
Individual Tree Identification and Segmentation in Pinus spp. Stands through Portable LiDAR



Abstract
1. Introduction
2. Study Area
3. Materials
4. Methods
- Point cloud acquisition and georeferencing: Both stands were scanned, and the cartographic coordinates of ground control points were measured to georeference the resulting point clouds;
- Processing of point clouds: The point clouds were processed through normalization, filtering, and rasterization to obtain a canopy height model;
- Ground truth dataset: The real trees were identified and geolocated through visual interpretation of the point clouds;
- Automatic tree identification: Six different identification methods were performed and verified in each stand; three were raster-based methods, and the other three were point-cloud-based methods;
- Automatic tree segmentation: Seven segmentation methods were performed and verified in each stand. Five were raster-based methods, and two were point-cloud-based methods.
- A flowchart of the methodology can be observed in Figure 5.

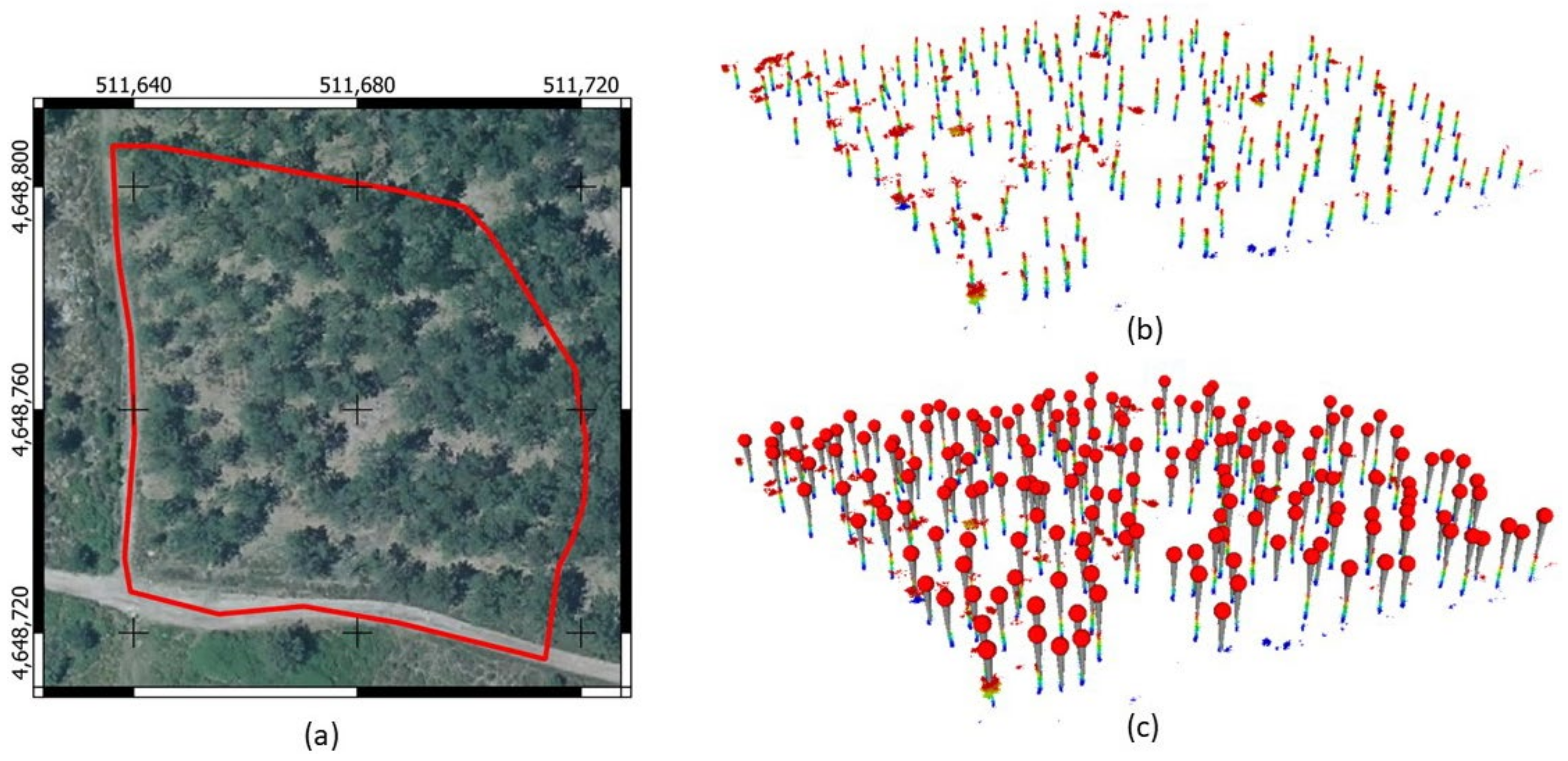
4.1. Point Cloud Acquisition and Georeferencing
4.2. Processing of Point Clouds
4.3. Ground Truth Dataset
4.4. Automatic Tree Identification
4.4.1. Treetop Identification through CHM Segmentation (CS)
4.4.2. Treetop Identification through Point-Cloud Inversion and CHM Segmentation (PCICS)
4.4.3. Treetop Identification through CHM Local Maxima (CLM)
4.4.4. Treetop Identification through Point Cloud Local Maxima (PCLM)
4.4.5. Tree Trunk Identification through Circle Fitting (CF)
4.4.6. Tree Trunk Identification through Central Axis Estimation (CAE)
4.5. Automatic Tree Segmentation
4.5.1. CHM Segmentation (Methods CS_I and CS_II)
4.5.2. CHM Segmentation through 2D Seeding (Methods CS2D_I, CS2D_II and CS2D_III)
4.5.3. Point Cloud Segmentation through Three-Dimensional Seeding (PCS3D Method)
4.5.4. Point Cloud Segmentation through Minimum Distances (PCSMD Method)
4.6. Verification
- The number of identified trees;
- Precision: the number of true positives divided by the total number of trees identified in the stand;
- Recall: the number of true positives divided by the total number of real trees in the stand;
- F-score: the harmonic mean of the precision and recall, calculated as follows:
- The number of segmented trees;
- Precision: the number of true positives divided by the total number of trees segmented in the stand;
- Recall: the number of true positives divided by the total number of real trees in the stand;
- Ratio of false positives: the number of false positives divided by the total number of segmented trees in the stand. This metric is provided in total but also differentiates between segmentations that corresponded to groups of real trees and segmentations that did not correspond to any real tree;
- F-score: the harmonic mean of the precision and recall (see Equation (1)).
5. Results
5.1. Point Cloud Acquisition and Georeferencing
5.2. Processing and Ground Truth
5.3. Automatic Tree Identification
5.4. Automatic Tree Segmentation
6. Discussion
6.1. Tree Identification
6.2. Tree Segmentation
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bončina, A.; Simončič, T.; Rosset, C. Assessment of the concept of forest functions in Central European forestry. Environ. Sci. Policy 2019, 99, 123–135. [Google Scholar] [CrossRef]
- Oswalt, S.N.; Smith, W.N.; Miles, P.D.; Pugh, S.A. Forest Resources of the United States, 2017: A Technical Document Supporting the Forest Service RPA Assessment; General Technical Report WO-97; U.S. Department of Agriculture, Forest Service, Washington Office: Washington, DC, USA, 2020; 223p. [Google Scholar] [CrossRef]
- Pace, R.; Masini, E.; Giuliarelli, D.; Biagiola, L.; Tomao, A.; Guidolotti, G.; Agrimi, M.; Portoghesi, L.; De Angelis, P.; Calfapietra, C. Tree measurements in the urban environment: Insights from traditional and digital field instruments to smartphone applications. Arboric. Urban For. AUF 2022, 48, 113–123. [Google Scholar] [CrossRef]
- Alonso, L.; Picos, J.; Armesto, J. Mapping eucalyptus species using worldview 3 and random forest. In Proceedings of the ISPRS—International Archives of the Photogrammetry Remote Sensing and Spatial Information Sciences, XLIII-B3-2022, Nice, France, 6–11 June 2022; pp. 819–825. [Google Scholar] [CrossRef]
- Newnham, G.J.; Armston, J.D.; Calders, K.; Disney, M.I.; Lovell, J.L.; Schaaf, C.B.; Strahler, A.H.; Danson, F.M. Terrestrial laser scanning for plot-scale forest measurement. Curr. For. Rep. 2015, 1, 239–251. [Google Scholar] [CrossRef]
- Xie, Y.; Yang, T.; Wang, X.; Chen, X.; Pang, S.; Hu, J.; Wang, A.; Chen, L.; Shen, Z. Applying a Portable Backpack Lidar to Measure and Locate Trees in a Nature Forest Plot: Accuracy and Error Analyses. Remote Sens. 2022, 14, 1806. [Google Scholar] [CrossRef]
- Piermattei, L.; Karel, W.; Wang, D.; Wieser, M.; Mokroš, M.; Surový, P.; Koreň, M.; Tomaštík, J.; Pfeifer, N.; Hollaus, M. Terrestrial structure from motion photogrammetry for deriving forest inventory data. Remote Sens. 2019, 11, 950. [Google Scholar] [CrossRef]
- Bülbül, R.; Reder, S.; Mund, J.P. Performance test of tree segmentation algorithms for WLS point clouds. In Proceedings of the SilviLaser Conference, Vienna, Austria, 28–30 September 2021. [Google Scholar] [CrossRef]
- Yang, Q.; Su, Y.; Jin, S.; Kelly, M.; Hu, T.; Ma, Q.; Li, Y.; Song, S.; Zhang, J.; Xu, G.; et al. The influence of vegetation characteristics on individual tree segmentation methods with airborne LiDAR data. Remote Sens. 2019, 11, 2880. [Google Scholar] [CrossRef]
- Dalla Corte, A.P.; Rex, F.E.; Almeida, D.R.A.; Sanquetta, C.R.; Silva, C.A.; Moura, M.M.; Wilkinson, B.; Zambrano, A.M.A.; Cunha Neto, E.M.; Veras, H.F.P.; et al. Measuring Individual Tree Diameter and Height Using GatorEye High-Density UAV-Lidar in an Integrated Crop-Livestock-Forest System. Remote Sens. 2020, 12, 863. [Google Scholar] [CrossRef]
- Liang, X.; Kukko, A.; Hyyppä, J.; Lehtomäki, M.; Pyörälä, J.; Yu, X.; Kaartinen, H.; Jaakkola, A.; Wang, Y. In-situ measurements from mobile platforms: An emerging approach to address the old challenges associated with forest inventories. ISPRS J. Photogramm. Remote Sens. 2018, 143, 97–107. [Google Scholar] [CrossRef]
- Thompson, I.D.; Maher, S.C.; Rouillard, D.P.; Fryxell, J.M.; Baker, J.A. Accuracy of forest inventory mapping: Some implications for boreal forest management. For. Ecol. Manag. 2007, 252, 208–221. [Google Scholar] [CrossRef]
- White, J.C.; Coops, N.C.; Wulder, M.A.; Vastaranta, M.; Hilker, T.; Tompalski, P. Remote sensing technologies for enhancing forest inventories: A review. Can. J. Remote Sens. 2016, 42, 619–641. [Google Scholar] [CrossRef]
- Liu, H.; Cao, F.; She, G.; Cao, L. Extrapolation Assessment for Forest Structural Parameters in Planted Forests of Southern China by UAV-LiDAR Samples and Multispectral Satellite Imagery. Remote Sens. 2022, 14, 2677. [Google Scholar] [CrossRef]
- Lechner, A.M.; Foody, G.M.; Boyd, D.S. Applications in remote sensing to forest ecology and management. One Earth 2020, 2, 405–412. [Google Scholar] [CrossRef]
- Shugart, H.H.; Saatchi, S.; Hall, F.G. Importance of structure and its measurement in quantifying function of forest ecosystems. J. Geophys. Res. Biogeosci. 2010, 115, G00E13. [Google Scholar] [CrossRef]
- Choi, I.-H.; Nam, S.-K.; Kim, S.-Y.; Lee, D.-G. Forest Digital Twin Implementation Study for 3D Forest Geospatial Information Service. Korean J. Remote Sens. 2023, 39, 1165–1172. [Google Scholar] [CrossRef]
- Michez, A.; Bauwens, S.; Bonnet, S.; Lejeune, P. Characterization of forests with LiDAR technology. In Land Surface Remote Sensing in Agriculture and Forest; Elsevier: Amsterdam, The Netherlands, 2016; pp. 331–362. [Google Scholar] [CrossRef]
- Zhen, Z.; Quackenbush, L.J.; Zhang, L. Trends in automatic individual tree crown detection and delineation—Evolution of LiDAR data. Remote Sens. 2016, 8, 333. [Google Scholar] [CrossRef]
- Gollob, C.; Ritter, T.; Nothdurft, A. Forest inventory with long range and high-speed personal laser scanning (PLS) and simultaneous localization and mapping (SLAM) technology. Remote Sens. 2020, 12, 1509. [Google Scholar] [CrossRef]
- Donager, J.J.; Sánchez Meador, A.J.; Blackburn, R.C. Adjudicating perspectives on forest structure: How do airborne, terrestrial, and mobile lidar-derived estimates compare? Remote Sens. 2021, 13, 2297. [Google Scholar] [CrossRef]
- Hilker, T.; van Leeuwen, M.; Coops, N.C.; Wulder, M.A.; Newnham, G.J.; Jupp, D.L.; Culvenor, D.S. Comparing canopy metrics derived from terrestrial and airborne laser scanning in a Douglas-fir dominated forest stand. Trees Struct. Funct. 2010, 24, 819–832. [Google Scholar] [CrossRef]
- Xia, S.; Chen, D.; Peethambaran, J.; Wang, P.; Xu, S. Point Cloud Inversion: A Novel Approach for the Localization of Trees in Forests from TLS Data. Remote Sens. 2021, 13, 338. [Google Scholar] [CrossRef]
- Yrttimaa, T.; Junttila, S.; Luoma, V.; Calders, K.; Kankare, V.; Saarinen, N.; Kukko, A.; Holopainen, M.; Hyppä, J.; Vastaranta, M. Capturing seasonal radial growth of boreal trees with terrestrial laser scanning. For. Ecol. Manag. 2023, 529, 120733. [Google Scholar] [CrossRef]
- Chiappini, S.; Pierdicca, R.; Malandra, F.; Tonelli, E.; Malinverni, E.S.; Urbinati, C.; Vitali, A. Comparing Mobile Laser Scanner and manual measurements for dendrometric variables estimation in a black pine (Pinus nigra Arn.) plantation. Comput. Electron. Agric. 2022, 198, 107069. [Google Scholar] [CrossRef]
- Latella, M.; Sola, F.; Camporeale, C. A density-based algorithm for the detection of individual trees from LiDAR data. Remote Sens. 2021, 13, 322. [Google Scholar] [CrossRef]
- Vauhkonen, J.; Ene, L.; Gupta, S.; Heinzel, J.; Holmgren, J.; Pitkänen, J.; Solberg, S.; Wang, Y.; Weinacker, H.; Hauglin, K.M.; et al. Comparative testing of single-tree detection algorithms under different types of forest. Forestry 2012, 85, 27–40. [Google Scholar] [CrossRef]
- Hyyppä, J.; Kelle, O.; Lehikoinen, M.; Inkinen, M. A segmentation-based method to retrieve stem volume estimates from 3-D tree height models produced by laser scanners. IEEE Trans. Geosci. Remote Sens. 2001, 39, 969–975. [Google Scholar] [CrossRef]
- Li, W.; Guo, Q.; Jakubowski, M.K.; Kelly, M. A new method for segmenting individual trees from the lidar point cloud. Photogramm. Eng. Remote Sens. 2012, 78, 75–84. [Google Scholar] [CrossRef]
- Lisiewicz, M.; Kamińska, A.; Kraszewski, B.; Stereńczak, K. Correcting the results of CHM-based individual tree detection algorithms to improve their accuracy and reliability. Remote Sens. 2022, 14, 1822. [Google Scholar] [CrossRef]
- Popescu, S.C.; Wynne, R.H. Seeing the trees in the forest: Using lidar and multispectral data fusion with local filtering and variable window size for estimating tree height. Photogramm. Eng. Remote Sens. 2004, 70, 589–604. [Google Scholar] [CrossRef]
- Liu, L.; Lim, S.; Shen, X.; Yebra, M. A hybrid method for segmenting individual trees from airborne lidar data. Comput. Electron. Agric. 2019, 163, 104871. [Google Scholar] [CrossRef]
- Zaforemska, A.; Xiao, W.; Gaulton, R. Individual tree detection from UAV LiDAR data in a mixed species woodland. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 657–663. [Google Scholar] [CrossRef]
- Picos, J.; Bastos, G.; Míguez, D.; Alonso, L.; Armesto, J. Individual tree detection in a Eucalyptus plantation using unmanned aerial vehicle (UAV)-LiDAR. Remote Sens. 2020, 12, 885. [Google Scholar] [CrossRef]
- Solares-Canal, A.; Alonso, L.; Picos, J.; Armesto, J. Automatic tree detection and attribute characterization using portable terrestrial lidar. Trees-Struct. Funct. 2023, 37, 963–979. [Google Scholar] [CrossRef]
- Pu, Y.; Xu, D.; Wang, H.; Li, X.; Xu, X. A New Strategy for Individual Tree Detection and Segmentation from Leaf-on and Leaf-off UAV-LiDAR Point Clouds Based on Automatic Detection of Seed Points. Remote Sens. 2023, 15, 1619. [Google Scholar] [CrossRef]
- Tockner, A.; Gollob, C.; Kraßnitzer, R.; Ritter, T.; Nothdurft, A. Automatic tree crown segmentation using dense forest point clouds from Personal Laser Scanning (PLS). Int. J. Appl. Earth Obs. Geoinf. 2022, 114, 103025. [Google Scholar] [CrossRef]
- Hu, B.; Li, J.; Jing, L.; Judah, A. Improving the efficiency and accuracy of individual tree crown delineation from high-density LiDAR data. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 145–155. [Google Scholar] [CrossRef]
- Yang, J.; Kang, Z.; Cheng, S.; Yang, Z.; Akwensi, P.H. An individual tree segmentation method based on watershed algorithm and three-dimensional spatial distribution analysis from airborne LiDAR point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1055–1067. [Google Scholar] [CrossRef]
- Jing, L.; Hu, B.; Li, J.; Noland, T. Automated delineation of individual tree crowns from LiDAR data by multi-scale analysis and segmentation. Photogramm. Eng. Remote Sens. 2012, 78, 1275–1284. [Google Scholar] [CrossRef]
- Dalponte, M.; Coomes, D.A. Tree-centric mapping of forest carbon density from airborne laser scanning and hyperspectral data. Methods Ecol. Evol. 2016, 7, 1236–1245. [Google Scholar] [CrossRef] [PubMed]
- Huo, L.; Lindberg, E. Individual tree detection using template matching of multiple rasters derived from multispectral airborne laser scanning data. Int. J. Remote Sens. 2020, 41, 9525–9544. [Google Scholar] [CrossRef]
- Lindberg, E.; Eysn, L.; Hollaus, M.; Holmgren, J.; Pfeifer, N. Delineation of tree crowns and tree species classification from full-waveform airborne laser scanning data using 3-D ellipsoidal clustering. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 3174–3181. [Google Scholar] [CrossRef]
- Brolly, G.; Király, G.; Lehtomäki, M.; Liang, X. Voxel-based automatic tree detection and parameter retrieval from terrestrial laser scans for plot-wise forest inventory. Remote Sens. 2021, 13, 542. [Google Scholar] [CrossRef]
- Burt, A.; Disney, M.; Calders, K. Extracting individual trees from lidar point clouds using treeseg. Methods Ecol. Evol. 2018, 10, 438–445. [Google Scholar] [CrossRef]
- Fu, H.; Li, H.; Dong, Y.; Xu, F.; Chen, F. Segmenting individual tree from TLS point clouds using improved DBSCAN. Forests 2022, 13, 566. [Google Scholar] [CrossRef]
- Li, Y.; Xie, D.; Wang, Y.; Jin, S.; Zhou, K.; Zhang, Z.; Li, W.; Zhang, W.; Mu, X.; Yan, G. Individual tree segmentation of airborne and UAV LiDAR point clouds based on the watershed and optimized connection center evolution clustering. Ecol. Evol. 2023, 13, e10297. [Google Scholar] [CrossRef]
- Comesaña-Cebral, L.; Martínez-Sánchez, J.; Lorenzo, H.; Arias, P. Individual tree segmentation method based on mobile backpack LiDAR point clouds. Sensors 2021, 21, 6007. [Google Scholar] [CrossRef]
- Levers, C.; Verkerk, P.J.; Müller, D.; Verburg, P.H.; Butsic, V.; Leitão, P.J.; Lindner, M.; Kuemmerle, T. Drivers of forest harvesting intensity patterns in Europe. For. Ecol. Manag. 2014, 315, 160–172. [Google Scholar] [CrossRef]
- MITERD. Anuario de Estadística Forestal; Ministerio para la Transición Ecológica y el Reto Demográfico: Madrid, Spain, 2018; Available online: https://www.miteco.gob.es/es/biodiversidad/estadisticas/forestal_anuario_2018.html (accessed on 22 February 2024).
- MITECO. Mapa Forestal de España (MFE) de Máxima Actualidad; Ministerio para la Transición Ecológica y el Reto Demográfico: Madrid, Spain, 2011; Available online: https://www.miteco.gob.es/es/cartografia-y-sig/ide/descargas/biodiversidad/mfe.aspx (accessed on 22 February 2024).
- GeoSLAM-ZEB Horizon. Available online: https://geoslam.com/solutions/zeb-horizon/ (accessed on 22 February 2024).
- Centro de Descargas. Organismo Autónomo Centro Nacional de Información Geográfica. Centro Nacional de Información Geográfica. IGN and MTMAU (Ministerio de Transporte Movilidad y Agenda Urbana and Instituto geográfico Nacional). Available online: http://centrodedescargas.cnig.es/CentroDescargas/index.jsp (accessed on 26 June 2024).
- Especificaciones Técnicas Vuelos PNOA-LiDAR. Available online: https://pnoa.ign.es/pnoa-lidar/especificaciones-tecnicas (accessed on 21 June 2024).
- GeoSLAM Hub 6.2.1. Available online: https://geoslam.com/hub/ (accessed on 22 February 2024).
- Rapidlasso GmbH “LAStools—Efficient LiDAR Processing Software” (Academic). Available online: http://rapidlasso.com/LAStools (accessed on 22 February 2024).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2013; Available online: http://www.R-project.org/ (accessed on 22 February 2024).
- RStudio Team. RStudio: Integrated Development Environment for R; RStudio, PBC: Boston, MA, USA, 2021; Available online: http://www.rstudio.com/ (accessed on 22 February 2024).
- Python Software Foundation. Python Language Reference, Version 3.9; Python Software Foundation: Wilmington, DE, USA, 2020. [Google Scholar]
- QGIS Development Team. QGIS Geographic Information System. Open Source Geospatial Foundation Project. 2021. Available online: http://qgis.osgeo.org (accessed on 22 February 2024).
- Fugro. Fugro-Fugroviewer. 2021. Available online: https://www.fugro.com/about-fugro/our-expertise/technology/fugroviewer (accessed on 22 February 2024).
- Roussel, J.R.; Auty, D.; Coops, N.C.; Tompalski, P.; Goodbody, T.R.H.; Sánchez Meador, A.; Bourdon, J.F.; De Boissieu, F.; Achim, A. lidR: An R package for analysis of Airborne Laser Scanning (ALS) data. Remote Sens. Environ. 2020, 251, 112061. [Google Scholar] [CrossRef]
- Roussel, J.R.; Auty, D. Airborne LiDAR Data Manipulation and Visualization for Forestry Applications. R Package Version 3.1.4. 2021. Available online: https://cran.r-project.org/package=lidR (accessed on 22 February 2024).
- Valledor, L.; Guerrero, S.; García-Campa, L.; Meijón, M. Proteometabolomic characterization of apical bud maturation in Pinus pinaster. Tree Physiol. 2021, 41, 508–521. [Google Scholar] [CrossRef]
- Pau, G.; Fuchs, F.; Sklyar, O.; Boutros, M.; Huber, W. EBImage—An R package for image processing with applications to cellular phenotypes. Bioinformatics 2010, 26, 979–981. [Google Scholar] [CrossRef] [PubMed]
- Hahsler, M.; Piekenbrock, M.; Doran, D. dbscan: Fast Density-Based Clustering with R. J. Stat. Softw. 2019, 91, 1–30. [Google Scholar] [CrossRef]
- Umbach, D.; Jones, K.N. A few methods for fitting circles to data. IEEE Trans. Instrum. Meas. 2003, 52, 1881–1885. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; Van Der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Ye, W.; Qian, C.; Tang, J.; Liu, H.; Fan, X.; Liang, X.; Zhang, H. Improved 3D stem mapping method and elliptic hypothesis-based DBH estimation from terrestrial laser scanning data. Remote Sens. 2020, 12, 352. [Google Scholar] [CrossRef]
- Hyyppä, E.; Kukko, A.; Kaijaluoto, R.; White, J.C.; Wulder, M.A.; Pyörälä, J.; Liang, X.; Yu, X.; Wang, Y.; Kaartinen, H.; et al. Accurate derivation of stem curve and volume using backpack mobile laser scanning. ISPRS J. Photogramm. Remote Sens. 2020, 161, 246–262. [Google Scholar] [CrossRef]
- Tupinambá-Simões, F.; Pascual, A.; Guerra-Hernández, J.; Ordóñez, C.; de Conto, T.; Bravo, F. Assessing the performance of a handheld laser scanning system for individual tree mapping—A Mixed forests showcase in Spain. Remote Sens. 2023, 15, 1169. [Google Scholar] [CrossRef]
- Lu, X.; Guo, Q.; Li, W.; Flanagan, J. A bottom-up approach to segment individual deciduous trees using leaf-off lidar point cloud data. ISPRS J. Photogramm. Remote Sens. 2014, 94, 1–12. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scanning Time (min) | Number of Points (in Millions) | Point Density (pts/m2) | |
|---|---|---|---|
| Stand 1 | 12 | 90.26 | 1206.5 |
| Stand 2 | 17 | 127.75 | 1407.47 |
| Target | Actual | |||||||
|---|---|---|---|---|---|---|---|---|
| Stand | GCP | X | Y | Z | X | Y | Z | Error (m) |
| 1 | 1 | 511,631.61 | 4,648,678.33 | 427.01 | 511,631.60 | 4,648,678.25 | 427.00 | 0.08 |
| 2 | 511,683.14 | 4,648,723.92 | 432.43 | 511,683.20 | 4,648,723.93 | 432.34 | 0.11 | |
| 3 | 511,619.03 | 4,648,812.97 | 440.67 | 511,619.01 | 4,648,813.11 | 440.82 | 0.20 | |
| 4 | 511,641.12 | 4,648,724.98 | 431.52 | 511,641.16 | 4,648,724.99 | 431.50 | 0.03 | |
| 1 | 511,631.61 | 4,648,678.33 | 427.01 | 511,631.60 | 4,648,678.24 | 427.00 | 0.09 | |
| 2 | 1 | 511,631.607 | 4,648,678.326 | 427.013 | 511,631.639 | 4,648,678.316 | 426.951 | 0.070 |
| 5 | 511,618.875 | 4,648,632.219 | 425.184 | 511,618.854 | 4,648,632.137 | 425.144 | 0.093 | |
| 6 | 511,575.815 | 4,648,583.022 | 425.315 | 511,575.796 | 4,648,582.892 | 425.333 | 0.133 | |
| 7 | 511,564.813 | 4,648,743.541 | 432.153 | 511,564.813 | 4,648,743.647 | 432.158 | 0.106 | |
| 4 | 511,641.122 | 4,648,724.978 | 431.521 | 511,641.111 | 4,648,725.085 | 431.665 | 0.179 | |
| 1 | 511,631.607 | 4,648,678.326 | 427.013 | 511,631.626 | 4,648,678.336 | 426.949 | 0.068 | |
| Method | IT | P (%) | R (%) | F-Score |
|---|---|---|---|---|
| CS | 127 | 85.9 | 58.0 | 69.2 |
| PCICS | 200 | 93.0 | 98.9 | 95.9 |
| CLM | 159 | 96.2 | 81.4 | 88.2 |
| PCLM | 162 | 96.9 | 83.5 | 89.7 |
| CF | 192 | 97.9 | 100.0 | 99.0 |
| CAE | 189 | 98.9 | 99.5 | 99.2 |
| Method | IT | P (%) | R (%) | F-Score |
|---|---|---|---|---|
| CS | 141 | 65.3 | 59.7 | 62.4 |
| PCICS | 178 | 56.2 | 64.9 | 60.2 |
| CLM | 166 | 72.3 | 77.9 | 75.0 |
| PCLM | 182 | 69.2 | 81.8 | 75.0 |
| CF | 236 | 51.7 | 79.2 | 62.6 |
| CAE | 117 | 100.0 | 76.0 | 86.4 |
| Method | ST | P (%) | FP (%) | R(%) | F-Score | ||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 3 | 4 | Total | |||||
| CS_I | 127 | 59.8 | 3.1 | 26.8 | 6.3 | 3.9 | 40.2 | 40.4 | 48.3 |
| CS_II | 200 | 94.0 | 6.0 | 0 | 0 | 0 | 6.0 | 100.0 | 96.9 |
| CS2D_I | 159 | 77.4 | 2.5 | 20.1 | 0 | 0 | 22.6 | 65.4 | 70.9 |
| CS2D_II | 162 | 80.2 | 2.5 | 16.7 | 0.6 | 0 | 19.8 | 69.2 | 74.3 |
| CS2D_III | 192 | 92.7 | 4.7 | 2.6 | 0 | 0 | 7.3 | 94.7 | 93.7 |
| PCS3D | 162 | 79.0 | 1.9 | 18.5 | 0.6 | 0 | 21.0 | 68.1 | 73.1 |
| PCSMD | 189 | 98.4 | 1.1 | 0.5 | 0 | 0 | 1.6 | 99.0 | 98.7 |
| Method | ST | P (%) | FP (%) | R(%) | F-Score | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 3 | 4 | 5 | 6 | Total | |||||
| CS_I | 141 | 69.5 | 12.8 | 14.9 | 2.1 | 0 | 0.7 | 0 | 30.5 | 63.6 | 66.4 |
| CS_II | 178 | 62.4 | 28.1 | 6.7 | 1.1 | 1.1 | 0.6 | 0 | 37.6 | 72.1 | 66.9 |
| CS2D_I | 166 | 72.3 | 19.9 | 6.6 | 1.2 | 0 | 0 | 0 | 27.7 | 77.9 | 75.0 |
| CS2D_II | 182 | 70.3 | 24.7 | 4.4 | 0.5 | 0 | 0 | 0 | 29.7 | 83.1 | 76.2 |
| CS2D_III | 236 | 49.2 | 48.3 | 2.5 | 0 | 0 | 0 | 0 | 50.8 | 75.3 | 59.5 |
| PCS3D | 181 | 71.3 | 23.8 | 4.4 | 0.6 | 0 | 0 | 0 | 28.7 | 83.8 | 77.0 |
| PCSMD | 117 | 72.6 | 0 | 17.9 | 6.8 | 1.7 | 0 | 0.9 | 27.4 | 55.2 | 62.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Solares-Canal, A.; Alonso, L.; Picos, J.; Armesto, J. Individual Tree Identification and Segmentation in Pinus spp. Stands through Portable LiDAR. Forests 2024, 15, 1133. https://doi.org/10.3390/f15071133
Solares-Canal A, Alonso L, Picos J, Armesto J. Individual Tree Identification and Segmentation in Pinus spp. Stands through Portable LiDAR. Forests. 2024; 15(7):1133. https://doi.org/10.3390/f15071133
Chicago/Turabian StyleSolares-Canal, Ana, Laura Alonso, Juan Picos, and Julia Armesto. 2024. "Individual Tree Identification and Segmentation in Pinus spp. Stands through Portable LiDAR" Forests 15, no. 7: 1133. https://doi.org/10.3390/f15071133
APA StyleSolares-Canal, A., Alonso, L., Picos, J., & Armesto, J. (2024). Individual Tree Identification and Segmentation in Pinus spp. Stands through Portable LiDAR. Forests, 15(7), 1133. https://doi.org/10.3390/f15071133