1. Introduction
Ontology-based data access (OBDA) [
1,
2] is a paradigm for accessing data using a conceptual representation of the domain of interest expressed as an ontology. An OBDA system relies on a three-level architecture, consisting of the data layer, the ontology, and the mapping between the two. More in detail,
the data layer is constituted by the existing data sources that are relevant for the organization,
the ontology is a declarative and explicit representation of the domain of interest for the organization, formulated in a description logic (DL) [
3] so as to take advantage of various reasoning capabilities in accessing data,
the mapping is a set of declarative assertions specifying how the sources in the data layer relate to the ontology.
Several OBDA projects have been carried out in recent years [
4,
5,
6,
7], and various OBDA management systems have been designed to support OBDA applications, e.g., [
8,
9,
10]. In current OBDA systems the ontology is expressed as a DL TBox, i.e., a set of assertions on the relevant concepts and roles (i.e., binary relationships between concepts) of the domain of interest, constituting the intensional level of the representation, and the mapping assertions are used to specify how the data at the sources correspond to the instances of the concepts and the relations, which form the extensional level of the representation. Thus, the mapping assertions, together with the source data, determine the so-called virtual ABox, in the sense that the instance assertions are not explicitly given but are specified through the relationships between the data and the elements of the TBox.
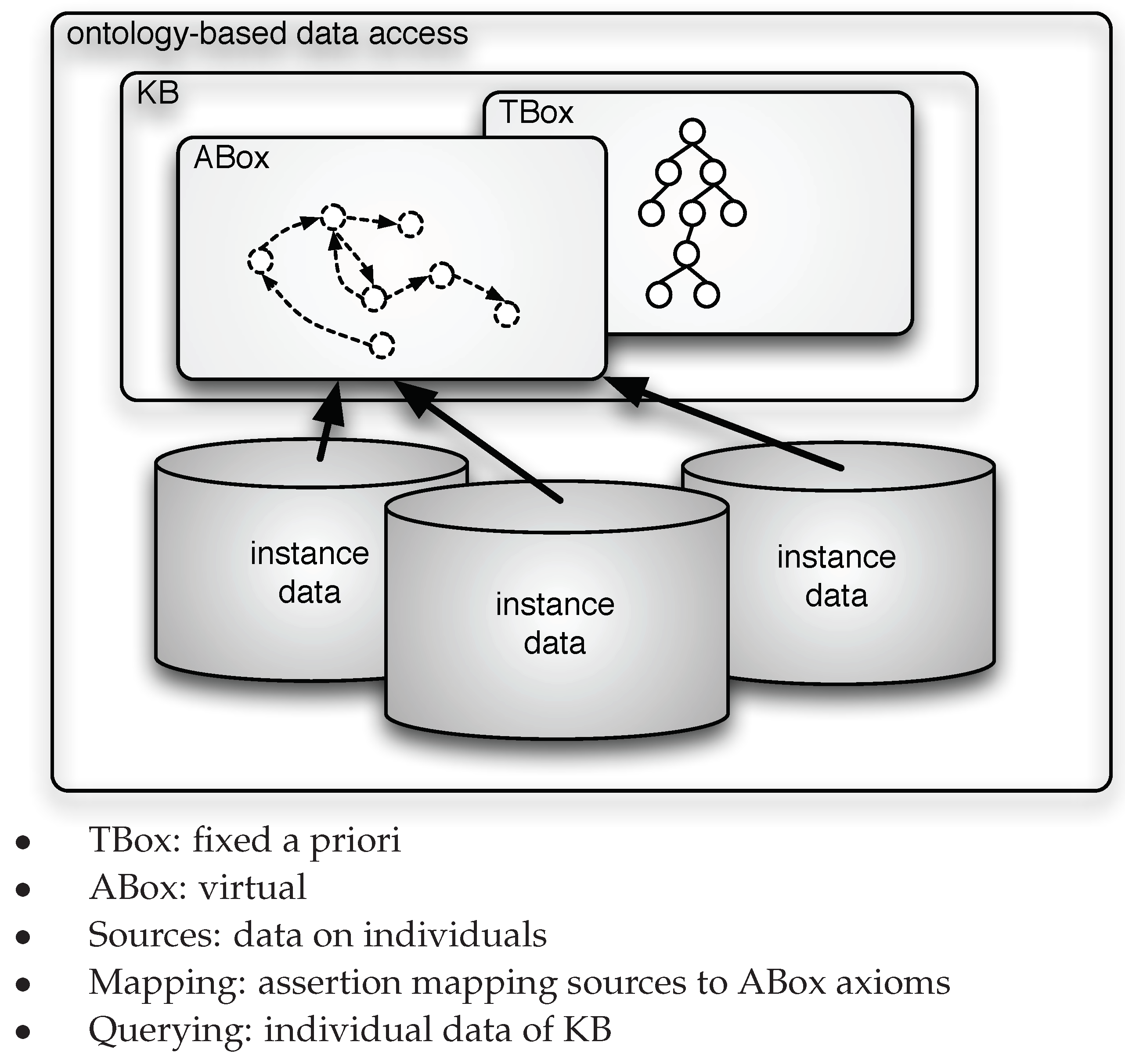
From the above observations it should be clear that current works on OBDA share the idea, originally stemmed in data integration and in data exchange [
11,
12,
13,
14], that mappings are used to (virtually) retrieve extensional information of the ontology from the sources, as shown in
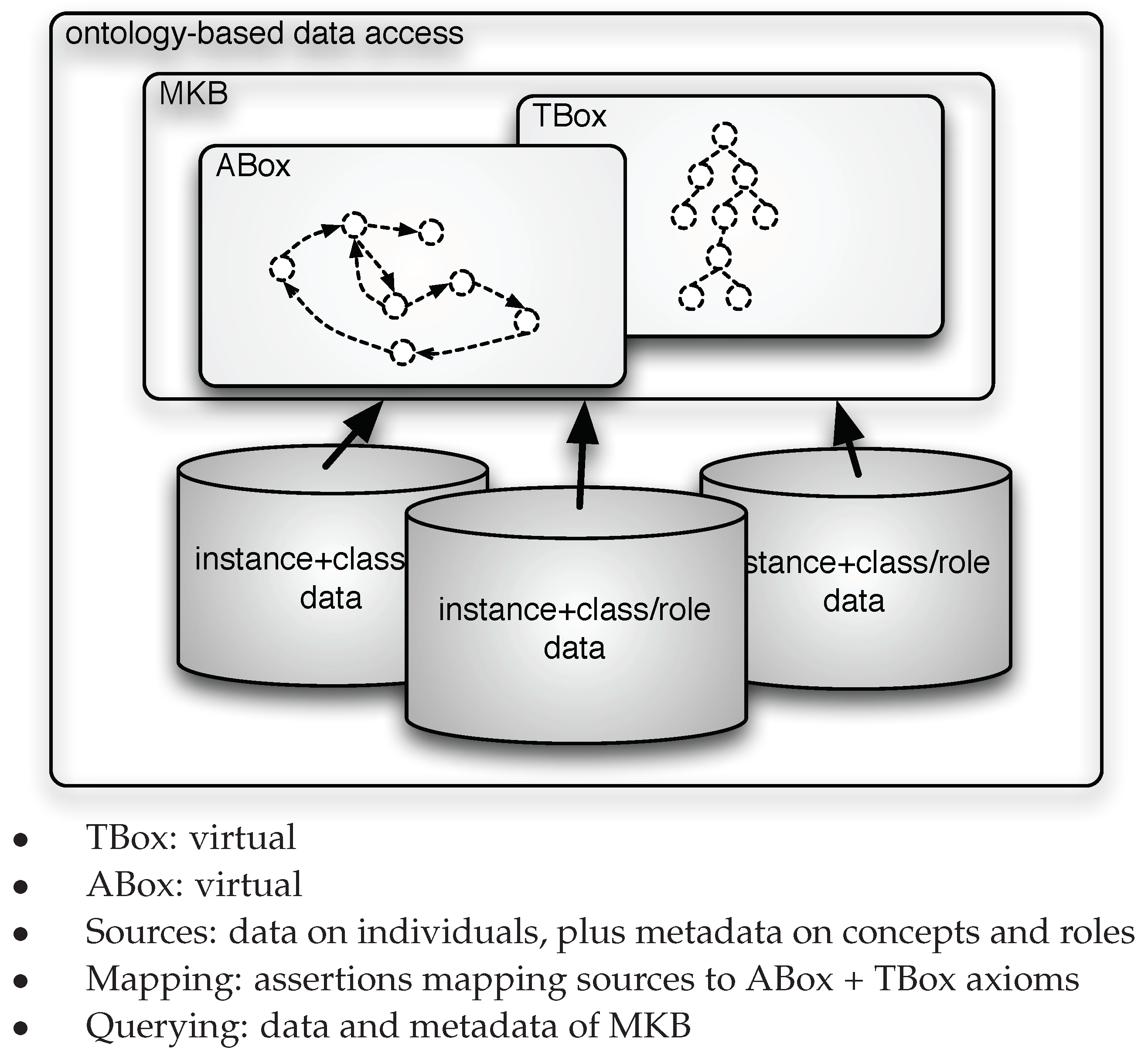
Figure 1, while the intensional level information, represented by the TBox, remains fixed a priori, once and for all. In this paper, we challenge this preconception and propose to adopt a virtual approach to the specification of the TBox, thus virtualizing both the extensional and the intensional level of the ontology. In other words, we propose a setting where not only the ABox but also the TBox is specified through mappings linking the data to the ontology, as illustrated in
Figure 2. Our approach is based on addressing two issues.
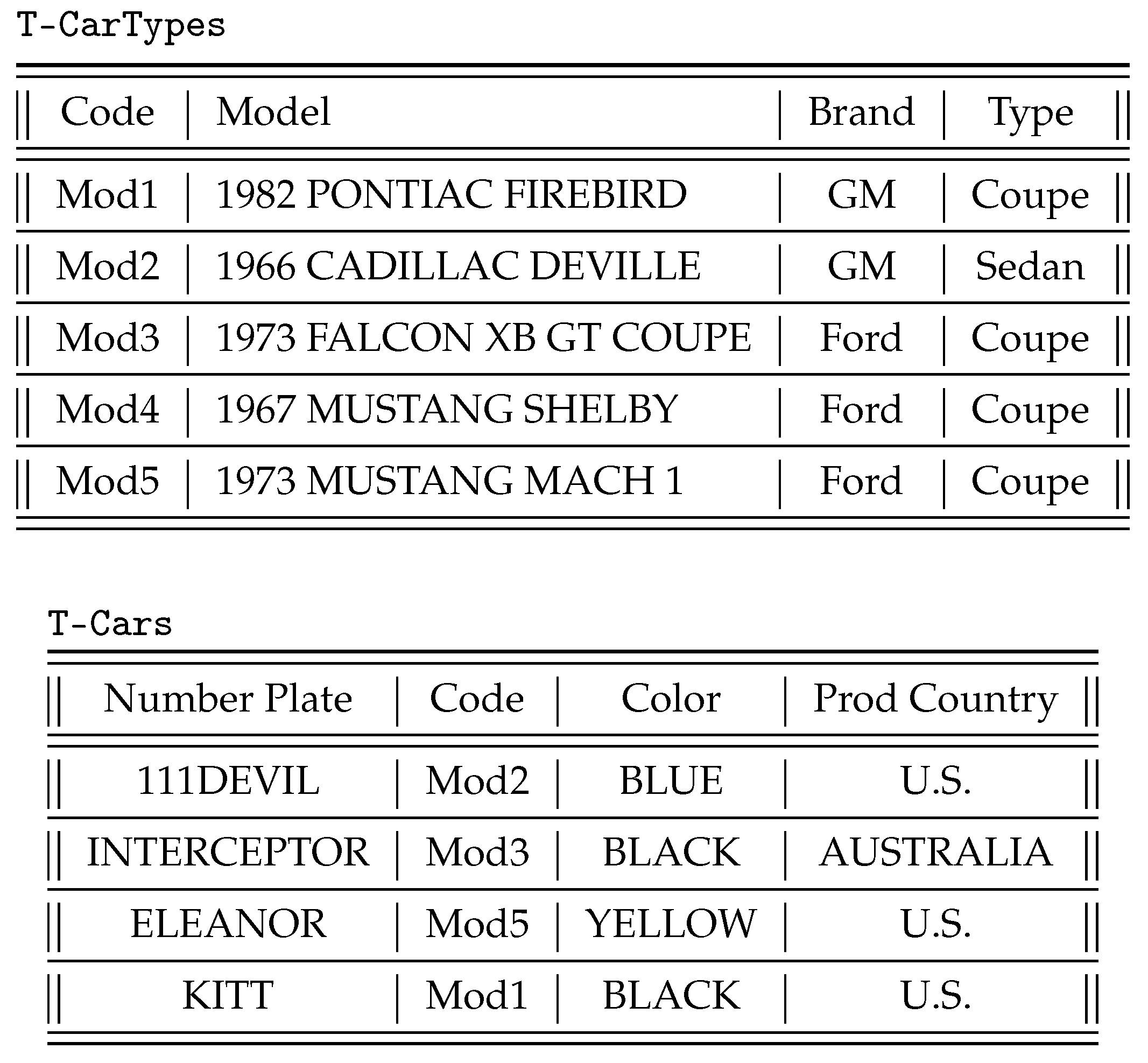
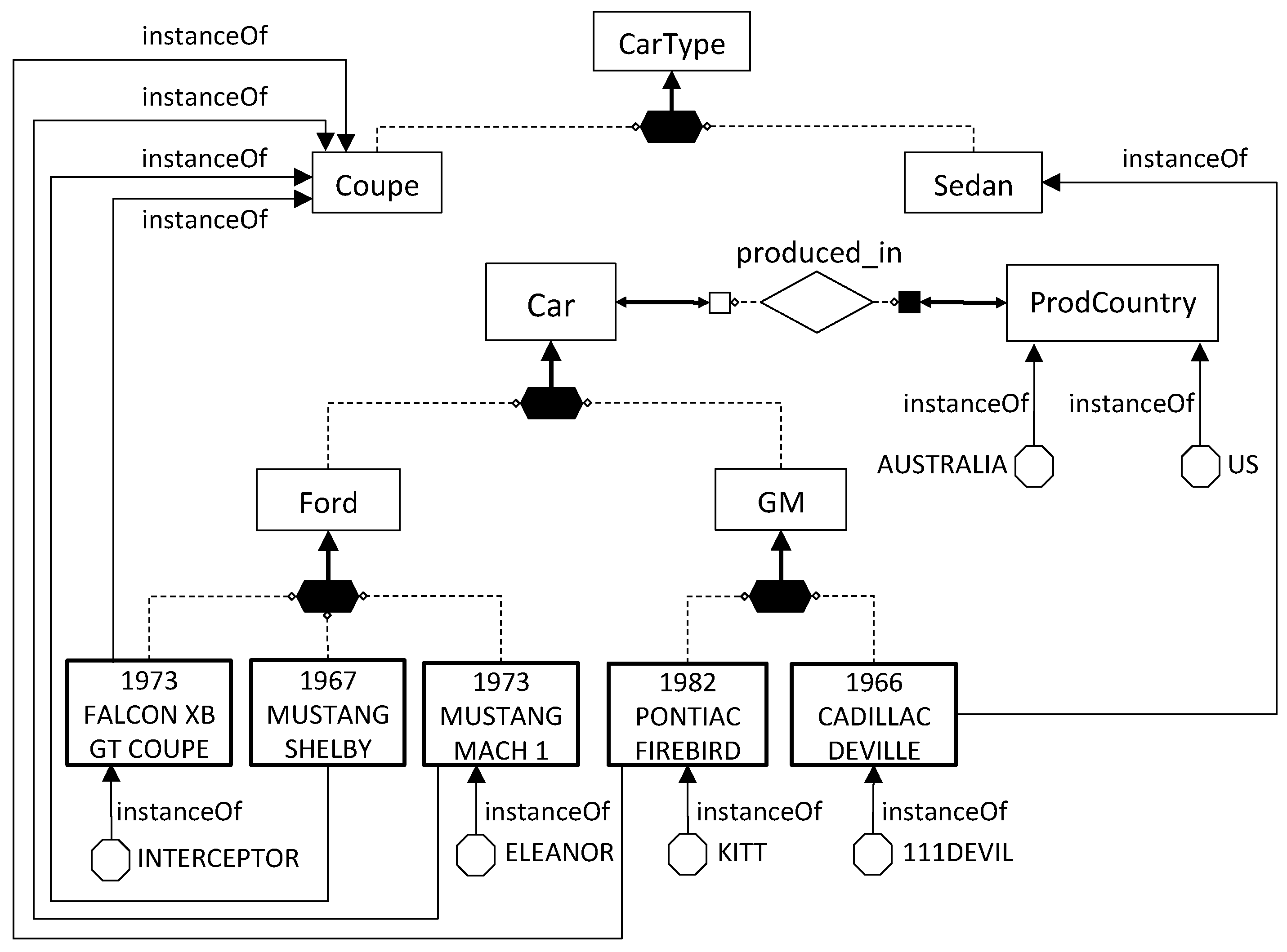
The first issue is related to looking at the content of the data sources to identify concepts and roles that are relevant to the domain of interest but that have not been modeled in the TBox, because they were not known at design time. As an example, the database
in
Figure 3 stores data about different models and different types of cars manufactured by motor companies (table
T-CarTypes), as well as various cars of such types (table
T-Cars). If we look carefully at the semantics of the data in
, we realize that such database not only stores information about the instances of the concepts in the domain of interest (e.g., the first row of table
T-Cars collects data about an instance of the concept
Car) but contains also pieces of data denoting new concepts of the domain. In particular, table
T-CarTypes contains data denoting concepts such as
1973 FALCON XB GT,
1967 MUSTANG SHELBY,
1973 MUSTANG MACH 1, and so on. Considering the context where these concepts appear, it is not difficult to conclude that they are all mutually disjoint subconcepts of
Car. Table
T-Cars, on the other hand, provides information about the instances of the various concepts, as well as other properties about them (i.e.,
Color, ProdCountry). We observe that, in order to acquire the knowledge about the concepts mentioned in the data sources, we need a flexible mechanism that is able to map data at the sources to concepts in the ontology. Without such flexibility, the designer would be forced to manually inspect the data sources and enrich the ontology off-line.
The second issue is related to the need of meta-modeling constructs in the language used to specify the ontology [
16,
17,
18,
19]. Meta-modeling allows concepts and relations to be conceived as first-order citizens and to see them as individuals that are instances of other concepts, called meta-concepts. By exploiting meta-modeling we might introduce in the ontology the meta-concept
Car-Type, with
Coupe,
Sedan, etc. as its specializations. Note that the instances of such specialized concepts include the subconcepts of cars listed in the rows stored in table
T-CarTypes. With this mechanism, the designer is allowed to specify the means for dynamically acquiring TBox axioms, through simple queries asking for the instances of the meta-concept
Car-Type. Indeed, without the possibility of using meta-concepts in the ontology, it would be impossible to deal with the first issue mentioned above, that is exactly based on the idea of using mappings in order to transfer the knowledge fragments residing in the data sources to the TBox of the ontology. Note that for the technical development related to meta-modeling, we base our work on the approach and the results reported in [
18].
In this paper, we deal with both the issue of acquiring TBox axioms from data sources and the issue of meta-modeling. In particular, we focus on designing tractable algorithms for query answering in such a setting. Indeed, looking for query answering algorithms that are tractable in data complexity is a distinguishing characteristic of OBDA systems. We follow [
20], and we work with the
family of DLs, which enjoys the first-order logic (FOL) rewritability properties. In a DL, enjoying such property answering (unions) of conjunctive queries can be done in two steps. The first one, called rewriting, uses the TBox axioms in order to transform the query
q into a new FOL query
. The second step evaluates
over the ABox seen as a database.
The challenge we face in this paper is to design tractable query answering algorithms even in cases where the mapping assertions map the data at the sources to both the extensional and the intensional level of the ontology and both meta-concepts and meta-relations are used in the queries. In particular, we present the following contributions.
We formalize the notion of
mapping-based knowledge base (MKB), that captures the idea of acquiring the axioms of both the extensional and the intensional level of the ontology through mapping assertions linking the source data to the ontology. This mechanism allows the designer to achieve a level of flexibility that is not possible in current OBDA systems. Our formalization relies on the notion of higher-order DL, as introduced in [
18]. Indeed, De Giacomo et al. [
18] describe a methodology that, starting from a traditional DL
, allows one to define its higher-order version
. Here, we apply this idea and make use of the higher-order DL
.
We propose to query mapping-based knowledge bases by means of an extension of unions of conjunctive queries (UCQs), taking advantage of the higher-order features of . In particular we define a suitable class of such queries, the so-called instance higher-order UCQs (IHUCQs), enjoying nice computational properties. The basic characteristic of IHUCQs is to allow higher-order features (i.e., meta-concepts and meta-properties) in the query expression but to disregard subclass and subproperty assertions in the body of the query.
We study the problem of answering IHUCQs posed to MKBs expressed in . We show that this problem is efficiently solvable by exhibiting an algorithm based on FOL rewriting. The algorithm works in with respect to the extensional level of the data sources, i.e., the portion of the data sources that is not involved in the intensional level of the ontology. More precisely, our algorithm, given an IHUCQ q over an MKB, reformulates q into a FOL query that is evaluated taking into account only the portion of the MKB involving the extensional level of the ontology. As a consequence, query answering can be delegated to a database management system, exactly as in the traditional OBDA approach.
To sum up, the main achievement of this paper is to prove that we can extend the mapping language used in current OBDA systems so as to talk about concepts and roles as objects (requiring higher-order features), thus realizing the idea of virtualizing both the extensional and the intensional information in a way that is natural and even very effective. Indeed, our result can be interpreted as follows: the complexity of answering higher-order queries posed on knowledge bases built using such extended mappings remains the same as in traditional OBDA settings, when measured only with respect to the extensional level of the data sources.
We observe that initial ideas on generating the intensional level of a representation through mappings was explored in the data exchange setting. In particular, Papotti and Torlone [
21] propose a setting where both data and meta-data stored in relational tables typical of DBMSs, are exchanged. In the context of RDF, the standard language R2RML (
https://www.w3.org/TR/r2rml/) for mapping relational databases to RDF datasets, also allows to map patterns in the relational data to assertions (e.g., subsetting) on RDF predicates. In this sense, this is in the same spirit as our proposal, that however is tailored to ontologies and not only to RDF data. In the context of ontologies, this issue is actually new. Indeed, to the best of our knowledge, the only reference dealing with generating TBoxes through mappings is [
15], of which this paper is an extended version. More specifically, with respect to [
15], the reader can find in the present paper additional examples and discussions, a detailed description of our technique for query answering, and complete proofs for all our results. Furthermore, we revised the analysis of combined complexity of query answering over
MKBs (Theorem 3).
The rest of this paper is structured as follows. In
Section 2 we recall the definition of
, the DL adopted in our work. In
Section 3 we introduce and discuss the notion of mapping-based knowledge base. In
Section 4 we illustrate the kinds of queries that we consider in this paper, and in
Section 5 we present our algorithm for query answering.
Section 6 concludes the paper.
2. Higher-Order
We start by recalling some notions on DLs in general and in particular. Then, we provide the syntax and the semantics of , i.e., the higher-order version of .
DLs [
3] are logics that represent the domain of interest in terms of
concepts, denoting sets of objects, and
roles, denoting binary relations between (instances of) concepts. Complex concept and role expressions are constructed starting from a set of atomic concepts and roles and by recursively applying suitable constructs.
A DL knowledge base (KB) is constituted by two components, and , i.e., , where:
, called TBox, is the terminological component of , which contains statements representing intensional knowledge, and
, called ABox, is the assertional component of , which contains assertions representing extensional knowledge.
is a member of the
family of tractable DLs [
22,
23] and is the logical basis of OWL 2 QL, one of the profiles of OWL, the W3C standard for representing ontologies [
24].
expressions are given by the following syntax:
Role expressions:
where
A is an atomic concept (i.e., a unary predicate from the signature of the knowledge base),
B is a basic concept (i.e, an atomic concept
A or an existential restriction on a role
, which denotes individuals occurring in the first component of the role
Q, which is called the
domain of
Q),
C is a general concept (i.e., a basic concept
B or its negation
),
P is an atomic role (i.e., a binary predicate from the signature of the knowledge base),
Q is a basic role (i.e., an atomic role
P or its inverse
), and
R is a general role (i.e., a basic role
Q or its negation
). The domain of
(i.e.,
) is also called the
range of
P.
A TBox in
is a finite set of assertions in form:
When C and R above assume the form and , respectively, the above inclusions are called negative inclusions and allow us to specify disjointness between concepts or between roles, respectively. Otherwise, the above inclusions are called positive inclusions and allow us to specify is_a relations between concepts or roles, respectively.
An Abox in
is a finite set of membership assertions (i.e., facts) of the form:
where
a and
b are constants, that is, names for individuals (i.e., predicates of arity 0 from the signature of the knowledge base).
We are now ready to describe the higher-order DL
. We start by observing that, as discussed in [
18], every traditional DL
can be characterized by a set
of
operators, used to form concept and role expressions and a set of
of
meta-predicates, used to form assertions. Each operator and each meta-predicate have an associated arity. Given a symbol
T, we write
to denote that
T has arity
n. For
, we simply have:
,
,
provided that and take only a role as argument, takes an individual as first argument and a concept as second argument, takes an individual as first and second argument and a role as third argument, and take two concepts as arguments, and and take two roles as arguments.
Example 1. Consider the followingknowledge base:In words, the knowledge base says thatis a concept that specializes the concept,is a role typed onand, which is a concept denoting production countries. More precisely, the domain ofcan be instantiated only with instances of, as stated by the second inclusion, whereas the range ofcan be instantiated only with instances of, as stated by the third inclusion. The above knowledge base can be reformulated in the high-order style syntax foras follows:We finally note that in both syntaxes given above, the first three assertions constitute the TBox of the KB, whereas the last two assertions constitute the ABox of the KB. Let us turn our attention to the definition of the syntax of . Hereinafter we assume the existence of two disjoint, countably infinite alphabets: , the set of predicates, also called names and , the set of variables. Intuitively, the names in are the symbols denoting the atomic elements of a knowledge base. The building blocks of such a knowledge base are assertions, which in turn are based on terms and atoms.
We inductively define the set of terms, denoted by , over the alphabets and for as follows:
if then ;
if
, and
e is not of the form
(where
is any term), then
(Differently from [
18], we avoid the construction of terms of the form
which, as roles, are equivalent to
e. Under this assumption, we do not have safe-range issues when dealing with queries, thus, differently form [
18], we consider here non-Boolean queries.);
if then .
Intuitively, a term denotes either an atomic element, the inverse of an atomic element, or the projection of an atomic element on either the first or the second component.
Example 2. If the namesbelong to the alphabet, then the following areterms:,,, which, intuitively, denote the concept representing the set of cars, the role, and the concept representing those individuals (e.g., countries) where something is.
Ground terms, i.e., terms without variables, are called expressions, and the set of expressions is denoted by . The terms in the example above are all expressions.
A -atom, or simply atom, over the alphabets and for is a statement of the form or where , belong to , and . Note that -atoms (and even terms) are not required to respect the proviso we have introduced before to limit the usage of predicates from and so that through them it is possible to express (only) knowledge bases. For instance, a and are both legal -atoms, that is, differently from we can instantiate a concept with another concept. If X is a subset of , a is an atom, and all variables appearing in a belong to X, then a is called an X-atom.
Ground -atoms, i.e., -atoms without variables, are called -assertions, or simply assertions. Thus, an assertion is simply an application of a meta-predicate to a set of expressions, which intuitively means that an assertion is an axiom that predicates over a set of individuals, concepts, or roles.
A KB over is a finite set of -assertions over . To agree with the usual terminology of DLs, we use the term TBox to denote a set of , , and assertions, also called intensional assertions, and the term ABox to denote a set of and assertions, also called extensional assertions. Obviously, a KB is also (a special case of) an KB.
Example 3. In Figure 4 we provide a graphical representation of aKB modeling (a portion of) the domain of cars that we use throughout the paper in our examples. The ontology is drawn in Graphol, a diagrammatic language that allows OWL ontologies to be graphically specified [25,26]. In Graphol, as in ER diagrams, concepts and roles are denoted by rectangles and diamonds, respectively, and solid directed arrows represent inclusions. The full hexagon denotes at the same time the union of the concepts connected to it through a dashed line and the disjunction of such concepts. Finally, each octagon represents an individual, and each arrow labeled instance Of from and element A to an element B specifies that A is an instance of B. In words, the ontology is saying thatandare specific types of Cars (i.e., they are sub-concepts of), and that they are disjoint. In addition,is an instance of Coupe (in this respect it can also be seen as an individual) and at the same time it is a concept that specializes(i.e., it is a subconcept of) and hasas an instance. Finally,is a subconcept of, andis an instance of. Below we provide the above ontology through formulas, using the higher order notation given in this section: Notice how the second assertion exploits the meta-modeling capabilities of, i.e., it treats the concept1973_FALCON_XB_GT_COUPEas an individual instance of the concept Coupe, rather than as a concept (which is instead the way the penultimate assertion refers to it).
The semantics of
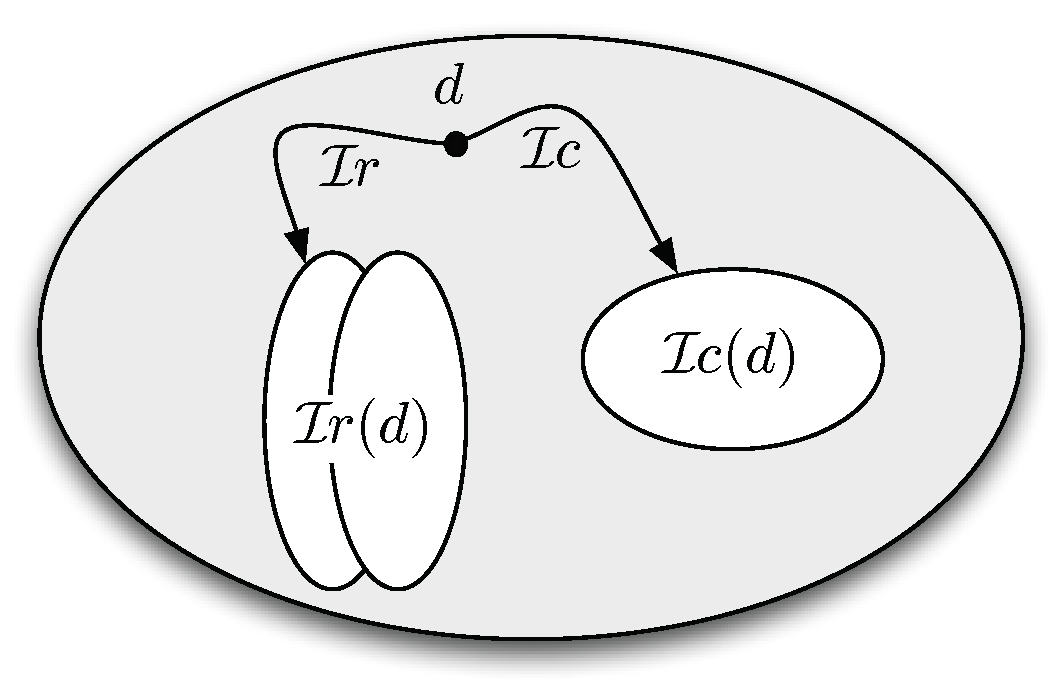
is based on the notion of interpretation structure. An
interpretation structure is a triple
where (see
Figure 5):
is a non-empty, possibly countably infinite, set;
is a function that maps each into a subset of ; and
is a function that maps each into a subset of .
In other words, treats every element of simultaneously as:
an individual;
a unary relation, i.e., a concept, through ; and
a binary relation, i.e., a role, through .
An interpretation for (simply called an interpretation, when is clear from the context) over the interpretation structure is a pair , where
is an interpretation structure, and
is a function that maps:
- -
each element of to a single object in ; and
- -
each element to a function that satisfies the conditions characterizing the operator . In particular, the conditions for the operators in are as follows:
- *
for each such that =, we have that =, where is the inverse of the relation , and
- *
for each such that we have that .
We now turn our attention to the interpretation of terms in . To interpret non-ground terms, we need assignments over interpretations, where an assignment over is a function . Given an interpretation and an assignment over , the interpretation of terms is specified by the function defined as follows:
if then ;
if then ;
.
Finally, we define the semantics of atoms, by defining the notion of satisfaction of an atom with respect to an interpretation and an assignment over as follows:
if ;
⊧ if ∈;
if ;
if ;
if ;
if .
A KB is satisfied by if all the assertions in are satisfied by (We do not need to mention assignments here, since all assertions in are ground.). As usual, the interpretations satisfying are called the models of . A KB is satisfiable if it has at least one model.
3. Mapping-Based Knowledge Bases
In a traditional OBDA system, the axioms concerning the intensional level of the representation are stated once and for all at design time. This is a reasonable assumption in many cases, for example when the ontology is built from scratch for a specific application. However, there are application domains where, with the goal of achieving a higher level of flexibility, it is convenient to build on-the-fly the KB directly from a set of data sources, through suitable mappings that insist both on extensional information (as usual in OBDA) and intensional information. The result is that all the axioms (not only the ones relative to the extensional level, like in current OBDA systems) of the knowledge base are defined by mappings to such data sources. This is exactly the idea behind the notion of mapping-based knowledge base (MKB), that we define in detail in this section.
In what follows, we assume that the data sources are structured as a relational database. We observe that this does not hamper the generality of our work, since existing data federation tools support the designer in wrapping a set of heterogeneous data sources so as to present them as a single relational database. In addition, we assume that the relational data sources store directly the symbols in
and in particular the names of elements used in the MKB. In other words, here we ignore the problem of the impedance mismatch between sources that store “data values” and the MKB that contains ontology elements [
20]. Note, however, that all the results presented in this paper can be extended to the case where the impedance mismatch is dealt with as in [
20].
Definition 1. A mapping-based knowledge base (MKB) is a pair such that:
is a relational database;
is a mapping, i.e., a set of mapping assertions, each one of the form , where Φ is an arbitrary FOL query over of arity with free variables , and ψ is an X-atom in , with .
Note that when the arity n of is 0, then is a boolean query and is a ground atom. In particular, when the is the query , then the mapping assertion corresponds to the assertion constituted by the ground atom . In this way, we can easily specify through also assertions that are “static”, i.e., that do not depend on the current source database instance, and thus we do not need to include a different component in the formalization of an MKB for such static assertions.
We now turn to the semantics of a MKB . We start by defining when an interpretation satisfies an assertion in with respect to the source data . To this end, we make use of the notion of ground instance of an atom and the notion of answer to a query over . Let be an X-atom with , and let be a tuple of arity n with values from . Then the ground instance of is the formula obtained by substituting every occurrence of with (for ) in . If is a relational database, and is a query over , we write to denote the set of answers to over . With this notion at hand, we are ready to present the following definition.
Definition 2. An interpretation satisfies a mapping assertion with respect to a database , if for every tuple of values , the ground atom is satisfied by . The interpretation is called a model of if it satisfies every assertion in with respect to .
We now present an example of MKB, with the goal of illustrating how such a notion can capture real world situations by introducing a notable flexibility in modeling the domain of interest.
Example 4. Consider the MKB
, where is the database shown in the introduction (cf. Figure 3) and is the following set of mapping assertions: M1:T-CarTypes
M2:T-CarTypes
M3:T-CarTypes
M4:T-CarTypesT-CarTypes
M5:T-CarTypesT-CarTypes
M6:
M7:
M8:
M9:
M10:T-CarTypes
M11:T-CarTypes
M12:T-CarTypes
M13:T-CarTypesT-CarTypes
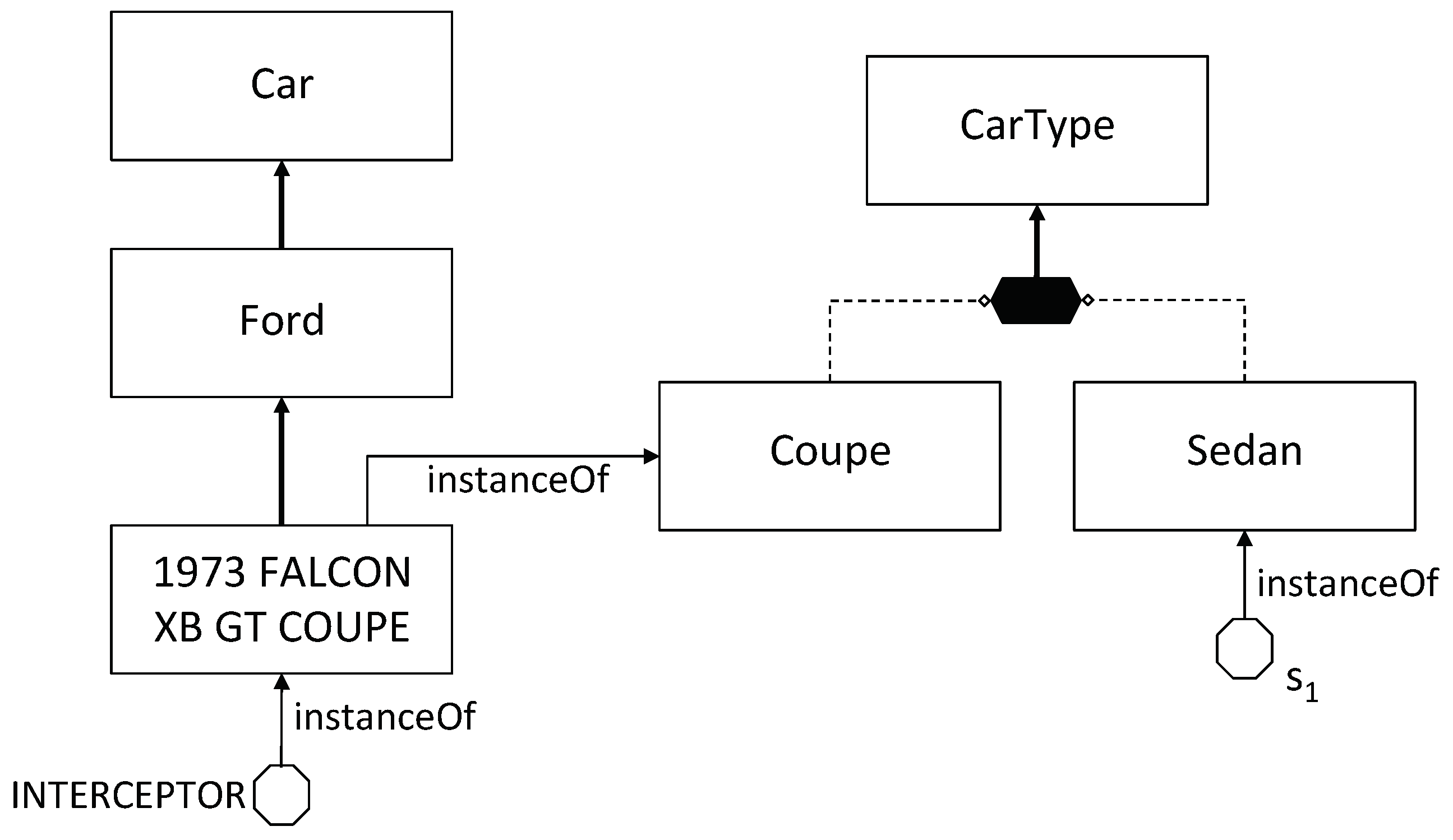
M1 asserts that for every tuple t of theT-CarTypestable, the value appearing in the second column of t denotes a subconcept of the concept denoted by the value in the third column of the same tuple. Thus, for example, considering the fifth tupleofT-CarTypes, M1 states that 1973 MUSTANG MACH 1 is a subconcept of the concept Ford. M2 asserts that every value appearing in the third column ofT-CarTypesis a subconcept ofCar. For example, by referring toagain, such tuple states that Ford is a subconcept ofCar. Analogously, M3 asserts that every value appearing in the fourth column ofT-CarTypesis a subconcept ofCarType. For example,states that Coupe is a subconcept ofCarType. M4 (resp., M5) asserts that the values appearing in the fifth column (resp., second column) ofT-CarTypesdenote concepts that are pairwise disjoint. M6–M9 assert properties about the relation produced_in, between the concepts Car and ProdCountry . M10 populates the relation produced_in, and M11 does the same for the concept ProdCountry . Mapping M12 exploits the meta-modeling capabilities of and relates the different car models to their specific type. For example, looking at tuple again, we can infer by M12 that 1973 FALCON XB GT COUPE is an instance of the concept Coupe. Note that M1 asserted that 1973 FALCON XB GT COUPE is a concept, and therefore, we are taking advantage of the possibility provided by of defining a concept to be an instance of another concept (a metaconcept). Finally, M13 allows us to correctly assign the instances stored in the T-Cars table to the concepts corresponding to the different car models. For example, through this mapping we can infer that the “Mad Max“ police car INTERCEPTOR is an instance of 1973 FALCON XB GT COUPE (see the second tuple of T-Cars ), the famous car ELEANOR of movie “Gone in 60 s“ is an instance of the concept 1973 MUSTANG MACH 1 (third tuple), and the “Supercar“ KITT is an instance of 1982 PONTIAC FIREBIRD (fourth tuple).
We hope that the above example clarifies the potential of MKBs in acquiring ontology axioms in a flexible way. In particular, let us observe how the domain ontology is dynamically built through the mapping, even though no information about the different types of cars and the different models produced by the motor companies was available at design time. Indeed, the mappings in retrieve at run-time both intensional and extensional knowledge from the current database instance. Suppose, for example, that a motor company, say GM, decides to produce cars of new model, say 1967 CADILLAC ELDORADO. Given the structure of the database and its intended usage, the natural thing to do for the organization is to add suitable tuples (e.g., ) in the T-CarTypes table. In our approach, the new information is automatically detected at run-time by the mappings in and correctly introduced in the ontology. So, instead of manually changing the ontology and “re-compiling it” at design time, the new concept is dynamically captured at run-time.
In
Figure 6, using the Graphol language, we provide the graphical representation of the ontology dynamically constructed from the database
used in the example (In addition to the Graphol constructs already used in
Figure 4, in
Figure 6 we also use a diamond to denote a role (namely
), and a blank and a full box connected to such role through a dashed line in order to denote its domain and range, respectively. Moreover, the solid double arrowed line denotes a mutual inclusion between concepts (i.e, an equivalence). By using it, we say, for instance, that
is equivalent to the domain of
, that is, every car is produced somewhere and only cars are produced (somewhere). It is analogous for the range of
(cf. mapping assertion M6–M9).).
We also want to add that, although the Example 4 does not show it, our framework allows variables to be used inside operators, in the right-hand side of mapping assertions. This is useful, in particular, to extract knowledge from the database catalog. For example, if FK is the database table storing information about foreign keys between binary tables, and such binary tables correspond to roles in the ontology, the mapping assertion
allows us to transfer the foreign key property at the level of the ontology, by correctly representing every foreign key as an inclusion between the corresponding roles.
4. Queries
In this section we describe the class of queries that we consider in this paper. We start by introducing “query atoms”. Intuitively, a query atom is an atom constituted by a meta-predicate applied to a set of arguments, where each argument is either an expression or a variable. The precise definition relies on the notion of q-terms: a q-term is any element of the set . Thus a q-term is either an expression in or a variable. In other words, we do not allow for non-ground terms in queries, except for variables themselves. We are now ready to define the notion of query atom. A query atom is an atom constituted by the application of a meta-predicate in to a set of q-terms. A query atom is called ground if no variable occurs in it and is called an instance-query atom if its meta-predicate is or . The definition of the syntax of the class of queries that we are interested in is as follows.
Definition 3. A higher-order conjunctive query (HCQ)
is an expression of the form, where q, called the query predicate, is a symbol not in , n is the arity of the query, every is a (possibly non-ground) query atom, and all variables belong to and occur in some . The variables are called the free variables
(or distinguished variables) of the query, while the other variables occurring in are called existential variables
. A higher-order union of conjunctive queries (HUCQ)
is a set of HCQs of the same arity with the same query predicate. Notice that an HCQ corresponds to an HUCQ formed by a single query. A HCQ is called Boolean if it has no free variables. It is analogous for an HUCQ.
An HCQ (HUCQ) constituted by instance-query atoms only is called an instance HCQ or IHCQ (IHUCQ).
We now turn our attention to the semantics of queries. Let be an interpretation and an assignment over . A Boolean HCQ q of the form is satisfied in if every query atom is satisfied in .
Given a Boolean HCQ q and a KB (or MKB) , we say that q is logically implied by (denoted by ) if for each model of there exists an assignment such that q is satisfied by .
Given a non-Boolean HCQ q of the form , a grounding substitution of q is a substitution such that are ground terms. We call a grounding tuple.
Definition 4. Given aKBand a non-Boolean HCQ q of the form, The set of certain answers to q in , denoted by , is the set of grounding tuples that make the Boolean query logically implied by .
These notions extend immediately to HUCQs.
Example 5. We illustrate some examples of HCQs that can be posed to the MKBof Example 4.
- (i)
Compute the instances ofFordthat were produced in Australia and are of typeCoupe; note that an instance x ofFordof certain type T is an instance of a car model y such that y is an instance of T (this in fact holds for all instances ofCar, not only for instances ofFord). It follows that the correct query expression is as follows: - (ii)
Compute the pairs of cars, one of type Coupe, and one of type Sedan that were produced in the same country: - (iii)
Compute all the concepts in the ontology to which a given object (e.g., Eleanor) belongs to: - (iv)
Compute all the concepts in the ontology whose instances are the concepts to which Eleanor or Kitt belong to:
We observe that all queries in the above example are actually IHCUQs. This is the class of queries that we deal with in the next section.
5. Query Answering
In this section we study how to answer IHUCQs over
MKBs. In the following we consider only consistent MKBs, i.e., MKBs that have at least one model. This is indeed not a limitation, considering that consistency of a MKB can be checked through query answering, by means of methods similar to those used for checking consistency of
KBs [
23].
Before delving into the details of our technique, we introduce some useful definitions. In what follows, we refer to a MKB .
We denote by the set of assertions contained in having either or as predicate in their right-hand side.
We denote by the set , that is, the set of assertions contained in having any of , , , as predicate in their right-hand side.
is called an instance-mapping if and are the only predicates that appear in the right-hand side of the mapping assertions in .
We say that e occurs as a concept argument in the atoms (), (), (), (), and ().
We say that e occurs as a role argument in the atoms (), (), (), (), and ().
A atom is an atom of the form or , where N is a name and are either variables or names.
An extended CQ (ECQ) is an expression of the form such that belong to , is a conjunction of atoms, each atom (with ) is either a atom or an instance-query atom (i.e., an atom whose meta-predicate is or ), and each (with ) occurs in at least one . An extended UCQ (EUCQ) is a union of ECQs.
Given a TBox
(specified in high-order style syntax, cf.
Section 2), we define
occurs as a concept argument in
occurs as a role argument in
, and
occurs as a role argument in
.
Given a mapping
and a database
,
denotes the
KB
defined as follows:
where
is a tuple of constants and
is a tuple of variables having the same arity.
Given an instance-mapping and an ABox , we say that is retrievable through if there exists a database such that .
The query answering technique we are about to present is based on the following four main steps.
In the first step, all intensional assertions are gathered by accessing the sources and using the mapping, in particular the portion. This way, a TBox is available for the subsequent steps.
In the second step, the input query is rewritten on the basis of
, using the algorithm
presented in [
23]. In fact this is not just a trivial call to
, since we need to transform the input IHUCQ, which cannot be given directly in input to
, into a EUCQ. Similarly, we also need to translate the rewriting produced by
in a form that is compatible with the syntax used in the mapping (which is required by the following steps of our algorithm).
In the third step, the query obtained by the second step is unfolded using the mapping, in particular the portion, so as to obtain a query expressed over the alphabet of the source schema.
In the fourth step, the query obtained by the third step is evaluated over the source data, so as to obtain the final result.
In
Section 5.1 we deal with the second step of our technique. In particular, we study the problem of computing a
perfect rewriting of an IHUCQ over a
TBox. We recall that given a query
q, a perfect rewriting of
q with respect to a TBox
is a query
such that, for every ABox
,
[
23]. That is, to obtain the certain answers to
q in
, it is sufficient to evaluate
over
seen as a database (such an evaluation indeed returns the certain answers to
q in
). As said, in our rewriting algorithm we first retrieve a TBox through the mapping (step 1). We thus adapt the above notion to the context of MKBs as follows. Given an MKB
, let
, a perfect rewriting to
q with respect to
and the instance-mapping
is a query
such that, for every ABox
retrievable through
,
.
After the detailed description of the second step above, in the subsequent
Section 5.2, we present the complete query answering algorithm for MKBs based on our perfect rewriting technique.
5.1. Query Rewriting
The basic idea of our technique is to reduce the computation of the perfect rewriting of an IHUCQ over a
TBox to the computation of the perfect rewriting of an UCQ over a
TBox, which can be then done by using the algorithm
described in [
23].
To this aim, we first transform the IHUCQ into a standard UCQ, actually an EUCQ. This is realized through a first partial grounding of the query, using the function and then through the functions and . In particular, the function eliminates the meta-variables, i.e., the variables occurring as a concept or as a role argument, from the query, substitutes atoms whose second argument is of the form into atoms (i.e., the instance of the domain or the range of a role expression e is reformulated as an instance of e), and transforms and atoms in DL atoms.
Afterwards, the query resulting from the perfect rewriting of the EUCQ is transformed back into an IHUCQ, by the functions and . This is because the third step of the query answering algorithm assumes the query to be an IHUCQ.
We now describe in more detail the functions , , , and .
If are two IHCQs, and is a TBox, then is a partial metagrounding of q with respect to if , where is a partial substitution of the meta-variables of q with the expressions occurring in such that, for each meta-variable x of q, either or:
- -
if x occurs in a concept position in q, then ;
- -
if x occurs in a role position in q, then .
Given an IHCQ q and a TBox , the function applied to q and computes the set of all partial metagroundings of q with respect to , i.e., it computes the IHUCQ . When applied to an IHUCQ Q and a TBox , the function computes the IHUCQ .
Example 6. Consider the MKBgiven in Example 4, the TBoxdynamically constructed fromthrough, and represented inFigure 6, and the query (i) given in Example 5. Then,,, and, contains, among other queries, the query:where we abbreviated1973 FALCON XB GT COUPEintoFALCON(to obtain all other queries insubstituteFALCONwith all elements of). Notice that the notion of partial metagrounding is crucial for our rewriting method. Indeed, even if in the set of expressions that can be constructed from a finite set of names occurring in the TBox is infinite, we can in fact limit to ground the meta-variables in the query on a finite set of expressions only, as stated by the following lemma.
Lemma 1. If Q is an IHUCQ, andis a TBox, then for every ABox,.
Proof. Assume . It is easy to prove that . Thus, there exists a tuple t such that . This implies that there exists a model for such that and . Let be the domain of . We define below an interpretation over the same domain . For every :
;
if there exists such that , otherwise ;
if there exists such that , otherwise .
It is easy to see that is a model for the KB . However, it is also straightforward to verify that if and only if , and since by hypothesis , then as well. As a consequence, , which contradicts the hypothesis that , thus proving the thesis. □
We now turn our attention to the functions and .
Let be an instance atom, returns a new atom defined as follows:
if and has the form where is an expression which is not of the form , then , where _ denotes an existentially quantified variables;
if and has the form where is any expression, then .
The above definition naturally extends to queries. More precisely, let
be an IHCQ,
computes the IHCQ
. Finally, if
Q is an IHUCQ, then
returns the query
. As an example, consider the query
returns the query
Then, let q be an IHCQ and be an instance-mapping, is the IHUCQ Q defined inductively as follows:
;
if and contains an atom of the form , and either occurs in or (where x is a variable) occurs in , then the query obtained from by replacing with the atom belongs to Q;
if and contains an atom of the form , and either occurs in or (where x is a variable) occurs in , then the query obtained from by replacing with the atom belongs to Q;
if and contains an atom of the form and either occurs in or (where x is a variable) occurs in , then the query obtained from by replacing with the atom belongs to Q.
Finally, let Q be an IHUCQ and let be a mapping, we define as .
We formally introduce below the functions and , which transform IHUCQs into EUCQs and vice versa. Let q be an IHCQ and let be a TBox, is the ECQ obtained from q as follows:
each atom of q of the form , such that , is replaced with the atom ;
each atom of q of the form , such that , is replaced with the atom .
Example 7. Let us now apply the function τ to the query (1) (which is already normalized), and obtain the query Then, given an IHUCQ Q, we define .
Let q be an ECQ and be a TBox, then is the IHCQ obtained from q as follows:
each atom of q of the form is replaced with the atom ;
each atom of q of the form is replaced with the atom .
Then, given an IHUCQ Q, we define . An example of application of can be obtained by simply reversing the transformation shown in Example 7.
We can now formally define our algorithm for query rewriting. The algorithm takes as input an IHUCQ, a TBox and an instance-mapping, and returns a new IHUCQ. Given an IHUCQ
Q and a TBox
, we denote by
the EUCQ returned by the query rewriting algorithm for
presented in [
23] (Actually, we consider a slight generalization of that algorithm, allowing for the presence of a ternary relation (
) in the query.).
ALGORITHM
INPUT: IHUCQ Q, TBox , instance-mapping
OUTPUT: IHUCQ
begin
;
;
;
;
;
;
return ;
end
Example 8. To provide an example of a complete execution of the algorithm, let us now continue the rewriting described in Example 6 and in Example 7. Let us focus on thefunction, and apply it to the query (2) (which is contained in the setof CQs).transforms the atoms of the query using TBox inclusions as rewriting rules, from right to left. For example, according to the inclusionFALCON ⊑
Ford, it rewrites the atom in query (2) into the atom FALCON (x) (intuitively, the encodes in the rewriting the knowledge expressed by the ontology saying that to obtain instances of one has to look also for instances of FALCON). In this way produces the following query and adds it to the set (notice that the atom FALCON(x) was already present in the query, thus the effect of the rewriting in this case is simply dropping the first atom of the query):A similar reformulation is performed for all atoms whose predicate occurs in the right-hand side of a positive inclusion (provided that its arguments are not bound, as described in [23]). Among the queries returned by we consider in the following only query (3), which, as we will see later, will allow us to obtain the answer to the original query (the other queries returned by do not really contribute to the final answer in our example). Finally, applies and (which in this case is immaterial) to query (3), thus returning the query The IHUCQ returned by constitutes a perfect rewriting of the query Q with respect to the TBox and the mapping , as formally stated by the following theorem.
Theorem 1. Letbe a TBox, letbe an instance-mapping and let Q be an IHUCQ. Then, for every ABoxthat is a retrievable through,.
Proof. The proof follows from Definition 4, from Lemma 1, from the correctness of the algorithm
[
23], and from the fact that the functions
,
,
and
just perform equivalent transformations of the query. □
5.2. Query Answering
We now provide an algorithm for query answering over MKBs, which makes use of the query rewriting technique presented in the previous subsection. As already said, our idea is to first compute a TBox by evaluating the mapping assertions involving the predicates , , , over the database of the MKB; then, such a TBox is used to compute the perfect rewriting of the input IHUCQ.
To complete query answering, we have to also consider the mapping of the predicates
and
and reformulate the query thus obtained by replacing the above predicates with the FOL queries occurring in the corresponding mapping assertions (step 3 of our technique). In this way we obtain an FOL query expressed over the database. This second rewriting step, usually called
unfolding, can be performed by the algorithm
presented in [
20] (Here, we assume that the algorithm
takes as input an EUCQ and an instance-mapping. This corresponds to actually considering a straightforward extension of the algorithm presented in [
20] in order to deal with the presence of the ternary predicate
.). In the following, given a mapping
and a database
, we denote by
the database constituted by every relation
R of
such that
R occurs in
. Furthermore, we define
as the database
(i.e.,
is the portion of
which is not involved by the mapping
). We are now ready to present our query answering algorithm.
ALGORITHM
INPUT: IHUCQ Q, MKB
OUTPUT:
begin
;
;
;
return
end
The algorithm starts by retrieving (function ) the TBox from through the mapping . Then, it computes (function ) the perfect rewriting of the query with respect to the retrieved TBox and next computes (function ) the unfolding of such a query with respect to the mapping . Finally, it evaluates (function the query over the database and returns the result of the evaluation.
Example 9. Let us consider again the MKD system and the query of Example 6. We notice thatandconsists of the mapping assertions M1-M9 and M10-M-13 given in Example 4, respectively, andcoincides with the databasedescribed in Figure 3. Thus, the TBoxreturned bycoincides with the TBox described in Figure 6 (not considering InstanceOf arrows).is as discussed in Example 8. As said, amog all queries inwe consider only query (4). By unfolding it through, we obtain (among other queries) the FOL query More in detail, we have unfolded the atomusing mapping M13, atomusing mapping M12, and the atomusing mapping M10. Notice also that other queries are produced by the functionapplied to the query (4) and the(e.g., by unfoldingthrough M12). However, the one we showed is sufficient to obtain the answers to the original query. It is indeed easy to see that by evaluating the above query over(see Figure 3), we obtain the answerINTERCEPTOR, and this is the only answer to the query (i) given in Example 5 evaluated over the MKD system. To prove correctness of the above algorithm, we first state the following property, whose proof immediately follows from the definition of and the definition of model of a MKB.
Lemma 2. Letbe aMKB and let. The set of models ofandcoincide.
We also need the following additional property.
Lemma 3. Letbe an instance-mapping, and let Q be an IHUCQ. Then, for every database, Proof. The proof follows from Definition 4 and by a natural, slight extension (which we leave to the reader) of the proof of correctness of the algorithm
shown in [
20]. □
We are now ready to show the correctness of the algorithm .
Theorem 2. Let=be aMKB, let Q be an IHUCQ, and let U be the set of tuples returned by. Then,.
Proof. The proof immediately follows from Theorem 1 and Lemmas 2 and 3. □
Finally, from the algorithm we are able to derive the following complexity results for query answering over MKBs.
Theorem 3. Let=be aMKB, let Q be an IHUCQ and letbe a tuple of expressions. Deciding whetheris inwith respect to the size of, is in PSPACE with respect to the size of, and is NP-complete with respect to the size of.
Proof. To decide whether we can execute . Then, membership in with respect to the size of follows from the fact that the only step of the algorithm that depends on is , where is a FOL query and the fact that evaluating an FOL query over a database is in in data complexity. Membership in PSPACE with respect to the size of follows from the fact that evaluating a FOL query is in PSPACE in combined complexity (whereas the other steps of the algorithm are in PTIME with respect to the size of the ). Finally, NP-completeness with respect to the size of follows from Lemma 2, from the fact that computing can obviously be done in constant time with respect to the size of and from the fact that evaluating an IHUCQ over a KB is NP-complete in query complexity. □

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





