ESRI User Conference, San Diego, CA, USA, 9–13 July 2001. [Google Scholar]
- van Gils, H.A.M.J.; Ugon, A.V.L.A. What Drives Conversion of Tropical Forest in Carrasco Province, Bolivia? AMBIO J. Hum. Environ. 2006, 35, 81–85. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Pal, M.; Mather, P.M. An assessment of the effectiveness of decision tree methods for land cover classification. Remote Sens. Environ. 2003, 86, 554–565. [Google Scholar] [CrossRef]
- Vapnik, V.; Golowich, S.E.; Smola, A. Support vector method for function approximation, regression estimation and signal processing. In Proceedings of the 9th International Conference on Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1996; pp. 281–287. [Google Scholar]
- Aizerman, M.A.; Braverman, E.M.; Rozonoer, L.I. Theoretical foundation of potential functions method in pattern recognition. Avtomatika i Telemekhanika 2019, 25, 917–936. [Google Scholar]
- Nichols, T.R.; Wisner, P.M.; Cripe, G.; Gulabchand, L. Putting the Kappa Statistic to Use. Qual. Assur. J. 2011, 13, 57–61. [Google Scholar] [CrossRef]
- Kumar, R.; Nandy, S.; Agarwal, R.; Kushwaha, S.P.S. Forest cover dynamics analysis and prediction modeling using logistic regression model. Ecol. Indic. 2014, 45, 444–455. [Google Scholar] [CrossRef]
- Nurda, N.; Noguchi, R.; Ahamed, T. Change Detection and Land Suitability Analysis for Extension of Potential Forest Areas in Indonesia Using Satellite Remote Sensing and GIS. Forests 2020, 11, 398. [Google Scholar] [CrossRef]
- Guo, X.; Chen, R.; Meadows, M.E.; Li, Q.; Xia, Z.; Pan, Z. Factors Influencing Four Decades of Forest Change in Guizhou Province, China. Land 2023, 12, 1004. [Google Scholar] [CrossRef]
- Mertens, B.; Lambin, E.F. Spatial modelling of deforestation in southern Cameroon. Appl. Geogr. 1997, 17, 143–162. [Google Scholar] [CrossRef]
- Linkie, M.; Smith, R.J.; Leader-Williams, N. Mapping and predicting deforestation patterns in the lowlands of Sumatra. Biodivers. Conserv. 2004, 13, 1809–1818. [Google Scholar] [CrossRef]
- Mas, J. Modelling deforestation using GIS and artificial neural networks. Environ. Model. Softw. 2004, 19, 461–471. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Sub-Class Name | 2011 Land Area (sq km) | 2021 Land Area (sq km) | Change Detection (sq km) |
|---|---|---|---|---|
| Non-forest | Waterbodies | 40.30 | 52.76 | 12.46 |
| Agriculture | 2249.47 | 1863.70 | −385.76 | |
| Built-up area | 124.56 | 150.61 | 26.06 | |
| Forest | Forest | 10,272.68 | 10,619.93 | 347.24 |
| Total | 12,687.00 | 12,687.00 |
| Variable | Original Data | Source |
|---|---|---|
| Forest change | Land use change | Google Earth Engine |
| Distances from roads, waterbodies, and settlements | Roads, waterbodies, and settlements | Land Development Department |
| Soil series and rock types | Soil series and rock types | Department of Environmental Quality Promotion |
| DEM | DEM | ASTER Global Digital Elevation Map |
| NDVI and NDWI | Landsat ETM+/OLI | Google Earth Engine |
| Class Level | Distances from Roads (Meters) | Distances from Settlements (Meters) | Distances from Waterbodies (Meters) | DEM (Meters) | Slope (Degrees) |
|---|---|---|---|---|---|
| Level 1 | 0–400 | 0–1500 | 0–500 | −33–420 | 0–10 |
| Level 2 | 401–1000 | 1500–3000 | 501–1500 | 421–620 | 11–30 |
| Level 3 | 1001–1500 | 3001–4500 | 1501–3000 | 621–820 | 31–40 |
| Level 4 | 1501–2000 | 4500–6000 | 3000–4500 | 821–1020 | 41–50 |
| Level 5 | >2000 | >6000 | >4500 | 1021–2016 | >50 |
| Legend | Description |
|---|---|
| 1 | Lowland areas with gray clay soils (soil group numbers 5 and 7) |
| 2 | Lowland areas with gray loamy soils (soil group numbers 18, 59, and 59B) |
| 3 | Lowland areas with gray loamy riverbank soils (soil group number 21) |
| 4 | Upland areas with loamy soils found on both sides of riverbanks (soil group numbers 33, 38, and 38B) |
| 5 | Upland areas with clay soils and slopes (soil group numbers 29B, 29C, 29D, 29E, 30B, 30D, 30E, 31, 31B, 31C, 31D, and 31E) |
| 6 | Upland areas with loamy soils and slopes (soil group numbers 35, 35B, 35C, 36, 60, and 60B) |
| 7 | Upland areas with sandy soils (soil group numbers 44B and 44C) |
| 8 | Upland areas with moderately deep soils and slopes (soil group numbers 56B, 56C, 56D, and 56E) |
| 9 | Upland areas with shallow soils and slopes (soil group numbers 48B, 48C, 48D, 48E, and 49B) |
| 10 | Upland areas with shallow bedrock and slopes (soil group number 47D) |
| 11 | Upland areas with extremely steep slopes or mountainous areas (soil group number 62). These areas were not studied, surveyed, or classified based on their soil characteristics and properties because they have slopes greater than 35%. They are considered difficult to manage and maintain for agriculture and consist of very shallow to deep soils, and they potentially contain boulders, rock fragments, and exposed bedrock scattered on the soil surface. |
| Legend | Description |
|---|---|
| Qa | Alluvial deposits: sandy clay, clayey sand, lateritic soil, and clay |
| Qt | Terrace deposits: gravel, sand, and laterite |
| Qc | Calluvial and residual deposits |
| T | Claystone, siltstone, sandstone, mudstone, diatomite, and lignite |
| J | Red conglomerate and reddish-brown sandstone intercalated with shale and mudstone |
| Ju | Sandstone, siltstone, conglomerate, limestone, bivalve, and ammonite |
| TRJ | Greenish-gray sandstone, reddish-brown siltstone, limestone, and conglomerate |
| TR2 | Shale, chert, and thin-bedded limestone with bivalve fossils |
| TR1 | Red conglomerate, sandstone, and red to reddish-brown shale |
| PTR | Shale, siltstone, and dark gray to greenish-gray sandstone intercalated with thin-bedded chert |
| Pph | Gray limestone with thick-bedded, distinct karst topography and shale |
| Pkl | Sandstone, chert, and gray shale |
| P | Sandstone, gray siltstone, red shale, mudstone, and gray thick-bedded limestone |
| CP | Sandstone, shale, red conglomerate, chert, and slaty shale |
| C2 | Shale, siltstone, and gray sandstone interbedded with chert |
| C1 | Gray sandstone, gray shale, green-to-gray chert, and limestone interbedded with shale |
| C | Sandstone interbedded with gray shale, conglomerate, shale, chert, limestone, and mudstone |
| D | Shale interbedded with limestone and sandstone |
| SDC | Gray shale interbedded with limestone, with fossils of nautiloids, gastropods, and conodonts |
| SD | Sandstone interbedded with siltstone, shale, limestone, and phyllitic shale, with tentaculite fossils |
| O | Gray argillaceous limestone interbedded with mudstone and shale, with fossils of conodonts and nautiloids |
| EO | White banded marble and quartz–mica schist |
| E | Quartzite and sandstone interbedded with shale and slaty shale |
| bs | Volcanic rock: basalt, black, and gray |
| TRgr | Igneous rock: biotite granite, hornblende–biotite granite, muscovite granite with equigranular-to-porphyritic texture, and fine-grained leucogranite |
| TRm | Migmatite, unclassified granite, gneiss, schist, quartzite, and sandstone |
| Cgr | Igneous rock: granite in contact metamorphism zone, cataclastic granite, and biotite granite |
| Actual class | Predicted class | |||
| No change | Change | |||
| No change | True Positive (TP) | False Positive (FP) | ||
| Change | False Negative (FN) | True Negative (TN) | ||
| Kappa | Interpretation |
|---|---|
| <0% | No agreement |
| 0.01%–20% | Slight agreement |
| 21%–40% | Fair agreement |
| 41%–60% | Moderate agreement |
| 61%–80% | Substantial agreement |
| 81%–100% | Perfect agreement |
| Coefficients | |||||
|---|---|---|---|---|---|
| Estimate | Std. Error | z Value | Pr(>|z|) | Significance | |
| Intercept | 6.263955 | 0.678038 | 9.238 | <2 × 10−16 | *** |
| Soil series | −0.374430 | 0.079131 | −4.732 | 2.23 × 10−6 | *** |
| Rock types | −0.016687 | 0.005221 | −3.196 | 0.00139 | ** |
| DEM | −0.013484 | 0.041603 | −0.324 | 0.74585 | |
| Slope | −0.356960 | 0.058326 | −6.120 | 9.35 × 10−10 | *** |
| NDVI | −0.831213 | 0.109684 | −7.578 | 3.50 × 10−14 | *** |
| NDWI | 1.045128 | 0.106785 | 9.787 | <2 × 10−16 | *** |
| Distances from roads | −0.039336 | 0.039755 | −0.989 | 0.32243 | |
| Distances from waterbodies | 0.051698 | 0.037715 | 1.371 | 0.17045 | |
| Distances from settlements | −0.533503 | 0.035352 | −15.091 | <2 × 10−16 | *** |
| Ground truth | Model prediction | |||
| No change | Change | |||
| No change | 417 | 190 | ||
| Change | 161 | 425 | ||
| Ground truth | Model prediction | |||
| No change | Change | |||
| No change | 575 | 59 | ||
| Change | 21 | 538 | ||
| Ground truth | Model prediction | |||
| No change | Change | |||
| No change | 503 | 117 | ||
| Change | 93 | 480 | ||
| Authors | Variables | Period | Techniques | Results |
|---|---|---|---|---|
| Kumar et al. [33] | Distances from forest edges, roads, and settlements and slope position classes as explanatory variables of forest change | 1990 to 2010 | LRM | The LRM successfully predicted the forest cover in 2010 with reasonably high accuracy (ROC = 87%). |
| Nurda et al. [34] | Distances from rivers, distances from roads, elevation, LULC, and settlements | 2003 to 2018 | AHP | In the AHP method, the influential criteria had higher weights and were ranked as follows: settlements, elevation, distances from roads, and distances from rivers. |
| Guo et al. [35] | Land use; night light; settlement density; GDP; state, county, and township roads; lithological data; precipitation; evaporation; and DEM | 1980 to 2018 | Generalized linear model (GLM) regression | The effects of population and gross domestic product (GDP) on the forest changes weakened, and the influence of land use change markedly increased. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Worachairungreung, M.; Kulpanich, N.; Yodsuk, P.; Kaewnet, T.; Sae-ngow, P.; Ngansakul, P.; Thanakunwutthirot, K.; Hemwan, P. Using a Logistic Regression Model to Examine the Variables Influencing Changes in Northern Thailand’s Forest Cover and Comparing Machine Learning Algorithms. Forests 2024, 15, 981. https://doi.org/10.3390/f15060981
Worachairungreung M, Kulpanich N, Yodsuk P, Kaewnet T, Sae-ngow P, Ngansakul P, Thanakunwutthirot K, Hemwan P. Using a Logistic Regression Model to Examine the Variables Influencing Changes in Northern Thailand’s Forest Cover and Comparing Machine Learning Algorithms. Forests. 2024; 15(6):981. https://doi.org/10.3390/f15060981
Chicago/Turabian StyleWorachairungreung, Morakot, Nayot Kulpanich, Pichamon Yodsuk, Thactha Kaewnet, Pornperm Sae-ngow, Pattarapong Ngansakul, Kunyaphat Thanakunwutthirot, and Phonpat Hemwan. 2024. "Using a Logistic Regression Model to Examine the Variables Influencing Changes in Northern Thailand’s Forest Cover and Comparing Machine Learning Algorithms" Forests 15, no. 6: 981. https://doi.org/10.3390/f15060981