
Preference for Number of Friends in Online Social Networks

 , , ,
, , , 
Abstract
:1. Introduction
2. Related Work
3. Datasets and Methods
3.1. Datasets
3.2. Methods
4. Results
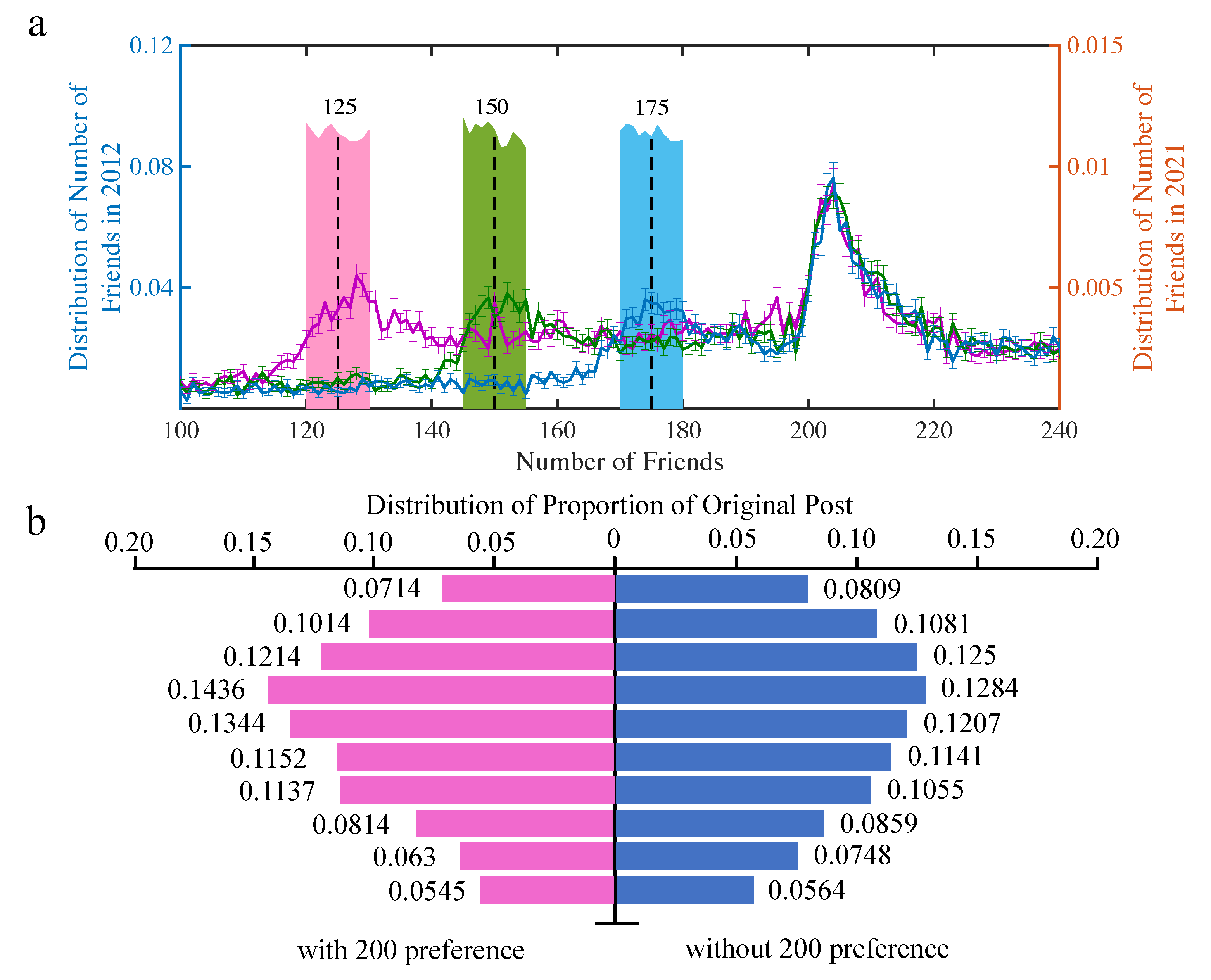
4.1. Evolution of the Number of Friends
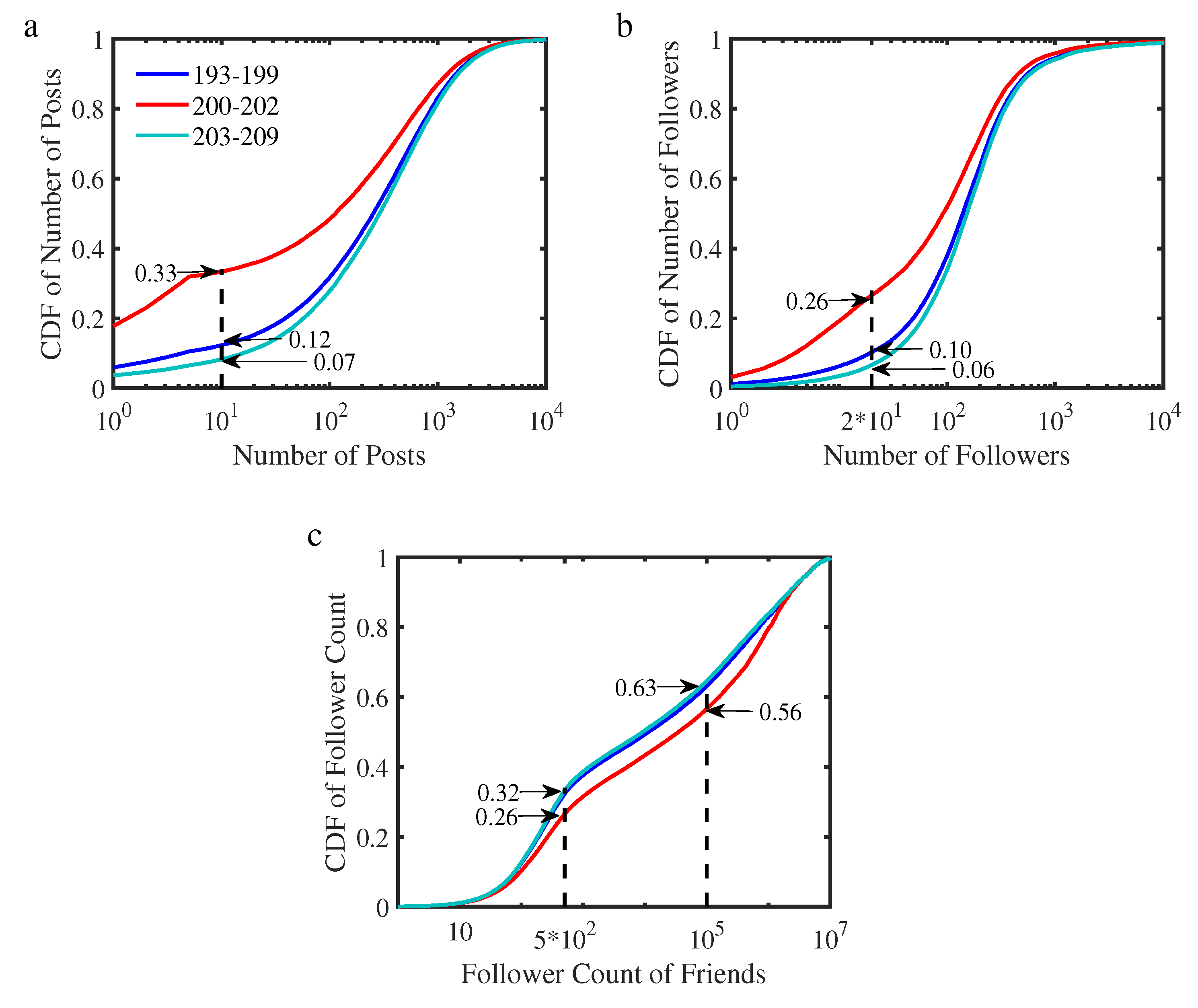
4.2. User Activity, Popularity, and Attention Tendency
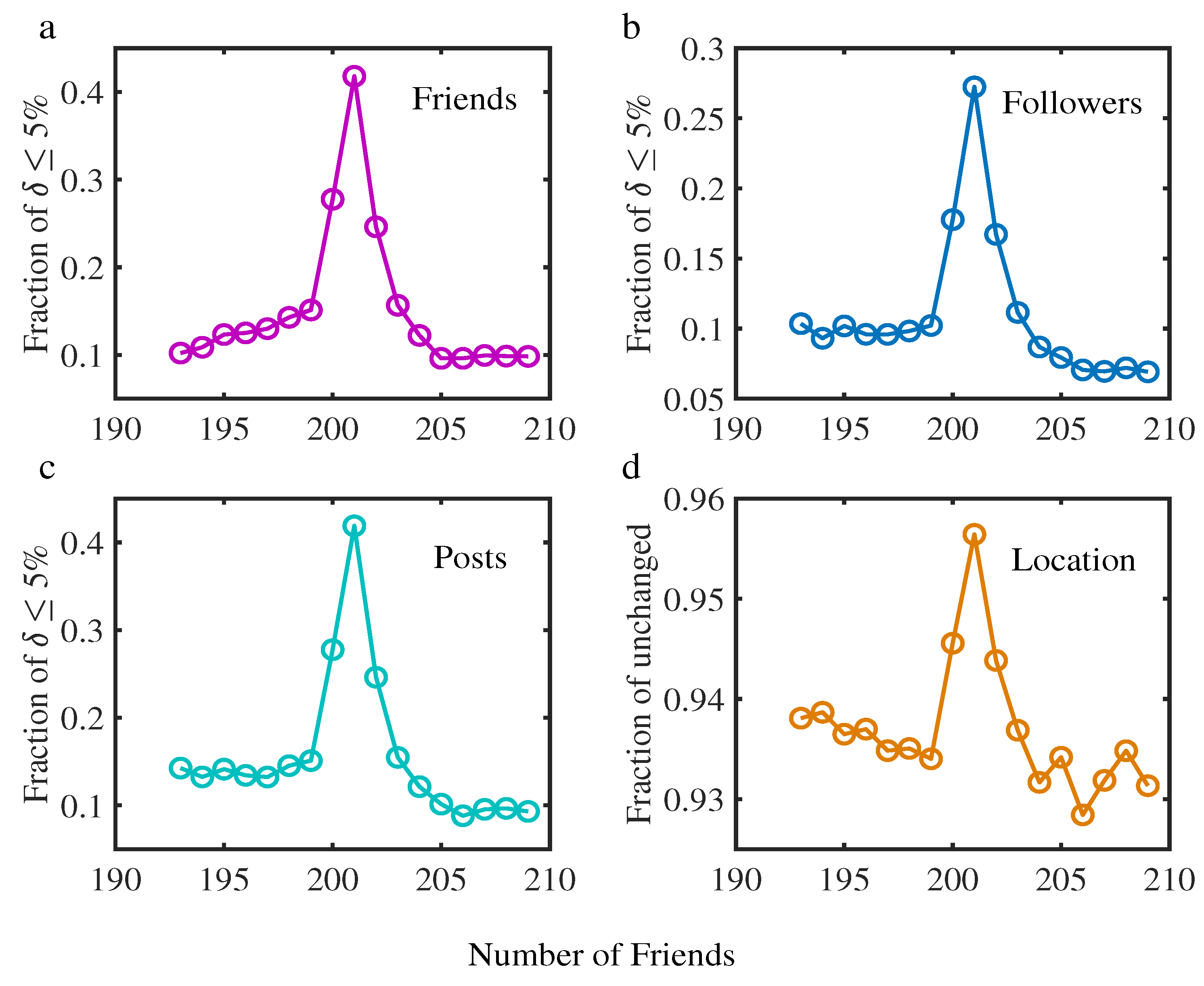
4.3. User Portrait Evolution
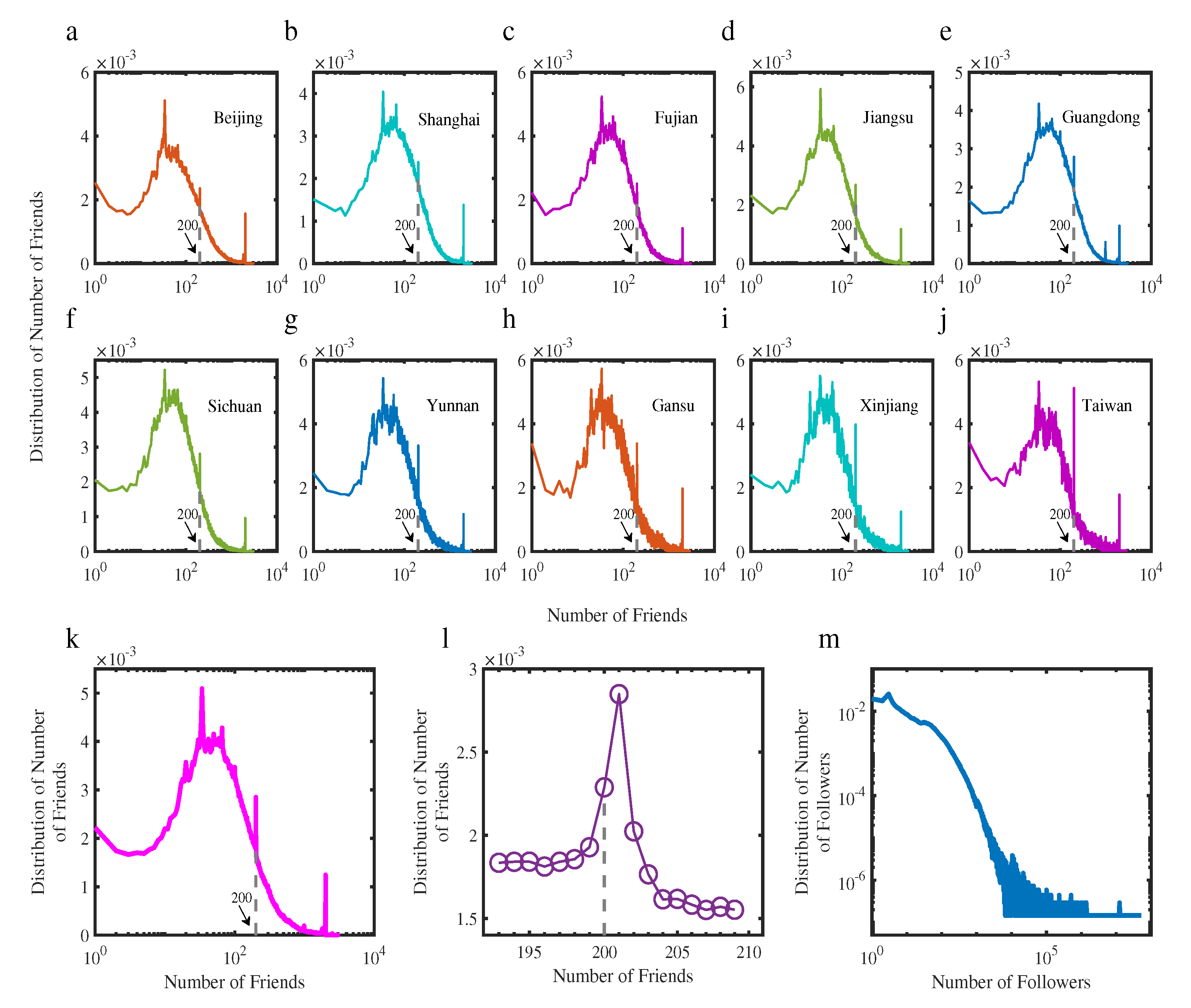
4.4. Regional Difference
4.5. Economic and Educational Level
5. Conclusions
6. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Group i | |
| Preference Intensity |
Mathematical Symbols
| δ | Fluctuation of user portraits |
| Distribution of number of friends | |
| Sum of distribution of number of friends | |
| Average of distribution of number of friends in |
References
- Heath, T.L. A History of Greek Mathematics; Cambridge University Press: Cambridge, UK, 2013; Volume 1. [Google Scholar] [CrossRef]
- Maziarz, E.A. Greek Mathematical Philosophy; Duke University Press: Durham, NC, USA, 1968. [Google Scholar] [CrossRef]
- Zhmud, L.J. “All Is Number”? “ Basic Doctrine” of Pythagoreanism Reconsidered. Phronesis 1989, 34, 270–292. [Google Scholar]
- Burkert, W. Lore and Science in Ancient Pythagoreanism; Harvard University Press: Harvard, MA, USA, 1972; ISBN 978-0674539181. [Google Scholar]
- Riedweg, C. Pythagoras: His Life, Teaching, and Influence; Cornell University Press: Ithaca, NY, USA, 2008; ISBN 978-0801474521. [Google Scholar]
- Tong, S.T.; Van Der Heide, B.; Langwell, L.; Walther, J.B. Too much of a good thing? The relationship between number of friends and interpersonal impressions on Facebook. J. Comput.-Mediat. Commun. 2008, 13, 531–549. [Google Scholar] [CrossRef] [Green Version]
- Caplan, S.E. Preference for online social interaction: A theory of problematic Internet use and psychosocial well-being. Commun. Res. 2003, 30, 625–648. [Google Scholar] [CrossRef]
- Chau, K.; Ma, V.; Ho, D. The pricing of ‘luckiness’ in the apartment market. J. Real Estate Lit. 2001, 9, 29–40. [Google Scholar] [CrossRef]
- Bourassa, S.C.; Peng, V.S. Hedonic prices and house numbers: The influence of feng shui. Int. Real Estate Rev. 1999, 2, 79–93. [Google Scholar]
- Ngan, H.F.B.; Ren, L.; O’Bree, G. Lucky 8-ending—A case study on managerial price-ending beliefs in Macao. J. Hosp. Tour. Manag. 2018, 36, 22–30. [Google Scholar] [CrossRef]
- Raesita, K.; Mahadwartha, P.A. Superstitions and Price Clustering in the Taiwan Stock Exchange. In Proceedings of the 17th International Symposium on Management (INSYMA 2020), Vung Tao City, Vietnam, 19–31 February 2020; Vũng TàuAtlantis Press: Vung Tao City, Vietnam, 2020; pp. 483–488. [Google Scholar] [CrossRef] [Green Version]
- Hock-Eam, L.; Wong, W.C.; Hiau Abdullah, N.A. Estimating the Value of Chinese Superstitions in Car Plate Number of ‘8’: A Nonlinear Decomposition Analysis. 2020. Available online: https://ssrn.com/abstract=3721982 (accessed on 16 September 2021).
- Keith, A.B. The unlucky number 13. J. R. Asiat. Soc. 1916, 48, 350–355. [Google Scholar] [CrossRef] [Green Version]
- Hassler, U.; Pohle, M.O. Unlucky Number 13? Manipulating Evidence Subject to Snooping. arXiv 2020, arXiv:2009.02198. [Google Scholar]
- Hoon Ang, S. Chinese consumers’ perception of alpha-numeric brand names. Asia Pac. J. Mark. Logist. 1996, 8, 31–47. [Google Scholar] [CrossRef]
- Boyd, C.W. Alpha-Numeric Brand Names; Advertising res Foundation, 641 Lexington Ave: New York, NY, USA, 1985. [Google Scholar]
- Hamerman, E.J.; Johar, G.V. Conditioned superstition: Desire for control and consumer brand preferences. J. Consum. Res. 2013, 40, 428–443. [Google Scholar] [CrossRef]
- Kramer, T.; Block, L. Conscious and nonconscious components of superstitious beliefs in judgment and decision making. J. Consum. Res. 2007, 34, 783–793. [Google Scholar] [CrossRef] [Green Version]
- Shum, M.; Sun, W.; Ye, G. Superstition and “lucky” apartments: Evidence from transaction-level data. J. Comp. Econ. 2014, 42, 109–117. [Google Scholar] [CrossRef]
- Pokryshevskaya, E.B.; Antipov, E.A. A study of numerological superstitions in the apartments market. Econ. Bull. 2015, 35, 83–88. [Google Scholar] [CrossRef]
- Kendall, M.G.; Smith, B.B. Randomness and random sampling numbers. J. R. Stat. Soc. 1938, 101, 147–166. [Google Scholar] [CrossRef]
- Kramer, T.; Block, L. Nonconscious effects of peculiar beliefs on consumer psychology and choice. J. Consum. Psychol. 2011, 21, 101–111. [Google Scholar] [CrossRef]
- Jain, G.; Gaeth, G.J.; Nayakankuppam, D.; Levin, I.P. Revisiting attribute framing: The impact of number roundedness on framing. Organ. Behav. Hum. Decis. Process. 2020, 161, 109–119. [Google Scholar] [CrossRef]
- Pedersen, R.T.; Larsen, M.V. Putting a number on preferences: How numerical attitudes are shaped by ideology and equivalency framing. Int. J. Public Opin. Res. 2019, 31, 528–548. [Google Scholar] [CrossRef]
- Anderson, M.; Jiang, J. Teens, social media & technology 2018. Pew Res. Cent. 2018, 31, 1673–1689. Available online: https://www.pewresearch.org/internet/2018/05/31/teens-social-media-technology-2018/ (accessed on 8 August 2021).
- Fuchs, C. Social Media: A Critical Introduction; Sage: Newcastle upon Tyne, UK, 2021; ISBN 9781529752748. [Google Scholar]
- Perrin, A. Social media usage. Pew Res. Cent. 2015, 125, 52–68. Available online: https://books.google.ru/books?id=OupAnQAACAAJ (accessed on 8 August 2021).
- Hjorth, L.; Hinton, S. Understanding Social Media; Sage: Newcastle upon Tyne, UK, 2019; ISBN 9781526425966. [Google Scholar]
- Carr, C.T.; Hayes, R.A. Social media: Defining, developing, and divining. Atl. J. Commun. 2015, 23, 46–65. [Google Scholar] [CrossRef]
- Hawi, N.; Samaha, M. Identifying commonalities and differences in personality characteristics of Internet and social media addiction profiles: Traits, self-esteem, and self-construal. Behav. Inf. Technol. 2019, 38, 110–119. [Google Scholar] [CrossRef]
- Chen, Y.; He, J.; Wei, W.; Zhu, N.; Yu, C. A Multi-Model Approach for User Portrait. Future Internet 2021, 13, 147. [Google Scholar] [CrossRef]
- Wang, X.; Zhu, W.; Liu, C. Social Recommendation with Optimal Limited Attention. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Association for Computing Machinery, New York, NY, USA, 4–8 August 2019; pp. 1518–1527. [Google Scholar] [CrossRef]
- Souri, A.; Hosseinpour, S.; Rahmani, A.M. Personality classification based on profiles of social networks’ users and the five-factor model of personality. Hum.-Centric Comput. Inf. Sci. 2018, 8, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Tadesse, M.M.; Lin, H.; Xu, B.; Yang, L. Personality predictions based on user behavior on the facebook social media platform. IEEE Access 2018, 6, 61959–61969. [Google Scholar] [CrossRef]
- Stankevich, M.; Smirnov, I.V.; Ignatiev, N.; Grigoryev, O.; Kiselnikova, N. Analysis of Big Five Personality Traits by Processing of Social Media Users Activity Features. In Proceedings of the DAMDID/RCDL, CEUR-WS, Moscow, Russia, 9–12 October 2018; pp. 162–166. Available online: http://ceur-ws.org/Vol-2277/paper29.pdf (accessed on 8 August 2021).
- Cinelli, M.; Brugnoli, E.; Schmidt, A.L.; Zollo, F.; Quattrociocchi, W.; Scala, A. Selective exposure shapes the Facebook news diet. PLoS ONE 2020, 15, e0229129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sivaraman, N.K.; Tokala, J.R.; Rupesh, R.S.C.V.; Muthiah, S.B. Event Detection in Twitter using Social Synchrony and Average Number of Common Friends. In Proceedings of the 13th ACM Web Science Conference 2021, Association for Computing Machinery, New York, NY, USA, 21–25 June 2021; pp. 115–119. [Google Scholar] [CrossRef]
- Sánchez-Romero, C.; Muñoz-Jiménez, E.M. Social and Educational Coexistence in Adolescents’ Perception in Current Social Problems through Networks. Future Internet 2021, 13, 141. [Google Scholar] [CrossRef]
- Efthimion, P.G.; Payne, S.; Proferes, N. Supervised machine learning bot detection techniques to identify social twitter bots. SMU Data Sci. Rev. 2018, 1, 5. Available online: https://scholar.smu.edu/cgi/viewcontent.cgi?article=1019&context=datasciencereview (accessed on 8 August 2021).
- Beskow, D.M.; Carley, K.M. You are known by your friends: Leveraging network metrics for bot detection in twitter. In Open Source Intelligence and Cyber Crime; Springer: Berlin/Heidelberg, Germany, 2020; pp. 53–88. [Google Scholar] [CrossRef]
- Spradling, M.; Straub, J.; Strong, J. Protection from ‘Fake News’: The Need for Descriptive Factual Labeling for Online Content. Future Internet 2021, 13, 142. [Google Scholar] [CrossRef]
- Luqiu, L.R.; Schmierbach, M.; Ng, Y.L. Willingness to follow opinion leaders: A case study of Chinese Weibo. Comput. Hum. Behav. 2019, 101, 42–50. [Google Scholar] [CrossRef]
- Xie, J.; Meng, F.; Sun, J.; Ma, X.; Yan, G.; Hu, Y. Detecting and modelling real percolation and phase transitions of information on social media. Nat. Hum. Behav. 2021, 1–8. [Google Scholar] [CrossRef]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Ji, S.; Jin, Y.; Feng, L.; Stanley, H.E.; Havlin, S. Local structure can identify and quantify influential global spreaders in large scale social networks. Proc. Natl. Acad. Sci. USA 2018, 115, 7468–7472. [Google Scholar] [CrossRef] [Green Version]
- Dunbar, R.I. Do online social media cut through the constraints that limit the size of offline social networks? R. Soc. Open Sci. 2016, 3, 150292. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hill, R.A.; Dunbar, R.I. Social network size in humans. Hum. Nat. 2003, 14, 53–72. [Google Scholar] [CrossRef]
- Weng, P.S. Lucky issuance: The role of numerological superstitions in irrational return premiums. Pac.-Basin Financ. J. 2018, 47, 79–91. [Google Scholar] [CrossRef]
- Otekunrin, O.A.; Folorunso, A.G.; Alawode, K.O. Number preferences in selected Nigerian lottery games. Judgm. Decis. Mak. 2021, 16, 1060–1071. Available online: http://journal.sjdm.org/20/201204a/jdm201204a.pdf (accessed on 8 August 2021).
- Xie, J.; Wang, X.; Feng, L.; Zhao, J.H.; Moreno, Y.; Hu, Y. Induced Percolation on Networked Systems. arXiv 2020, arXiv:2011.14034. [Google Scholar]
- Balakrishnan, V.; Khan, S.; Fernandez, T.; Arabnia, H.R. Cyberbullying detection on twitter using Big Five and Dark Triad features. Personal. Individ. Differ. 2019, 141, 252–257. [Google Scholar] [CrossRef]
- Sina Weibo Platform. Available online: https://weibo.com/ (accessed on 1 September 2012).
- Leskovec, J.; Faloutsos, C. Sampling from Large Graphs. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, Philadelphia, PA, USA, 20–23 August 2006; pp. 631–636. [Google Scholar] [CrossRef]
- Good, P.I. Resampling Methods; Springer: Berlin/Heidelberg, Germany, 2006; ISBN 10. [Google Scholar]
- Qi, W.; Liu, S.; Zhao, M. Study on the stability of Hu Line and different spatial patterns of population growth on its both sides. Acta Geogr. Sin. 2015, 70, 551–566. [Google Scholar] [CrossRef]
- National Bureau of Statistics of China Website. Available online: http://www.stats.gov.cn/ (accessed on 26 April 2018).
- Cadwalladr, C.; Graham-Harrison, E. Revealed: 50 million Facebook profiles harvested for Cambridge Analytica in major data breach. Guard 2018, 17, 22. Available online: http://freestudio21.com/wp-content/uploads/2018/04/50-million-fb-profiles-harvested-by-cambridge-analitica.pdf (accessed on 8 August 2021).
- Isaak, J.; Hanna, M.J. User data privacy: Facebook, Cambridge Analytica, and privacy protection. Computer 2018, 51, 56–59. [Google Scholar] [CrossRef]
- Bruns, A. After the ‘APIcalypse’: Social media platforms and their fight against critical scholarly research. Information, Commun. Soc. 2019, 22, 1544–1566. [Google Scholar] [CrossRef]
- Lopes, H.; Pires, I.M.; Sánchez San Blas, H.; García-Ovejero, R.; Leithardt, V. PriADA: Management and Adaptation of Information Based on Data Privacy in Public Environments. Computers 2020, 9, 77. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | N | Nickname | m | Post Content | City | Gender | ||
|---|---|---|---|---|---|---|---|---|
| 2012 | 6,836,935 | ✔ | ✔ | ✔ | ✔ | ✖ | ✔ | ✔ |
| 2018 | 189,602 | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| 2021 | 68,655 | ✔ | ✔ | ✔ | ✔ | ✖ | ✔ | ✔ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, F.; Sun, H.; Xie, J.; Wang, C.; Wu, J.; Hu, Y. Preference for Number of Friends in Online Social Networks. Future Internet 2021, 13, 236. https://doi.org/10.3390/fi13090236
Meng F, Sun H, Xie J, Wang C, Wu J, Hu Y. Preference for Number of Friends in Online Social Networks. Future Internet. 2021; 13(9):236. https://doi.org/10.3390/fi13090236
Chicago/Turabian StyleMeng, Fanhui, Haoming Sun, Jiarong Xie, Chengjun Wang, Jiajing Wu, and Yanqing Hu. 2021. "Preference for Number of Friends in Online Social Networks" Future Internet 13, no. 9: 236. https://doi.org/10.3390/fi13090236
APA StyleMeng, F., Sun, H., Xie, J., Wang, C., Wu, J., & Hu, Y. (2021). Preference for Number of Friends in Online Social Networks. Future Internet, 13(9), 236. https://doi.org/10.3390/fi13090236