
Ontology-Based Feature Selection: A Survey




Abstract
:1. Introduction
2. Classification Methods
2.1. Probabilistic Data Classification
2.2. Decision Tree Data Classification
2.3. Rule-Based Data Classification
2.4. Associative Classification
2.5. Support Vector Machines
2.6. Artificial Neural Networks Data Classification
2.7. Instance-Based Data Classification
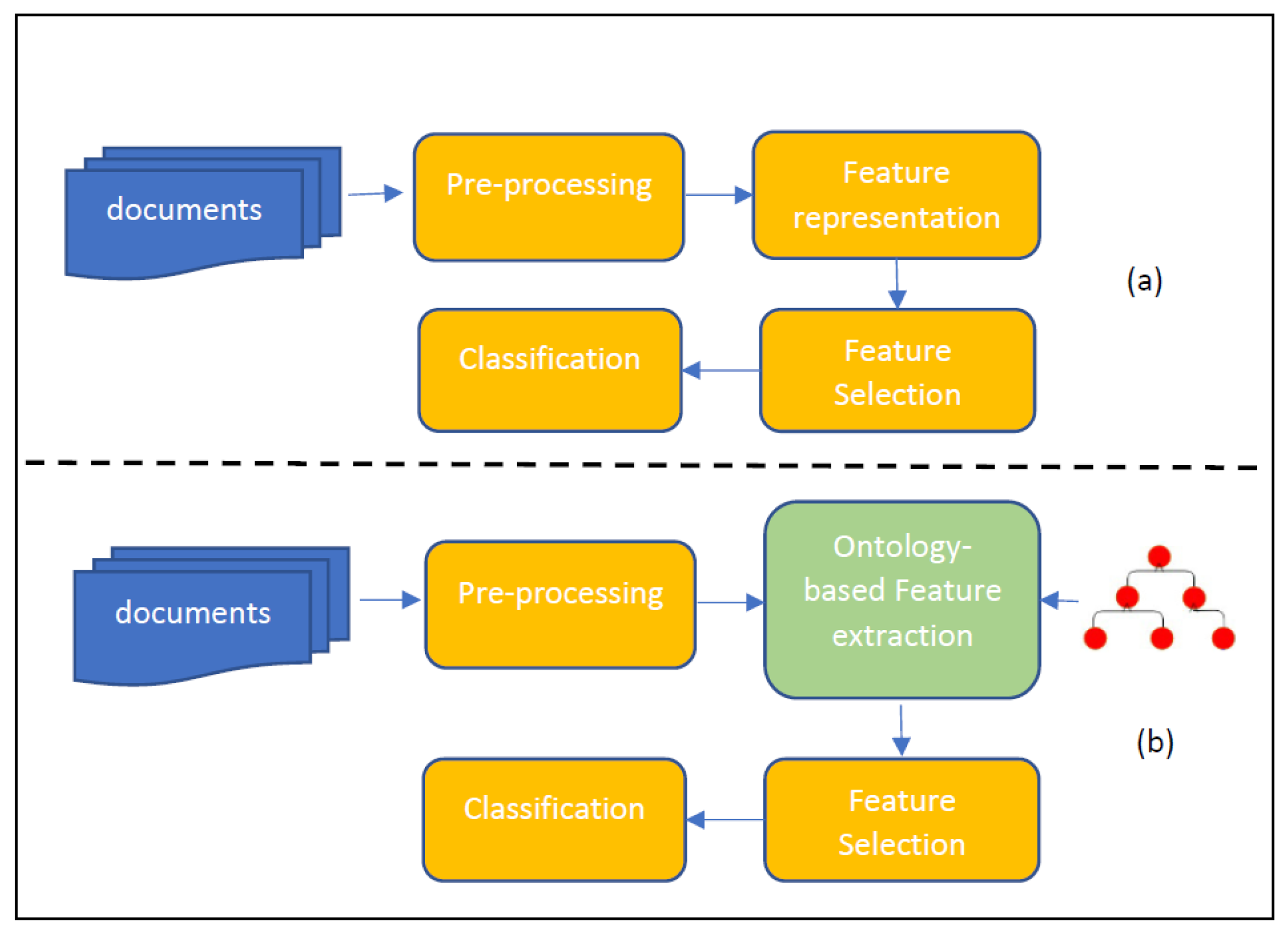
3. Feature Selection
3.1. Filter Models
3.2. Wrapper Models
3.3. Embedded Methods
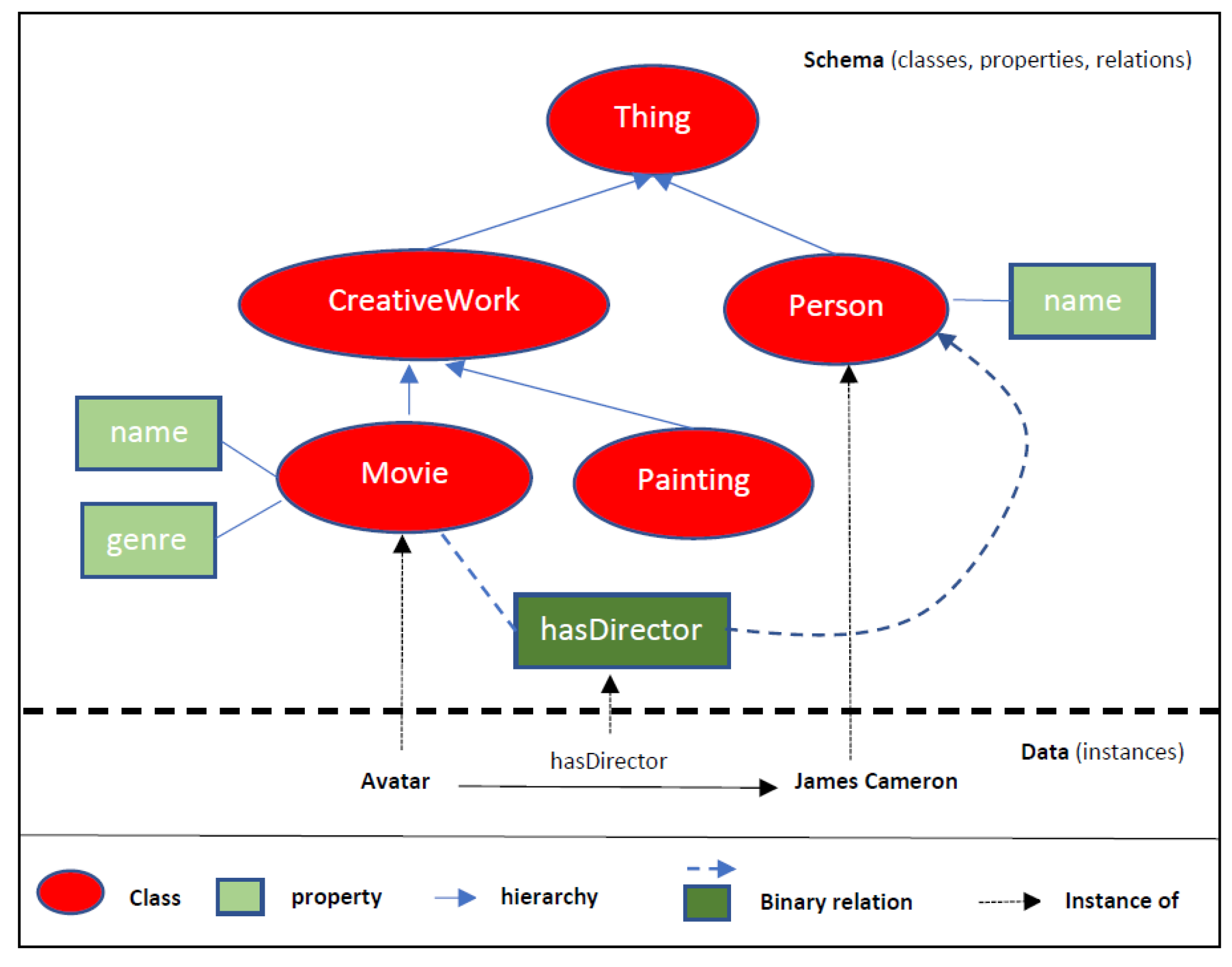
4. Ontologies
5. Ontology-Based Feature Selection
5.1. Document Classification

{kind=link}
{kind=link}
{kind=link}
| Related Work | Application | Ontology | Feature Selection | Classifier |
|---|---|---|---|---|
| [55] | Web Text | WordNet | TFIDF | NB, JRip, |
| J48, SVM | ||||
| [56] | Web text | Tourism, Space, Film, WordNet | Web-based PMI () | - |
| [59] | Text | UMLS | Frequency, | KNN |
| (Medical) | Hill Climbing | |||
| [62] | Text | WordNet | MFS, TFIDF | NB |
| [64] | Clinical Notes | UMLS | TFIDF, PSO | NP, LSVM, |
| (CAD) | KNN, DT, LR | |||
| [66] | Medication list | RxNorm, | IGR | NB |
| (hospital re-entry) | NDF-RT | |||
| [69] | Web text | Custom, | Ontology-based, | - |
| (Tweets) | BabelNet | SWRL | ||
| [70] | Text | WordNet | Similarity | SVM |
| [71] | Text | WordNet | Similarity | Sperical |
| (Clustering) | K-means | |||
| [72] | Text (Clinical) | UMLS | IG, Lin | SVM |
| [74] | Web text (Sports) | Custom | TFIDF | MNB, DT, KNN, Rocchio |
| [75] | Text | WordNet, OpenCyc, SUMO | Custom (Mapping Score) | SVM |
5.2. Opinion Mining
5.3. Other Applications
5.4. Discussion
- Most of the related works examined in this review paper concern ontology-based feature selection for text document classification, with the majority of them being Web-related.
- Most of the approaches utilize generic lexicons (either just the lexicon or in combination with domain ontologies), with the majority of them utilizing WordNet.
- For the task of feature selection, most of the approaches are based on the TFIDF method and filtering.
- SVM is the most common classification method, with KNN to follow.
6. Open Issues and Challenges
- The large expansion of knowledge recorded in Wikipedia, from which DBpedia and YAGO have been created as reference sources for general domain knowledge, is needed to assist information disambiguation and extraction.
- Advancements in statistical NLP techniques, and the appearance of new techniques that combine statistical and linguistic ones.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ALS | Airborne Laser Scanning |
| BoC | Bag of Concepts |
| BoW | Bag of Words |
| CAD | Coronary Artery Disease |
| CARs | Class Association Rules |
| CBR | Case-based reasoning subsystem |
| DSS | Decision support system |
| DC | Dublin Core |
| DT | Decision Tree |
| EEL | Entity Extraction and Linking |
| FE | Feature Engineering |
| FOAF | Friend Of A Friend |
| IG | Information Gain |
| IGR | Information Gain Ratio |
| KNN | K-Nearest neighbor |
| LCS | Least Common Subsumer |
| LD | Linked data |
| LR | Logistic Regression |
| LSVM | Linear Support Vector Machine |
| LVQ | Learning Vector Quantization |
| MFS | Maximal frequent sequence |
| MPS | Suitable manufacturing process |
| NB | Naive Bayes |
| NDF-RT | National Drug File - Reference Terminology |
| NE | Named entities |
| NER | Named-Entity Recognition |
| NLPP | Natural Language Processing Parser |
| NVH | Noise, Vibration and Harshness |
| OC | Ontological classes |
| OWL | Web Ontology Language |
| PCA | Principal Component Analysis |
| PMI | Pointwise Mutual Information |
| PoS | Part of speech |
| PSO | Particle Swarm Optimization |
| RBC | Rule-Based Classification |
| RDF | Resource Description Framework |
| REL | Relation Extraction and Linking |
| RDFS | RDF Scheme |
| RF | Random Forest |
| RS | Recommendation (or Recommender) systems |
| SC | Subsumer concept |
| SOM | Self-organizing Map |
| SP | Security patterns |
| SR | Security requirements |
| SVM | Support Vector Machines |
| SWRL | SemanticWeb rule language |
| TFIFD | Term frequency-inverse document frequency |
| UMLS | Unified Medical Language System |
| XML | eXtensible Markup Language |
| WSD | Word Sense Disambiguation |
References
- Heilman, C.M.; Kaefer, F.; Ramenofsky, S.D. Determining the appropriate amount of data for classifying consumers for direct marketing purposes. J. Interact. Mark. 2003, 17, 5–28. [Google Scholar] [CrossRef]
- Kuhl, N.; Muhlthaler, M.; Goutier, M. Supporting customer-oriented marketing with artificial intelligence: Automatically quantifying customer needs from social media. Electron. Mark. 2020, 30, 351–367. [Google Scholar] [CrossRef]
- Kour, H.; Manhas, J.; Sharma, V. Usage and implementation of neuro-fuzzy systems for classification and prediction in the diagnosis of different types of medical disorders: A decade review. Artif. Intell. Rev. 2020, 53, 4651–4706. [Google Scholar] [CrossRef]
- Tomczak, J.M.; Zieba, M. Probabilistic combination of classification rules and its application to medical diagnosis. Mach. Learn. 2015, 101, 105–135. [Google Scholar] [CrossRef] [Green Version]
- Kumar, A.; Sinha, N.; Bhardwaj, A. A novel fitness function in genetic programming for medical data classification. J. Biomed. Inform. 2020, 112, 103623. [Google Scholar] [CrossRef] [PubMed]
- Jiménez-Guarneros, M.; Gómez-Gil, P. Standardization-refinement domain adaptation method for cross-subject EEG-based classification in imagined speech recognition. Pattern Recognit. Lett. 2021, 141, 54–60. [Google Scholar] [CrossRef]
- Langari, S.; Marvi, H.; Zahedi, M. Efficient speech emotion recognition using modified feature extraction. Inform. Med. Unlocked 2020, 20, 100424. [Google Scholar] [CrossRef]
- Shah Fahad, M.; Ranjan, A.; Yadav, J.; Deepak, A. A survey of speech emotion recognition in natural environment. Digit. Signal Process. 2021, 110, 102951. [Google Scholar] [CrossRef]
- Memon, J.; Sami, M.; Khan, R.A.; Uddin, M. Handwritten Optical Character Recognition (OCR): A Comprehensive Systematic Literature Review (SLR). IEEE Access 2020, 8, 142642–142668. [Google Scholar] [CrossRef]
- Ma, Z.; Nie, F.; Yang, Y.; Uijlings, J.R.R.; Sebe, N.; Hauptmann, A.G. Discriminating Joint Feature Analysis for Multimedia Data Understanding. IEEE Trans. Multimed. 2012, 14, 1662–1672. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Ma, Z.; Hauptmann, A.G.; Sebe, N. Feature Selection for Multimedia Analysis by Sharing Information Among Multiple Tasks. IEEE Trans. Multimed. 2013, 15, 661–669. [Google Scholar] [CrossRef]
- Pashaei, E.; Aydin, E.N. Binary black hole algorithm for feature selection and classification on biological data. Appl. Soft Comput. 2017, 56, 94–106. [Google Scholar] [CrossRef]
- Kim, K.; Zzang, S.Y. Trigonometric comparison measure: A feature selection method for text categorization. Data Knowl. Eng. 2019, 119, 1–21. [Google Scholar] [CrossRef]
- Lee, Y.-H.; Hu, P.J.-H.; Tsao, W.-J.; Li, L. Use of a domain-specific ontology to support automated document categorization at the concept level: Method development and evaluation. Expert Syst. Appl. 2021, 174, 114681. [Google Scholar] [CrossRef]
- Rezaeipanah, A.; Ahmadi, G.; Matoori, S.S. A classifcation approach to link prediction in multiplex online ego social networks. Soc. Netw. Anal. Min. 2020, 10, 27. [Google Scholar] [CrossRef]
- Selvalakshmi, B.; Subramaniam, M. Intelligent ontology based semantic information retrieval using feature selection and classification. Clust. Comput. 2019, 22, S12871–S12881. [Google Scholar] [CrossRef]
- Alzamil, Z.; Appellbaum, D.; Nehmer, R. An ontological artifact for classifying social media: Text mining analysis for financial data. Int. J. Account. Inf. Syst. 2020, 38, 100469. [Google Scholar] [CrossRef]
- Everitt, B.S.; Landau, S.; Leese, M.; Stahl, D. Cluster Analysis; John Wiley and Sons: West Sussex, UK, 2011. [Google Scholar]
- Wierzchon, S.T.; Klopotek, M.A. Modern Algorithms of Cluster Analysis; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Lyu, S.; Tian, X.; Li, Y.; Jiang, B.; Chen, H. Multiclass Probabilistic Classification Vector Machine. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 3906–3919. [Google Scholar] [CrossRef]
- Shahrokni, A.; Drummond, T.; Fleuret, F.; Fua, P. Classification-Based Probabilistic Modeling of Texture Transition for Fast Line Search Tracking and Delineation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 570–576. [Google Scholar] [CrossRef] [Green Version]
- Demirkus, M.; Precup, D.; Clark, J.J.; Arbel, T. Hierarchical Spatio-Temporal Probabilistic Graphical Model with Multiple Feature Fusion for Binary Facial Attribute Classification in Real-World Face Videos. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1185–1203. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.F.; Zhang, J.W.; Zhou, Y.Q.; Guo, X.J.; Ma, Y.M. A feature selection algorithm of decision tree based on feature weight. Expert Syst. Appl. 2021, 164, 113842. [Google Scholar] [CrossRef]
- Rincy, T.; Gupt, R. An efficient feature subset selection approach for machine learning. Multimed. Tools Appl. 2021, 80, 12737–12830. [Google Scholar]
- Lu, X.-Y.; Chen, M.-S.; Wu, J.-L.; Chang, P.-C.; Chen, M.-H. A novel ensemble decision tree based on under-sampling and clonal selection for web spam detection. Pattern Anal. Appl. 2018, 21, 741–754. [Google Scholar] [CrossRef]
- Gupta, K.; Khajuria, A.; Chatterjee, N.; Joshi, P.; Joshi, D. Rule based classification of neurodegenerative diseases using data driven gait features. Health Technol. 2019, 9, 547–560. [Google Scholar] [CrossRef]
- Verikas, A.; Guzaitis, J.; Gelzinis, A.; Bacauskiene, M. A general framework for designing a fuzzy rule-based classifier. Knowl. Inf. Syst. 2011, 29, 203–221. [Google Scholar] [CrossRef]
- Almaghrabi, F.; Xu, D.-L.; Yang, J.-B. An evidential reasoning rule-based feature selection for improving trauma outcome prediction. Appl. Soft Comput. 2021, 103, 107112. [Google Scholar] [CrossRef]
- Singh, N.; Singh, P.; Bhagat, D. A rule extraction approach from support vector machines for diagnosing hypertension among diabetics. Expert Syst. Appl. 2019, 130, 188–205. [Google Scholar] [CrossRef]
- Liu, M.-Z.; Shao, Y.-H.; Li, C.-N.; Chen, W.-J. Smooth pinball loss nonparallel support vector machine for robust classification. Appl. Soft Comput. 2021, 98, 106840. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Data Classification: Algorithms and Applications; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Singapore, 2006. [Google Scholar]
- Verikas, A.; Gelzinis, A.; Bacauskiene, M. Mining data with random forests: A survey and results of new tests. Pattern Recognit. 2011, 44, 330–349. [Google Scholar] [CrossRef]
- Padillo, F.; Luna, J.M.; Ventura, S. LAC: Library for associative classification. Knowl. Based Syst. 2020, 193, 105432. [Google Scholar] [CrossRef]
- Deng, N.; Tian, Y.; Zhang, C. Support Vector Machines: Optimization Based Methods, Algorithms, and Extensions; Chapman and Hall/CRC: Boca Raton, FL, USA, 2013. [Google Scholar]
- Nocedal, J.; Wright, S.J. Numerical Optimization; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Aha, D.W.; Kibler, D.; Albert, M.K. Instance-based learning algorithms. Mach. Learn. 1991, 6, 37–66. [Google Scholar] [CrossRef] [Green Version]
- Mitchell, T. Machine Learning; McGraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Duboue, P. The Art of Feature Engineering: Essentials for Machine Learning; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Liu, H.; Motoda, H. Computational Methods of Feature Selection; Chapman and Hall/CRC: Boca Raton, FL, USA, 2007. [Google Scholar]
- Kuhn, M.; Johnson, K. Feature Engineering and Selection: A Practical Approach for Predictive Models; Chapman and Hall/CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Jovic, A.; Brkic, K.; Bogunovic, N. A review of feature selection methods with applications. In Proceedings of the 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; pp. 1200–1205. [Google Scholar]
- W3C. OWL Use Cases and Requirements. 2004. Available online: https://www.w3.org/TR/2004/REC-webont-req-20040210/ (accessed on 16 June 2021).
- OWL Reference. 2004. Available online: https://www.w3.org/OWL/ (accessed on 16 June 2021).
- Dublin Core Metadata Initiative. 2000. Available online: https://dublincore.org/ (accessed on 16 June 2021).
- Dan Brickley and Libby Miller. FOAF Vocabulary Specification 0.99. 2001. Available online: http://xmlns.com/foaf/spec/ (accessed on 16 June 2021).
- The Gene Ontology Resource. 2008. Available online: http://geneontology.org/ (accessed on 16 June 2021).
- Schema.org. Available online: http://schema.org/ (accessed on 16 June 2021).
- Kotis, K.; Vouros, G.A.; Spiliotopoulos, D. Ontology engineering methodologies for the evolution of living and reused ontologies: Status, Trends, Findings and Recommendations. Knowl. Eng. Rev. 2020, 35, e4. [Google Scholar] [CrossRef]
- Allemang, D.; Hendler, J. Semantic Web for the Working Ontologist: Effective Modeling in RDFS and OWL; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2011. [Google Scholar]
- Antoniou, G.; Groth, P.; van Harmelen, F.; Hoekstra, R. A Semantic Web Primer; The MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Domingue, J.; Fensel, D.; Hendler, J.A. Handbook of Semantic Web Technologies; Springer: Heidelberg, Germany, 2011. [Google Scholar]
- Tosi, D.; Morasca, S. Supporting the semi-automatic semantic annotation of web services: A systematic literature review. Inf. Softw. Technol. 2015, 61, 16–32. [Google Scholar] [CrossRef]
- Elhadad, M.; Badran, K.M.; Salama, G. A novel approach for ontology-based dimensionality reduction for web text document classification. In Proceedings of the 16th IEEE/ACIS International Conference on Computer and Information Science (ICIS 2017), Wuhan, China, 24–26 May 2017; pp. 373–378. [Google Scholar]
- Princeton Univeristy. WordNet-A Lexical Database for English. Available online: https://wordnet.princeton.edu/ (accessed on 16 June 2021).
- Vicient, C.; Sanchez, D.; Moreno, A. An automatic approach for ontology-based feature extraction from heterogeneous textual resources. Eng. Appl. Artif. Intell. 2013, 26, 1092–1106. [Google Scholar] [CrossRef]
- Apache Software Foundation. Apache Open NLP. 2004. Available online: https://opennlp.apache.org/ (accessed on 16 June 2021).
- Wang, B.B.; McKay, R.I.; Abbass, H.A.; Barlow, M. Learning text classifier using the domain concept hierarchy. In Proceedings of the IEEE International Conference on Communications, Circuits and Systems and West Sino Expositions Proceedings, Chengdu, China, 29 June–1 July 2002; Volume 2, pp. 1230–1234. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice Hall Press: Hoboken, NY, USA, 2009. [Google Scholar]
- US National Library of Medicine. Unified Medical Language System. 1986. Available online: https://www.nlm.nih.gov/research/umls/ (accessed on 16 June 2021).
- Khan, A.; Baharudin, B.; Khan, K. Semantic Based Features Selection and Weighting Method for Text Classification. In Proceedings of the International Symposium on Information Technology, Kuala Lumpur, Malaysia, 15–17 June 2010. [Google Scholar]
- Yap, I.; Loh, H.T.; Shen, L.; Liu, Y. Topic Detection Using MFSs. LNAI 2006, 4031, 342–352. [Google Scholar]
- Abdollahi, M.; Gao, X.; Mei, Y.; Ghosh, S.; Li, J. An ontology-based two-stage approach to medical text classification with feature selection by particle swarm optimization. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), Wellington, New Zealand, 10–13 June 2019; pp. 119–126. [Google Scholar]
- Kennedy, J.; Eberhart, R.C. Swarm Intelligence; Morgan Kaufmann: London, UK, 2001. [Google Scholar]
- Lu, S.; Ye, Y.; Tsui, R.; Su, H.; Rexit, R.; Wesaratchakit, S.; Liu, X.; Hwa, R. Domain ontology-based feature reduction for high dimensional drug data and its application to 30-day heart failure readmission prediction. In Proceedings of the 9th IEEE International Conference on Collaborative Computing: Networking, Applications and Worksharing, Austin, TX, USA, 20–23 October 2013. [Google Scholar]
- US National Library of Medicine. RxNorm. 2012. Available online: https://www.nlm.nih.gov/research/umls/rxnorm/index.html (accessed on 16 June 2021).
- U.S. Veterans Health Administration. National Drug File–Reference Terminology (NDF-RT) Documentation. Available online: https://evs.nci.nih.gov/ftp1/NDF-RT (accessed on 16 June 2021).
- Barhamgi, M.; Masmoudi, A.; Lara-Cabrera, R.; Camacho, D. Social networks data analysis with semantics: Application to the radicalization problem. J. Ambient. Intell. Humaniz. Comput. 2018. [Google Scholar] [CrossRef]
- Kerem, C.; Tunga, G. A comprehensive analysis of using semantic information intext categorization. In Proceedings of the IEEE International Symposium on Innovations in Intelligent Systems and Applications (INISTA 2013), Albena, Bulgaria, 19–21 June 2013; pp. 1–5. [Google Scholar]
- Fodeh, S.; Punch, B.; Tan, P.N. On ontology-driven document clustering using core semantic features. Knowl. Inf. Syst. 2011, 28, 395–421. [Google Scholar] [CrossRef]
- Garla, V.N.; Brandt, C. Ontology-guided feature engineering for clinical text classification. J. Biomed. Inform. 2012, 45, 992–998. [Google Scholar] [CrossRef]
- Lin, D. Automatic retrieval and Clustering of Similar Words. In Proceedings of the 17th International Conference on Computational Linguistics, Morristown, NJ, USA, 10–14 August 1998; pp. 768–774. [Google Scholar]
- Qazia, A.; Goudar, R.H. An Ontology-based Term Weighting Technique for Web Document Categorization. Procedia Comput. Sci. 2018, 133, 75–81. [Google Scholar] [CrossRef]
- Rujiang, B.; Junhua, L. Improving Documents Classification with Semantic Features. In Proceedings of the 2nd International Symposium on Electronic Commerce and Security, Nanchang, China, 22–24 May 2009; pp. 640–643. [Google Scholar]
- Jena Ontology API. Available online: https://jena.apache.org/documentation/ontology/ (accessed on 16 June 2021).
- Shein, K.P.P.; Nyunt, T.T.S. Sentiment Classification based on Ontology and SVM Classifier. In Proceedings of the International Conference on Communication Software and Networks, Singapore, 26–28 February 2010; pp. 169–172. [Google Scholar]
- Kontopoulos, E.; Berberidis, C.; Dergiades, T.; Bassiliades, N. Ontology-based sentiment analysis of twitter posts. Expert Syst. Appl. 2013, 40, 4065–4074. [Google Scholar] [CrossRef]
- Wang, D.; Xu, L.; Younas, A. Social Media Sentiment Analysis Based on Domain Ontology and Semantic Mining. Lect. Notes Artif. Intell. 2018, 10934, 28–39. [Google Scholar]
- Penalver-Martinez, I.; Garcia-Sanchez, F.; Valencia-Garcia, R.; Rodriguez-Garcia, M.A.; Moreno, V.; Fraga, A.; Sanchez-Cervantes, J.L. Feature-based opinion mining through ontologies. Expert Syst. Appl. 2014, 41, 5995–6008. [Google Scholar] [CrossRef]
- Zhou, L.; Chaovalit, P. Ontology-Supported Polarity Mining. J. Am. Soc. Inf. Sci. Technol. 2008, 59, 98–110. [Google Scholar] [CrossRef]
- Alfrjani, R.; Osman, T.; Cosma, G. A New Approach to Ontology-Based Semantic Modelling for Opinion Mining. In Proceedings of the 18th International Conference on Computer Modelling and Simulation (UKSim), Cambridge, UK, 6–8 April 2016; pp. 267–272. [Google Scholar]
- Siddiqui, S.; Rehman, M.A.; Daudpota, S.M.; Waqas, A. Ontology Driven Feature Engineering for Opinion Mining. IEEE Access 2019, 7, 67392–67401. [Google Scholar] [CrossRef]
- Zhao, L.; Li, C. Ontology Based Opinion Mining for Movie Reviews. Lect. Notes Artif. Intell. 2009, 5914, 204–214. [Google Scholar]
- de Freitas, L.A.; Vieira, R. Ontology-based Feature Level Opinion Mining for Portuguese Reviews. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 367–370. [Google Scholar]
- Ali, F.; Kwak, K.-S.; Kim, Y.-G. Opinion mining based on fuzzy domain ontology and Support VectorMachine: A proposal to automate online review classification. Appl. Soft Comput. 2016, 47, 235–250. [Google Scholar] [CrossRef]
- Ali, F.; EI-Sappagh, S.; Khan, P.; Kwak, K.-S. Feature-based Transportation Sentiment Analysis Using Fuzzy Ontology and SentiWordNet. In Proceedings of the International Conference on Information and Communication Technology Convergence (ICTC 2018), Jeju, Korea, 17–19 October 2018; pp. 1350–1355. [Google Scholar]
- MO-the Movie Ontology. Available online: http://www.movieontology.org/ (accessed on 16 June 2021).
- Andrea, E.; Fabrizio, S. Determining the semantic orientation of terms through gloss classification. In Proceedings of the 14th ACM International Conference on Information and Knowledge Management, Bremen, Germany, 31 October–5 November 2005. [Google Scholar]
- Joachims, T. A probabilistic analysis of the Rocchio algorithm with TFIDF for text categorization. In Proceedings of the 14th International Conference on Machine Learning (ICML-97), Nashville, TN, USA, 8–12 July 1997; pp. 143–151. [Google Scholar]
- Di Noia, T.; Magarelli, C.; Maurino, A.; Palmonari, M.; Rula, A. Using Ontology-Based Data Summarization to Develop Semantics-Aware Recommender Systems. LNCS 2018, 10843, 128–144. [Google Scholar]
- Ragone, A.; Tomeo, P.; Magarelli, C.; Di Noia, T.; Palmonari, M.; Maurino, A.; Di Sciascio, E. Schema-summarization in Linked-Data-based feature selection for recommender systems. In Proceedings of the Symposium on Applied Computing (SAC ’17), Marrakech, Morocco, 3–7 April 2017; pp. 330–335. [Google Scholar]
- Nilashi, M.; Ibrahim, O.; Bagherifard, K. A recommender system based on collaborative filtering using ontology and dimensionality reduction techniques. Expert Syst. Appl. 2018, 92, 507–520. [Google Scholar] [CrossRef]
- Mabkhot, M.M.; Al-Samhan, A.M.; Hidri, L. An ontology-enabled case-based reasoning decision support system for manufacturing process selection. Adv. Mater. Sci. Eng. 2019, 2019, 2505183. [Google Scholar] [CrossRef] [Green Version]
- Eum, K.; Kang, M.; Kim, G.; Park, M.W.; Kim, J.K. Ontology-Based Modeling of Process Selection Knowledge for Machining Feature. Int. J. Precis. Eng. Manuf. 2013, 4, 1719–1726. [Google Scholar] [CrossRef]
- Kang, M.; Kim, G.; Lee, T.; Jung, C.H.; Eum, K.; Park, M.W.; Kim, J.K. Selection and Sequencing of Machining Processes for Prismatic Parts using Process Ontology Model. Int. J. Precis. Eng. Manuf. 2016, 17, 387–394. [Google Scholar] [CrossRef]
- Han, S.; Zhou, Y.; Chen, Y.; Wei, C.; Li, R.; Zhu, B. Ontology-based noise source identification and key feature selection: A case study on tractor cab. Shock Vib. 2019, 2019, 6572740. [Google Scholar] [CrossRef]
- Ma, H.; Zhou, X.; Liu, W.; Niu, Q.; Kong, C. A customizable process planning approach for rotational parts based on multi-level machining features and ontology. Int. J. Adv. Manuf. Technol. 2020, 108, 647–669. [Google Scholar] [CrossRef]
- Belgiu, M.; Tomljenovic, I.; Lampoltshammer, T.; Blaschke, T.; Hofle, B. Ontology-based classification of building types detected from airborne laser scanning data. Remote Sens. 2014, 6, 1347–1366. [Google Scholar] [CrossRef] [Green Version]
- Guan, H.; Yang, H.; Wang, J. An Ontology-based Approach to Security Pattern Selection. Int. J. Autom. Comput. 2016, 13, 16–182. [Google Scholar] [CrossRef] [Green Version]
- SWRL Reference. Available online: https://www.w3.org/Submission/SWRL/ (accessed on 16 June 2021).
- Guan, H.; Chen, W.R.; Liu, L.; Yang, H.J. Estimating security risk for web applications using security vectors. J. Comput. 2012, 23, 54–70. [Google Scholar]
- Martinez-Rodriguez, J.L.; Hogan, A.; Lopez-Arevalo, I. Information Extraction Meets the Semantic Web: A Survey. Semant. Web 2020, 11, 255–335. [Google Scholar] [CrossRef]
- Janowicz, K.; Yan, B.; Regalia, B.; Zhu, R.; Mai, G. Debiasing Knowledge Graphs: Why Female Presidents are not like Female Popes. In Proceedings of the 17th International Semantic Web Conference (ISWC 2018), Monterey, CA, USA, 8–12 October 2018. [Google Scholar]
- Li, J.; Liu, H. Challenges of Feature Selection for Big Data Analytics. IEEE Intell. Syst. 2017, 32, 9–15. [Google Scholar] [CrossRef] [Green Version]
- Wu, X.; Yu, K.; Ding, W.; Wang, H.; Zhu, X. Online feature selection with streaming features. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1178–1192. [Google Scholar]
- Bolon-Canedo, V.; Sanchez-Marono, N.; Alonso-Betanzos, A. Recent advances and emerging challenges of feature selection in the context of big data. Knowl. Based Syst. 2015, 86, 33–45. [Google Scholar] [CrossRef]



| Related Work | Ontology | Type of Ontology | Classifier |
|---|---|---|---|
| [80] | Movie Ontology | Crisp | Lexicon-based |
| [83] | Crisp | SVM | |
| Movie Ontology, WordNet | |||
| [77] | Custom | Crisp | SVM |
| based on FCA and OWL | |||
| [85] | Movie Ontology | Crisp | Lexicon-based |
| [86] | Custom | Fuzzy | SVM |
| based on fuzzy set theory | |||
| [82] | Custom | Crisp | Lexicon-based |
| [86] | Custom | Fuzzy | Lexicon-based |
| [84] | Custom | Crisp | Lexicon-based |
| Related Work | Application | Ontology | Feature Selection | Classifier |
|---|---|---|---|---|
| [91] | Recommender | Custom | Ontology-based | KNN |
| system | domain ontology | summary | ||
| [92] | Recommender | DBpedia | Information | KNN |
| system | Gain | |||
| [93] | Recommender | Movie | Filtering | Clustering |
| system | Ontology | |||
| [94] | Manufacturing | Custom | Similarity | Rule-based |
| domain ontology | measure | |||
| [95] | Manufacturing | Custom | Filtering | Rule-based |
| domain ontology | ||||
| [96] | Manufacturing | Custom | Filtering | Rule-based |
| domain ontology | ||||
| [97] | Manufacturing | Custom | Filtering | Rule-based |
| domain ontology | (Pearson Coef.) | |||
| [98] | Manufacturing | Custom | Filtering | Rule-based |
| domain ontology | ||||
| [99] | Urban | Custom | Filtering | Random |
| management | domain ontology | Forest | ||
| [100] | Information | Custom | Filtering | Decision |
| security | domain ontology | Tree |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sikelis, K.; Tsekouras, G.E.; Kotis, K. Ontology-Based Feature Selection: A Survey. Future Internet 2021, 13, 158. https://doi.org/10.3390/fi13060158
Sikelis K, Tsekouras GE, Kotis K. Ontology-Based Feature Selection: A Survey. Future Internet. 2021; 13(6):158. https://doi.org/10.3390/fi13060158
Chicago/Turabian StyleSikelis, Konstantinos, George E. Tsekouras, and Konstantinos Kotis. 2021. "Ontology-Based Feature Selection: A Survey" Future Internet 13, no. 6: 158. https://doi.org/10.3390/fi13060158
APA StyleSikelis, K., Tsekouras, G. E., & Kotis, K. (2021). Ontology-Based Feature Selection: A Survey. Future Internet, 13(6), 158. https://doi.org/10.3390/fi13060158