1. Introduction
A researcher’s professional career is heavily dependent on the visibility of, and the recognition afforded by, their scholarly output. The number of citations received and the corresponding indexes associated with this variable, in particular the h-index, are typically the most widely used metrics employed in official processes of accreditation before appropriate academic boards or commissions. Indeed, the need to be cited, combined with the exponential increase in world bibliographic output, means that researchers today have to promote their own articles as the final step in the complex process of publishing their research findings. This promotion of their research output usually also implies building their personal academic brand [
1,
2], including the creation of complementary content that extends well beyond traditional scholarly articles for specialized publications or papers for conferences.
Among the actions researchers can take to promote both their personal brand and scientific output are mentioning their articles in academic and non-academic social networks, creating a professional blog with complementary content (videos, presentations, PDFs), creating profiles on a range of platforms from ORCID, Google Scholar Citation, and ResearcherID to Mendeley, depositing documents in open access repositories and optimizing articles so that they command a good position in search engines, especially Google Scholar. Indeed, the vast majority of Internet users do not look beyond the second or third page of results [
3], which means for a document to be found easily it has to be optimized to ensure it appears towards the top of the first page.
Search results are ranked according to relevance, a value automatically calculated by search engines. Moreover, this ranking is usually established as the default order, because other forms of sorting—for example, by title or by date—are considered less significant for most search intentions (although these other forms of sorting are often available). Relevance is calculated using an algorithm that takes into account a range of factors, which means that for each search engine, relevance will differ to some degree, given that it is being defined by a distinct algorithm in each case.
Search engine optimization (SEO) [
4,
5] is, today, a well-established discipline, the goal of which is to highlight the quality of web pages and so improve their position in the results pages. This goal should not be achieved by fraudulent means, but depends rather on knowing how the algorithms that determine relevance operate, identifying the factors taken into account and, finally, optimizing these factors in one’s documents. However, Google Scholar is not always able to detect attempts at manipulation [
6,
7].
Today, there is a huge community of SEO experts and companies that dedicate their efforts to analyzing and discussing Google’s relevance ranking algorithm. Via blogs [
8,
9,
10,
11], online publications [
12,
13,
14], and books [
15,
16,
17] they advise designers and webmasters as to how they can optimize their websites so that they are easily indexed and can occupy the highest rankings in the results pages.
Google’s relevance algorithm is based on more than 200 factors [
18] and include the number of links received, the keywords and related terms in the title and other significant areas of the document, the download speed of the server on which the page is hosted, the length of the text, the user experience, the mobile-first design, the semantic tagging, the age of the domain, etc. Google has never released complete information about all these factors or the exact weighting attached to each; the company only provides general, incomplete information in order to avoid spam. Indeed, if all the details of how the algorithm works were known, then poor quality documents could be placed at the top of the results page.
This “black box” policy has led SEO professionals to conduct reverse engineering research in an effort to identify the specific factors involved in relevance ranking. Thus, they analyze the search results in order to infer how the algorithm works. However, it is a complicated process in which many factors intervene and it is not easy to draw any conclusive results.
In recent years, this ecosystem of research concerned with algorithms and the subsequent publication of recommendations has been extended to Google Scholar and academic articles. On a much smaller scale, reverse engineering research has been applied to Google Scholar [
19,
20,
21,
22,
23,
24,
25] and blogs [
26,
27,
28,
29,
30], university library guidelines [
31,
32,
33,
34] and the authors’ services of the publishers of academic journals [
35,
36,
37,
38,
39,
40] offer their recommendations as to how to optimize articles so that they appear at the top of the rankings of Google Scholar’s results pages. This SEO applied to academic search engines has been called academic search engine optimization or ASEO [
20,
22,
41,
42,
43].
This research community is still in its infancy both in terms of the quantity and quality of its output; moreover, the recommendations given for Google Scholar are often contaminated by research findings for Google. In fact, they are two quite distinct algorithms that operate on two quite distinct types of document in two very different environments. Indeed, as far as the ranking algorithm is concerned, academic documents have at least four major characteristics that clearly distinguish them from web pages: most are in PDF (and not HTML) format; they contain links based on bibliographic citations with other academic documents (not hyperlinks); once published, they are not modified; and, usually, author metadata and the date of publication are clearly identified.
Promoting a personal academic brand and the visibility of web pages, blogs, videos and other complementary content depend to a large extent on Google positioning. But the visibility of academic articles or conference papers is determined by their optimization for Google Scholar. These differences need to be clarified, while it is necessary to further our understanding of Google Scholar’s relevance ranking algorithm, which is not so well known and widely analyzed as Google’s general search algorithm.
The aim of this study is to do just that and, more specifically, here, because of its far-reaching implications, we seek to determine whether the language in which a document is written is a key positioning factor. In this regard, no previous study, to the best of our knowledge, has attempted to find a relationship between positioning and language, be it for Google Scholar or for the general Google search engine.
Normally, language plays no role as a ranking factor in keyword searches, given that the language of the search word itself determines the language of the documents retrieved. If the documents are written in the same language, this factor is overridden. Language only intervenes in those few cases of keywords with the same spelling in different languages that generate multilingual lists of results. In contrast, searches by author or year are conducted independently of language and always provide what we shall refer to henceforth as multilingual results (or searches).
When searches are multilingual, that is, when results are provided in different languages for the same search, the language of the documents can be a decisive factor if it can be shown that this conditions ranking. Thus, our primary research question here is the following: In multilingual searches, is the language in which a document is written a factor in Google Scholar’s ranking algorithm?
Our hypothesis is that Google Scholar favors the English language in multilingual search results. As a result, documents in other languages have fewer possibilities of being placed at the top of the rankings for the sole reason that they are not published in English.
In the following section, we discuss related studies in the literature, before moving on to present the applied research methodology and the method used to select our sample. Next, we analyze the results obtained from our statistical data and from observation of our scatter plots. The limitations of the study are discussed and new lines of research are proposed. Finally, in the conclusions, the repercussions of our findings are highlighted, both for searches and for the optimization of positioning in Google Scholar.
2. Prior Studies
Google Scholar has been the subject of numerous studies, aimed, above all, at assessing its quality [
44,
45,
46,
47,
48,
49,
50,
51,
52,
53] and search effectiveness [
45,
54], determining whether it is a suitable tool for conducting bibliometric studies [
55,
56,
57,
58,
59,
60,
61] and evaluating author impact using the h-index [
25,
56,
62,
63,
64,
65,
66,
67].
In contrast, few studies have specifically examined how the Google Scholar ranking algorithm works [
19,
20,
21,
22]. One of the reasons for this is probably the erroneous belief that Google Scholar uses the same or a very similar algorithm to the one used by the general Google search engine. However, the few studies of ranking by relevance in Google Scholar that have been conducted [
19,
20,
21,
22,
23,
24,
25] conclude that it is a specific algorithm, adapted to the particular characteristics of scholarly documents; nevertheless, some ranking factors may be the same in both cases, such as the weight attached to keywords in the title [
19]. Other factors, though, are clearly specific, such as the number of citations received, which is unique to Google Scholar [
21,
25].
Moreover, the frequency of keywords in the text of the article does not appear to be a factor that the Google Scholar algorithm takes into account [
19]. Yet, there is evidence that the date of publication is of relevance, given that according to Beel and Gipp [
19] older articles have a higher ranking than more recent publications.
A further factor identified by various authors is that the search term has to coincide exactly with a term in the documents retrieved and, moreover, that Google Scholar does not expand its searches through synonyms of keywords in the same way that Google does [
68,
69].
Where there is greater consensus is in attributing considerable weight to the number of citations received in Google Scholar’s calculation of ranking by relevance [
19,
23,
24,
25]. This is hardly surprising, given that Google Scholar is a bibliographic database and traditionally tools of this type use citations received as a means for sorting their results page.
3. Methodology
As indicated, the aim of this study is to further our understanding of the Google Scholar relevance ranking algorithm. We are particularly interested in determining whether the language in which a document is written affects its position on the results page, in other words, if language is one of the factors that intervenes in this algorithm when results exist in several languages.
We have employed reverse engineering techniques as our research methodology. This method is frequently used to determine how a device works by undertaking an analysis of its behavior and results. The method is also used to extract the source code from the compiled files.
Reverse engineering has been used for years to study search engine ranking algorithms [
70,
71,
72]. The documents that occupy the highest rankings in the results lists are analyzed and, then, by means of a statistical analysis it can be deduced whether the factors they present intervene in the ranking. The most frequently used statistical test in this context is Spearman’s correlation, given that the data never form normal distributions. The native search engine ranking is compared with the rankings created by the researcher using some of the frequent characteristics presented by the highest-ranking documents. The higher the correlation coefficient, the more similar the two rankings are and, therefore, the greater the weight that can be attributed to the alternative ranking factor in the search engine algorithm under analysis.
In the case of Google’s algorithm, more than 200 factors are considered [
73,
74]. This algorithm is highly complex and, moreover, it is subject to constant improvements, a process in which the application of artificial intelligence is involved [
75]. It is for this reason that in studies of Google correlation coefficients rarely exceed 0.3. These results are very low, but sufficient to obtain some indication as to whether a particular factor under analysis is included in the computation of the ranking of documents.
Google Scholar adheres to the same (dis)information policy as Google and does not provide specific details as to how the algorithm works, officially, in an effort to prevent spam. This means it publishes only very general guidelines:
“Google Scholar aims to rank documents the way researchers do, weighing the full text of each document, where it was published, who it was written by as well as how often and how recently it has been cited in other scholarly literature.”
However, thanks to the findings of previous studies [
57,
77], it is evident that the Google Scholar algorithm is simpler than that of the general Google search engine. This has certain advantages for reverse engineering studies of Google Scholar, with correlation coefficients higher than 0.8 often being obtained, which allows more reliable conclusions to be drawn.
The sample data for this study consisted of a total of 45 searches each producing 1000 results, which means we analyzed approximately 45,000 items of information, a similar number to other studies of the same type in which reverse engineering was employed [
70,
71,
78] to study the Google Scholar algorithm [
19,
20,
21,
22,
23,
28].
More specifically, we conducted three different types of search, obtaining 15,000 results in each case: searches by author, by year, and by keyword. By so doing, our aim was to analyze the algorithm in different contexts and to identify similar patterns of behavior that would lend more robustness to our results.
In the case of searches by keyword, we selected the most frequent terms meeting the following conditions:
General, non-specialized, language terms, in order to avoid any thematic biases.
Terms spelt the same in English and Spanish (i.e., cognates), in order to generate multilingual searches in at least these two languages. Subsequently, we also detected results in Portuguese and other languages, as the spelling of some of the terms selected also coincided with the spellings in these languages.
Additionally, by using the search form, we forced the appearance of the keyword in the title of the documents found so that, in this way, we could neutralize this factor and prevent it from distorting our results.
In the case of searches by year, we included documents published before 2015, in order to avoid more recent documents that might not have had sufficient time to generate a significant number of citations. As we report below, citations are a central element in this methodology.
Finally, in the case of searches by author, to generate as many multilingual results as possible, we selected the most frequently used surnames of Hispanic origin in the United States. Note, surnames were used in isolation from any first names.
To avoid data bias due to low data volumes, the following conditions were also applied to all searches in the sample:
At least 2.5% of the documents in all the searches conducted had to be written in languages other than English.
All documents included in the analysis had to have at least 15 citations received. The reason for our introducing this condition was to avoid a high number of documents with zero citations received which would have made it impossible to differentiate their ranking by citations.
Our final sample was made up as follows:
Keywords: capital, combustible, crisis, cultural, federal, festival, final, general, idea, invisible, moral, popular, social, terror, total.
Authors: Cruz, Diaz, Flores, Garcia, Gomez, Gutierrez, Hernandez, Martinez, Morales, Ortiz, Perez, Ramirez, Ramos, Sanchez, Torres.
Years: from 2000 to 2014.
Table 1 shows the percentages of documents written in languages other than English retrieved in each search. The data for this study were collected between 28 August 2020 and 22 September 2020 using the Publish or Perish tool [
79,
80]. Searches by keyword and author were performed without accents and in lower case. The language of each item was identified by employing Google’s language recognition technology by primarily analyzing the title of the documents. This technology is available among the spreadsheet functions of Google Drive.
For the statistical study, as the distributions were not normal according to the Kolmogorov-Smirnov test, we used Spearman’s correlation.
For each of the searches analyzed, the number of citations received was transformed to an ordinal scale. In this way, we constructed an alternative ranking that could subsequently be correlated with the native Google Scholar ranking. This is a very common procedure [
19,
21] in this type of research as it allows the comparison to be more naturally made between two ordinal variables.
As mentioned, the number of citations a document receives is a very important factor in the Google Scholar ranking algorithm, especially in searches by date and author, when keywords do not intervene. In searches of this type, the ranking by number of citations received is very similar to the native Google Scholar ranking, with correlation coefficients higher than 0.9 [
23].
To determine the role that language plays in Google Scholar’s ranking, we exploited this similarity. Our aim in so doing was to determine whether documents written in English follow a similar pattern to documents written in other languages when the native ranking is compared with the ranking by citations received. We wished to see if the number of citations received is an equally determining factor regardless of the language in which the document is written.
If the correlations of the documents written in English are similar to those of documents written in other languages, it means that language does not condition the ranking algorithm; on the other hand, if the correlations are different we will have found indications that language may play a role in this ranking, be it positive or negative.
In order to obtain global values of the correlations, we calculated the median values of the ranking by citations of the 45 searches making up the sample and for each of the 1000 document positions in the results list. These one thousand medians (for each of the 45 searches) provide a measure of central tendency of the citation ranking which can then be correlated with the native Google Scholar ranking.
To conduct the statistical analysis, we used R, version 3.4.0 [
71]; SPSS, version 20.0.0; Excel, and Google Sheets. Confidence intervals were constructed using the normal approximation method and applying Fisher’s transformation using the R psych package [
81,
82,
83]. Fisher’s transformation when applied to Spearman’s correlation coefficient is asymptotically normal. The scatter plots were created with Google Sheets and Tableau.
4. Results
In line with previous research [
23,
24], an analysis of our data verified a high correlation between the ranking by the number of citations received and Google Scholar’s native ranking. The high value of these coefficients indicates that a document receiving a high ranking on the basis of the number of citations received is also highly positioned in Google Scholar’s native ranking.
However, when we focused our analysis solely on documents written in languages other than English, we detected an unusual ranking pattern, one that had not previously been identified. This pattern can be defined in terms of the following two characteristics:
In multilingual searches in Google Scholar, documents written in languages other than English fail, in the main, to appear among the first 900 results on the search page (i.e., they present a ranking >900).
The Google Scholar ranking algorithm works differently for documents written in languages other than English, as it does not consider the number of citations received as the main ranking factor.
This implies that while documents written in English are awarded a good position based on the number of citations received, this same factor, even when the number of citations is high, does not benefit documents written in other languages. In other words, in multilingual searches in Google Scholar, the widely recognized positioning factor based on the number of citations received is not applicable to documents that are not published in English.
Below, we present in detail the data tables and scatter plots that corroborate these conclusions.
4.1. Data Analysis Identifying the Different Ranking Pattern Presented by Documents Written in Languages other than English
Table 2,
Table 3 and
Table 4 show the percentages of documents in languages other than in English which failed to appear among the top 900 search results. It is evident that they constitute the vast majority: 92.1% in the case of searches by year, 85.3% in those by author and 89.7% in those by keyword.
Table 5 provides a summary of these results, indicating that, overall, 91% of documents in languages other than English are ranked above 900 (i.e., >900). This contrasts with just 3.7% of documents in English that appear in these positions. It is also striking that only 0.7% of documents in languages other than English appear in the top 100 positions. This figure falls to 0.2% when the first 20 positions are analyzed (
Table 5).
Table 6,
Table 7 and
Table 8 show the correlation coefficients between the ranking by the number of citations received and the Google Scholar native ranking. The results in English are differentiated from those of the other languages in order to highlight the different ranking pattern identified. In all cases, the correlations are higher for the documents published in English. These differences are especially notable in searches by years and by authors with values always higher than 0.82 in the case of documents in English and values always lower than 0.44 in documents published in other languages.
In the case of searches by keyword, some outcomes point to more moderate differences, but if we observe the correlations between the median values, the differences are again very high with values of 0.91 for documents in English and 0.05 for those in other languages, although this last value is not statistically significant (
Table 8). In fact, most of the correlations of the results for documents in other languages are not statistically significant, another indication that we are dealing with two different distributions.
If we take the overall data (
Table 9) for all the searches and compare the correlations of the medians of the two rankings, we obtain values of 0.97 for the documents in English and of just 0.18 for those in other languages.
The value of the correlation for all the data is, likewise, very high at 0.91. As discussed previously, this indicates that while the number of citations is a very important factor in the ranking algorithm, the low values recorded in the case of documents written in languages other than English shows that this factor is not being applied and, as a result, the behavior of the ranking algorithm is unusual in these cases.
4.2. Analysis of Scatter Plots to Show the Differ Ranking Pattern of Documents Written in Languages other than English
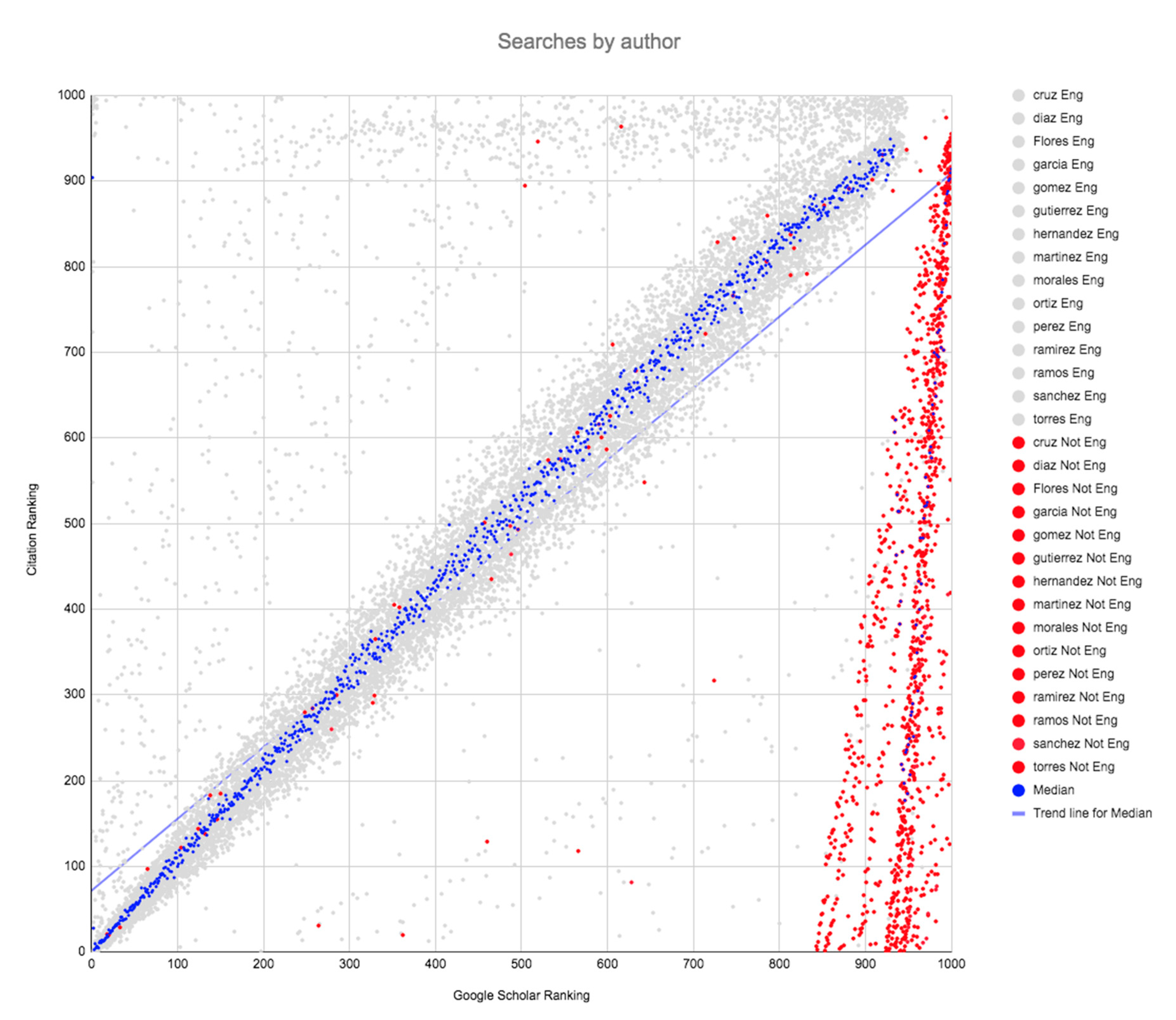
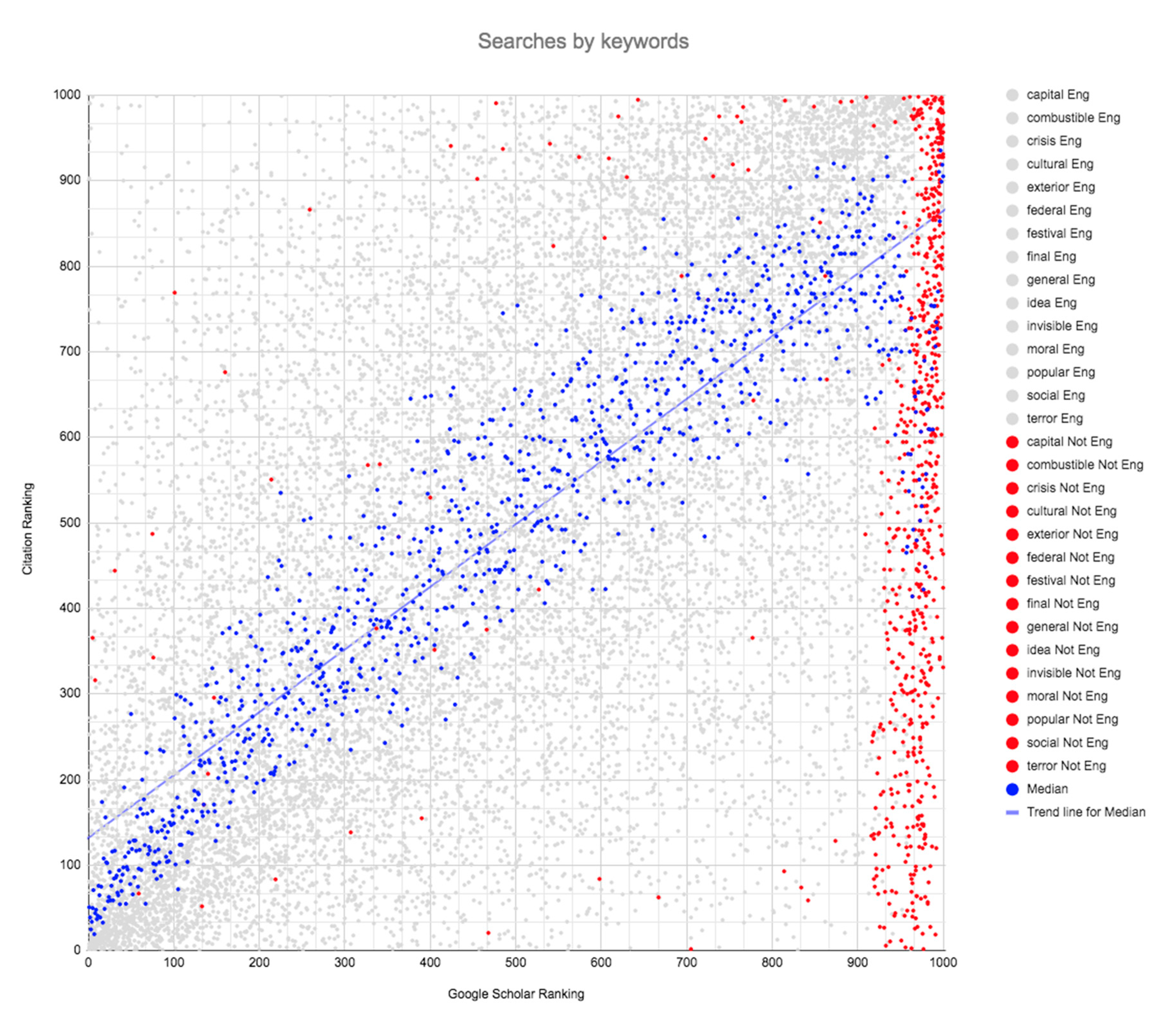
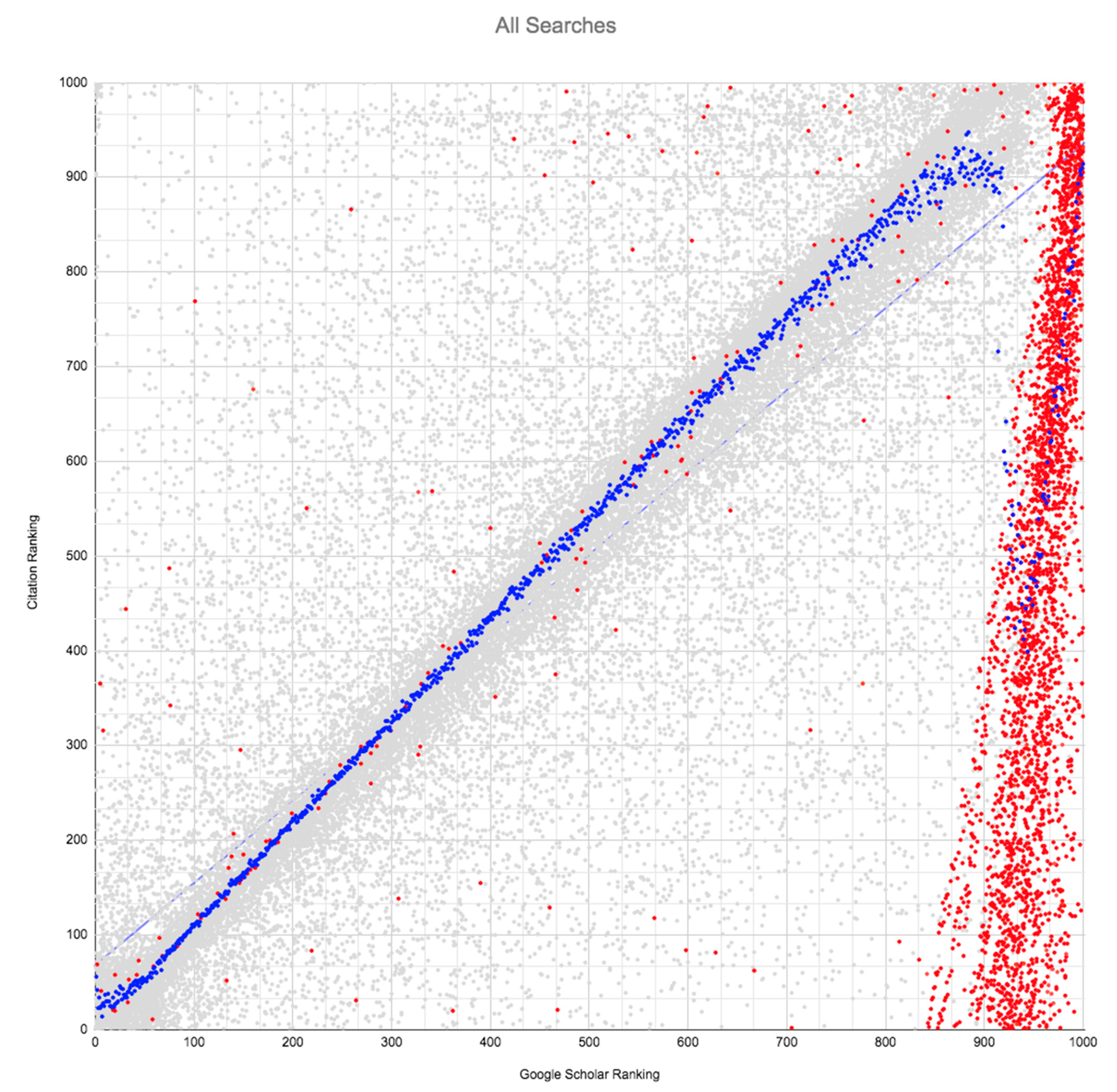
The different ranking pattern presented by documents written in languages other than English is also evident in the scatter plots (
Figure 1,
Figure 2,
Figure 3 and
Figure 4), where the documents published in English are represented by gray dots and those corresponding to other languages are represented by red dots. The blue dots represent the median values of the ranking by citations of the documents listed among the top thousand in the results page. As is evident, the vast majority of the results corresponding to documents written in languages other than English (red dots) do not appear in the top 900 positions. There are, in fact, two-point clouds: One essentially for documents published in English and one for documents published in other languages.
Documents in languages other than English do not adhere to the pattern set by the overall results, a pattern that places the points along the diagonal of the scatter plot, corresponding to a high correlation coefficient. A pattern that gives a good position in the ranking according to the number of citations received also gives a good position in the Google Scholar native ranking. The breakdown in this pattern is especially notable in the case of the dots located in the lower right corner of the four graphs, corresponding to documents that appear in the top 100 positions in the ranking by number of citations, but which are located above rank position 900 in the Google Scholar native ranking.
This second point cloud that forms above rank position 900 has been previously detected by Beel [
19] and Rovira [
23], but these authors did not attribute its origin to the language in which the documents were published.
The scatter plots illustrate quite clearly the same inconsistency in the ranking algorithm that we report above in our data analysis. This inconsistency implies that documents written in languages other than English are treated in a discriminatory manner.
5. Discussion
Our data are insufficient to be able to conclude whether the ranking of documents in languages other than English is due simply to an accidental bias, caused by an unintentional error in the software program, or whether it is an intentional outcome of the design of the algorithm, based, for example, on a belief that the English language has what might be considered an internationally superior dimension to that of other languages. This would explain (although we cannot state with any certainty) why in multilingual searches documents written in other languages become virtually invisible.
Neither do we have sufficient data to determine whether, in fact, two different algorithms are being used, one for English and one for all other languages, or whether the documents in English are ranked first and only then are the documents in all other languages ranked employing the same algorithm, to mention just a few possibilities.
However, what we have been able to demonstrate is that the Google Scholar relevance ranking algorithm favors documents in English and handicaps documents written in other languages in searches that produce multilingual results. Moreover, the vast majority of documents written in languages other than English have no chance at all of being found in searches of this type, even if they are high quality articles with hundreds or, even, thousands of citations received. Indeed, for 94% of documents of this type their possibilities of being found are absolutely zero, given that almost nobody accesses items located above a rank position of 700 on a list of search results (
Table 5).
More specifically, only 0.2% of these non-English documents have a chance of being found in a multilingual search in Google Scholar, given that they would occupy a place in the top 20 rankings. However, if the ranking algorithm were to be applied homogeneously across all documents, giving the same weight to citations received in all of them, the percentage of non-English documents among these top 20 positions would be 3.2%, i.e., much higher than the value of 0.2% actually obtained (
Table 5).
This anomalous behavior is detected in multilingual searches that return results in different languages, that is, searches conducted, for example, by year, by author, or by keywords with identical spelling in more than one language. Clearly, in typical keyword searches, in which all the results are in the same language, this bias does not occur.
We can, moreover, rule out the possibility that other variables, in addition to the language in which a document is written, might be intervening, to produce this anomalous ranking. We have been able to verify that these results only occur in documents written in a language other than English and at such high percentages that the possibility of the participation of any other factors can be discarded.
Despite the restrictions we imposed on our data collection, the number of results in languages other than English is relatively low compared to the whole sample of data analyzed: 4.4% in the case of keywords, 7.7% in that of authors and 8.4% in the case of years (
Table 1). These low percentages are also a consequence of a biased ranking. Future studies need to include searches with a more balanced number of results between documents in English and those published in other languages in order to corroborate that the ranking is also discriminatory in these cases. However, the only way to obtain percentages close to 50% is by conducting unnatural searches, such as combining years and keywords of one or two letters.
Finally, it is worth highlighting two additional aspects that might also be the object of future research. First, we have reported that the point cloud for searches by keyword is much more dispersed than those for searches by year or by author. This dispersion is a clear indication that in searches by keyword other factors, in addition to the number of citations received, are intervening. For this reason, more research is needed to identify the other factors that contribute to this dispersion. Second, it would be of interest to determine whether the bias we report differs according to the non-English language used for publication, in other words, whether documents written in Spanish, French or German, for example, present a specific ranking pattern in Google Scholar searches.
6. Conclusions
Both standard SEO and ASEO have a primary concern with determining the main factors employed in ranking algorithms. The aim of these two fields of enquiry is to make more visible the characteristics that articles present and which, in turn, serve as criteria for ranking. This is the case of so-called “white hat SEO”, that is, positioning actions that seek to optimize the visibility of information by ethical means.
This need to identify positioning factors has motivated and guided our research here, which reports an unexpected result with major repercussions for researchers. We have demonstrated that in Google Scholar, in the case of multilingual results, documents in languages other than English are systematically relegated to positions that make them virtually invisible. These positions are not the result of applying the standard ranking algorithm, as is done for documents in English. Moreover, in practical terms, it is of little importance whether this bias is accidental or the result of an algorithm designed specifically to rank differently according to the language in which a document is written.
However, it is important to draw attention to this major bias so that it might be limited or compensated for when a search is conducted. A lack of awareness of this factor could be detrimental to researchers from all over the non-English-speaking world, making them believe that there is no literature in their national language when they conduct searches with multilingual results. This is particularly the case in the most frequent searches, that is, those conducted by year. Nevertheless, it can also occur in searches using certain keywords that are the same in languages around the world, including trademarks, chemical compounds, industrial products, acronyms, drugs, and diseases, with Covid-19 being the most recent example.
Moreover, if we consider the results of this study from the perspective of ASEO, it is more than evident that until this bias is addressed, the chances of being ranked in a multilingual Google Scholar search increase remarkably if the researchers opt for publication in English. This recommendation is especially critical for researchers working in the areas mentioned in the previous paragraph whose names are the same in English and in their national language.










{kind=link}
{kind=link}
{kind=link}
{kind=link}