

Tackling the Wildfire Prediction Challenge: An Explainable Artificial Intelligence (XAI) Model Combining Extreme Gradient Boosting (XGBoost) with SHapley Additive exPlanations (SHAP) for Enhanced Interpretability and Accuracy


Abstract
:1. Introduction
- Data Collection and Feature Engineering: Initially, ArcGIS10.8 software was used to process orbital level imagery and vector data, which were geographically registered to fire point locations and converted into structured tabular data. These data were then combined with meteorological information to construct a comprehensive dataset. Feature engineering techniques, such as Weight of Evidence (WOE) encoding, were applied to enhance feature representation [22]. Additionally, to address the data imbalance, Random Over Sampling was employed, providing a solid foundation for model development and analysis.
- Model Construction: Using the dataset derived from the feature engineering process, EWXS constructs a wildfire prediction model based on the XGBoost algorithm. The model is evaluated using key performance metrics, including accuracy, recall, specificity, F1 score, and AUC. It is also compared with models from the existing literature to assess the comparative efficacy of EWXS.
- Enhancing Model Interpretability: Given the proven efficacy of Particle Swarm Optimization (PSO) in high-dimensional hyperparameter spaces [23], the hyperparameters of EWXS were optimized through 500 swarm iterations. Additionally, the SHAP framework was employed to conduct a detailed analysis of the features influencing wildfires. The study identified proximity to villages, meteorological conditions, air humidity, and temperature differentials as key factors influencing wildfire occurrences, aligning with the findings of Nur et al. [9] and Abdollahi et al. [24]. Specifically, the fire risk was found to be highest within a 0–2.7 km radius from villages, decreasing progressively with increasing distance and stabilizing beyond 8.07 km.
2. Related Research
- Handling of Imbalanced Data: Wildfire datasets often exhibit significant class imbalance, as fire incidents are relatively rare compared to non-fire events. This imbalance can lead to models that are biased towards predicting non-fire cases, as they optimize for overall accuracy rather than correctly identifying minority class events. Consequently, models may struggle to detect actual wildfire risks, reducing their practical applicability in fire prevention and emergency response. To mitigate this issue, various resampling techniques, cost-sensitive learning approaches, and anomaly detection methods have been proposed, yet many studies still fail to effectively address the problem.
- Model Interpretability: While ensemble learning models and deep neural networks have significantly improved prediction accuracy, they often function as black boxes, offering limited insight into their decision-making processes. In wildfire risk prediction, model interpretability is crucial not only for scientific transparency, but also for practical implementation. Decision-makers, including government agencies and emergency responders, require clear explanations of predictive outcomes to develop effective mitigation strategies. Traditional explainability techniques such as feature importance ranking and partial dependence plots provide some insights, but they fail to capture complex feature interactions inherent in wildfire prediction. Therefore, enhancing model interpretability remains an urgent research challenge.
3. Research Area and Data Construction
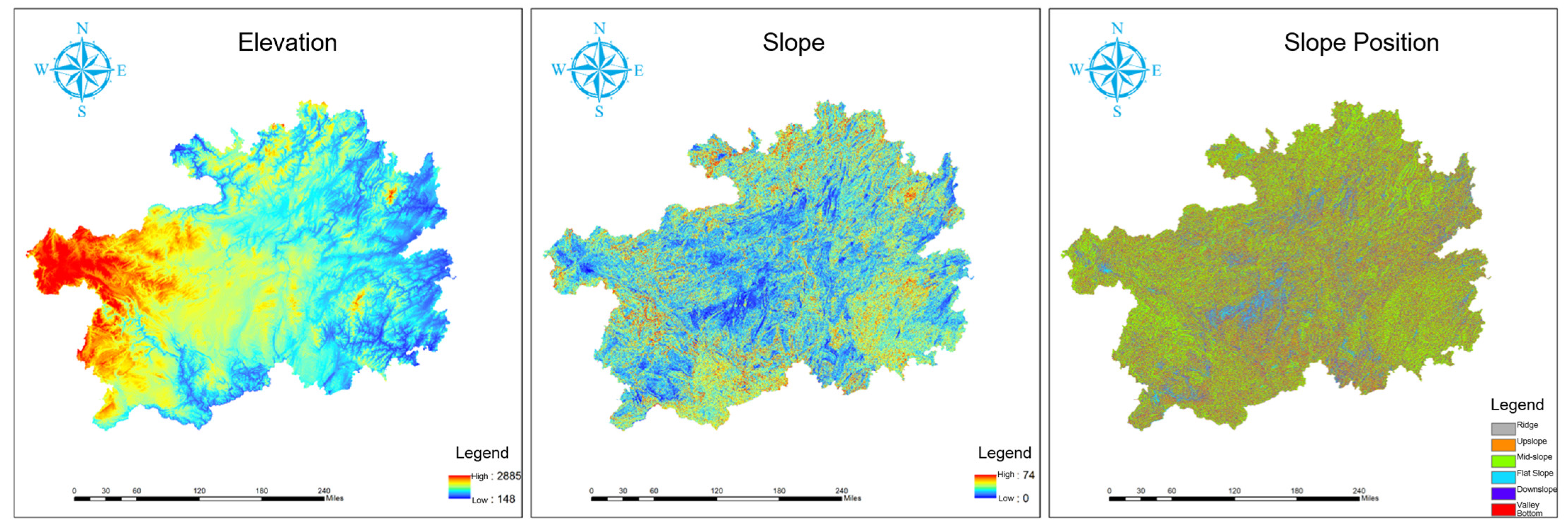
3.1. Introduction to the Research Area
3.2. Data Sources
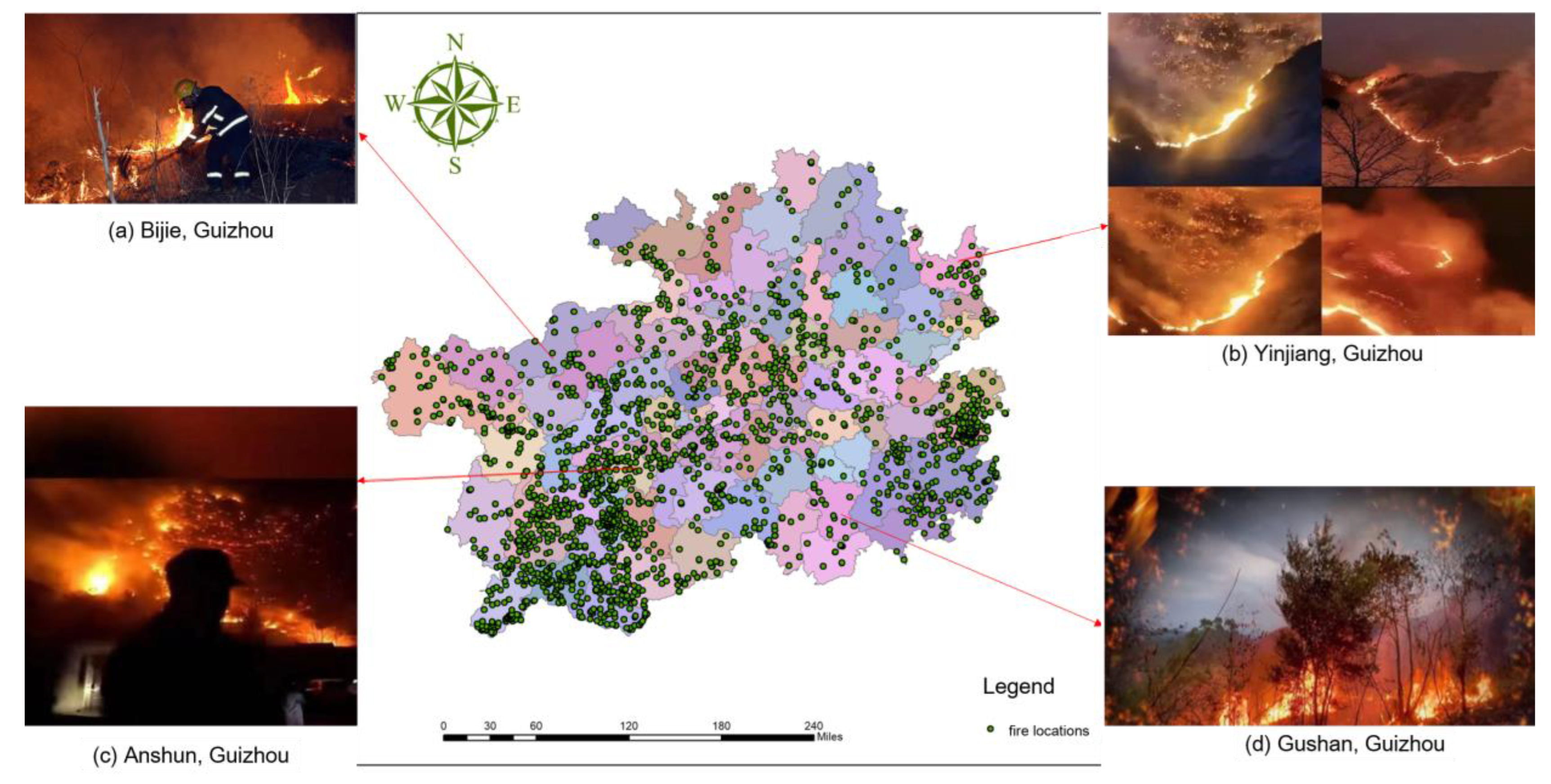
- Fire Point Data: The fire point data used in this study were derived from satellite hotspot data provided by the Institute of Remote Sensing and Digital Earth, Chinese Academy of Sciences [28]. This dataset spans from 2013 to 2021 and includes 16,331 samples, comprising 2721 fire points and 13,610 non-fire points. It provides essential information on the spatial distribution of wildfires, with fire point samples shown in Figure 2.
- Geographic Factor Data: Data on the 90 m resolution Digital Elevation Model (DEM), slope, aspect, and location were obtained from the Geospatial Data Cloud platform. Monthly vegetation coverage and soil moisture data were sourced from the National Tibetan Plateau Data Center, facilitating the assessment of vegetation conditions and soil moisture on wildfire occurrences. Land cover data, provided by GlobalLand30, include crucial surface characteristic information and are accessible through the Global Land Cover Data website.
- Meteorological Factor Data: Meteorological data, including temperature, humidity, and wind speed, were sourced from the CnopenData database and the 2345 Weather website.
- Human Activity Factor Data: Vector data were obtained from OpenStreetMap, and grid data were sourced from the Cubic Database. This includes distances to railways, rivers, major roads, and significant settlements, as well as the number of villages within a 5 km radius.
3.3. Data Construction
3.3.1. Data Spatialization and Integration
- Buffer Zone Establishment and Sample Point Generation: A 500 m buffer radius around fire ignition points was selected based on previous studies demonstrating that this scale effectively captures fuel continuity and initial spread patterns in grassland-forest ecotones [29]. Non-fire points were then randomly generated outside this buffer zone at a 1:5 ratio. This ratio has been widely adopted in similar studies [30]. This fire-to-non-fire ratio balances the dataset, mitigates bias toward fire occurrences, and enhances model generalizability by adequately representing both fire and non-fire conditions.
- Raster Data Transformation: Spatial mapping of raster data was conducted using ArcMap10.8 software. The georeferencing process employed the WGS 84 (World Geodetic System 1984) coordinate system, a globally accepted standard for precise spatial referencing. The data were aligned with known geographic features to ensure spatial accuracy, and quality control checks were implemented to verify the precision of the georeferenced data. Additionally, the “Extract Values to Points” tool was used to extract key information from geographic and raster datasets, ensuring consistency across the dataset.
- Vector Data Transformation: As shown in Figure 3, for vector data, such as railways and rivers, nearest neighbor analysis tools were applied to calculate the shortest distance from sample points to these features. A 5 km buffer zone centered on villages was established, and the number of villages within this zone was quantified to assess their potential impact on wildfire occurrences.
- Data Integration: The structured data were consolidated and exported through table conversion tools. Meteorological data were then integrated to create a comprehensive dataset encompassing meteorological factors.
3.3.2. Construction of Derived Variables
- Meteorological Factor-Derived Variables: In addition to maximum and minimum temperatures, this study incorporates temperature differences, average temperatures, and the average maximum and minimum temperatures from the previous month. Weather-related variables are derived from the number of rainy and sunny days and include categorical weather conditions such as sunny, cloudy, overcast, rainy, or snowy.
- Human Factor-Derived Variables: This study calculates the average number of fire days per month for each county, as well as the average distances to railways and highways. In addition, it considers various ethnic festivals in Guizhou Province, including the Miao ethnic group’s lunar 30 November and the Bouyei ethnic group’s lunar 3 March and 6 June, along with traditional festivals such as New Year’s Eve and the Qingming Festival, to assess their potential impact on wildfire risk.
4. Construction of the Explaining Wildfire with XGBoost and SHAP (EWXS) Model
4.1. Symbol Definitions
4.2. Framework Overview
- Data Construction and Processing: To enhance the model’s ability to detect fire events, non-fire point samples are generated at a 1:5 ratio. ArcMap10.8 software is then employed to spatially map vector and raster data to corresponding sample points, ensuring spatial accuracy. Data preprocessing involves filling missing values—continuous variables with the mean and discrete variables with “None”—followed by Weight Of Evidence (WOE) encoding and feature selection. To address data imbalance, random oversampling is applied to augment the minority class, ensuring balanced model training. Finally, weather data are integrated with other datasets via an inner join, resulting in a comprehensive wildfire dataset that supports subsequent analyses and model development.
- Model Establishment: Various widely used classification algorithms are evaluated for predicting wildfire occurrence probabilities. The most suitable algorithm is selected based on performance assessments. To further enhance model performance and generalizability, a particle swarm optimization algorithm is employed for hyperparameter tuning. The specific algorithms utilized are discussed in Section 4.3.
- Interpretability Analysis: Following model optimization, the SHAP (SHapley Additive exPlanations) framework is applied to enhance interpretability. SHAP decision and summary plots illustrate model predictions and identify key factors influencing wildfire occurrences. Dependence plots analyze feature−prediction relationships, while SHAP force plots provide detailed explanations for individual samples. This approach not only improves model transparency, but also offers empirical support for wildfire prevention and management. A detailed discussion of interpretability analysis is presented in Section 4.4.
4.3. Algorithm and Principles of the EWXS Model
| Algorithm 1. Pseudocode for training BestEWXS. |
| Training algorithm for the best prediction model BestEWXS |
| INPUT: Parameter 1: Parameter 2: Parameters of the EWXS algorithm OUTPUT: BestEWXS |
Missing Value Imputation(I) } = train_test_split(X, y, 0.3) 9 max_iter ← Maximum number of iterations 10 for iteration in range(max_iter): 11 for each particle in the swarm: 12 Evaluate the accuracy of the particle’s current position 13 Update personal best position and global best position, if necessary 14 Update particle velocities and positions using PSO equations 15 Best_Parameter2 ← global_best_position ) 17 return BestEWXS |
4.4. Introduction to the SHapley Additive exPlanations (SHAP) Model
5. Model Construction and Experimental Comparison
5.1. Experimental Environment and Evaluation Metrics
5.2. Feature Engineering and Data Exploration and Analysis
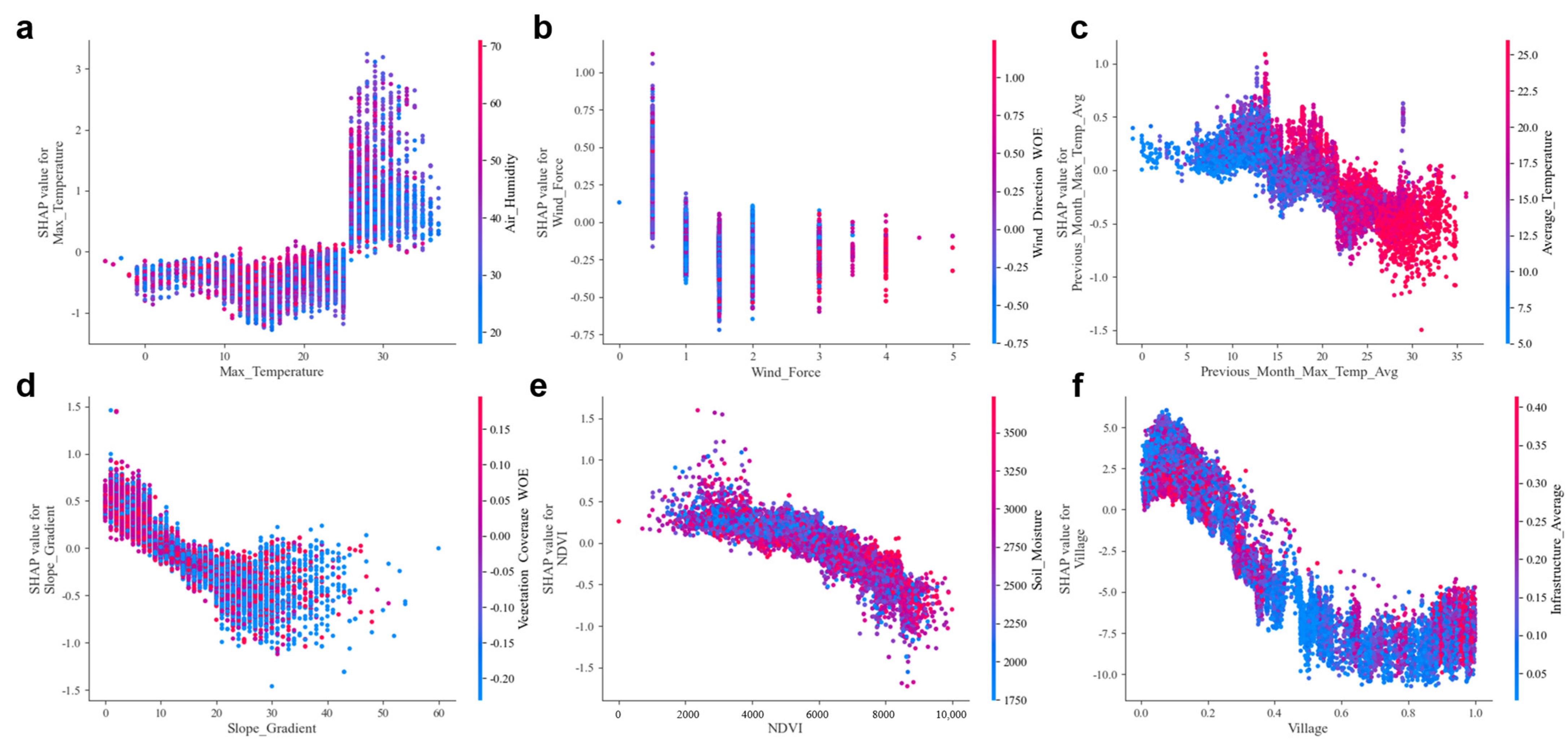
- Meteorological Factors: The joint distribution plot of air humidity and maximum temperature reveals that the likelihood of wildfire occurrence increases when both air humidity and temperature are elevated, with minimal overlap between the two. An analysis of wind speed and direction indicates that wildfires are more likely to occur in regions with lower wind speeds. Additionally, a comparison of the average maximum temperature from the previous month with the current month’s average temperature suggests that elevated temperatures increase the probability of wildfire occurrences.
- Geographic Factors: Joint distribution plots examining the relationship between slope and vegetation cover, as well as soil moisture and the Normalized Difference Vegetation Index (NDVI), suggest that topographic factors have a relatively minor role in wildfire prediction. This is supported by the observation that the peak values of contour lines remain largely unchanged regardless of fire occurrence.
- Human Activity Factors: Wildfires are more frequently observed near administrative villages. In contrast, proximity to infrastructure (such as railways and roads) has a lesser influence on fire occurrences.
5.3. Comparison of Imbalanced Data Handling Methods
5.4. Comparison with Existing Work
- Multi-Source Data Integration: This study developed a comprehensive dataset by integrating vector data, raster data, and structured tabular data from diverse sources. Specifically, non-wildfire samples were generated at a 1:5 ratio to enhance the model’s ability to detect fire events. Key factors such as distance to villages, temperature variations, and air humidity provided critical information for predicting wildfire risk.
- Imbalanced Data Handling: After data integration, the study employed random oversampling techniques to address the issue of data imbalance. This approach increased the number of fire samples, thereby improving the model’s accuracy in predicting the minority class (i.e., fire events).
5.5. Comparison with Mainstream Machine Learning Models
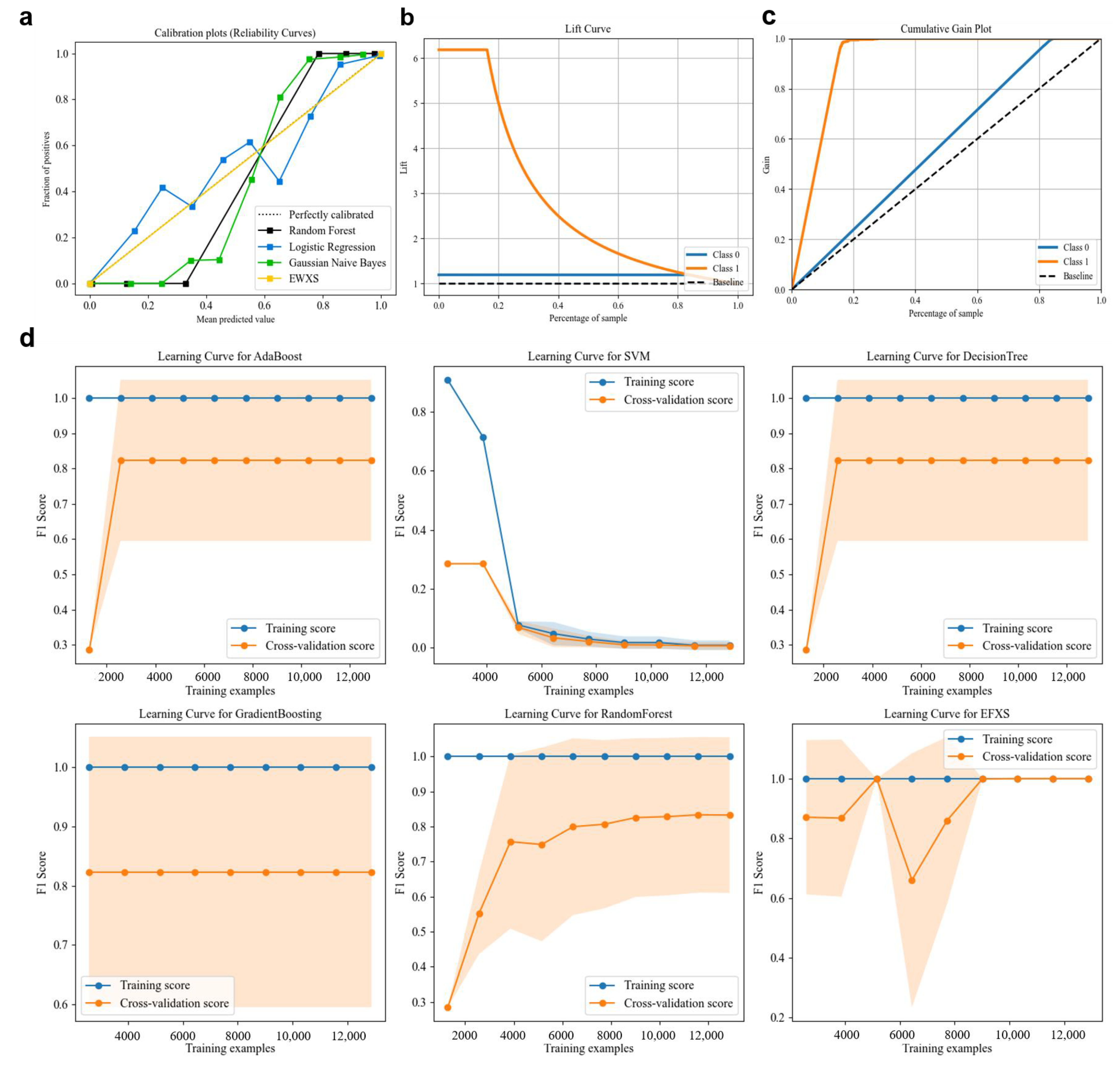
5.6. Hyperparameter Optimization and Generalization Ability Analysis
6. Interpretability Analysis
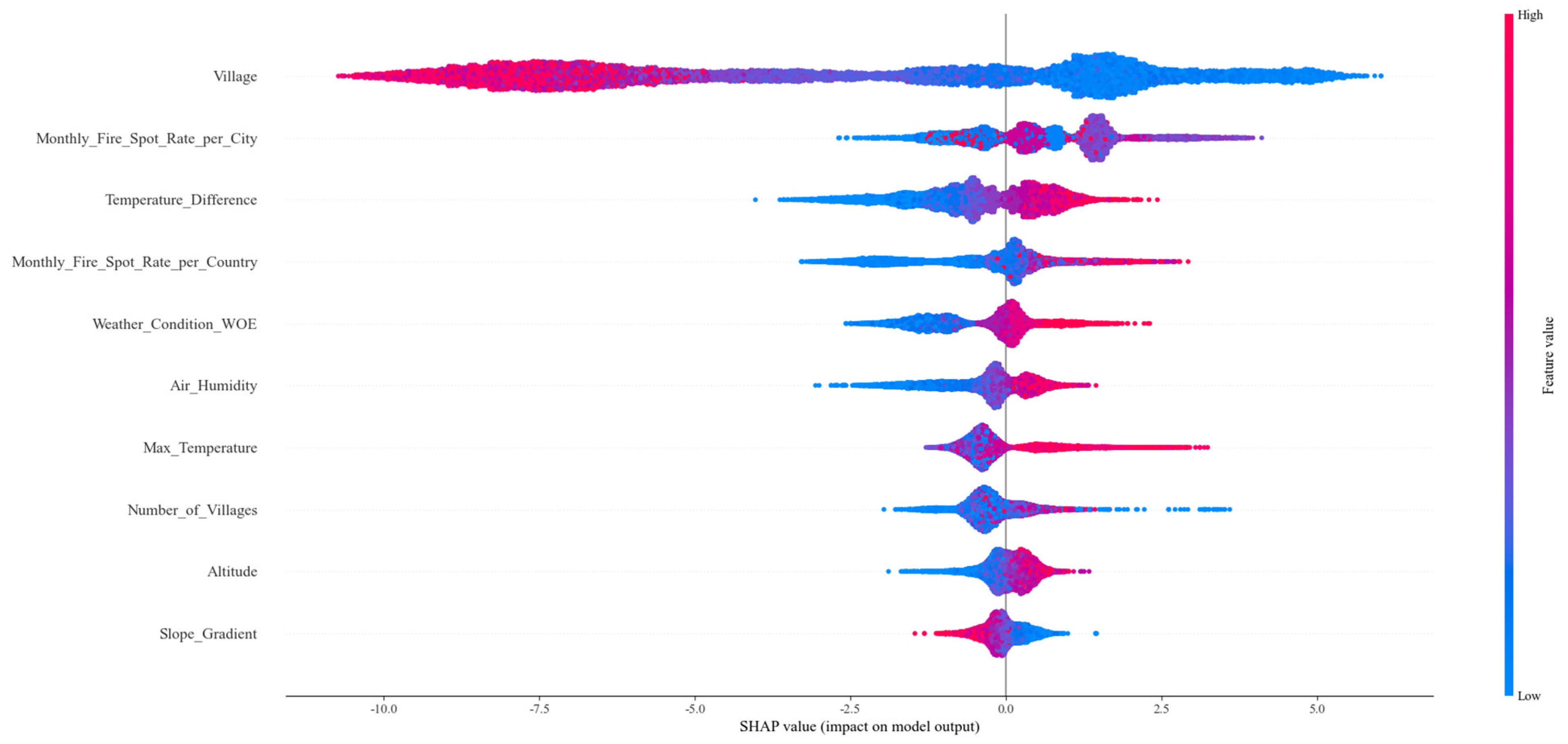
6.1. Feature Importance Comparison Analysis
- Figure 8a Meteorological Factors: Temperature Difference (Temperature_Difference), Weather Condition (Weather_Condition_WOE), Air Humidity (Air_Humidity), and Maximum Temperature (Max_Temperature) are positively correlated with wildfire risk. Specifically, increases in these factors raise the likelihood of fire occurrence. Additionally, the minimum temperature and weather conditions from the previous month significantly influence wildfire risk.
- Figure 8b Human Activity Factors: Distance to Towns and Villages (Village), Monthly Average Fire Spot Rate in the City (Monthly_Fire_Spot_Rate_pre_City), and Monthly Average Fire Spot Rate in the County (Monthly_Fire_Spot_Rate_pre_Country) exhibit a negative correlation with wildfire risk. Greater distances from villages are associated with reduced fire risk, while regions with a history of frequent fires have a higher risk of future fires. Notably, the variable “Village” plays a particularly prominent role in the decision plot, underscoring its critical importance in predicting wildfire risk.
- Figure 8c Geographical Factors: Among the geographical factors, Altitude (Altitude) and Slope Gradient (Slope_Gradient) significantly affect wildfire risk. Increased altitude raises fire risk, while reduced slope gradients also contribute to higher fire risk. Furthermore, the Normalized Difference Vegetation Index (NDVI) and Soil Moisture (Soil_Moisture) are crucial factors in fire prediction.
6.2. Feature Dependence Analysis
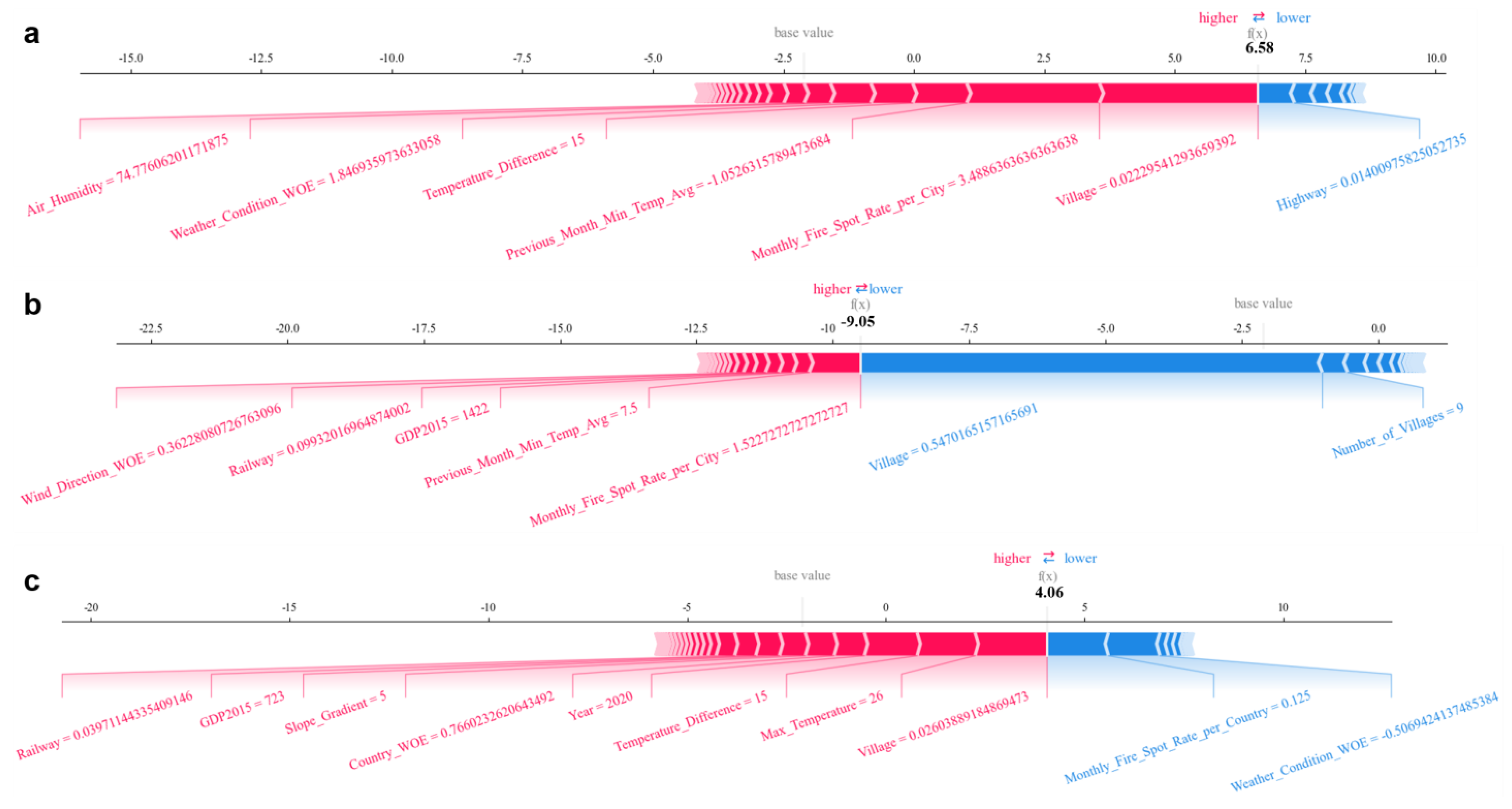
6.3. Sample Decision Process Analysis
7. Discussion
8. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wei, J.; Li, Z.; Ma, Z.; Wang, H.; Wang, Q.; Shu, L.; Yang, Y.; Gao, Z. Spatiotemporal Clustering Analysis of Forest Fires in Yunnan Province. Fire Sci. Technol. 2020, 39, 1425–1429. [Google Scholar]
- Ponomarev, E.; Yakimov, N.; Ponomareva, T.; Yakubailik, O.; Conard, S.G. Current trend of carbon emissions from wildfires in Siberia. Atmosphere 2021, 12, 559. [Google Scholar] [CrossRef]
- Tükenmez, İ.; Özkan, Ö. Matheuristic approaches for multi-visit drone routing problem to prevent forest fires. Int. J. Disaster Risk Reduct. 2024, 112, 104776. [Google Scholar] [CrossRef]
- Zaidi, A. Predicting wildfires in Algerian forests using machine learning models. Heliyon 2023, 9, e18064. [Google Scholar] [CrossRef]
- Zhang, H.; Li, H.; Zhao, P.W. Risk of forest fire occurrence in Inner Mongolia and the impact of its drivers. Acta Ecol. Sin. 2024, 44, 5669–5683. [Google Scholar]
- Xu, S.; Xu, J.; Qu, K.; Yang, J.; Zhou, C. Fire prediction algorithm based on improved neighborhood rough set and optimized BPNN. J. Nanjing Univ. Sci. Technol. 2024, 48, 192–201. [Google Scholar]
- Zhang, J.; Peng, D.; Zhang, C.; He, D.; Yang, C. Research on fire prediction modeling in the Greater Khingan Range of Inner Mongolia based on deep learning. For. Sci. Res. 2024, 37, 31–40. [Google Scholar]
- Xi, J.; Fu, W. Watershed-scale forest fire risk prediction based on machine learning. J. Nat. Disasters 2024, 33, 89–98. [Google Scholar]
- Nur, A.S.; Kim, Y.J.; Lee, J.H.; Lee, C.W. Spatial prediction of wildfire susceptibility using hybrid machine learning models based on support vector regression in Sydney, Australia. Remote Sens. 2023, 15, 760. [Google Scholar] [CrossRef]
- Cao, L.; Liu, X.; Chen, X.; Yu, M.; Xie, W.; Shan, Z.; Gao, B.; Shan, Y.; Yu, B.; Cui, C. Prediction Model of Forest Fire Occurrence Probability in Yanbian Area, Jilin Province. J. Northeast For. Univ. 2024, 52, 90–96. [Google Scholar]
- Pérez-Porras, F.J.; Triviño-Tarradas, P.; Cima-Rodríguez, C.; Meroño-de-Larriva, J.E.; García-Ferrer, A.; Mesas-Carrascosa, F.J. Machine learning methods and synthetic data generation to predict large wildfires. Sensors 2021, 21, 3694. [Google Scholar] [CrossRef]
- Dong, H.; Wu, H.; Sun, P.; Ding, Y. Wildfire Prediction Model Based on Spatial and Temporal Characteristics: A Case Study of a Wildfire in Portugal’s Montesinho Natural Park. Sustainability 2022, 14, 10107. [Google Scholar] [CrossRef]
- Rubí, J.N.S.; Gondim, P.R. A performance comparison of machine learning models for wildfire occurrence risk prediction in the Brazilian Federal District region. Environ. Syst. Decis. 2023, 44, 351–368. [Google Scholar] [CrossRef]
- Tavakkoli Piralilou, S.; Einali, G.; Ghorbanzadeh, O.; Nachappa, T.G.; Gholamnia, K.; Blaschke, T.; Ghamisi, P. A Google Earth Engine approach for wildfire susceptibility prediction fusion with remote sensing data of different spatial resolutions. Remote Sens. 2022, 14, 672. [Google Scholar] [CrossRef]
- Radke, D.; Hessler, A.; Ellsworth, D. FireCast: Leveraging Deep Learning to Predict Wildfire Spread. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (IJCAI-19), Macao, 10–16 August 2019; pp. 4575–4581. [Google Scholar]
- Pereira, J.; Mendes, J.; Júnior, J.S.; Viegas, C.; Paulo, J.R. A review of genetic algorithm approaches for wildfire spread prediction calibration. Mathematics 2022, 10, 300. [Google Scholar] [CrossRef]
- Wang, S.S.-C.; Qian, Y.; Leung, L.R.; Zhang, Y. Identifying Key Drivers of Wildfires in the Contiguous US Using Machine Learning and Game Theory Interpretation. Earth’s Future 2021, 9, e2020EF001910. [Google Scholar] [CrossRef]
- Ban, Y.; Zhang, P.; Nascetti, A.; Bevington, A.R.; Wulder, M.A. Near real-time wildfire progression monitoring with Sentinel-1 SAR time series and deep learning. Sci. Rep. 2020, 10, 1322. [Google Scholar] [CrossRef]
- Jaafari, A.; Zenner, E.K.; Panahi, M.; Shahabi, H. Hybrid artificial intelligence models based on a neuro-fuzzy system and metaheuristic optimization algorithms for spatial prediction of wildfire probability. Agric. For. Meteorol. 2019, 266, 198–207. [Google Scholar] [CrossRef]
- Song, Y.; Wang, Y. Global wildfire outlook forecast with neural networks. Remote Sens. 2020, 12, 2246. [Google Scholar] [CrossRef]
- Bustillo Sánchez, M.; Tonini, M.; Mapelli, A.; Fiorucci, P. Spatial assessment of wildfires susceptibility in Santa Cruz (Bolivia) using random forest. Geosciences 2021, 11, 224. [Google Scholar] [CrossRef]
- Riaz, M.T.; Riaz, M.T.; Rehman, A.; Bindajam, A.A.; Mallick, J.; Abdo, H.G. An integrated approach of support vector machine (SVM) and weight of evidence (WOE) techniques to map groundwater potential and assess water quality. Sci. Rep. 2024, 14, 26186. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. inproceedings of icnn’95-international conference on neural networks 1995. IEEE. View Article. 1995, 4, 1942–1948. [Google Scholar]
- Abdollahi, A.; Pradhan, B. Explainable artificial intelligence (XAI) for interpreting the contributing factors feed into the wildfire susceptibility prediction model. Sci. Total Environ. 2023, 879, 163004. [Google Scholar] [CrossRef]
- Sakellariou, S.; Sfougaris, A.; Christopoulou, O. Integrated wildfire risk assessment of natural and anthropogenic ecosystems based on simulation modeling and remotely sensed data fusion. Int. J. Disaster Risk Reduct. 2022, 78, 103125. [Google Scholar]
- Qiu, L.; Chen, J.; Fan, L.; Sun, L.; Zheng, C. High-resolution map of wildfire drivers in California based on machine learning. Sci. Total Environ. 2022, 833, 155155. [Google Scholar] [CrossRef]
- Zhao, W.; Lu, X.; Chen, Q. The impact of topography on soil properties and soil type distribution in the limestone area of Guizhou. Chin. Soil Fertil. 2023, 1, 1–13. [Google Scholar]
- Zhang, Y.L.; Tian, L.L.; Ding, B.; Zhang, Y.W.; Liu, X.; Wu, Y. Driving factors and prediction model of forest fire in Guizhou Province. Chin. J. Ecol. 2024, 43, 282–289. [Google Scholar]
- Calkin, D.E.; Cohen, J.D.; Finney, M.A.; Thompson, M.P. How risk management can prevent future wildfire disasters in the wildland-urban interface. Proc. Natl. Acad. Sci. USA 2014, 111, 746–751. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 27. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Ji, S.; Li, J.; Du, T.; Li, B. Survey on Techniques, Applications and Security of Machine Learning Interpretability. J. Comput. Res. Dev. 2019, 56, 2071–2096. [Google Scholar]
- Wang, L.; Han, M.; Li, X.; Zhang, N.; Cheng, H. Review of classification methods on unbalanced data sets. IEEE Access 2021, 9, 64606–64628. [Google Scholar] [CrossRef]
- Vilar, L.; Woolford, D.G.; Martell, D.L.; Martín, M.P. A model for predicting human-caused wildfire occurrence in the region of Madrid, Spain. Int. J. Wildland Fire 2010, 19, 325–337. [Google Scholar] [CrossRef]
- Jaafari, A.; Rahmati, O.; Zenner, E.K.; Mafi-Gholami, D. Anthropogenic activities amplify wildfire occurrence in the Zagros eco-region of western Iran. Nat. Hazards 2022, 114, 457–473. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Dataset | Country/Region | Methods for Addressing Data Imbalance | Model | Performance Outcomes | Interpretability | Explanation of the Sample Decision-Making Process |
|---|---|---|---|---|---|---|---|
| Zhang H et al. [5] | Historical wildfire data from Inner Mongolia covering the period from 1981 to 2020 | Inner Mongolia, People’s Republic of China | None | Enhanced Regression Tree | Accuracy: 89.3% AUC: 93% | None | None |
| Xu S et al. [6] | UCI public wildfire dataset, encompassing data from Montesano National Park in Algeria and Northern Portugal | Algeria and Northern Portugal | None | BPNN | Accuracy: 78.89% Precision: 78.68% Recall: 54.33% AUC: 79.31% | None | None |
| Zhang J et al. [7] | MCD64A1 monthly fire product data in conjunction with terrain and climate datasets | Ding-a-ling Region, Inner Mongolia, People’s Republic of China | None | Convolutional Neural Network | Accuracy: 95% Precision: >90% Recall: >90% AUC: 83.8% | None | None |
| Xi J et al. [8] | Fire point data from the Jialing River Basin in Chongqing, spanning from 2018 to 2022 | Chongqing, People’s Republic of China | None | GBDT | Accuracy: 95% AUC: 0.983 | None | None |
| Nur A. S. et al. [9] | VIIRS-Suomi thermal anomaly fire data from Sydney, covering the period from 2011 to 2020 | Sydney, New South Wales, Australia | None | SVR-PSO | AUC: 88.2% RMSE: 0.006 | None | None |
| Cao L et al. [10] | Wildfire and meteorological data from Yantian, Jilin, covering the period from 2000 to 2019 | Yantian Korean Autonomous Prefecture, Jilin Province, People’s Republic of China | None | Random Forest | Accuracy: 93.80% | None | None |
| Pérez-Porras FJ et al. [11] | Data derived from Landsat and MODIS imagery in Southern Spain | Huelva Province, located in Western Andalusia, Spain | SMOTE and SMOTETK | MLP | Recall: 75% F1: 60% | None | None |
| Dong H et al. [12] | Historical wildfire data from Montesano Natural Park in Portugal, available in the UCI Machine Learning Repository | Portugal | None | XGB | Accuracy: 81.32% F1: 78.62% AUC: 80.5% | None | None |
| Rubi J N S et al. [13] | Satellite and climate data collected over the past 20 years | Brazil | None | AdaBoost | AUC: 99.3% | Feature importance analysis method | None |
| Tavakkoli Piralilou S et al. [14] | MODIS thermal anomaly products combined with GPS-based wildfire location data | Gillan Province, Iran | None | Random Forest | Accuracy: 92.5% AUC: 0.947 | None | None |
| Abdollahi A et al. [24] | MODIS fire point data, historical records, Sentinel-2 imagery, and additional meteorological datasets | Victoria, Australia | None | Deep Learning Model | Accuracy: 93% AUC: 0.91 | Feature importance analysis method | Yes |
| Qiu L et al. [26] | Data on wildfire events and burnt areas from California, spanning from 1981 to 2019 | California, United States of America | None | Random Forest | AUC: 98% Kappa: 0.92 | SHapley values method | Yes |
| Influencing Factors | Data Type | Data Source | Source Website | |
|---|---|---|---|---|
| Geographic Factors | Elevation | Continuous | Geospatial Data Cloud Platform | https://www.gscloud.cn/search (accessed on 4 May 2024) |
| NDVI | Continuous | |||
| Slope Gradient | Continuous | |||
| Slope Position | Discrete | |||
| Slope Aspect | Continuous | |||
| Monthly Vegetation Coverage Data | Discrete | National Tibetan Plateau Science Data Center | https://data.tpdc.ac.cn/zh-hans/data/f3bae344-9d4b-4df6-82a0-81499c0f90f7 (accessed on 4 May 2024) | |
| Soil Moisture | Continuous | |||
| Land Cover Data | Discrete | Global Land Cover Data | https://www.gscloud.cn/ (accessed on 4 May 2024) | |
| Meteorological Factors | Maximum Temperature | Continuous | 2345 Historical Weather Data CnopenData Database | https://tianqi.2345.com/ (accessed on 4 May 2024) https://www.cnopendata.com/ (accessed on 4 May 2024) |
| Minimum Temperature | Continuous | |||
| Wind Speed | Continuous | |||
| Wind Direction | Discrete | |||
| Weather | Discrete | |||
| Humidity | Continuous | |||
| Human Activity Factors | Distance to Railway | Continuous | OpenStreetMap | https://www.openstreetmap.org/ (accessed on 4 May 2024) |
| Distance to River | Continuous | |||
| Distance to Major Road | Continuous | |||
| Distance to Major Settlement | Continuous | |||
| Number of Villages within a 5 km Radius | Continuous | |||
| Other Factors | County Affiliation | Discrete | CnopenData Database | |
| GDP Grid Data | Continuous | Cubic Database | https://www.cnopendata.com/ (accessed on 4 May 2024) | |
| Electricity Consumption Grid Data | Continuous | |||
| Fire Point Data | Discrete | Institute of Remote Sensing and Digital Earth, Chinese Academy of Sciences | http://satsee.radi.ac.cn:8080/index.html (accessed on on 4 May 2024) | |
| Feature Name | Feature Type | Mean | Min | 50% | Max | Explanation |
|---|---|---|---|---|---|---|
| Date | Raw Feature | 23 December 2017 | 2 January 2013 | 19 June 2018 | 30 December 2021 | Date |
| Year | Raw Feature | 2017.49 | 2013.00 | 2018.00 | 2021.00 | Year |
| Max_Temperature | Raw Feature | 19.73 | −5.00 | 20.00 | 38.00 | Maximum Temperature |
| Min_Temperature | Raw Feature | 11.87 | −14.00 | 12.00 | 27.00 | Minimum Temperature |
| Wind_Force | Raw Feature | 1.24 | 0.00 | 1.00 | 5.00 | Wind Force |
| Air Humidity | Raw Feature | 40.39 | 3.20 | 37.09 | 171.00 | Air Humidity |
| Month | Raw Feature | 6.30 | 1.00 | 6.00 | 12.00 | Month |
| Highway | Raw Feature | 0.10 | 0.00 | 0.06 | 1.00 | Distance to Highway |
| River | Raw Feature | 0.86 | 0.00 | 0.97 | 1.00 | Distance to River |
| Railway | Raw Feature | 0.24 | 0.00 | 0.18 | 1.00 | Distance to Railway |
| Slope_Position | Raw Feature | 3.29 | 1.00 | 3.00 | 6.00 | Slope Position |
| Slope_Gradient | Raw Feature | 14.06 | 0.00 | 13.00 | 60.00 | Slope Gradient |
| Altitude | Raw Feature | 1078.69 | 218.00 | 1056.00 | 2638.00 | Altitude |
| Population2020 | Raw Feature | 2.57 | 0.02 | 0.77 | 967.03 | Population in 2020 (in ten thousand) |
| EC2019 | Raw Feature | 610,883.88 | 14,875.40 | 88,778.50 | 19,977,700.00 | Electricity Consumption in 2019 |
| GDP2015 | Raw Feature | 1352.48 | 70.00 | 397.00 | 165,642.00 | GDP in 2015 |
| Soil_Moisture | Raw Feature | 2707.65 | −0.10 | 2675.00 | 6000.00 | Soil Moisture |
| NDVI | Raw Feature | 6058.80 | 0.00 | 6175.00 | 10,000.00 | Normalized Difference Vegetation Index |
| Vegetation_Coverage | Raw Feature | 20.48 | 10.00 | 20.00 | 80.00 | Vegetation Coverage |
| Slope_Direction | Raw Feature | 179.10 | 0.00 | 175.16 | 359.74 | Slope Direction |
| Village | Raw Feature | 0.40 | 0.00 | 0.29 | 1.00 | Distance to Village |
| Number_of_Villages | Raw Feature | 8.27 | 0.00 | 5.00 | 280.00 | Number of Villages |
| Temperature_Difference | Derived Feature | 7.86 | −2.00 | 8.00 | 26.00 | Temperature Difference |
| Average_Temperature | Derived Feature | 15.80 | −6.00 | 16.00 | 31.50 | Average Temperature |
| Monthly_Fire_Spot_Rate_per_City | Derived Feature | 3.69 | 1.16 | 3.49 | 7.60 | Monthly Average Fire Days per City |
| Monthly_Fire_Spot_Rate_per_Country | Derived Feature | 0.42 | 0.01 | 0.27 | 1.72 | Monthly Average Fire Days per County |
| Contains_Overcast | Derived Feature | 0.42 | 0.00 | 0.00 | 1.00 | Weather Includes Overcast |
| Contains_Sunny | Derived Feature | 0.12 | 0.00 | 0.00 | 1.00 | Weather Includes Sunny |
| Contains_Cloudy | Derived Feature | 0.38 | 0.00 | 0.00 | 1.00 | Weather Includes Cloudy |
| Contains_Rain | Derived Feature | 0.51 | 0.00 | 1.00 | 1.00 | Weather Includes Rain |
| Contains_Snow | Derived Feature | 0.01 | 0.00 | 0.00 | 1.00 | Weather Includes Snow |
| Infrastructure_Average | Derived Feature | 0.17 | 0.00 | 0.14 | 0.73 | Average Distance to Infrastructure |
| Previous_Month_Max_Temp_Avg | Derived Feature | 19.41 | 1.79 | 19.58 | 31.71 | Average Maximum Temperature of Previous Month |
| Previous_Month_Min_Temp_Avg | Derived Feature | 11.76 | −1.58 | 11.47 | 22.04 | Average Minimum Temperature of Previous Month |
| Previous_Month_Rain_Days | Derived Feature | 0.00 | 0.00 | 0.00 | 0.00 | Rain Days in the Previous Month |
| Previous_Month_Sunny_Days | Derived Feature | 7.48 | 0.00 | 1.00 | 88.00 | Sunny Days in the Previous Month |
| Number | Symbol | Meaning |
|---|---|---|
| 1 | X = [x1, x2 … xn] ∈ Rn×d | Wildfire Feature Space |
| 2 | s | Feature Dimension |
| 3 | Y = {y0, y1} | Output Space |
| 4 | Training Dataset | |
| 5 | n | Sample Size |
| 6 | D | Data After Feature Engineering |
| 7 | l | Loss Function |
| 8 | Actual Value | |
| 9 | Prediction Value from Iteration t − 1 | |
| 10 | Score Function of the Sample at Iteration t | |
| 11 | Complexity of the Tree | |
| 12 | T | Number of Leaf Nodes |
| 13 | Regularization Parameter | |
| 14 | Weight of Leaf Nodes |
| Actual Condition | Predicted Outcome | |
|---|---|---|
| Wildfire Event Predicted | No Wildfire Predicted | |
| Wildfire Event Occurred | True Positive (TP) | False Negative (FN) |
| Absence of Wildfire | False Positive (FP) | True Negative (TN) |
| Imbalanced Data Handling Method | Accuracy | Precision | Recall | F1 Score | AUC | Overall |
|---|---|---|---|---|---|---|
| None | 99.02% | 98.39% | 95.70% | 97.02% | 0.977 | 97.57% |
| Cluster Centroids | 79.62% | 44.89% | 98.47% | 61.65% | 0.872 | 74.36% |
| SMOTE | 98.86% | 97.67% | 95.44% | 96.54% | 0.975 | 97.20% |
| ADASYN | 98.96% | 97.53% | 96.18% | 96.85% | 0.979 | 97.47% |
| Borderline SMOTE | 98.98% | 97.54% | 96.30% | 96.91% | 0.979 | 97.53% |
| Random Under Sampler | 96.43% | 83.69% | 97.72% | 90.13% | 0.970 | 92.98% |
| Random Over Sampler | 99.03% | 97.33% | 96.82% | 97.08% | 0.982 | 97.68% |
| Reference | Model | Accuracy | Precision | Recall | F1 | AUC |
|---|---|---|---|---|---|---|
| Zhang H et al. [5] | Enhanced Regression Tree | 89.3% | / | / | / | 0.93 |
| Xu S et al. [6] | BPNN | 78.89% | 78.86% | 54.33% | / | 0.793 |
| Zhang J et al. [7] | Convolutional Neural Network | 95% | 90% | 90% | / | 0.838 |
| Xi J et al. [8] | GBDT | 95% | / | / | / | 0.83 |
| Cao L et al. [10] | Random Forest | 93.80% | / | / | / | / |
| Pérez-Porras FJ et al. [11] | MLP | / | 75% | 60% | / | |
| Dong H et al. [12] | XGB | 81.32% | / | / | 78.62% | 0.805 |
| Qiu L et al. [26] | Random Forest | / | / | / | / | 0.98 |
| Rubí J N S et al. [13] | AdaBoost | / | / | / | / | 0.993 |
| Nur A S et al. [9] | SVR-PSO | / | / | / | / | 0.882 |
| Abdollahi A et al. [24] | Deep Learning Model | 93% | / | / | / | 0.91 |
| Tavakkoli Piralilou S et al. [14] | Random Forest | 92.5% | / | / | / | 0.947 |
| Ours | BestEWXS | 99.22% | 98.48% | 96.82% | 97.64% | 0.983 |
| Model Name | Accuracy | Precision | Recall | F1 Score | AUC | Average |
|---|---|---|---|---|---|---|
| Logistic | 60.58% | 23.12% | 59.03% | 33.23% | 0.600 | 47.19% |
| KNC | 71.05% | 32.15% | 66.85% | 43.41% | 0.694 | 56.57% |
| Naive Bayes | 55.73% | 22.60% | 67.57% | 33.70% | 0.605 | 48.02% |
| DTC | 96.81% | 90.10% | 90.80% | 90.44% | 0.944 | 92.51% |
| MLPC | 71.13% | 33.38% | 49.90% | 27.71% | 0.626 | 48.94% |
| GBDT | 95.38% | 80.10% | 96.11% | 87.37% | 0.957 | 90.93% |
| RF | 98.13% | 96.02% | 92.59% | 94.27% | 0.959 | 95.38% |
| ETC | 98.03% | 98.25% | 89.75% | 93.80% | 0.947 | 94.91% |
| AdaBoost | 92.06% | 69.72% | 92.44% | 79.48% | 0.922 | 85.18% |
| HGBC | 98.63% | 95.09% | 96.75% | 95.91% | 0.979 | 96.86% |
| Ridge | 87.20% | 56.99% | 93.94% | 70.93% | 0.899 | 79.79% |
| SVM | 78.88% | 23.14% | 11.67% | 15.50% | 0.520 | 36.24% |
| LGBM | 98.74% | 95.79% | 96.67% | 96.23% | 0.979 | 97.07% |
| EWXS | 99.03% | 97.33% | 96.82% | 97.08% | 0.982 | 97.69% |
| Hyperparameter | Range of Values | Optimized Value | Description of the Parameter |
|---|---|---|---|
| learning_rate | [0.001, 0.5] | 0.465 | Learning Rate |
| max_depth | [2, 50] | 7 | Maximum Depth |
| n_estimators | [0, 100] | 94 | Number of Base Estimators |
| n_bins | [2, 256] | 107 | Number of Bins |
| min_child_samples | [1, 50] | 12 | Minimum Samples per Leaf |
| Accuracy | Precision | Recall | F1 Score | AUC | |
|---|---|---|---|---|---|
| EWXS | 99.03% | 97.33% | 96.82% | 97.08% | 0.982 |
| BestEWXS | 99.22% | 98.48% | 96.82% | 97.64% | 0.983 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, B.; Zhou, T.; Liu, Y.; Li, M.; Zhang, T. Tackling the Wildfire Prediction Challenge: An Explainable Artificial Intelligence (XAI) Model Combining Extreme Gradient Boosting (XGBoost) with SHapley Additive exPlanations (SHAP) for Enhanced Interpretability and Accuracy. Forests 2025, 16, 689. https://doi.org/10.3390/f16040689
Liao B, Zhou T, Liu Y, Li M, Zhang T. Tackling the Wildfire Prediction Challenge: An Explainable Artificial Intelligence (XAI) Model Combining Extreme Gradient Boosting (XGBoost) with SHapley Additive exPlanations (SHAP) for Enhanced Interpretability and Accuracy. Forests. 2025; 16(4):689. https://doi.org/10.3390/f16040689
Chicago/Turabian StyleLiao, Bin, Tao Zhou, Yanping Liu, Min Li, and Tao Zhang. 2025. "Tackling the Wildfire Prediction Challenge: An Explainable Artificial Intelligence (XAI) Model Combining Extreme Gradient Boosting (XGBoost) with SHapley Additive exPlanations (SHAP) for Enhanced Interpretability and Accuracy" Forests 16, no. 4: 689. https://doi.org/10.3390/f16040689
APA StyleLiao, B., Zhou, T., Liu, Y., Li, M., & Zhang, T. (2025). Tackling the Wildfire Prediction Challenge: An Explainable Artificial Intelligence (XAI) Model Combining Extreme Gradient Boosting (XGBoost) with SHapley Additive exPlanations (SHAP) for Enhanced Interpretability and Accuracy. Forests, 16(4), 689. https://doi.org/10.3390/f16040689