
LD-YOLO: A Lightweight Dynamic Forest Fire and Smoke Detection Model with Dysample and Spatial Context Awareness Module


Abstract
1. Introduction
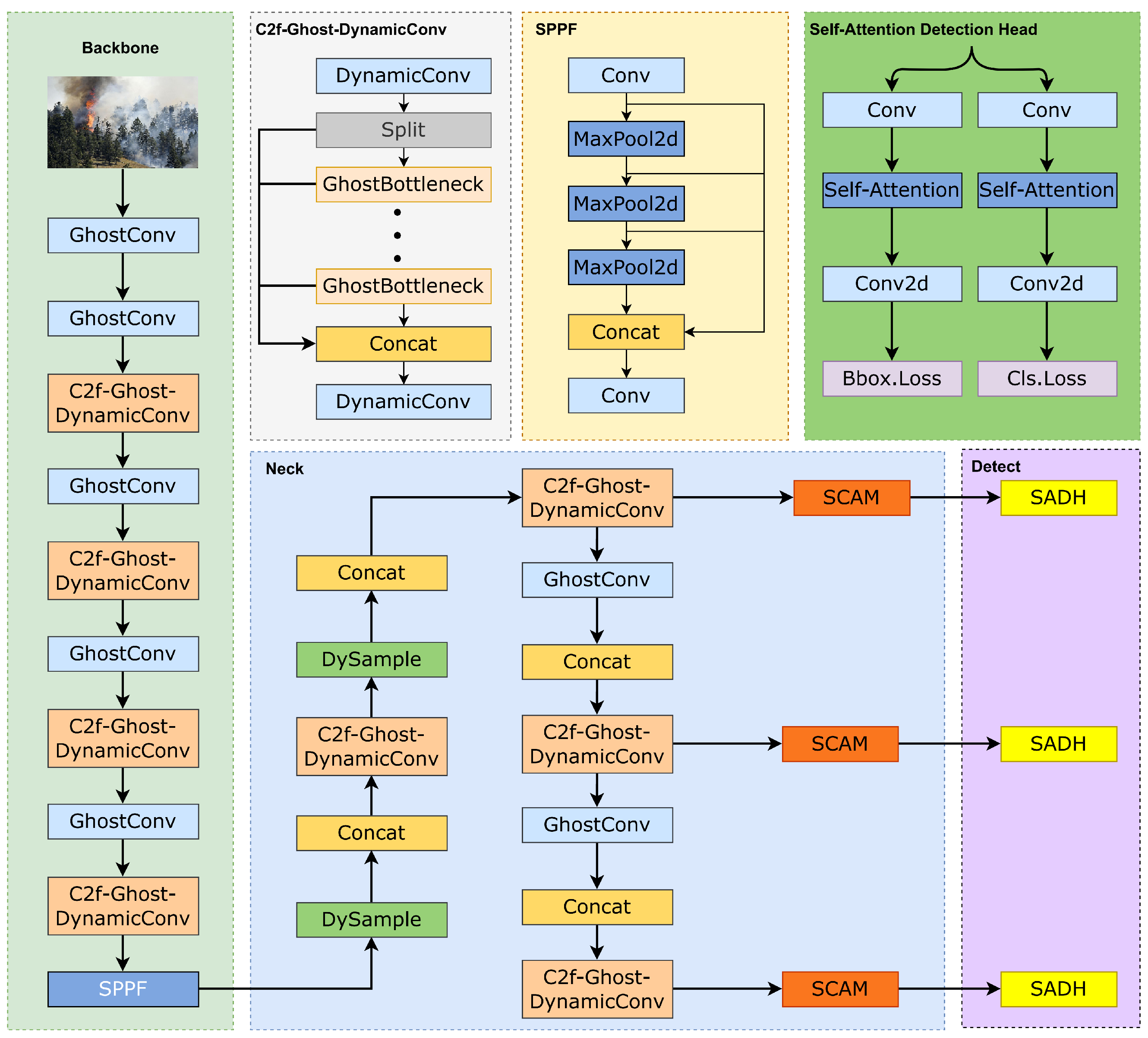
- GhostConv improves the efficiency of smoke detection in forest fires by creating extra feature maps for fire and smoke through economical linear transformations, leading to a reduction in the number of parameters within the detection model. Furthermore, C2f-Ghost-DynamicConv, is introduced, which adaptively fuses multiple convolutional kernels based on the input. This approach improves feature extraction and representation for forest fires and smoke of varying sizes and shapes. It also optimizes the use of computational resources for forest fire smoke detection and enhances performance in low floating-point operations.
- To address the time-consuming and labor-intensive processes involved in dynamic convolution for forest fire detection, as well as the creation of additional sub-networks for dynamic kernels, DySample is introduced. This method is a super-lightweight and highly efficient dynamic upsampling technique. By using point sampling for upsampling, DySample circumvents the necessity of dynamic convolution, which greatly lowers the parameter count in detection models. This approach minimizes GPU memory consumption and lowers latency, leading to quicker detection of smoke and forest fires.
- Introducing the Spatial Context Aware Module (SCAM) aims to better detect small fire and smoke targets early and minimize background interference in fire and smoke detection. This module improves the model’s capability to globally associate information across both channels and spatial dimensions, effectively addressing the challenge of detecting small-target forest fires and smoke.
- To capture comprehensive information about forest fire and smoke features, a detection head utilizing self-attention (SADH) is introduced. Introducing Shape-IoU enhances regression accuracy, improving both the detection accuracy and convergence speed of the detection model.
2. Materials and Methods
2.1. Dataset
2.2. Methods
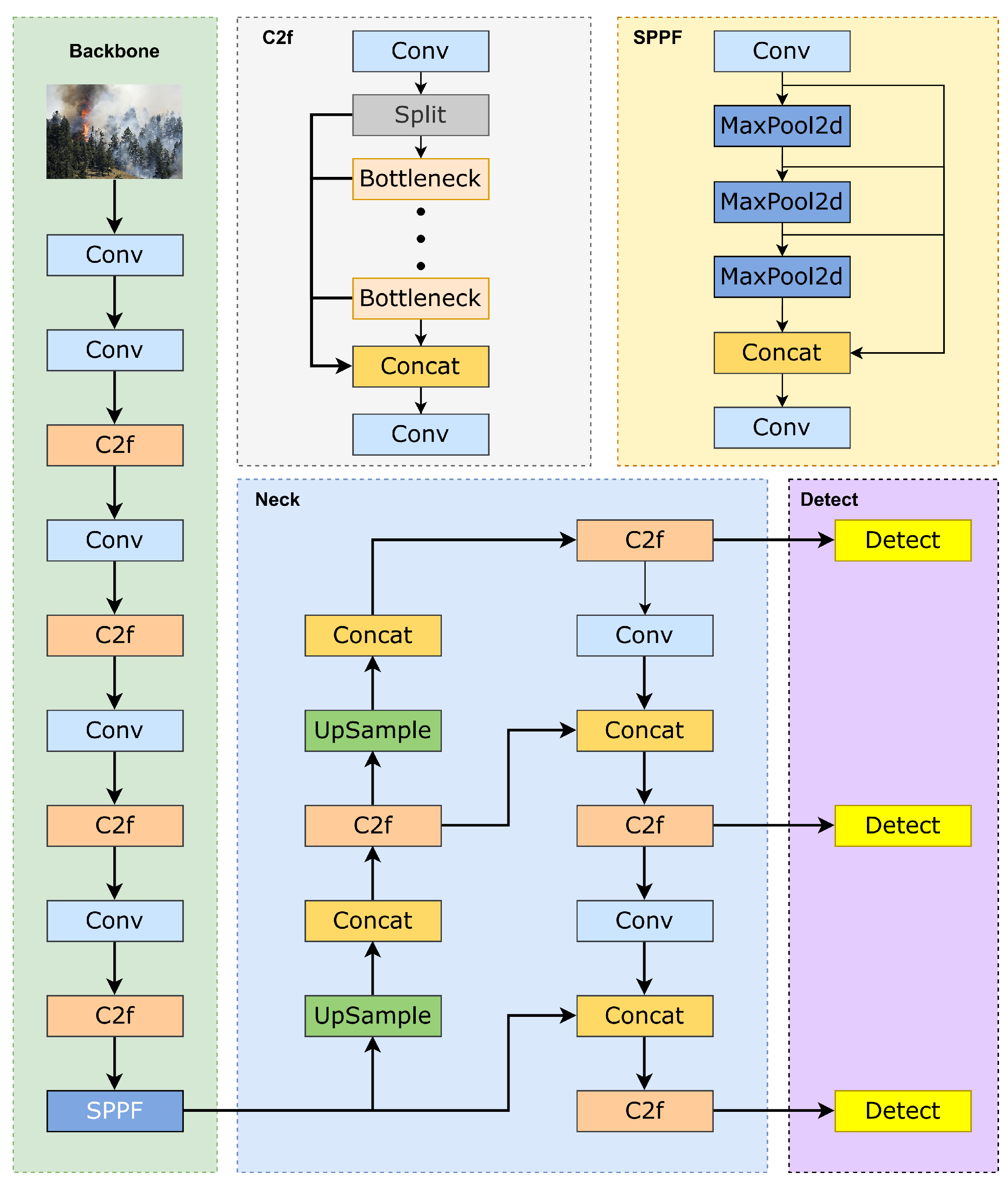
2.2.1. YOLOv8
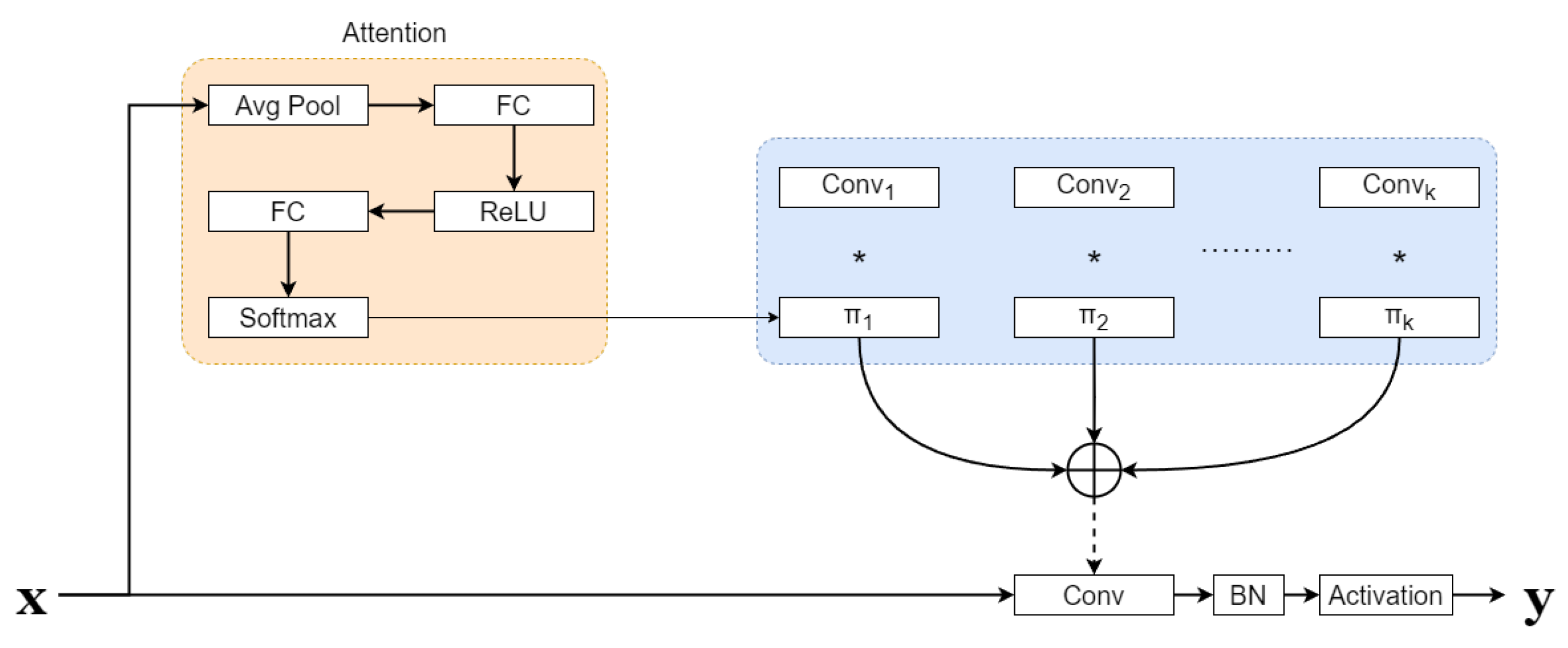
2.2.2. GhostDynamicModule
- GhostModule
- C2f-Ghost-DynamicConv
2.2.3. DySample and Spatial Context Aware Module
- DySample
- Spatial Context Aware Module

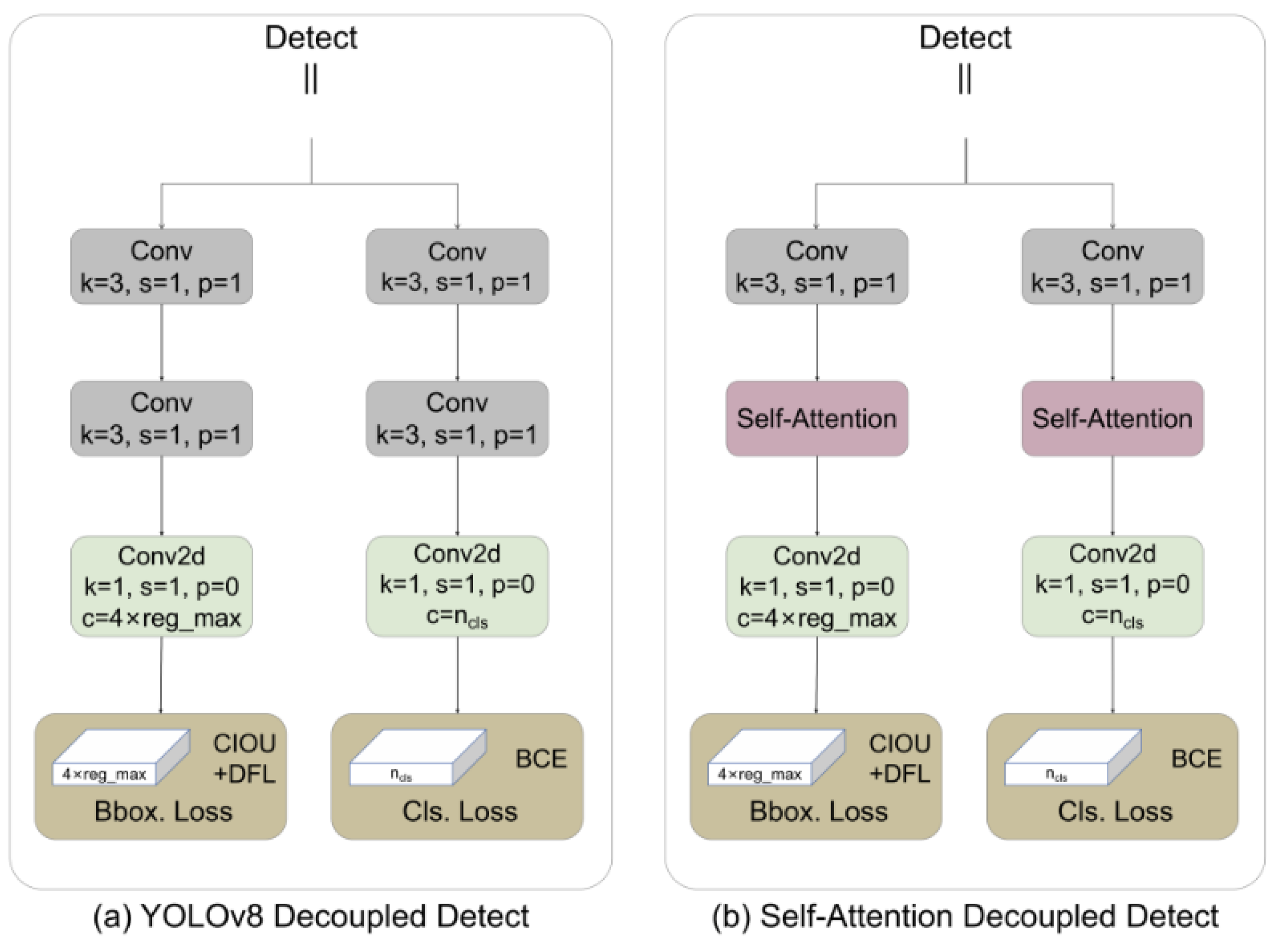
2.2.4. Self-Attention Detection Head
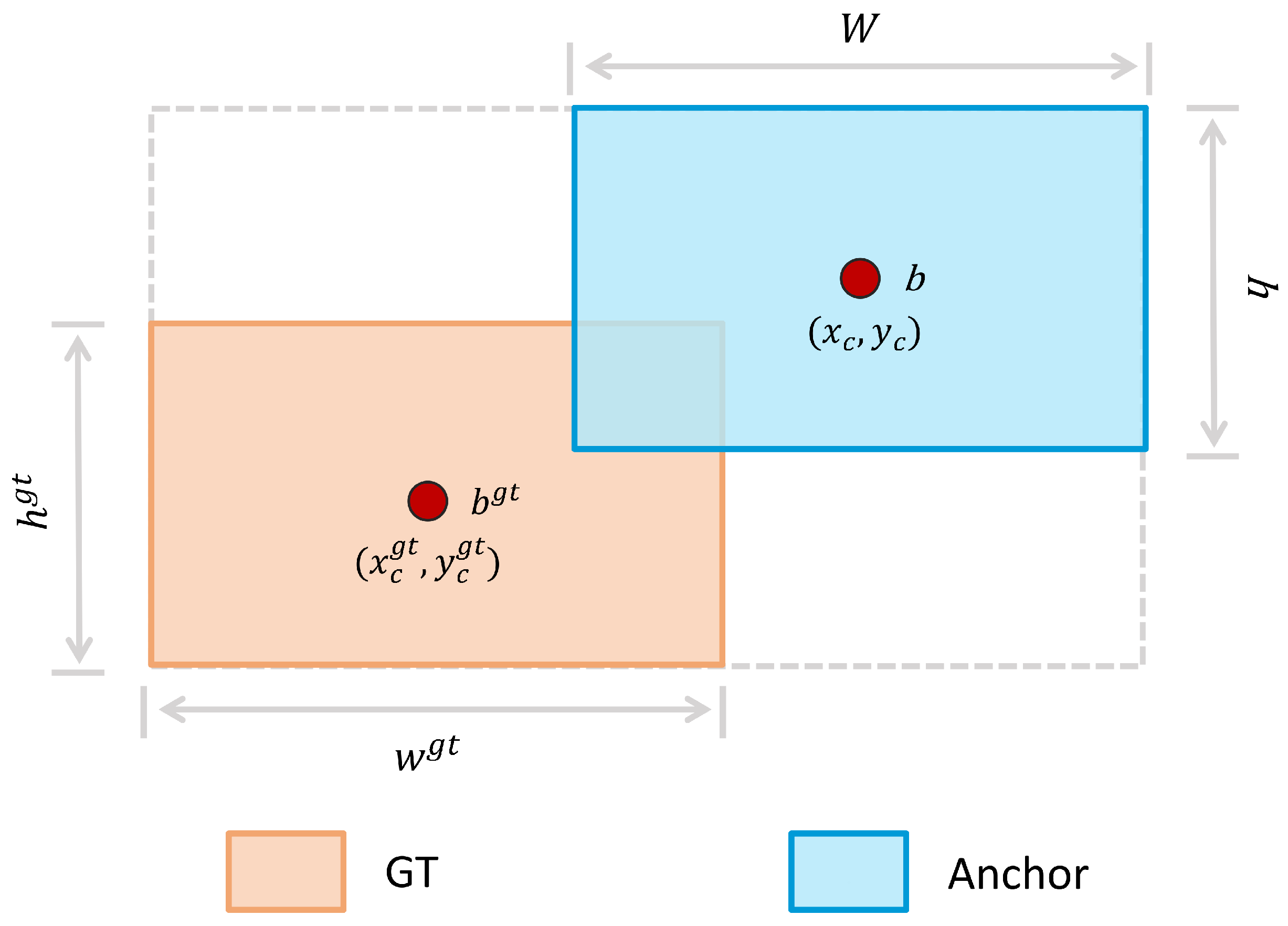
2.2.5. Shape-IoU Loss
2.2.6. LD-YOLO
3. Results
3.1. Experimental Environment
3.2. Model Evaluation
3.3. Ablation Experiment
3.4. Performance and Comparative Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Keenan, R.J.; Reams, G.A.; Achard, F.; de Freitas, J.V.; Grainger, A.; Lindquist, E. Dynamics of global forest area: Results from the FAO Global Forest Resources Assessment 2015. For. Ecol. Manag. 2015, 352, 9–20. [Google Scholar] [CrossRef]
- Morales-Hidalgo, D.; Oswalt, S.N.; Somanathan, E. Status and trends in global primary forest, protected areas, and areas designated for conservation of biodiversity from the Global Forest Resources Assessment 2015. For. Ecol. Manag. 2015, 352, 68–77. [Google Scholar] [CrossRef]
- Bergeron, Y.; Gauthier, S.; Flannigan, M.; Kafka, V. Fire regimes at the transition between mixedwood and coniferous boreal forest in northwestern Quebec. Ecology 2004, 85, 1916–1932. [Google Scholar] [CrossRef]
- Parashar, A.; Biswas, S. The impact of forest fire on forest biodiversity in the Indian Himalayas (Uttaranchal). In Proceedings of the XII World Forestry Congress, Quebec City, QC, Canada, 21–28 September 2003; Volume 358. [Google Scholar]
- Cha, S.; Kim, C.B.; Kim, J.; Lee, A.L.; Park, K.H.; Koo, N.; Kim, Y.S. Land-use changes and practical application of the land degradation neutrality (LDN) indicators: A case study in the subalpine forest ecosystems, Republic of Korea. For. Sci. Technol. 2020, 16, 8–17. [Google Scholar] [CrossRef]
- Bui, D.T.; Van Le, H.; Hoang, N.D. GIS-based spatial prediction of tropical forest fire danger using a new hybrid machine learning method. Ecol. Inform. 2018, 48, 104–116. [Google Scholar]
- Zheng, B.; Ciais, P.; Chevallier, F.; Chuvieco, E.; Chen, Y.; Yang, H. Increasing forest fire emissions despite the decline in global burned area. Sci. Adv. 2021, 7, eabh2646. [Google Scholar] [CrossRef]
- Andela, N.; Morton, D.C.; Schroeder, W.; Chen, Y.; Brando, P.M.; Randerson, J.T. Tracking and classifying Amazon fire events in near real time. Sci. Adv. 2022, 8, eabd2713. [Google Scholar] [CrossRef]
- Bowman, D.M.; Williamson, G.J.; Abatzoglou, J.T.; Kolden, C.A.; Cochrane, M.A.; Smith, A.M. Human exposure and sensitivity to globally extreme wildfire events. Nat. Ecol. Evol. 2017, 1, 0058. [Google Scholar] [CrossRef]
- Baijnath-Rodino, J.A.; Kumar, M.; Rivera, M.; Tran, K.D.; Banerjee, T. How vulnerable are American states to wildfires? A livelihood vulnerability assessment. Fire 2021, 4, 54. [Google Scholar] [CrossRef]
- Haight, R.G.; Cleland, D.T.; Hammer, R.B.; Radeloff, V.C.; Rupp, T.S. Assessing fire risk in the wildland-urban interface. J. For. 2004, 102, 41–48. [Google Scholar] [CrossRef]
- Mahmoud, H.; Chulahwat, A. Unraveling the complexity of wildland urban interface fires. Sci. Rep. 2018, 8, 9315. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Zhao, P.; Xu, S.; Wu, Y.; Yang, X.; Zhang, Y. Integrating multiple factors to optimize watchtower deployment for wildfire detection. Sci. Total Environ. 2020, 737, 139561. [Google Scholar] [CrossRef] [PubMed]
- Yao, J.; Raffuse, S.M.; Brauer, M.; Williamson, G.J.; Bowman, D.M.; Johnston, F.H.; Henderson, S.B. Predicting the minimum height of forest fire smoke within the atmosphere using machine learning and data from the CALIPSO satellite. Remote Sens. Environ. 2018, 206, 98–106. [Google Scholar] [CrossRef]
- Yu, L.; Wang, N.; Meng, X. Real-time forest fire detection with wireless sensor networks. In Proceedings of the 2005 International Conference on Wireless Communications, Networking and Mobile Computing, Wuhan, China, 23–26 September 2005; Volume 2, pp. 1214–1217. [Google Scholar]
- Hefeeda, M.; Bagheri, M. Wireless sensor networks for early detection of forest fires. In Proceedings of the 2007 IEEE International Conference on Mobile Adhoc and Sensor Systems, Pisa, Italy, 8–11 October 2007; pp. 1–6. [Google Scholar]
- Mölders, N. Suitability of the Weather Research and Forecasting (WRF) model to predict the June 2005 fire weather for Interior Alaska. Weather Forecast. 2008, 23, 953–973. [Google Scholar] [CrossRef]
- Kumar, M.; Kosović, B.; Nayak, H.P.; Porter, W.C.; Randerson, J.T.; Banerjee, T. Evaluating the performance of WRF in simulating winds and surface meteorology during a Southern California wildfire event. Front. Earth Sci. 2024, 11, 1305124. [Google Scholar] [CrossRef]
- Celik, T.; Ma, K.K. Computer vision based fire detection in color images. In Proceedings of the 2008 IEEE Conference on Soft Computing in Industrial Applications, Muroran, Japan, 25–27 June 2008; pp. 258–263. [Google Scholar]
- Abidha, T.; Mathai, P.P.; Divya, M. Vision Based Wildfire Detection Using Bayesian Decision Fusion Framework. Int. J. Adv. Res. Comput. Commun. Eng. 2013, 2, 4603–4609. [Google Scholar]
- Gubbi, J.; Marusic, S.; Palaniswami, M. Smoke detection in video using wavelets and support vector machines. Fire Saf. J. 2009, 44, 1110–1115. [Google Scholar] [CrossRef]
- Frizzi, S.; Kaabi, R.; Bouchouicha, M.; Ginoux, J.M.; Moreau, E.; Fnaiech, F. Convolutional neural network for video fire and smoke detection. In Proceedings of the IECON 2016—42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; pp. 877–882. [Google Scholar]
- Yuan, F.; Zhang, L.; Wan, B.; Xia, X.; Shi, J. Convolutional neural networks based on multi-scale additive merging layers for visual smoke recognition. Mach. Vis. Appl. 2019, 30, 345–358. [Google Scholar] [CrossRef]
- Sathishkumar, V.E.; Cho, J.; Subramanian, M.; Naren, O.S. Forest fire and smoke detection using deep learning-based learning without forgetting. Fire Ecol. 2023, 19, 9. [Google Scholar] [CrossRef]
- Zhang, J.; Guo, S.; Zhang, G.; Tan, L. Fire Detection Model Based on Multi-scale Feature Fusion. J. Zhengzhou Univ. Eng. Sci. 2021, 42. [Google Scholar]
- Ryu, J.; Kwak, D. Flame detection using appearance-based pre-processing and convolutional neural network. Appl. Sci. 2021, 11, 5138. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Jindal, P.; Gupta, H.; Pachauri, N.; Sharma, V.; Verma, O.P. Real-time wildfire detection via image-based deep learning algorithm. In Proceedings of the Soft Computing: Theories and Applications: Proceedings of SoCTA 2020; Springer: New York, NY, USA, 2021; Volume 2, pp. 539–550. [Google Scholar]
- Qian, J.; Lin, J.; Bai, D.; Xu, R.; Lin, H. Omni-dimensional dynamic convolution meets bottleneck transformer: A novel improved high accuracy forest fire smoke detection model. Forests 2023, 14, 838. [Google Scholar] [CrossRef]
- Saydirasulovich, S.N.; Mukhiddinov, M.; Djuraev, O.; Abdusalomov, A.; Cho, Y.I. An improved wildfire smoke detection based on YOLOv8 and UAV images. Sensors 2023, 23, 8374. [Google Scholar] [CrossRef] [PubMed]
- Yunusov, N.; Islam, B.M.S.; Abdusalomov, A.; Kim, W. Robust Forest Fire Detection Method for Surveillance Systems Based on You Only Look Once Version 8 and Transfer Learning Approaches. Processes 2024, 12, 1039. [Google Scholar] [CrossRef]
- Yun, B.; Zheng, Y.; Lin, Z.; Li, T. FFYOLO: A Lightweight Forest Fire Detection Model Based on YOLOv8. Fire 2024, 7, 93. [Google Scholar] [CrossRef]
- de Venâncio, P.V.A.; Lisboa, A.C.; Barbosa, A.V. An automatic fire detection system based on deep convolutional neural networks for low-power, resource-constrained devices. Neural Comput. Appl. 2022, 34, 15349–15368. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Han, K.; Wang, Y.; Guo, J.; Wu, E. ParameterNet: Parameters Are All You Need for Large-scale Visual Pretraining of Mobile Networks. arXiv 2023, arXiv:2306.14525. [Google Scholar]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11030–11039. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to Upsample by Learning to Sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 6027–6037. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Zhang, Y.; Ye, M.; Zhu, G.; Liu, Y.; Guo, P.; Yan, J. FFCA-YOLO for small object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5611215. [Google Scholar] [CrossRef]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Liu, Y.; Li, H.; Hu, C.; Luo, S.; Luo, Y.; Chen, C.W. Learning to aggregate multi-scale context for instance segmentation in remote sensing images. IEEE Trans. Neural Netw. Learn. Syst. 2024, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Yu, H.; Wan, C.; Liu, M.; Chen, D.; Xiao, B.; Dai, X. Real-Time Image Segmentation via Hybrid Convolutional-Transformer Architecture Search. arXiv 2024, arXiv:2403.10413. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Zhang, H.; Zhang, S. Shape-IoU: More Accurate Metric considering Bounding Box Shape and Scale. arXiv 2023, arXiv:2312.17663. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Images | Number of Fire and Smoke | Number of Clouds |
|---|---|---|---|
| Training | 2883 | 2773 | 110 |
| Validation | 360 | 345 | 15 |
| Testing | 360 | 350 | 10 |
| Configuration | Version |
|---|---|
| Framework | PyTorch (version 2.3.0) |
| Programming Language | Python (version 3.9) |
| GPU | RTX A6000 |
| Operating System | Linux Ubuntu 22.04LTS |
| Parameter | Value |
| Input Image Size | 640 × 640 |
| Epochs | 250 |
| Batch Size | 32 |
| Patience | 50 |
| Optimizer | Adam |
| Learning Rate | 0.01 |
| Adam Momentum | 0.937 |
| Workers | 8 |
| Weight Decay | 0.0005 |
| Warmup Momentum | 0.8 |
| Module | Base Line | Imp 1 | Imp 2 | Imp 3 | Imp 4 | Imp 5 | Imp 6 | Imp 7 | Imp 8 | Ours |
|---|---|---|---|---|---|---|---|---|---|---|
| GhostConv | √ | √ | √ | √ | √ | √ | ||||
| C3fGhost | √ | √ | ||||||||
| C2f-Ghost-DynamicConv | √ | √ | √ | √ | ||||||
| DySample-SCAM | √ | √ | √ | √ | √ | |||||
| SADH | √ | √ | √ | |||||||
| Shape-IoU | √ | √ | ||||||||
| Precision | 0.788 | 0.817 | 0.795 | 0.77 | 0.789 | 0.796 | 0.785 | 0.795 | 0.796 | 0.801 |
| Recall | 0.779 | 0.764 | 0.783 | 0.783 | 0.759 | 0.779 | 0.784 | 0.781 | 0.79 | 0.798 |
| mAP@0.5 | 0.821 | 0.833 | 0.836 | 0.844 | 0.845 | 0.83 | 0.848 | 0.853 | 0.86 | 0.863 |
| mAP@0.5∼0.95 | 0.59 | 0.599 | 0.602 | 0.593 | 0.618 | 0.58 | 0.608 | 0.601 | 0.602 | 0.603 |
| APfire | 0.781 | 0.794 | 0.784 | 0.819 | 0.818 | 0.788 | 0.811 | 0.818 | 0.826 | 0.83 |
| APsmoke | 0.86 | 0.873 | 0.888 | 0.869 | 0.872 | 0.873 | 0.884 | 0.888 | 0.893 | 0.897 |
| FLOPs(G) | 10.6 | 5.6 | 6.4 | 11.3 | 10.3 | 10.6 | 6.3 | 7 | 6.7 | 6.7 |
| Parameters(M) | 28.4 | 16.4 | 16.8 | 29.4 | 25.7 | 28.4 | 17 | 17.8 | 14.7 | 14.7 |
| Model Size(MB) | 22.5 | 12.2 | 13.6 | 24 | 21.9 | 22.5 | 13.7 | 15.1 | 14.4 | 14.4 |
| FPS | 138.82 | 164.61 | 152.32 | 173.22 | 157.05 | 145.95 | 148.63 | 153.54 | 156.77 | 161.02 |
| Model | Precision | Recall | mAP@0.5 | mAP@0.5∼0.95 | APfire | APsmoke | Parameters | FLOPs/G | Model Size (MB) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 | 0.78 | 0.787 | 0.847 | 0.594 | 0.822 | 0.871 | 98.9 | 282.2 | 207.8 |
| YOLOv3-tiny | 0.753 | 0.739 | 0.807 | 0.469 | 0.775 | 0.839 | 11.6 | 18.9 | 24.4 |
| YOLOv5s | 0.775 | 0.77 | 0.816 | 0.565 | 0.783 | 0.848 | 8.7 | 23.8 | 18.5 |
| YOLOv5m | 0.788 | 0.774 | 0.838 | 0.568 | 0.812 | 0.864 | 23.9 | 64 | 50.5 |
| YOLOv5l | 0.778 | 0.755 | 0.837 | 0.548 | 0.804 | 0.87 | 50.7 | 134.7 | 106.8 |
| YOLOv5x | 0.791 | 0.759 | 0.841 | 0.563 | 0.817 | 0.865 | 92.7 | 246 | 195 |
| YOLOv6s | 0.768 | 0.787 | 0.84 | 0.575 | 0.808 | 0.871 | 15.5 | 44 | 32.8 |
| YOLOv6m | 0.754 | 0.759 | 0.818 | 0.553 | 0.787 | 0.849 | 49.6 | 161.1 | 104.3 |
| YOLOv6l | 0.74 | 0.734 | 0.799 | 0.544 | 0.778 | 0.821 | 105.7 | 391.2 | 222.2 |
| YOLOv6x | 0.747 | 0.743 | 0.81 | 0.544 | 0.786 | 0.834 | 165 | 610.2 | 346.5 |
| YOLOv7 | 0.788 | 0.719 | 0.752 | 0.528 | 0.77 | 0.733 | 35.5 | 105.1 | 74.8 |
| YOLOv7-tiny | 0.728 | 0.75 | 0.812 | 0.489 | 0.799 | 0.825 | 5.7 | 13.2 | 12.3 |
| YOLOv8n | 0.807 | 0.754 | 0.813 | 0.576 | 0.774 | 0.853 | 2.9 | 8.1 | 6.2 |
| YOLOv8s | 0.788 | 0.779 | 0.821 | 0.59 | 0.781 | 0.86 | 10.6 | 28.4 | 22.5 |
| YOLOv8m | 0.789 | 0.785 | 0.856 | 0.591 | 0.825 | 0.888 | 24.6 | 78.7 | 52 |
| YOLOv8l | 0.803 | 0.772 | 0.85 | 0.603 | 0.819 | 0.88 | 41.6 | 164.8 | 87.7 |
| YOLOv8x | 0.798 | 0.772 | 0.851 | 0.594 | 0.817 | 0.885 | 65 | 257.4 | 136.7 |
| YOLOv9c | 0.8 | 0.781 | 0.846 | 0.575 | 0.819 | 0.873 | 24.1 | 102.3 | 51.6 |
| YOLO-World | 0.804 | 0.781 | 0.852 | 0.596 | 0.816 | 0.889 | 3.9 | 13.1 | 8.4 |
| Faster R-CNN | 0.805 | 0.749 | 0.812 | 0.561 | 0.788 | 0.836 | 41.4 | 239.3 | 321 |
| LD-YOLO(Ours) | 0.801 | 0.798 | 0.863 | 0.603 | 0.83 | 0.897 | 6.7 | 14.7 | 14.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Z.; Yun, B.; Zheng, Y. LD-YOLO: A Lightweight Dynamic Forest Fire and Smoke Detection Model with Dysample and Spatial Context Awareness Module. Forests 2024, 15, 1630. https://doi.org/10.3390/f15091630
Lin Z, Yun B, Zheng Y. LD-YOLO: A Lightweight Dynamic Forest Fire and Smoke Detection Model with Dysample and Spatial Context Awareness Module. Forests. 2024; 15(9):1630. https://doi.org/10.3390/f15091630
Chicago/Turabian StyleLin, Zhenyu, Bensheng Yun, and Yanan Zheng. 2024. "LD-YOLO: A Lightweight Dynamic Forest Fire and Smoke Detection Model with Dysample and Spatial Context Awareness Module" Forests 15, no. 9: 1630. https://doi.org/10.3390/f15091630
APA StyleLin, Z., Yun, B., & Zheng, Y. (2024). LD-YOLO: A Lightweight Dynamic Forest Fire and Smoke Detection Model with Dysample and Spatial Context Awareness Module. Forests, 15(9), 1630. https://doi.org/10.3390/f15091630