CMS: A Continuous Machine-Learning and Serving Platform for Industrial Big Data

Abstract
:1. Introduction
- A container-based computing platform is constructed for continuous model learning and serving;
- A model management service, Orchestrator, is proposed to streamline the model updating process. The structures for trainer and modelet are also formulized to ensure consistent invocation and avoid ad-hoc glue codes;
- A continuous model switching mechanism is proposed. It allows the model serving process to be uninterrupted even the model of the modelet is updated.
2. Related Work
2.1. Computing Platform for Industrial Big Data
2.2. Learning & Serving for Industrial Big Data
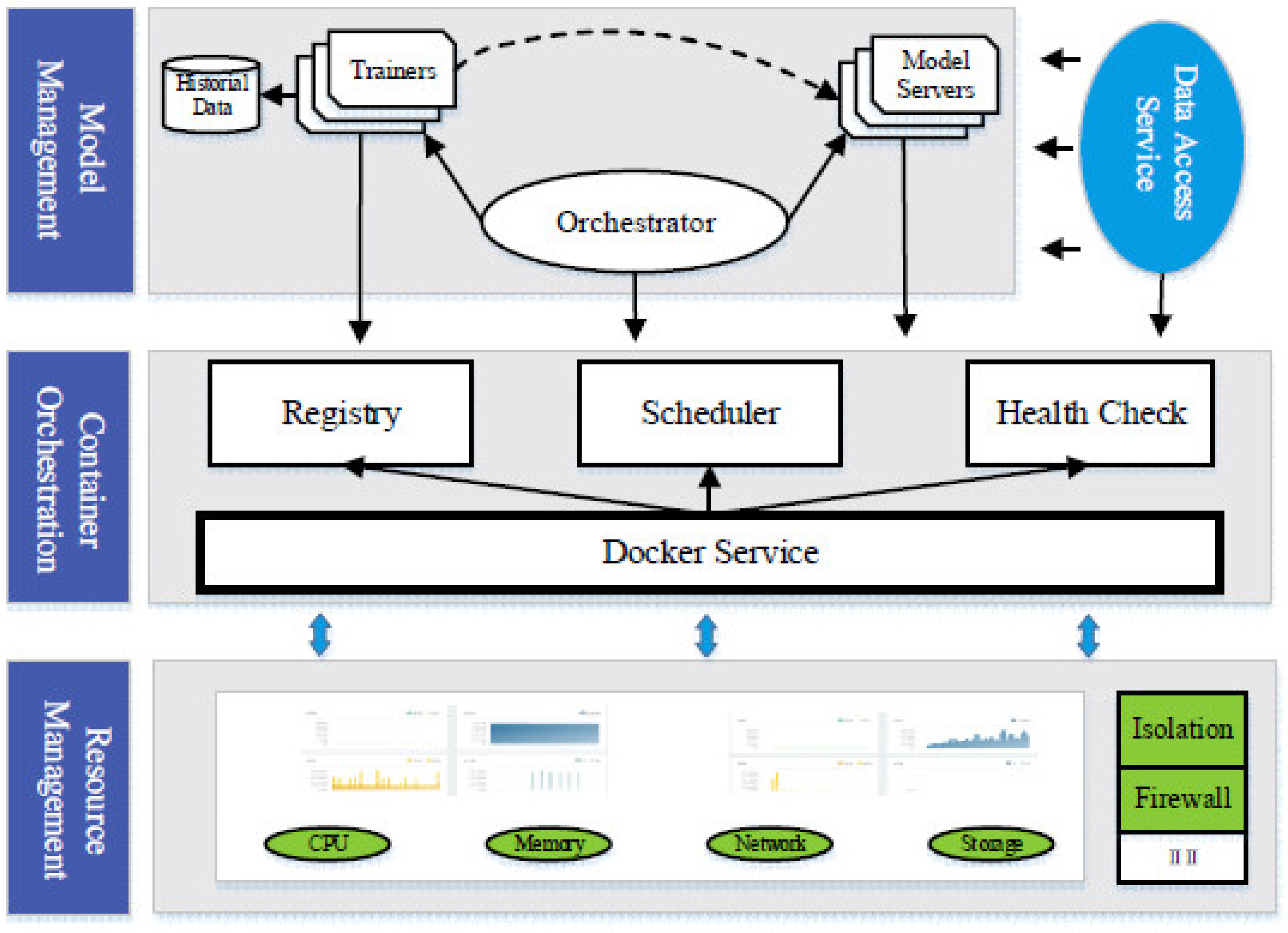
3. Platform Architecture
3.1. Requirement Analysis
- One platform for learning and deployment. For an industrial machine-learning platform, it is important to support both an off-line trainer for model generation from historical data and online model serving for real-time prediction. For the off-line trainer, several machine learning suits, e.g., Spark ML, TensorFlow® and Keras®, should be supported as they are widely used by different developers. The different machine learning suits adopt different model formats, e.g., the HDF5 format for Keras models and the TensorFlow specific model format. The supports for the different machine learning suits mean that the model serving implementations should be designed independently with different model formats. Thus, the current main stream approaches should be seamlessly integrated. The compatibility of the existing modeling efforts is quite important for many existing industrial environments in which the model designs normally need considerable work from both data scientists and industrial domain-specific experts;
- Autonomous model re-training. Due to the strong time series nature of industrial data, the obtained target value error may become larger as time goes on, leading to the loss of reference value for the target value. For an industrial model, the machine learning pipelines are carefully pre-defined via machine learning experts. The training processes execute the feature selection, feature construction and training process in a defined sequence. When the newer data arrive, it is important to update the model by executing the same computing algorithm again with data within a certain range. By doing so, an up-to-date model with a newer version number is generated and needs to be deployed into the model serving process. As the machine-learning platform is deployed close to the data source and it is mainly maintained by non-machine-learning experts, it is important to provide a solution that enables the whole process to be executed without human intervention;
- Model validation. For a newly generated model, it has to be validated before it is deployed into the practical industrial environment. This means that the generated model should be verified, especially with the on-line data, to check the accuracy of the newly generated model. Therefore, it is vital for the reliability and robustness of the platform to ensure the generated model performances before pushing the generated model into the production environment. The transmission errors would result in data errors. Thus, the model validation should be coupled with data validation to address this problem.
- Seamless model updating. When a set of new models are generated and validated, it is important to use the new models to replace their corresponding models used in the model serving service. For the industrial environments, many serving processes could not be interrupted. Thus, it is important to design a model seamless updating mechanism.
3.2. System Architecture
4. Orchestrator
4.1. Scheduler
4.2. Model Validation
4.3. Model Seamless Switching Mechanism
5. Case Study and Experimental Results
5.1. Case Study: 1000 MW Thermal Power Plant
5.2. Model Evolution
5.3. Performance Evaluation
5.3.1. Resource Usage
5.3.2. Multitenancy with Isolation
5.3.3. Model Switching Overhead
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Da Xu, L.; He, W.; Li, S. Internet of things in industries: A survey. IEEE Trans. Ind. Inform. 2014, 10, 2233–2243. [Google Scholar] [CrossRef]
- Díaz, M.; Martín, C.; Rubio, B. State-of-the-art, challenges, and open issues in the integration of Internet of things and cloud computing. J. Netw. Comput. Appl. 2016, 67, 99–117. [Google Scholar] [CrossRef]
- Mourtzis, D.; Vlachou, E.; Milas, N. Industrial big data as a result of IoT adoption in manufacturing. Procedia Cirp 2016, 55, 290–295. [Google Scholar] [CrossRef] [Green Version]
- Hashem, I.A.T.; Yaqoob, I.; Anuar, N.B.; Mokhtar, S.; Gani, A.; Khan, S.U. The rise of “big data” on cloud computing: Review and open research issues. Inf. Syst. 2015, 47, 98–115. [Google Scholar] [CrossRef]
- Tao, F.; Cheng, Y.; Xu, L.D.; Zhang, L.; Li, B.H. CCIoT-CMfg: Cloud computing and internet of things-based cloud manufacturing service system. IEEE Trans. Ind. Inf. 2014, 10, 1435–1442. [Google Scholar] [CrossRef]
- Ji, C.; Liu, S.; Yang, C.; Wu, L.; Pan, L. IBDP: An industrial big data ingestion and analysis platform and Case studies. In Proceedings of the 2015 International Conference on Identification, Information, and Knowledge in the Internet of Things (IIKI), Beijing, China, 22–23 October 2015; pp. 223–228. [Google Scholar]
- Bellavista, P.; Berrocal, J.; Corradi, A.; Das, S.K.; Foschini, L.; Zanni, A. A survey on fog computing for the Internet of Things. Pervasive Mob. Comput. 2019, 52, 71–99. [Google Scholar] [CrossRef]
- Kaur, K.; Sachdeva, M. Fog computing in IOT: An overview of new opportunities. In Proceedings of the International Conference on Emerging Trends in Information Technology, Delhi, India, 24 September 2019. [Google Scholar]
- Shi, W.; Dustdar, S. The Promise of Edge Computing. Computer 2016, 49, 78–81. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Olston, C.; Fiedel, N.; Gorovoy, K.; Harmsen, J.; Lao, L.; Li, F.; Rajashekhar, V.; Ramesh, S.; Soyke, J. TensorFlow-Serving: Flexible, high-performance ML serving. arXiv 2017 arXiv:1712.06139.
- Baylor, D.; Breck, E.; Cheng, H.-T.; Fiedel, N.; Foo, C.Y.; Haque, Z.; Haykal, S.; Ispir, M.; Jain, V.; Koc, L.; et al. TFX: A TensorFlow-Based production-scale machine learning platform. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 23–27 August 2017. [Google Scholar]
- Moreira, M.; Rodrigues, J.J.P.C.; Korotaev, V.; Al-Muhtadi, J.; Kumar, N. A comprehensive review on smart decision support systems for health care. IEEE Syst. J. 2019, 13, 3536–3545. [Google Scholar] [CrossRef]
- Lee, J.; Ardakani, H.D.; Yang, S.; Bagheri, B. Industrial big data analytics and cyber-physical systems for future maintenance & service innovation. Procedia Cirp 2015, 38, 3–7. [Google Scholar]
- Merkel, D. Docker: Lightweight linux containers for consistent development and deployment. Linux J. 2014, 2014, 2. [Google Scholar]
- Chen, M.; Mao, S.; Liu, Y. Big data: A survey. Mob. Networks Appl. 2014, 19, 171–209. [Google Scholar] [CrossRef]
- Wang, X.V.; Xu, X. An interoperable solution for Cloud manufacturing. Robot. Comput. Manuf. 2013, 29, 232–247. [Google Scholar] [CrossRef]
- Chang, H.; Hari, A.; Mukherjee, S.; Lakshman, T.V.; Mukherjee, S. Bringing the cloud to the edge. In Proceedings of the 2014 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Institute of Electrical and Electronics Engineers (IEEE), Toronto, Ontario, Canada, 27 April–2 May 2014; pp. 346–351. [Google Scholar]
- Hao, Z.; Novak, E.; Yi, S.; Li, Q. Challenges and Software Architecture for Fog Computing. IEEE Intern. Comput. 2017, 21, 44–53. [Google Scholar] [CrossRef]
- Liu, X.; Iftikhar, N.; Xie, X. Survey of real-time processing systems for big data. In Proceedings of the 18th International Database Engineering & Applications Symposium, Porto, Portugal, 7–9 July 2014. [Google Scholar]
- Wan, J.; Tang, S.; Li, D.; Wang, S.; Liu, C.; Abbas, H.; Vasilakos, A.V. A manufacturing big data solution for active preventive maintenance. IEEE Trans. Ind. Inf. 2017, 13, 2039–2047. [Google Scholar] [CrossRef]
- Tseng, F.-H.; Tsai, M.-S.; Tseng, C.-W.; Yang, Y.-T.; Liu, C.-C.; Chou, L.-D. A lightweight autoscaling mechanism for fog computing in industrial applications. IEEE Trans. Ind. Inform. 2018, 14, 4529–4537. [Google Scholar] [CrossRef]
- Daoqu, G.; Chengyun, Z.; Chengjing, X.; Xue, X.; Qilin, L.; Xinshuai, F. Big data-based improved data acquisition and storage system for designing industrial data platform. IEEE Access. 2019, 7, 44574–44582. [Google Scholar]
- Ismail, B.I.; Goortani, E.M.; Ab Karim, M.B.; Tat, W.M.; Setapa, S.; Luke, J.Y.; Hoe, O.H. Evaluation of docker as edge computing platform. In Proceedings of the 2015 IEEE Conference on Open Systems (ICOS), Institute of Electrical and Electronics Engineers (IEEE), Melaka, Malaysia, 24–26 August 2015. [Google Scholar]
- Sculley, D.; Chaudhary, V.; Young, M.; Crespo, J.-F.; Dennison, D.; Holt, G.; Golovin, D.; Davydov, E.; Phillips, T.; Ebner, D. Hidden technical debt in machine learning systems. Neural Inf. Process. Syst. 2015, 2, 2503–2511. [Google Scholar]
- Landset, S.; Khoshgoftaar, T.M.; Richter, A.N.; Hasanin, T. A survey of open source tools for machine learning with big data in the Hadoop ecosystem. J. Big Data 2015, 2, 380. [Google Scholar] [CrossRef] [Green Version]
- Vartak, M.; Subramanyam, H.; Lee, W.-E. ModelDB: A system for machine learning model management. In Proceedings of the Workshop on Human-In-the-Loop Data Analytics, San Francisco, CA, USA, 14–19 June 2016. [Google Scholar]
- Shahoud, S.; Gunnarsdottir, S.; Khalloof, H.; Clemens, D.; Veit, H. Facilitating and managing machine learning and data analysis tasks in big data environments using Web and microservice technologies. In Proceedings of the 11th International Conference on Management of Digital EcoSystems, Limassol, Cyprus, 12–14 November 2019. [Google Scholar]
- Zhang, C.; Yu, M.; Wang, W.; Yan, F. Mark: Exploiting cloud services for cost-effective, slo-aware machine learning inference serving. In Proceedings of the 2019 {USENIX} Annual Technical Conference ({USENIX}{ATC} 19), Renton, WA, USA, 10–12 July 2019. [Google Scholar]
- Perez-Botero, D.; Szefer, J.; Lee, R.B. Characterizing hypervisor vulnerabilities in cloud computing servers. In Proceedings of the Workshop on Security in Cloud Computing (SCC), Hangzhou, China, 8 May 2013. [Google Scholar]
- Zhu, Y.; Ma, J.; An, B.; Cao, D. Monitoring and billing of a lightweight cloud system based on linux container. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems Workshops (ICDCSW), Atlanta, GA, USA, 5–8 June 2017. [Google Scholar]
- E N, P.; Mulerickal, F.J.P.; Paul, B.; Sastri, Y. Evaluation of docker containers based on hardware utilization. In Proceedings of the 2015 International Conference on Control Communication & Computing India (ICCC), Institute of Electrical and Electronics Engineers (IEEE), Trivandrum, Kerala, India, 19–21 November 2015. [Google Scholar]
- Dragoni, N.; Giallorenzo, S.; Lafuente, A.L.; Mazzara, M.; Montesi, F.; Mustafin, R.; Safina, L. Microservices: Yesterday, today, and tomorrow. In Present and Ulterior Software Engineering; Springer: Cham, Switzerland, 2017; pp. 195–216. [Google Scholar]
- Benveniste, A.; Caillaud, B.; Nickovic, D.; Passerone, R.; Raclet, J.-B.; Reinkemeier, P.; Sangiovanni-Vincentelli, A.; Damm, W.; Henzinger, T.A.; Larsen, K.G. Contracts for system design. Contract. Syst. Des. 2018, 12, 124–400. [Google Scholar] [CrossRef]
- Dauphin, Y.; Pascanu, R.; Gulcehre, C.; Cho, K.; Ganguli, S.; Bengio, Y. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. In Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2, Cambridge, MA, USA, 8–13 December 2014; pp. 2933–2941. [Google Scholar]
- Zhang, J.; Ding, Z.; Li, W.; Ogunbona, P. Importance weighted adversarial nets for partial domain adaptation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 23 June 2018; pp. 8156–8164. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modeling Targets | Features | MAE-30s | Algorithm |
|---|---|---|---|
| Power | 12 | 0.25 | Ridge |
| main steam temperature | 75 | 0.08 | Ridge |
| reheat steam temperature | 93 | 0.11 | Ridge |
| main steam pressure | 48 | 0.16 | Ridge |
| feedwater temperature | 49 | 0.06 | Ridge |
| active power | 10 | 0.20 | Ridge |
| Max superheater wall temp | 10 | 0.06 | LSTM |
| Max reheater wall temp | 10 | 0.05 | LSTM |
| Num | CPU (%) | Memory (MB) | Disk (KB/s) | |
|---|---|---|---|---|
| Data processors | 10 | 17.24/17.24 | 2824/2825 | 76.6/76.6 |
| Trainers | 4 | 2.12/160.4 | 46.72/ 11059 | 0/176.2 |
| Modelet | 4 | 18.17/18.17 | 369.4/369.8 | 24.2 /24.2 |
| Orchestrator | 1 | 6.3/5.9 | 51.6/48.7 | 17/15.7 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, K.; Gui, N. CMS: A Continuous Machine-Learning and Serving Platform for Industrial Big Data. Future Internet 2020, 12, 102. https://doi.org/10.3390/fi12060102
Li K, Gui N. CMS: A Continuous Machine-Learning and Serving Platform for Industrial Big Data. Future Internet. 2020; 12(6):102. https://doi.org/10.3390/fi12060102
Chicago/Turabian StyleLi, KeDi, and Ning Gui. 2020. "CMS: A Continuous Machine-Learning and Serving Platform for Industrial Big Data" Future Internet 12, no. 6: 102. https://doi.org/10.3390/fi12060102
APA StyleLi, K., & Gui, N. (2020). CMS: A Continuous Machine-Learning and Serving Platform for Industrial Big Data. Future Internet, 12(6), 102. https://doi.org/10.3390/fi12060102