
Machine Learning in Detecting COVID-19 Misinformation on Twitter


Abstract
:1. Introduction
2. Related Work
2.1. Health Misinformation
2.2. Detecting Misinformation on Social Networking Services (SNS)
2.3. Machine-Learning Models to Detect Misinformation
- 1.
- non-negativity
- 2.
- only identity
- 3.
- symmetry
- 4.
- triangle inequality
2.4. Misinformation on Twitter
2.5. Misinformation Corpus
3. Methods
3.1. CoAID Dataset
3.2. Performance Metrics
- TP or true positive: classifier correctly predicted the observation as positive.
- TN or true negative: classifier correctly predicted the observation as negative.
- FP or false positive: classifier wrongly classified the observation as positive, but it is actually negative.
- FN or false negative: classifier wrongly classified the observation as negative, but it is actually positive.
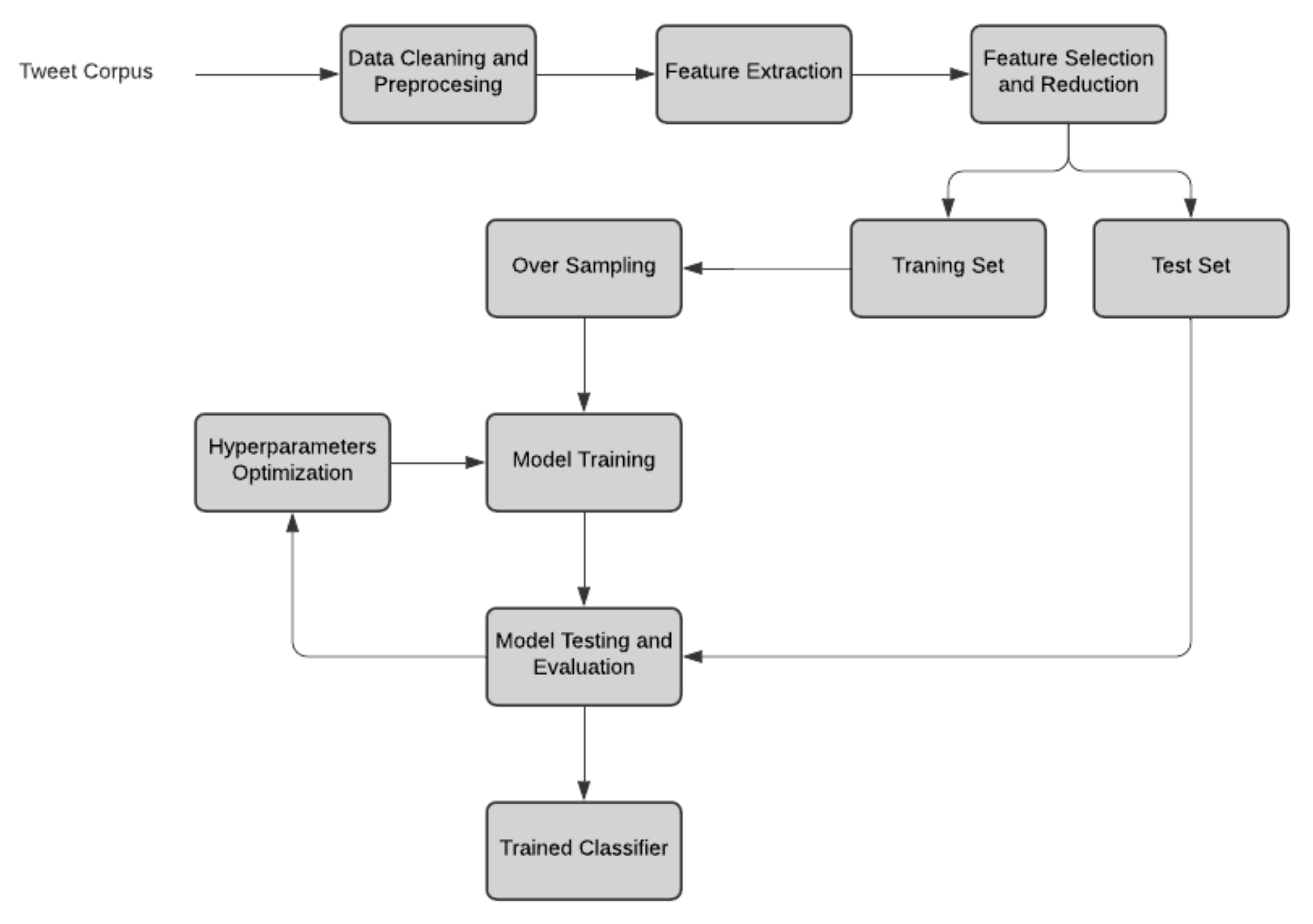
3.3. Framework of Proposed Models
- 1.
- Data cleaning and preprocessing: they are conducted to eliminate unwanted or irrelevant data or noise in the supplied dataset in order to produce the corpus in a clean and understandable format to improve data accuracy. This step involves the removal of unwanted symbols such as punctuation, special characters, URLs, hashtags, www, HTTPS, and digits. After the data are cleaned, they are preprocessed, including stop-word removal, stemming, and lemmatization. Here, we only removed the stop words.
- 2.
- Feature extraction: After performing data cleaning and preprocessing, it is important to extract the features from the text documents. There are many features, but the most important and commonly used are words. In this step, extracted features are converted into vector representation. For this model, TF-IDF was selected for converting text features into corresponding word-vector representation. The generated vector may be high0dimensional.
- 3.
- Feature selection and dimensionality reduction: dimensionality reduction is important in text classification applications to improve the performance of the proposed models. It reduces the number of features to represent documents by selecting the most essential features to project the documents. Feature selection is most important in dimensionality reduction since it selects the most essential feature, capturing the essence of a document. There are various feature-selection and dimensionality-reduction models, from which singular value decomposition was implemented here, which is one of the most effective models. After dimensionality reduction, the entire corpus is divided into training and test sets.
- 4.
- Sampling the training set: Sampling is mainly performed on an imbalanced corpus to rebalance class distributions. There are mainly two types of sampling: over- and undersampling. Oversampling duplicates or generates new data in the minority class to balance the corpus, whereas undersampling delete or merges the data in the majority class. Oversampling is more effective, since undersampling may delete relevant examples from the majority class. Here, oversampling was performed to rebalance the training corpus.
- 5.
- Training: the proposed model is trained using the training corpus.
- 6.
- Performance evaluation: the performance of each model is evaluated using different evaluation metrics such as accuracy, precision, recall, F measure, and PR-AUC.
- 7.
- Hyperparameter optimization: Hyperparameters are very significant since they directly impact the characteristics of the proposed model, and can even control the performance of the model to be trained. So, for improving the effectiveness of the proposed model, hyperparameters are tuned.
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- ITU—Facts and Figures 2020—Interactive Report. Available online: https://www.itu.int/en/ITU-D/Statistics/Pages/ff2020interactive.aspx (accessed on 20 March 2021).
- Philander, K.; Zhong, Y. Twitter sentiment analysis: Capturing sentiment from integrated resort tweets. Int. J. Hosp. Manag. 2016, 55, 16–24. [Google Scholar] [CrossRef]
- Durier, F.; Vieira, R.; Garcia, A.C. Can Machines Learn to Detect Fake News? A Survey Focused on Social Media. In Proceedings of the 52nd Hawaii International Conference on System Sciences, HICSS, Grand Wailea, Maui, HI, USA, 8–11 January 2019. [Google Scholar]
- Thota, A.; Tilak, P.; Ahluwalia, S.; Lohia, N. Fake News Detection: A Deep Learning Approach. SMU Data Sci. Rev. 2018, 1, 10. [Google Scholar]
- Sun, D.; Du, Y.; Xu, W.; Zuo, M.Y.; Zhang, C.; Zhou, J. Combining Online News Articles and Web Search to Predict the Fluctuation of Real Estate Market in Big Data Context. Pac. Asia J. Assoc. Inf. Syst. 2015, 6, 2. [Google Scholar] [CrossRef]
- Alaei, A.R.; Becken, S.; Stantic, B. Sentiment Analysis in Tourism: Capitalizing on Big Data. J. Travel Res. 2019, 58, 175–191. [Google Scholar] [CrossRef]
- Alnawas, A.; Arici, N. Sentiment Analysis of Iraqi Arabic Dialect on Facebook Based on Distributed Representations of Documents. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2019, 18. [Google Scholar] [CrossRef]
- Al-Smadi, M.; Qawasmeh, O.; Al-Ayyoub, M.; Jararweh, Y.; Gupta, B. Deep Recurrent neural network vs. support vector machine for aspect-based sentiment analysis of Arabic hotels’ reviews. J. Comput. Sci. 2018, 27, 386–393. [Google Scholar] [CrossRef]
- Hwang, S.Y.; Lai, C.; Jiang, J.J.; Chang, S. The Identification of Noteworthy Hotel Reviews for Hotel Management. Pac. Asia J. Assoc. Inf. Syst. 2014, 6. [Google Scholar] [CrossRef]
- Binder, M.; Heinrich, B.; Klier, M.; Obermeier, A.; Schiller, A. Explaining the Stars: Aspect-based Sentiment Analysis of Online Customer Reviews. In Proceedings of the 27th European Conference on Information Systems—Information Systems for a Sharing Society, ECIS, Stockholm and Uppsala, Sweden, 8–14 June 2019. [Google Scholar]
- Ceron, A.; Curini, L.; Iacus, S.M. Using Sentiment Analysis to Monitor Electoral Campaigns: Method Matters—Evidence From the United States and Italy. Soc. Sci. Comput. Rev. 2015, 33, 3–20. [Google Scholar] [CrossRef]
- Sandoval-Almazan, R.; Valle-Cruz, D. Sentiment Analysis of Facebook Users Reacting to Political Campaign Posts. Digit. Gov. Res. Pract. 2020, 1. [Google Scholar] [CrossRef]
- Davcheva, E. Text Mining Mental Health Forums-Learning From User Experiences. In Proceedings of the ECIS 2018, Portsmouth, UK, 23–28 June 2018. [Google Scholar]
- Deng, S.; Huang, Z.J.; Sinha, A.P.; Zhao, H. The Interaction between Microblog Sentiment and Stock Returns: An Empirical Examination. MIS Q. 2018, 42, 895–918. [Google Scholar] [CrossRef]
- Deng, S.; Kwak, D.H.; Wu, J.; Sinha, A.; Zhao, H. Classifying Investor Sentiment in Microblogs: A Transfer Learning Approach. In Proceedings of the International Conference on Information Systems (ICIS 2018), San Francisco, CA, USA, 13–16 December 2018. [Google Scholar]
- Jost, F.; Dale, A.; Schwebel, S. How positive is “change” in climate change? A sentiment analysis. Environ. Sci. Policy 2019, 96, 27–36. [Google Scholar] [CrossRef]
- Wollmer, M.; Weninger, F.; Knaup, T.; Schuller, B.; Sun, C.; Sagae, K.; Morency, L. YouTube Movie Reviews: Sentiment Analysis in an Audio-Visual Context. IEEE Intell. Syst. 2013, 28, 46–53. [Google Scholar] [CrossRef]
- Yan, Z.; Xing, M.; Zhang, D.; Ma, B.; Wang, T. A Context-Dependent Sentiment Analysis of Online Product Reviews based on Dependency Relationships. In Proceedings of the 35th International Conference on Information Systems: Building a Better World Through Information Systems, ICIS, Auckland, New Zealand, 14–17 December 2014. [Google Scholar]
- Srivastava, D.P.; Anand, O.; Rakshit, A. Assessment, Implication, and Analysis of Online Consumer Reviews: A Literature Review. Pac. Asia J. Assoc. Inf. Syst. 2017, 9, 43–73. [Google Scholar] [CrossRef]
- Lak, P.; Turetken, O. The Impact of Sentiment Analysis Output on Decision Outcomes: An Empirical Evaluation. AIS Trans. Hum. Comput. Interact. 2017, 9, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Moravec, P.L.; Kim, A.; Dennis, A.R. Flagging fake news: System 1 vs. System 2. In Proceedings of the International Conference on Information Systems (ICIS 2018), San Francisco, CA, USA, 13–16 December 2018; pp. 1–17. [Google Scholar]
- Abbott, R.J. Letters to the Editor: Gathering of Misleading Data with Little Regard for Privacy. Commun. ACM 1968, 11, 377–378. [Google Scholar] [CrossRef]
- Loftus, E. Reacting to blatantly contradictory information. Mem. Cogn. 1979, 7, 368–374. [Google Scholar] [CrossRef] [Green Version]
- Wessel, M.; Thies, F.; Benlian, A. A Lie Never Lives to be Old: The Effects of Fake Social Information on Consumer Decision-Making in Crowdfunding. In Proceedings of the European Conference on Information Systems, Münster, Germany, 26–29 May 2015. [Google Scholar]
- Allcott, H.; Gentzkow, M. Social Media and Fake News in the 2016 Election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef] [Green Version]
- Rosenberg, S.A.; Elbaum, B.; Rosenberg, C.R.; Kellar-Guenther, Y.; McManus, B.M. From Flawed Design to Misleading Information: The U.S. Department of Education’s Early Intervention Child Outcomes Evaluation. Am. J. Eval. 2018, 39, 350–363. [Google Scholar] [CrossRef]
- Bianchini, C.; Truccolo, I.; Bidoli, E.; Mazzocut, M. Avoiding misleading information: A study of complementary medicine online information for cancer patients. Libr. Inf. Sci. Res. 2019, 41, 67–77. [Google Scholar] [CrossRef]
- Commision, E. Tackling Online Disinformation. Available online: https://digital-strategy.ec.europa.eu/en/policies/online-disinformation (accessed on 9 May 2021).
- UNESCO. Fake News: Disinformation in Media. Available online: https://en.unesco.org/news/unesco-published-handbook-fake-news-and-disinformation-media (accessed on 9 May 2021).
- Hou, R.; Pérez-Rosas, V.; Loeb, S.; Mihalcea, R. Towards Automatic Detection of Misinformation in Online Medical Videos. In Proceedings of the 2019 International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019; pp. 235–243. [Google Scholar] [CrossRef] [Green Version]
- Bautista, J.R.; Zhang, Y.; Gwizdka, J. Healthcare professionals’ acts of correcting health misinformation on social media. Int. J. Med. Inform. 2021, 148, 104375. [Google Scholar] [CrossRef]
- Suarez-Lledo, V.; Alvarez-Galvez, J. Prevalence of Health Misinformation on Social Media: Systematic Review. J. Med. Internet Res. 2021, 23, e17187. [Google Scholar] [CrossRef] [PubMed]
- Van Bavel, J.; Boggio, P.; Capraro, V.; Cichocka, A.; Cikara, M.; Crockett, M.; Crum, A.; Douglas, K.; Druckman, J.; Drury, J.; et al. Using social and behavioural science to support COVID-19 pandemic response. Nat. Hum. Behav. 2020, 460–471. [Google Scholar] [CrossRef]
- Venkatesan, S.; Han, W.; Kisekka, V.; Sharman, R.; Kudumula, V.; Jaswal, H.S. Misinformation in Online Health Communities. In Proceedings of the Eighth Pre-ICIS Workshop on Information Security and Privacy, Milano, Italy, 14 December 2013. [Google Scholar]
- Chou, W.S.; Sciences, P.; Cancer, N.; Oh, A.; Sciences, P.; Cancer, N.; Klein, W.M.P.; Sciences, P.; Cancer, N. The Persistence and Peril of Misinformation. Am. Sci. 2017, 372. [Google Scholar] [CrossRef]
- Li, Y.J.; Cheung, C.M.; Shen, X.L.; Lee, M.K. Health Misinformation on Social Media: A Literature Review. In Proceedings of the 23rd Pacific Asia Conference on Information Systems: Secure ICT Platform for the 4th Industrial Revolution, PACIS, Xi’an, China, 8–12 July 2019; Volume 194. [Google Scholar]
- Coronavirus DISEASE (COVID-19) Pandemic. Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019 (accessed on 20 March 2021).
- Munich Security Conference. Available online: https://www.who.int/director-general/speeches/detail/munich-security-conference (accessed on 20 February 2021).
- Fell, L. Trust and COVID-19: Implications for Interpersonal, Workplace, Institutional, and Information-Based Trust. Digit. Gov. Res. Pract. 2020, 2. [Google Scholar] [CrossRef]
- Bode, L.; Vraga, E. See Something, Say Something: Correction of Global Health Misinformation on Social Media. Health Commun. 2017, 33, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Gu, R.; Li, M.X. Investigating the Psychological Mechanism of Individuals’ Health Misinformation Dissemination on Social Media. Available online: https://scholars.hkbu.edu.hk/en/publications/investigating-the-psychological-mechanism-of-individuals-health-m (accessed on 19 August 2021).
- Swire-Thompson, B.; Lazer, D. Public Health and Online Misinformation: Challenges and Recommendations. Annu. Rev. Public Health 2020, 41, 433–451. [Google Scholar] [CrossRef] [Green Version]
- Ghenai, A. Health Misinformation in Search and Social Media. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’17), Tokyo, Japan, 7–11 August 2017; Association for Computing Machinery: New York, NY, USA, 2017; p. 1371. [Google Scholar] [CrossRef] [Green Version]
- Khan, T.; Michalas, A.; Akhunzada, A. Fake news outbreak 2021: Can we stop the viral spread? J. Netw. Comput. Appl. 2021, 190, 103112. [Google Scholar] [CrossRef]
- Apuke, O.D.; Omar, B. Social media affordances and information abundance: Enabling fake news sharing during the COVID-19 health crisis. Health Inform. J. 2021, 27, 14604582211021470. [Google Scholar] [CrossRef]
- Southwell, B.; Niederdeppe, J.; Cappella, J.; Gaysynsky, A.; Kelley, D.; Oh, A.; Peterson, E.; Chou, W.Y. Misinformation as a Misunderstood Challenge to Public Health. Am. J. Prev. Med. 2019, 57. [Google Scholar] [CrossRef]
- Tasnim, S.; Hossain, M.M.; Mazumder, H. Impact of Rumors and Misinformation on COVID-19 in Social Media. J. Prev. Med. Public Health 2020, 53, 171–174. [Google Scholar] [CrossRef] [Green Version]
- Vraga, E.; Bode, L. Addressing COVID-19 Misinformation on Social Media Preemptively and Responsively. Emerg. Infect. Dis. 2021, 27. [Google Scholar] [CrossRef]
- Zhou, X.; Zafarani, R. A Survey of Fake News: Fundamental Theories, Detection Methods, and Opportunities. ACM Comput. Surv. 2020, 53. [Google Scholar] [CrossRef]
- Obiala, J.; Obiala, K.; Mańczak, M.; Owoc, J.; Olszewski, R. COVID-19 misinformation: Accuracy of articles about coronavirus prevention mostly shared on social media. Health Policy Technol. 2021, 10, 182–186. [Google Scholar] [CrossRef]
- Apuke, O.D.; Omar, B. Fake news and COVID-19: Modelling the predictors of fake news sharing among social media users. Telemat. Inform. 2021, 56, 101475. [Google Scholar] [CrossRef]
- Jonathan, G.M.; Jonathan, G.M. Exploring Social Media Use during a Public Health Emergency in Africa: The COVID-19 Pandemic. Available online: https://www.researchgate.net/publication/345877480_Exploring_Social_Media_Use_During_a_Public_Health_Emergency_in_Africa_The_COVID-19_Pandemic (accessed on 19 August 2021).
- Islam, A.N.; Laato, S.; Talukder, S.; Sutinen, E. Misinformation sharing and social media fatigue during COVID-19: An affordance and cognitive load perspective. Technol. Forecast. Soc. Chang. 2020, 159, 120201. [Google Scholar] [CrossRef] [PubMed]
- Bastani, P.; Bahrami, M. COVID-19 Related Misinformation on Social Media: A Qualitative Study from Iran (Preprint). J. Med. Internet Res. 2020. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, K.; Bhatia, S.; Bhattacharyya, S.; Platos, J.; Bag, R.; Hassanien, A.E. Sentiment Analysis of COVID-19 tweets by Deep Learning Classifiers—A study to show how popularity is affecting accuracy in social media. Appl. Soft Comput. 2020, 97, 106754. [Google Scholar] [CrossRef]
- Pennycook, G.; McPhetres, J.; Zhang, Y.; Lu, J.G.; Rand, D.G. Fighting COVID-19 Misinformation on Social Media: Experimental Evidence for a Scalable Accuracy-Nudge Intervention. Psychol. Sci. 2020, 31, 770–780. [Google Scholar] [CrossRef] [PubMed]
- Mejova, Y.; Kalimeri, K. COVID-19 on Facebook Ads: Competing Agendas around a Public Health Crisis. In Proceedings of the 3rd ACM SIGCAS Conference on Computing and Sustainable Societies, Guayaquil, Ecuador, 15–17 June 2020; pp. 22–31. [Google Scholar] [CrossRef]
- Dimitrov, D.; Baran, E.; Fafalios, P.; Yu, R.; Zhu, X.; Zloch, M.; Dietze, S. TweetsCOV19—A Knowledge Base of Semantically Annotated Tweets about the COVID-19 Pandemic. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management (CIKM’20), Online, 19–23 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 2991–2998. [Google Scholar] [CrossRef]
- Aphiwongsophon, S.; Chongstitvatana, P. Identifying misinformation on Twitter with a support vector machine. Eng. Appl. Sci. Res. 2020, 47, 306–312. [Google Scholar] [CrossRef]
- Deokate, S.B. Fake News Detection using Support Vector Machine learning Algorithm. Int. J. Res. Appl. Sci. Eng. Technol. (IJRASET) 2019. Available online: https://www.researchgate.net/publication/336465014_Fake_News_Detection_using_Support_Vector_Machine_learning_Algorithm (accessed on 19 August 2021).
- Ciprian-Gabriel, C.; Coca, G.; Iftene, A. Identifying Fake News on Twitter Using Naïve Bayes, Svm And Random Forest Distributed Algorithms. In Proceedings of the 13th Edition of the International Conference on Linguistic Resources and Tools for Processing Romanian Language (ConsILR-2018), Bucharest, Romania, 22–23 November 2018. [Google Scholar]
- Shmueli, G.; Bruce, P.C.; Gedeck, P.; Patel, N.R. Data Mining for Business Analytics: Concepts, Techniques and Applications in Python; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Kolbe, D.; Zhu, Q.; Pramanik, S. Efficient k-nearest neighbor searching in nonordered discrete data spaces. ACM Trans. Inf. Syst. (TOIS) 2010, 28, 1–33. [Google Scholar] [CrossRef]
- Cunningham, P.; Delany, S.J. k-Nearest Neighbour Classifiers-A Tutorial. ACM Comput. Surv. (CSUR) 2021, 54, 1–25. [Google Scholar] [CrossRef]
- Ali, M.; Jung, L.T.; Abdel-Aty, A.H.; Abubakar, M.Y.; Elhoseny, M.; Ali, I. Semantic-k-NN algorithm: An enhanced version of traditional k-NN algorithm. Expert Syst. Appl. 2020, 151, 113374. [Google Scholar] [CrossRef]
- Mokhtar, M.S.; Jusoh, Y.Y.; Admodisastro, N.; Pa, N.C.; Amruddin, A.Y. Fakebuster: Fake News Detection System Using Logistic Regression Technique In Machine Learning. Int. J. Eng. Adv. Technol. (IJEAT) 2019, 9, 2407–2410. [Google Scholar]
- Ogdol, J.M.G.; Samar, B.L.T.; Catarroja, C. Binary Logistic Regression based Classifier for Fake News. J. High. Educ. Res. Discip. 2018. Available online: http://www.nmsc.edu.ph/ojs/index.php/jherd/article/view/98 (accessed on 19 August 2021).
- Nada, F.; Khan, B.F.; Maryam, A.; Nooruz-Zuha; Ahmed, Z. Fake News Detection using Binary Logistic Regression. Int. Res. J. Eng. Technol. (IRJET) 2019, 8, 1705–1711. [Google Scholar]
- Bharti, P.; Bakshi, M.; Uthra, R. Fake News Detection Using Logistic Regression, Sentiment Analysis and Web Scraping. Int. J. Adv. Sci. Technol. 2020, 29, 1157–1167. [Google Scholar]
- Ghosh, A.; Sufian, A.; Sultana, F.; Chakrabarti, A.; De, D. Fundamental concepts of convolutional neural network. In Recent Trends and Advances in Artificial Intelligence and Internet of Things; Springer: Berlin/Heidelberg, Germany, 2020; pp. 519–567. [Google Scholar]
- Bai, L.; Yao, L.; Wang, X.; Kanhere, S.S.; Guo, B.; Yu, Z. Adversarial multi-view networks for activity recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2020, 4, 1–22. [Google Scholar] [CrossRef]
- Chen, J.; Yang, Y.t.; Hu, K.k.; Zheng, H.b.; Wang, Z. DAD-MCNN: DDoS attack detection via multi-channel CNN. In Proceedings of the 2019 11th International Conference on Machine Learning and Computing, Zhuhai, China, 22–24 February 2019; pp. 484–488. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2015, arXiv:abs/1409.0473. [Google Scholar]
- Ruchansky, N.; Seo, S.; Liu, Y. CSI: A Hybrid Deep Model for Fake News Detection. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management (CIKM’17), Singapore, 6–10 November 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 797–806. [Google Scholar] [CrossRef] [Green Version]
- Cui, L.; Wang, S.; Lee, D. SAME: Sentiment-Aware Multi-Modal Embedding for Detecting Fake News. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM ’19), Vancouver, BC, Canada, 27–30 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 41–48. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Cui, L.; Shu, K.; Wang, S.; Lee, D.; Liu, H. DEFEND: A System for Explainable Fake News Detection. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management (CIKM ’19), Beijing, China, 3–7 November 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 2961–2964. [Google Scholar] [CrossRef]
- Cui, L.; Lee, D. CoAID: COVID-19 Healthcare Misinformation Dataset. arXiv 2020, arXiv:2006.00885. [Google Scholar]
- Jamison, A.; Broniatowski, D.A.; Smith, M.C.; Parikh, K.S.; Malik, A.; Dredze, M.; Quinn, S.C. Adapting and extending a typology to identify vaccine misinformation on twitter. Am. J. Public Health 2020, 110, S331–S339. [Google Scholar] [CrossRef]
- Hartwig, K.; Reuter, C. TrustyTweet: An Indicator-based Browser-Plugin to Assist Users in Dealing with Fake News on Twitter. In Proceedings of the WI 2019, the 14th International Conference on Business Informatics, AIS eLibrary, Siegen, Germany, 23–27 February 2019; pp. 1844–1855. Available online: https://aisel.aisnet.org/wi2019/specialtrack01/papers/5/ (accessed on 10 April 2021).
- Memon, S.A.; Carley, K.M. Characterizing COVID-19 Misinformation Communities Using a Novel Twitter Dataset. arXiv 2020, arXiv:2008.00791. [Google Scholar]
- Shahi, G.; Dirkson, A.; Majchrzak, T.A. An Exploratory Study of COVID-19 Misinformation on Twitter. Online Soc. Netw. Media 2020, 22, 100104. [Google Scholar] [CrossRef] [PubMed]
- Singh, L.; Bansal, S.; Bode, L.; Budak, C.; Chi, G.; Kawintiranon, K.; Padden, C.; Vanarsdall, R.; Vraga, E.; Wang, Y. A first look at COVID-19 information and misinformation sharing on Twitter. arXiv 2020, arXiv:2003.13907. [Google Scholar]
- Alqurashi, S.; Hamawi, B.; Alashaikh, A.; Alhindi, A.; Alanazi, E. Eating Garlic Prevents COVID-19 Infection: Detecting Misinformation on the Arabic Content of Twitter. arXiv 2021, arXiv:2101.05626. [Google Scholar]
- Girgis, S.; Amer, E.; Gadallah, M. Deep Learning Algorithms for Detecting Fake News in Online Text. In Proceedings of the 2018 13th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, 18–19 December 2018; pp. 93–97. [Google Scholar] [CrossRef]
- Hossain, T.; Logan IV, R.L.; Ugarte, A.; Matsubara, Y.; Young, S.; Singh, S. COVIDLies: Detecting COVID-19 Misinformation on Social Media. Available online: https://openreview.net/pdf?id=FCna-s-ZaIE (accessed on 19 August 2021).
- Shahi, G.K.; Nandini, D. FakeCovid—A Multilingual Cross-domain Fact Check News Dataset for COVID-19. In Proceedings of the 14th International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 8–11 June 2020. [Google Scholar]
- Zhou, X.; Mulay, A.; Ferrara, E.; Zafarani, R. ReCOVery: A Multimodal Repository for COVID-19 News Credibility Research. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management (CIKM 20), Turin, Italy, 22–26 October 2018; Association for Computing Machinery: New York, NY, USA, 2020; pp. 3205–3212. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M.N. A Review on Evaluation Metrics for Data Classification Evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar] [CrossRef]
- Ahmad, I.; Yousaf, M.; Yousaf, S.; Ahmad, M.O. Fake News Detection Using Machine Learning Ensemble Methods. Complexity 2020, 2020, 8885861. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Equation | Explanation |
|---|---|---|
| Accuracy (acc) | The fraction of observations that are correctly classified. | |
| Precision (P) | The fraction of correctly classified positive classes from the set of observations that were predicted to be positive. | |
| Recall (R) | The fraction of correctly classified positive classes from the set of observations that were classified correctly. | |
| F measure | The harmonic mean of precision and recall metrics. |
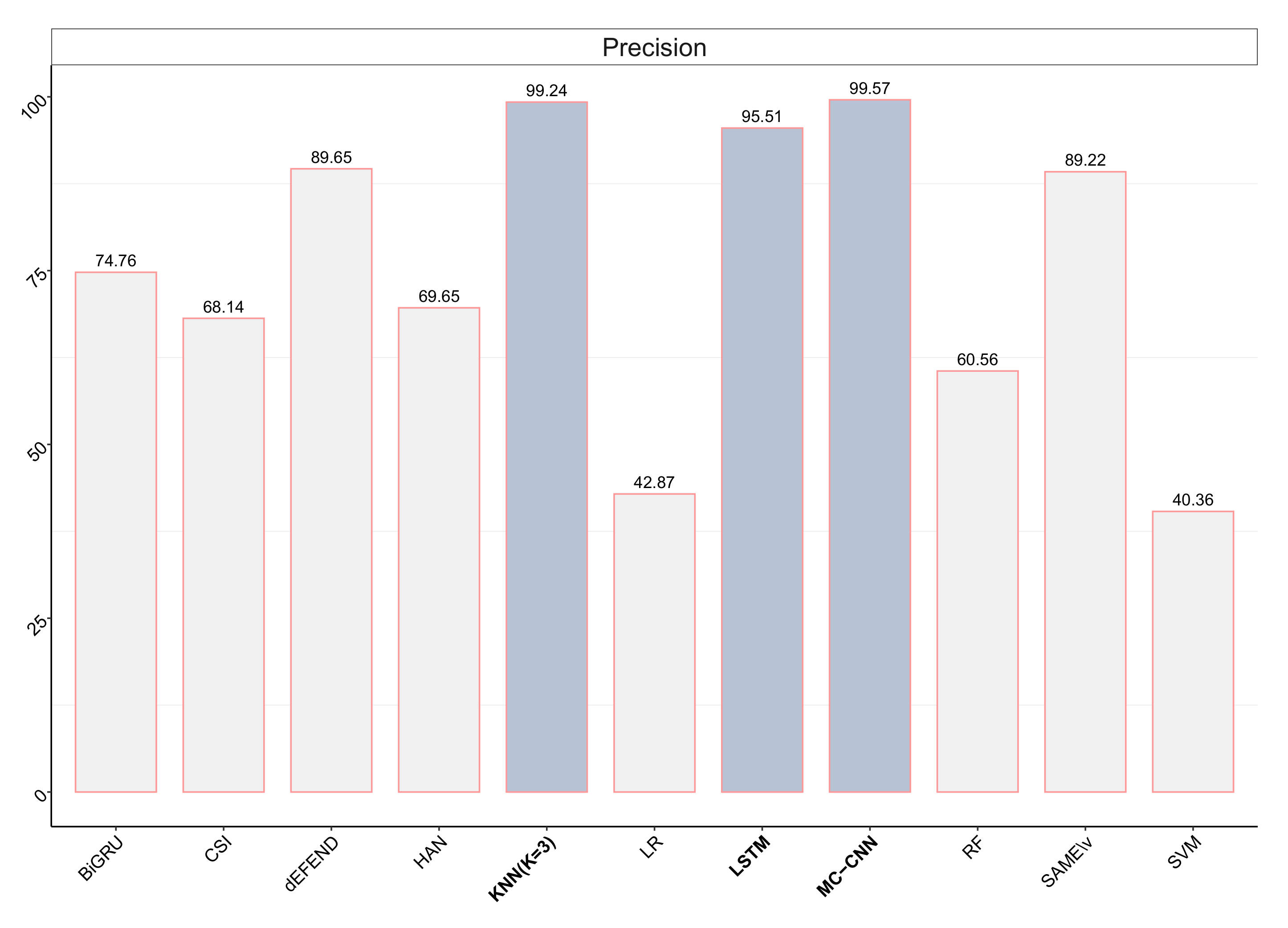
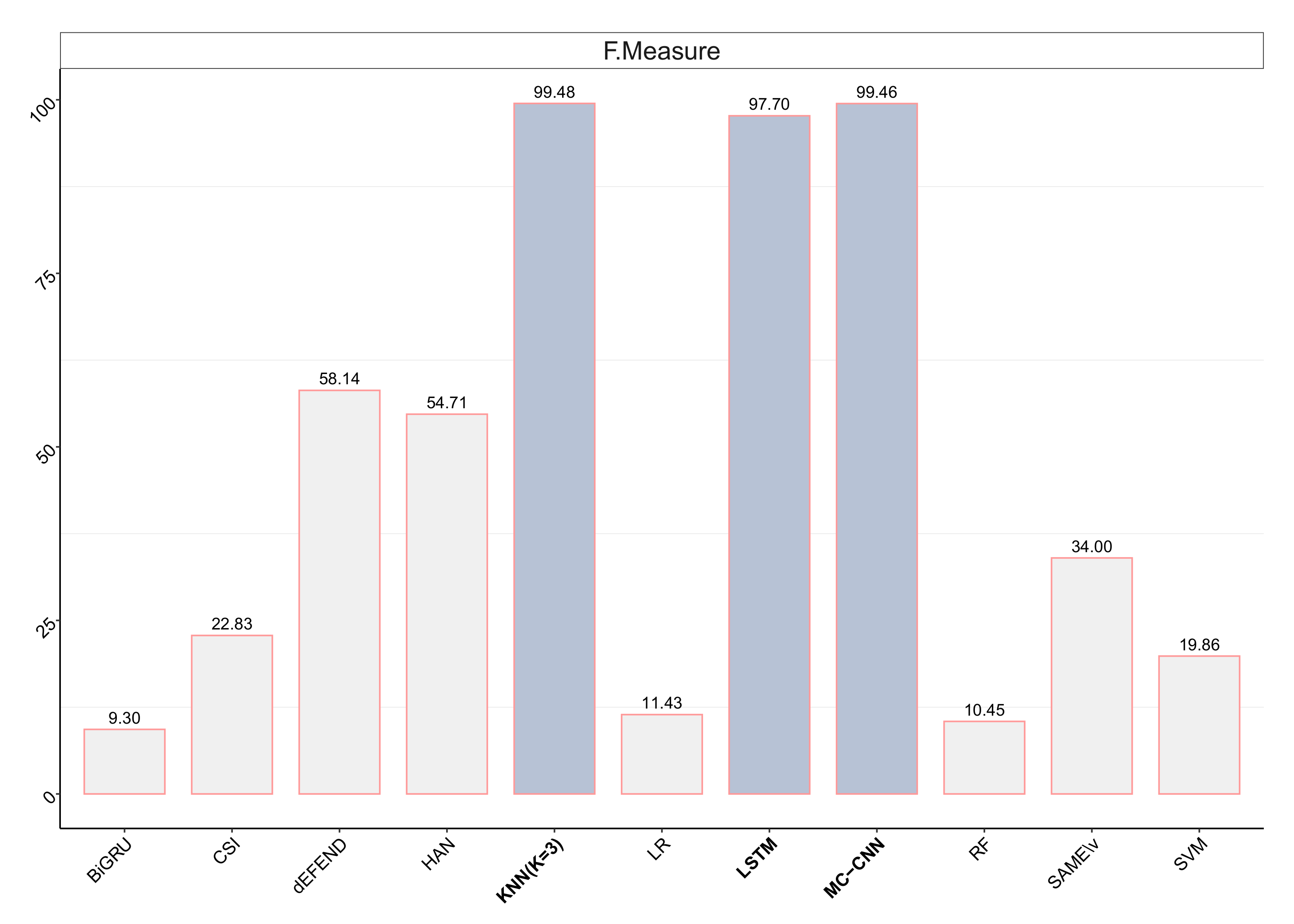
| Classification Models | PU-AUC (%) | Precision (%) | Recall (%) | F Measure (%) | Accuracy (%) |
|---|---|---|---|---|---|
| LSTM | 97.76 | 95.51 | 99.99 | 97.7 | 95.51 |
| MC-CNN | 99.9 | 99.57 | 99.35 | 99.46 | 98.96 |
| KNN (K = 3) | 99.3 | 99.24 | 99.72 | 99.48 | 99.03 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alenezi, M.N.; Alqenaei, Z.M. Machine Learning in Detecting COVID-19 Misinformation on Twitter. Future Internet 2021, 13, 244. https://doi.org/10.3390/fi13100244
Alenezi MN, Alqenaei ZM. Machine Learning in Detecting COVID-19 Misinformation on Twitter. Future Internet. 2021; 13(10):244. https://doi.org/10.3390/fi13100244
Chicago/Turabian StyleAlenezi, Mohammed N., and Zainab M. Alqenaei. 2021. "Machine Learning in Detecting COVID-19 Misinformation on Twitter" Future Internet 13, no. 10: 244. https://doi.org/10.3390/fi13100244
APA StyleAlenezi, M. N., & Alqenaei, Z. M. (2021). Machine Learning in Detecting COVID-19 Misinformation on Twitter. Future Internet, 13(10), 244. https://doi.org/10.3390/fi13100244