1. Introduction
In recent years, with the unprecedented growth of user data traffic, network services are becoming more diverse and dynamic [
1]. Network Function Virtualization (NFV) is a novel networking paradigm that has become a key enabling technology for delivering such services. Specifically, NFV through the Service Chaining (SC) model [
2] can provide the necessary flexibility to offer a large range of network services tailored to the needs of the end users.
To reap the benefits introduced by NFV, usually other technologies are also utilized. For example, Cloud Computing and NFV are tightly coupled towards providing Virtualized Network Functions (VNFs) typically instantiated as Virtual Machines (VMs) on data centers remote from the end-users. Nonetheless, following the evolution of recent trends in networking, NFV and Cloud Computing can also be interconnected with other emerging technologies, such as the Mobile Edge Computing [
3], Internet of Things (IoT), and 5G towards providing the necessary tools of building a service-centric future Internet architecture.
This model follows recent trends of service provisioning, where services are moving from a host-centric to a data-centric model, in which the computational resources are repositioned closer to the end users [
4,
5]. This can be enabled by the MEC layer that provides small-scale Cloud Computing capabilities close to the end-users. Hence, the mix of all the above technologies is expected to essentially benefit from the proximity and elasticity of the programmable network resources that MEC offers, creating a new communication era.
The immense benefits and opportunities introduced by the edge concept urged major international initiatives to standardize this paradigm. For example, the European Telecommunication Standards Institute (ETSI) developed the Mobile Edge Computing (MEC) arhicecture [
6], the OpenFog Consortium, the Fog Computing architecture [
7], and National Institue of Standards and Technology (NIST), the Fog computing conceptual architecture [
8]. Both MEC and Fog computing introduce the same concept of bringing cloud computing capabilities at the edge of the network; however, they include slightly different architectures. Both platforms utilize a distributed paradigm to provide low latency, high communication rates, and mobility support. However, Fog computing focuses on the infrastructure perspective while the Edge computing on things, pushing computing capabilities closer to the mobile devices in radio access networks (RAN) [
9,
10]. In this current work, since the emphasis is on the traffic generated by the IoT layer, we are using the MEC definition as our Edge Computing solution.
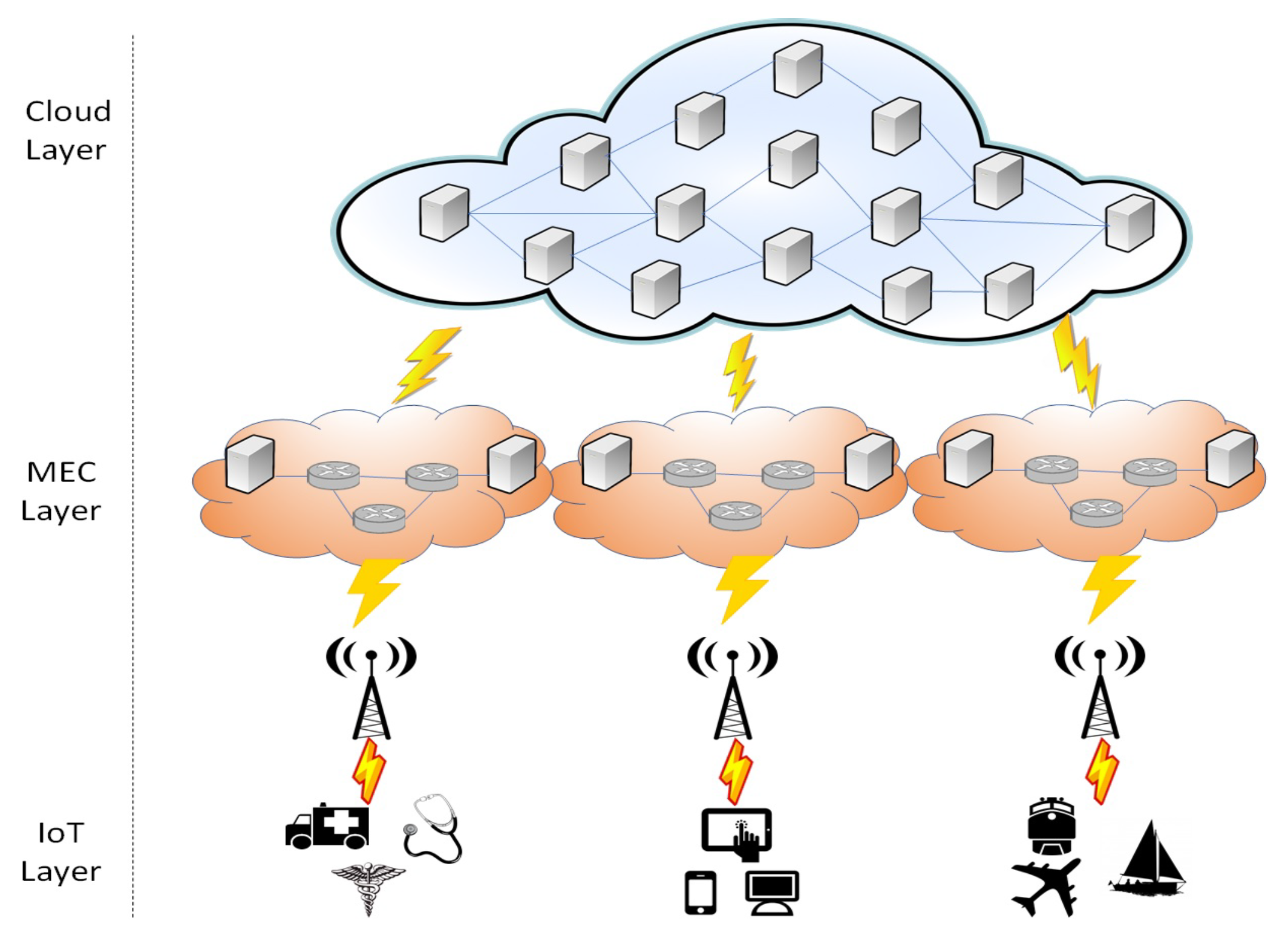
An example of such a scenario is cloud-based managed services for IoT applications (
Figure 1). In this case, multiple IoT devices can generate huge amounts of traffic. This traffic can be routed through appropriate IoT gateways located at the edge of the network to a cloud environment consisting of multiple data centers. Hence, according to the amount of data generated by the IoT devices and the type of network services that are required to be applied, appropriate Service Chains (SCs) must be deployed in the MEC and Cloud infrastructures. At the same time, the generated traffic has specific requirements in terms of bandwidth and overall delay that can further guide the deployment of the SC. For example, for mission critical IoT applications, SCs should be deployed in the MEC taking advantage the close proximity to the IoT layer and, thus, lower latency is introduced. However, more resource intensive applications can benefit from the abundant and reliable resources in the Cloud.
The deployment of SCs essentially amounts to solving the problem of finding the underlying physical resources to instantiate the various VNFs comprising the SCs. A problem also known as the VNF Placement problem [
11]. One major concern when solving the VNF Placement problem in such an environment is how to efficiently utilize the resources between the MEC and Cloud infrastructures in order to reconcile the conflicting goals of latency performance and deployment cost. This is a major challenge even if the Cloud was the only infrastructure available. For example, a Service Provider (SP) needs to balance the conflicting goals of minimizing the cloud resources used (e.g., for reducing the overall deployment cost) and minimizing the end-to-end delay for meeting pre-specified service-level agreements (SLA) [
12,
13]. However, minimizing the number of used servers can lead to an over-utilization of the server resources that can have a serious effect on the overall network delay [
14].
The existence of both the MEC and Cloud creates an extra level of complexity when trying to balance the two particular metrics. On the one hand, utilizing the resources of the MEC can significantly reduce the perceived propagation delay. However, the MEC has a limited amount of resources and over-provisioning can lead to overutilization of the underlying infrastructure. On the other hand, the Cloud has many more available resources, but are usually remote from the IoT devices adding delay overhead. Furthermore, there are additional constraints that should be taken into consideration during the deployment of the SCs. For example, a subset of VNFs may come with location constraints. In this case, some VNFs must be deployed at the reliable and more resource powerful Cloud Computing layer (e.g., video optimization, deep packet inspection [
15]), while others need to be instantiated close to the end users at the MEC (e.g., network address translation-NAT, firewall, traffic prioritazion) [
4,
16].
The topological characteristics of the SC can impose further limitations. Until now, most of the existing works assume that an SC is a simple line sequentially connecting several VNFs. However, more realistic scenarios include topologies with bifurcated paths (i.e., service graphs) [
17]. Furthermore, the rate of the data can change according to the type of VNF processing that is applied. For example, a firewall can drop untrusted data streams resulting in flows with lower data rate, and video rendering VNFs can change the encoding of the traffic leading to higher/lower data rates [
18]. These are factors that should also be considered, especially in a delay sensitive environment such as IoT.
To this end, we propose a novel resource allocation strategy to reconcile the conflicting goals of concurrently minimizing overall deployment costs and delays. In contrast with other existing approaches, we take into consideration a realistic scenario, incorporating a complete set of constraints, while we extend our framework and incorporate new directions in an intermix of different platforms and requirements.
The main contributions of the paper are listed as follows:
Extend the VNF Placement problem taking into consideration the existence of both the Edge and Cloud infrastructures (VNF Placement at the Edge and Cloud VNF-PEC).
Introduce an optimal placement algorithm formulated as a Mixed Integer Programming problem and a sub-optimal but fast approach based on the Tabu Search meta-heuristic.
Take into consideration realistic SC topologies with features that can modify the incoming and outgoing data rate.
Provide additional constraints regarding the location requirements imposed by the VNFs.
Formulate the total experienced delay by considering all different delay levels during this end-to-end communication.
Create a realistic experimentation environment using real data for the resource characteristics of the MEC and Cloud infrastructures and for the requirements of the IoT traffic.
The remainder of the paper is organized as follows: in
Section 2, we present a detailed overview of the related work.
Section 3 provides the system model followed to perform the VNF-PEC optimization.
Section 4 introduces the proposed resource allocation algorithms.
Section 5 presents the experimentation environment.
Section 6 presents the performance evaluation of the proposed solution. Finally, in
Section 7, we summarize and discuss future work.
2. Related Work
In this section, we review the different VNF approaches proposed in the literature and how the VNF Placement problem can be applied when both MEC and Cloud resources are available.
In particular, many works address the VNF-PEC problem with the goal to minimize the deployment cost of an SC. In the traditional VNF placement problem, deployment cost is usually expressed as the computational and communication resources that an SC needs to in order to be provisioned [
19]. The same objective also applied in the context of the VNF-PEC problem [
20]. Nonetheless, there may be monetary costs associated with leasing the MEC and Cloud resources [
21,
22], which may be different according to the ownership of the infrastructures (e.g., different pricing models followed from the MEC and Cloud providers).
One other major concern during the SC deployment and VNF placement is the delay perceived in the overall communication. Up until recently, the major consideration in minimizing the overall delay was only the propagation delay [
18,
23,
24,
25]. However, in the context of NFV, there are other major delay contributors that need to be taken into account. One additional delay factor that should be also minimized is the processing delay. This processing delay can be assumed as fixed [
26] provided that the servers have enough capacity to execute the VNFs, or it can be proportional to the server utilization [
12,
27]. Thus, both processing and propagation delays should be taken into consideration when the objective is to minimize the delay during the VNF placement [
28,
29,
30]. Attention should be drawn to the fact that the processing delay also includes a queueing delay that is highly affected by the number of users/IoT devices associated with each SC and their traffic rate [
1]. Apart from queuing models, state-space models combined with feedback controllers can be used to approximate the overall processing delay [
31]. All of these delay factors apply in all layers of the IoT to Cloud communication and should be jointly minimized. This is particularly important in an IoT communication environment, since many IoT applications are characterized as mission critical and delay sensitive. Furthermore, within this context, the positioning of the VNFs can highly affect the overall delay [
32]. Placing the VNFs in the physical devices of the infrastructure that are closer to the wireless devices can also reduce the communication delay [
33]. An approach to accomplish this is to create clusters of available VNFs in the MEC layer, where the various requested SCs can be deployed [
34]. Minimizing the number of clusters and appropriately positioning the VNFs can lead to a minimization of the communication delay.
Another objective that is mainly arised by the requirements of the infrastructure providers (e.g., MEC/Cloud providers) is how to carefully allocate and schedule the available resources. Thus, there is a high interest in path optimization, efficient resource usage, and load balancing when solving the VNF placement problem [
35]. The goal is to provide the necessary scalability by increasing the availability of the resources, increasing the number of SCs that can be concurrently deployed in the physical infrastructure, and facilitate VNF placement of future SC requests. This objective can be translated into minimizing the overall resource usage, in order to enable multiple heterogeneous SCs servicing heterogeneous IoT users co-existing in the MEC layer [
36,
37] or minimizing the resource idleness of the infrastructure [
38]. Load balancing can also be applied by minimizing the maximum link utilization and reducing bandwidth consumption [
39]. This can be achieved by adopting appropriate queuing and Quality of Service (QoS) modeling during the optimization problem to minimize resource utilization [
40]. This is particularly important for the MEC provider since applying load balancing can prevent its infrastructure from being overloaded, especially when it has to handle an intense amount of incoming traffic [
41]. In addition, the manipulated traffic can be bursty and can dynamically change during different time periods [
38]. Hence, an appropriate load balancing scheme can easily facilitate any bursts and spikes of the incoming traffic. There are multiple benefits of this approach that include the avoidance of Service Level Agreement (SLA) violations and the need to utilize additional resources from the Cloud that have to cross a possible expensive transport network.
In case that there are both Cloud and MEC resources available, an additional objective can be how to optimally offload and redirect traffic between the two layers [
42]. This is particularly important for applications that generate a huge amount of data and an optimal decision needs to be made on where these data should be processed. Of course, the MEC layer may not have the necessary infrastructure to provide networking services for these huge amounts of traffic. Hence, a first decision can be performed in the MEC to determine in real time which traffic should be forwarded to the Cloud to apply the necessary VNFs [
43]. The decision of which VNFs should be deployed to the Cloud is very important, since a continuous data transmission to the Cloud can cause cost, privacy, and data storage overheads [
44]. Another important action comes when performing traffic offloading and load balancing at the same time. In this case, a vertical approach can be considered by appropriately offloading the wireless traffic to a set of cloudlets residing at the edge of the network [
45]. To optimize traffic offloading, real-time VNF placement solutions should be devised. This way, traffic can be redirected on the fly according to the computational and communication requirements of the aggregated traffic stream. The objective function should reflect the dynamic nature of the streams and perform the VNF allocation wisely to efficiently offload the traffic to the Cloud respecting any location and latency requirements imposed by the IoT application.
The above objectives entail different requirements and component goals that are usually conflicting, making the VNF-PEC a very challenging problem. For example, aiming to minimize deployment cost can lead to a consolidation of multiple VNFs on the same server. This can have an immense impact on the processing delay, which is roughly proportional to resource utilization. Similarly, the minimization of deployment cost can affect the load balancing objective by inefficiently utilizing the available resources. Another conflict can be generated when the traffic is offloaded to the Cloud. Either a cost and delay increase will be noticed, since the traffic now has to cross the expensive transport network adding a delay overhead to the overall communication. Load balancing and delay is another pair of conflicting objectives. Load balancing can dictate the VNF placement solution to utilize less loaded resources to equalize the average resource utilization. However, this can lead to placing parts of the same SCs in physical hosts that are very distant, increasing the overall propagation delay. These conflicts arise from the different requirements of the involved actors of this communication model. The infrastructure providers (either MEC or Cloud) want to efficiently utilize their resources by performing load balancing and VNF consolidation. Network service providers aim for a minimization of the total cost of providing their networking solutions to the end users, while the end users require a high QoS by experiencing low delays.
Hence, in contrast with the research endeavours existing above, which consider only a subset of the total set of factors that can influence VNF-PEC performance, in this work, we target finding an optimal trade-off by jointly optimizing the total set of requirements and objectives. Furthermore, we consider SCs with different topological characteristics and traffic manipulation (e.g., compressed/decompressed traffic) that can influence the overall solution. Finally, we also include additional realistic constraints regarding the location of the VNFs that can have an immense impact in terms of cost, delay, resource utilization, and traffic offloading to the overall placement solution.
3. System Model
In order to perform VNF-PEC allocation, we model our infrastructure, based on
Figure 1, as a graph denoted by
, where
V represents the set of nodes and
E the set of the links. Two types of nodes are identified: (i) servers
that are used to host the VNFs as VMs, and (ii) routers
that are used only for forwarding purposes, where
(e.g.,
N and
Q sets are mutually exclusive). Moreover, servers are further divided based on their location into MEC servers
and Cloud servers
, where
. Each node
is attributed with a vector of available resource capacities
(e.g., CPU, Memory, etc.). Moreover, every edge
is associated with a bandwidth capacity
.
We assume that there is a set of
SCs available, representing
I IoT applications. Each SC consists of a random number of
K VNFs, i.e.,
,
. Each VNF in the SC is characterized a vector of demands
(CPU and Memory) that needs to be satisfied. Furthermore, as stated in
Section 1, there may exist only a subset
T of the servers
N that can host a specific VNF
. For example, some VNFs need to be close to the end-users (e.g., MEC servers
), while others are in the Cloud (e.g., Cloud servers
). Moreover, we assume that the end-users/IoT devices associated with an SC
are randomly entering and leaving the SC according to an i.i.d. Poisson point process. Thus, the traffic demand of each SC
is time varying according to the number of devices that needs to be serviced at each time. Additionally, according to the type of the VNF, the rate of the incoming traffic may differ from the rate of the outgoing traffic by a percentage
.
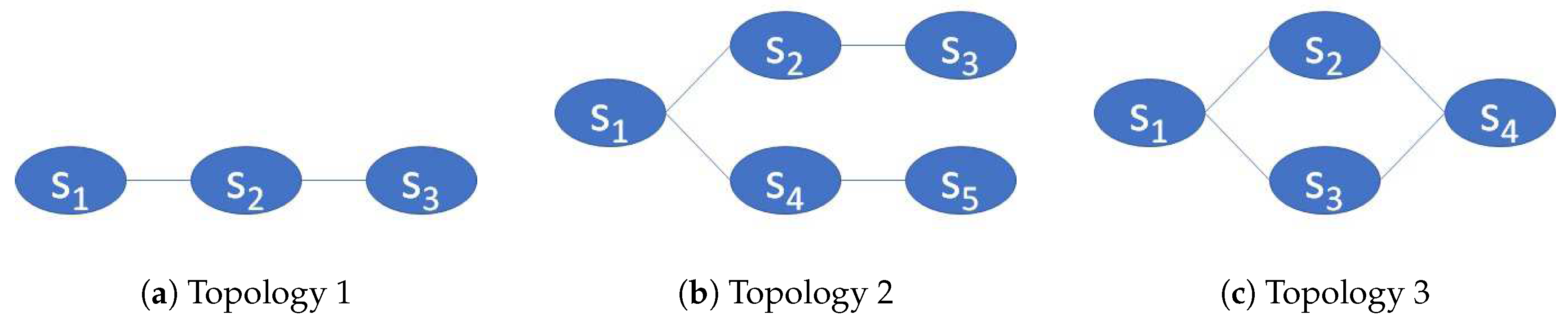
Furthermore, we assume that the SCs can have different topological characteristics following three different cases as shown in
Figure 2. The first topology (
Figure 2a) is the most common and simple case, where an SC is a line sequentially connecting VNFs. The second and third case is when we have bifurcated paths, where two branches are created after a VNF splits the traffic. This can happen when a reclassification occurs. As packets traverse an SC, reclassification may result in the selection of a new SC path, referred as branching. The new branch can later return to the original SC (
Figure 2c) or not (
Figure 2b). Further details and technical examples on these topological cases can be found in [
2].
Finally, regarding delay, we assume that we have four different communication delays: (i) propagation delay , (ii) transmission delay , (iii) node queuing delay , and (iv) processing delay .
Propagation Delay
The propagation delay in a link , depends on the distance between the two communicating nodes. In this work, our network is comprised of the MEC and Cloud layers. Hence, a different propagation delay is considered according to the network layer in which the layer the VNFs are placed.
Transmission Delay
The transmission delay can be defined as the time needed to transfer the packets from a communicating device to the outgoing link , . The transmission delay depends on the average length of the packet and the transmission capacity allocated to the SC ; and it can be expressed as: .
Processing Delay
The processing delay
includes the time needed by the VM hosting the VNF
to apply a specific network operation on the arriving packets. Thus, the processing delay depends on the type of the VNF that is used and the resource footprint allocated to the VM. In this work, we assume an optimal server configuration, avoiding multiple packet copy operations between NIC, OS, and VM (e.g., by using Single Root Input/Ouput Virtualization for our I/O technology), providing a meticulous Non-Uniform Memory Access (NUMA) socket design, and an efficient CPU memory access [
46] that can minimize the effect of those in the overall processing delay. Thus, we assume that we can fully use the total processing capacity of the server.
Queuing Delay
The last delay contributor is the queuing delay
and is the time the packets spend in a node
of the network as they traverse the SC path. Taking into consideration that, in this particular work, the users are randomly associated with an SC according to a Poisson point process, while the lifetime of each user is exponentially distributed, we model the communicating devices as M/M/1 queues, which have been argued as appropriate to be used for server queues [
4]. Hence, the average time a packet spends in a queue can be expressed as
, where
is the arrival rate and
is the service time of the packets [
47].
Furthermore, there are extra delays for creating, booting up, and loading VNFs. However, since this is an extra level of latency that cannot be avoided, we do not consider this in our total delay evaluation.
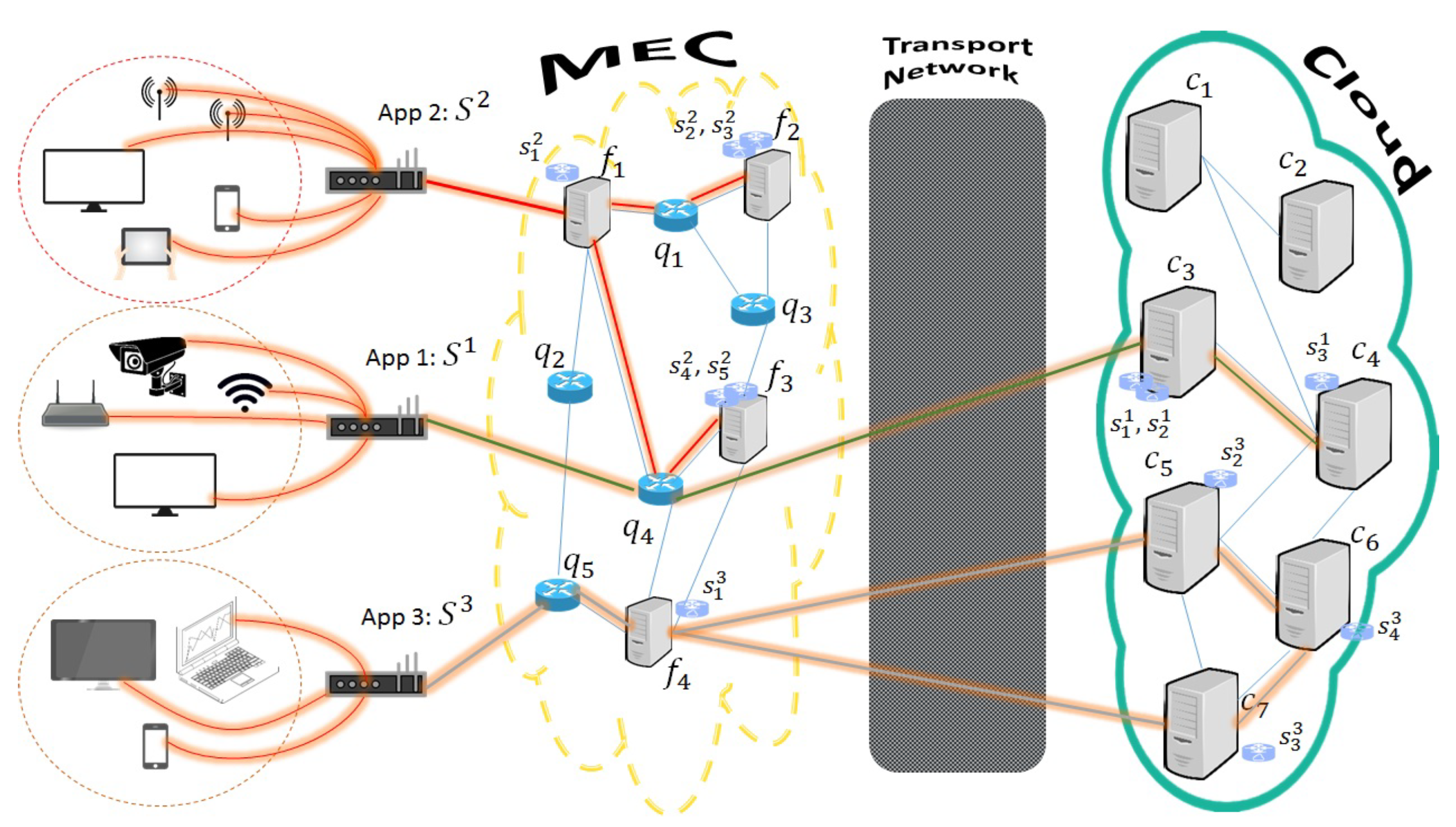
An example of the VNF-PEC placement is illustrated in
Figure 3. In this example, we have three SCs (
) that represent the networking services that should be applied in three different applications and have the topological characteristics of
Figure 2. The first SC consists of three sequentially interconnected VNFs (
Figure 2a) that are allocated only in the Cloud infrastructure (e.g., due to location constraints, or due to limited resources in the MEC). Specifically, VNFs
and
are allocated on the Cloud site
, while the third VNF is placed on the Cloud site
. For the interconnection of the two first VNFs, we don’t need to find any path since they are both provisioned on the same Cloud server. On the other hand, the link between the VNFs (
) is allocated on the path
. For the second SC, we only utilize the MEC resources (e.g., for lower latency and deployment cost) in this case the bifurcated SC (
Figure 2b) is allocated as follows: VNF
is allocated on the MEC device
, VNFs (
) on MEC device
, while VNFs (
) on MEC device
. In this case, the flow of the second application is splitted in the first VNF and follows two branches. The first branch follows the {
} path, and the second branch the {
} path. For the last SC (
Figure 2c), we utilize both MEC and Cloud resources (e.g., for traffic offloading). In particular, VNF
is placed on MEC device
,
on Cloud site
,
on Cloud site
, and
on Cloud site
. Regarding the paths that are used to interconnect the VNFs, for the first two VNFs (
), the path is allocated on a set of routers that belong to the transport network, while the rest of the VNFs are placed on the Cloud and they are using inter-cloud links for the interconnection (e.g., {
} and {
}). There may be many placement solutions, but, in this example, we are just showing three different possible placement solutions to shed light on how the MEC and Cloud infrastructures can be utilized to facilitate the VNF placement. In the following, we explain how the appropriate available resources should be selected to optimally place the VNFs.
5. Experimentation Environment
To model and evaluate our approach, we used and extended a discrete event java-based simulator called simulator for controlling virtual infrastructures (CVI-SIM) [
50]. The particular simulator enables the evaluation of resource allocation approaches in the existence of single or multi-provider cloud infrastructures. CVI-SIM allows for modelling the physical infrastructure along with the control and management plane for more realistic scenarios. It further supports various probabilistic distributions to model the end-user requests.
In order to model the VNF-PEC problem, we created three different infrastructures representing the cloud, edge, and transport networks. To create and interconnect these infrastructures, the JUNG library was used that facilitates the modelling of the various networks as graphs. The JUNG library generates random graphs using the erdos-renyi model, while the simulator guarantees the repeatability of the experimental set up by setting up a specific seed at the beginning of the execution.
The SCs are also modeled as graphs using the JUNG library, while they belong under the IoT layer package of the CVI-SIM. In the same package, the IoT devices are also modeled including their requirements, their association with the IoT applications, their inter-arrival time, and their lifetime distribution.
Another package of the CVI-SIM includes the VNF placement algorithms. In the above section, we have already presented the theoretical aspects of the VNF-PEC algorithms along with their mathematical formulation and pseudocode. However, in this part of the paper, we provide a more complete description of the proposed algorithms and optimization approaches, including their technical aspects and how they were executed in the CVI-SIM simulator.
Regarding MIP approaches, they are characterized by an increased complexity. In addition, for the VNF Placement problem, the MIP approach is characterized as an Non-deterministic Polynomial-time (NP)-hard problem [
51]. This makes the particular solution computational intractrable for large scale experimentations and thus we can only use it as a benchmark approach or an offline solution. The main reason is that the particular algorithms, as the optimal ones, are exhaustive, meaning they are trying to go through every possible solution to extract the optimal one. Thus, appropriate solvers are needed to model and solve MIP problems.
In this work, we utilized the IBM CPLEX 12.8 package to solve the MIP formulation [
48]. In particular, we used the Cplex Java API to execute the MIP algorithm in our discrete event java-based simulator. Cplex library uses a generic branch and cut approach to extract the final solution. In the particular approach, the problem is decomposed in a number of continuous subproblems in a form of a tree. At the beginning, the problem is treated as a continuous relaxation of the integer constraint. If the solution contains one or more fractional variables, CPLEX will try to find cuts to remove areas of the search space that contain fractional solutions. Then, it branches to the cut (subproblem) with the more restrictive bounds until it finds an all-integer solution.
In contrast to MIP, the TS algorithm is very simple and easy to implement by simply translating the pseudocode into a java class with a dozen lines of code. Specifically, it needs a total of operations, where is the number of iterations needed to evoke the termination criterion of the algorithm, while at each iteration we only perform four operations: (i) select a random neighbor solution, (ii) calculate the cost of the new solution, (iii) compare the new solution with the current best, and (iv) finally update the Tabu List. From these four operations, the cost calculation is only proportional to the number of VNFs K consisting of the SC.
6. Results and Discussions
In this section, a comparison of the two approaches is presented via simulation. However, it should be noted that the MIP algorithm is used as a benchmark since it is not implementable for large-scale systems (e.g., MIP needs 200 × more execution time than TS). To better illustrate the efficiency of the proposed approaches, we compare them against the Instance Consolidation (IC) [
38] and Baseline [
40] heuristics. The IC algorithms try to consolidate as many adjacent VNFs of an SC as possible to a single instance that can be deployed on a server with the goal to minimize the resource idleness. This can be a very cost-effective solution since it can minimize the number of physical resources used for the placement of the VNFs. In the Baseline approach, the algorithm tries first to place the VNFs at the Edge. If there are not enough resources at the Edge, then it offloads the rest of the VNFs at the Cloud. The reason we selected this algorithm is to compare our approach with an algorithm that tries to benefit as much as possible from the presence of the Edge infrastructure.
Our physical infrastructure consists of 50 nodes, with 60% cloud servers, 20% MEC servers, and 20% routers used only for forwarding purposes (e.g., for our transport network). Nodes are interconnected with 50% probability. The resource characteristics of the physical resources are provided in
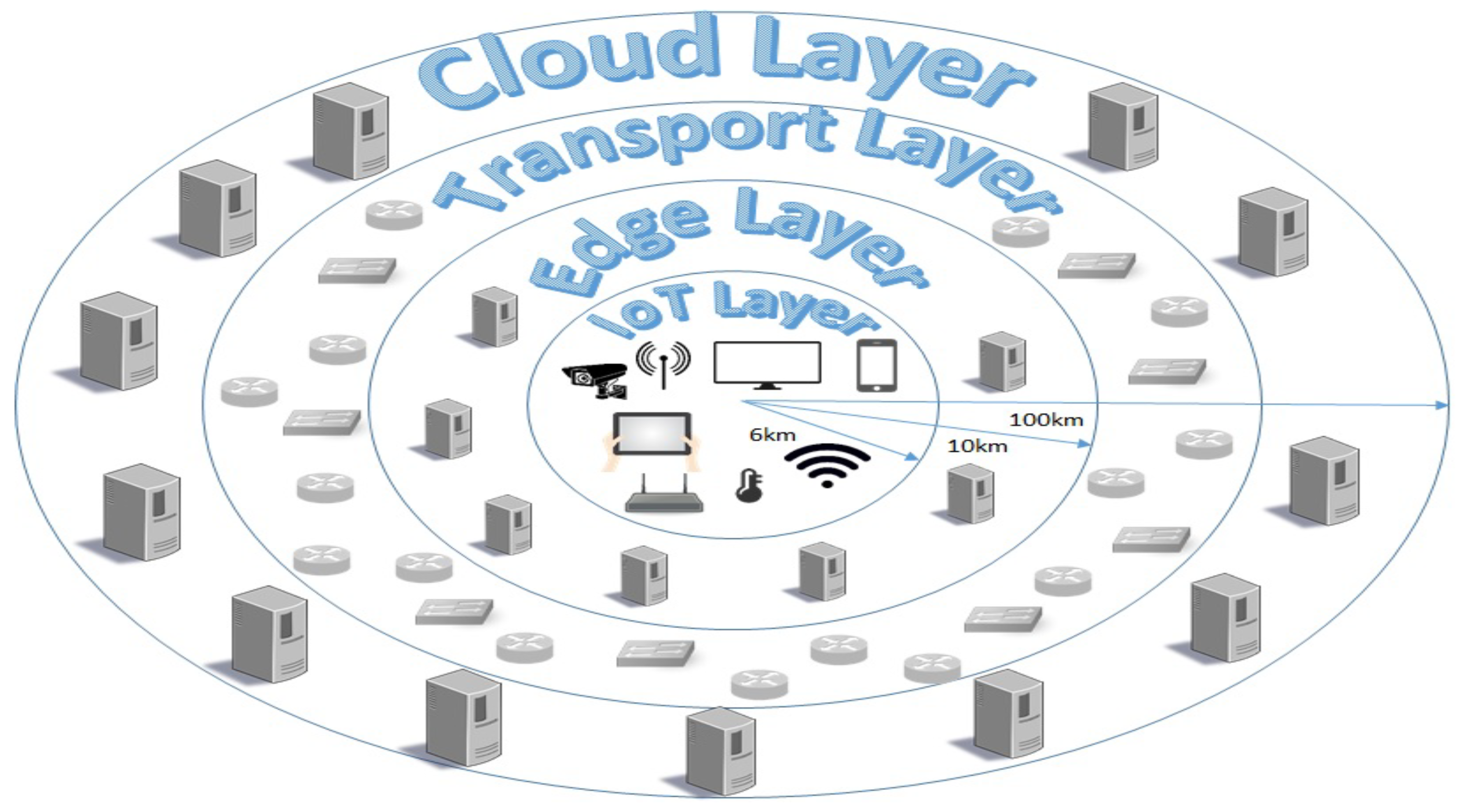
Table 1. Regarding the propagation delay, we assume we cover IoT applications on a smart city with a radius of 6 km. The edge servers are uniformly distributed in the vicinity of the IoT service area in a radius of 10 km. Finally, the core network lies in an area of 100 km away from our IoT devices. The infrastructure topology used to extract the propagation delay characteristics is illustrated in
Figure 4.
There are 10 SCs available consisting of a number of VNFs uniformly distributed in the range from 2 to 5 following the topological characteristics as in
Figure 2. The resource demands are provided in
Table 1. The demands of CPU and Memory are per VNF, while the demands of bandwidth are per IoT device. Regarding the requested bandwidth, we are using typical rate values generated per IoT device according to the IoT application it belongs (e.g., Virtual Reality [
52], Retail [
53], e-Health [
54], Wearables [
55], and Autonomous Vehicles [
56]). To better illustrate the importance of an efficient resource allocation, we utilize high traffic rate IoT applications in order to stress the capabilities of our infrastructure.
Each SC is assumed to handle a random number of devices according to the type of the service being processed. To this end, each SC is modeled with a different arrival rate between the range of 2–10 devices per hour, while the lifetime lies in the range of 1–24 h. The experiments last for a period of one day, while measurements are taken every half an hour. Based on this distribution, we can model a M/M/1 queue as described in
Section 3. Furthermore, to model the transmission and processing delays, we assume that a server that is not fully loaded can process packets with a rate of 0.88 Mpps using packets of 1518 bytes. Moreover, we consider that each VNF may cause the traffic to be compressed, decompressed, or remain intact with an equal probability. For compression and decompression, a 20% change in the traffic is applied. Finally, we assume that 20% of the VNFs of an SC need to be deployed on the MEC layer, 30% on the Cloud, and the remaining 50% does not pose any location restrictions.
To quantify the achieved performance, two experiments are carried out. In the first experiment, we evaluate the impact of each component of the TS algorithm in the allocation solution and we extract the optimal configuration. Following that, in the second experiment, we evaluate the various allocation algorithms in terms of the deployment cost. For modeling the deployment cost, we use the pricing model provided in [
57]. Furthermore, we evaluate the number of resources used by each algorithm both in terms of the number of servers and links to interconnect them and the number of SCs instantiated. Finally, the algorithms are compared in terms of the overall delay.
6.1. Experiment 1: Tabu Search Evaluation
In this experiment, we try to find the optimal configuration of the TS algorithm to provide solutions with low deployment cost. The default configuration of the TS components are set as follows: (i) random initial solution, (ii) neighborhood of one VNF, (iii) tabu list size of 10, and (iv) 1000 iterations as our termination criterion. In the following experiments, we use this default configuration and we only change the component under consideration.
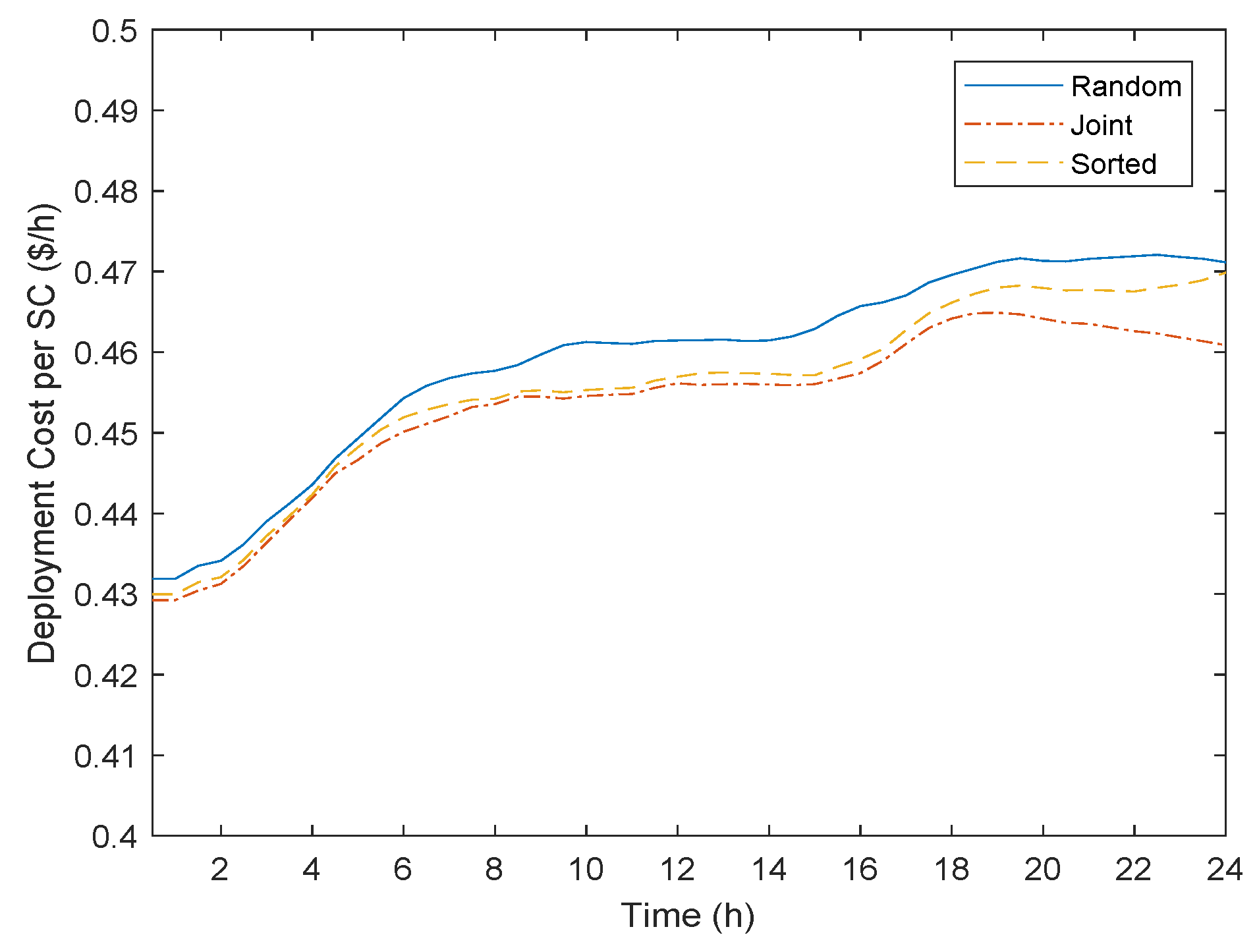
Figure 5 illustrates that the initial solution can impact the overall deployment cost. Specifically, the more sophisticated the initial solution, the better the results. For example, the Random initial solution provides the worst deployment cost, while the Joint approach (placing VNFs in neighboring servers and interconnect the VNFs) presents the best. By selecting the servers with the highest availability (Sorted), we can get a solution in between these two extremes. This reveals that providing as input to the local search mechanism an initial solution with a lower cost can help the TS algorithm to converge to a better overall solution. It is worth noting that, even though the Joint solution is the most computational intense approach, the execution-time overhead is relatively small since it is executed only once at the beginning of the algorithm.
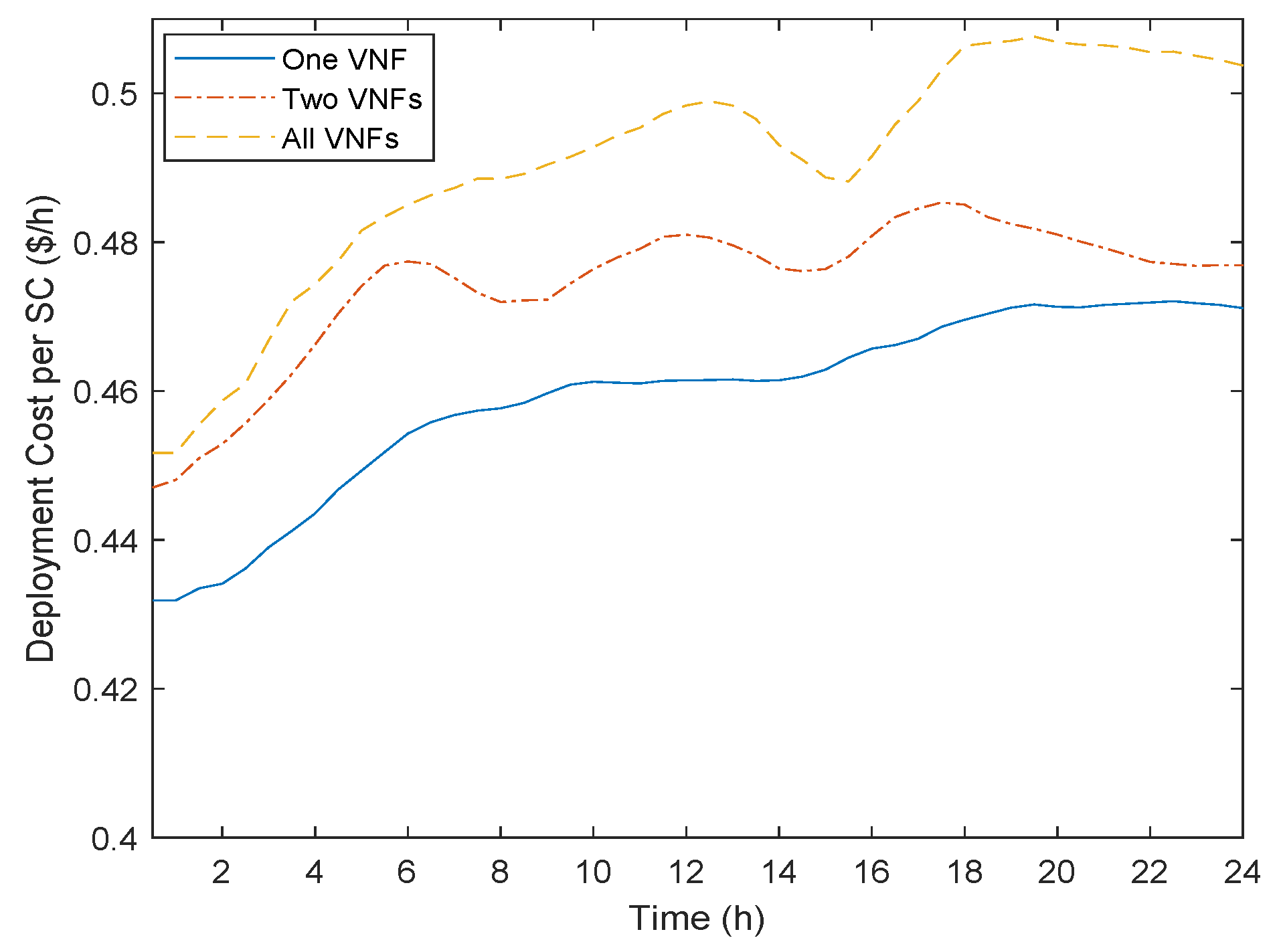
Regarding the neighborhood, as illustrated in
Figure 6, for movements of one VNF at each iteration of the Local Search, we can have better results. As the neighborhood grows (for example, more VNFs), the results get worse. The reason is that moving only one VNF to a new server can help the TS algorithm to escape from local optima easier. In contrast, moving two VNFs or the whole SC at each iteration does not help the algorithm avoid a local optima, since we cannot efficiently explore the search space of available solutions. In order to perform a detailed exploration of the search space, a higher number of iterations would be needed, which would significantly increase the execution time. To this end, as our goal is to propose an algorithm that can reduce the execution time in comparison to MIP, we adopt the “One VNF” neighborhood approach.
As a third step of the fine tuning of the TS algorithm, we evaluate the impact of the Tabu List size.
Figure 7 shows that, with a Tabu List of size 10, we can achieve the highest cost reduction. For a small sized Tabu List, we do not efficiently restrict the TS to not cycle into previously explored solutions, which can affect the overall deployment cost. On the other hand, if we utilize a large sized Tabu List, we significantly eliminate the search space and the available neighborhood of each VNF. For example, if a neighbor solution of a current solution is the optimal one but we select a different one from the available neighborhood, then we eliminate the algorithm to not find it for at least 15 iterations.
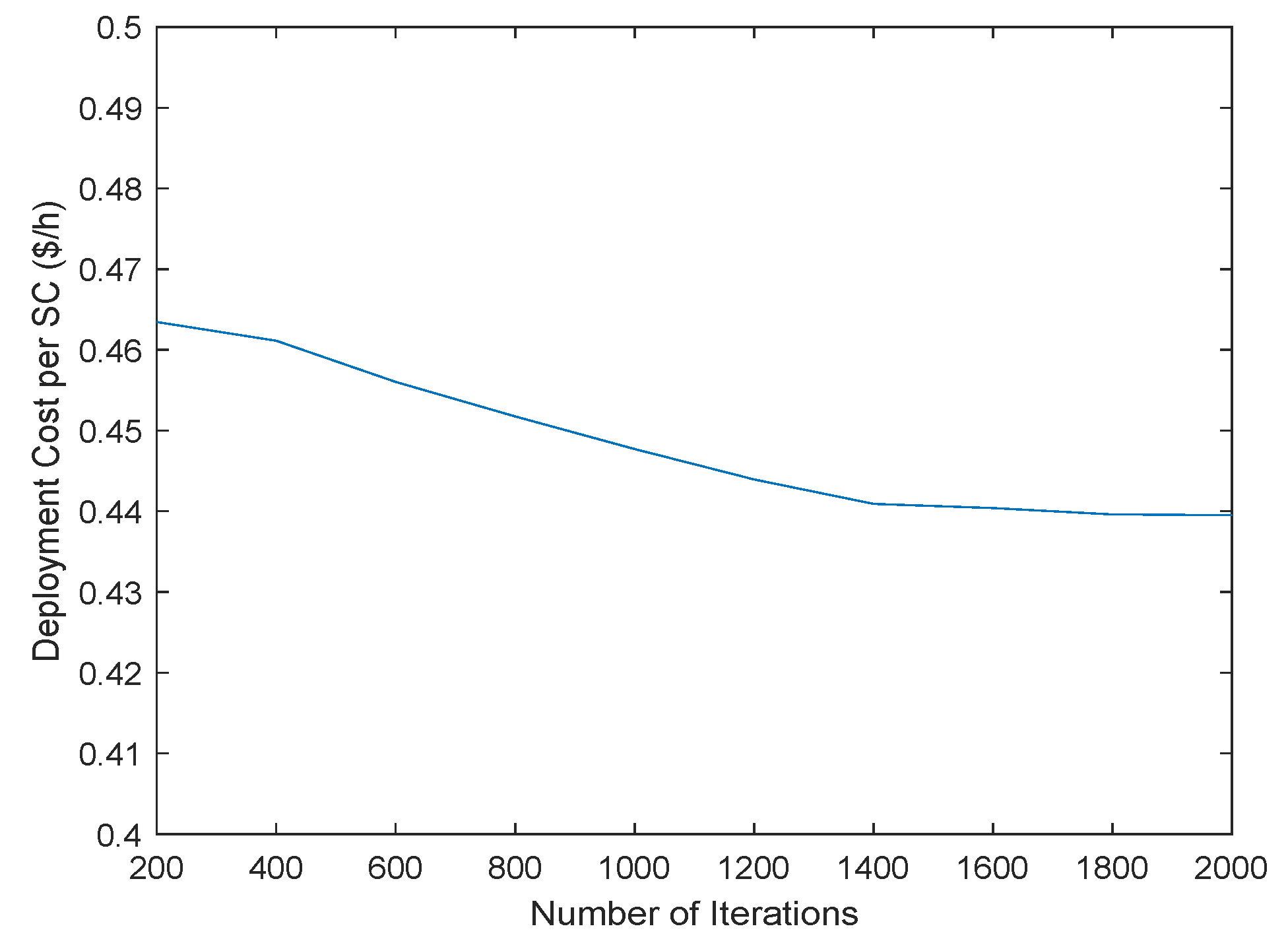
As a final performance tuning step, we evaluate the impact of the termination criterion to the overall solution. We evaluate how the cost evolves as we increase the total number of iterations from 200 to 2000 with a step of 200. As
Figure 8 illustrates, as we increase the number of iterations, a more refined final solution can be extracted. However, after 1400 iterations, the algorithm converges to a local optimum and no further improvements can be achieved. To this end, in the following experiment, we configure the TS algorithm to use a Joint initial solution, with a single movement of a VNF as the neighbor solution, a Tabu List with size 10, and 1400 iterations for our termination criterion.
6.2. Experiment 2: VNF-PEC Evalution
In this experiment, we evaluate the performance of the four algorithms under consideration.
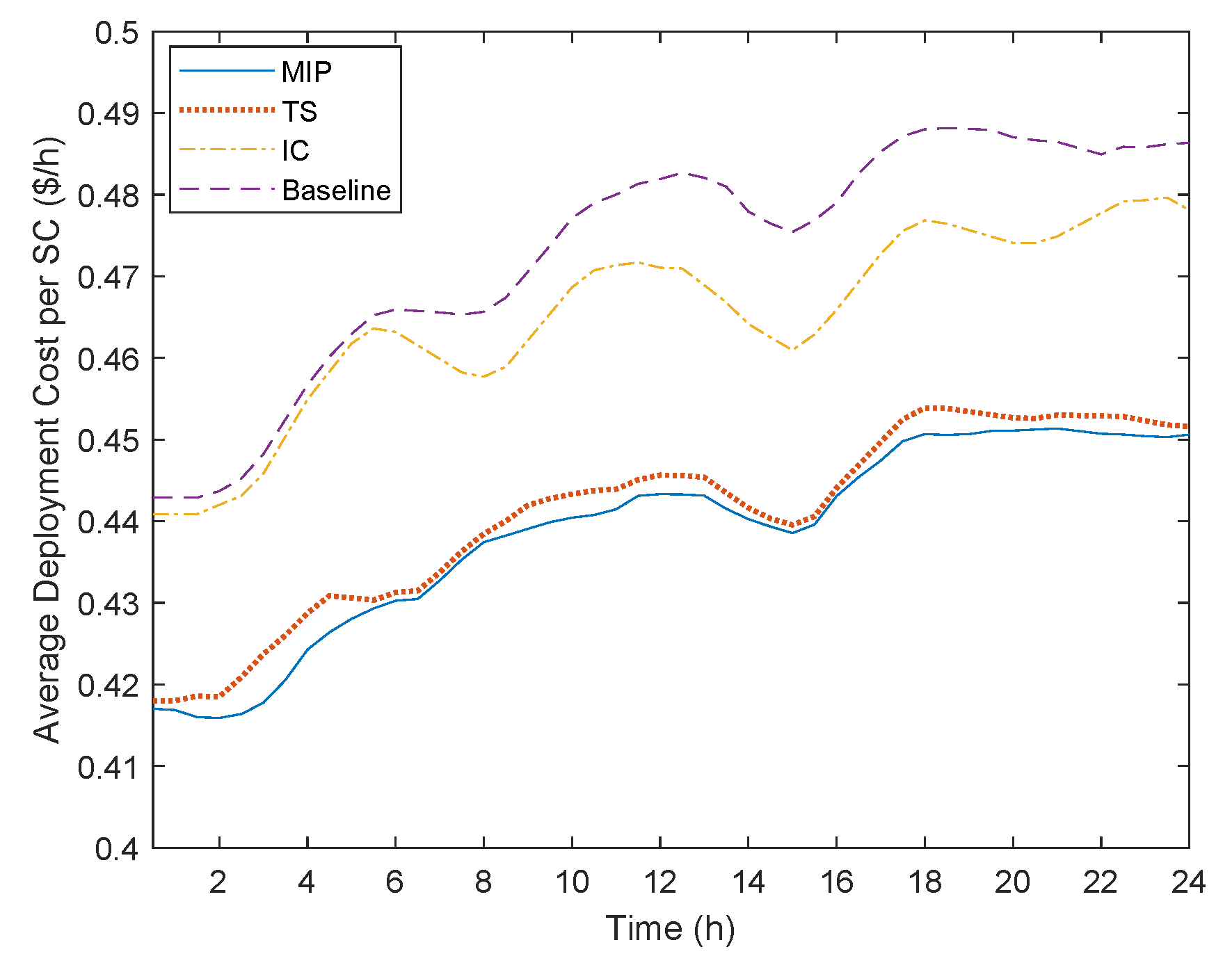
Figure 9 illustrates the average deployment cost per SC. As was expected, the MIP algorithm provides the lowest cost. Nonetheless, the TS approach manages to provide a very cost-efficient solution close to an optimal one. The reason is that TS adopts the same multi-objective function as the MIP algorithm. Hence, only solutions that lead to lower costs are produced at each step of the local search mechanism. On the other hand, the IC and Baseline algorithms present the worst performance. Even though both algorithms try to consolidate the VNFs on the same server or at the Edge, they fail to do it as efficiently as the other two algorithms. The rationale behind this behavior is that both algorithms do not consider any possible location constraint. Hence, they may not find neighbor servers that can host the rest of an SC, leading to using a higher number of links and thus a higher cost. This can be more evident for the Baseline algorithm, where VNFs constrained to be located at the cloud can lead to multiple crossings of the transport network, which significantly adds to the overall cost.
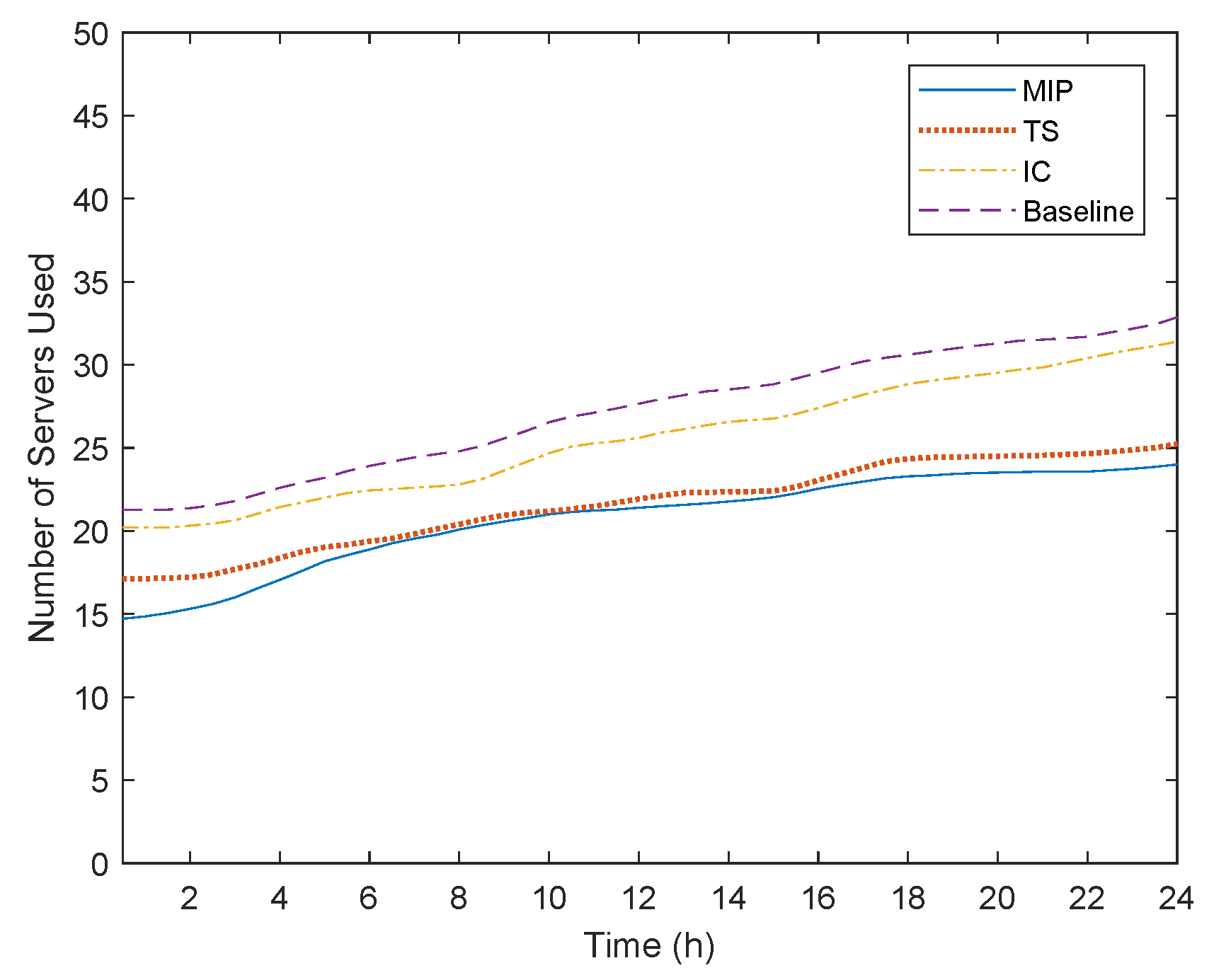
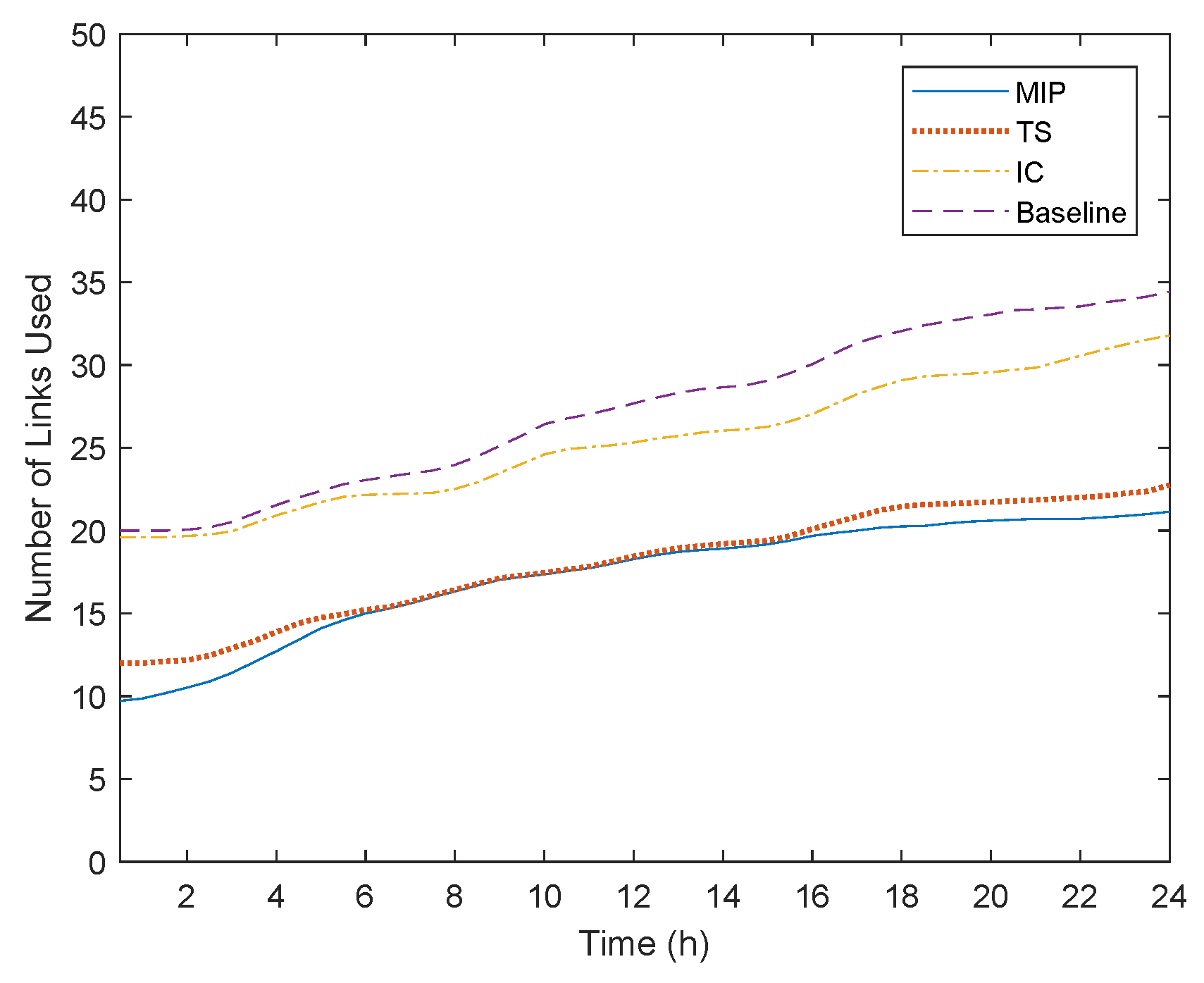
To better understand the deployment solutions produced, we also evaluate the total number of servers and links used as illustrated in
Figure 10 and
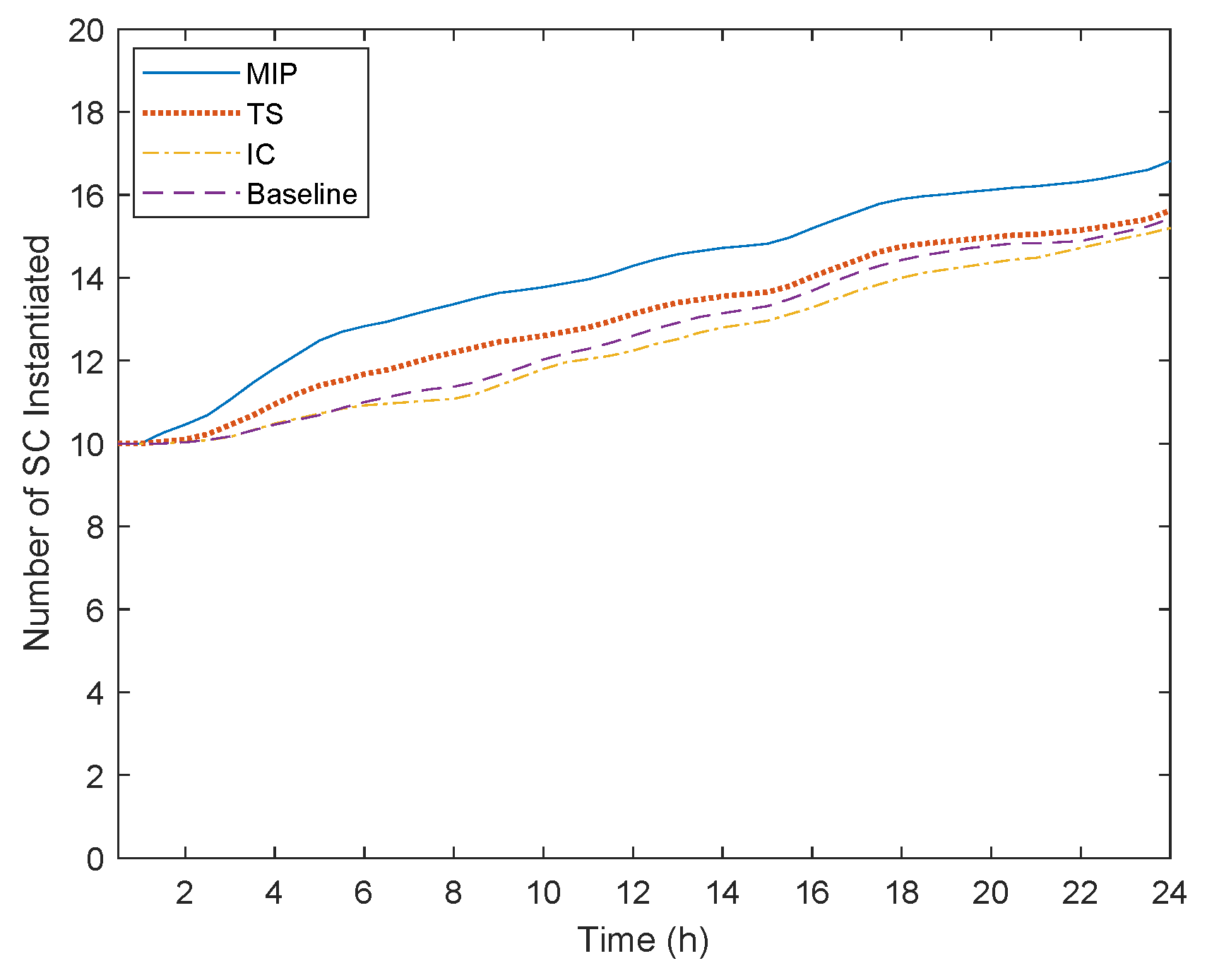
Figure 11. Our first observation is that, in the course of time, the number of nodes and links needed to facilitate the incoming users increases for all algorithms. This happens because even though we may consider 10 SCs, which is a typical number of a service portfolio by a SP, some of them need to be duplicated to serve all the incoming users. This can be validated by
Figure 12, where we can see that initially only 10 SCs are deployed. However, as more users are associated with the SCs, more instances of the SCs are provisioned to serve the total traffic generated.
The second observation is that the IC and Baseline algorithms utilize the highest number of resources, which also validates the highest cost noticed in
Figure 9. On the one hand, IC tries to consolidate as many adjacent VNFs as possible in one server. However, if two or more consecutive VNFs are constrained to be located at the Edge or Cloud, efficient consolidation is not possible, leading to higher resource utilization. Similarly, for the Baseline algorithm, if the Edge resources are stressed or if there are VNFs with Cloud resource requirements, the resource allocation performance is significantly deteriorated. On the other hand, the MIP and TS algorithms utilize less physical resources and more efficiently. This validates the efficiency of a multi-objective approach, when considering both the Edge and Cloud infrastructures. The MIP algorithm as an optimal solution provides the lowest number of resources, while TS through the refinement mechanism applied by the Local Search can minimize the performance gap.
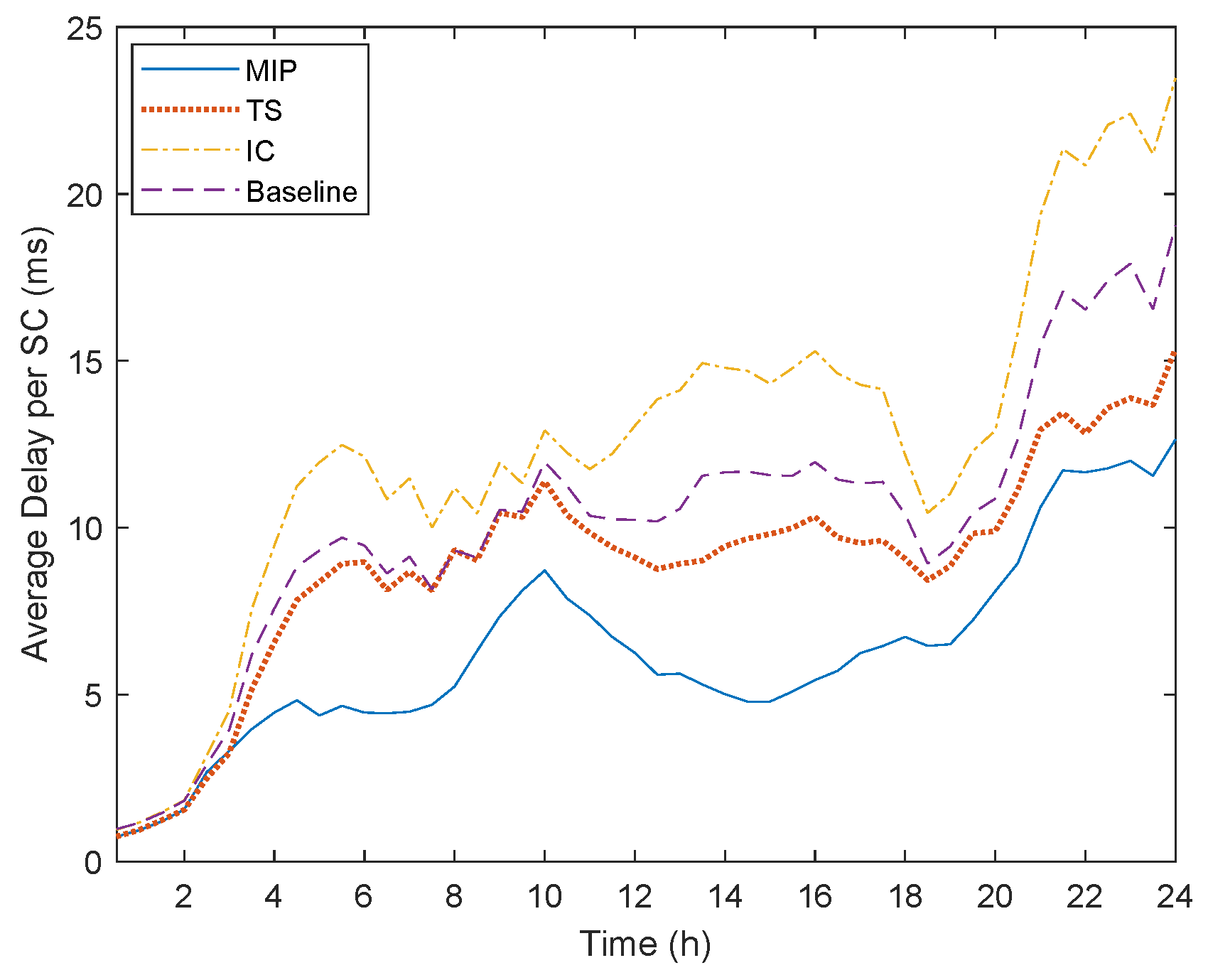
Even though we would expect that the MIP and TS algorithms would present a higher total delay, since they utilize less resources than the other two algorithms, this is not the case. As illustrated in
Figure 13, the MIP algorithm manages to succeed the least total delay per SC. This is because the MIP algorithm instantiates a higher number of SC and thus distributes more efficiently the load between the servers, while minimizing processing and queuing delays. At the same time, since it jointly tries to allocate the VNFs and interconnect them with the goal to minimize the deployment cost and overall delay, it performs a much more efficient link selection. On the other hand, the TS algorithm utilizes a simple shortest path algorithm similar to the other heuristics. Nevertheless, TS presents a lower delay since it takes into consideration the location constraints and thus can avoid long paths between the Edge and Cloud. The two heuristics once again show a poor performance. The Baseline algorithm, exactly due to the fact that does not take into consideration the latency overhead of using the transport network, presents a high propagation delay that significantly contributes to the overall delay. Similarly, IC even as tries to minimize the propagation delay (e.g., through consolidating the VNFs in one server), does not take into account how overloading the servers can exponentially increase the overall queuing and processing delay. Finally, it is worth noting that the high fluctuations observed in
Figure 13 are due to the dynamic traffic model that is followed.
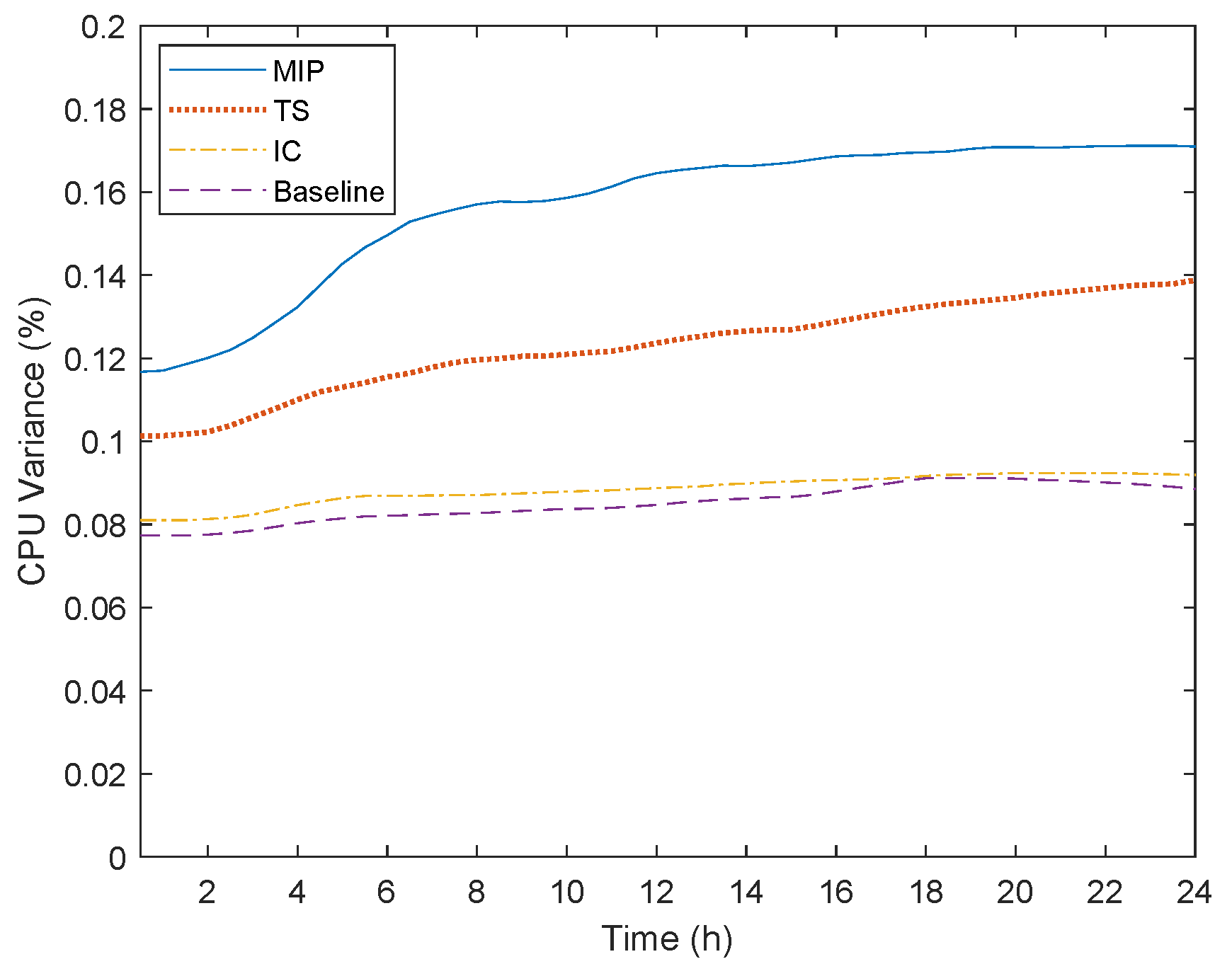
The above results demonstrate that the MIP and TS algorithms can actually reconcile the conflicting goals of reduced deployment cost and delay. In contrast, the IC and Baseline approaches, even though they consider the interoperation of Cloud and Edge layers, only consider the efficient resource utilization in terms of resource usage. This is validated by the average CPU variance among the servers utilized by their solution (
Figure 14). This particular behavior, along with the other results, reveal that the two algorithms try to deplete the resources of each server before activating a new server in order to minimize resource idleness. Even though that behavior would be desirable in an environment where we only had just the Edge or Cloud infrastructures or when they are not location constrained VNFs, this is not a realistic approach. In addition, minimizing resource idleness can greatly affect the overall delay, which can be performance-harmful when considering mission critical IoT applications.
6.3. A Hybrid Simulation Approach
Above, we evaluated the performance of the proposed VNF-PEC algorithms using a java-based simulator. A simulation-based evaluation introduces many benefits, especially in terms of cost and time execution of the experiments. However, using a purely simulated environment to evaluate the performance of such a complex system, where different and heterogeneous hardware and software components are merged together towards providing a flexible and efficient end-to-end networking solution from the things to the Cloud, can lead to a discrepancy in the results extracted under an emulation approach (e.g., using IoT, Edge, and Cloud testbeds).
Even though this deviation in the results between a simulation-based and an emulation-based approach can be significant, in the particular work, we tried to create a realistic experimentation environment using real data from industrial use-cases and literature reviews to reduce the gap between these two testing methodologies. Furthermore, bearing in mind that we have to deal with mission critical IoT applications in which the delay is of utmost importance in the overall evaluation, we introduced a complete and thorough delay model to simulate the latency performance of our approaches.
On the other hand, aiming to conduct real experiments for large-scale IoT, MEC, and Cloud research concepts comes with a high setup and implementation cost. For example, in order to reproduce our experimentation set-up, we would need hundreds of IoT devices, dozens of servers, dozens of different software packages and licenses, and an extremely high amount of time for configuring our hardware and software components, making a purely emulation approach impossible.
Thus, inspired by the hybrid simulation approach proposed in [
58], we design and propose a hybrid simulation alternative that can combine emulation and simulation together towards providing a more realistic evaluation.
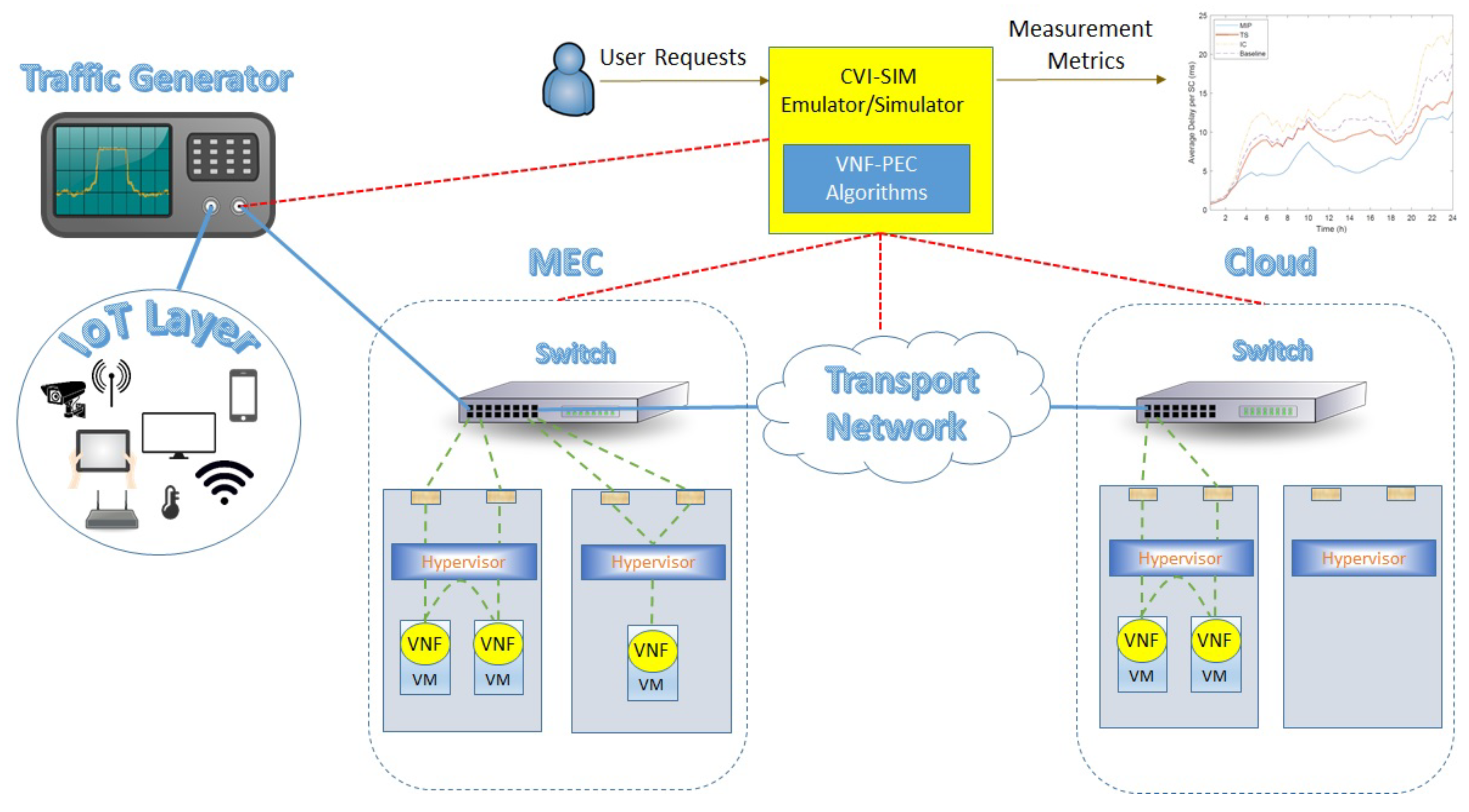
Figure 15 illustrates the design of a hybrid simulation/emulation approach for the VNF-PEC implementation. In the particular framework, the first step is to emulate our IoT platform. For this step, we envision the utilization of an IoT testbed, where we can deploy our IoT applications and gather statistics regarding their traffic characteristics. The data statistics will be stored as traffic profiles that we will load to our traffic generator, which will be used to emulate the IoT traffic. However, since we are assuming a dynamic traffic model, we will simulate the random inter-arrival and lifetime distribution of the IoT devices, which will constitute the input of our CVI-SIM simulator. The CVI-SIM will then accordingly update the traffic profile of the traffic generator (e.g., by adjusting the number of flows corresponding to the number of IoT devices associated with the IoT applications).
The infrastructure topology including the networking aspects of representing the Edge and Cloud will be simulated as typical network graphs, upon which the VNF placement will be performed. From this placement, we will extract offline statistics of the VNF-PEC evaluation like the total deployment cost, number of leased resources and routing decisions. In other words, the CVI-SIM will act as a controller with a complete knowledge of the underlying infrastructure and the status of the available resources.
However, in this case, the intercommunication of the VNFs will be emulated by using two small-scale data centers to emulate the delay behavior of the placement solution. Specifically, as shown in
Figure 15, we assume that we have an SC of five VNFs that is allocated in two servers at the Edge and another one at the Cloud. At the edge, two VNFs of the SC are allocated on the same server, while the third one at a different server. Finally, the rest two VNFs are allocated on a Cloud server. By sending the traffic and configuring the routing path, we can extract real processing and queuing delays, while the propagation delays will be simulated and added to the overall delay communication by simulating the distances between the communicating servers. In the same manner, the transport network will be simulated as a link connecting the two data centers, adding the corresponding propagation delay.
Finally, for the chaining of the VNFs, two different approaches will be used according to the placement decision. In the first case, assuming that two consecutive VNFs are allocated on the same server, a Virtual Ethernet Bridging (VEB) technique will be used by creating a bridge at the hypervisor level that will facilitate the interconnection of the VNFs. In the second case, the traffic forwarding between two VNFs residing on different servers will be performed through the switch, using a Virtual Ethernet Port Aggregator (VEPA) technique. The CVI-SIM will monitor and gather real-time metrics (e.g., delay, throughput) and will extract the necessary results after the completion of the experiment.
Nonetheless, the major challenge in this hybrid system is the response time to interconnect and synchronize the different modules. We need to make sure that the communication of the involved modules will be performed seamlessly without adding any significant delays, especially since we are measuring the response-time of mission critical IoT applications.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}