
Person Re-Identification by Low-Dimensional Features and Metric Learning



Abstract
:1. Introduction
- Based on the prior knowledge of humans, we designed a color feature with spatial information to solve the problem of person re-identification. Compared with the common method of extracting deep features using convolutional neural networks, the biggest advantage of the handcraft features we designed is that it consumes less computing resources during extraction, has better interpretability, and is less affected by image resolution.
- Att-BLSTM is used to obtain the contextual semantic relationship in the color features, and due to the attention mechanism, the model can automatically focus on the features that are decisive for the task. The performance of the model and its generalization ability can be greatly improved.
- The combination of hand-crafted features and the deep learning in person re-identification task not only greatly reduces the number of parameters and the resource consumption of training models, but also gives the model better interpretability, and the performance of the model can still reach an advanced level.
2. Related Works
2.1. Person Re-Identification
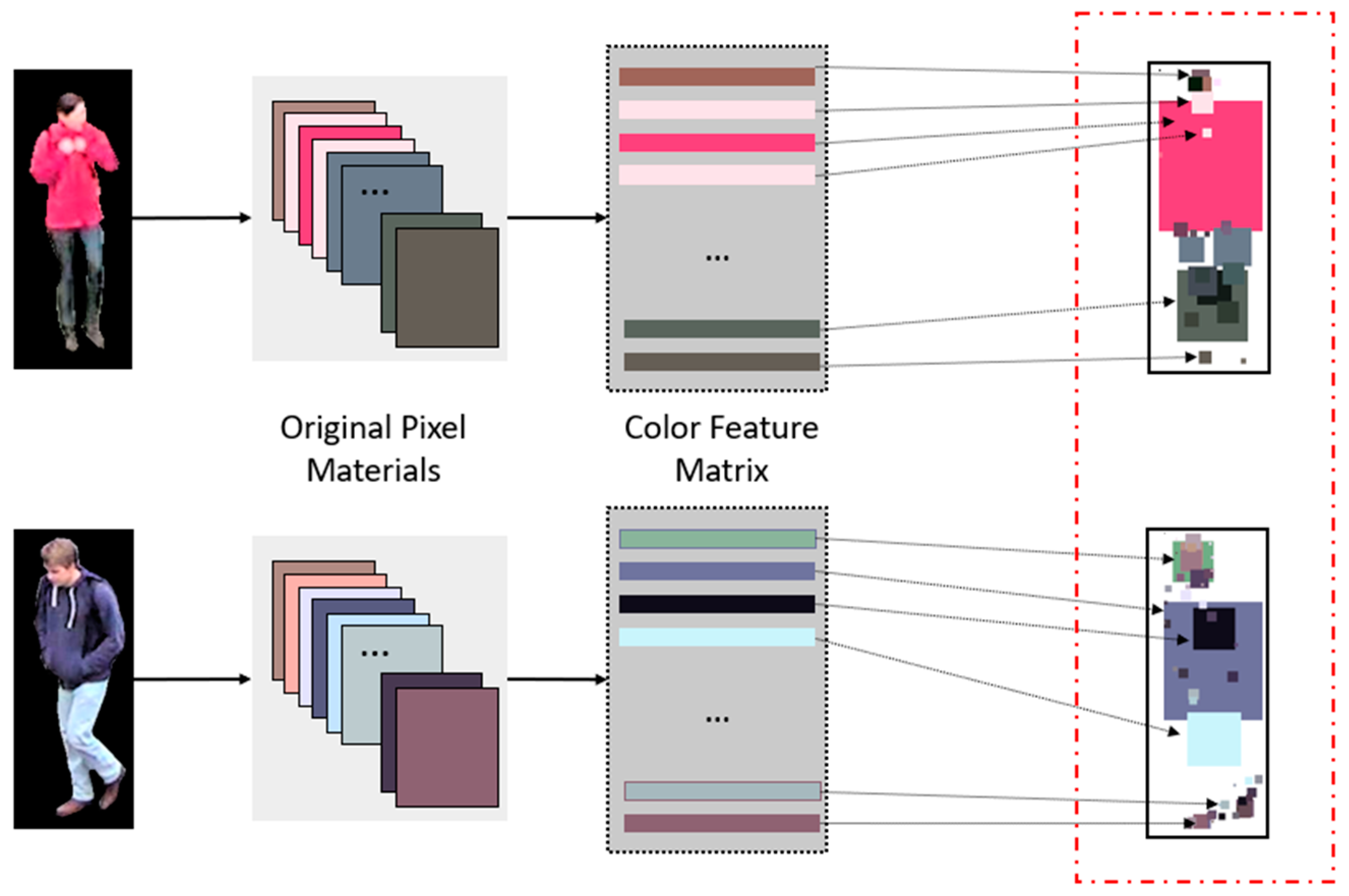
2.2. Color Feature
2.3. Recurrent Neural Network
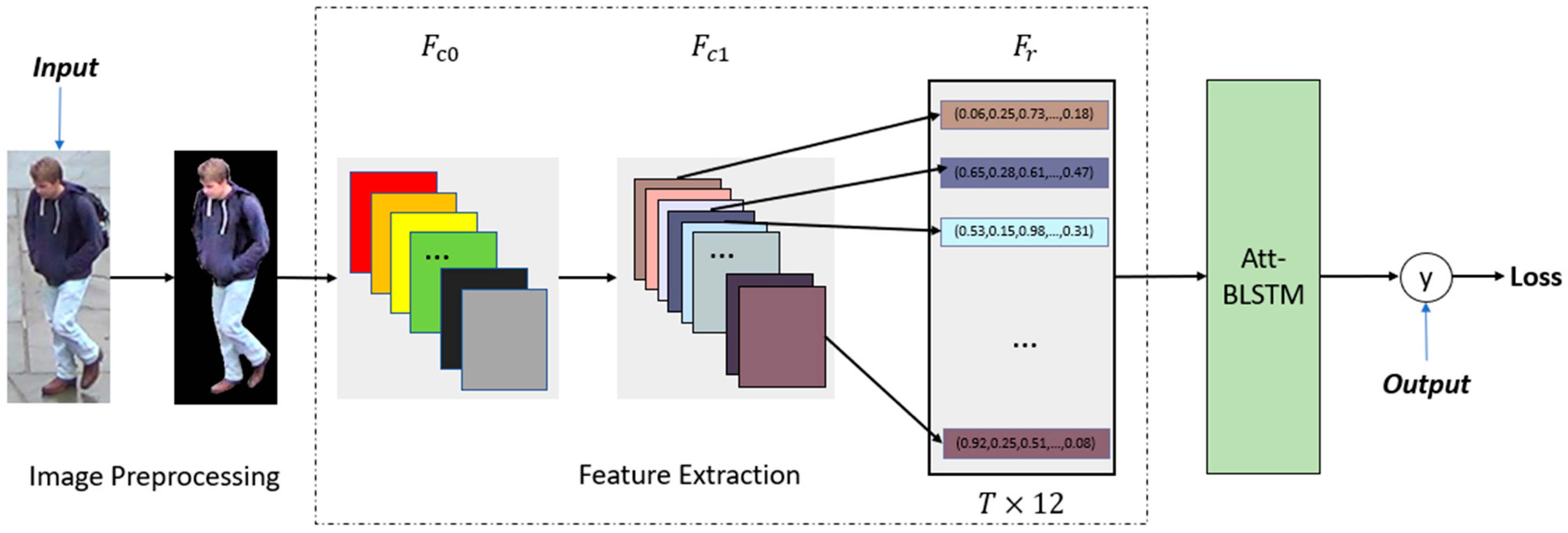
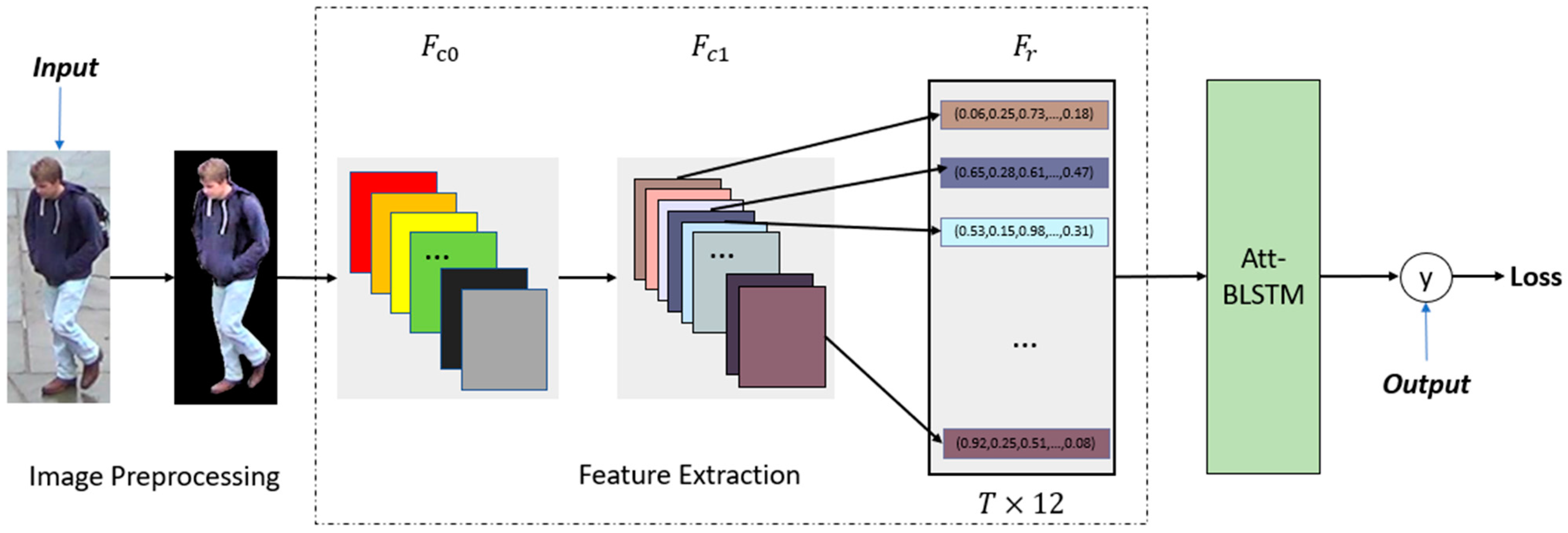
3. The Proposed Method
3.1. Image Preprocessing
3.2. Hand-Crafted Feature Extraction
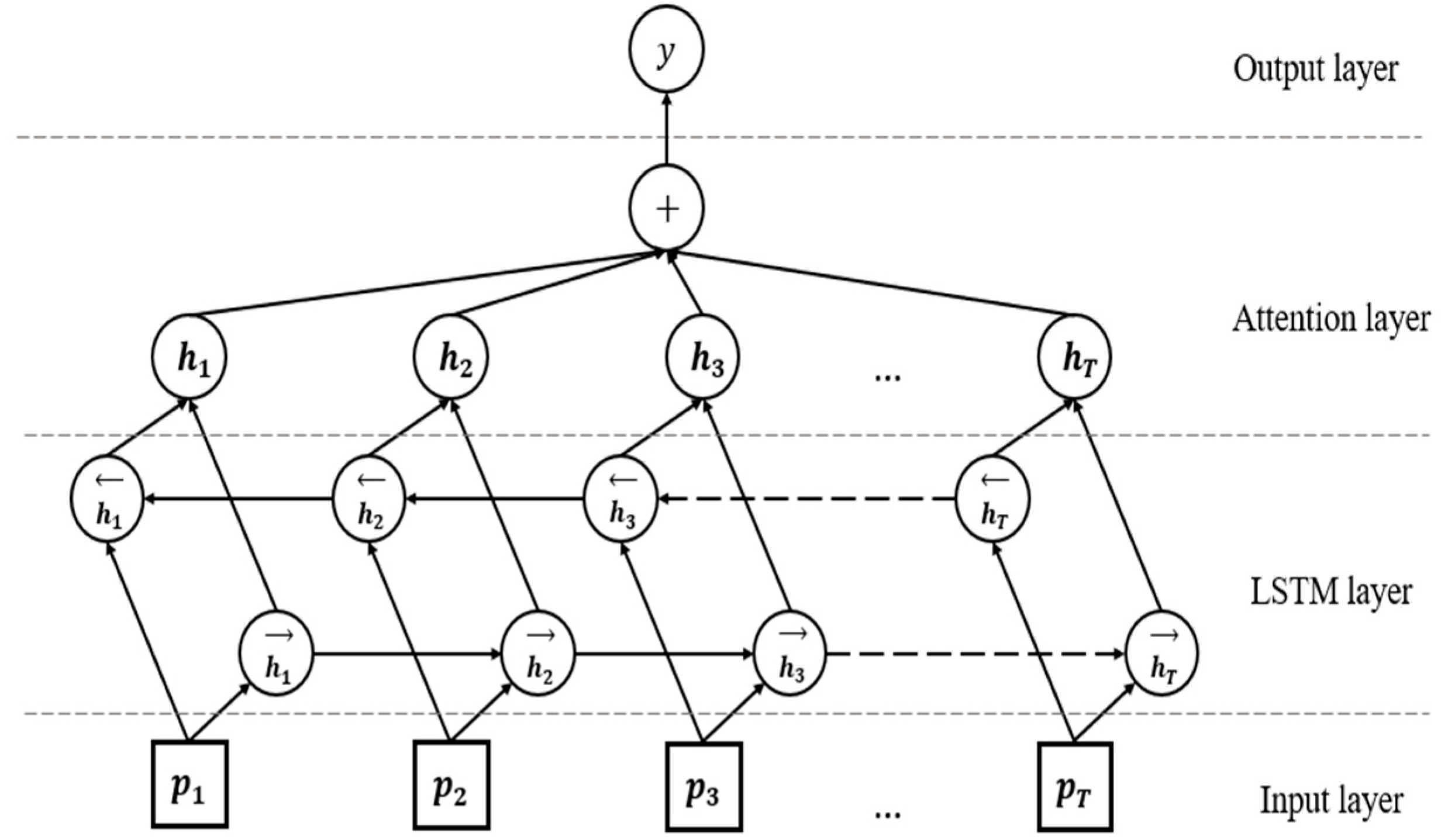
3.3. Att-BLSTM
3.4. Loss Function
4. Experiments and Discussion
4.1. Datasets and Evaluation Protocol
4.1.1. DukeMTMC-reID
4.1.2. Market-1501
4.1.3. Evaluation Protocol
4.2. Implementation Details
4.3. Comparisons with Traditional Methods
4.4. Comparisons with the State-of-the-Arts
4.5. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bazzani, L.; Cristani, M.; Murino, V. Symmetry-driven accumulation of local features for human characterization and re-identification. Comput. Vis. Image Underst. 2013, 117, 130–144. [Google Scholar] [CrossRef]
- Zeng, M.; Wu, Z.; Chang, T.; Lei, Z.; Lei, H. Efficient Person Re-identification by Hybrid Spatiogram and Covariance Descriptor. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zhao, R.; Ouyang, W.; Wang, X. Person re-identification by saliency learning. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 356–370. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liao, S.; Yang, H.; Zhu, X.; Li, S.Z. Person re-identification by Local Maximal Occurrence representation and metric learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Layne, R.; Hospedales, T.M.; Gong, S. Person Re-identification by Attributes. BMVC 2012, 2, 8. [Google Scholar]
- Varior, R.R.; Haloi, M.; Wang, G. Gated Siamese Convolutional Neural Network Architecture for Human Re-Identification. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Lin, W.; Shen, C.; Hengel, A. Personnet: Person re-identification with deep convolutional neural networks. arXiv 2016, arXiv:1601.07255. [Google Scholar]
- Xuan, Z.; Hao, L.; Xing, F.; Xiang, W.; Jian, S. Alignedreid: Surpassing human-level performance in person re-identification. arXiv 2017, arXiv:1711.08184. [Google Scholar]
- Wang, G.A.; Yang, S.; Liu, H.; Wang, Z.; Yang, Y.; Wang, S.; Yu, G.; Zhou, E.; Sun, J. High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Jing, X.; Rui, Z.; Feng, Z.; Wang, H.; Ouyang, W. Attention-aware compositional network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Cai, H.; Wang, Z.; Cheng, J. Multi-Scale Body-Part Mask Guided Attention for Person Re-Identification. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Leng, Q.; Ye, M.; Tian, Q. A survey of open-world person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1092–1108. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Hoi, S. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1. [Google Scholar] [CrossRef] [PubMed]
- Ma, B.; Yu, S.; Jurie, F. Covariance descriptor based on bio-inspired features for person re-identification and face verification. Image Vis. Comput. 2014, 32, 379–390. [Google Scholar] [CrossRef] [Green Version]
- Matsukawa, T.; Okabe, T.; Suzuki, E.; Sato, Y. Hierarchical Gaussian Descriptor for Person Re-identification. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ma, L.; Yang, X.; Tao, D. Person re-identification over camera networks using multi-task distance metric learning. IEEE Trans. Image Process. 2014, 23, 3656–3670. [Google Scholar] [PubMed]
- Zheng, Z.; Liang, Z.; Yi, Y. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), IEEE Computer Society, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Qian, X.; Fu, Y.; Jiang, Y.G.; Xiang, T.; Xue, X. Multi-scale Deep Learning Architectures for Person Re-identification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Swaintand, M.J.; Ballard, D.H. Indexing Via Color Histograms Object Identification via Histogram; Springer: Berlin/Heidelberg, Germany, 1990. [Google Scholar]
- Hu, H.M.; Fang, W.; Zeng, G.; Hu, Z.; Li, B. A person re-identification algorithm based on pyramid color topology feature. Multimed. Tools Appl. 2016, 76, 26633–26646. [Google Scholar] [CrossRef]
- Li, Y.; Tian, Z. Person Re-Identification Based on Color and Texture Feature Fusion; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Geng, Y.; Hu, H.M.; Zeng, G.; Zheng, J. A person re-identification algorithm by exploiting region-based feature salience. J. Vis. Commun. Image Represent. 2015, 29, 89–102. [Google Scholar] [CrossRef]
- Peng, Z.; Wei, S.; Tian, J.; Qi, Z.; Bo, X. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics 2016, Berlin, Germany, 7–12 August 2016; Volume 2. [Google Scholar]
- Fu, Y.; Wei, Y.; Zhou, Y.; Shi, H.; Huang, G.; Wang, X.; Yao, Z.; Huang, T. Horizontal pyramid matching for person re-identification. Proc. AAAI Conf. Artif. Intell. 2018, 33, 8295–8302. [Google Scholar] [CrossRef]
- Stewart, R.; Andriluka, M.; Ng, A.Y. End-to-end people detection in crowded scenes. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Neculoiu, P.; Versteegh, M.; Rotaru, M. Learning Text Similarity with Siamese Recurrent Networks. In Proceedings of the Repl4NLP Workshop at ACL2016, Berlin, Germany, 11 August 2016. [Google Scholar]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Guler, R.A.; Trigeorgis, G.; Antonakos, E.; Snape, P.; Kokkinos, I. Densereg: Fully convolutional dense shape regression in-the-wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xiang, L.; Zheng, W.S.; Wang, X.; Tao, X.; Gong, S. Multi-Scale Learning for Low-Resolution Person Re-Identification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Khan, F.S.; Rao, M.A.; Weijer, J.; Felsberg, M.; Laaksonen, J. Deep Semantic Pyramids for Human Attributes and Action Recognition. In Proceedings of the Scandinavian Conference on Image Analysis, Copenhagen, Denmark, 15–17 June 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Srivastava, D.; Bakthula, R.; Agarwal, S. Image classification using surf and bag of lbp features constructed by clustering with fixed centers. Multimed. Tools Appl. 2018, 78, 14129–14153. [Google Scholar] [CrossRef]
- Eitz, M.; Hildebrand, K.; Boubekeur, T.; Alexa, M. Sketch-based image retrieval: Benchmark and bag-of-features descriptors. IEEE Trans. Vis. Comput. Graph. 2011, 17, 1624–1636. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Zhu, X.; Gong, S. Person Re-identification by Deep Learning Multi-scale Representations. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Zheng, L.; Shen, L.; Lu, T.; Wang, S.; Qi, T. Scalable Person Re-identification: A Benchmark. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Kostinger, M.; Hirzer, M.; Wohlhart, P.; Roth, P.M.; Bischof, H. Large scale metric learning from equivalence constraints. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2288–2295. [Google Scholar]
- Song, C.; Yan, H.; Ouyang, W.; Liang, W. Mask-Guided Contrastive Attention Model for Person Re-identification. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious Attention Network for Person Re-Identification. In Proceedings of the 2018 IEEE Con-ference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Liu, C.; Chang, X.; Shen, Y.D. Unity Style Transfer for Person Re-Identification. In Proceedings of the 2020 IEEE/CVF Con-ference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Time | Images | Resolution |
|---|---|---|---|
| VIPeR | 2007 | 1264 | 128 × 48 |
| CUHK01 | 2012 | 3884 | 160 × 60 |
| Market-1501 | 2015 | 32,668 | 128 × 64 |
| MARS | 2016 | 1,191,003 | 256 × 128 |
| DukeMT-MCreID | 2017 | 36,441 | vary |
| Methods | Rank-1 | mAP |
|---|---|---|
| gBiCov [14] | 8.28 | 2.33 |
| LOMO [4] | 43.79 | 22.22 |
| BoW | 34.38 | 14.10 |
| BoW+KISSME [38] | 44.4 | 20.8 |
| ours | 95.7 | 88.1 |
| Methods | Million Parameters |
|---|---|
| AlexNet [40] | 60 |
| VGG16 [41] | 138 |
| GoogleNet [42] | 6.8 |
| Inception-v3 [43] | 23.2 |
| ResNet50 [44] | 25.5 |
| ours | 0.24 |
| Methods | Market-1501 | DukeMTMC-reID | ||
|---|---|---|---|---|
| Rank-1 | mAP | Rank-1 | mAP | |
| ACCN [10] | 85.9 | 66.9 | 76.8 | 59.3 |
| MSCAN [39] | 83.6 | 74.3 | - | - |
| MultiScale [3] | 88.9 | 73.1 | 79.2 | 60.6 |
| HA-CNN [45] | 91.2 | 75.7 | 80.5 | 63.8 |
| AlignedReID [8] | 91.0 | 79.4 | ||
| HPM [24] | 94.2 | 82.7 | 86.4 | 74.6 |
| MMGA [11] | 95.0 | 87.2 | 89.5 | 78.1 |
| UnityStyle+RE [46] | 93.2 | 89.3 | 85.9 | 82.3 |
| ours | 95.7 | 88.1 | 85.3 | 78.4 |
| Index | Methods | Rank-1 | mAP |
|---|---|---|---|
| 1 | without RSI | 38.6 | 18.7 |
| 2 | with RSI | 47.2 | 25.1 |
| 3 | without RSI + Att-BLSTM | 87.3 | 73.6 |
| 4 | with RSI + Att-BLSTM | 95.7 | 88.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Xu, H.; Li, Y.; Bian, M. Person Re-Identification by Low-Dimensional Features and Metric Learning. Future Internet 2021, 13, 289. https://doi.org/10.3390/fi13110289
Chen X, Xu H, Li Y, Bian M. Person Re-Identification by Low-Dimensional Features and Metric Learning. Future Internet. 2021; 13(11):289. https://doi.org/10.3390/fi13110289
Chicago/Turabian StyleChen, Xingyuan, Huahu Xu, Yang Li, and Minjie Bian. 2021. "Person Re-Identification by Low-Dimensional Features and Metric Learning" Future Internet 13, no. 11: 289. https://doi.org/10.3390/fi13110289
APA StyleChen, X., Xu, H., Li, Y., & Bian, M. (2021). Person Re-Identification by Low-Dimensional Features and Metric Learning. Future Internet, 13(11), 289. https://doi.org/10.3390/fi13110289