1. Introduction
In the last decade, video game companies have introduced a new paradigm that involves players actively moving in front of the screen, picking up simulated objects around them and interacting with the game in a three-dimensional space. This has been mostly enhanced by immersive, Virtual Reality (VR) games, where players are plunged into an artificial world reproduced by ad-hoc intelligent systems and devices [
1]. These scenarios, although enabling a deep game experience, may in some cases introduce potential health and safety issues, such as cybersickness and deleterious physiological aftereffects [
2].
Physically Interactive RoboGames (PIRG), on the other hand, comprise an emerging application field that consists of a number of autonomous agents (including software and hardware) of which at least one is an autonomous, physical robot and one is a person. These agents interact with each other in the real world by following some game rules so that the human players can have fun [
3].
PIRG may be seen as well as a specific setting to study human-robot interaction in situations framed by rules, where attention and physical challenges are involved. Furthermore, the increased maturity of fields like social robotics, artificial intelligence and machine learning offers the possibility to design a new generation of such games, where adaptive behavior to support human entertainment, for instance, plays a central role. In general, such applications can foster the wide spread of robots in the society via ludic applications.
In a PIRG, the physical, autonomous agents are actively engaged, creating some sort of interaction, either competitive or cooperative. From one’s perspective, such games are similar to robotic Exergames [
4,
5,
6,
7,
8], but with a mobile companion and with less concern for promoting specific activity conditions driven by therapeutic motivations. Like commercial video games, the main aspect in a PIRG is to produce a sense of entertainment and pleasure that can be “consumed” by a large number of users.
It has been noticed [
3,
9] that an important aspect of such playing entities and systems during the game should be an exhibition of rational behavior, and in this sense, they must be able to play the role of effective opponents or teammates, since people tend to lose their will to play with, or against, a dull entity. Therefore, a robot adapted to the skill and attitudes of the human player may achieve an acceptable performance, possibly providing a highly entertaining experience. Such requirements motivate the design of player’s categorization models in order to understand the player’s behavior and preferences, as well as to guide the expected robot adaptation.
Possible issues may arise, mainly due to the challenges in modeling the real world and the problem of overcoming common limitations present in a robotic platform. For example, a PIRG designer building a mobile playing agent has to deal with the problem of noisy sensory data, partial information, perception, locomotion and planing in a real environment. Safety issues regarding human-robot interaction are, as well, an important factor that has to be taken into account. All of those aspects, together with budget constraints, make the design of intelligent playing robots a difficult task.
Companies like Anki started to make use of artificial intelligence techniques to bring consumer robotics into physical gaming experience. One of its product, Anki Drive, features toy-sized robotic cars controlled by a mobile app. In the game, the cars sense their positions on the track and continually exchange data via Bluetooth with a smartphone. The app computes possible actions and decides what each car should do based on its objective. Additionally, the cars can also show different “personalities”. Despite the app’s ability to orchestrate the behaviors of the cars, players are still limited to the use of the smartphone to drive their car and cannot participate in first person in the game.
Following such an example, one may envision PIRG as one of the next robotic products for the mass technological market, which demands a large exploration of new methodologies, especially as concerns the methods for enabling high autonomy, intelligence and adaptive behavior.
Over the years, there have been some important attempts at presenting robots as games. However, in most cases, the robots act more or less as a mobile pet (e.g., [
10,
11]), where the interaction is often seen as limited to almost static positions [
12], not exploiting rich movement, nor a high level of autonomy, which makes for a low credibility of these toys to really engage lively people [
3,
9].
Some PIRG prototypes have been reported over the last few years. Jedi Trainer 3.0 allowed for a more physical interaction between robot and players [
3]. It was developed with the goal of replicating a scene of the first Star Wars saga movie “Episode IV—A New Hope”. An autonomous drone flew around the human player (Jedi trainee) and could produce, when needed, the sound of a laser blast. Jedi Trainer was successfully tested in different unstructured environments [
9], being capable of showing some apparent adaptation, achieved by always making the drone tend to keep a fixed distance from the player so that the speed of movement of the latter could be matched by the drone. The randomness arising from noisy sensors added realism to the drone’s behavior, which could be perceived as some kind of rational behavior by the human player [
3].
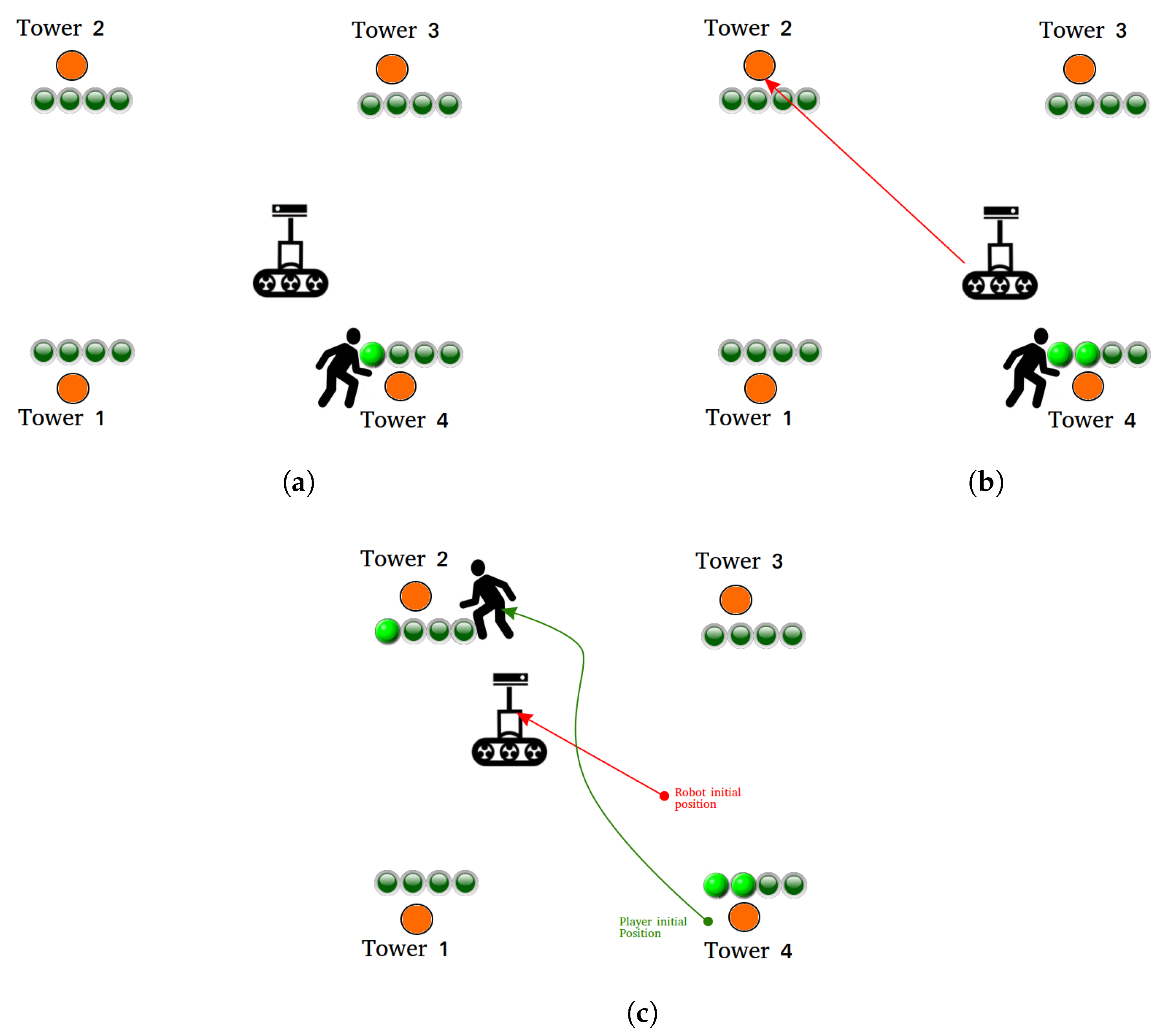
Another example of PIRG with mobile robots was RoboTower [
3,
9]. In the game, a 30 cm high robot had to push down a set of towers in three minutes. Human players could interact with the robot by delaying its movement by placing specific cards on the robot’s path; the robot was capable of reading the cards when passing over them. Each card represented either an action the robot had to execute (go back, turn around, stop) or a deficit of its sensors (go blind). There, the authors reported that engagement was related to the challenge of putting the cards at the right place and by the pressure given by time.
A different and more complex version of RoboTower has been recently implemented [
13,
14], where humans interact with a three-wheeled omni-directional robot one meter high. In this version, only physical interaction is exploited. The present work uses this version of the game as the case study.
Closely related to PIRG, some proposals of user models in games have been made using Playware playground [
15]. Some of them consider physiological data, such as heart rate [
12], for capturing and modeling individual entertainment preferences in children. Others focus on more general attributes like force sensing data and entropy of game events [
16].
Despite the examples of successful PIRG applications using mobile robots, only a few works [
12,
14] concern a direct quantification of the human behavior during game play. In this paper, we present an approach to categorize the players’ behaviors by analyzing data about their movement. The primary source of information is a single three-axis accelerometer placed on the player’s chest. The analysis is performed by first mapping the stream of data into an image representation, namely a Gramian Angular Field (GAF) [
17], which is subsequently processed by a simple autoencoder [
18] architecture for unsupervised feature extraction. After the definition of a dictionary of primitives on the feature space, we apply latent Dirichlet allocation [
19], a generative model mostly used for document retrieval and classification, to uncover coherent groups of motion patterns that can be used to categorize players.
Our decision to use Latent Dirichlet Allocation (LDA) takes inspiration from recent approaches where each game session is represented as a “document”, and chunks of generated stream data are encoded into discrete “words” [
20]. This arrangement is based on the assumption that different players generate different streams of input words, thus different documents, depending on their own motivation or play style.
The possibility to apply LDA to this problem is further reinforced by noticing the apparent difficulty in objectively separating types of motion patterns, since a player in his/her playing activity may show one or more different motion styles. More explicitly, a player may, for instance, become bored or frustrated with the game and consequently show a low motion profile w.r.t. the one that the same player might have shown at other moments during the same game session; for instance, when he/she was excited about it. Here, we consider that a high motion profile, i.e., high turbulence in acceleration signal, is typical for a highly motivated player, since by common sense, a non-motivated player tends to stay relatively still or show a very low acceleration signal.
The claim that motion style conveys engagement or even emotion [
21,
22,
23] types has been supported by several papers. As an example, systematic approaches for describing movement, such as Laban Movement Analysis (LMA) [
24], are often used in deriving low-dimensional representation of movement, facilitating affective motion modeling [
25]. This same type of analysis has been applied when investigating motor elements that characterize movements whose execution enhances basic emotions, such as: anger, fear, happiness and sadness [
22]. In game situations, despite the limited capacity for entertainment detection and modeling in Exergames, LMA had been reported as useful in fostering emotion recognition in states like: concentration, meditation, excitement and frustration [
26].
Here, we hypothesize that, on average, a player will display his/her game-intrinsic motion style and convey some information about his/her interest in/motivation to play. Discovering which coherent groups of motion style exist in a dataset allows us to estimate to what extent an unknown player relates in terms of his/her own motion profile to known groups. This may ultimately help in designing PIRGs that are able to adapt accordingly in order to offer a better user experience for the players.
Following this, in this manuscript, a player representation is addressed as how much of each discovered motion types to which we are confident to say a given player is mostly related. We call this representation a mixture proportion of motion types (similar to topics in the LDA perspective).
In summary, we expect to see that similar player-generated data are grouped together in a coherent collection, allowing the distinction of the existing motion types. The results obtained are validated with human supervision, suggesting the applicability of our method to future mechanisms for designing auto-adapting PIRGs agents.
3. Problem Statement
This section formulates the problem of modeling the player as a probabilistic mixture of uncovered player styles from data. There are at least three basic dimensions (or problems) of interest that must be considered when building a model of this kind for PIRGs. Such dimensions are related to the specific capabilities of a mobile robot to achieve a reasonable in-game performance. We delineate such dimensions as follows:
Dimension #1: Fundamental robot behavior, which concerns the fundamental aspects of the robot locomotion, timing of actions, localization and other abilities to keep it alive and well-functioning during the game play.
Dimension #2: In-game competitive capabilities, which are more related to the intelligent selection of actions aimed at achieving in-game goals. In another words, this dimension captures the intricacies of planning and rational behavior, using solutions for Dimension #1.
Dimension #3: Adaptive power, which is a higher level dimension concerned with how and when during the game to adjust the robot performance to match that of the current player.
Dimension #1 concerns the setup of an appropriate robotic platform, including aspects like: electrical disturbances, power consumption, kinematic constraints, processing capabilities, sensing and safety. These are recurrent issues that must be appropriately dealt with. In turn, Dimension #2 encompasses the problem of finding a plan or strategy to achieve the robot goals. This is the problem most related to the competitive behavior the robot can impose on the human player, since action selection is driven by the tendency to maximize the robot’s own pay-off. After all, the robot has to give the idea that it is at best trying to beat/help its opponent(s)/companion(s).
Dimension #3, acting as the superset for #1 and #2, defines constraints on the robot behavior such that the action selection is not longer just governed by the tendency to be competitive/helpful, but is also driven by the compelling necessity to support the player interaction, in real time, as robustly as possible.
One can see that the present work as a step towards advancements in Dimension #3. Here, we exploit data coming from a single accelerometer placed on the human player’s body; thus, player movement is our primary source of information for describing the playing style and engagement.
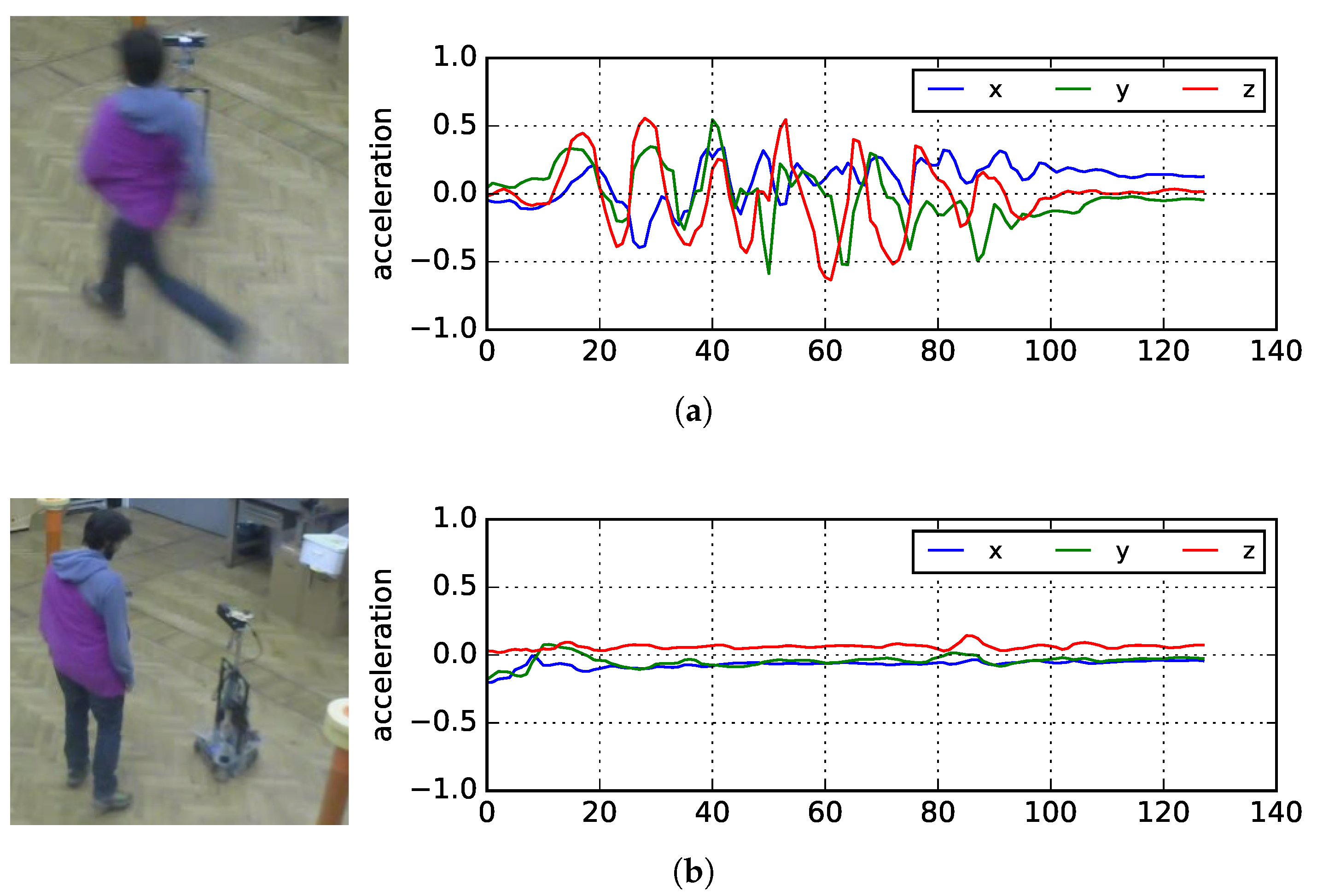
The basic assumption is that a highly active player would naturally express his/her status by a very turbulent motion signal that is compatible with strong in-game activity. Consider, for instance, the difference in signal shapes reported in
Figure 6.
Following this line of reasoning, we also assume players do not fake their engagement by unnecessarily performing strong activities, like running, when they actually are not engaged in the game or feel bored by the robot behavior. Therefore, we assume that a highly motivated player would act more intensively and frequently than a non-motivated one, thus showing a more turbulent acceleration signal profile.
In situations like PIRG, movement information is useful and should not be disregarded. Furthermore, a model that is able to extract a description of the player’s movement profile for the purpose of robot behavior adaptation would generate interesting dynamics able to hide existing platform limitations (kinematics constraints, tracking problems, etc.) and boost game experience.
One important aspect not considered yet by our assumptions is the role of skill level. For example, a highly skilled player could try to minimize his/her energy expenditure by performing precise movements towards winning the game and in theory could perfectly show a low-movement profile. Moreover, these assumptions cannot directly measure player engagement in the game, given that it is also possible for a player to move not too much, but, at the same time, be highly engaged.
In summary, we are interested in investigating time series data, especially acceleration patterns as proxy and/or engagement cues (given the mentioned assumptions) towards the creation of auto-adjusting robotic companions or opponents.
4. Technical Approach
This section describes our approach while emphasizing the differences and similarities with respect to existing methods. We take inspiration from approaches like [
17,
20,
29] and aim at modeling game sessions as “documents”, where player’s acceleration data are considered as “words”. We use Latent Dirichlet Allocation (LDA) [
19] to categorize the player’s motion profile as a composition or mixture of game play motion types, the latter being analogous to the “topics” in the general application of LDA for document modeling.
Differently from [
20], our input word atoms are not discrete. Instead, they are continuous (acceleration data) and also are not attached to any explicit meaning. Take, for instance, the natural interpretability of joystick input signals like “left” and “right”, which convey their respective meaning when controlling a game character, and compare it with an acceleration signal that carries no obvious absolute meaning.
The adopted method for selecting the input words is based on sliding windows (just as in [
20]), without overlap. Considering each game session as a document, the windowed segments play the role of words. Since the space is continuous, a procedure of discretization and dictionary learning for LDA had to be performed. For this, we clustered the segments and used the so-obtained cluster centroids as dictionary words.
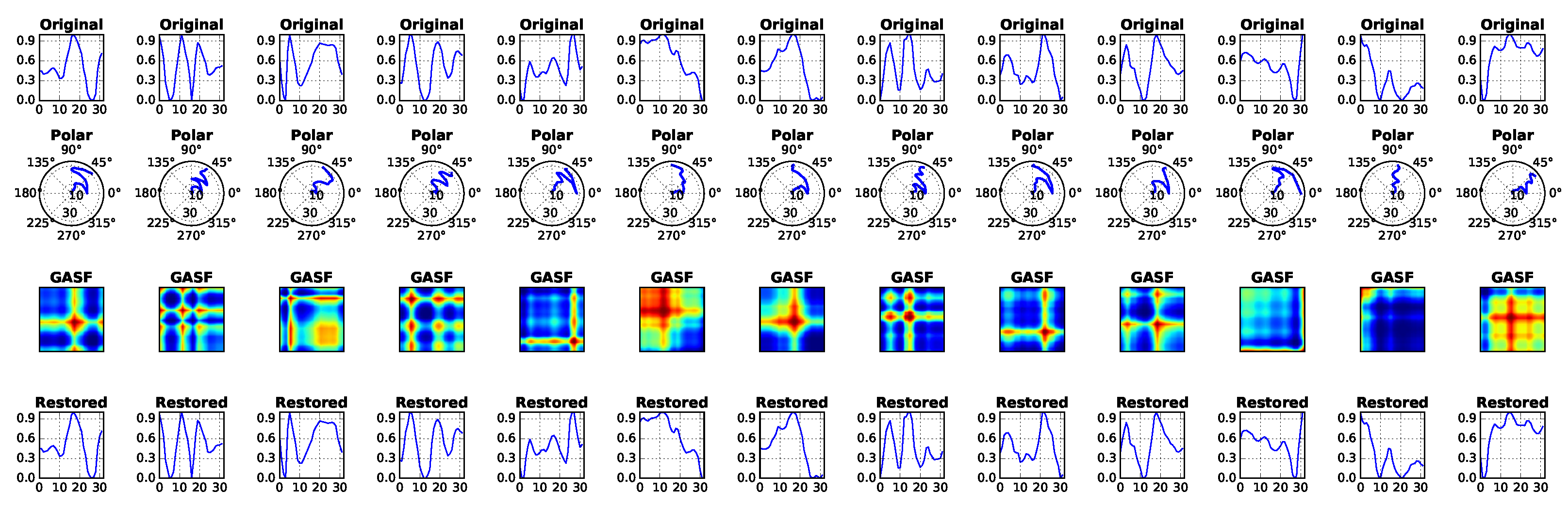
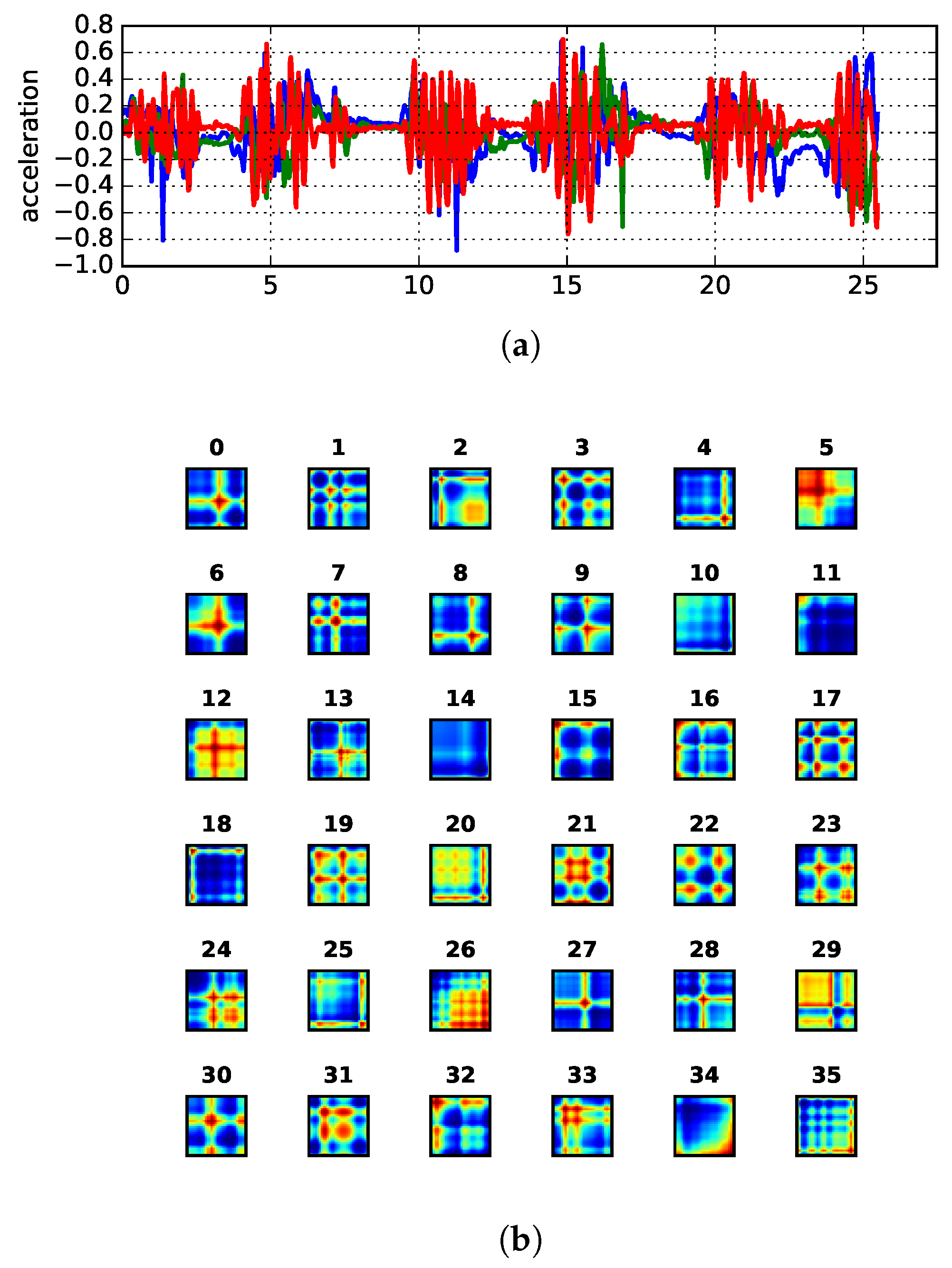
We have used GASF images instead of GADF because the mapping functions of the rescaled time series in
are bijections, which allows for precise reconstruction of the original time series [
17]. The reconstruction takes advantage of the the main diagonal of GASF, i.e.,
, and is performed as reported in Equation (
6) [
17]:
An example of signal decomposition into GASF images is shown in
Figure 7. Given recent advances in deep learning and pattern recognition for images, we take the route of [
29] and exploit the applicability of autoencoders for extracting unsupervised features from GASF images (see
Section 2.3). This is relevant since the process of feature engineering is time-consuming and laborious. Moreover, unsupervised feature extraction from such methods has been proven to work well [
17,
30]. Sparse encoding via linear-algebra methods for dictionary learning is also a possibility. However, in our experiments, it turned out to be not as efficient as autoencoders. We present details of our experimental activity in the next section. Our methodology is summarized in
Figure 8.
6. Experimental Results
In this section, the exploration of an undercomplete representation of the GASF images using a simple autoencoder architecture is firstly reported, then we discuss how we transform the extracted features into input words for the LDA model. Finally, we show the results when confronting the model output with human judgment. All experimental code used is available at the link in supplementary materials.
6.1. Feature Extraction
The first question we need to answer concerns the size of the sliding window. This parameter regards the definition of the GASF images used as building blocks for the dictionary learning. The window size should be large enough to capture motion patterns relevant for the player characterization, but not so large to confound their interpretation. We tried different window sizes, and in the end, we followed [
13] and decided to consider half a second of data per window without overlap, which allows for a fine-grained data representation.
We applied no preprocessing to the signal, since we were interested in observing how an autoencoder would perform using the unfiltered input. The expectation was that it would naturally compensate for the differences in the images, decisively choosing to capture important features (the main signal characteristic) and disregarding non-representative ones (the small noise associated). We defined an architecture composed by dropout and dense layers where only hyperbolic tangent activation functions where used, except in the last layer, where a linear activation function was used instead. The best performing architecture was composed by the following layers: dropout (0.1 drop fraction), dense (size = 256), dropout (0.2) and dense (size = 64). The same layers (in reversed order) were used for the decoder part.
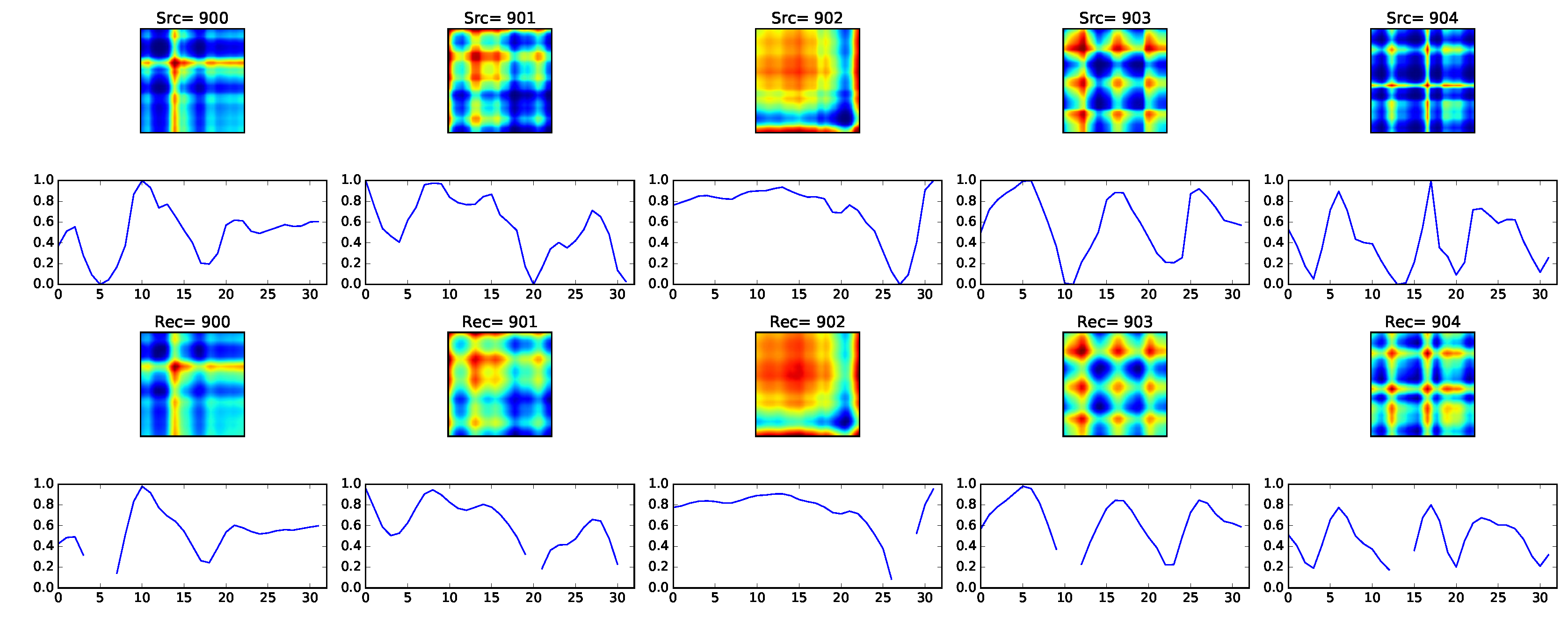
A window of half a second corresponded to 32 samples given our accelerometer average frequency of 48.8 Hz. As a consequence, we obtain GASF images (without using PAA) with a total of 1024 pixels. Using the autoencoder, we manage to reduce the representation down to a 64-dimensional input, resulting in the reconstruction presented in
Figure 13. The choice of a 64-dimensional representation is empirical, meaning that we were in principle searching for an undercomplete representation of the data and, upon testing with different configurations, we have chosen the one with the lowest reconstruction error. As it turned out, a 64-dimensional vector representation was the best result, given our dataset.
It is possible to notice from the reconstruction result that, despite such a large compression (from 1024 to only 64 values), the input image structures are captured. This can also be seen in the reconstructed time series. A closer look reveals that the autoencoder practically smoothed the time series while preserving the overall shape, this being a nice property that can help to prevent overfitting.
From
Figure 13, we can also see that the obtained time series reconstruction presents some holes. This seems to be caused by the information loss in the reconstruction and demands further investigation. However, in our experimentation, it did not seem to affect performance.
6.2. Dictionary Learning and Input Word Definition
Latent Dirichlet allocation works by considering the relationship among word tokens with respect to a collection of documents. Therefore, in order to use the method, we needed to come up with a way to encode the taxonomy of GASF images into a discrete set of fixed tokens describing the motion primitives appearing in each game session. We opted to follow [
35] and encode the features extracted from the GASF using the autoencoders as visual words, composing the game session document.
After getting the 64-dimensional vector representation for each GASF image (see
Section 2.3), we cluster them into
V groups using the K-means algorithm. In this way, we define a dictionary of size
V, with each word corresponding to a cluster centroid. Each game session is then translated into a collection of
V possible clusters, which can then be fed into the LDA algorithm.
From text mining and information retrieval, we know that having documents with different sizes can be a potential issue. This is because given the bag of words representation used in LDA, a small document may be included as a subset in a larger one. Additionally, it might be a problem to evaluate longer documents in our scenario, since, at least from a human perspective, it is not simple to define the overall behavior.
In text mining, this issue is handled by imposing a weight based on the length of the document; in our case, instead, we decided to split each session into smaller segments of 15 s each. In this setting, the evaluation is more consistent, and it is possible that the behavior of a player will be maintained within segments. We decided this length for each document both for convenience with respect to the window length and from the assumption that in each fraction of 15 s, the player can show a consistent behavior, which can be somehow easily identifiable. In the next section, we present the results achieved with the approach we just presented.
6.3. Validation
Our ultimate objective is to represent the player motion style by a mixture of topic proportions following the LDA framework. Unfortunately, the method by itself demands the programmer to initialize the desired number of topics. Thus, we had to perform a search for the optimal value given our dataset.
By performing grid search, we selected a range of values for the two main hyperparameters, namely dictionary size, for the input word definition, and number of topics. We would like to keep the number of topics low, preferably less than 10, since by observing our dataset, it is not possible to distinguish many groups of different motion styles; this suggests that a coarse-grained definition would be better. Choosing the number of topics to be at most 10, as in [
20], the evaluation of the uncovered topics remains manageable, while maintaining a certain degree of freedom for the existing motion diversity.
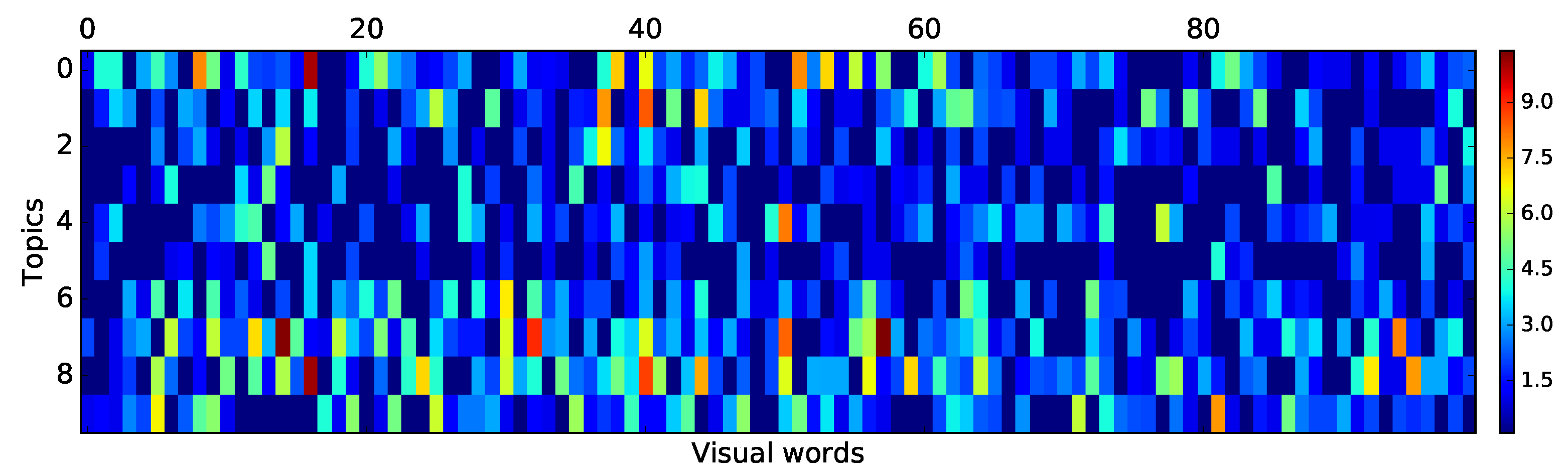
The distribution of cluster centroids (words) given topics (our player motion types) is shown in
Figure 14. Each line represents a topic, while each column represents a word. As one can see, there are no topics represented by the same distribution over the same word.
Figure 14 shows how much each word is important for the specific topic.
In order to validate the discovered topics, we use human judgment. We invited volunteers to watch a set of pairs of recorded game segments (15 s each) and point out the similarities between players in their motivation as perceived by their motion. Subjects had to judge how similar, on a scale from 0–5, the movements of two players were. With this, we generated a similarity matrix to be used as the ground truth and main guide for deciding which hyper-parameter value to use and to check whether the proposed method could achieve reasonable results.
The similarity matrix was composed of 406 independent evaluations from six different human subjects. The generated evaluation matrix was then compared with a cosine similarity matrix generated after training the LDA in our dataset. The similarity, in this case, is based on the mixture proportions among the discovered topics.
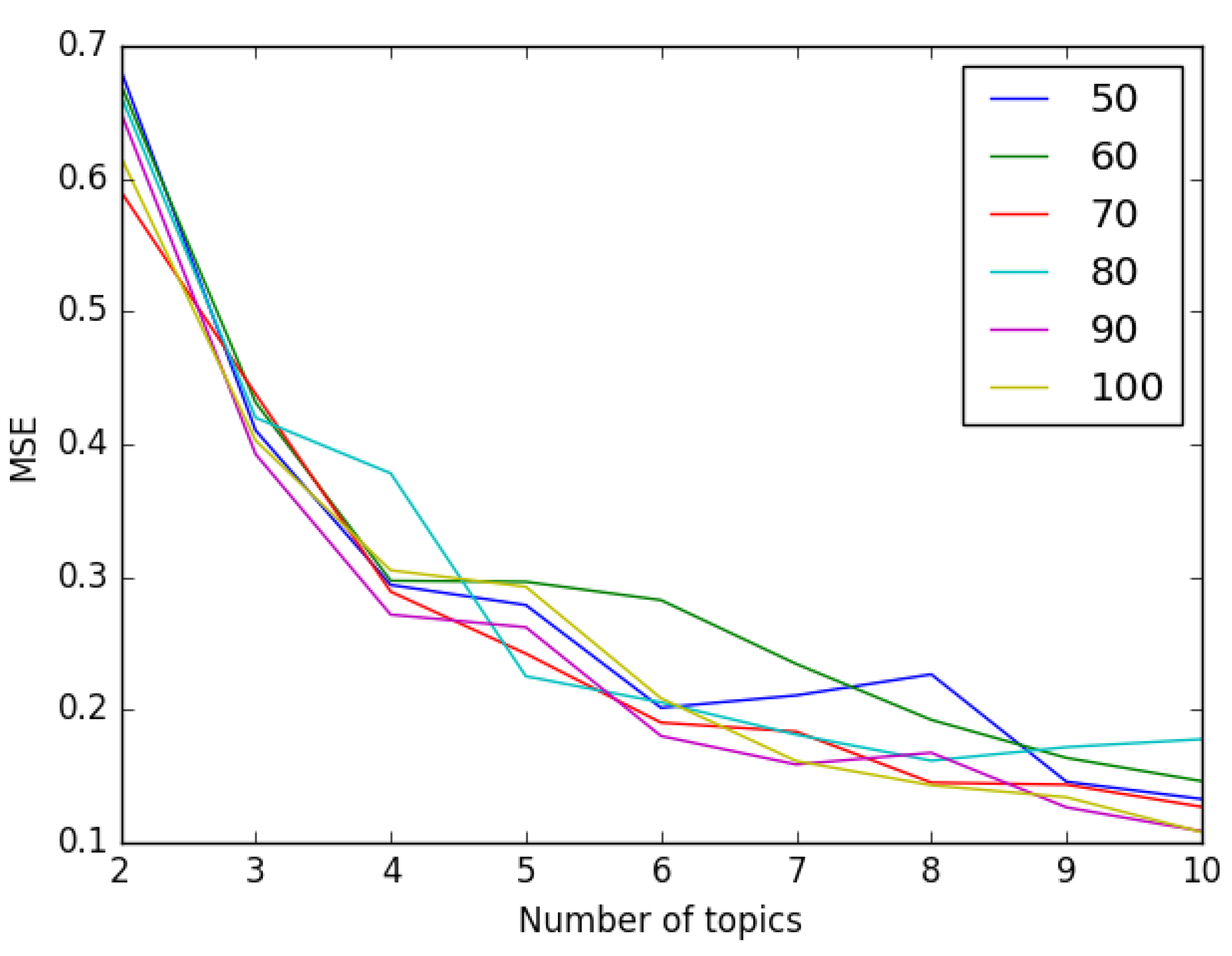
We used this information to define the number of topics and the number of words. The best set of parameters is the one that presents a higher similarity compared to the one expressing human judgment, thus the smallest Mean Squared Error (MSE). The graph in
Figure 15 shows the results obtained varying the size of the dictionary (number of cluster centroids) and the number or topics. From it, we have decided to pick 100 as the number of visual words and 10 for the topics present in our dataset.
The observed similarity results were verified by visual inspection of video logs from estimated similar players; that is, by checking how reported mixture proportions actually look similar in video. However, we state that much work should still be performed towards easily and reliably assessing model correctness and selection. This also relates to the possibility of confidently giving names to discovered motion types, very much in the way as is done in classic LDA for text categorization.
Another aspect that demands further investigation is how to avoid the decrease in accuracy when considering variable-sized game sessions. As mentioned before, game sessions with different sizes may artificially increase similarity in case one is a subset of another. The solution to this problem provides only a baseline, and much more sophisticated approaches to the problem should be devised.
We believe that a potential way for improvements in interpretability and accuracy is that of removing the vector quantization in defining each topic. It would be interesting to remain in the continuous domain defined by our input data representation (GASF features), instead of relying on a fixed predefined vocabulary set used for training the LDA. Such vectorization is known to lead to information loss [
36]. In avoiding such an issue, one possibility may be replacing the topic multinomial distribution by a mixture of Gaussians [
36].
7. Discussion
In this work, we introduced an approach to identify the player motion styles from measurements obtained by the use of a single three-axial accelerometer sensor. Such a signal is then transformed using the Gramian angular field in an image that represents its content. The reason for such representation stems from recent publications aiming at using deep learning and state-of-the-art image processing techniques for achieving better classification results. Additionally, using the autoencoder for representing the obtained GASFs reduced the workload necessary for hand-crafting features, as often done when using machine learning classification/clustering methods with time series data.
By applying latent Dirichlet allocation to characterize the motion behavior of different players, we were interested in getting a description that would foster the development of self-adjusting PIRGs agents capable of improving/sustaining engagement. In this, we had shown that the model is able to capture the overall human judgment by matching reported similarities.
This is the first work, to our knowledge, that tries to model the motion behavior of the player using this type of signal in conjunction with LDA in a robogame scenario. We have demonstrated that the proposed approach is able to cluster and represent different behaviors learned from data. We have evidence that our methodology can achieve better performances than that of relying solely on the measurements of the accelerometer as input for the dictionary learning step. We are still working to provide a fair comparison between the two approaches.
As future work, we want to test our approach with a series of different input signals in order to assess its capability. One alternative could be the incorporation of proximity information in order to capture how proximity patterns relate to a player game play style. Moreover, we are interested in measuring the player’s effort expenditure in terms of difficulty of motion given a difficult setting for the robot.
In our method, we also wish to incorporate time dependency. We believe such information would help to describe variations in playing style during play, given the opportunity to detect change points in styles and favor game (robot behavior) personalization. This also may help to avoid the rubber-band effect, a system instability concern often present when designing auto-adjusting game systems.
Another means for improvements, and one that we are currently working on, is that of removing the vector quantization step necessary for the definition of the multinomial distribution of words that defines each topic. We believe that it would be interesting to remain in the continuous domain defined by our input data, instead of relying on a fixed predefined set of tokens, i.e., the vocabulary set used for training the LDA. Our current experimentation goes along the lines of testing how a Gaussian version of LDA would work in our domain and whether that could give better results. Additionally, comparing our results with a continuous version of LDA would help to answer questions regarding stop word filtering, such as: To what extent removing certain common segments would improve or worsen accuracy?
Finally, we are working to redesign the experiments in order to allow for collecting user survey data, which comprise a valuable resource regarding player style and engagement levels. This is all in order to increase our understanding in interpreting the obtained results. We plan to collect self-reported engagement levels when comparing with different robot behavior configuration while allowing for adaptation. Regarding such adaptation, we currently are investigating how to relate the robot game’s difficult settings (such as velocity, tower LED control rules, among others) and the mixture proportion of motion types discovered by our reported method. One alternative is to design a utility function that would describe what is the pay-off in facing a certain player given a certain difficult setting, therefore turning the adaptation problem into a full on-line optimization procedure where we try to match player motion types with robot behavior implied by difficulty settings.

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














