
Tree Height Estimation of Chinese Fir Forests Based on Geographically Weighted Regression and Forest Survey Data


 and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Forest Survey Data
2.3. Research Framework
2.4. Recursive Feature Elimination
2.5. RF Algorithm
2.6. Ordinary Least Squares
2.7. The Geographically Weighted Regression
2.8. Accuracy Assessment
3. Results
3.1. Feature Selection Result
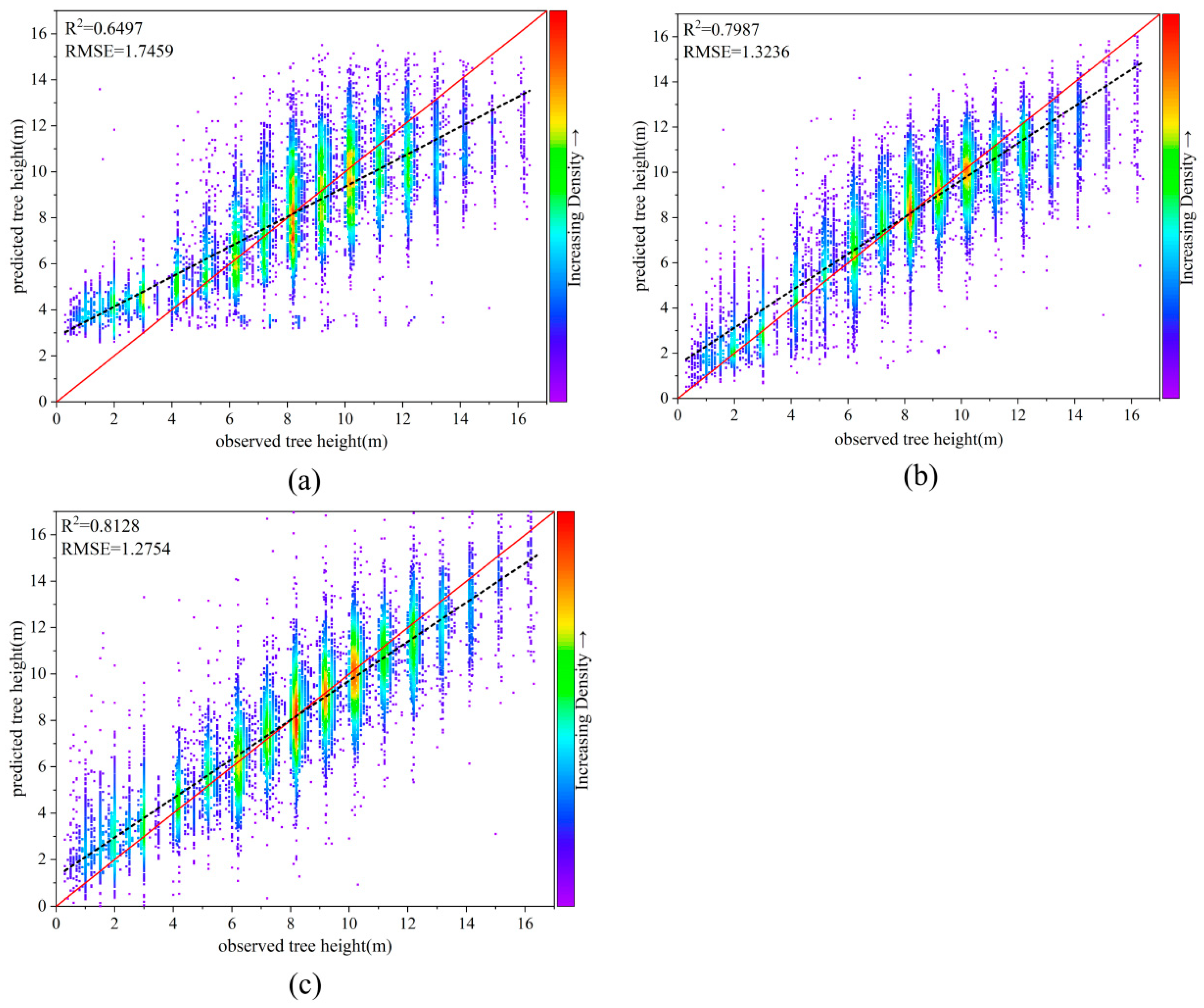
3.2. Comparison of Model Results
3.3. Parameter Estimates with the GWR
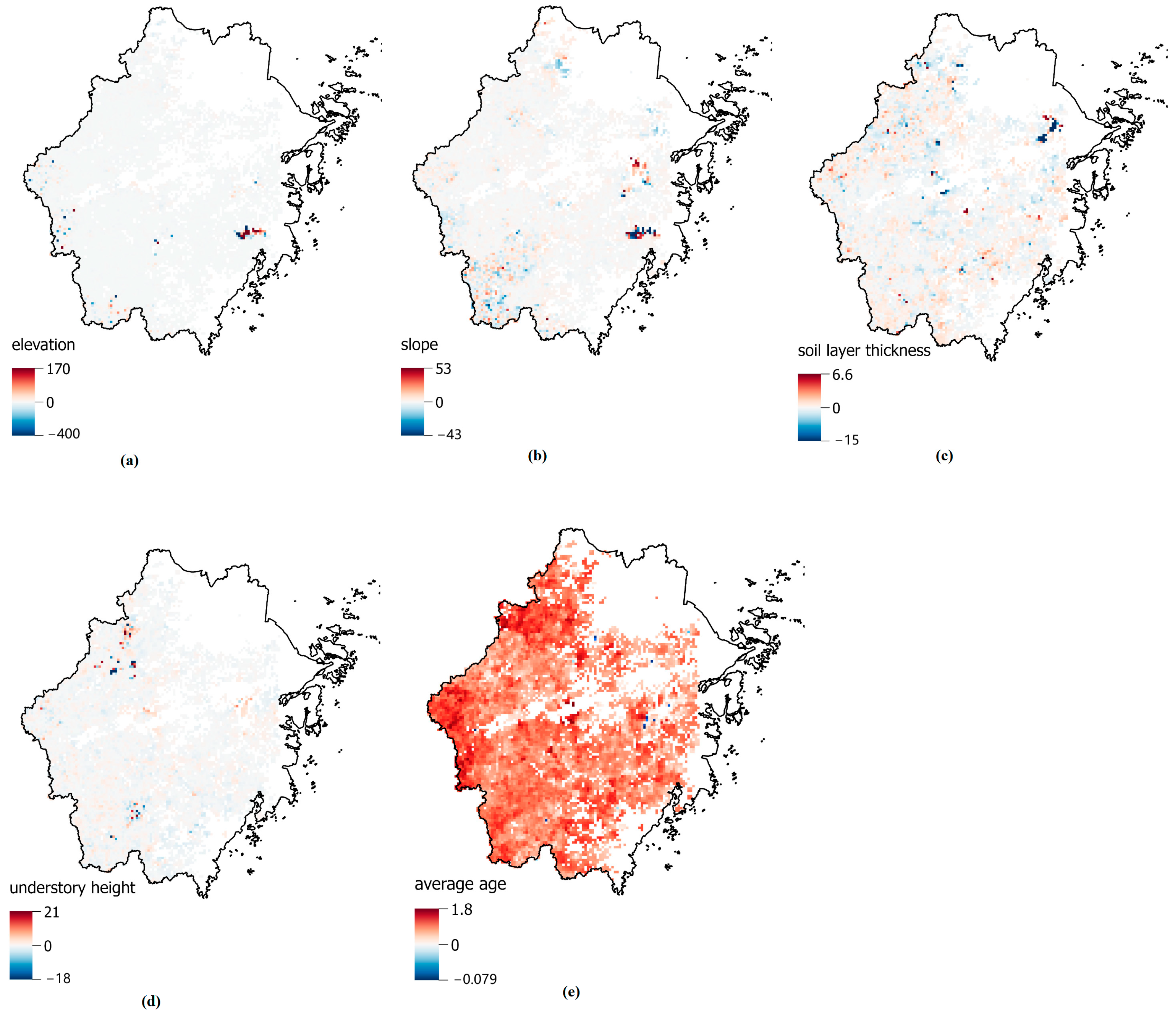
3.4. Spatial Variation of Parameter Estimates
4. Discussion
4.1. Tree Height Modeling and Estimation
4.2. Global-Based Models and Local-Based Models
4.3. The Local-Based Geographically Weighted Regression
4.4. Spatial Heterogeneity of Feature Impact Effects
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lausch, A.; Erasmi, S.; King, D.; Magdon, P.; Heurich, M. Understanding Forest Health with Remote Sensing-Part II—A Review of Approaches and Data Models. Remote Sens. 2017, 9, 129. [Google Scholar] [CrossRef]
- Guimarães, N.; Pádua, L.; Marques, P.; Silva, N.; Peres, E.; Sousa, J.J. Forestry Remote Sensing from Unmanned Aerial Vehicles: A Review Focusing on the Data, Processing and Potentialities. Remote Sens. 2020, 12, 1046. [Google Scholar] [CrossRef]
- Asner, G.P. Tropical Forest Carbon Assessment: Integrating Satellite and Airborne Mapping Approaches. Environ. Res. Lett. 2009, 4, 034009. [Google Scholar] [CrossRef]
- Wang, R.; Gamon, J.A. Remote Sensing of Terrestrial Plant Biodiversity. Remote Sens. Environ. 2019, 231, 111218. [Google Scholar] [CrossRef]
- Turner, W.; Spector, S.; Gardiner, N.; Fladeland, M.; Sterling, E.; Steininger, M. Remote Sensing for Biodiversity Science and Conservation. Trends Ecol. Evol. 2003, 18, 306–314. [Google Scholar] [CrossRef]
- Torresani, M.; Rocchini, D.; Sonnenschein, R.; Zebisch, M.; Hauffe, H.C.; Heym, M.; Pretzsch, H.; Tonon, G. Height Variation Hypothesis: A New Approach for Estimating Forest Species Diversity with CHM LiDAR Data. Ecol. Indic. 2020, 117, 106520. [Google Scholar] [CrossRef]
- Yu, Z.; Liu, S.; Li, H.; Liang, J.; Liu, W.; Piao, S.; Tian, H.; Zhou, G.; Lu, C.; You, W.; et al. Maximizing Carbon Sequestration Potential in Chinese Forests through Optimal Management. Nat. Commun. 2024, 15, 3154. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Sun, W.; Qin, Z.; Zhang, W.; Yu, Y.; Li, T.; Zhang, Q.; Wang, G.; Yu, L.; Wang, Y.; et al. The Role of China’s Terrestrial Carbon Sequestration 2010–2060 in Offsetting Energy-Related CO2 Emissions. Natl. Sci. Rev. 2022, 9, nwac057. [Google Scholar] [CrossRef]
- Tang, X.; Zhao, X.; Bai, Y.; Tang, Z.; Wang, W.; Zhao, Y.; Wan, H.; Xie, Z.; Shi, X.; Wu, B.; et al. Carbon Pools in China’s Terrestrial Ecosystems: New Estimates Based on an Intensive Field Survey. Proc. Natl. Acad. Sci. USA 2018, 115, 4021–4026. [Google Scholar] [CrossRef]
- Shang, R.; Chen, J.M.; Xu, M.; Lin, X.; Li, P.; Yu, G.; He, N.; Xu, L.; Gong, P.; Liu, L.; et al. China’s Current Forest Age Structure Will Lead to Weakened Carbon Sinks in the near Future. Innovation 2023, 4, 100515. [Google Scholar] [CrossRef]
- Xie, X.; Wang, Q.; Dai, L.; Su, D.; Wang, X.; Qi, G.; Ye, Y. Application of China’s National Forest Continuous Inventory Database. Environ. Manag. 2011, 48, 1095–1106. [Google Scholar] [CrossRef] [PubMed]
- Zeng, W.; Tomppo, E.; Healey, S.P.; Gadow, K.V. The National Forest Inventory in China: History-Results-International Context. For. Ecosyst. 2015, 2, 23. [Google Scholar] [CrossRef]
- Fang, N.; Yao, L.; Wu, D.; Zheng, X.; Luo, S. Assessment of Forest Ecological Function Levels Based on Multi-Source Data and Machine Learning. Forests 2023, 14, 1630. [Google Scholar] [CrossRef]
- Fang, G.; Xu, H.; Yang, S.-I.; Lou, X.; Fang, L. Synergistic Use of Sentinel-1, Sentinel-2, and Landsat 8 in Predicting Forest Variables. Ecol. Indic. 2023, 151, 110296. [Google Scholar] [CrossRef]
- Huang, H.; Wu, D.; Fang, L.; Zheng, X. Comparison of Multiple Machine Learning Models for Estimating the Forest Growing Stock in Large-Scale Forests Using Multi-Source Data. Forests 2022, 13, 1471. [Google Scholar] [CrossRef]
- McCombs, J.W.; Roberts, S.D.; Evans, D.L. Influence of Fusing Lidar and Multispectral Imagery on Remotely Sensed Estimates of Stand Density and Mean Tree Height in a Managed Loblolly Pine Plantation. For. Sci. 2003, 49, 457–466. [Google Scholar] [CrossRef]
- Wilkes, P.; Jones, S.; Suarez, L.; Mellor, A.; Woodgate, W.; Soto-Berelov, M.; Haywood, A.; Skidmore, A. Mapping Forest Canopy Height Across Large Areas by Upscaling ALS Estimates with Freely Available Satellite Data. Remote Sens. 2015, 7, 12563–12587. [Google Scholar] [CrossRef]
- Su, Y.; Ma, Q.; Guo, Q. Fine-Resolution Forest Tree Height Estimation across the Sierra Nevada through the Integration of Spaceborne LiDAR, Airborne LiDAR, and Optical Imagery. Int. J. Digit. Earth 2017, 10, 307–323. [Google Scholar] [CrossRef]
- García, M.; Saatchi, S.; Ustin, S.; Balzter, H. Modelling Forest Canopy Height by Integrating Airborne LiDAR Samples with Satellite Radar and Multispectral Imagery. Int. J. Appl. Earth Obs. Geoinf. 2018, 66, 159–173. [Google Scholar] [CrossRef]
- Lin, X.; Shang, R.; Chen, J.M.; Zhao, G.; Zhang, X.; Huang, Y.; Yu, G.; He, N.; Xu, L.; Jiao, W. High-Resolution Forest Age Mapping Based on Forest Height Maps Derived from GEDI and ICESat-2 Space-Borne Lidar Data. Agric. For. Meteorol. 2023, 339, 109592. [Google Scholar] [CrossRef]
- Lefsky, M.A. A Global Forest Canopy Height Map from the Moderate Resolution Imaging Spectroradiometer and the Geoscience Laser Altimeter System. Geophys. Res. Lett. 2010, 37, 2010GL043622. [Google Scholar] [CrossRef]
- Costa, E.A.; Hess, A.F.; Finger, C.A.G.; Schons, C.T.; Klein, D.R.; Barbosa, L.O.; Borsoi, G.A.; Liesenberg, V.; Bispo, P.D.C. Enhancing Height Predictions of Brazilian Pine for Mixed, Uneven-Aged Forests Using Artificial Neural Networks. Forests 2022, 13, 1284. [Google Scholar] [CrossRef]
- Huang, H.; Liu, C.; Wang, X.; Biging, G.S.; Chen, Y.; Yang, J.; Gong, P. Mapping Vegetation Heights in China Using Slope Correction ICESat Data, SRTM, MODIS-Derived and Climate Data. ISPRS J. Photogramm. Remote Sens. 2017, 129, 189–199. [Google Scholar] [CrossRef]
- Liu, X.; Su, Y.; Hu, T.; Yang, Q.; Liu, B.; Deng, Y.; Tang, H.; Tang, Z.; Fang, J.; Guo, Q. Neural Network Guided Interpolation for Mapping Canopy Height of China’s Forests by Integrating GEDI and ICESat-2 Data. Remote Sens. Environ. 2022, 269, 112844. [Google Scholar] [CrossRef]
- Brunsdon, C.; Fotheringham, A.S.; Charlton, M.E. Geographically Weighted Regression: A Method for Exploring Spatial Nonstationarity. Geogr. Anal. 1996, 28, 281–298. [Google Scholar] [CrossRef]
- Du, Z.; Wang, Z.; Wu, S.; Zhang, F.; Liu, R. Geographically Neural Network Weighted Regression for the Accurate Estimation of Spatial Non-Stationarity. Int. J. Geogr. Inf. Sci. 2020, 34, 1353–1377. [Google Scholar] [CrossRef]
- Tu, J. Spatially Varying Relationships between Land Use and Water Quality across an Urbanization Gradient Explored by Geographically Weighted Regression. Appl. Geogr. 2011, 31, 376–392. [Google Scholar] [CrossRef]
- Wang, Q.; Ni, J.; Tenhunen, J. Application of a Geographically-weighted Regression Analysis to Estimate Net Primary Production of Chinese Forest Ecosystems. Glob. Ecol. Biogeogr. 2005, 14, 379–393. [Google Scholar] [CrossRef]
- Liu, H.; Fu, Y.; Pan, J.; Wang, G.; Hu, K. Biomass Spatial Pattern and Driving Factors of Different Vegetation Types of Public Welfare Forests in Hunan Province. Forests 2023, 14, 1061. [Google Scholar] [CrossRef]
- Chen, L.; Ren, C.; Zhang, B.; Wang, Z.; Xi, Y. Estimation of Forest Above-Ground Biomass by Geographically Weighted Regression and Machine Learning with Sentinel Imagery. Forests 2018, 9, 582. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, Y.; Jia, W.; Wang, F.; Guo, H.; Ao, Z. Research on the Temporal and Spatial Distributions of Standing Wood Carbon Storage Based on Remote Sensing Images and Local Models. Forests 2022, 13, 346. [Google Scholar] [CrossRef]
- Chen, F.-S.; Niklas, K.J.; Liu, Y.; Fang, X.-M.; Wan, S.-Z.; Wang, H. Nitrogen and Phosphorus Additions Alter Nutrient Dynamics but Not Resorption Efficiencies of Chinese Fir Leaves and Twigs Differing in Age. Tree Physiol. 2015, 35, 1106–1117. [Google Scholar] [CrossRef] [PubMed]
- Zhejiang Provincial Forestry Department. Technical Regulations of Forest Resources Planning and Design Survey in Zhejiang Province (in Chinese); Zhejiang Provincial Forestry Department: Hangzhou, China, 2014. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- George, C.S.; Sumathi, B. Grid Search Tuning of Hyperparameters in Random Forest Classifier for Customer Feedback Sentiment Prediction. IJACSA 2020, 11. [Google Scholar] [CrossRef]
- Rey, S.J.; Anselin, L. PySAL: A Python Library of Spatial Analytical Methods. In Handbook of Applied Spatial Analysis; Fischer, M.M., Getis, A., Eds.; Springer Berlin Heidelberg: Berlin/Heidelberg, Germany, 2010; pp. 175–193. ISBN 978-3-642-03646-0. [Google Scholar]
- Oshan, T.; Li, Z.; Kang, W.; Wolf, L.; Fotheringham, A. Mgwr: A Python Implementation of Multiscale Geographically Weighted Regression for Investigating Process Spatial Heterogeneity and Scale. IJGI 2019, 8, 269. [Google Scholar] [CrossRef]
- Wu, S.; Sun, Y.; Jia, W.; Wang, F.; Lu, S.; Zhao, H. Estimation of Above-Ground Carbon Storage and Light Saturation Value in Northeastern China’s Natural Forests Using Different Spatial Regression Models. Forests 2023, 14, 1970. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, K.; Xing, X.; Guo, H.; Zhang, W. On Spatial Effects in Geographical Analysis. Acta Geogr. Sin. 2023, 78, 517–531. [Google Scholar]
- Fotheringham, A.S.; Brunsdon, C. Local Forms of Spatial Analysis. Geogr. Anal. 1999, 31, 340–358. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Yang, W.; Kang, W. Multiscale Geographically Weighted Regression (MGWR). Ann. Am. Assoc. Geogr. 2017, 107, 1247–1265. [Google Scholar] [CrossRef]
- Suryowati, K.; Ranggo, M.O.; Bekti, R.D.; Sutanta, E.; Riswanto, E. Geographically Weighted Regression Using Fixed and Adaptive Gaussian Kernel Weighting for Maternal Mortality Rate Analysis. In Proceedings of the 2021 3rd International Conference on Electronics Representation and Algorithm (ICERA), Yogyakarta, Indonesia, 29 July 2021; pp. 115–120. [Google Scholar]
- Haining, R.; Zhang, J. Spatial Data Analysis: Theory and Practice; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Junttila, V.; Laine, M. Bayesian Principal Component Regression Model with Spatial Effects for Forest Inventory Variables under Small Field Sample Size. Remote Sens. Environ. 2017, 192, 45–57. [Google Scholar] [CrossRef]
- Han, N.; Du, H.; Zhou, G.; Xu, X.; Cui, R.; Gu, C. Spatiotemporal Heterogeneity of Moso Bamboo Aboveground Carbon Storage with Landsat Thematic Mapper Images: A Case Study from Anji County, China. Int. J. Remote Sens. 2013, 34, 4917–4932. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | FMI Variables | Description |
|---|---|---|
| 1 | elevation | average elevation within sub-compartments, recorded in meters, extracted from Digital Elevation Models (DEM) |
| 2 | aspect | categorical variable with nine aspects: east, south, west, north, northeast, southeast, northwest, southwest, and no aspect |
| 3 | slope position | categorical variable with ridge, upper, middle, lower, valley, flat, and full slope |
| 4 | slope | average slope within sub-compartments, recorded in degree of angle, extracted from Digital Elevation Models (DEM) |
| 5 | SLT | average soil layer thickness within sub-compartments, recorded in centimeters |
| 6 | humus layer thickness | categorical variable, divided into thick, medium, and thin three grades, less than 2 cm is defined as thin grade, higher than 5 cm is defined as thick grade |
| 7 | site quality class | categorical variable, according to the terrain characteristics, soil, and other natural environmental factors at the location of the plot, the forest land quality was evaluated into 5 levels |
| 8 | forest protection grade | categorical variable, divided into 3 levels according to county-level forest protection planning |
| 9 | understory species | according to the vegetation type of shrub layer and herbaceous layer under the tree layer, the understory species are divided into 8 categories, including non-vegetation, grass, straw, etc. |
| 10 | UH | average height of the understory, recorded in meters |
| 11 | forest structure | categorical variable, forest structure is divided into complete structure, relatively complete structure, and simple structure according to whether it includes tree layer, underwood layer, and ground cover layer |
| 12 | origin | According to the development pattern of the stand, it is divided into two major categories and 7 subclasses |
| 13 | tree species composition | When there is only one tree species (group) in sub-compartments, only the tree name is recorded. When multiple tree species are mixed, use the ten-point method to record and write the dominant tree species first. This study took Chinese fir as the research object, so this variable was divided into two categories: pure forest and mixed forest. |
| 14 | average age | average age of dominant tree species |
| 15 | TH | average tree height of dominant species, recorded in meters |
| Selected Variables | VIFs |
|---|---|
| elevation | 2.2023 |
| slope | 2.3225 |
| SLT | 5.1114 |
| UH | 4.3566 |
| average age | 5.0030 |
| Model | MAE | RMSE | R2 | |
|---|---|---|---|---|
| OLS | 1.3785 | 1.7459 | 0.6497 | 0.6496 |
| RF | 0.9524 | 1.3236 | 0.7987 | 0.7986 |
| GWR | 0.9305 | 1.2754 | 0.8129 | 0.8128 |
| Parameter Estimates | Mean | STD | Median |
|---|---|---|---|
| Intercept | −0.1243 | 29.0739 | 0.05119 |
| parameter of elevation | −0.1830 | 31.1533 | −0.0117 |
| parameter of slope | −0.0268 | 2.2402 | −0.0033 |
| parameter of SLT | 0.0406 | 1.3076 | 0.0278 |
| parameter of UH | 0.0098 | 5.6540 | 0.0168 |
| parameter of average age | 0.8707 | 0.3085 | 0.8626 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, X.; Wang, H.; Dong, C.; Lou, X.; Wu, D.; Fang, L.; Dai, D.; Xu, L.; Xue, X. Tree Height Estimation of Chinese Fir Forests Based on Geographically Weighted Regression and Forest Survey Data. Forests 2024, 15, 1315. https://doi.org/10.3390/f15081315
Zheng X, Wang H, Dong C, Lou X, Wu D, Fang L, Dai D, Xu L, Xue X. Tree Height Estimation of Chinese Fir Forests Based on Geographically Weighted Regression and Forest Survey Data. Forests. 2024; 15(8):1315. https://doi.org/10.3390/f15081315
Chicago/Turabian StyleZheng, Xinyu, Hao Wang, Chen Dong, Xiongwei Lou, Dasheng Wu, Luming Fang, Dan Dai, Liuchang Xu, and Xingyu Xue. 2024. "Tree Height Estimation of Chinese Fir Forests Based on Geographically Weighted Regression and Forest Survey Data" Forests 15, no. 8: 1315. https://doi.org/10.3390/f15081315
APA StyleZheng, X., Wang, H., Dong, C., Lou, X., Wu, D., Fang, L., Dai, D., Xu, L., & Xue, X. (2024). Tree Height Estimation of Chinese Fir Forests Based on Geographically Weighted Regression and Forest Survey Data. Forests, 15(8), 1315. https://doi.org/10.3390/f15081315