1. Introduction
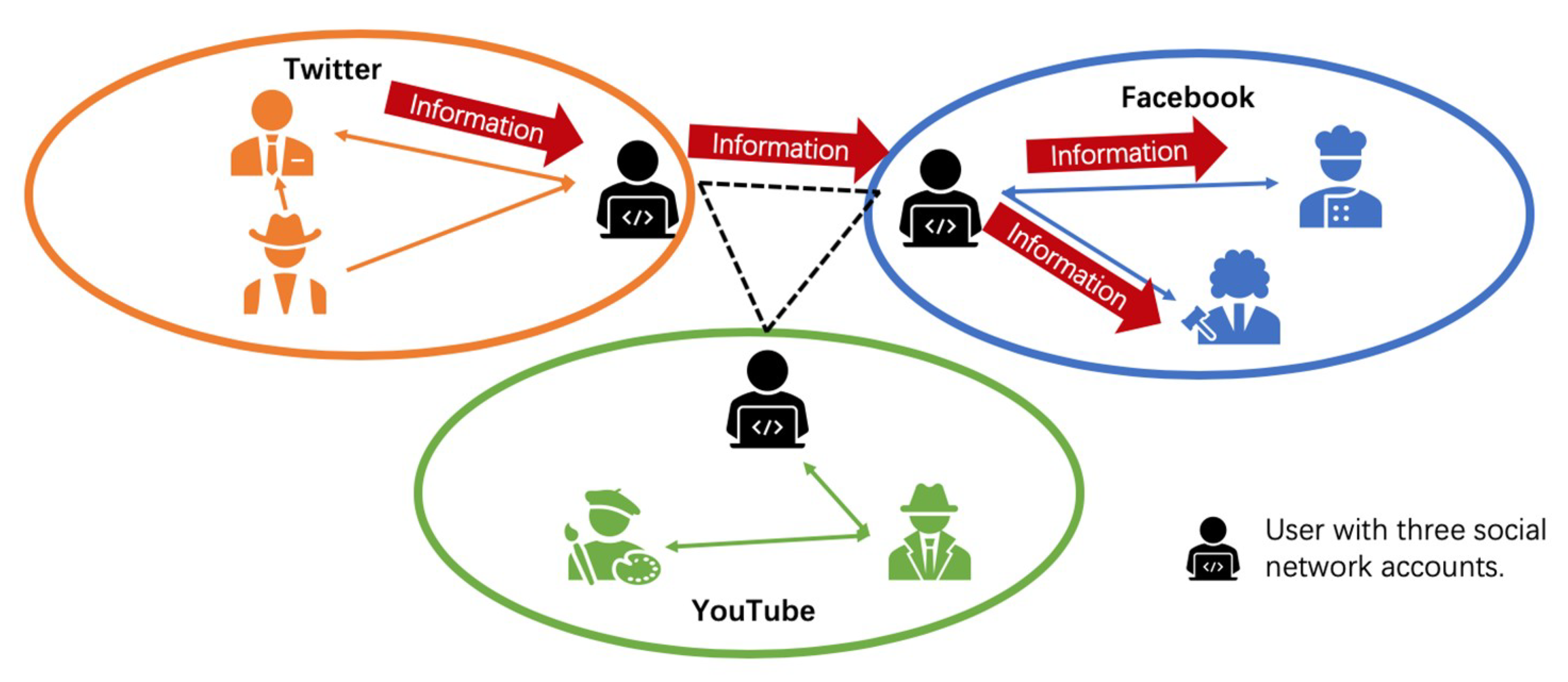
In recent years, various social networks [
1] offering different services have appeared on the Internet, e.g., Facebook, Twitter, YouTube and Foursquare. For the purpose of enjoying different services, some users register accounts on different social networks simultaneously. Different from the traditional connections with other users, they have not only social links among users within one social network, but also crossing links connecting accounts between different social networks. Multi-social networks are connected by these shared users [
2]. Due to their obvious advantages in spreading information, as exemplified by the high speed, low cost and wide influence, social networks attract more and more attention of researchers, which results in many hot topics, involving social information spreading [
3], public opinion [
4], Internet marketing [
5] and so on. The influence maximization in a social network has been extensively studied in the academic community [
6,
7,
8,
9,
10], which is the problem of finding a small subset of nodes in a social network that could maximize the spread of influence [
7]. However, the existing influence maximization research for the single social network cannot be directly adapted to the multi-social networks due to their heterogeneous architecture and complex connections among users. The users with multiple social network accounts can spread information from social network A to social network B. An example is given in
Figure 1, a user who is registered on Twitter and Facebook has the ability to forward the information on Twitter to Facebook, which demonstrates the scope of information spreading no longer confined within the single social network. This factor leads to the different characteristics of information spreading as before and needs to be considered in the influence of maximization research.
To maximize the influence spreading in multi-social networks, the researchers in References [
11,
12,
13,
14,
15,
16] focus on finding
k (
) users to constitute the initial active seed node set
S to spread information, the expected number of active nodes
R(
S) at the end of a diffusion process in multi-social networks can be maximized. Due to budgetary constraints, the size of
S is usually fixed in existing research, i.e.,
k is fixed. However, when we get
S through complex theoretical calculations, some initial seed nodes in the set
S may be difficult to activate for some reasons. In the end, a broken
S cannot get the maximum influence, resulting in the low influence spreading performance. For example, in social network advertising marketing, one user has high influence in social networks, but for some reasons, he is unwilling to post advertisements, which may lead to advertising marketing failure. Therefore, when some users in
S cannot be activated, it is very necessary to find substitutes for these nodes to reduce the loss of influence.
Some researchers have already done some work on this subject. Li et al. [
17] proposed the idea of finding “successors”. When a seed node cannot be activated, the neighbor node is selected as a substitute. Ma et al. [
18] named this problem as the Substitutes Discovery in Influence Maximization and proposed three solving algorithms based on the Greedy algorithms. However, these two works aim at solving the substitute mining problem in a single social network, which cannot adapt to the information spread in multi-social networks directly. In this paper, we discuss the information spread across social networks and focus on solving the problem of multi-social networks influence maximization. Specifically, the contributions of this paper are summarized as follows:
- (1)
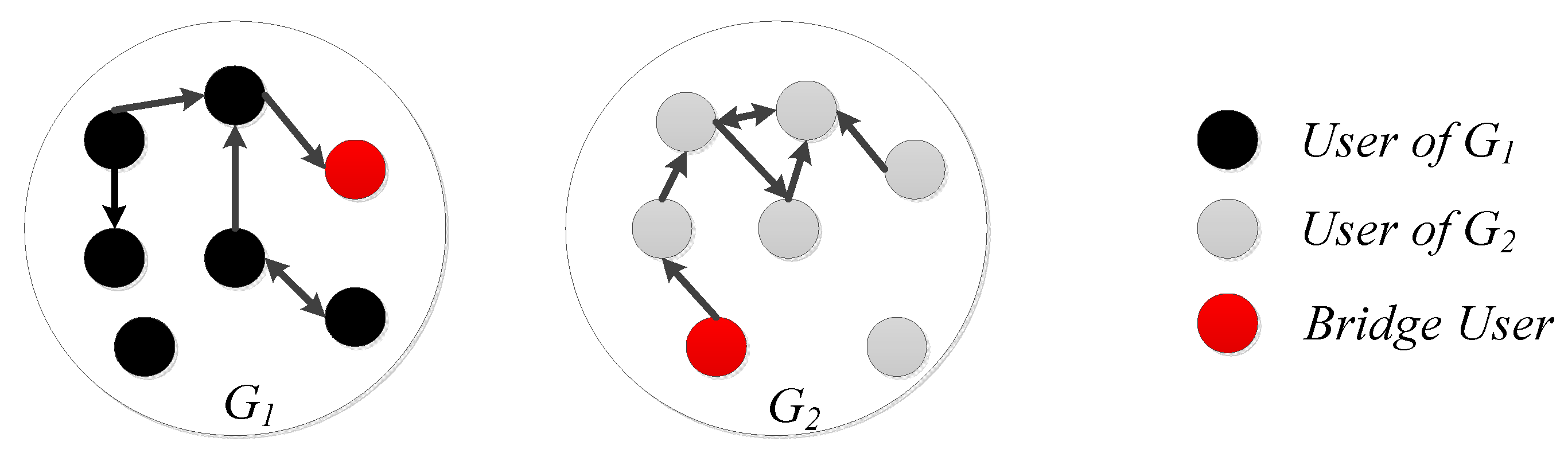
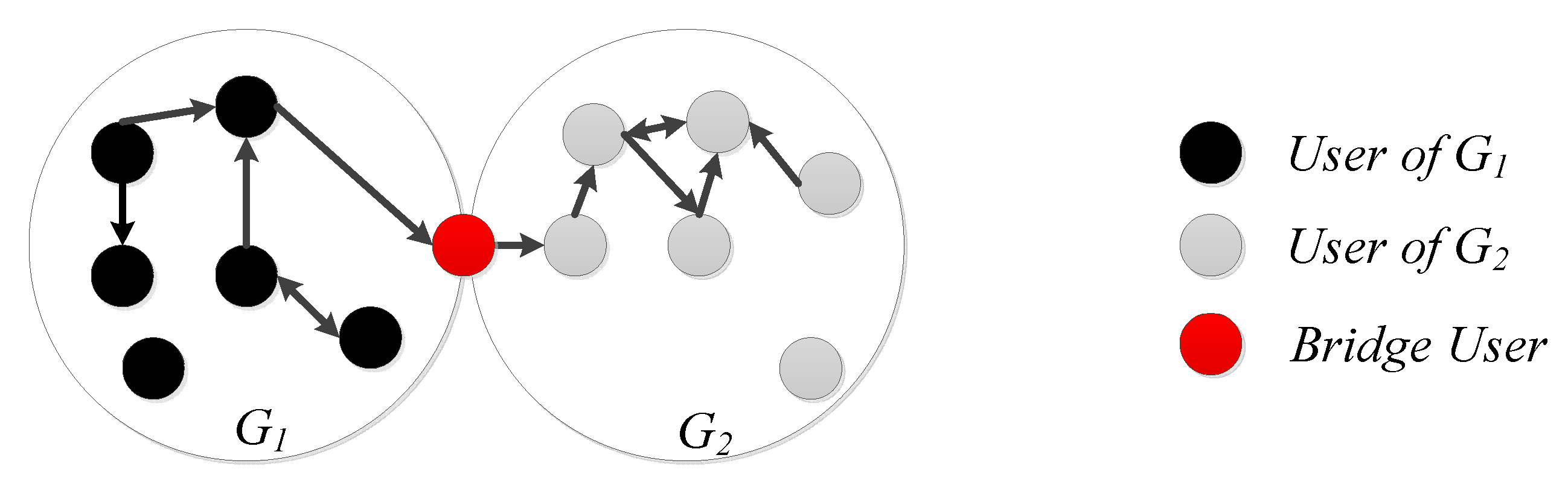
We analyze the characteristics of information spreading in multi-social networks and define the special use with multiple social network accounts as Bridge User, which plays an important role in forwarding information from one social network to another.
- (2)
We discuss the problem of substitutes mining for multi-social networks influence maximization (SMMNIM), which aims to find substitutes and to reduce the loss of information spread caused by the uncooperative seed nodes.
- (3)
Three algorithms are proposed to solve SMMNIM in this paper for different application scenarios.
The rest of the paper is organized as follows.
Section 2 introduces the special type of nodes named as
Bridge Users, and the multi-social networks influence maximization problem.
Section 3 presents the substitutes mining for multi-social networks influence maximization. In
Section 4, substitutes seed nodes mining algorithms are proposed. The viability and performance of the proposed algorithms are evaluated in
Section 5. Finally, we conclude this paper in
Section 6.
3. Substitutes Mining for Multi-Social Networks Influence Maximization
Given multiple social networks
,
,
, …,
, which are made of
m social network users
and the relationship between these users. Using multi-social networks influence maximization algorithms, we can find the initial user set represented as
. Assume that the user in the subset
(
) cannot be activated at the initial moment, it needs to find
t substitute nodes in the set
to form a substitute user set
, constituting a new initial seed user set
, so that
e.g., the difference between the new initial set
S’ and the original set
S is smallest, ensuring that the reduction of influence is close to the minimum.
We name this as the problem of substitutes mining for multi-social networks influence maximization (SMMNIM), in the following part, we will propose algorithms to solve this problem.
4. Substitutes Mining Algorithms for SMMNIM
In order to mine the substitutes for influence maximization in multi-social networks, three substitutes mining algorithms for SMMNIM are proposed in this section.
4.1. Greedy-Based Substitutes Mining Algorithm for SMMNIM (G_S)
The literature [
13] has proved that substitute nodes mining for influence maximization in a single social network is an NP-hard problem. SMMNIM can be regarded as finding
t seed users in the set
that can maximize information influence, so it is also an NP-hard problem. The NP-hard problem can be approximated to the optimal based on the greedy algorithm. Therefore, we first design a Greedy-based substitutes mining algorithm for SMMNIM (G_S), which is shown in Algorithm 2.
| Algorithm 2. Greedy-based Substitutes Mining Algorithm for SMMNIM (G_S). |
| Input:, seed node set , the subset of seed nodes that can be activated , number of seeds that cannot be activated t; |
| Output: New initial seed seeds set ; |
| 1) ; |
| 2) : The number of active nodes obtained by ; |
| 3) for to |
| 4) for in |
| 5) select |
| 6) end for |
| 7) |
| 8) end for |
| 9) Output ; |
4.2. Pre-Selected-Based Substitutes Mining Algorithm for SMMNIM(P_S)
Using G_S, the most suitable set of substitutes can be found. However, G_S needs to simulate and calculate the influence of all users, thus requires a large number of calculations, which leads to low algorithm efficiency. In this section, we propose an algorithm based on the idea of “prepare in advance”. When selecting initial seed nodes, additional nodes will be selected, we call these nodes as “pre-selected nodes”. When some nodes cannot be activated, pre-selected nodes will be used as substitute nodes. Assuming that k initial seed nodes need to be selected, we select initial seed nodes form a preselected set . When the number of non-cooperative nodes is t , the nodes from to are selected as substitutes. If there are still uncooperative nodes in the substitutes, we will continue to select nodes from the pre-selected set . The amount of calculation will be greatly reduced. This algorithm we named as pre-selected-based substitutes mining algorithm for SMMNIM (P_S), which is shown in Algorithm 3.
| Algorithm 3. Pre-selected-based Substitutes Mining Algorithm for SMMNIM (P_S). |
| Input:, pre-selected seed node set , the number of additional selected nodes ; |
| Output: New initial seed seeds set ; |
| 1) , ; |
| 2) : The number of active nodes obtained by ; |
| 3) for i = 1 to |
| 4) for in |
| 5) select |
| 6) end for |
| 7) |
| 8) end for |
| 9) for v in |
| 10) if v is uncooperative node |
| 11) |
| 12) end for |
| 13) for i = 1 to k |
| 14) for v in |
| 15) |
| 16) end for |
| 17) end for |
| 18) Output ; |
4.3. Similar-Users-Based Substitutes Mining Algorithm for SMMNIM (S_S)
In this section, we propose another solution to find substitutes based on the idea of “finding the most similar user of uncooperative user”. We focus on seeking the most similar users of the uncooperative nodes as the substitutes and propose a similar-users-based substitutes mining algorithm for SMMNIM (S_S), which is shown in Algorithm 4. We integrate structure similarity and neighbor attribute similarity to evaluate the similarity between two users.
Given an aggregation graph of multi-social networks, indicates the edge from node u to node v. The structure of the node u is determined by the in-edges and out-edges of the node.
indicates the out-edges and be defined as
indicates the in-edges and be defined as
The structure of the node
u is defined as
The structural similarity of node
u and node
v is defined as
The self-spread of a Bridge User makes it more likely to have a wider scope of influence spread than ordinary users. When choosing the most similar user of the uncooperative user, the other factor we need to consider is the similarity of neighbor attributes (Bridge Users or ordinary users).
In the neighbor node set of node
u, the number of
Bridge Users is denoted as
, and the number of ordinary users is denoted as
. The neighbor node attributes of node
u are defined as vectors
The Euclidean distance of the neighboring attributes of
u and
v is
Then we define the neighbor attributes similarity between node
u and
v is
Finally, the similarity between node
u and
v is based on the similarity calculated by the structure similarity and the neighbor attributes similarity,
| Algorithm 4. Similar-users-based Substitutes Mining Algorithm for SMMNIM (S_S). |
| Input:, seed node set , the subset of seed nodes that can be activated , the subset of seed nodes that cannot be activated ; |
| Output: New initial seed seeds set ; |
| 1) ; |
| 2) : The number of active nodes obtained by ; |
| 3) for i = 1 to || |
| 4) for in |
| 5) for v in |
| 6) select |
| 7) |
| 8) end for |
| 9) end for |
| 10) end for |
| 11) Output ; |
5. Simulation
5.1. Data Description
The experiments are based on the following three social network datasets:
NetHEPT: This dataset is derived from “High Energy Physics” and is a web-based data about authors of articles. Each node represents an author, and the number of edges between a pair of nodes is equal to the number of papers the two authors collaborated [
7].
Epinions: This dataset comes from the social network “Epinions”. In the data set, if a user trusts another user, there is an edge between the users.
Slashdot: This dataset is derived from the “Slashdot” website, a consulting technology website and its users can post comments on the website. In this data set, if the user is a friend or an opponent, it is considered that there is a relationship between the users and there is an edge.
The detailed information of nodes and edges is shown in
Table 1.
5.2. Analysis of Multi-Social Networks Influence Maximization
In the simulation, CELF++ is used to solve the problem of influence maximization and the propagation model we selected is the LT model. For the edge (u, v) existing in the graph G, the probability the node u to activate its neighbor node v is calculated by the reciprocal of the number of node v’s in-degrees, that is . Each time the influence of the seed set was calculated, the propagation process was simulated by 10,000 Monte Carlo methods.
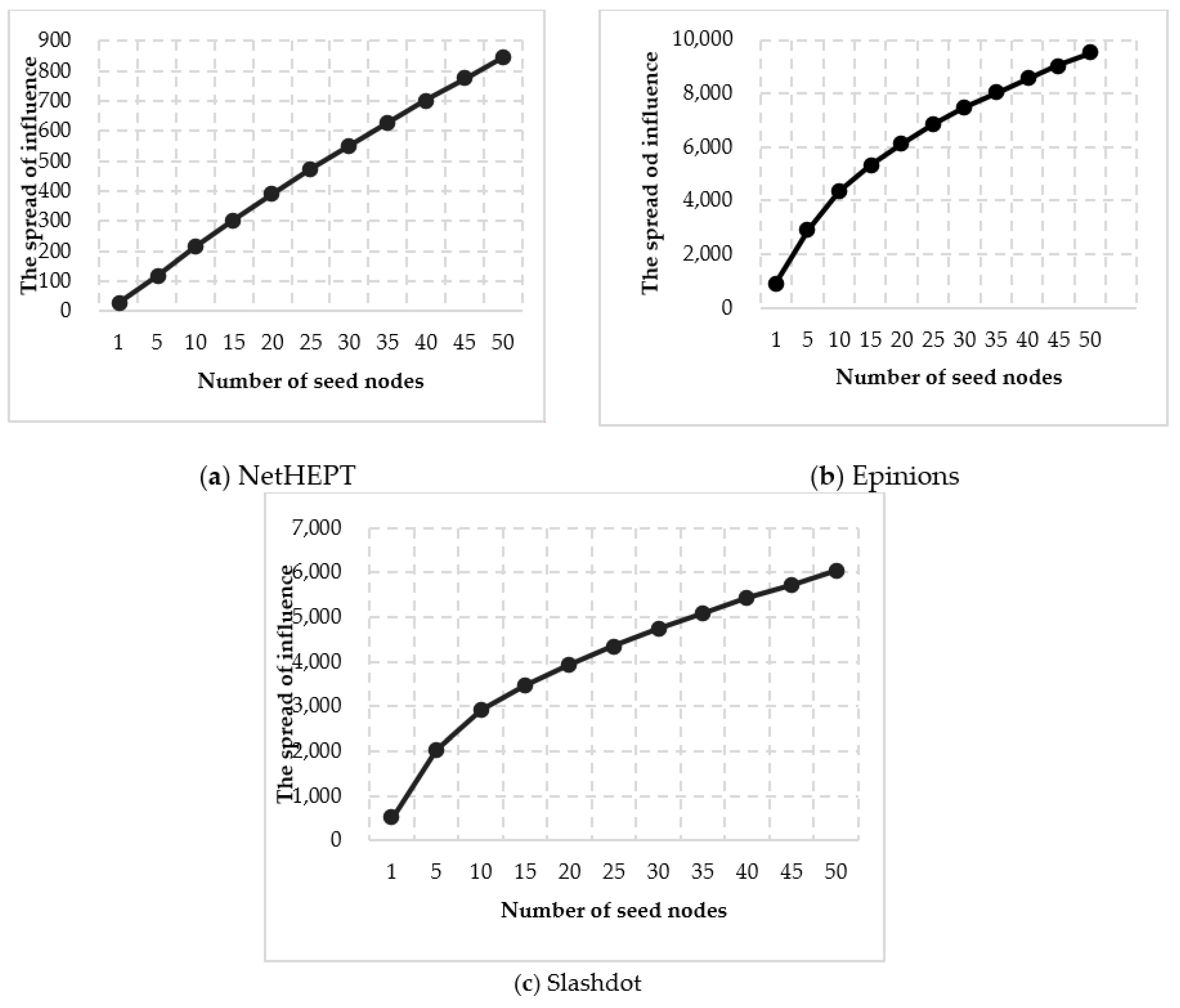
To compare with the information spread in multi-social networks, we first show the spread of influence in a single social network, as shown in
Figure 4. From the experimental results we can see that, as the number of seed nodes increases, the influence increases.
Next, the experiments verify the information spread in multiple social networks. However, we cannot get the social network data sets with the annotated
Bridge Users. In the experiments, we choose the node with the same ID from the three social networks and assume these nodes (with the same ID) belong to one user, this user is regarded as a
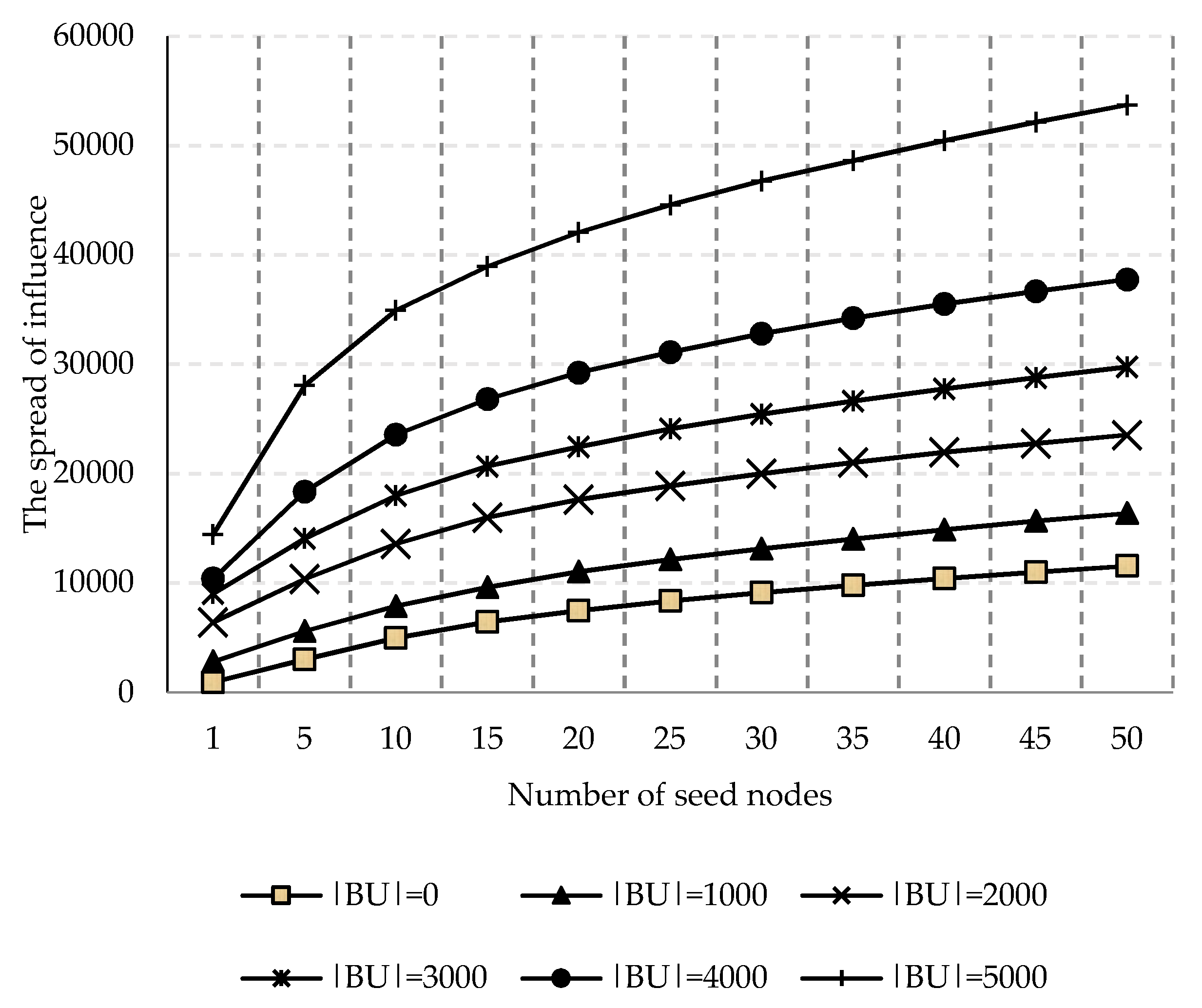
Bridge User. In the following simulation, the BU is obtained by this method. Then the above three social networks
,
,
can be aggregated into one network
by algorithm 1. When aggregation, the number of selected
Bridge User is set as 0, 1000, 2000, 3000, 4000, and 5000 respectively. The information spread with a different number of
Bridge Users in multi-social networks is shown in
Figure 5.
As the result shown in
Figure 5, we can find that, as the number of seed nodes increases, the spread of influence becomes larger. As discussed before, we have analyzed that
Bridge Users can spread information from social network
to
. When comparing the influence spreading of a different number of
Bridge Users, we can see that the more
Bridge Users, the wider influence spreading, which indicates the self-spread of
Bridge User expands the scope of information spreading. These results confirm that the problem of influence maximization is different from previous, multi-social networks can be connected by
Bridge Users.
5.3. Comparison Results of Substitutes Mining Algorithms
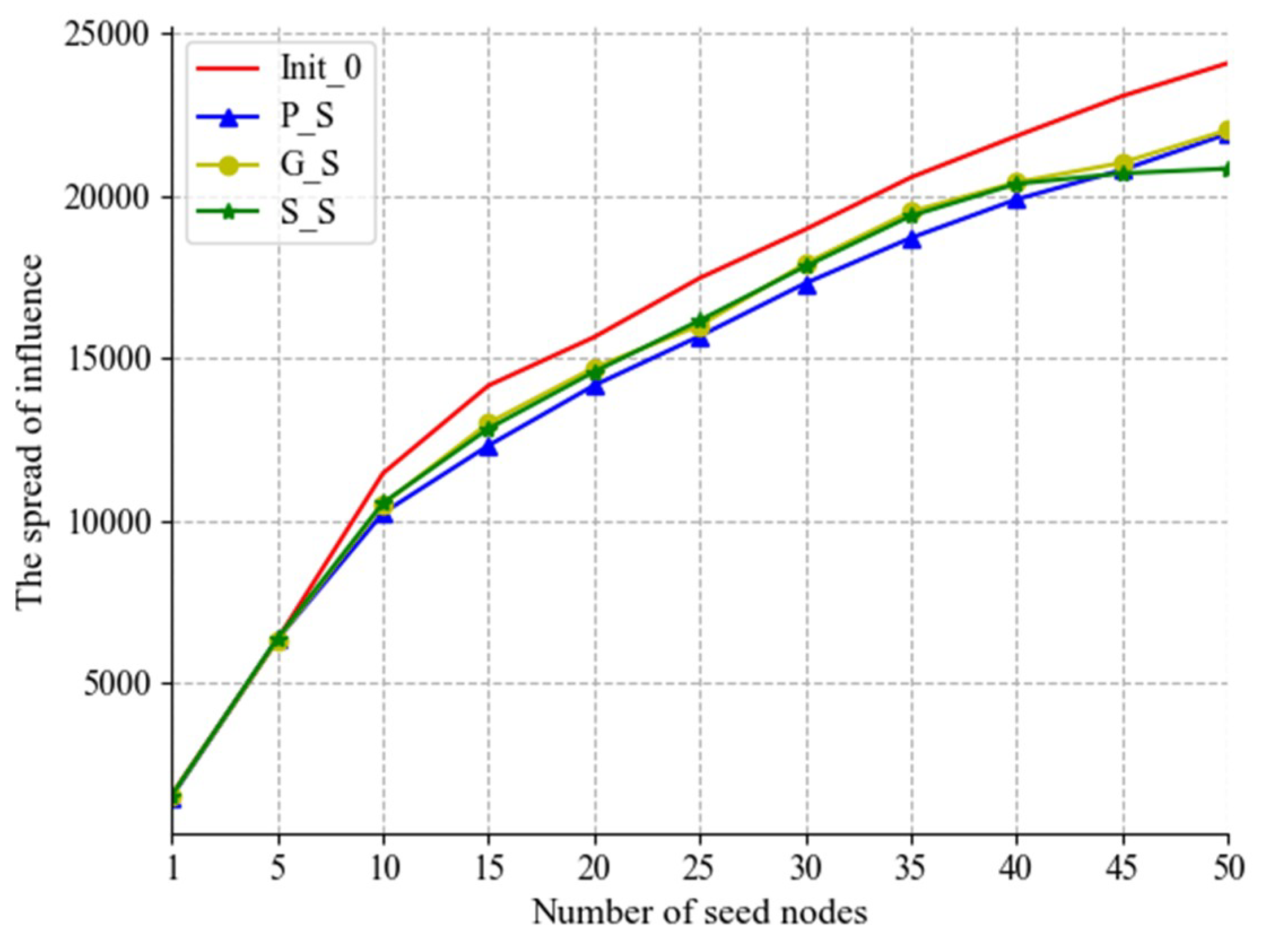
The uncooperative seed nodes will lead to the failure of influence maximization, it is necessary to select appropriate substitute nodes to replace the uncooperative seed nodes. In this section, assume that the cooperation rate of the seed nodes is 80%, this means that if we expect to select 50 nodes as the initial seed nodes, there may be 10 nodes will be uncooperative seed nodes. The purpose of the three algorithms designed in this paper is to find 10 substitutes to replace the uncooperative seed nodes. To evaluates the performance of each algorithm, this paper compares the algorithm in three aspects: the influence spread range of the new seed set, the loss rate of the influence spreading, and the memory/time consumption of the algorithm running. Each algorithm is executed multiple times to avoid errors (in this experiment, the number of times is five). In the figure of experimental results, init-0 represents the initial set of seed nodes, G_S represents solving algorithms for SMMNIM based on Greedy, P_S represents pre-selected-based substitutes mining algorithm for SMMNIM, and S_S represents similar-users-based substitutes mining algorithm for SMMNIM.
Figure 6 shows the influence spreading of the new seed set obtained by the three algorithms G_S, P_S and S_S. Compare with the influence spreading of original initial seed set (Init_0), we find that the three new seed set get lower influence spreading. Although we have proposed algorithms to find substitutes, it still unable to make up for the losses caused by the uncooperative nodes. It indicates that the uncooperative nodes lead to the reduction of influence maximization in multiple social networks. In other aspects, the new seed set obtained by G_S algorithm can achieve the closest influence spreading to the original seed set can produce. This is because the G_S algorithm is equivalent to finding the optimal seed set in the rest nodes. Therefore, the new seed set solved by G_S can obtain a wider range of influence than the other two algorithms. Compared with the P_S algorithm, the new seed set obtained by S_S algorithm has a wider range of influence. This is because the S_S algorithm looks for the most similar node of the uncooperative node as the substitute node, the influence that substitute nodes can produce is similar to the original uncooperative node. P_S algorithm just pre-select some nodes for replacing the uncooperative node. Therefore, S_S has a better performance than the P_S algorithm.
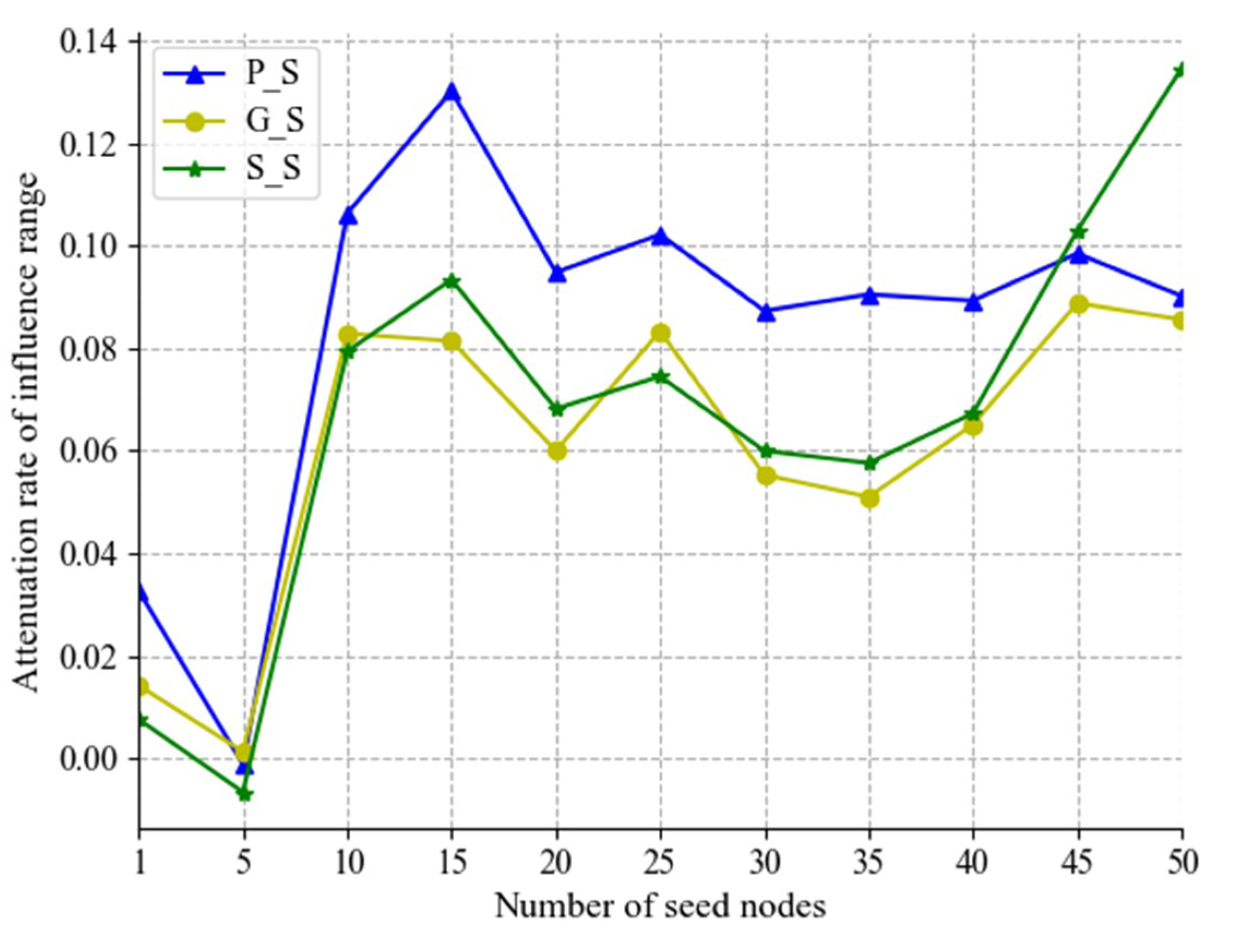
Figure 7 illustrates the loss rate of influence spreading of the new seed set by three algorithms. While the G_S algorithm solves the better alternative nodes, the loss of influence is smaller. The S_S algorithm takes second place.
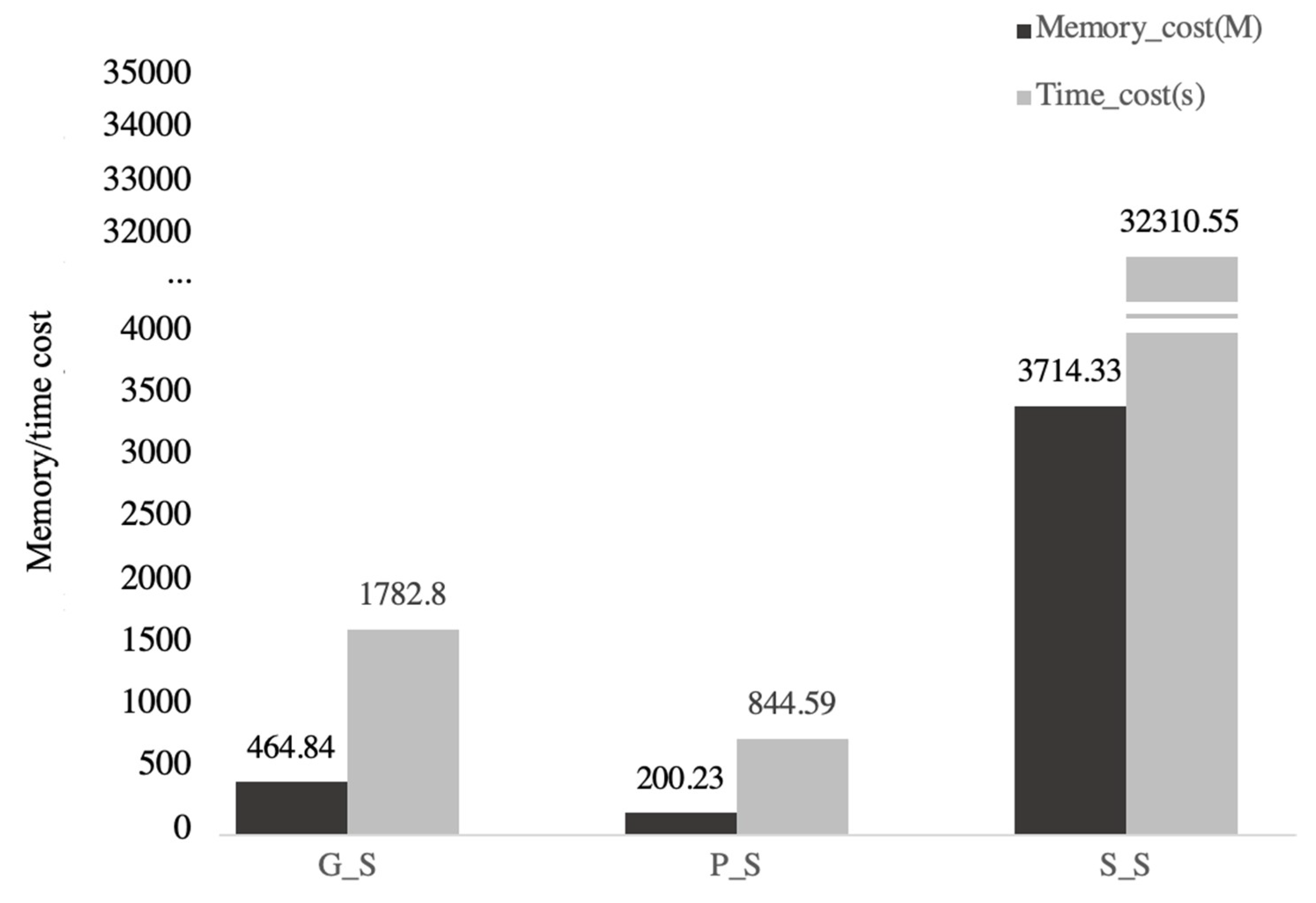
In terms of algorithm memory/time cost (
Figure 8), P_S algorithm costs less memory than G_S algorithm, and the time cost is smaller than G_S algorithm. The main reason is that P_S algorithm will pre-select some nodes in advance as “standby” nodes. When some nodes do not cooperate, they can select substitute nodes from the “standby” nodes without recalculations. The G_S algorithm needs a long time to recalculate the new seed set, it’s about two times that of P_S algorithm, and the cost of memory is also larger than P_S. In addition, the S_S algorithm spends a number amount of calculations on user similarity, so its memory/time cost is the largest.
Therefore, all three algorithms can find the substitute nodes and reduce the influence loss caused by uncooperative nodes, we can choose one of them according to different requirements. The substitute nodes found by G_S algorithm can get closer influence to the original seed node set, but it cost more time and memory. That is, G_S is suitable for the scenes that are not sensitive to time or memory but require a wider range of influence; P_S algorithm can get the substitute nodes immediately, so it is more suitable for time-sensitive or memory-sensitive scenes; Due to the large number of calculations on user similarity, the S_S algorithm can be selected when the user similarity is known in advance.
6. Conclusions
In this paper, we first studied the problem of multi-social networks influence maximization. By defining the user with multiple social network accounts as a Bridge User, we discussed how a Bridge User affects the information spreading in multiple social networks. Then we considered a new and significant problem by analyzing that there may be some seed nodes cannot be activated in the process of influence maximization. Hence, it is necessary to find substitute nodes to reduce the losses caused by these uncooperative seed nodes. This brings up the problem of Substitutes Mining for Multi-Social Networks Influence Maximization (SMMNIM). In this paper, three substitute nodes mining algorithms were proposed (G_S, P_S and S_S). The experimental results showed that: (1) In multi-social networks, Bridge Users can make information spread across social networks and expand the range of information influence; (2) the uncooperative nodes will reduce the range of information influence; (3) three substitute node mining algorithms can find suitable substitute nodes and construct the new seed set, which makes the information influence as close as possible to the original seed node set; (4) according to different application scenarios, the three algorithms can be selected for mining the substitute seed nodes.
In the future research, we will further consider the attributes of nodes and information, such as the node’s interests, the subject of the information, etc., take these factors into the process of multi-social networks influence maximization, and propose more accurate and efficient substitute node mining algorithm.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}