
YOLOTree-Individual Tree Spatial Positioning and Crown Volume Calculation Using UAV-RGB Imagery and LiDAR Data

 ,
,  and
and
Abstract
:1. Introduction
2. Related Work
2.1. The Development of Target Detection Method
2.2. The Development of Point Cloud Method
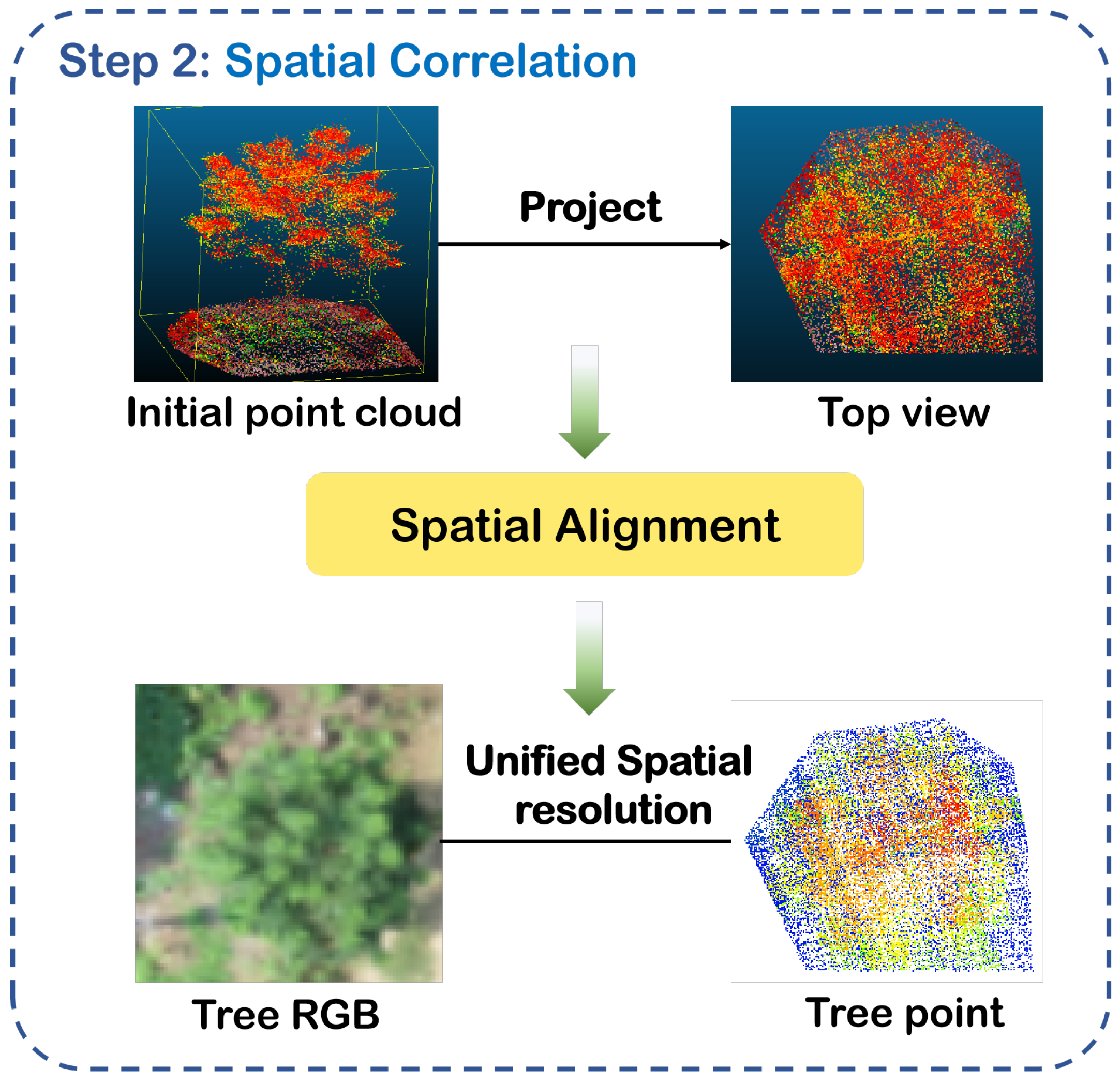
3. The Proposed Work
3.1. Our Work
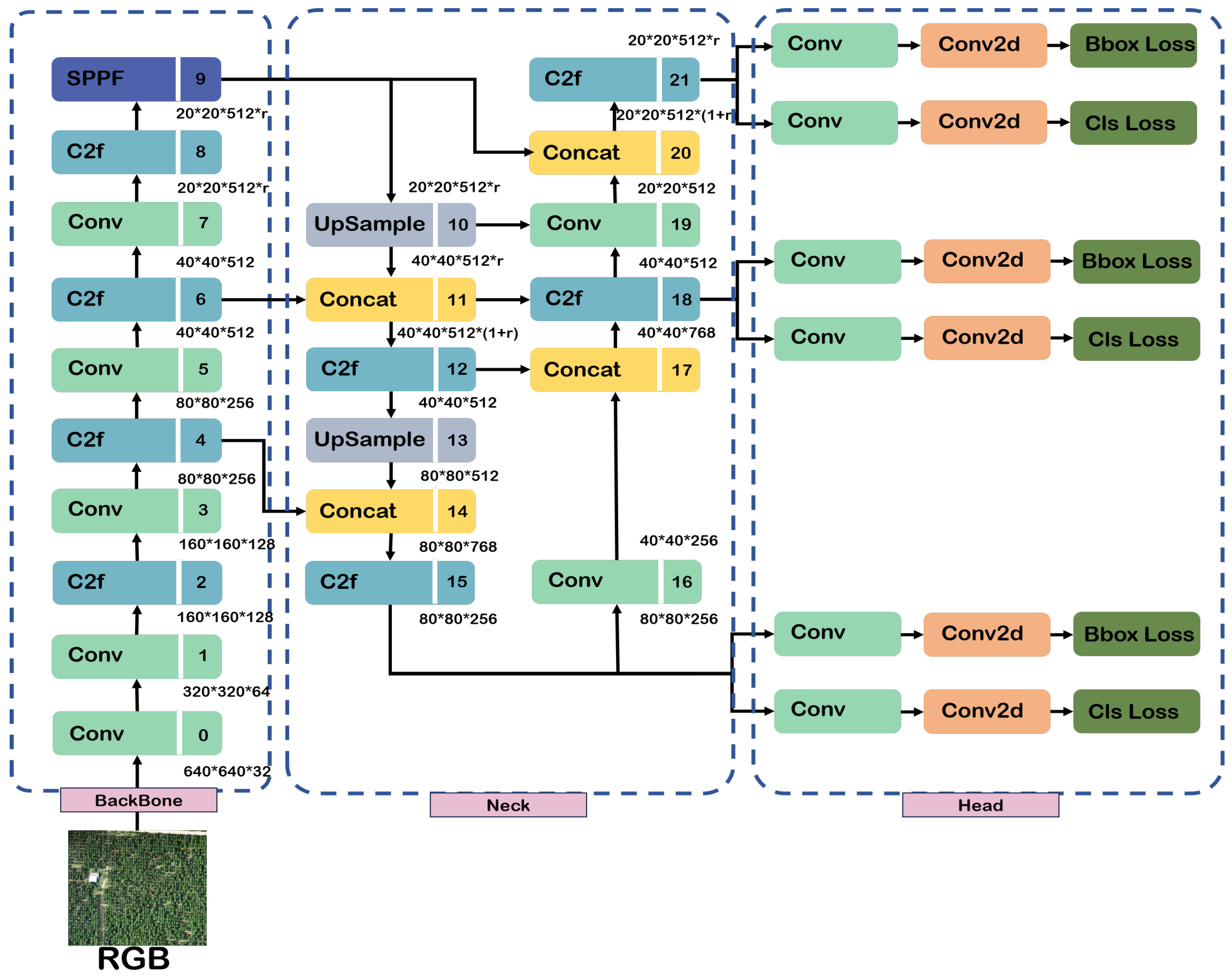
3.2. The Overview of YOLOv8
3.3. Overview of Proposed YOLOTree
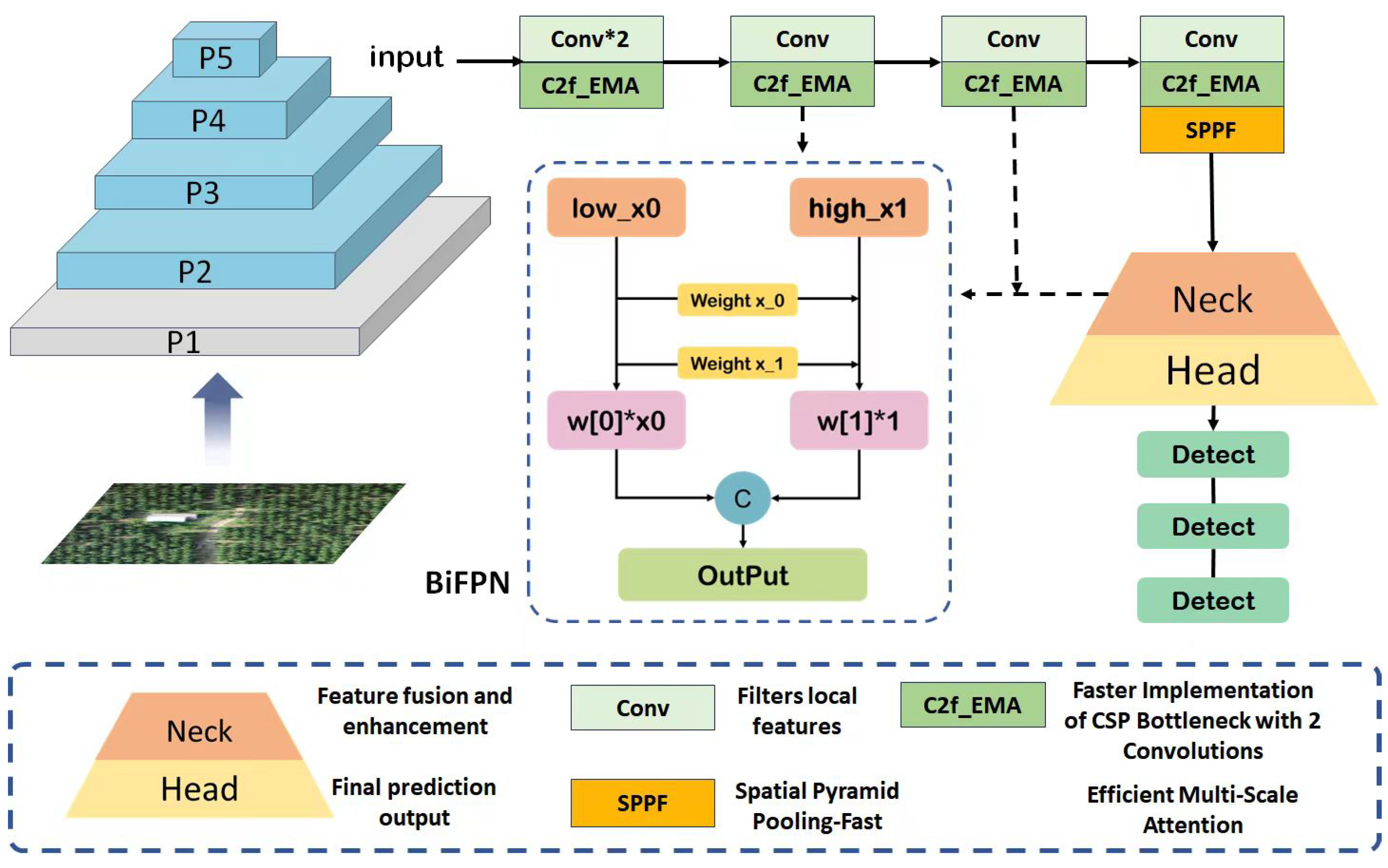
3.4. Multiscale Feature Fusion
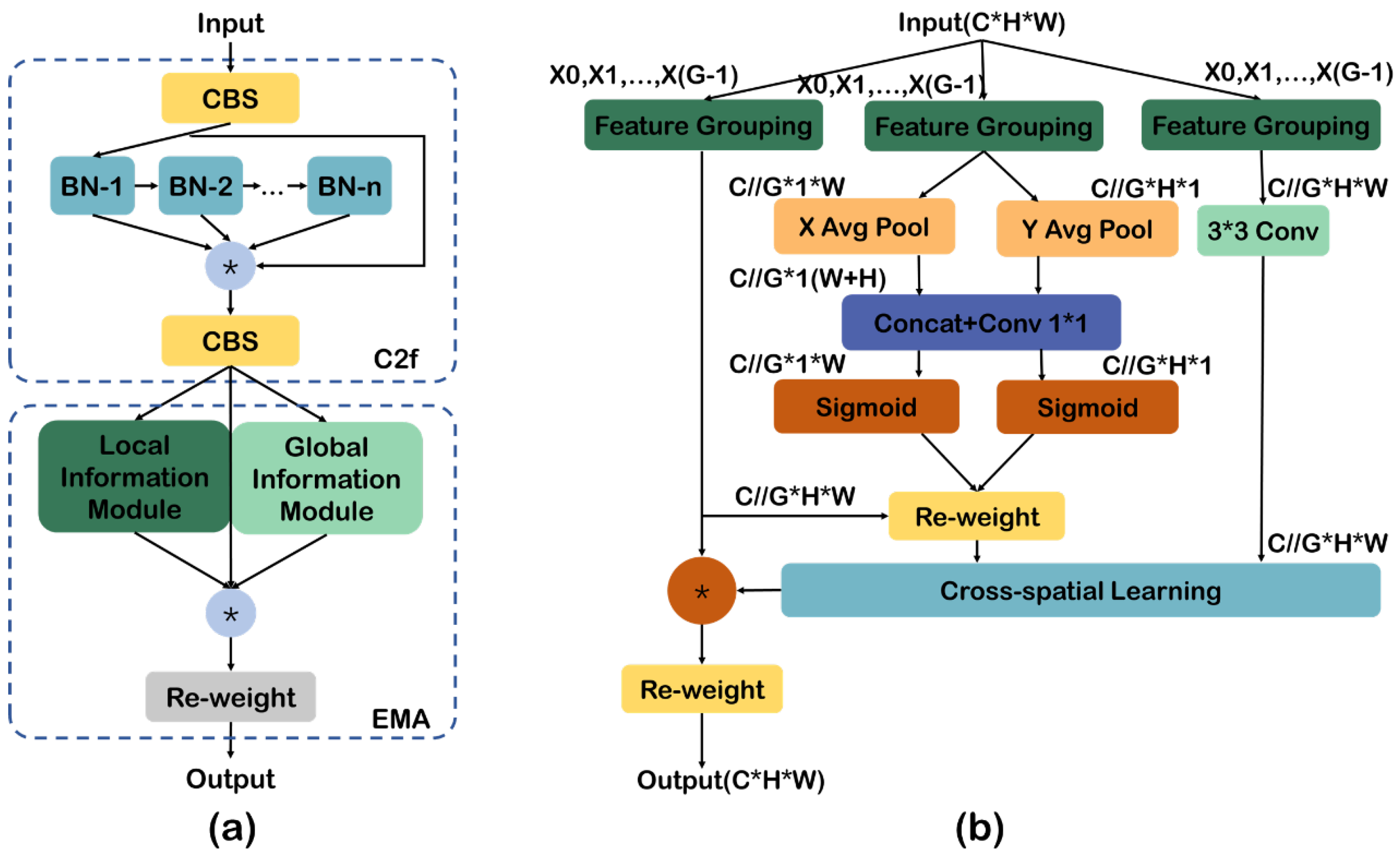
3.5. The C2F _EMA Module
- Two parallel subnetworks process the input feature map. Each of these subnetworks contains a 1 × 1 convolution layer that performs convolution operations on the feature map of each branch, adjusting the channel weights.
- Global average pooling is applied to each grouped feature map in both horizontal and vertical dimensions to obtain two sets of vectors. The aim is to aggregate spatial dimension information into a single vector to capture global spatial information. The vectors obtained from horizontal and vertical pooling are then concatenated to form a new feature vector. This new feature vector combines global information from both horizontal and vertical directions.
- A 1 × 1 convolution is applied to the concatenated feature vector to adjust its dimensions, generate new feature representations, and perform a Softmax operation to normalize the weights.
- The output features of the two parallel branches are further processed and aggregated. The aggregated feature map contains both global and local information from the two parallel branches.
4. Experiments
4.1. Experiments Details and Datasets
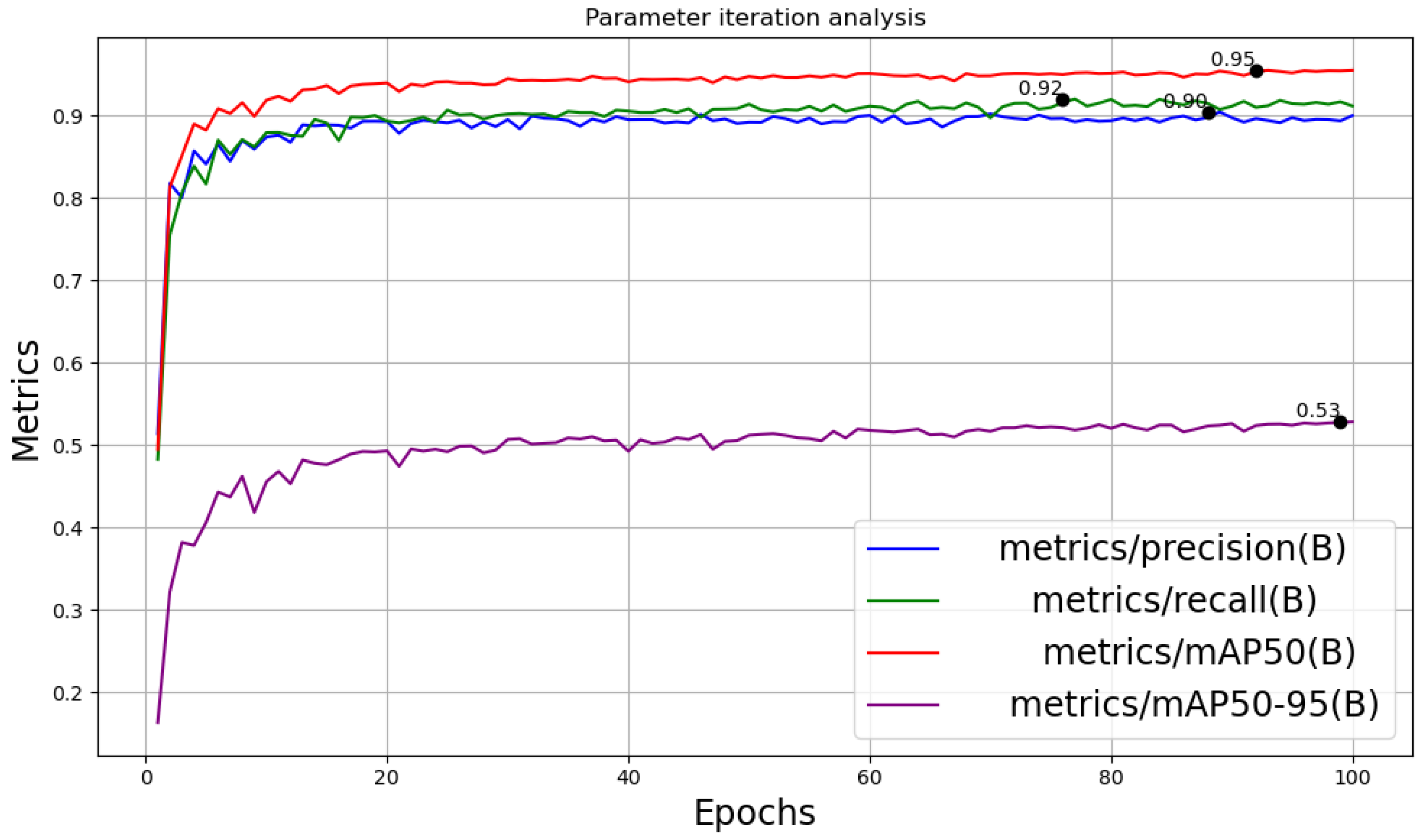
4.2. Quantitative Comparison Results
4.3. Visualization Comparison
5. Application
5.1. Modeling of the Canopy Volume Calculation for Catalpa Trees
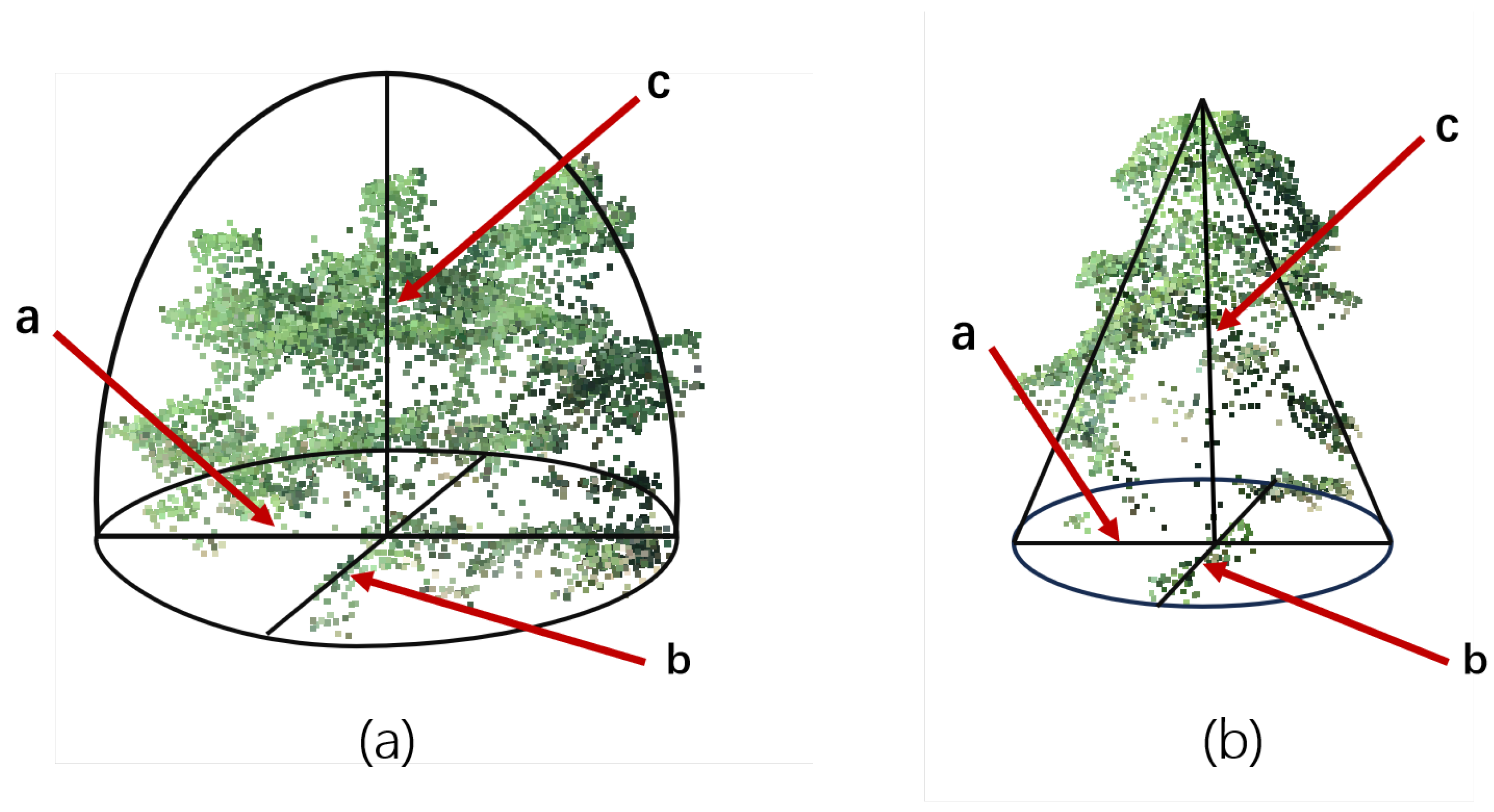
5.2. Existing Point Cloud Volume Calculation Methods and Error Analysis
5.3. Visualisation and Quantitative Analysis of Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, Y.; Lan, S.; Fan, X.; Tjahjadi, T.; Jin, S.; Cao, L. A dual-branch weakly supervised learning based network for accurate mapping of woody vegetation from remote sensing images. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103499. [Google Scholar] [CrossRef]
- Xu, S.; Zhou, K.; Sun, Y.; Yun, T. Separation of Wood and Foliage for Trees From Ground Point Clouds Using a Novel Least-Cost Path Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6414–6425. [Google Scholar] [CrossRef]
- de Paula Pires, R.; Olofsson, K.; Persson, H.J.; Lindberg, E.; Holmgren, J. Individual tree detection and estimation of stem attributes with mobile laser scanning along boreal forest roads. ISPRS J. Photogramm. Remote Sens. 2022, 187, 211–224. [Google Scholar] [CrossRef]
- Wu, Y.; Yang, H.; Mao, Y. Detection of the Pine Wilt Disease Using a Joint Deep Object Detection Model Based on Drone Remote Sensing Data. Forests 2024, 15, 869. [Google Scholar] [CrossRef]
- de Oliveira, L.E.; Yamasaki, T.N.; Janzen, J.G.; Gualtieri, C. Effects of vegetation density on flow, mass exchange and sediment transport in lateral cavities. J. Hydrol. 2024, 632, 130910. [Google Scholar] [CrossRef]
- Luo, T.; Gao, W.; Belotserkovsky, A.; Nedzved, A.; Deng, W.; Ye, Q.; Fu, L.; Chen, Q.; Ma, W.; Xu, S. VrsNet—Density map prediction network for individual tree detection and counting from UAV images. Int. J. Appl. Earth Obs. Geoinf. 2024, 131, 103923. [Google Scholar] [CrossRef]
- Xu, S.; Sun, X.; Yun, J.; Wang, H. A New Clustering-Based Framework to the Stem Estimation and Growth Fitting of Street Trees From Mobile Laser Scanning Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3240–3250. [Google Scholar] [CrossRef]
- Zhu, X.; Wang, R.; Shi, W.; Liu, X.; Ren, Y.; Xu, S.; Wang, X. Detection of Pine-Wilt-Disease-Affected Trees Based on Improved YOLO v7. Forests 2024, 15, 691. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2014, arXiv:1311.2524. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Yuan, W.; Gu, X.; Dai, Z.; Zhu, S.; Tan, P. NeW CRFs: Neural Window Fully-connected CRFs for Monocular Depth Estimation. arXiv 2022, arXiv:2203.01502. [Google Scholar]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar] [CrossRef]
- Fu, L.; Zhang, D.; Ye, Q. Recurrent Thrifty Attention Network for Remote Sensing Scene Recognition. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8257–8268. [Google Scholar] [CrossRef]
- Yu, Y.; Fu, L.; Cheng, Y.; Ye, Q. Multi-view distance metric learning via independent and shared feature subspace with applications to face and forest fire recognition, and remote sensing classification. Knowl.-Based Syst. 2022, 243, 108350. [Google Scholar] [CrossRef]
- Wen, C.; Sun, X.; Li, J.; Wang, C.; Guo, Y.; Habib, A. A deep learning framework for road marking extraction, classification and completion from mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2019, 147, 178–192. [Google Scholar] [CrossRef]
- Xu, S.; Wang, R.; Zheng, H. Road Curb Extraction From Mobile LiDAR Point Clouds. IEEE Trans. Geosci. Remote Sens. 2017, 55, 996–1009. [Google Scholar] [CrossRef]
- Meng, X.; Wang, T.; Cheng, D.; Su, W.; Yao, P.; Ma, X.; He, M. Enhanced Point Cloud Slicing Method for Volume Calculation of Large Irregular Bodies: Validation in Open-Pit Mining. Remote Sens. 2023, 15, 5006. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar] [CrossRef]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. arXiv 2020, arXiv:1911.09070. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023. [Google Scholar] [CrossRef]
- Moorthy, I.; Miller, J.R.; Hu, B.; Jimenez Berni, J.A.; Zarco-Tejada, P.J.; Li, Q. Extracting tree crown properties from ground-based scanning laser data. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–28 July 2007; pp. 2830–2832. [Google Scholar] [CrossRef]
- Hao, W.; Li, Y.; Xie Hong Wei, P.D.; Gao, J.; Zhao Zhang, R. A Voxel-Based Multiview Point Cloud Refinement Method via Factor Graph Optimization. In Proceedings of the Pattern Recognition and Computer Vision 2023, Xiamen, China, 13–15 October 2023; pp. 234–245. [Google Scholar]
- Yun, T.; Li, J.; Ma, L.; Zhou, J.; Wang, R.; Eichhorn, M.P.; Zhang, H. Status, advancements and prospects of deep learning methods applied in forest studies. Int. J. Appl. Earth Obs. Geoinf. 2024, 131, 103938. [Google Scholar] [CrossRef]
- Wang, Q.; Hu, C.; Wang, H.; Wang, R.; Xie, Y.; Zhao, Y. Semantic segmentation of urban land classes using a multi-scale dataset. Int. J. Remote Sens. 2024, 45, 653–675. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Dataset | Precision/% | Recall/% | mAP50/% | mAP50-95/% |
|---|---|---|---|---|---|
| YOLOv3 | TreeLD | 88.77 | 92.82 | 93.23 | 46.60 |
| YOLOv5 | 90.44 | 91.78 | 95.58 | 51.95 | |
| YOLOv7 | 89.84 | 90.8 | 94.73 | 49.91 | |
| YOLOv8 | 89.71 | 91.22 | 95.33 | 52.93 | |
| YOLOv9 | 90.13 | 90.32 | 95.04 | 53.96 | |
| Faster-RCNN | 83.94 | 94.96 | 83.94 | / | |
| YOLOTree(ours) | 90.52 | 91.14 | 95.53 | 52.84 | |
| YOLOv3 | CarPK | 97.34 | 94.31 | 97.65 | 68.64 |
| YOLOv5 | 98.27 | 95.75 | 98.50 | 68.20 | |
| YOLOv7 | 98.41 | 96.65 | 99.36 | 70.76 | |
| YOLOv8 | 98.98 | 97.69 | 99.38 | 81.35 | |
| YOLOv9 | 98.73 | 98.27 | 99.40 | 83.04 | |
| Faster-RCNN | 88.96 | 91.77 | 92.03 | / | |
| YOLOTree(ours) | 98.93 | 98.35 | 99.22 | 83.13 | |
| YOLOv5 | VisDrone | 34.07 | 34.07 | 32.66 | 17.81 |
| YOLOv8 | 43.29 | 31.70 | 31.83 | 18.37 | |
| YOLOv9 | 55.13 | 42.65 | 44.53 | 27.13 | |
| YOLOTree(ours) | 44.08 | 32.00 | 32.11 | 18.59 |
| Model | E_neck | E_detect | E_backbone | BiFPN | Precision/% | Recall/% | mAP50/% | mAP50-95/% | Parameters/Mb | GFLOPs |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv8n | 89.8 | 91.4 | 95.3 | 52.9 | 3.0 | 8.1 | ||||
| YOLOv8s | 90.5 | 91.0 | 95.6 | 53.2 | 11.1 | 28.4 | ||||
| YOLOv8m | 89.9 | 91.4 | 95.4 | 53.2 | 25.8 | 78.7 | ||||
| YOLOv8n | ✓ | 89.7 | 91.2 | 95.3 | 52.9 | 3.0 | 8.3 | |||
| YOLOv8s | ✓ | 89.6 | 90.9 | 95.1 | 52.8 | 11.2 | 29.3 | |||
| YOLOv8n | ✓ | 89.5 | 91.0 | 95.0 | 52.5 | 3.0 | 8.2 | |||
| YOLOv8n | ✓ | 90.5 | 90.5 | 95.3 | 52.7 | 3.0 | 8.4 | |||
| YOLOTree | ✓ | ✓ | 90.5 | 91.1 | 95.5 | 52.8 | 3.0 | 8.4 |
| Tree | V(2.5D) | V(Left) | V(Right) | V(GT) | V(Ours) | V(rs) |
|---|---|---|---|---|---|---|
| 1 | 46.643 | 36.416 | 14.704 | 25.56 | 28.42 | 27.68 |
| 2 | 20.566 | 17.024 | 6.776 | 11.9 | 9.53 | 6.37 |
| 3 | 38.43 | 26.688 | 11.304 | 18.996 | 20.88 | 14.93 |
| 4 | 31.499 | 22.08 | 9.256 | 15.668 | 19.47 | 12.84 |
| 5 | 26.583 | 19.584 | 7.704 | 13.644 | 15.16 | 12.44 |
| 6 | 18.417 | 12.864 | 5.488 | 9.176 | 13.67 | 15.04 |
| 7 | 30.51 | 22.08 | 9.432 | 15.756 | 14.85 | 10.32 |
| 8 | 20.573 | 14.848 | 6.104 | 10.476 | 11.38 | 9.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, T.; Rao, S.; Ma, W.; Song, Q.; Cao, Z.; Zhang, H.; Xie, J.; Wen, X.; Gao, W.; Chen, Q.; et al. YOLOTree-Individual Tree Spatial Positioning and Crown Volume Calculation Using UAV-RGB Imagery and LiDAR Data. Forests 2024, 15, 1375. https://doi.org/10.3390/f15081375
Luo T, Rao S, Ma W, Song Q, Cao Z, Zhang H, Xie J, Wen X, Gao W, Chen Q, et al. YOLOTree-Individual Tree Spatial Positioning and Crown Volume Calculation Using UAV-RGB Imagery and LiDAR Data. Forests. 2024; 15(8):1375. https://doi.org/10.3390/f15081375
Chicago/Turabian StyleLuo, Taige, Shuyu Rao, Wenjun Ma, Qingyang Song, Zhaodong Cao, Huacheng Zhang, Junru Xie, Xudong Wen, Wei Gao, Qiao Chen, and et al. 2024. "YOLOTree-Individual Tree Spatial Positioning and Crown Volume Calculation Using UAV-RGB Imagery and LiDAR Data" Forests 15, no. 8: 1375. https://doi.org/10.3390/f15081375