v-Mapper: An Application-Aware Resource Consolidation Scheme for Cloud Data Centers †


Abstract
:1. Introduction
2. Related Work
2.1. VM Management in Cloud Datacenters
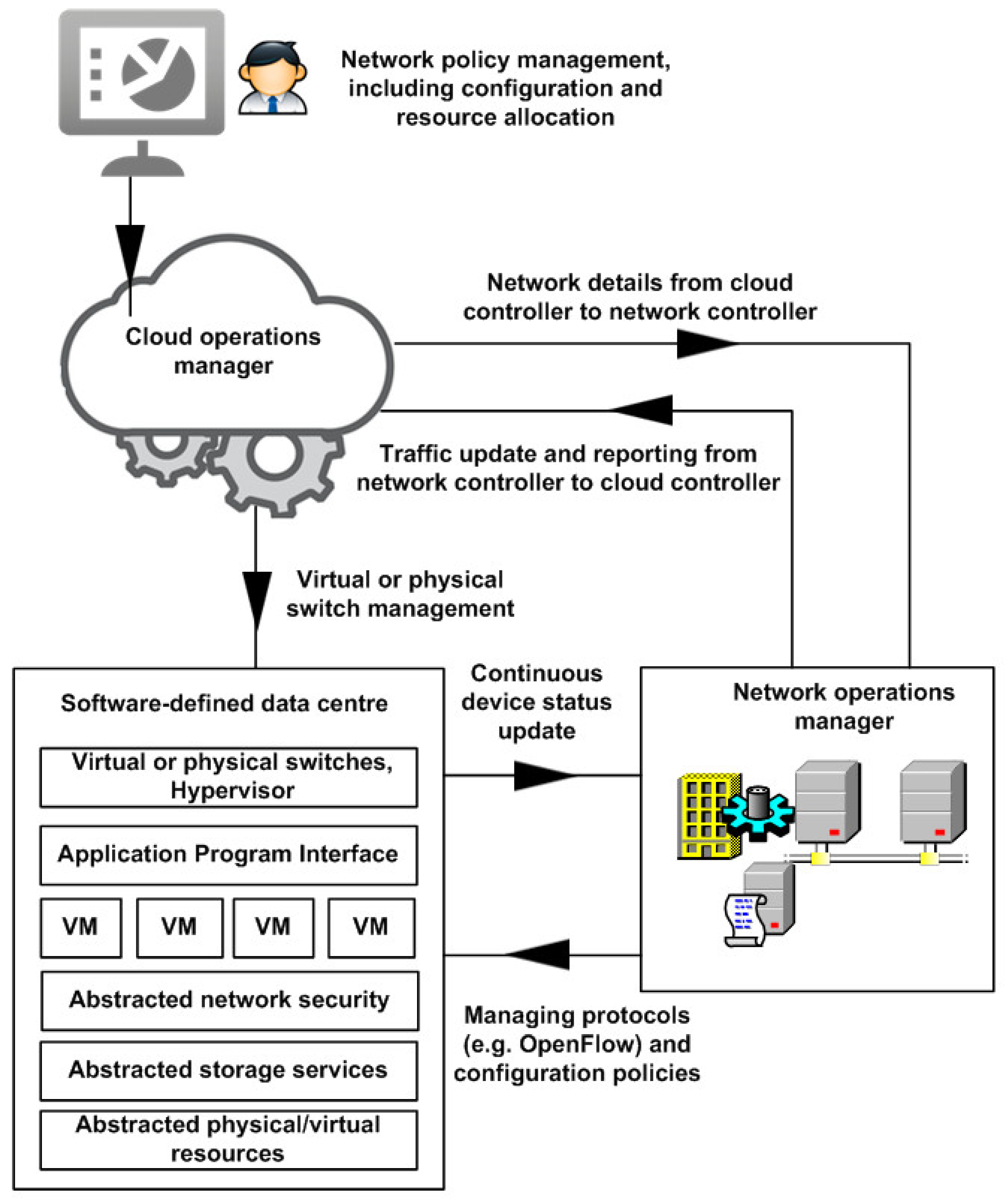
2.2. SDN Role in Datacenter Optimization
3. Application-Awareness Concepts in Cloud Datacenters
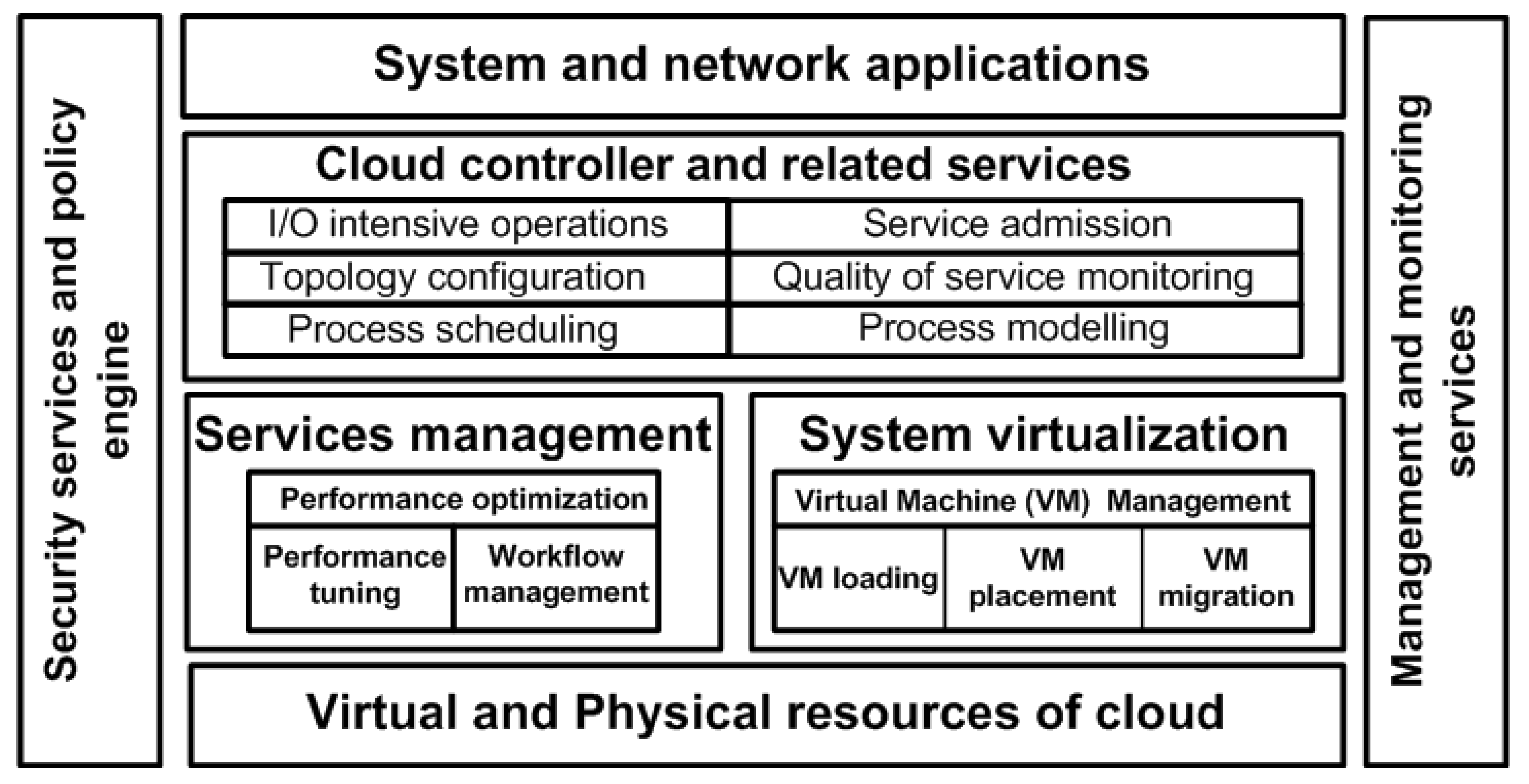
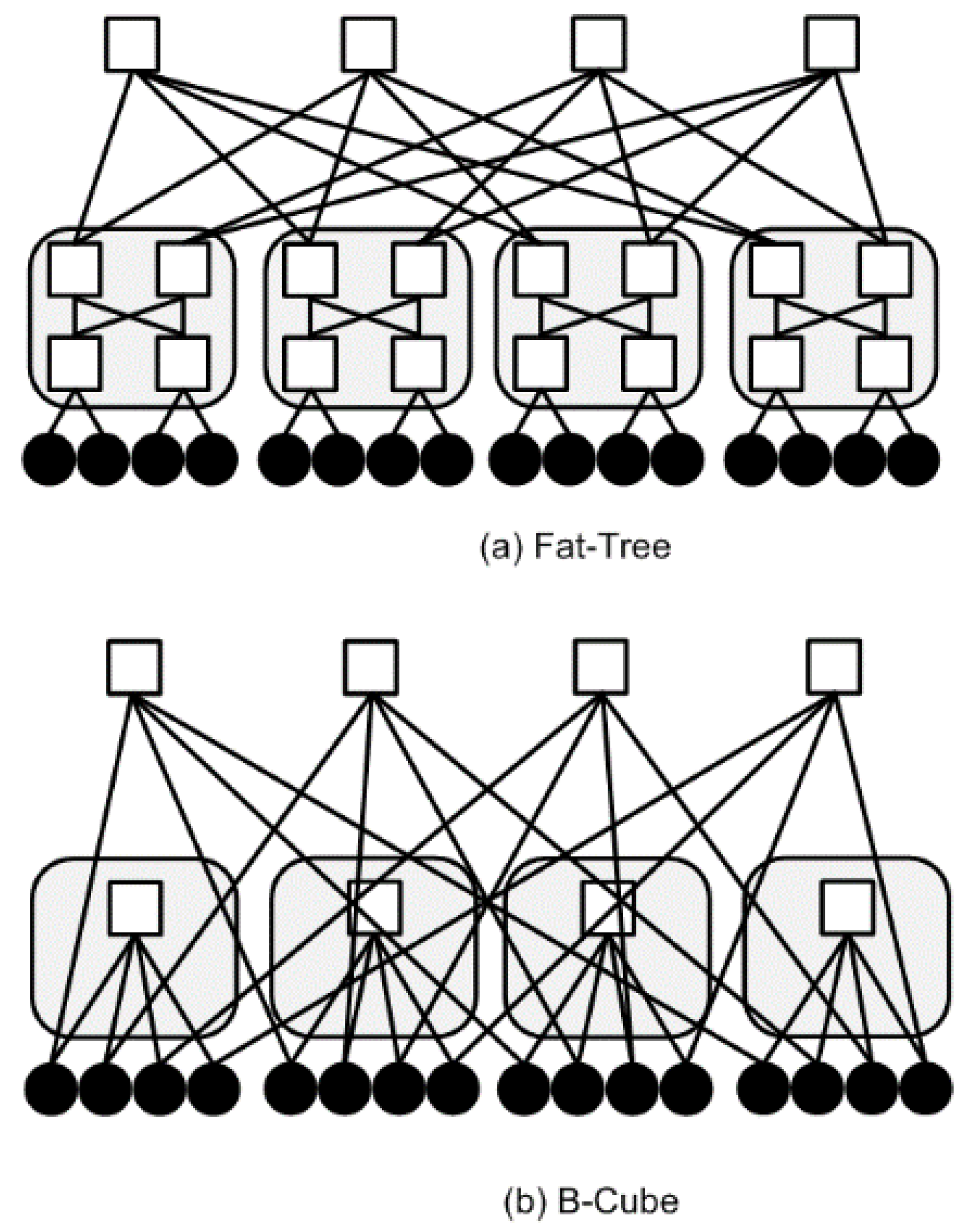
4. Data Center Design and the v-Mapper System Model
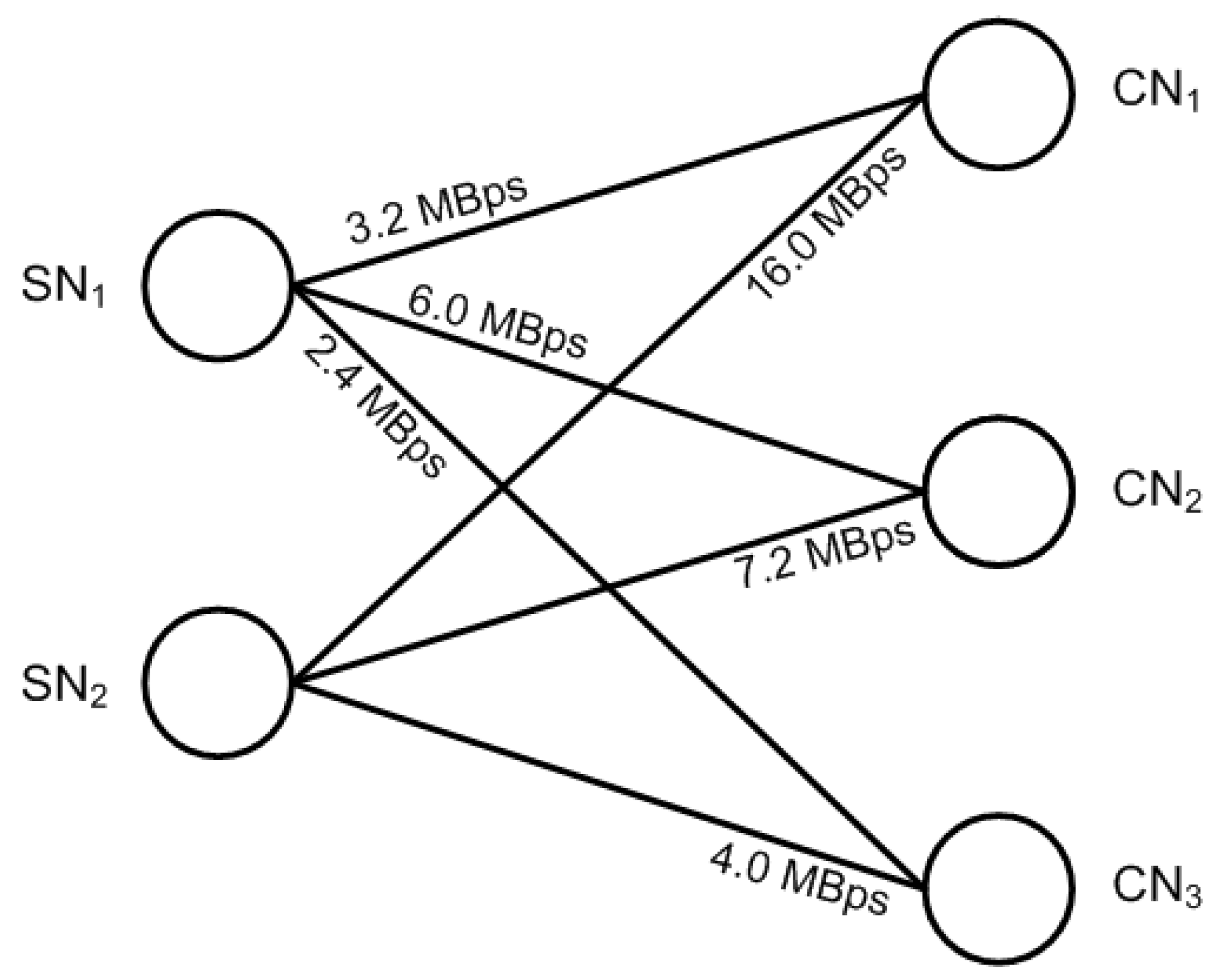
4.1. VM Placement and the Data Center Model
| Algorithm 1. VM placement | |
| 1: | Input: Load DP on SN |
| 2: | Output: VM placement decision |
| 3: | Let CN denote Compute Node of a cloud network |
| 4: | Let tCN,i denote service response time of a CNi |
| 5: | Let least denote least response time of all CN |
| 6: | Let j denote the CN with least response time |
| 7: | Calculate tR for each CN as |
| 8: | tCN,i = |
| 9: | i ⟵ 0 |
| 10: | j ⟵ 0 |
| 11: | least ⟵ tCN,0 |
| 12: | while I < n do |
| 13: | if least > tCN,i then |
| 14: | least ⟵ tCN,i |
| 15: | j ⟵ i |
| 16: | end if |
| 17: | i ⟵ i + 1 |
| 18: | end while |
| 19: | Place VM on CN j |
| 20: | Exit |
4.2. VM Workload Admission
- (1)
- First, we determine the factor and sub-factor weights for cloud services through an evaluation index (U). The factor and sub-factor weights are assigned through priority criteria of AHP. A simple case example is presented in [1] and can be used to measure functions influencing a cloud service’s resource management concerns.
- (2)
- “Not all clouds are created equal”; therefore, we create a set of comments (V) to describe the evaluation of cloud services by using phrases such as “Acceptable”, “Constrained”, etc. These are determined based on Saaty’s 1 to 9 scale [26] to describe the preferences between alternatives as being either equally, moderately, strongly, very strongly or extremely preferred.
- (3)
- To provide a comprehensive assessment methodology, we create an evaluation matrix (R) from U to V, where each factor ui (i ≤ n) can be written as a fuzzy vector Ri ∈ μ(V). Mathematically, this fuzzy relationship can be expressed as:The evaluated result of Equation (6) should match the normalized conditions, because the sum of the weight of the vector is 1 (i.e., for i, ri1 + ri2 + ri3 +…….. + rim = 1).
- (4)
- A factor assigned to a number in a computation system reflects its importance.The greater the weight of a factor is, the more importance it has in the system. We, therefore, determine the factor weight (FW) of each factor in the evaluation index (U) system.
- (5)
- We obtain the evaluation result (E) through the product of the factor weight (FW) and the evaluation matrix (R). This can be denoted as E = FW(R) = (E1, E2, E3,…, Em). Finally, the evaluated weight now can be assigned to the respective application.
| Algorithm 2. VM workload admission | |
| 1: | Input: Workload admission request |
| 2: | Output: Workload admission decision |
| 3: | Let resava denote the available resources for a VM |
| 4: | Let resreq denote the requested resources by a VM |
| 5: | Let queue denote the request queue |
| 6: | while (!queue.isEmpty()) |
| 7: | { |
| 8: | req = queue.firstRequestResource(); |
| 9: | if (resreq ≤ resava) |
| 10: | { |
| 11: | resava = resava − resreq |
| 12: | queue.pop(); |
| 13: | } |
| 14: | Else |
| 15: | { |
| 16: | sendMessage(“resources inadequate”); |
| 17: | queue.pop(); |
| 18: | } |
| 19: | } |
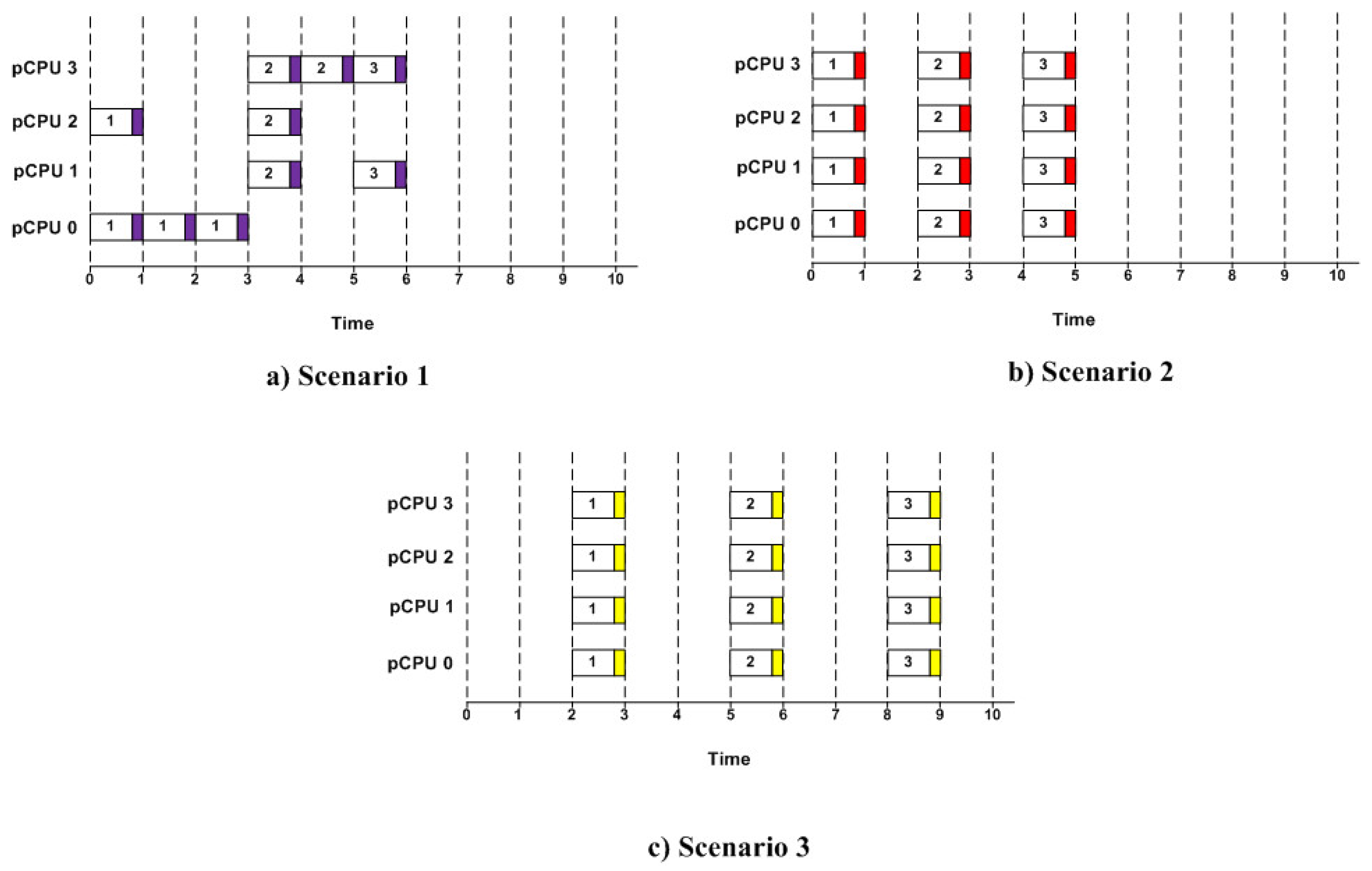
4.3. VM Scheduling Scheme
| Algorithm 3. VM scheduling policy | |
| Input: qi: represent a new request i; Rqi: the (required) resources for a service request i; Rt: system threshold for the resource, Pqi: priority of request i; N: request number in a memory buffer br. | |
| Output: scheduling decision | |
| 1: | Let priority = |
| 2: | while Rqi ≤ Rt do |
| 3: | Assign request qi its calculated priority value |
| 4: | Push qi to br |
| 5: | end while |
| 6: | /* Sort buffer requests by priority in descending order */ |
| 7: | for I ⟵ 0 to N do |
| 8: | for j ⟵ 0 to N-2-i do |
| 9: | if Pqj < Pq(j+1) do |
| 10: | Pqj ↔ Pq(j+1) |
| 11: | end if |
| 12: | end for |
| 13: | end for |
| 14: | /* Process all sorted VM requests */ |
| 15: | for i ⟵ 0 to N do |
| 16: | Process(qi) |
| 17: | end for |
| 18: | exit |
5. Performance Test Bed and Simulation Environment
5.1. Baseline Strategies and Compared Scenarios
5.2. Simulation Set-Up and Settings
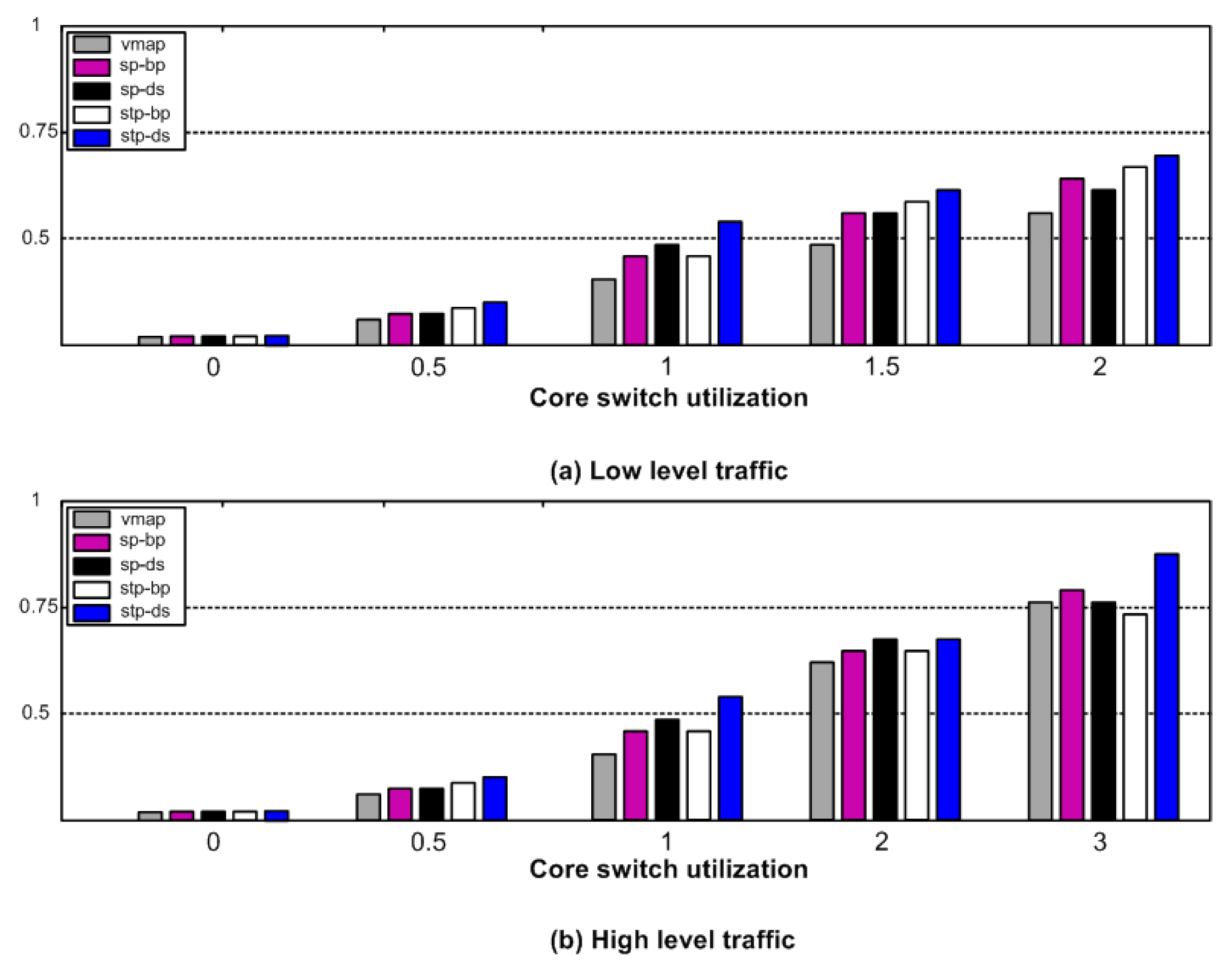
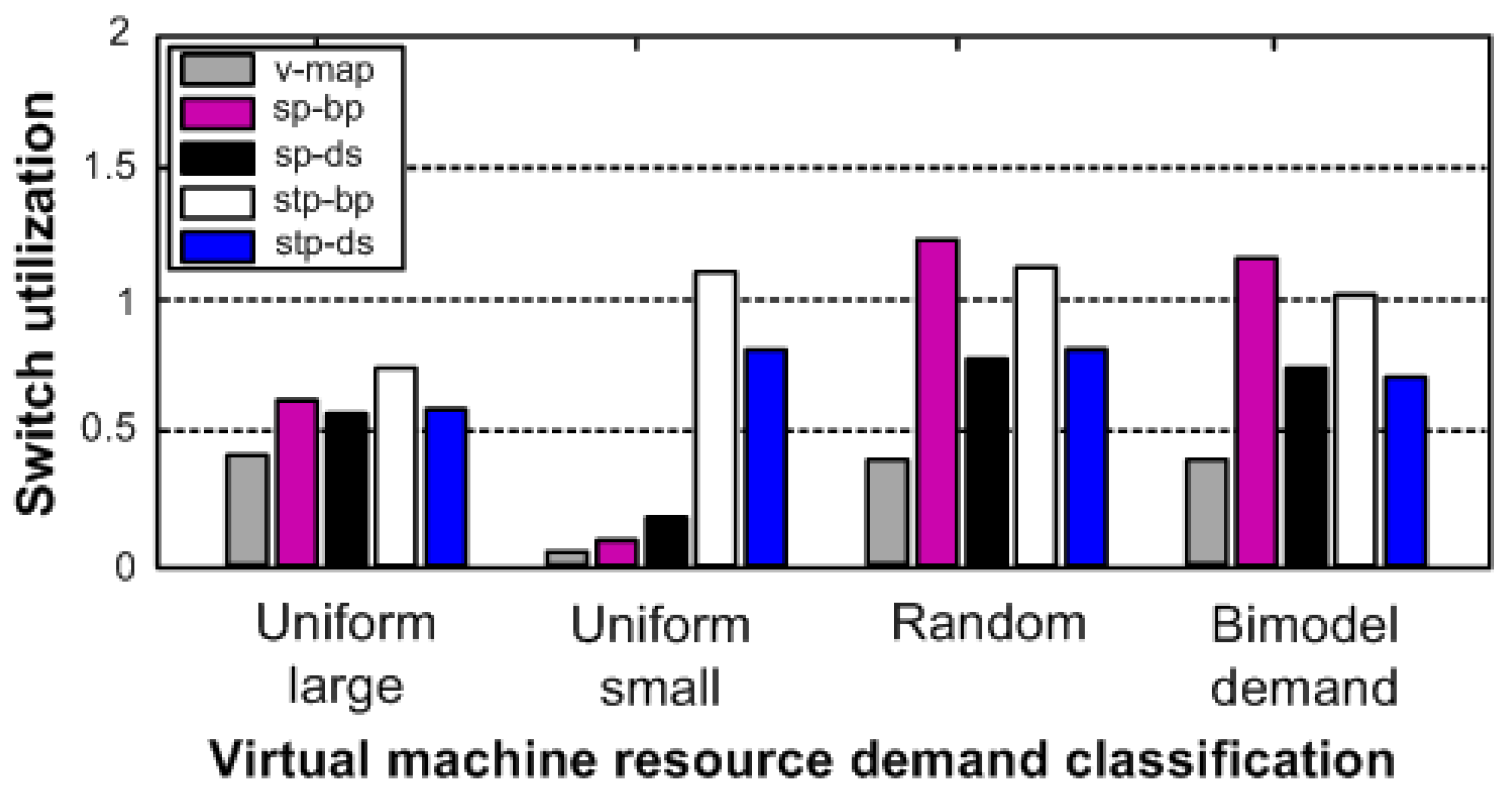
6. Performance Results and Analysis
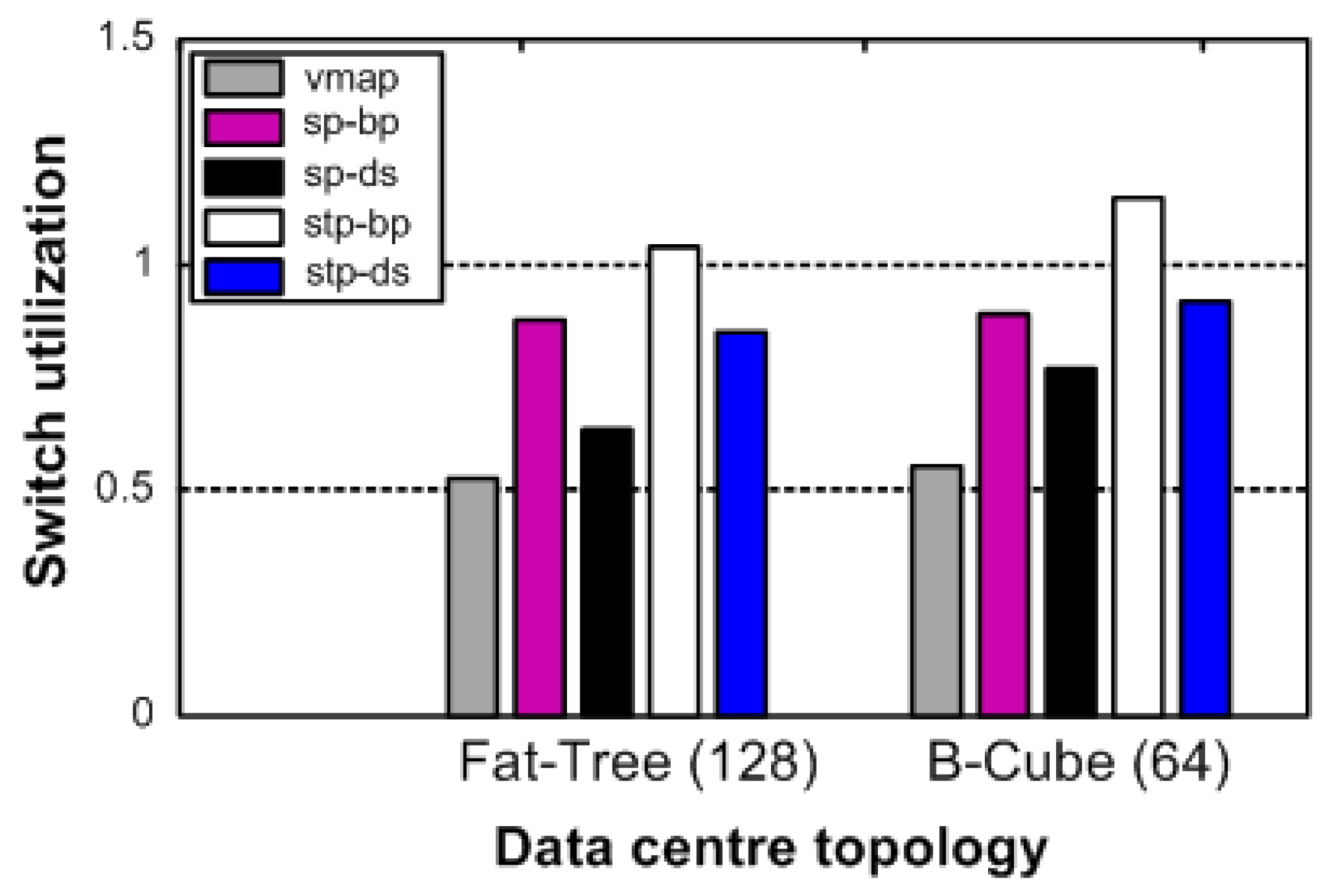
6.1. Impact on Data Center Topologies
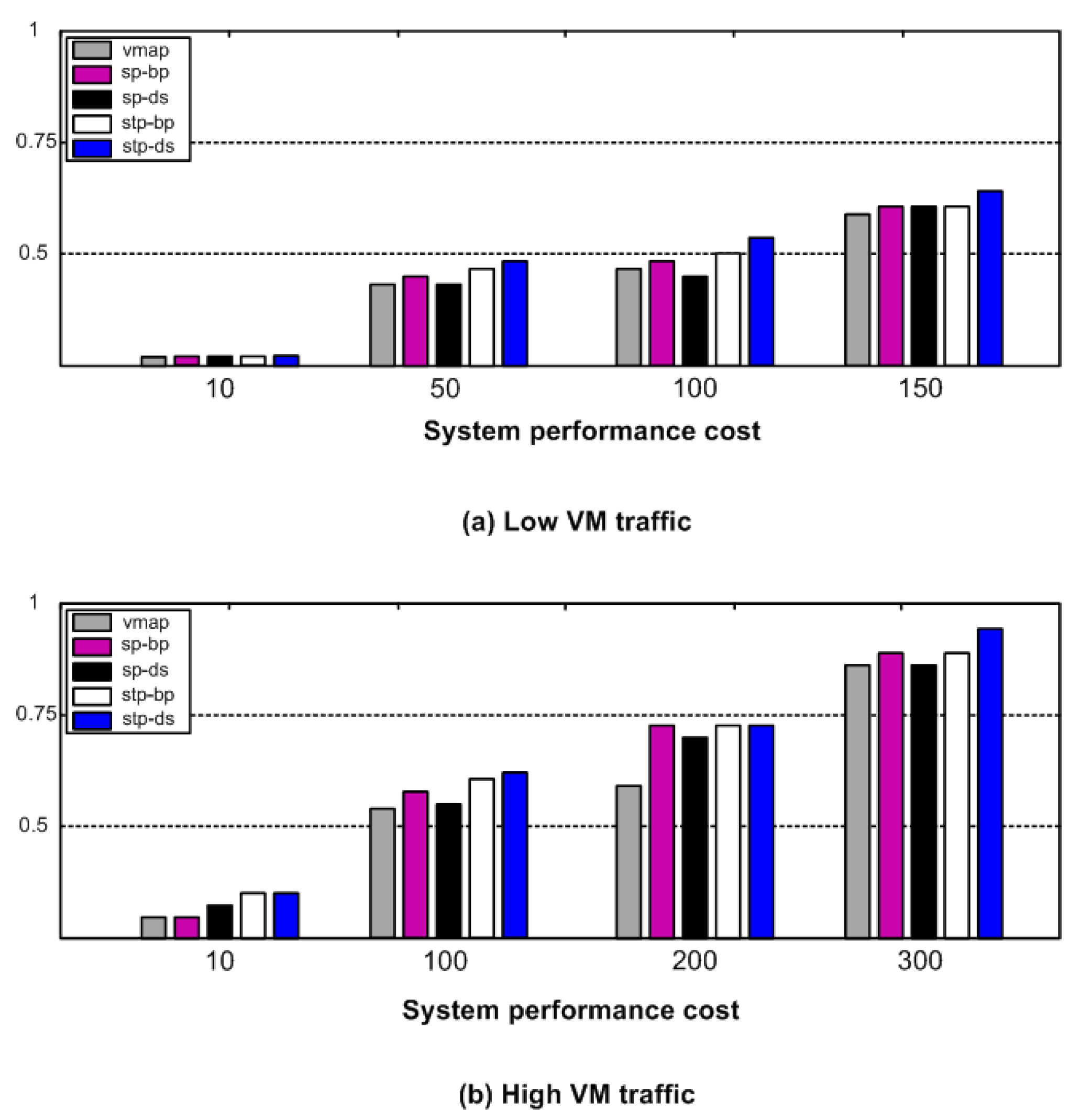
6.2. Performance Cost
6.3. VM Resource Occupancy
7. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Abbasi, A.A.; Jin, H.; Wu, S. A Software-Defined Cloud Resource Management Framework. In Proceedings of the Asia-Pacific Services Computing Conference, Bangkok, Thailand, 7–9 December 2015. [Google Scholar]
- Armbrust, M.; Fox, A.; Griffith, R.; Joseph, A.D.; Katz, R.; Konwinski, A.; Lee, G.; Patterson, D.; Rabkin, A.; Stoica, I.; et al. A view of cloud computing. Commun. ACM 2010, 53, 50–58. [Google Scholar] [CrossRef]
- Wu, S.; Zhou, L.; Sun, H.; Jin, H.; Shi, X. Poris: A Scheduler for Parallel Soft Real-Time Applications in Virtualized Environments. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 841–854. [Google Scholar] [CrossRef]
- Wu, S.; Chen, H.; Di, S.; Zhou, B.; Xie, Z.; Jin, H.; Shi, X. Synchronization-Aware Scheduling for Virtual Clusters in Cloud. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 2890–2902. [Google Scholar] [CrossRef]
- Greenberg, A.; Hamilton, J.; Maltz, D.A.; Patel, P. The cost of a cloud: Research problems in data center networks. Comput. Commun. Rev. 2008, 39, 68–73. [Google Scholar] [CrossRef]
- Liao, X.; Jin, H.; Liu, Y.; Ni, L.M.; Deng, D. AnySee: Peer-to-Peer Live Streaming. In Proceedings of the IEEE International Conference on Computer Communications, Barcelona, Spain, 23–29 April 2006; pp. 1–10. [Google Scholar]
- Kim, H.; Feamster, N. Improving network management with software defined networking. IEEE Commun. Mag. 2013, 51, 114–119. [Google Scholar] [CrossRef]
- Monsanto, C.; Reich, J.; Foster, N.; Rexford, J.; Walker, D. Composing software defined networks. In Proceedings of the USENIX Symposium on Networked Systems Design and Implementation, Lombard, IL, USA, 2–5April 2013; pp. 1–13. [Google Scholar]
- Jin, H. When Data Grows Big. Computer 2014, 12, 8. [Google Scholar] [CrossRef]
- Wang, M.; Meng, X.; Zhang, L. Consolidating virtual machines with dynamic bandwidth demand in data centers. In Proceedings of the IEEE International Conference on Computer Communications, Shanghai, China, 10–15 April 2011; pp. 71–75. [Google Scholar]
- Piao, J.T.; Yan, J. A network-aware virtual machine placement and migration approach in cloud computing. In Proceedings of the International Conference on Grid and Cooperative Computing, Nanjing, China, 1–5 November 2010; pp. 87–92. [Google Scholar]
- Meng, X.; Pappas, V.; Zhang, L. Improving the scalability of data center networks with traffic-aware virtual machine placement. In Proceedings of the IEEE International Conference on Computer Communications, San Diego, CA, USA, 15–19 March 2010; pp. 1–9. [Google Scholar]
- Wang, S.H.; Huang, P.P.W.; Wen, C.H.P.; Wang, L.C. EQVMP: Energy-efficient and QoS-aware virtual machine placement for software defined datacenter networks. In Proceedings of the IEEE International Conference on Information Networking, Phuket, Thailand, 10–12 February 2014; pp. 220–225. [Google Scholar]
- Bobroff, N.; Kochut, A.; Beaty, K. Dynamic placement of virtual machines for managing SLA violations. In Proceedings of the 10th IFIP/IEEE International Symposium on Integrated Network Management, Munich, Germany, 21–25 May 2007; pp. 119–128. [Google Scholar]
- Gong, Z.; Gu, X. Pac: Pattern-driven application consolidation for efficient cloud computing. In Proceedings of the IEEE International Symposium on Modeling, Analysis & Simulation of Computer and Telecommunication Systems, Miami, FL, USA, 17–19 August 2010; pp. 24–33. [Google Scholar]
- Calcavecchia, N.M.; Biran, O.; Hadad, E.; Moatti, Y. VM placement strategies for cloud scenarios. In Proceedings of the IEEE International Conference on Cloud Computing, Honolulu, HI, USA, 24–29 June 2012; pp. 852–859. [Google Scholar]
- Katta, N.P.; Rexford, J.; Walker, D. Incremental consistent updates. In Proceedings of the Second ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking, Hongkong, China, 16 August 2013; pp. 49–54. [Google Scholar]
- Foster, N.; Guha, A.; Reitblatt, M.; Story, A.; Freedman, M.J.; Katta, N.P.; Mosanto, C.; Reich, J.; Rexford, J.; Schlesinger, C.; et al. Languages for software-defined networks. IEEE Commun. Mag. 2013, 51, 128–134. [Google Scholar] [CrossRef] [Green Version]
- Banikazemi, M.; Olshefski, D.; Shaikh, A.; Tracey, J.; Wang, G. Meridian: An SDN platform for cloud network services. IEEE Commun. Mag. 2013, 51, 120–127. [Google Scholar] [CrossRef]
- Sherry, J.; Hasan, S.; Scott, C.; Krishnamurthy, A.; Ratnasamy, S.; Sekar, V. Making middleboxes someone else’s problem: Network processing as a cloud service. Comput. Commun. Rev. 2012, 42, 13–24. [Google Scholar] [CrossRef]
- Jin, H.; Abbasi, A.A.; Song, W. Pathfinder: Application-aware distributed path computation in clouds. Int. J. Parallel Prog. 2017, 45, 1273–1284. [Google Scholar] [CrossRef]
- Binz, T.; Breiter, G.; Leyman, F.; Spatzier, T. Portable cloud services using tosca. IEEE Internet Comput. 2012, 16, 80–85. [Google Scholar] [CrossRef]
- Mahindru, R.; Sarkar, R.; Viswanathan, M. Software defined unified monitoring and management of clouds. IBM J. Res. Dev. 2014, 58, 1–12. [Google Scholar] [CrossRef]
- Chang, D.; Xu, G.; Hu, L.; Yang, K. A network-aware virtual machine placement algorithm in mobile cloud computing environment. In Proceedings of the IEEE Wireless Communications and Networking Conference Workshops, Shanghai, China, 7–10 April 2013; pp. 117–122. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Saaty, T.L. What is the analytic hierarchy process? In Mathematical Models for Decision Support; Springer: Berlin, Germany, 1988; pp. 109–121. [Google Scholar]
- Bonald, T.; Virtamo, J. A recursive formula for multirate systems with elastic traffic. IEEE Commun. Lett. 2005, 9, 753–755. [Google Scholar] [CrossRef] [Green Version]
- Kaufman, J.S.; Rege, K.M. Blocking in a shared resource environment with batched Poisson arrival processes. Perform. Eval. 1996, 24, 249–263. [Google Scholar] [CrossRef]
- Cherkasova, L.; Gupta, D.; Vahdat, A. Comparison of the three CPU schedulers in Xen. Perform. Eval. Rev. 2007, 35, 42–51. [Google Scholar] [CrossRef] [Green Version]
- Jiang, J.W.; Lan, T.; Ha, S.; Chen, M.; Chiang, M. Joint VM placement and routing for data center traffic engineering. In Proceedings of the IEEE International Conference on Computer Communications, Orlando, FL, USA, 25–30 March 2012; pp. 2876–2880. [Google Scholar]
- Guo, C.; Lu, G.; Li, D.; Wu, H.; Zhang, X.; Shi, Y.; Tian, C.; Zhang, Y.; Wu, S. BCube: A high performance, server-centric network architecture for modular data centers. Comput. Commun. Rev. 2009, 39, 63–74. [Google Scholar] [CrossRef]
- Shojafar, M.; Cordeschi, N.; Baccarelli, E. Energy-efficient adaptive resource management for real-time vehicular cloud services. IEEE Trans. Cloud Comput. 2016. [Google Scholar] [CrossRef]
- Shojafar, M.; Canali, C.; Lancelotti, R.; Abawajy, J. Adaptive computing-plus-communication optimization framework for multimedia processing in cloud systems. IEEE Trans. Cloud Comput. 2016. [Google Scholar] [CrossRef]
- Canali, C.; Chiaraviglio, L.; Lancellotti, R.; Shojafar, M. Joint Minimization of the Energy Costs from Computing, Data Transmission, and Migrations in Cloud Data Centers. IEEE Trans. Green Commun. Netw. 2018, 2, 580–595. [Google Scholar] [CrossRef]
- Chiaraviglio, L.; D’Andregiovanni, F.; Lancellotti, R.; Shojafar, M.; Melazzi, N.B.; Canali, C. An Approach to Balance Maintenance Costs and Electricity Consumption in Cloud Data Centers. IEEE Trans. Sustain. Comput. 2018. [Google Scholar] [CrossRef]
- Rezaei, R.; Chiew, T.K.; Lee, S.P.; Shams, A.Z. A semantic interoperability framework for software as a service systems in cloud computing environments. Exp. Syst. Appl. 2014, 41, 5751–5770. [Google Scholar] [CrossRef]
- Shiau, W.L.; Chau, P.Y.K. Understanding behavioral intention to use a cloud computing classroom: A multiple model comparison approach. Inf. Manag. 2016, 53, 355–365. [Google Scholar] [CrossRef]
- Dillon, T.; Wu, C.; Chang, E. Cloud computing: Issues and challenges. In Proceedings of the 24th IEEE International Conference on Advanced Information Networking and Applications (AINA’10), Perth, Australia, 20–23 April 2010; pp. 27–33. [Google Scholar]
- Fan, M.; Kumar, S.; Whinston, A.B. Short-term and long term competition between providers of shrink-wrap software and software as a service. Eur. J. Oper. Res. 2009, 196, 661–671. [Google Scholar] [CrossRef]
- Palos-Sanchez, P.R.; Arenas-Marquez, F.J.; Aguayo-Camacho, M. Cloud Computing (SaaS) adoption as a strategic technology: Results of an empirical study. Mob. Inf. Syst. 2017, 2017, 2536040. [Google Scholar] [CrossRef]
- Sultan, N.A. Reaching for the “cloud”: How SMEs can manage. Int. J. Inf. Manag. 2011, 31, 272–278. [Google Scholar] [CrossRef]
- Palos-Sanchez, P.R. Drivers and Barriers of the Cloud Computing in SMEs: The Position of the European Union. Harvard Deusto Bus. Res. 2017, 6, 116–132. [Google Scholar] [CrossRef]
- Malik, S.U.R.; Khan, S.U.; Ewenet, S.J. Performance analysis of data intensive cloud systems based on data management and replication: A survey. Distrib. Parallel Databases 2016, 34, 179–215. [Google Scholar] [CrossRef]
- Haag, S.; Eckhardt, A. Organizational cloud service adoption: A scientometric and content-based literature analysis. J. Bus. Econ. 2014, 84, 407–440. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| SN | Storage Node |
| DP | Data Packets |
| U | Evaluation index |
| V | Set of comments |
| R | Evaluation matrix |
| FW | Factor Weight |
| P | Probability |
| SR | Shared Resources (Available) |
| SFL | Shared Fair Load |
| Qreq | Scheduling Request Query |
| Rt | System Threshold Capacity |
| Br | Buffered requests |
| Pqi | Priority value |
| B | Adjacency matrix between storage and cloud node matrices as i and j |
| N | Number of aggregate compute nodes |
| Shared fair load SFL of the shared resource SR |
| Size | Request Range |
|---|---|
| Uniform small | 30 percent |
| Uniform large | 100 percent |
| Random | 0 to 100 percent |
| Bimodel demand | Normal distributions N (0:3;0:1) and N (0:7;0:1) with equal probability |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbasi, A.A.; Jin, H. v-Mapper: An Application-Aware Resource Consolidation Scheme for Cloud Data Centers. Future Internet 2018, 10, 90. https://doi.org/10.3390/fi10090090
Abbasi AA, Jin H. v-Mapper: An Application-Aware Resource Consolidation Scheme for Cloud Data Centers. Future Internet. 2018; 10(9):90. https://doi.org/10.3390/fi10090090
Chicago/Turabian StyleAbbasi, Aaqif Afzaal, and Hai Jin. 2018. "v-Mapper: An Application-Aware Resource Consolidation Scheme for Cloud Data Centers" Future Internet 10, no. 9: 90. https://doi.org/10.3390/fi10090090
APA StyleAbbasi, A. A., & Jin, H. (2018). v-Mapper: An Application-Aware Resource Consolidation Scheme for Cloud Data Centers. Future Internet, 10(9), 90. https://doi.org/10.3390/fi10090090