Bidirectional Recurrent Neural Network Approach for Arabic Named Entity Recognition


Abstract
:1. Introduction
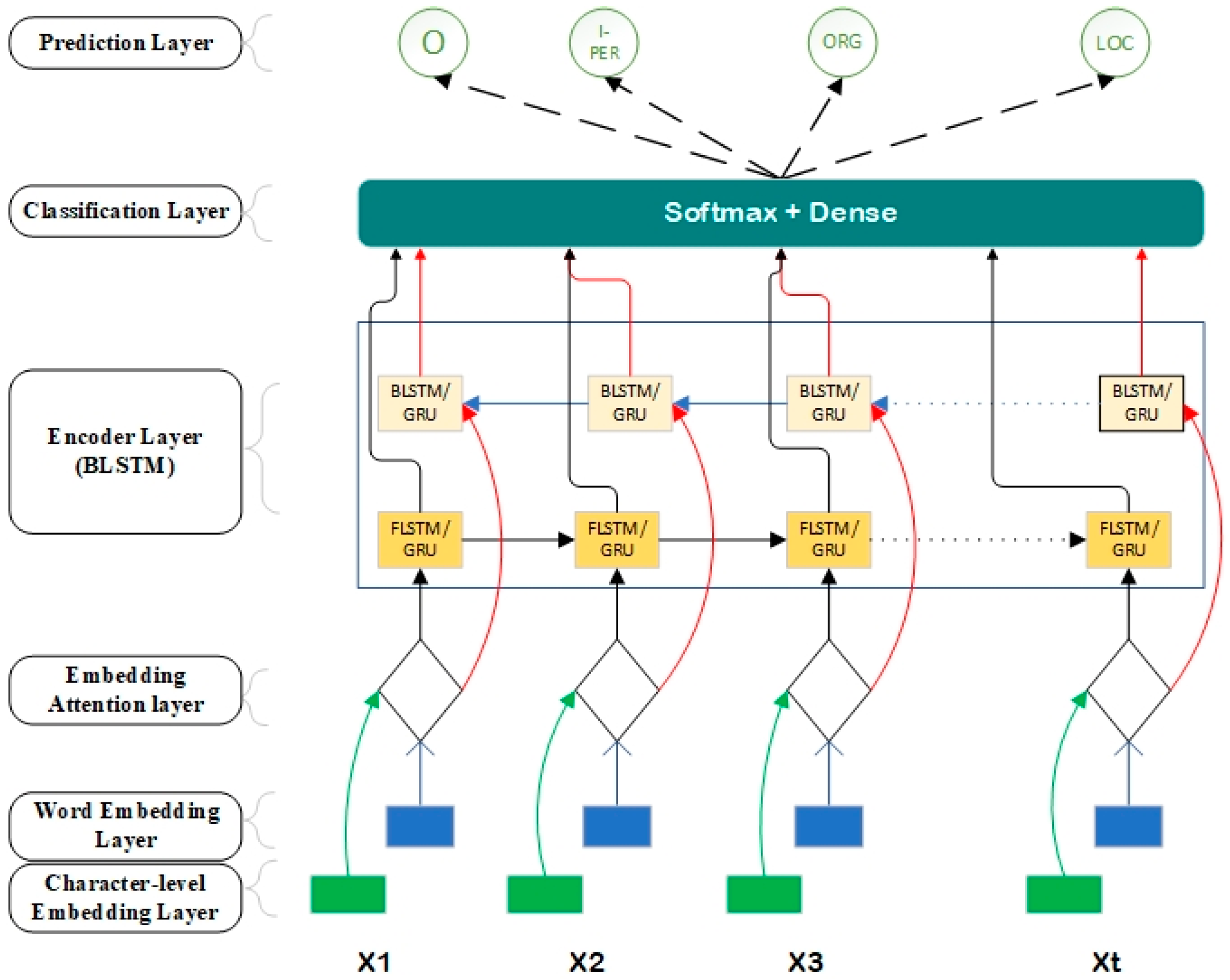
- An ANER system based on bidirectional long short-term memory (Bi-LSTM)/gated recurrent units (GRUs) is proposed by considering the NER problem as a classification problem and without using any manual feature engineering.
- Character embedding is used in addition to word embedding to enhance the model prediction.
- An embedding attention layer that combines word and character embeddings enable the model to create a good word representation.
2. Related Work
3. Approach
3.1. Recurrent Neural Network (RNN)
3.2. Long Short-Term Memory (LSTM)
3.3. Gated Recurrent Units (GRUs)
3.4. Proposed Model
- مملكة عربية يمنية قديمةسبأ “Saba is an ancient Yemeni kingdom.”
- المتحدة للصناعات الكيماوية المحدودة سبأ “Saba United Chemical Industries Ltd.”
- بنت مبخوت الشهراني زعيم أكبر القبائل العربية سبأ “Saba, the daughter of Mbkhout Shahrani leader of the largest Arab tribes.”
4. Experiment
4.1. Datasets
4.2. Baseline
4.3. Setting
4.4. Evaluation
5. Results
6. Discussion
6.1. Comparison of Different Architectures
6.2. Comparison with Other Models
6.3. Effect of Character Embedding
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shaalan, K.; Oudah, M. A hybrid approach to Arabic named entity recognition. J. Inf. Sci. 2014, 40, 67–87. [Google Scholar] [CrossRef]
- Etaiwi, W.; Awajan, A.; Suleiman, D. Statistical Arabic Name Entity Recognition Approaches: A Survey. Procedia Comput. Sci. 2017, 113, 57–64. [Google Scholar] [CrossRef]
- Zirikly, A.; Diab, M. Named entity recognition for arabic social media. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Berlin, Germany, 12 August 2016; pp. 176–185. [Google Scholar]
- Nydell, M.K. Understanding Arabs: A Guide for Modern Times; Intercultural Press: Boston, MA, USA, 2018. [Google Scholar]
- Shaalan, K.; Raza, H. NERA: Named entity recognition for Arabic. J. Assoc. Inf. Sci. Technol. 2009, 60, 1652–1663. [Google Scholar] [CrossRef]
- Oudah, M.; Shaalan, K. NERA 2.0: Improving coverage and performance of rule-based named entity recognition for Arabic. Nat. Lang. Eng. 2017, 23, 441–472. [Google Scholar] [CrossRef]
- Dahan, F.; Touir, A.; Mathkour, H. First Order Hidden Markov Model for Automatic Arabic Name Entity Recognition. Int. J. Comput. Appl. 2015, 123, 37–40. [Google Scholar] [CrossRef]
- Tomas, M. Statistical Language Models Based on Neural Networks. Available online: http://www.fit.vutbr.cz/~imikolov/rnnlm/google.pdf (accessed on 9 December 2018).
- Goyal, A.; Gupta, V.; Kumar, M. Recent Named Entity Recognition and Classification techniques: A systematic review. Comput. Sci. Rev. 2018, 29, 21–43. [Google Scholar] [CrossRef]
- Al-Ayyoub, M.; Nuseir, A.; Alsmearat, K.; Jararweh, Y.; Gupta, B. Deep learning for Arabic NLP: A survey. J. Comput. Sci. 2018, 26, 522–531. [Google Scholar] [CrossRef]
- Awad, D.; Sabty, C.; Elmahdy, M.; Abdennadher, S. Arabic Name Entity Recognition Using Deep Learning. In Proceedings of the International Conference on Statistical Language and Speech Processing, Mons, Belgium, 15–16 October 2018; pp. 105–116. [Google Scholar]
- Li, J.; Zhao, S.; Yang, J.; Huang, Z.; Liu, B.; Chen, S.H.; Pan, H.; Wang, Q. WCP-RNN: A novel RNN-based approach for Bio-NER in Chinese EMRs: Paper ID: FC_17_25. J. Supercomput. 2018. [Google Scholar] [CrossRef]
- Le, T.A.; Arkhipov, M.Y.; Burtsev, M.S. Application of a hybrid Bi-LSTM-CRF Model to the task of Russian named entity recognition. Commun. Comput. Inf. Sci. 2018, 789, 91–103. [Google Scholar]
- Ouyang, L.; Tian, Y.; Tang, H.; Zhang, B. Chinese Named Entity Recognition Based on B-LSTM Neural Network with Additional Features. In Proceedings of the International Conference on Security, Privacy and Anonymity in Computation, Communication and Storage, Guangzhou, China, 12–15 December 2017; pp. 269–279. [Google Scholar]
- Wu, Y.; Jiang, M.; Lei, J.; Xu, H. Named Entity Recognition in Chinese Clinical Text Using Deep Neural Network. Stud. Health Technol. Inform. 2015, 216, 624–628. [Google Scholar] [PubMed]
- Mohammed, N.F.; Omar, N. Arabic named entity recognition using artificial neural network. J. Comput. Sci. 2012, 8, 1285–1293. [Google Scholar]
- Yousfi, S.; Berrani, S.-A.; Garcia, C. Contribution of recurrent connectionist language models in improving LSTM-based Arabic text recognition in videos. Pattern Recognit. 2017, 64, 245–254. [Google Scholar] [CrossRef]
- Baly, R.; Hajj, H.; Habash, N.; Shaban, K.B.; El-Hajj, W. A sentiment treebank and morphologically enriched recursive deep models for effective sentiment analysis in arabic. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2017, 16, 23. [Google Scholar] [CrossRef]
- Chherawala, Y.; Roy, P.P.; Cheriet, M. Feature set evaluation for offline handwriting recognition systems: Application to the recurrent neural network model. IEEE Trans. Cybern. 2016, 46, 2825–2836. [Google Scholar] [CrossRef] [PubMed]
- Jozefowicz, R.; Zaremba, W.; Sutskever, I. An empirical exploration of recurrent network architectures. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2342–2350. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Li, F.; Zhang, M.; Fu, G.; Ji, D. A neural joint model for entity and relation extraction from biomedical text. BMC Bioinform. 2017, 18, 198. [Google Scholar] [CrossRef] [PubMed]
- Ling, W.; Luís, T.; Marujo, L.; Astudillo, R.F.; Amir, S.; Dyer, C.; Black, A.W.; Trancoso, I. Finding function in form: Compositional character models for open vocabulary word representation. arXiv, 2015; arXiv:1508.02096. [Google Scholar]
- Ballesteros, M.; Dyer, C.; Smith, N.A. Improved transition-based parsing by modeling characters instead of words with LSTMs. arXiv, 2015; arXiv:1508.00657. [Google Scholar]
- Kim, Y.; Jernite, Y.; Sontag, D.; Rush, A.M. Character-Aware Neural Language Models. In Proceedings of the AAAI, Phoenix, AZ, USA, 12–17 February 2016; pp. 2741–2749. [Google Scholar]
- Cocos, A.; Fiks, A.G.; Masino, A.J. Deep learning for pharmacovigilance: Recurrent neural network architectures for labeling adverse drug reactions in Twitter posts. J. Am. Med. Inform. Assoc. 2017, 24, 813–821. [Google Scholar] [CrossRef] [PubMed]
- Soliman, A.B.; Eissa, K.; El-Beltagy, S.R. Aravec: A set of arabic word embedding models for use in arabic nlp. Procedia Comput. Sci. 2017, 117, 256–265. [Google Scholar] [CrossRef]
- Rei, M.; Crichton, G.K.O.; Pyysalo, S. Attending to characters in neural sequence labeling models. arXiv, 2016; arXiv:1611.04361. [Google Scholar]
- Benajiba, Y.; Rosso, P.; Benedíruiz, J.M. Anersys: An arabic named entity recognition system based on maximum entropy. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Mexico City, Mexico, 18–24 February 2007. [Google Scholar]
- Kruschwitz, U.; Poesio, M. Combining minimally-supervised methods for arabic named entity recognition. Trans. Assoc. Comput. Linguist. 2015, 3, 243–255. [Google Scholar]
- Benajiba, Y.; Rosso, P. Arabic Named Entity Recognition using Conditional Random Fields. Proc. Work. HLT NLP Arab. World LREC 2008, 8, 143–153. [Google Scholar]


{kind=link}
| Model | P | R | F1 |
|---|---|---|---|
| LSTM | 80.49 | 79.71 | 80.07 |
| GRU | 75.46 | 76.86 | 76.13 |
| BLSTM | 86.85 | 86.01 | 86.42 |
| BGRU | 85.70 | 83.96 | 84.81 |
| BLSTM + char | 88.49 | 87.57 | 88.01 |
| BGRU + char | 87.73 | 86.51 | 87.12 |
| Model | P% | R% | F% |
|---|---|---|---|
| Maha Althobaiti [30] | 84.94 | 52.68 | 63.22 |
| Benajiba (ANERsys 2.0) [31] | 65.33 | 58.60 | 61.73 |
| Nazlia Omar [16] | 65.03 | 62.33 | 57.47 |
| F Dahan (HMM) [7] | 77 | 73 | 75.2 |
| OUR B-LSTM | 88.49 | 87.57 | 88.01 |
| OUR B-GRU | 87.73 | 86.51 | 87.12 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, M.N.A.; Tan, G.; Hussain, A. Bidirectional Recurrent Neural Network Approach for Arabic Named Entity Recognition. Future Internet 2018, 10, 123. https://doi.org/10.3390/fi10120123
Ali MNA, Tan G, Hussain A. Bidirectional Recurrent Neural Network Approach for Arabic Named Entity Recognition. Future Internet. 2018; 10(12):123. https://doi.org/10.3390/fi10120123
Chicago/Turabian StyleAli, Mohammed N. A., Guanzheng Tan, and Aamir Hussain. 2018. "Bidirectional Recurrent Neural Network Approach for Arabic Named Entity Recognition" Future Internet 10, no. 12: 123. https://doi.org/10.3390/fi10120123
APA StyleAli, M. N. A., Tan, G., & Hussain, A. (2018). Bidirectional Recurrent Neural Network Approach for Arabic Named Entity Recognition. Future Internet, 10(12), 123. https://doi.org/10.3390/fi10120123