
Object Detection in Remote Sensing Images of Pine Wilt Disease Based on Adversarial Attacks and Defenses

 ,
,
Abstract
1. Introduction
- The authors propose a forward-looking network architecture, YOLOv5-DRCS, which is unique in its ability to effectively deal with images that are subjected to adversarial perturbations. In the stage of feature map extraction, a self-adaptive filtering method for adversarial samples is introduced into the model, which is based on the residual shrinkage subnetwork, so that the threshold can be self-adaptively calculated to achieve effective denoising. At the same time, in the process of feature layer fusion, the SimAM attention mechanism is integrated to enhance the global attention and feature extraction ability of the model.
- Compared with the traditional defense method of adversarial training, the defense strategy proposed in this paper can optimize the interior of the model. The advantages of this strategy are the ease of deployment, there being no need to incur significant counter-training costs, and there being no need to introduce additional external modules. By modifying the internal modules, the method proposed in this paper greatly reduces the implementation cost and complexity while maintaining the model performance.
- To verify the validity of the proposed model, the remote sensing image dataset of pine wood nematode disease (PWT) was used and controlled experiments were conducted at different depths of the model. When adding adversarial samples with attack coefficients ϵ ∈ {2,4,6,8} and increasing the proportion of added adversarial samples to 40%, the YOLOv5-DRCS network structure could still maintain high accuracy, with average precisions of 91.4%, 91.5%, 91.0%, and 90.1%, respectively. These results indicate that the model could maintain excellent performance in the face of adversarial samples challenges.
2. Materials and Methods
2.1. Data Collection and Preprocessing
2.2. Adversarial Example Generation
| Algorithm 1: Adversarial Sample Attack Steps |
| Input: Dataset D, Training epochs N, Batch size B, Perturbation bounds |
| for epoch = 1 to N do for random batch do end for end for Output: Dataset |
2.3. Method
2.3.1. Conventional Defense Method
| Algorithm 2: YOLOv5-DRCS Object Detection Framework Pseudocode |
| Data Preparation: Collect remote sensing images of major forestry areas. Preprocessing and Data Fusion: Preprocess all images (e.g., normalization, denoising). Generate attacked dataset based on attack algorithm. Construct YOLOv5-DRCS Model: Soft Threshold Adaptive Filtering: Dynamically remove potential noise and redundant information. Adjust feature maps. Feature Fusion Layer: SimAM attention mechanism. Compute similarity between target and surrounding regions. Model Training: Train YOLOv5-DRCS model using PWD image. Model Evaluation and Optimization: Evaluate model performance on the attacked PWD image test set. Adjust and optimize the model based on evaluation results. |
2.3.2. Adversarial Attack
2.3.3. Adversarial Defense
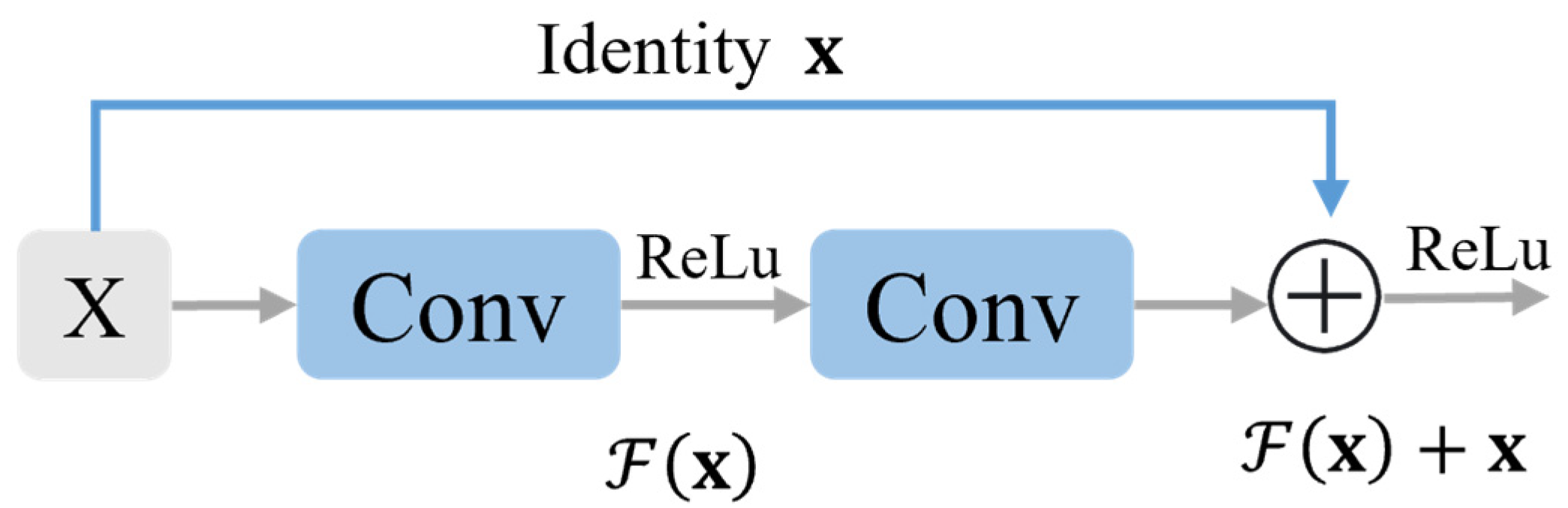
2.3.4. YOLOv5-DRCS
- After a series of convolutional operations, the feature is input into the subnetwork to obtain its absolute value .
- The global average pooling (GAP) is performed on the absolute value of feature to obtain .
- Perform three steps for : Full connection (FC), batch normalization (BN), ReLu activation. Finally, the sigmoid function is used to normalize the output to between zero and one. The coefficient obtained is as follows:where is the characteristic of the c neuron.
- Finally, multiply the resulting coefficient α and to obtain the final estimated threshold :where is the final threshold, and , , and are the width, height, and channel index of feature map , respectively. By employing the aforementioned method, residual shrinkage modules are introduced into residual networks, ensuring that all thresholds are positive and preventing the output from being zero, thus keeping the thresholds within a reasonable range. Finally, the non-important features caused by noise removal are removed based on the threshold, and each output is compared with the corresponding threshold using the following formula to perform soft thresholding processing on the feature map:
3. Results and Discussion
3.1. Experimental Setup and Model Training
3.2. Attack Experiment and Analysis
3.3. Gradient-Weighted Class Activation Mapping Analysis
3.4. Adversarial Training Results
3.5. Model Detection Results Image
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ikegami, M.; Jenkins, T.A. Estimate global risks of a forest disease under current and future climates using species distribution model and simple thermal model—Pine Wilt disease as a model case. For. Ecol. Manag. 2018, 409, 343–352. [Google Scholar] [CrossRef]
- Kuang, J.; Yu, L.; Zhou, Q.; Wu, D.; Ren, L.; Luo, Y. Identification of Pine Wilt Disease-Infested Stands Based on Single- and Multi-Temporal Medium-Resolution Satellite Data. Forests 2024, 15, 596. [Google Scholar] [CrossRef]
- Zhang, X.; Yang, H.; Cai, P.; Chen, G.; Li, X.; Zhu, K. A review on the research progress and methodology of remote sensing for monitoring pine wood nematode disease. J. Agric. Eng. 2022, 18, 184–194. [Google Scholar]
- Li, H.; Wang, Y. Influence of environmental factors on UAV image recognition accuracy for pine wilt disease. For. Res. 2019, 32, 102–110. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Boloor, A.; He, X.; Gill, C.; Vorobeychik, Y.; Zhang, X. Simple Physical Adversarial Examples against End-to-End Autonomous Driving Models. In Proceedings of the 2019 IEEE International Conference on Embedded Software and Systems (ICESS), Las Vegas, NV, USA, 2–3 June 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Frossard, P. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar] [CrossRef]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018—Conference Track Proceedings, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Zhang, H.; Wang, J. Towards Adversarially Robust Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 421–430. [Google Scholar] [CrossRef]
- Wang, J.; Chen, R.F.; Chen, Q.; Li, Y.H.; Zhang, C. Research on Forest Parameter Information Extraction Progress Driven by UAV Remote Sensing Technology. For. Resour. Manag. 2020, 5, 144–151. [Google Scholar]
- Huang, T.; Zhang, Q.; Liu, J.; Hou, R.; Wang, X.; Li, Y. Adversarial attacks on deep-learning-based SAR image target recognition. J. Netw. Comput. Appl. 2020, 162, 102632. [Google Scholar] [CrossRef]
- Yuan, X.; He, P.; Zhu, Q.; Li, X. Adversarial Examples: Attacks and Defenses for Deep Learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2805–2824. [Google Scholar] [CrossRef]
- Best, K.L.; Schmid, J.; Tierney, S.; Awan, J.; Beyene, N.; Holliday, M.A.; Khan, R.; Lee, K. How to Analyze the Cyber Threat from Drones: Background, Analysis Frameworks, and Analysis Tools; Rand Corp.: Santa Monica, CA, USA, 2020. [Google Scholar]
- Kwon, Y.-M. Vulnerability Analysis of the Mavlink Protocol for Unmanned Aerial Vehicles. Master’s Thesis, DGIST, Daegu, Republic of Korea, 2018. [Google Scholar] [CrossRef]
- Highnam, K.; Angstadt, K.; Leach, K.; Weimer, W.; Paulos, A.; Hurley, P. An Uncrewed Aerial Vehicle Attack Scenario and Trustworthy Repair Architecture. In Proceedings of the 2016 46th Annual IEEE/IFIP International Conference on Dependable Systems and Networks Workshop (DSN-W), Toulouse, France, 28 June–1 July 2016; pp. 222–225. [Google Scholar] [CrossRef]
- Syifa, M.; Park, S.J.; Lee, C.W. Detection of the Pine Wilt Disease Tree Candidates for Drone Remote Sensing Using Artificial Intelligence Techniques. Engineering 2020, 6, 919–926. [Google Scholar] [CrossRef]
- Iordache, M.-D.; Mantas, V.; Baltazar, E.; Pauly, K.; Lewyckyj, N. A Machine Learning Approach to Detecting Pine Wilt Disease Using Airborne Spectral Imagery. Remote Sens. 2020, 12, 2280. [Google Scholar] [CrossRef]
- Oide, A.H.; Nagasaka, Y.; Tanaka, K. Performance of machine learning algorithms for detecting pine wilt disease infection using visible color imagery by UAV remote sensing. Remote Sens. Appl. Soc. Environ. 2022, 28, 100869. [Google Scholar] [CrossRef]
- Yu, R.; Luo, Y.; Zhou, Q.; Zhang, X.; Wu, D.; Ren, L. Early detection of pine wilt disease using deep learning algorithms and UAV-based multispectral imagery. For. Ecol. Manag. 2021, 497, 119493. [Google Scholar] [CrossRef]
- Zhang, R.; You, J.; Lee, J. Detecting Pine Trees Damaged by Wilt Disease Using Deep Learning Techniques Applied to Multi-Spectral Images. IEEE Access 2022, 10, 39108–39118. [Google Scholar] [CrossRef]
- Yao, J.; Song, B.; Chen, X.; Zhang, M.; Dong, X.; Liu, H.; Liu, F.; Zhang, L.; Lu, Y.; Xu, C.; et al. Pine-YOLO: A Method for Detecting Pine Wilt Disease in Unmanned Aerial Vehicle Remote Sensing Images. Forests 2024, 15, 737. [Google Scholar] [CrossRef]
- Wu, W.; Zhang, Z.; Zheng, L.; Han, C.; Wang, X.; Xu, J.; Wang, X. Research Progress on the Early Monitoring of Pine Wilt Disease Using Hyperspectral Techniques. Sensors 2020, 20, 3729. [Google Scholar] [CrossRef]
- Li, M.; Li, H.; Ding, X.; Wang, L.; Wang, X.; Chen, F. The Detection of Pine Wilt Disease: A Literature Review. Int. J. Mol. Sci. 2022, 23, 10797. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 39–57. [Google Scholar] [CrossRef]
- Liao, F.; Liang, M.; Dong, Y.; Pang, T.; Hu, X.; Zhu, J. Defense against Adversarial Attacks Using High-Level Representation Guided Denoiser. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Chiang, P.Y.; Curry, M.; Abdelkader, A.; Kumar, A.; Dickerson, J.; Goldstein, T. Detection as regression: Certified object detection with median smoothing. Adv. Neural Inf. Process. Syst. 2020, 33, 1275–1286. [Google Scholar]
- Won, J.; Seo, S.-H.; Bertino, E. A Secure Shuffling Mechanism for White-Box Attack-Resistant Unmanned Vehicles. IEEE Trans. Mob. Comput. 2019, 19, 1023–1039. [Google Scholar] [CrossRef]
- Xu, L.; Zhai, J. DCVAE-adv: A Universal Adversarial Example Generation Method for White and Black Box Attacks. Tsinghua Sci. Technol. 2024, 29, 430–446. [Google Scholar] [CrossRef]
- YShi, Y.; Han, Y.; Hu, Q.; Yang, Y.; Tian, Q. Query-Efficient Black-Box Adversarial Attack With Customized Iteration and Sampling. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2226–2245. [Google Scholar] [CrossRef]
- Li, C.; Wang, H.; Zhang, J.; Yao, W.; Jiang, T. An Approximated Gradient Sign Method Using Differential Evolution for Black-Box Adversarial Attack. IEEE Trans. Evol. Comput. 2022, 26, 976–990. [Google Scholar] [CrossRef]
- Lu, J.; Sibai, H.; Fabry, E. Adversarial examples that fool detectors. arXiv 2017, arXiv:1712.02494. [Google Scholar]
- Chow, K.-H.; Liu, L.; Loper, M.; Bae, J.; Gursoy, M.E.; Truex, S.; Wei, W.; Wu, Y. TOG: Targeted Adversarial Objectness Gradient Attacks on Real-time Object Detection Systems. arXiv 2020, arXiv:2004.04320. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Zhou, Y.; Xie, L.; Yuille, A. Adversarial Examples for Semantic Segmentation and Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1378–1387. [Google Scholar] [CrossRef]
- Wei, X.; Liang, S.; Chen, N.; Cao, X. Transferable Adversarial Attacks for Image and Video Object Detection. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018. [Google Scholar] [CrossRef]
- Wang, J.; Liu, A.; Yin, Z.; Liu, S.; Tang, S.; Liu, X. Dual attention suppression attack: Generate adversarial camouflage in physical world. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2021; pp. 8565–8574. [Google Scholar]
- Shafahi, A.; Najibi, M.; Ghiasi, M.A.; Xu, Z.; Dickerson, J.; Studer, C.; Davis, L.S.; Taylor, G.; Goldstein, T. Adversarial training for free! In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, BC, Canada, 8–14 December 2019; pp. 3353–3364. [Google Scholar]
- Liu, A.; Liu, X.; Yu, H.; Zhang, C.; Liu, Q.; Tao, D. Training Robust Deep Neural Networks via Adversarial Noise Propagation. IEEE Trans. Image Process. 2021, 30, 5769–5781. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.I.; Tian, Q. Adversarial Attack and Defense of YOLO Detectors in Autonomous Driving Scenarios. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 5–9 June 2022; pp. 1011–1017. [Google Scholar] [CrossRef]
- Gu, S.; Rigazio, L. Towards deep neural network architectures robust to adversarial examples. arXiv 2014, arXiv:1412.5068. [Google Scholar]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Uesato, J.; Frossard, P. Robustness via Curvature Regularization, and Vice Versa. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9070–9078. [Google Scholar] [CrossRef]
- Muthukumar, R.; Sulam, J. Adversarial robustness of sparse local lipschitz predictors. arXiv 2022, arXiv:2202.13216. [Google Scholar] [CrossRef]
- Tang, H.; Liang, S.; Yao, D.; Qiao, Y. A visual defect detection for optics lens based on the YOLOv5-C3CA-SPPF network model. Opt. Express 2023, 31, 2628–2643. [Google Scholar] [CrossRef]
- Donoho, D.L. De-noising by soft-thresholding. IEEE Trans. Inf. Theory 1995, 41, 613–627. [Google Scholar] [CrossRef]
- Zhao, M.; Zhong, S.; Fu, X.; Tang, B.; Pecht, M. Deep Residual Shrinkage Networks for Fault Diagnosis. IEEE Trans. Ind. Informatics 2019, 16, 4681–4690. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting Adversarial Attacks with Momentum. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9185–9193. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Chu, J.; Cai, J.; Li, L.; Fan, Y.; Su, B. Bilinear Feature Fusion Convolutional Neural Network for Distributed Tactile Pressure Recognition and Understanding via Visualization. IEEE Trans. Ind. Electron. 2021, 69, 6391–6400. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Sampling Plots | Dead infected Pine Trees |
|---|---|---|
| Training set | 1, 2, 3, 6 | 3488 |
| Validation set | 7 | 743 |
| Test set | 4, 5 | 755 |
| Total | 1, 2, 3, 4, 5, 6, 7 | 4986 |
| Training Parameters | Details |
| Epochs | 150 |
| Image size (pixel) | 320 × 320 |
| batch size | 32 |
| Initial learning rate | 0.01 |
| Final OneCycleLR learning rate | 0.1 |
| Optimization algorithm and parameters | Adam (0.937) |
| Weight decay | 0.0005 |
| Epochs | 150 |
| Experimental Environment | Details |
| Programming language | Python 3.8 |
| Operating system | Windows 11 |
| Deep learning framework | Pytorch 1.11.0 |
| CPU | 22 vCPU AMD EPYC 7T83 64-Core |
| GPU | NVIDIA GeForce RTX 4090 |
| Model | mAP@0.5 | Recall | GFLOPs | FPS | Params (M) |
|---|---|---|---|---|---|
| YOLOv5s | 94.0 | 89.1 | 16.0 | 71.5 | 7.02 |
| YOLOv5m | 89.2 | 81.8 | 47.9 | 40.5 | 20.8 |
| YOLOv5l | 92.2 | 86.3 | 107.7 | 24.1 | 46.1 |
| YOLOv5-DRCS | 93.5 | 86.9 | 15.8 | 69.0 | 7.07 |
| Method | Att. Size | YOLOv5s | YOLOv5m | YOLOv5l | YOLOv5-DRCS |
| FGSM | = 2 | 92.7 | 91.7 | 91.8 | 92.4 |
| = 4 | 88.7 | 88.2 | 90.2 | 92.5 | |
| = 6 | 85.3 | 85.4 | 91.4 | 91.0 | |
| = 8 | 75.9 | 75.2 | 85.5 | 90.1 |
| Method | Att. Size | YOLOv5s | YOLOv5m | YOLOv5l | YOLOv5-DRCS |
|---|---|---|---|---|---|
| FGSM | = 2 | 85.8 | 90.3 | 91.9 | 89.6 |
| = 4 | 81.4 | 86.9 | 87.2 | 89.0 | |
| = 6 | 78.1 | 78.9 | 81.7 | 87.1 | |
| = 8 | 74.1 | 66.3 | 74.0 | 82.1 |
| Method | Att. Size | YOLOv5s | YOLOv5m | YOLOv5l | YOLOv5-DRCS |
|---|---|---|---|---|---|
| FGSM | = 2 | 81.1 | 86.9 | 86.5 | 88.1 |
| = 4 | 77.1 | 80.2 | 86.8 | 86.5 | |
| = 6 | 67.7 | 64.9 | 74.5 | 84.0 | |
| = 8 | 54.0 | 54.5 | 65.8 | 77.2 |
| Method | Att. Size | YOLOv5s | YOLOv5m | YOLOv5l | YOLOv5-DRCS |
|---|---|---|---|---|---|
| I-FGSM | = 2 | 89.2 | 85.5 | 84.1 | 86.7 |
| = 4 | 78.5 | 70.6 | 71.7 | 79.0 | |
| = 6 | 61.9 | 60.4 | 58.3 | 65.8 | |
| = 8 | 45.9 | 50.6 | 47.4 | 47.2 | |
| MI-FGSM | = 2 | 82.9 | 82.6 | 82.0 | 84.2 |
| = 4 | 74.3 | 71.6 | 70.7 | 75.8 | |
| = 6 | 64.8 | 64.0 | 61.4 | 68.3 | |
| = 8 | 50.3 | 48.9 | 46.3 | 52.2 | |
| PGD | = 2 | 78.4 | 72.8 | 73.0 | 78.8 |
| = 4 | 61.5 | 58.1 | 57.4 | 60.0 | |
| = 6 | 43.4 | 51.8 | 47.0 | 51.2 | |
| = 8 | 31.0 | 43.9 | 40.5 | 38.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Chen, W.; Chen, X.; Hu, J.; Su, X.; Ji, Z.; Wu, Y. Object Detection in Remote Sensing Images of Pine Wilt Disease Based on Adversarial Attacks and Defenses. Forests 2024, 15, 1623. https://doi.org/10.3390/f15091623
Li Q, Chen W, Chen X, Hu J, Su X, Ji Z, Wu Y. Object Detection in Remote Sensing Images of Pine Wilt Disease Based on Adversarial Attacks and Defenses. Forests. 2024; 15(9):1623. https://doi.org/10.3390/f15091623
Chicago/Turabian StyleLi, Qing, Wenhui Chen, Xiaohua Chen, Junguo Hu, Xintong Su, Zhuo Ji, and Yingjun Wu. 2024. "Object Detection in Remote Sensing Images of Pine Wilt Disease Based on Adversarial Attacks and Defenses" Forests 15, no. 9: 1623. https://doi.org/10.3390/f15091623
APA StyleLi, Q., Chen, W., Chen, X., Hu, J., Su, X., Ji, Z., & Wu, Y. (2024). Object Detection in Remote Sensing Images of Pine Wilt Disease Based on Adversarial Attacks and Defenses. Forests, 15(9), 1623. https://doi.org/10.3390/f15091623