
Dynamic Detection and Recognition of Objects Based on Sequential RGB Images

Abstract
:1. Introduction
2. Related Works
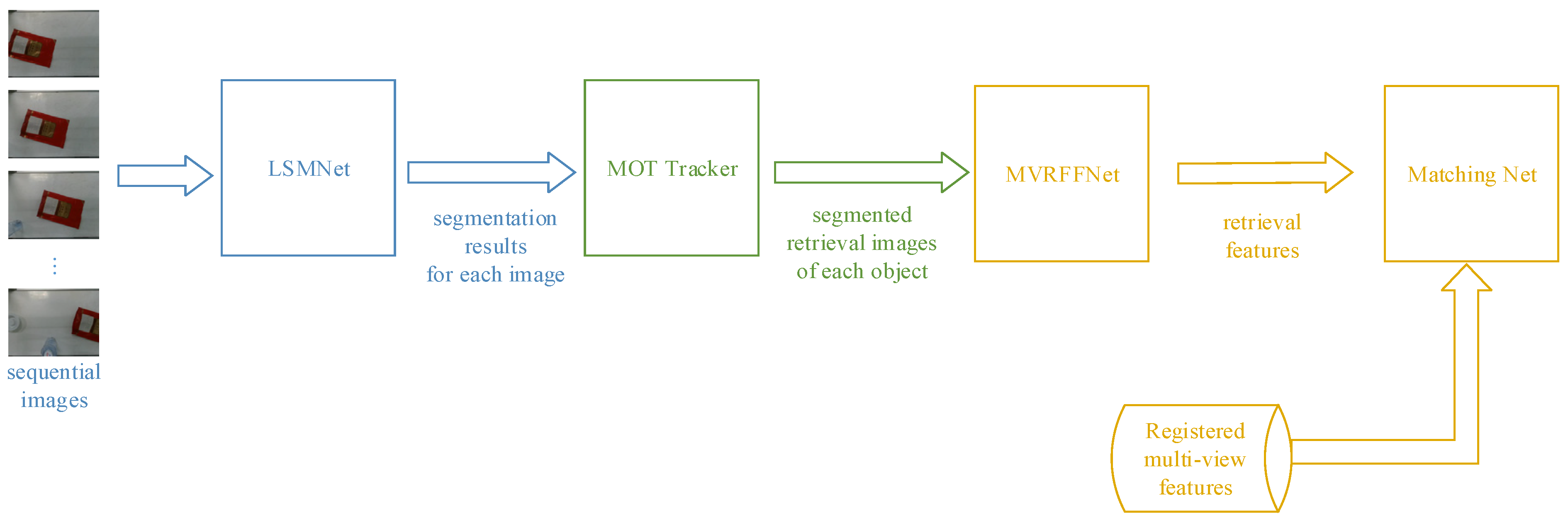
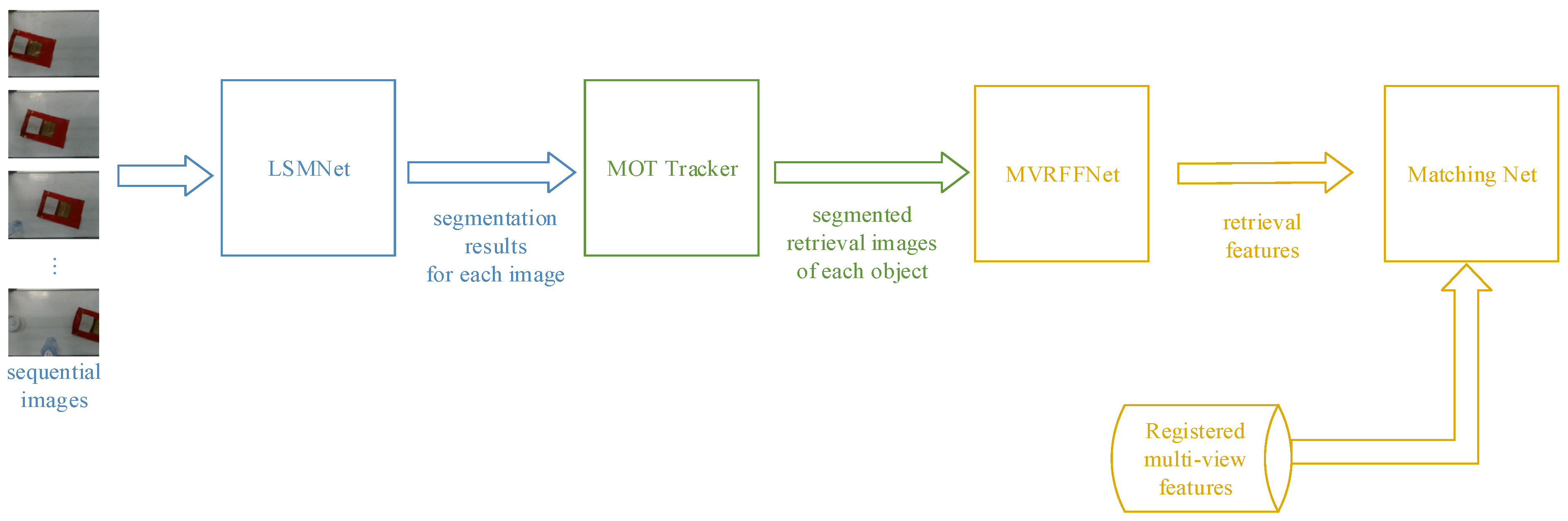
3. Framework of the System
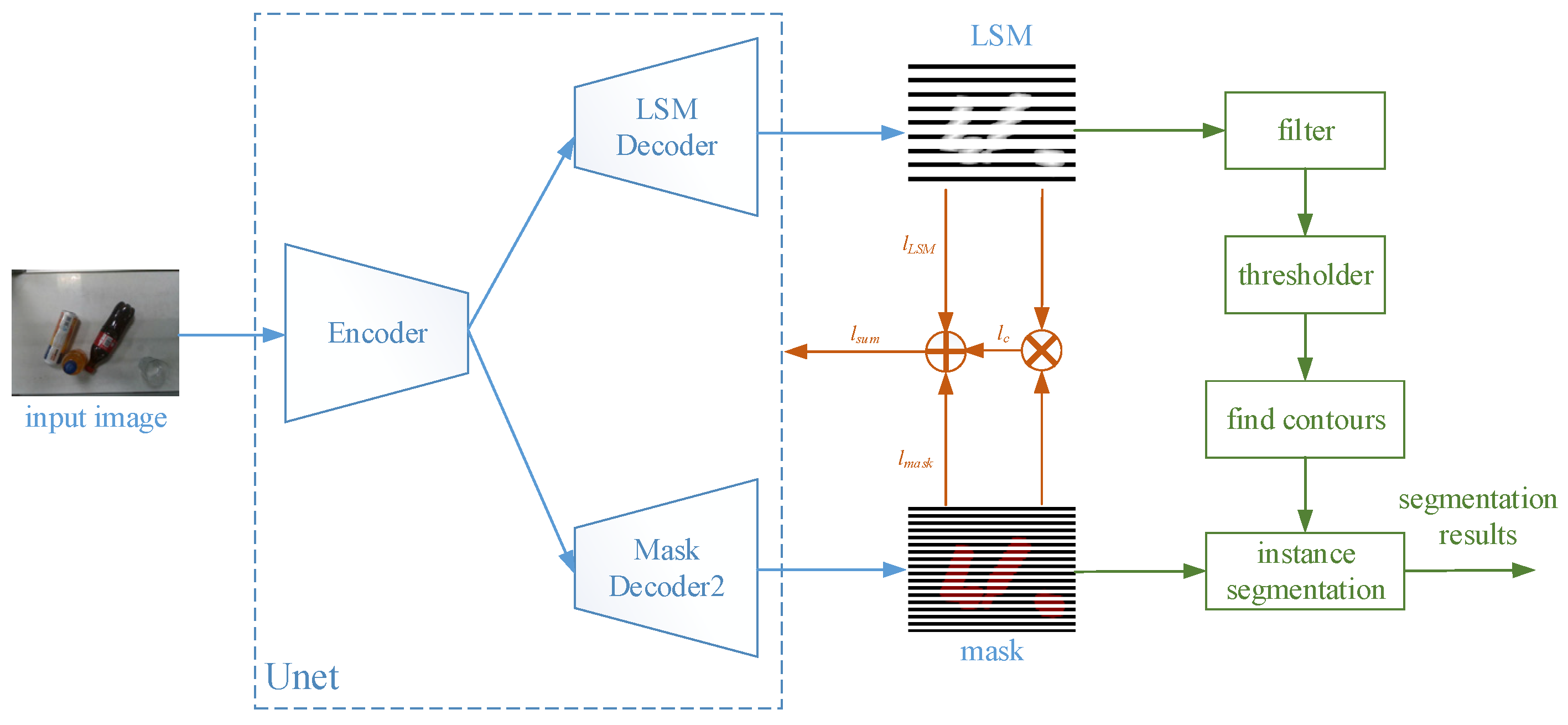
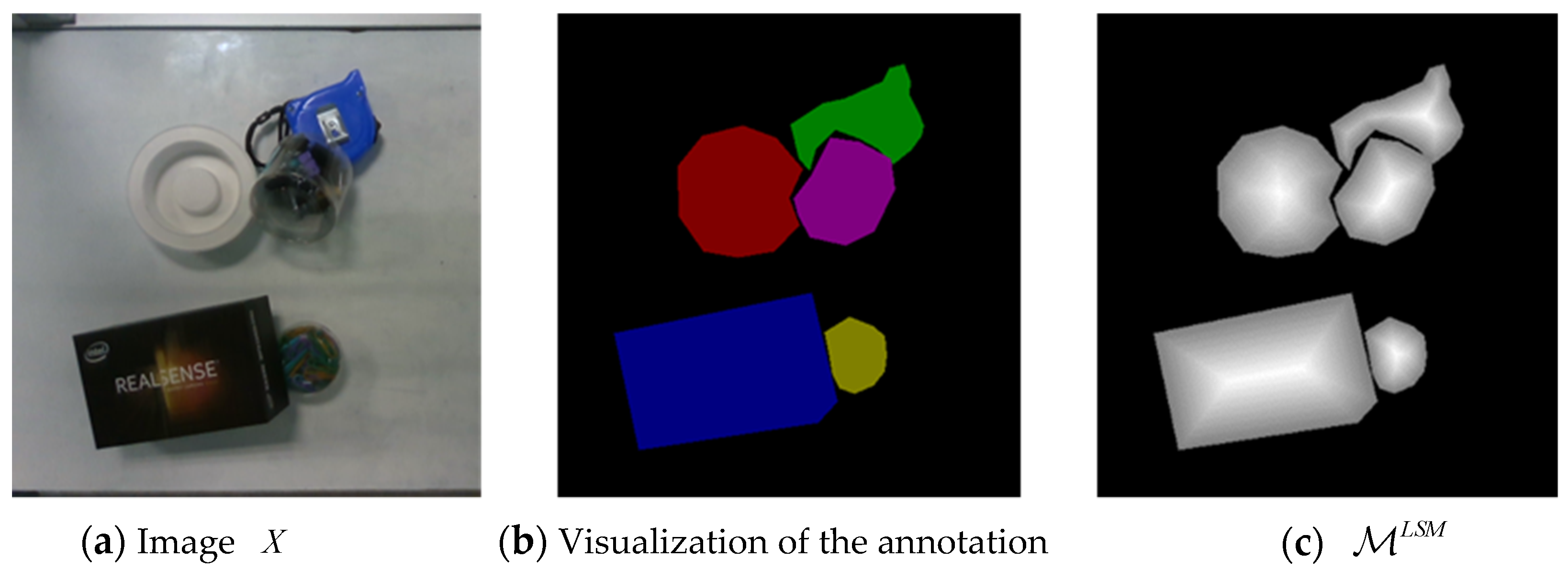
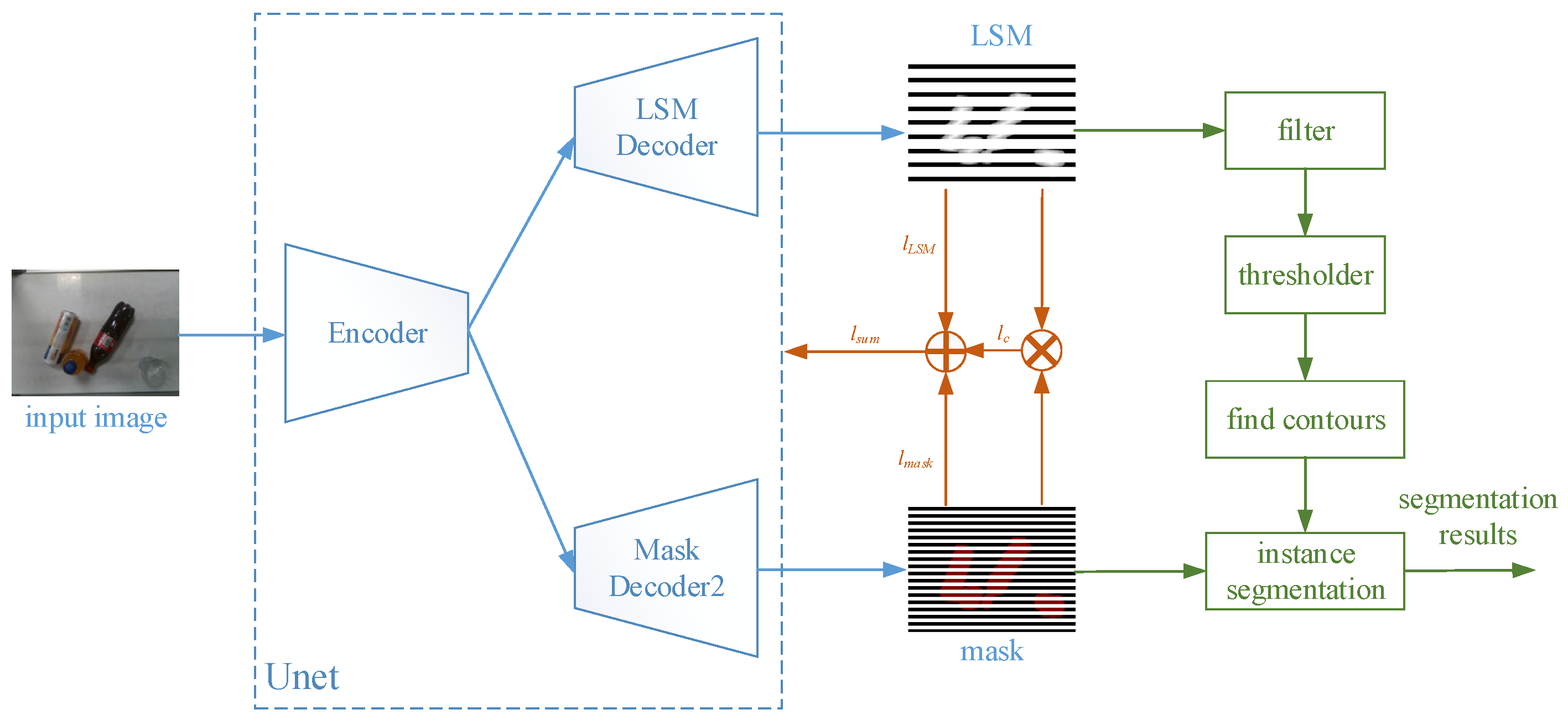
3.1. LSMNet
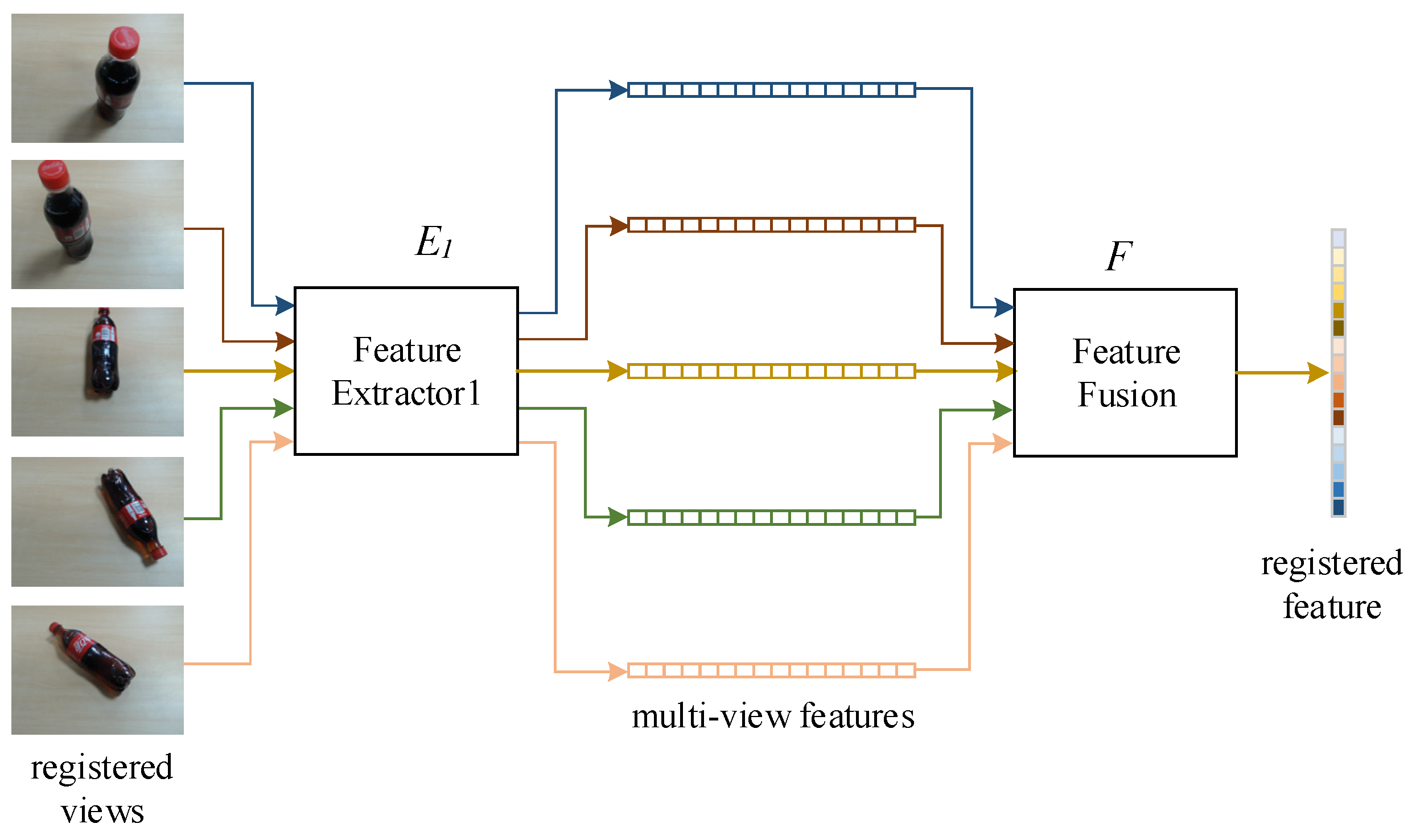
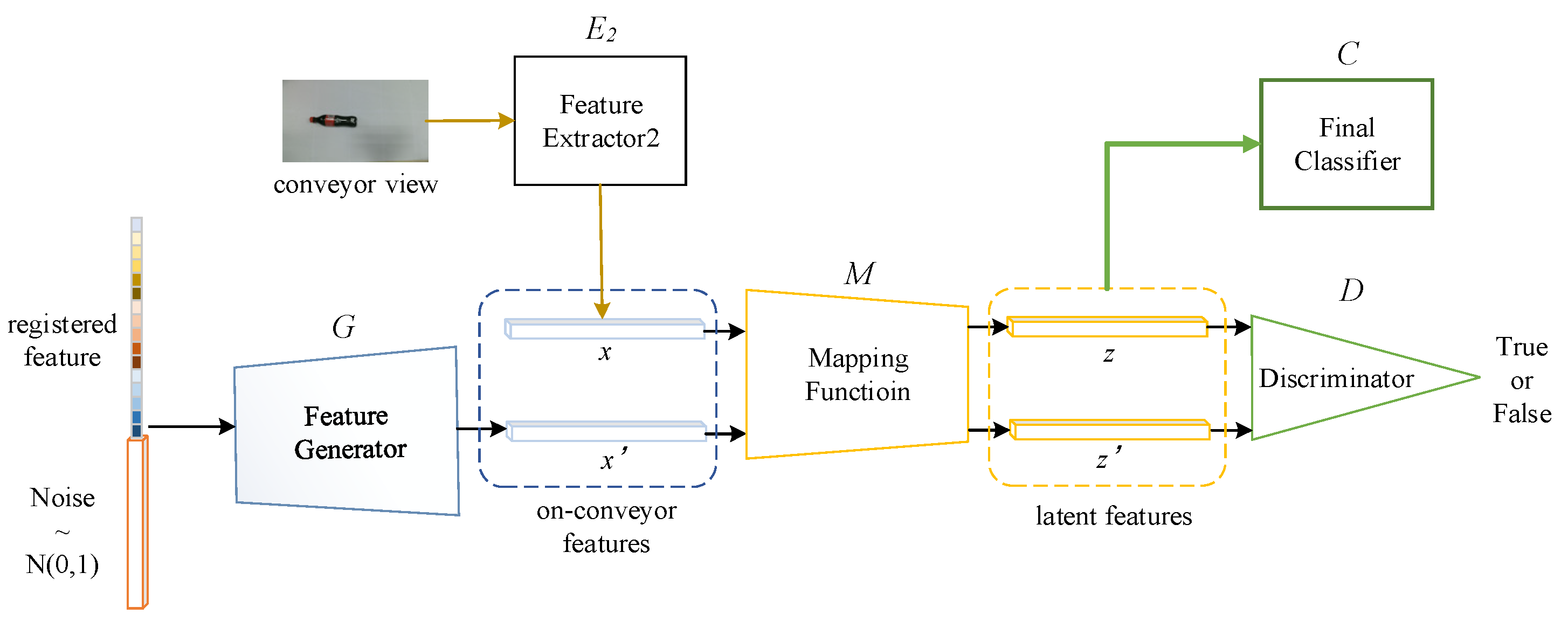
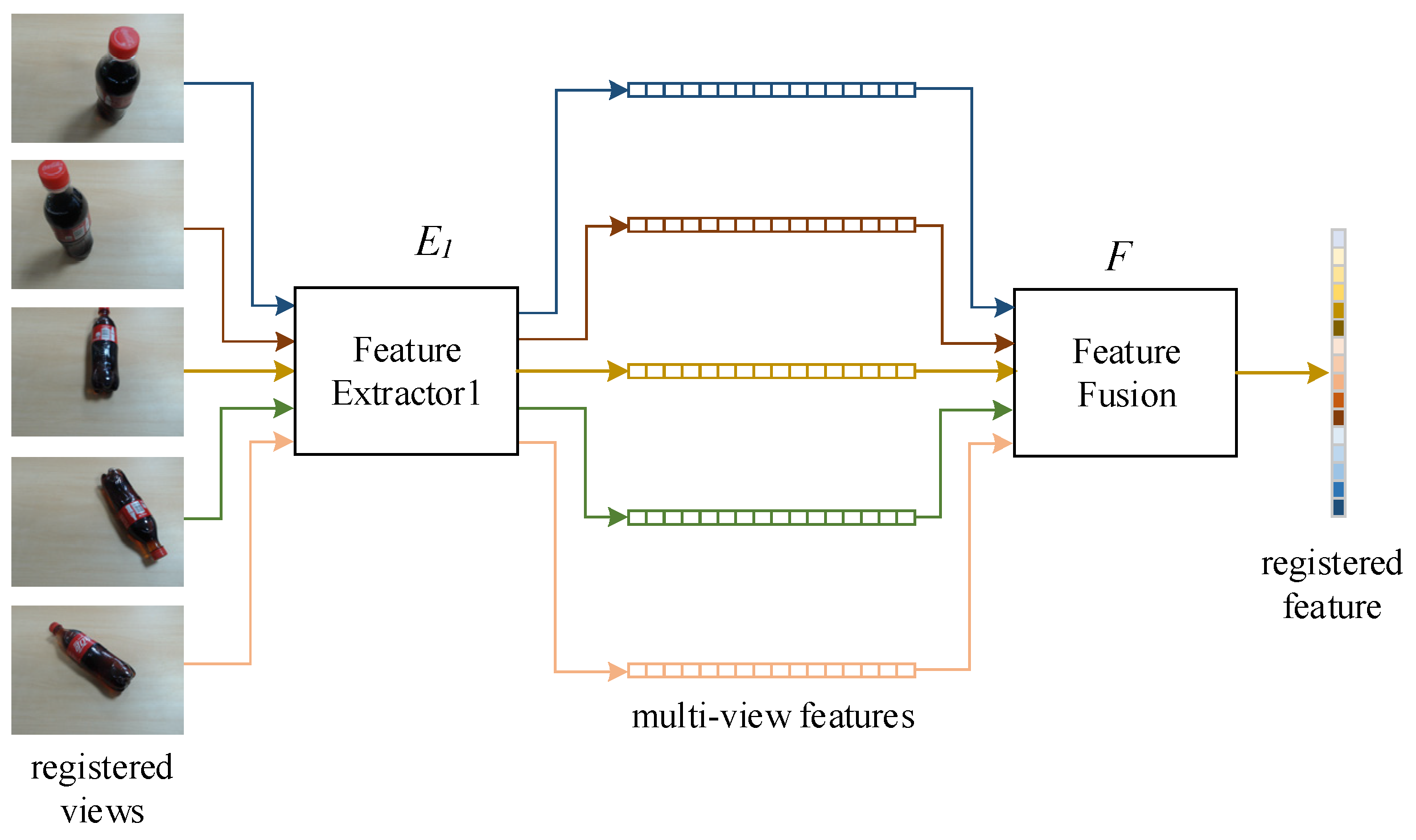
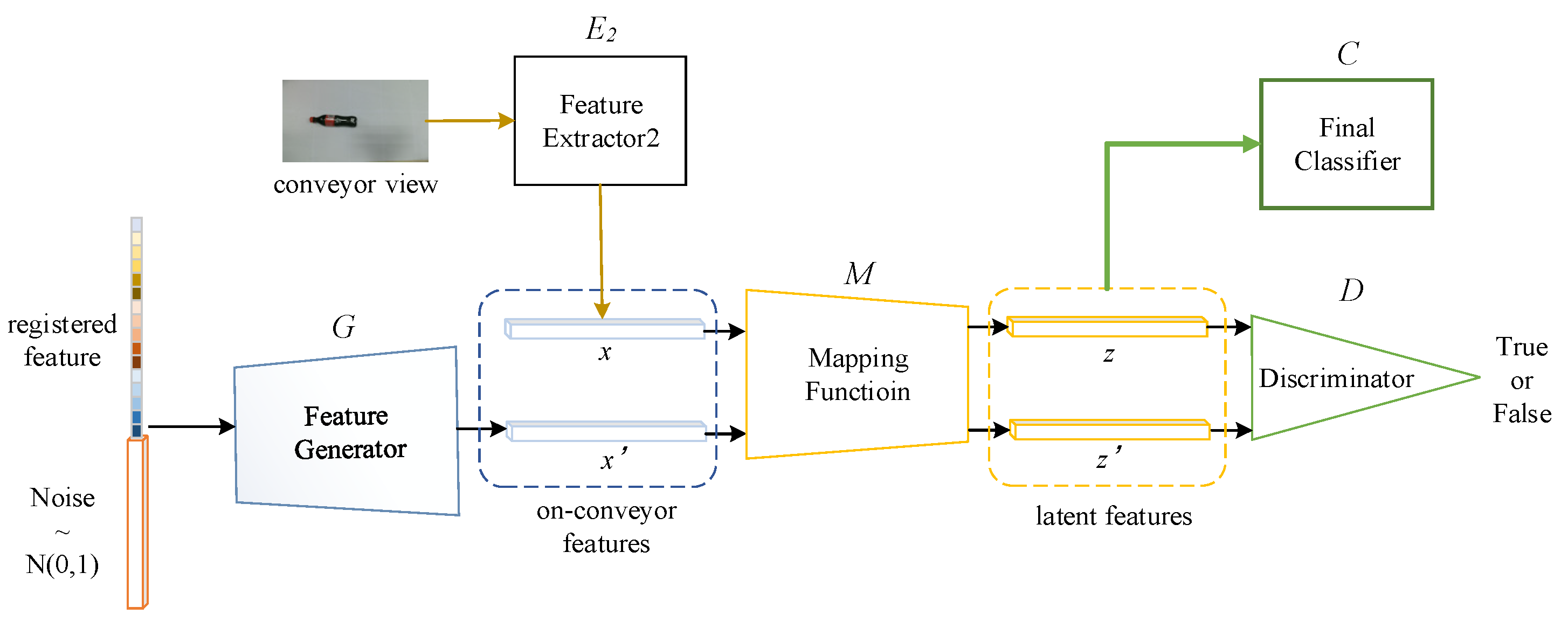
3.2. MVRFFNet
4. Experiments and Analysis
4.1. Datasets
4.1.1. OCIS Dataset and Fine-Grained Recognition Dataset
4.1.2. COCO-Car Dataset
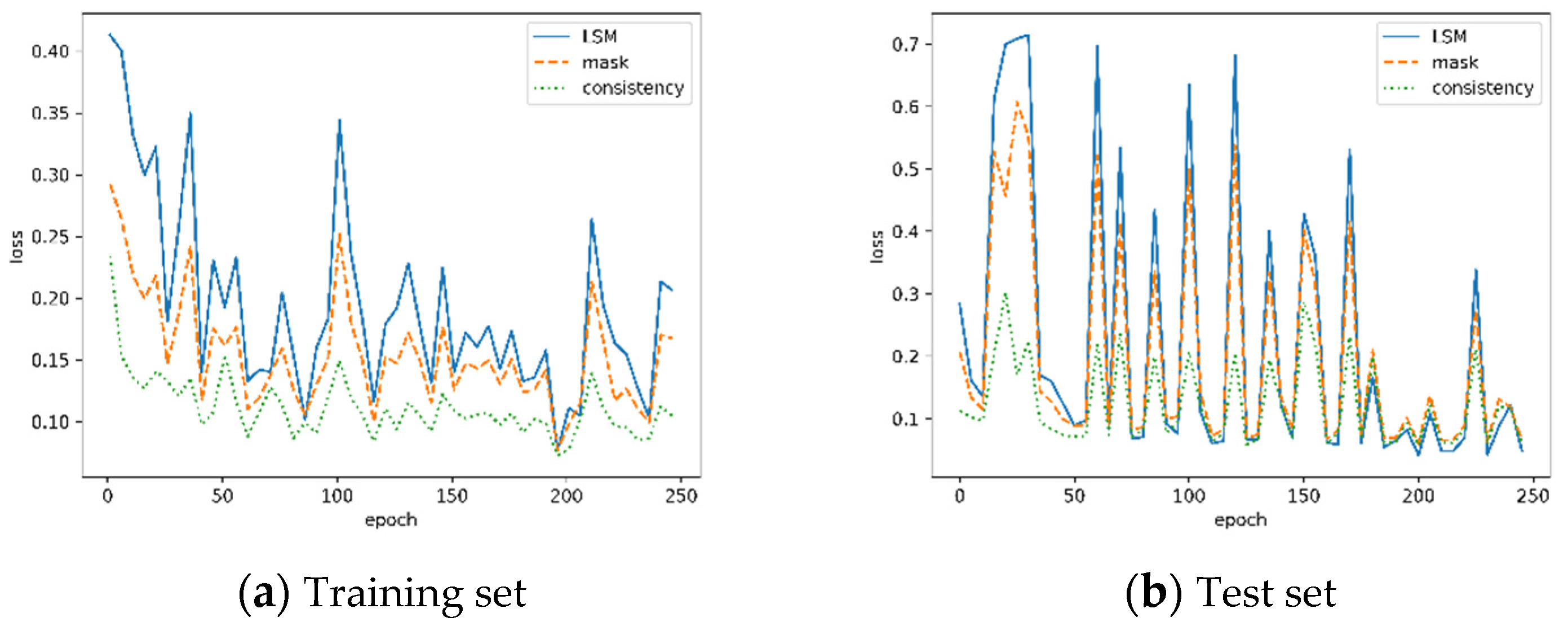
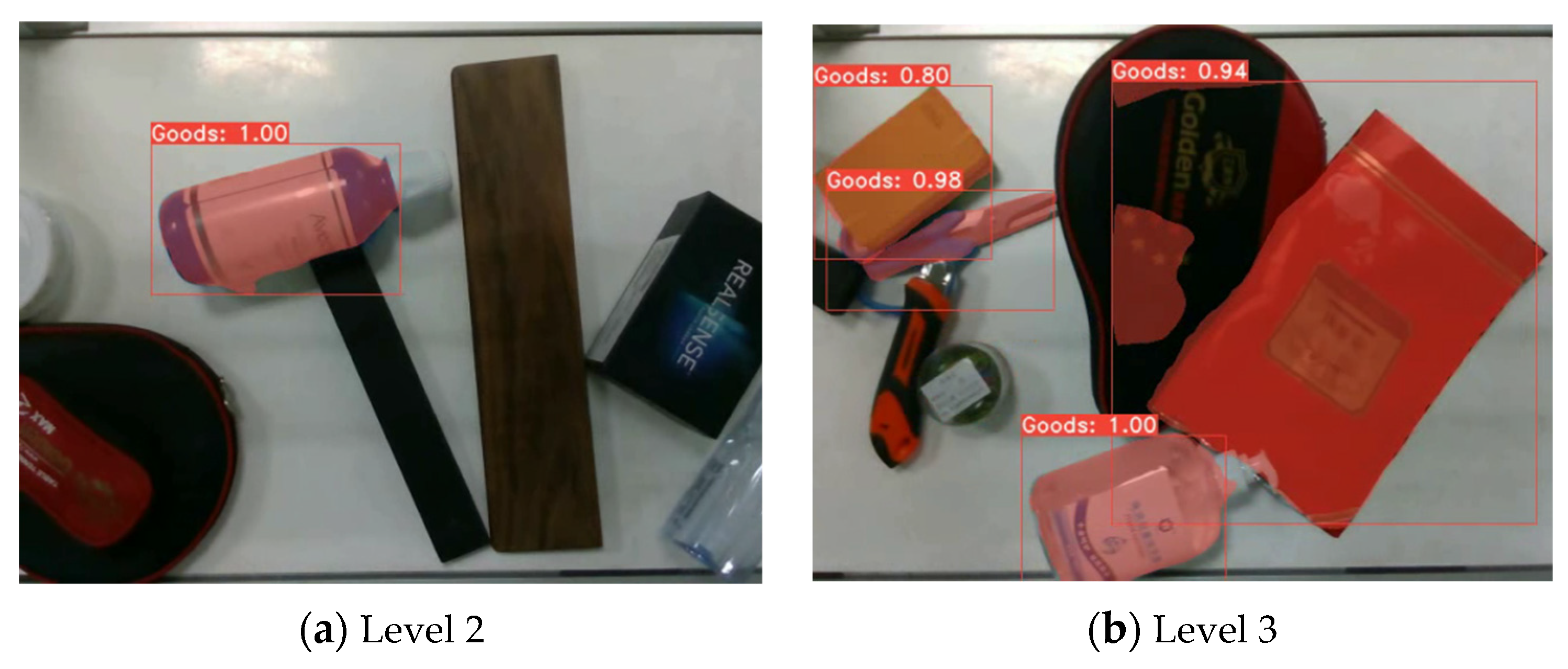
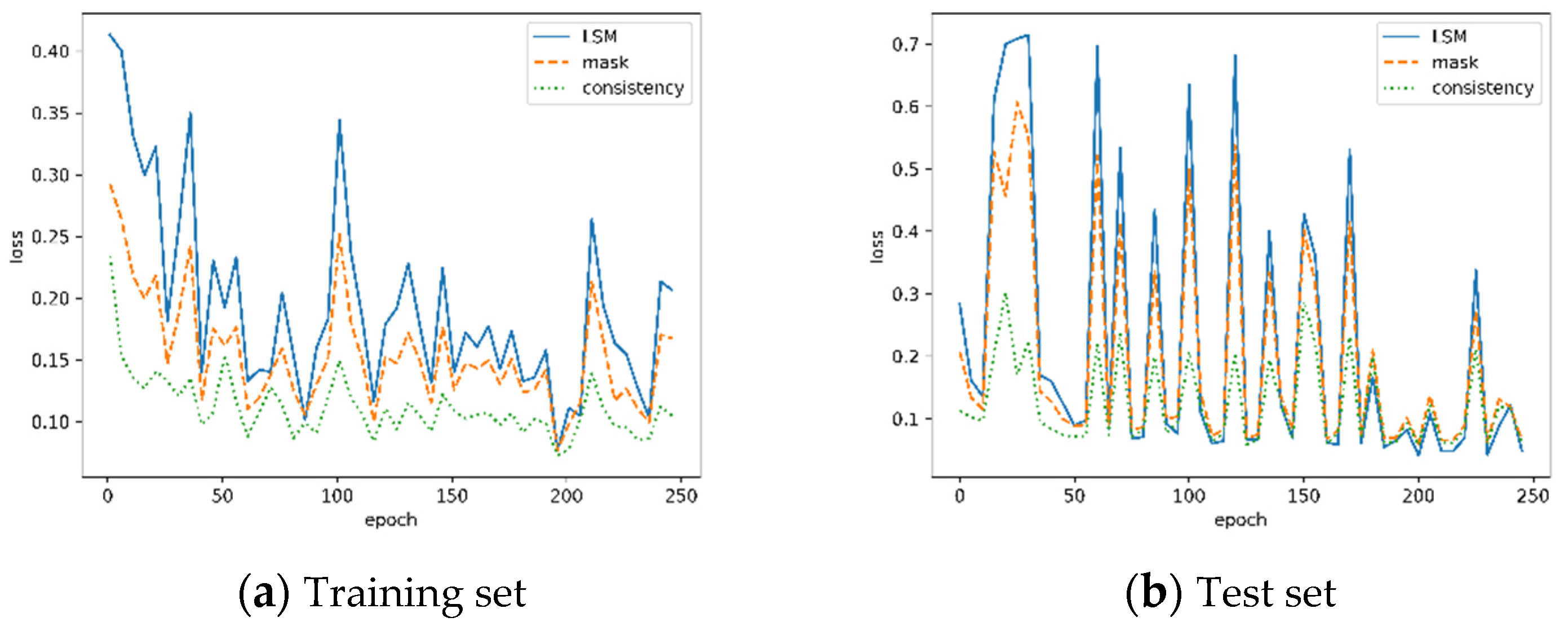
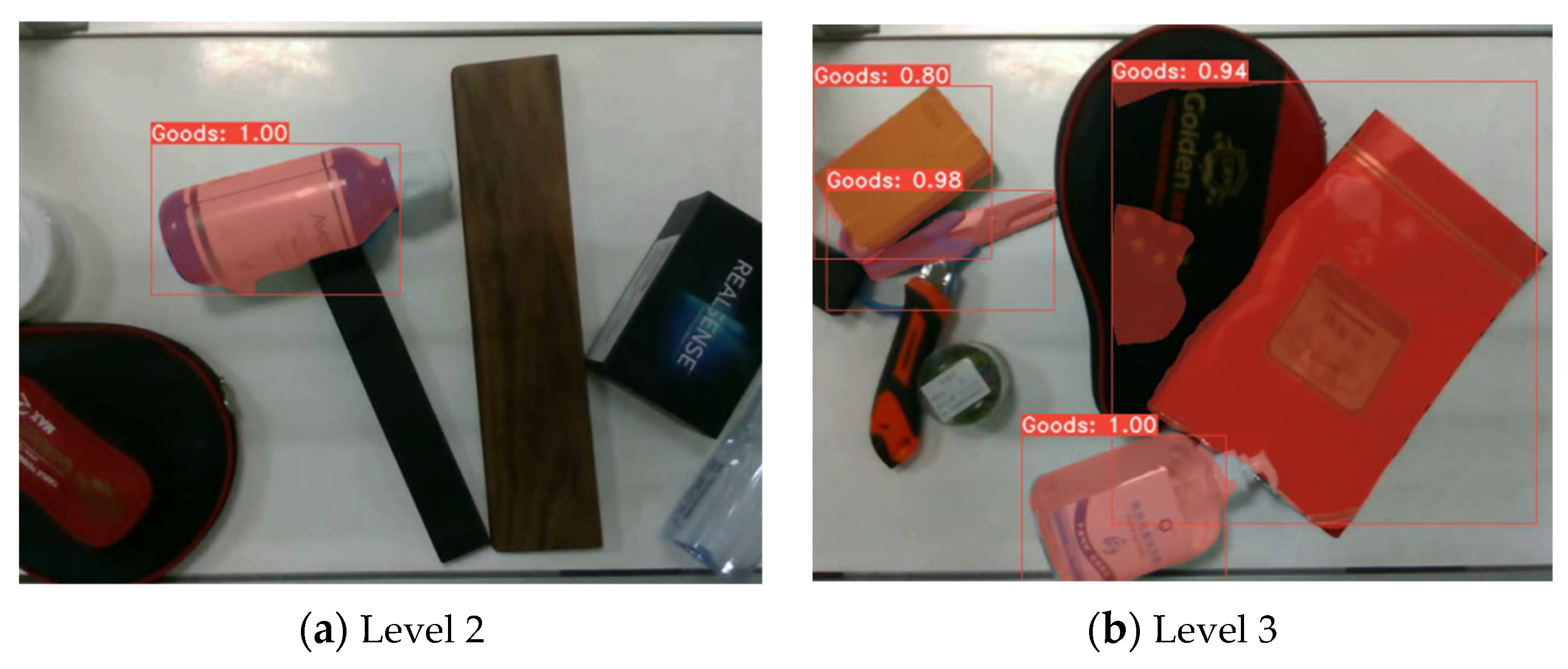
4.2. Results of LSMNet
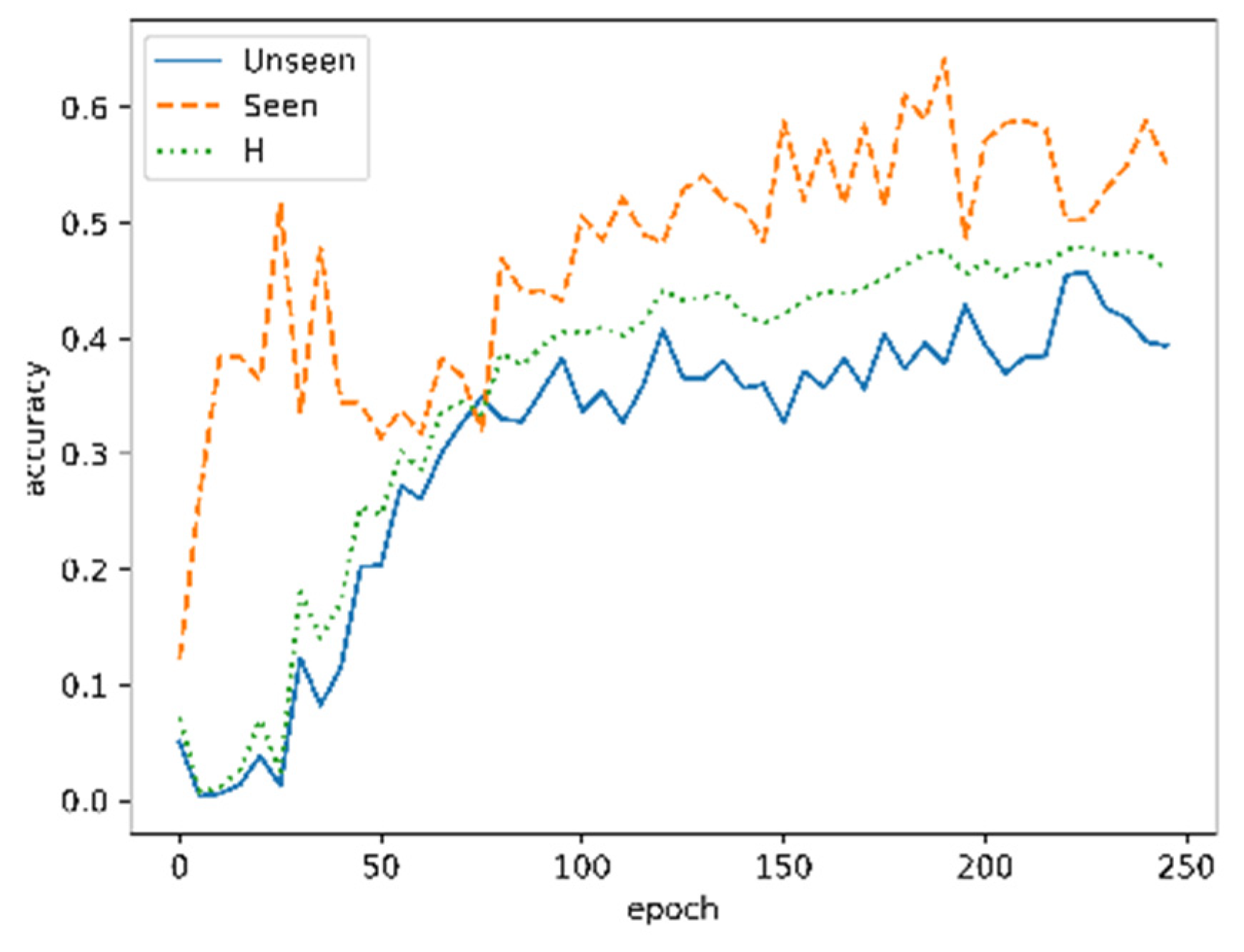
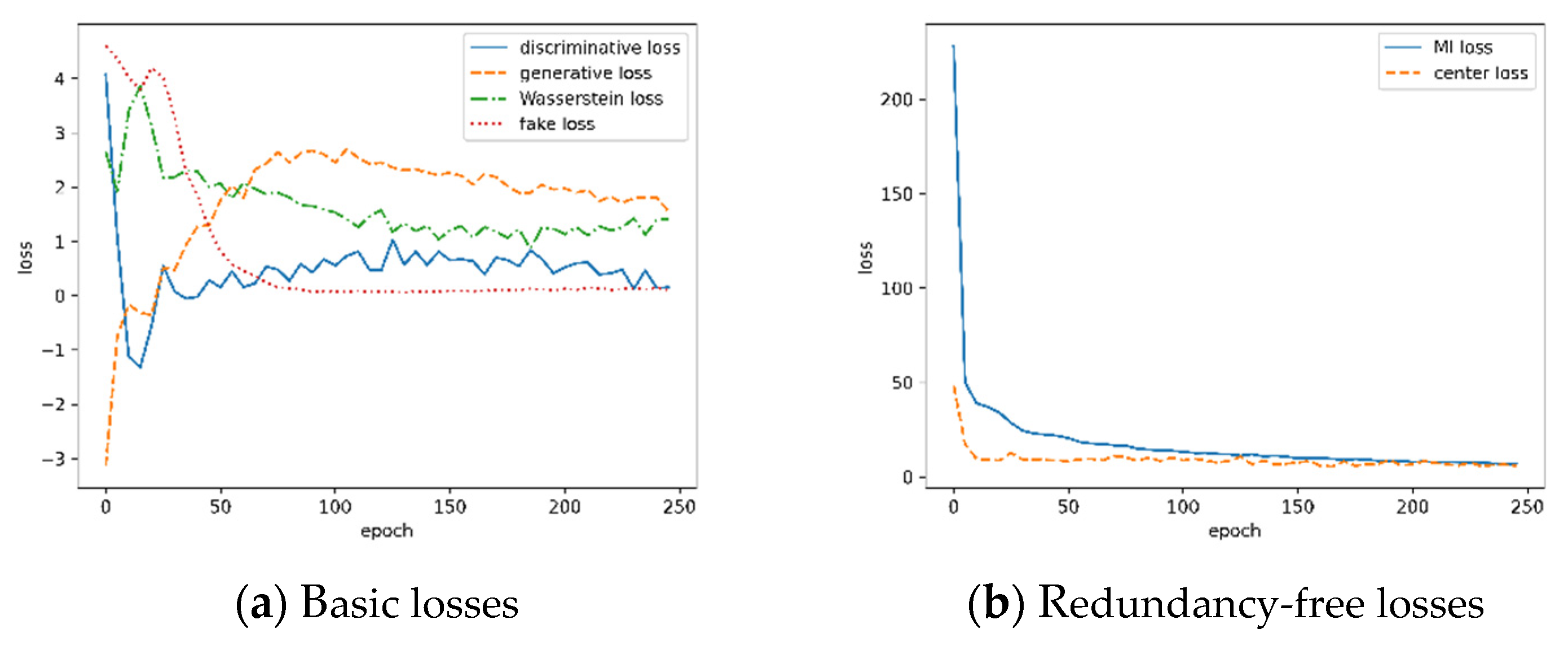
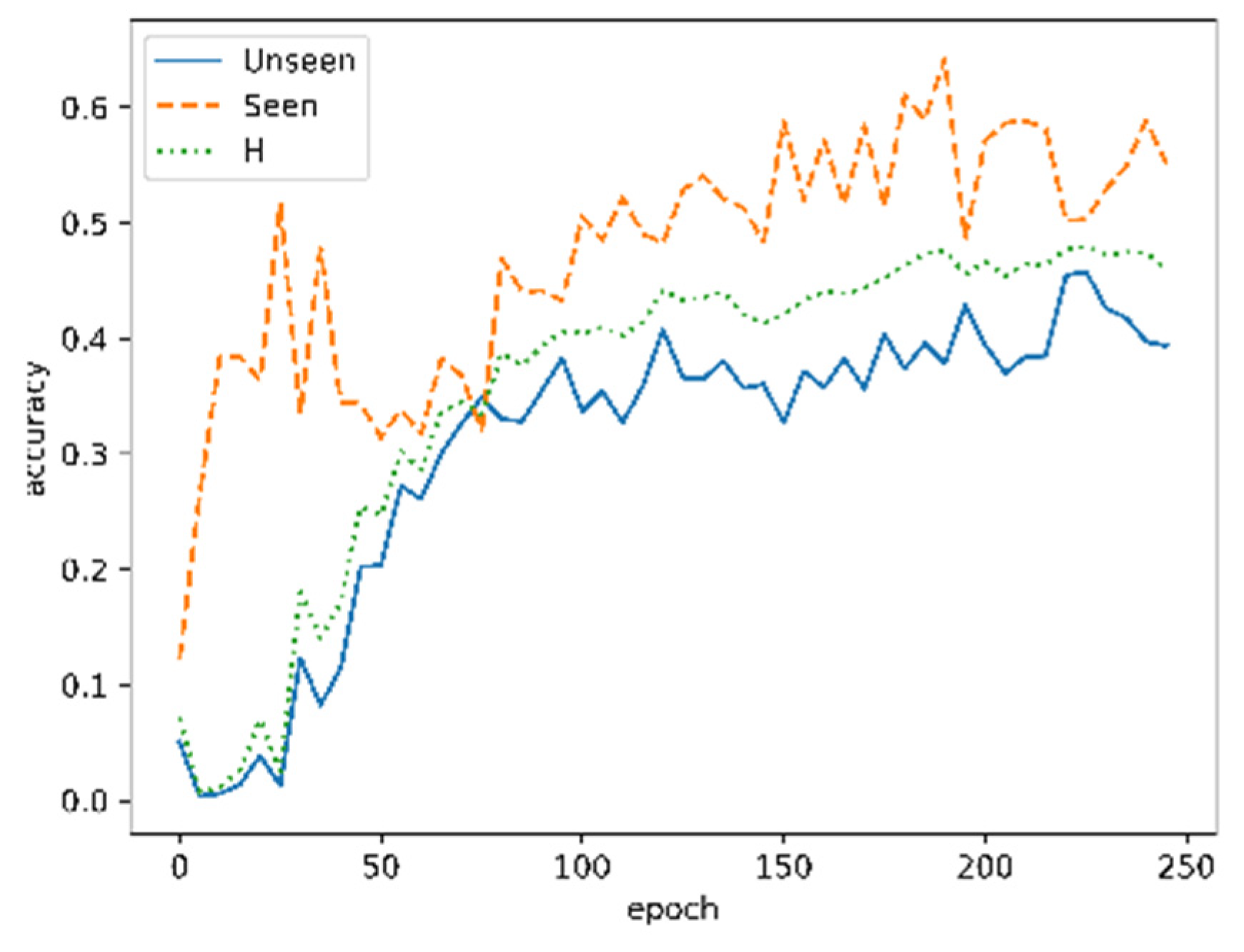
4.3. Results of MVRFFNet
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dong, S.; Zou, K.; Li, W. Fine-Grained Recognition of 3D Shapes Based on Multi-View Recurrent Neural Network. In Proceedings of the 12th International Conference on Machine Learning and Computing, Shenzhen, China, 15–17 February 2020; pp. 152–156. [Google Scholar]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-View Convolutional Neural Networks for 3d Shape Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Han, Z.; Fu, Z.; Yang, J. Learning the Redundancy-Free Features for Generalized Zero-Shot Object Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12862–12871. [Google Scholar]
- Han, Z.; Fu, Z.; Chen, S.; Yang, J. Contrastive Embedding for Generalized Zero-Shot Learning. arXiv 2021, arXiv:2103.16173. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple Online and Realtime Tracking with a Deep Association Metric. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.-K. Multiple Object Tracking: A Literature Review. Artif. Intell. 2020, 293, 103448. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. arXiv 2019, arXiv:1808.01244v2. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Object Detection with Keypoint Triplets. arXiv 2019, arXiv:1904.08189v1. [Google Scholar]
- Kim, Y.; Kim, S.; Kim, T.; Kim, C. CNN-Based Semantic Segmentation Using Level Set Loss. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1752–1760. [Google Scholar]
- Peng, S.; Jiang, W.; Pi, H.; Li, X.; Bao, H.; Zhou, X. Deep Snake for Real-Time Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8533–8542. [Google Scholar]
- Microsoft. Microsoft Common Objects in Context 2017. Available online: https://cocodataset.org/#detection-2017 (accessed on 1 September 2017).
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. arXiv 2019, arXiv:1912.06218v2. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875v3. [Google Scholar]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1–22. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Jian, S. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dai, J.; He, K.; Li, Y.; Ren, S.; Sun, J. Instance-Sensitive Fully Convolutional Networks. In Computer Vision–ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully Convolutional Instance-Aware Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2359–2367. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT++: Better Real-Time Instance Segmentation. arXiv 2019, arXiv:1904.02689. [Google Scholar] [CrossRef] [PubMed]
- Xie, E.; Sun, P.; Song, X.; Wang, W.; Liu, X.; Liang, D.; Shen, C.; Luo, P. Polarmask: Single Shot Instance Segmentation with Polar Representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 12193–12202. [Google Scholar]
- Lee, Y.; Park, J. Centermask: Real-Time Anchor-Free Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13906–13915. [Google Scholar]
- Wang, Y.; Xu, Z.; Shen, H.; Cheng, B.; Yang, L. Centermask: Single Shot Instance Segmentation with Point Representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9313–9321. [Google Scholar]
- Zhang, R.; Tian, Z.; Shen, C.; You, M.; Yan, Y. Mask Encoding for Single Shot Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 10226–10235. [Google Scholar]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Huang, Y.; Yan, Y. BlendMask: Top-down Meets Bottom-up for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 8573–8581. [Google Scholar]
- Lampert, C.H.; Nickisch, H.; Harmeling, S. Learning to Detect Unseen Object Classes by Between-Class Attribute Transfer. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Xian, Y.; Lampert, C.H.; Bernt, S.; Zeynep, A. Zero-Shot Learning—A Comprehensive Evaluation of the Good, the Bad and the Ugly. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2251–2265. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bendale, A.; Boult, T. Towards Open Set Deep Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xian, Y.; Sharma, S.; Schiele, B.; Akata, Z. F-VAEGAN-D2: A Feature Generating Framework for Any-Shot Learning. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Palatucci, M.; Pomerleau, D.; Hinton, G.E.; Mitchell, T.M. Zero-Shot Learning with Semantic Output Codes. In Proceedings of the Advances in Neural Information Processing Systems 22: 23rd Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009. [Google Scholar]
- Akata, Z.; Reed, S.; Walter, D.; Lee, H.; Schiele, B. Evaluation of Output Embeddings for Fine-Grained Image Classification. In Proceedings of the IEEE Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Bucher, M.; Herbin, S.; Jurie, F. Generating Visual Representations for Zero-Shot Classification. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2666–2673. [Google Scholar]
- Xian, Y.; Lorenz, T.; Schiele, B.; Akata, Z. Feature Generating Networks for Zero-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Felix, R.; Kumar, B.; Reid, I.; Carneiro, G. Multi-Modal Cycle-Consistent Generalized Zero-Shot Learning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Huang, H.; Wang, C.; Yu, P.S.; Wang, C.-D. Generative Dual Adversarial Network for Generalized Zero-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 801–810. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Verma, V.K.; Arora, G.; Mishra, A.; Rai, P. Generalized Zero-Shot Learning via Synthesized Examples. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Liu, W.; Chang, S.-F. Zero-Shot Visual Recognition Using Semantics-Preserving Adversarial Embedding Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1043–1052. [Google Scholar]
- Liu, S.; Long, M.; Wang, J.; Jordan, M.I. Generalized Zero-Shot Learning with Deep Calibration Network. In Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates Inc.: New York, NY, USA, 2018; pp. 2005–2015. [Google Scholar]
- Vu, T.; Kang, H.; Yoo, C.D. SCNet: Training Inference Sample Consistency for Instance Segmentation. arXiv 2021, arXiv:2012.10150. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. of Images/Videos | No. of Instances | |
|---|---|---|
| Training Set | 98 | 503 |
| Test Set | 18 | 105 |
| Level 1: 5 clip | 105 | |
| Validation Set | Level 2: 5 clip | 105 |
| Level 3: 5 clip | 105 |
| No. of Categories | No. of On-Conveyor Images | No. of Registered Views | |
|---|---|---|---|
| Training Set | 34 | 2380 | 510 |
| Seen Test Set | 34 | 1020 | - |
| Unseen Test Set | 18 | 1800 | 70 |
| No. of Images of COCO-Car (COCO2017) | No. of Instances of COCO-Car (COCO2017) | |
|---|---|---|
| Training Set | 12,251 (117,266) | 43,867 (860,001) |
| Validation Set | 535 (4952) | 1932 (36,781) |
| Level 1 | Level 2 | Level 3 | ||||
|---|---|---|---|---|---|---|
| TPR | FPR | TPR | FPR | TPR | FPR | |
| YOLACT | 0.7532 | 0.0987 | 0.7398 | 0.1035 | 0.7794 | 0.2335 |
| LSMNet | 0.9437 | 0.0224 | 0.7098 | 0.1362 | 0.6277 | 0.3361 |
| AP | APL | APM | APS | fps | |
|---|---|---|---|---|---|
| SCNet (R-50-FPN) | 0.4060 (0.4020) | 0.4640 (0.5340) | 0.4830 (0.4280) | 0.2500 (0.224) | 5 |
| Yolact (R-50-FPN) | 0.2160 (0.2060) | 0.4180 (0.3420) | 0.3830 (0.2160) | 0.1170 (0.0530) | 25 |
| LSMNet | 0.1530 (-) | 0.4150 (-) | 0.3620 (-) | 0.0450 (-) | 80 |
| Accuracy | |||
|---|---|---|---|
| Seen Categories | Unseen Categories | H | |
| Max Pooling | 0.6329 | 0.3974 | 0.4883 |
| Average Pooling | 0.6405 | 0.3962 | 0.4895 |
| RNN | 0.6217 | 0.4348 | 0.5168 |
| GNN | 0.6203 | 0.4328 | 0.5099 |
| Accuracy | |||
|---|---|---|---|
| Seen Categories | Unseen Categories | H | |
| Original feature | 0.5902 | 0.5781 | 0.5841 |
| MVRFFNet feature | 0.6870 | 0.6183 | 0.6508 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, S.; Yang, Z.; Li, W.; Zou, K. Dynamic Detection and Recognition of Objects Based on Sequential RGB Images. Future Internet 2021, 13, 176. https://doi.org/10.3390/fi13070176
Dong S, Yang Z, Li W, Zou K. Dynamic Detection and Recognition of Objects Based on Sequential RGB Images. Future Internet. 2021; 13(7):176. https://doi.org/10.3390/fi13070176
Chicago/Turabian StyleDong, Shuai, Zhihua Yang, Wensheng Li, and Kun Zou. 2021. "Dynamic Detection and Recognition of Objects Based on Sequential RGB Images" Future Internet 13, no. 7: 176. https://doi.org/10.3390/fi13070176
APA StyleDong, S., Yang, Z., Li, W., & Zou, K. (2021). Dynamic Detection and Recognition of Objects Based on Sequential RGB Images. Future Internet, 13(7), 176. https://doi.org/10.3390/fi13070176