
RecPOID: POI Recommendation with Friendship Aware and Deep CNN



Abstract
1. Introduction
2. Materials and Methods
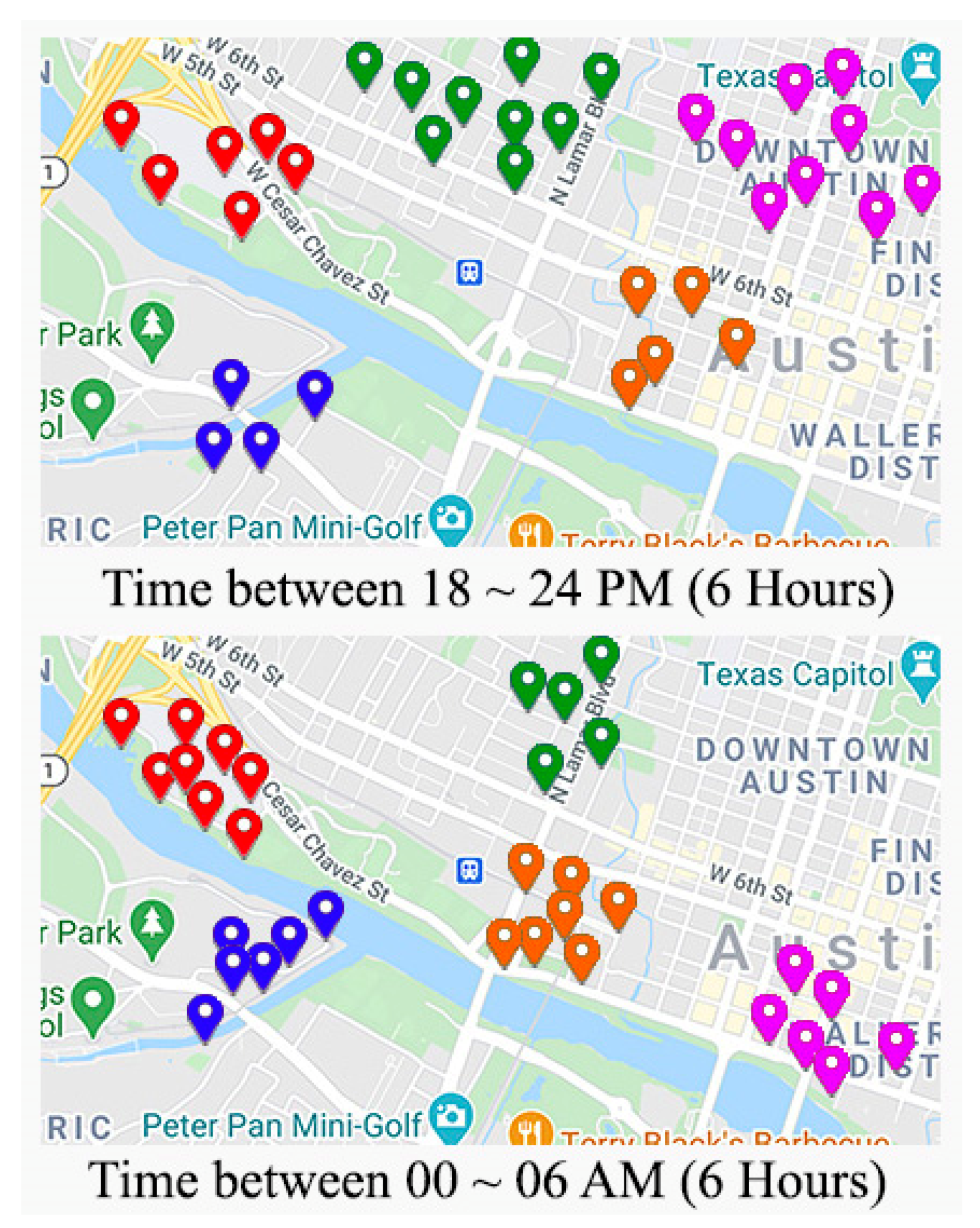
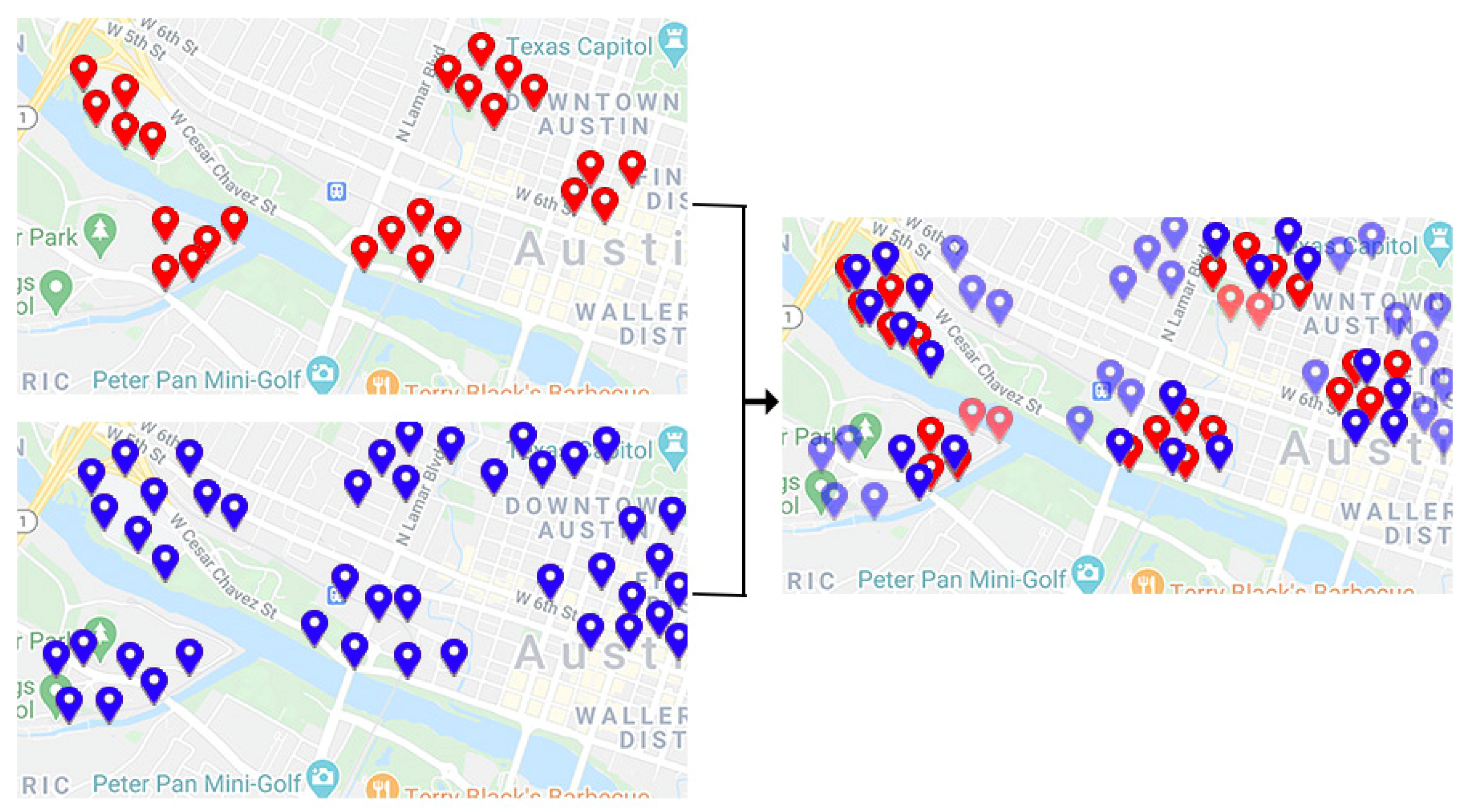
2.1. Clustering the POI’s
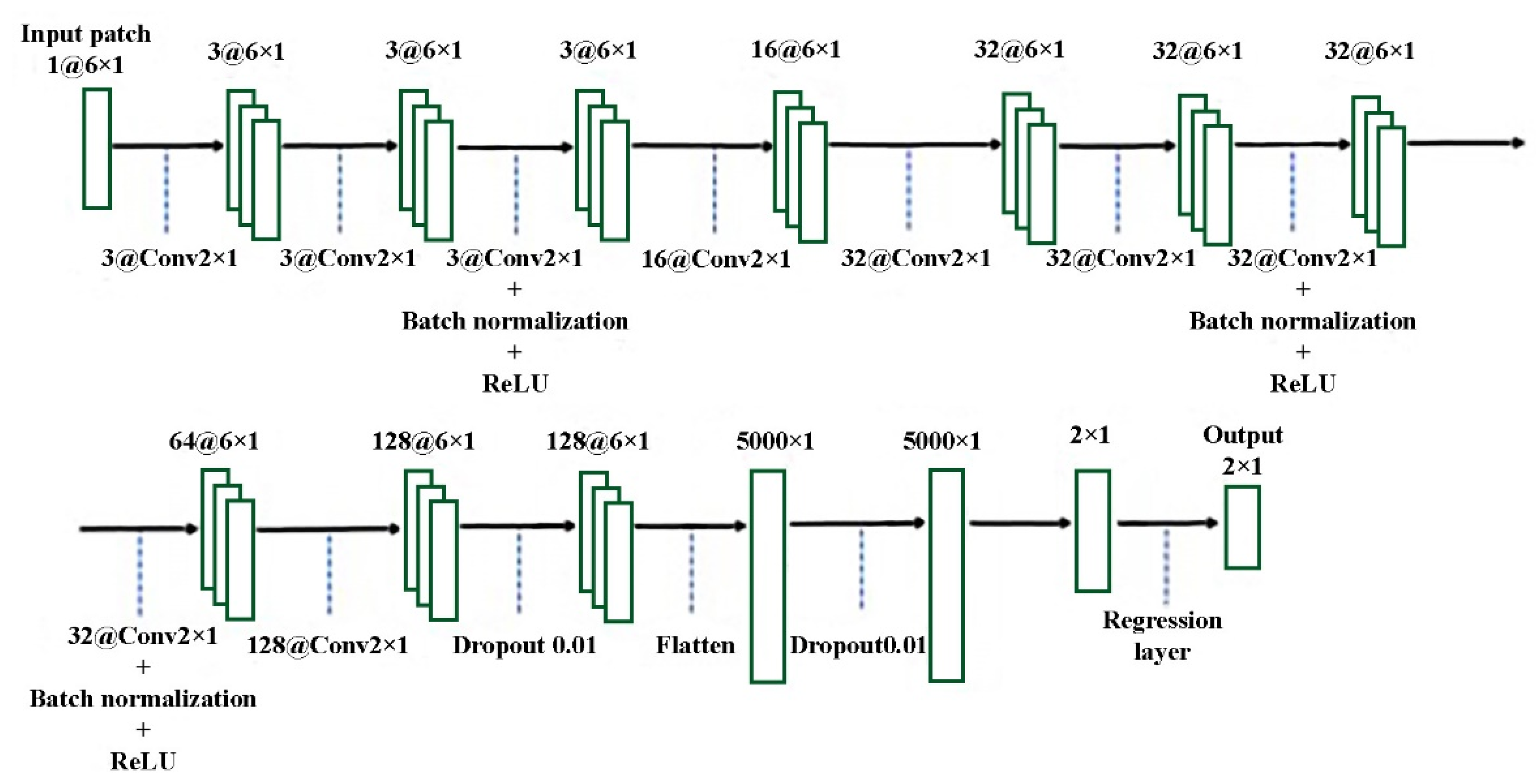
2.2. Convolutional Neural Network
2.3. Proposed CNN Architecture
| Algorithm 1 RecPOID algorithm |
| Input: user U, social relation G, check-in matrix R, DateTime T (month, day, hour, minute, and second), location L (ID, latitude and longitude) |
| Output: top-K POIs for each user u based on friendship |
| K _cluster = 5 |
| Epochs = 800 |
| Learning rate = 0.01 |
| Dropout probability = 0.01% |
| 1. Identify each user’s friends |
| 2. Divide the time span into 4 spans (00–06, 06:01–12, 12:01–18, 18:01–24) |
| 3. part_time = (0.00–06.00, 6.01–12.00, 12.01,18.00, 18.01–24) |
| 4. for i = 1: size(part_time) |
| 5. clustering users and their friendship based on the fuzzy c-means algorithm |
| 6. selecting 10 percent of the most overlapping between the user’s clusters and friendship clusters |
| 7. end |
| 8. Utilized proposed CNN architecture |
| 9. return predicted locations |
| 10. error = calculate the distance between the predicted location and the user’s friendship locations |
| 11. if error = 0 then |
| 12. return top-k POIs |
| 13. else |
| 14. Measure the shortest time distance with a similar friendship check-in pattern |
| 15. return top-k POIs |
| 16. end |
2.4. Datasets
2.5. Performance Metrics
3. Result and Discussion
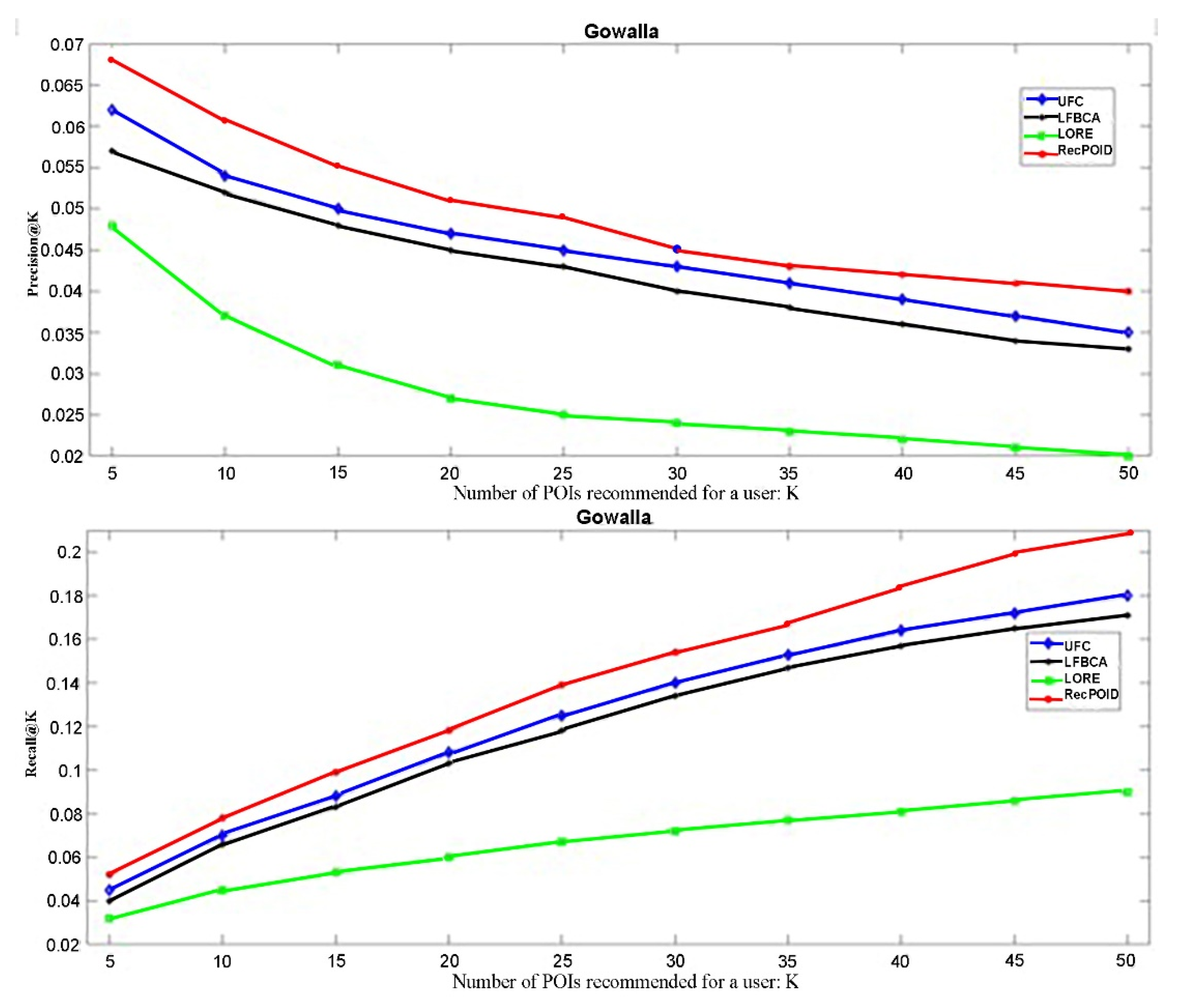
3.1. Experimental Results
3.2. Discussion on Performance
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qian, T.; Liu, B.; Nguyen, Q.V.H.; Yin, H. Spatiotemporal Representation Learning for Translation-Based POI Recommendation. ACM Trans. Inf. Syst. 2019, 37, 1–24. [Google Scholar] [CrossRef]
- Li, X.; Han, D.; He, J.; Liao, L.; Wang, M. Next and Next New POI Recommendation via Latent Behavior Pattern Inference. ACM Trans. Inf. Syst. 2019, 37, 1–28. [Google Scholar] [CrossRef]
- Liu, W.; Lai, H.; Wang, J.; Ke, G.; Yang, W.; Yin, J. Mix geographical information into local collaborative ranking for POI recommendation. World Wide Web 2019, 23, 131–152. [Google Scholar] [CrossRef]
- Wu, Y.; Li, K.; Zhao, G.; Qian, X. Personalized Long- and Short-term Preference Learning for Next POI Recommendation. IEEE Trans. Knowl. Data Eng. 2020, 10, 1. [Google Scholar] [CrossRef]
- Ding, R.; Chen, Z. RecNet: A deep neural network for personalized POI recommendation in location-based social networks. Int. J. Geogr. Inf. Sci. 2018, 32, 1631–1648. [Google Scholar] [CrossRef]
- Doan, T.-N.; Lim, E.-P. Modeling location-based social network data with area attraction and neighborhood competition. Data Min. Knowl. Discov. 2018, 33, 58–95. [Google Scholar] [CrossRef]
- Lian, D.; Zheng, K.; Ge, Y.; Cao, L.; Chen, E.; Xie, X. GeoMF++. ACM Trans. Inf. Syst. 2018, 36, 1–29. [Google Scholar] [CrossRef]
- Ye, M.; Yin, P.; Lee, W.-C.; Lee, D.-L. Exploiting geographical influence for collaborative point-of-interest recommendation. In Proceedings of the 34th international ACM SIGIR conference on Research and development in Information—SIGIR ’11, Beijing, China, 25–29 July 2011; pp. 325–334. [Google Scholar]
- Hao, P.-Y.; Cheang, W.-H.; Chiang, J.-H. Real-time event embedding for POI recommendation. Neurocomputing 2019, 349, 1–11. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, C.; Wu, Z.; Sun, A.; Ye, D.; Luo, X. NEXT: A neural network framework for next POI recommendation. Front. Comput. Sci. 2020, 14, 314–333. [Google Scholar] [CrossRef]
- Gao, Y.; Duan, Z.; Shi, W.; Feng, J.; Chiang, Y.-Y. Personalized Recommendation Method of POI Based on Deep Neural Network. In Proceedings of the 2019 6th International Conference on Behavioral, Economic and Socio-Cultural Computing (BESC), Beijing, China, 28–30 October 2019. [Google Scholar]
- Sit, M.A.; Koylu, C.; Demir, I. Identifying disaster-related tweets and their semantic, spatial and temporal context using deep learning, natural language processing and spatial analysis: A case study of Hurricane Irma. Int. J. Digit. Earth 2019, 12, 1205–1229. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Y.; Wu, Q.; Xia, Y. Medical image classification using synergic deep learning. Med. Image Anal. 2019, 54, 10–19. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Ma, Y.; Wang, S.; Liu, Y. An Attention-based Spatiotemporal LSTM Network for Next POI Recommendation. IEEE Trans. Serv. Comput. 2019, 10, 1. [Google Scholar] [CrossRef]
- Yuan, J.; Hou, X.; Xiao, Y.; Cao, D.; Guan, W.; Nie, L. Multi-criteria active deep learning for image classification. Knowl. -Based Syst. 2019, 172, 86–94. [Google Scholar] [CrossRef]
- Yin, H.; Wang, W.; Wang, H.; Chen, L.; Zhou, X. Spatial-Aware Hierarchical Collaborative Deep Learning for POI Recommendation. IEEE Trans. Knowl. Data Eng. 2017, 29, 2537–2551. [Google Scholar] [CrossRef]
- He, F.; Wei, P. Research on comprehensive point of interest (POI) recommendation based on spark. Clust. Comput. 2018, 22, 9049–9057. [Google Scholar] [CrossRef]
- Zhou, J.; Liu, B.; Chen, Y.; Lin, F. UFC: A Unified POI Recommendation Framework. Arab. J. Sci. Eng. 2019, 44, 9321–9332. [Google Scholar] [CrossRef]
- Wang, H.; Terrovitis, M.; Mamoulis, N. Location recommendation in location-based social networks using user check-in data. In Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Orlando, FL, USA, 5–8 November 2013. [Google Scholar]
- Zhang, J.-D.; Chow, C.-Y.; Li, Y. LORE: Exploiting sequential influence for location recommendations. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014. [Google Scholar]
- Ranjbarzadeh, R.; Saadi, S.B. Automated liver and tumor segmentation based on concave and convex points using fuzzy c-means and mean shift clustering. Measurement 2020, 150, 107086. [Google Scholar] [CrossRef]
- Tang, Y.; Hu, X.; Pedrycz, W.; Song, X. Possibilistic fuzzy clustering with high-density viewpoint. Neurocomputing 2019, 329, 407–423. [Google Scholar] [CrossRef]
- Ren, T.; Wang, H.; Feng, H.; Xu, C.; Liu, G.; Ding, P. Study on the improved fuzzy clustering algorithm and its application in brain image segmentation. Appl. Soft Comput. 2019, 81, 105503. [Google Scholar] [CrossRef]
- Karimi, N.; Kondrood, R.R.; Alizadeh, T. An intelligent system for quality measurement of Golden Bleached raisins using two comparative machine learning algorithms. Measurement 2017, 107, 68–76. [Google Scholar] [CrossRef]
- Sudharshan, P.; Petitjean, C.; Spanhol, F.; Oliveira, L.E.; Heutte, L.; Honeine, P. Multiple instance learning for histopathological breast cancer image classification. Expert Syst. Appl. 2019, 117, 103–111. [Google Scholar] [CrossRef]
- Ranjbarzadeh, R.; Saadi, S.B.; Amirabadi, A. LNPSS: SAR image despeckling based on local and non-local features using patch shape selection and edges linking. Measurement 2020, 164, 107989. [Google Scholar] [CrossRef]
- Mahmood, A.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F.; Hovey, R.; Kendrick, G.; Fisher, R.B. Deep Learning for Coral Classification. In Handbook of Neural Computation; Elsevier: Amsterdam, The Netherlands, 2017; pp. 383–401. [Google Scholar]
- Torres, A.D.; Yan, H.; Aboutalebi, A.H.; Das, A.; Duan, L.; Rad, P. Patient Facial Emotion Recognition and Sentiment Analysis Using Secure Cloud with Hardware Acceleration. In Computational Intelligence for Multimedia Big Data on the Cloud with Engineering Applications; Elsevier BV: Amsterdam, The Netherlands, 2018; pp. 61–89. [Google Scholar]
- Zhong, J.; Liu, Z.; Han, Z.; Han, Y.; Zhang, W. A CNN-Based Defect Inspection Method for Catenary Split Pins in High-Speed Railway. IEEE Trans. Instrum. Meas. 2019, 68, 2849–2860. [Google Scholar] [CrossRef]
- Chen, J.; Liu, Z.; Wang, H.; Nunez, A.; Han, Z. Automatic Defect Detection of Fasteners on the Catenary Support Device Using Deep Convolutional Neural Network. IEEE Trans. Instrum. Meas. 2018, 67, 257–269. [Google Scholar] [CrossRef]
- Özyurt, F.; Tuncer, T.; Avci, E.; Koç, M.; Serhatlioğlu, I. A Novel Liver Image Classification Method Using Perceptual Hash-Based Convolutional Neural Network. Arab. J. Sci. Eng. 2019, 44, 3173–3182. [Google Scholar] [CrossRef]
- Bengio, Y. Practical Recommendations for Gradient-Based Training of Deep Architectures; Springer: Berlin, Heidelberg, 2012. [Google Scholar]
- Dolz, J.; Desrosiers, C.; Ben Ayed, I. 3D fully convolutional networks for subcortical segmentation in MRI: A large-scale study. NeuroImage 2018, 170, 456–470. [Google Scholar] [CrossRef] [PubMed]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- Morabito, F.C.; Campolo, M.; Ieracitano, C.; Mammone, N. Deep Learning Approaches to Electrophysiological Multivariate Time-Series Analysis. In Artificial Intelligence in the Age of Neural Networks and Brain Computing; Elsevier BV: Amsterdam, The Netherlands, 2019; pp. 219–243. [Google Scholar]
- Shang, W.; Sohn, K.; Almeida, D.; Lee, H. Understanding and improving convolutional neural networks via concatenated rectified linear units. In Proceedings of the international conference on machine learning. PMLR, Long Beach, CA, USA, 13–18 July 2019. [Google Scholar]
- Yin, W.; Schütze, H.; Xiang, B.; Zhou, B. ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs. Trans. Assoc. Comput. Linguist. 2016, 4, 259–272. [Google Scholar] [CrossRef]
- Husain, F.; Dellen, B.; Torras, C. Scene Understanding Using Deep Learning. In Handbook of Neural Computation; Elsevier BV: Amsterdam, The Netherlands, 2017; pp. 373–382. [Google Scholar]
- Havaei, M.; Davy, A.; Warde-Farley, D.; Biard, A.; Courville, A.; Bengio, Y.; Pal, C.; Jodoin, P.-M.; Larochelle, H. Brain tumor segmentation with Deep Neural Networks. Med. Image Anal. 2017, 35, 18–31. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kim, T.-Y.; Cho, S.-B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Cho, E.; Seth, A. Myers, and Jure Leskovec. Friendship and Mobility: User Movement in Location-Based Social Networks. In Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), London, UK, 14–19 August 2021. [Google Scholar]
- Yelp Dataset. Available online: https://www.yelp.com/dataset (accessed on 17 March 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Users | POIs | Records | Social Relations | Sparsity (%) | |
|---|---|---|---|---|---|
| Yelp | 30,887 | 18,995 | 265,533 | 860,888 | 99.860 |
| Gowalla | 18,737 | 32,510 | 86,985 | 1,278,274 | 99.865 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Safavi, S.; Jalali, M. RecPOID: POI Recommendation with Friendship Aware and Deep CNN. Future Internet 2021, 13, 79. https://doi.org/10.3390/fi13030079
Safavi S, Jalali M. RecPOID: POI Recommendation with Friendship Aware and Deep CNN. Future Internet. 2021; 13(3):79. https://doi.org/10.3390/fi13030079
Chicago/Turabian StyleSafavi, Sadaf, and Mehrdad Jalali. 2021. "RecPOID: POI Recommendation with Friendship Aware and Deep CNN" Future Internet 13, no. 3: 79. https://doi.org/10.3390/fi13030079
APA StyleSafavi, S., & Jalali, M. (2021). RecPOID: POI Recommendation with Friendship Aware and Deep CNN. Future Internet, 13(3), 79. https://doi.org/10.3390/fi13030079